
基于多模态感知与融合的无人车韧性导航系统
2021-12-02 04:57仲训昱武东杰陈登龙庄明溪吴汶鸿彭侠夫
导航定位与授时 2021年6期
仲训昱,武东杰,陈登龙,庄明溪,吴汶鸿,彭侠夫
(厦门大学航空航天学院,厦门 361005)
0 引言
在卫星拒止、物理空间变化等复杂环境下,为了使地面无人车具备全天候、全时域的韧性导航能力,需要解决基于视觉、激光雷达、惯性测量单元(Inertial Measurement Unit,IMU)、轮式里程计及磁力计等多模态环境感知与信息获取、基于信息融合的最优位姿估计与导航规划等问题[1-2]。
针对最优位姿估计问题(基于微机电系统低精度IMU),国内外学者主要开展了基于卡尔曼滤波的融合定位方法研究。其中扩展卡尔曼滤波(Extended Kal-man Filter,EKF)是低延迟、高效状态估计的典型选择,已用于履带机器人的IMU和轮式里程计融合定位(精度达1.2%D)[3],还用于美国国防部高级研究计划局(Defense Advanced Research Projects Agency, DARPA) LS3四足机器人的IMU、相机、足式里程计融合定位(精度达1.0%D)[4],以及无人机组合导航[5]等。近年,误差状态EKF(Error State EKF,ESEKF)和不变EKF(Invariant EKF,IEKF)凭借其在提高精度、收敛性及实时性方面的优势,在多源融合定位中不断得到应用[6-8]。
针对导航规划(路径规划或运动规划)问题,在以往的研究中提出了基于环境的先验3D几何信息以选择最佳通行区域[9],但在越野环境中如果只依赖几何信息则会导致令人失望的结果,例如可通行的草丛或细小植物等都会被认为是不可通过的障碍物,这显然不是类似人类的感知行为。近年来,随着深度学习技术的发展,文献[10]提出了使用语义分割实时构建环境的2.5D语义地图,同时考虑环境的语义和几何信息使得无人车在导航过程中具备类似人的感知能力,例如可以自主选择是否穿越草丛行驶。但是2.5D语义地图对环境的表示能力不足,因为无人车在感知最真实的3D环境时,仍然需要重建完整的3D环境模型;文献[9]使用的局部规划器过于简单,无法满足复杂场景;并且语义分割模型的速度也有待提高,这些缺陷极大地限制了无人车在未知越野环境中的自主导航能力。
为了解决这些问题,本文提出了一种新颖的无人车自主导航系统。首先,为了尽量提高语义分割的速度,对实时网络LedNet[11]进行裁剪以加快模型推断速度,这样可以进一步提高后续环境模型构建的实时性。其次,使用了一种相较于传统贝叶斯算法[12]速度更快的局部语义3D地图构建算法,并结合语义和几何信息实时投影生成可通行性代价地图,为规划提供必要的实时性条件。最后,改进了传统动态窗口(Dynamic Window Approach,DWA)局部规划算法[13],为其增加一个语义约束,使得DWA算法无需全局规划器的指导即可具有实时感知前方最低通行难度区域的能力。
1 基于滤波的融合定位
1.1 融合框架与子系统设计
基于滤波的多模态信息融合位姿估计的总体框架如图1所示,包括四部分:1)具备多种信号感知能力的传感器集合;2)单一模态位姿估计子系统;3)基于ESEKF的位姿估计器;4)用于提高韧性的多模态测量信息管理器。

图1 基于ESEKF的多模态信息融合总体方案图Fig.1 Overall scheme of multi-modal information fusion based on ESEKF
在各位姿估计子系统中,IMU和旋转式编码器可感知无人车的运动学或动力学状态(如角速度、加速度、轮速等);在磁场均匀不受干扰的条件下,IMU中的磁力计可以提供一个绝对的偏航角参考;相机和激光雷达等传感器可以采用同步定位与构图(Simultaneous Localization and Mapping,SLAM)算法(如VINS[14]、LeGO-LOAM[15]等),获得相对位姿信息及速度测量信息。
1.2 ESEKF多模态信息融合位姿估计器
设计的ESEKF融合算法实现流程如图2所示,主要包括全状态预测、误差状态EKF预测、误差状态EKF更新和误差补偿与重置等模块。
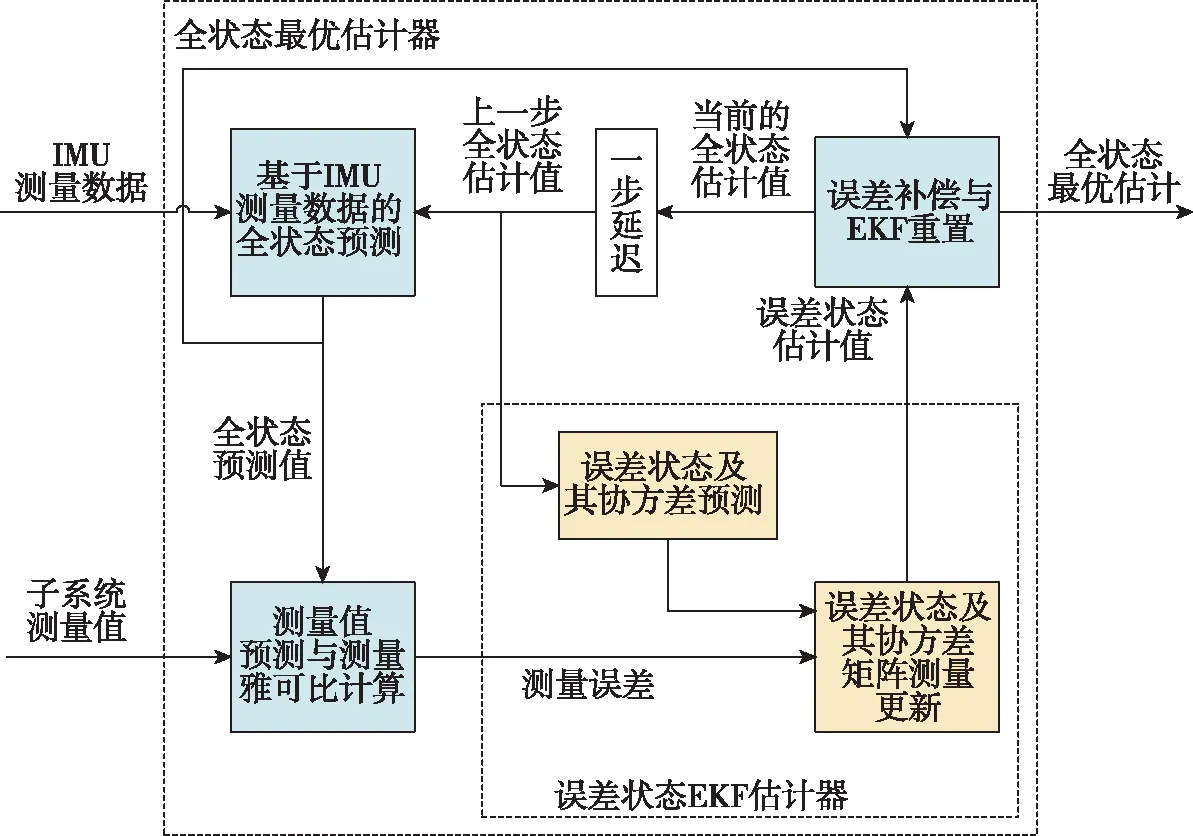
图2 基于ESEKF的多模态融合定位架构Fig.2 Multi-modal fusion positioning architecture based on ESEKF
全状态x∈R16定义为
(1)
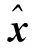
(2)
其中,位置误差δp∈R3、速度误差δv∈R3、加速度计测量偏差误差δab∈R3和陀螺仪测量偏差误差δωb∈R3由线性空间减法定义;姿态误差δθ∈R3由四元数乘法定义[16]。
ESEKF多模态信息融合位姿估计器的思路是[17]:1)利用高频IMU数据预测当前时刻的全状态和误差值;2)基于EKF算法,利用多模态子系统的测量值获得系统误差的最优估计值;3)将误差估计值和全状态预测值合成,获得系统全状态的最优估计。
(1)全状态预测估计过程
设am和ωm分别为加速度计和陀螺仪的测量值,利用数值积分知识可得到全状态的预测方程,设为
(3)
(4)
其中,R∈SO(3)表示姿态的旋转矩阵;g为重力加速度矢量;q{}表示将旋转向量转换为相应的四元数;⊗表示四元数乘法。
(2)误差状态EKF估计过程
δxk+1=Fkδxk+wF,k
(5)
其中
Fk=
wF,k~N(0,QF)
其中,I为单位矩阵;0为零矩阵;[]×表示将向量转换为对应的反对称矩阵;wF,k为过程噪声,其协方差设为QF,k。
当前时刻的全状态测量模型设为
yk+1=h(xk+1)+wh,k+1
(6)
其中,函数h的具体形式由子系统的输出性质决定;wh,k+1表示测量噪声,其协方差记为Rh,k+1。
根据EKF框架,误差状态最优估计过程为[16]
(7)
其中,P为滤波协方差矩阵;Hk+1为测量雅可比矩阵,计算公式如下
(8)
其中
位置测量方程为
pm,k+1=pk+1+wp,k+1
(9)
其中,pm,k+1为测量值;wp,k+1为位置测量噪声;测量雅可比为三维单位矩阵。
姿态测量方程为
qm,k+1=qk+1+wq,k+1
(10)
其中,qm,k+1为测量值;wq,k+1为姿态测量噪声;测量雅可比为四维单位矩阵。
(3)全状态更新估计过程
1)误差补偿
(11)
2)误差重置
当完成对全状态预测值的补偿后,需要对EKF误差状态估计器中的变量进行重置,过程如下[16]
(12)
其中
2 环境感知与语义3D地图构建
2.1 基于深度语义分割的环境感知
为提高实时性,对LedNet编码器端进行修改,得到计算速度更高的语义分割网络(如图3(a)所示),称为MiniLedNet。MiniLedNet在LedNet的基础上,引入瓶颈型深度可分离卷积模块(SS-Next-bt,如图3(b)所示),相较于LedNet的SS-nbt模块添加了具有扩张率的深度可分离卷积以及MobileNext提出来的SandGlass模块[18]。由于1×1的点卷积对通道数进行了缩小导致部分信息的丢失,所以又引入了MobileNext的线性瓶颈模块,再将这三者组合得到SS-Next-bt,该模块可在高通道特征层中大大减少运算量,同时仅小幅降低准确率,从而对LedNet模型进行压缩以提高推断速度。
2.2 融合激光点云的语义3D地图
如图4所示,双目相机RGB图像经MiniLedNet得到语义图像,与 3D 激光雷达的点云融合得到语义点云,再结合融合定位信息,通过八叉树存储结构的占有更新、语义更新建立局部和全局语义3D地图[19]。此外,为了获得更高精度的语义3D地图,通过语义标签分布修正和运动目标去除算法对地图进行纠错和修正,为地面无人车平台执行复杂任务提供准确的导航特征地图。
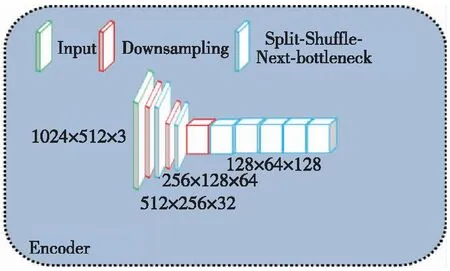
(a) MiniLedNet
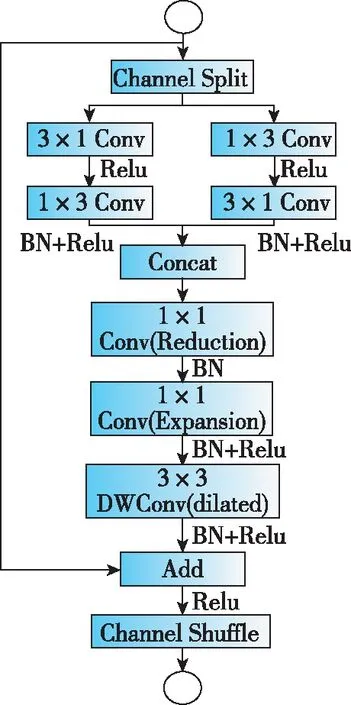
(b) SS-Next-bt图3 MiniLedNet 编码器及其Split-Shuffle-Next-bottleneck模块Fig.3 The encoder and its Split-Shuffle-Next-bottleneck module
(1)单帧语义融合
经外参标定对齐激光雷达和相机的坐标后,利用语义图像,将语义标签及其类别概率和3D点云进行关联[20]。语义分割网络首先在一帧RGB图像I上对每个像素(i,j)分别计算其属于类别k的置信度Ci,jk,然后使用softmax正则化函数将置信度转换为归一化的标签概率
(13)
为了得到每个像素最可能的标签概率,取所有类别标签概率的最大值
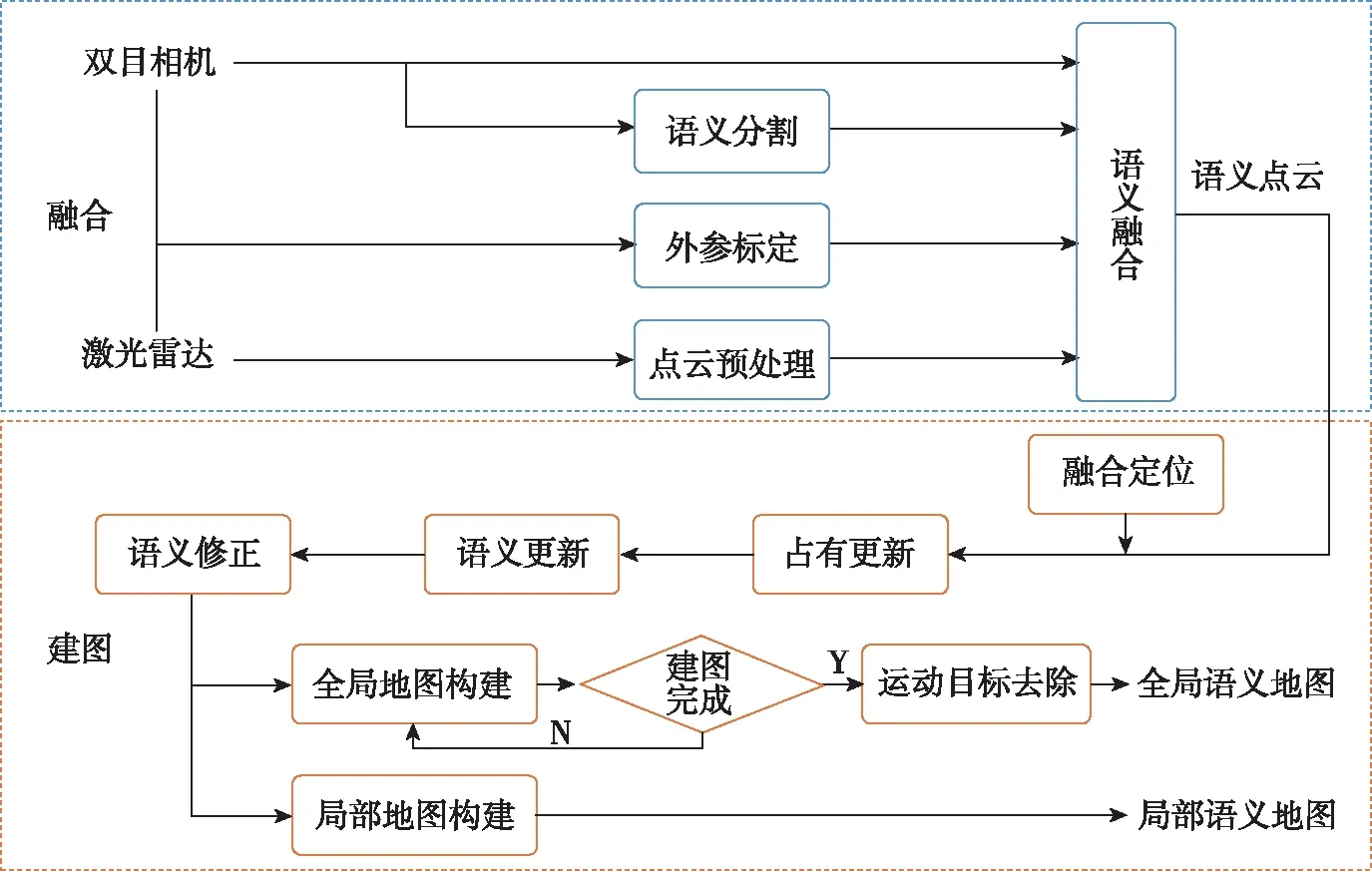
图4 语义3D地图构建总流程图Fig.4 The building process of semantic 3D map
Pi,j=
max[p(1|Ii,j),p(2|Ii,j),…,p(k|Ii,j)]
(14)
在得到每个像素的语义标签和标签概率后,通过外参矩阵将其与对应的点云进行融合得到语义点云。
(2)体素占有概率更新
当新的单帧融合后的语义点云插入到八叉树存储结构的地图时,八叉树内每个体素占有概率的更新公式如下[21]
P(n|z1:t)=
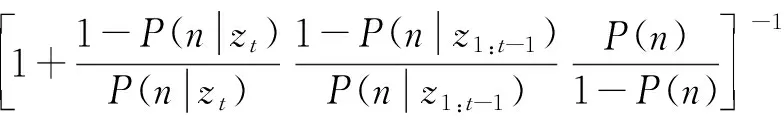
(15)
其中,z1:t为第1~t时刻所有的观测数据;P(n|z1:t)为第n个节点基于第1~t时刻观测数据的后验概率;P(n|zt)为第n个节点基于当前观测数据的占有概率;P(n)为节点n的先验概率(取0.5)。
根据 logit 变换,将式(15)简化成如下形式
L(n|z1:t)=L(n|z1:t-1)+L(n|zt)
(16)
(3)体素语义信息更新
采用八叉树结构存储语义地图,每个语义点云用立方体栅格表示,其中每一个体素在多帧图像中都可能被观察到并可能被语义分割网络预测一个不同的语义类别,因此需要通过融合多个时刻观察到的语义来确定一个体素的最终类别。
为保证实时性(尤其当语义类别较多时),采用最大概率更新方法。体素v在t时刻的语义类别为L(vt),标签概率P(c|zt)依赖于当前体素测量值zt和t-1时刻的状态量P(c|zt-1),则最大概率融合后的当前体素v的语义类别L(vt)的计算公式如下
(17)
最大概率融合后的当前体素v的标签概率P(c|zt)的计算如下
P(c|zt)=
(18)
其中,ε∈(0,1)表示t时刻体素v的语义标签概率对t-1时刻体素v语义标签概率的修正因子,取ε=0.9。
(4)体素语义修正
在更新完语义信息后,由于外参标定和语义分割存在误差,所以导致个别体素语义类别分配错误,因此采用空间推理法减少这些体素。首先,检测体素的K近邻体素,并计算这些体素和体素之间的平均距离。随后,如果平均距离小于某个阈值,则它对应于分割良好的体素,否则它被认为是噪声体素。表达式如下
(19)
(5)运动目标去除
当语义地图完成时,许多地图点是由移动的物体产生的,这使得地图变得混乱,必须消除这些地图点。采用一种具有低参数特征的基于密度的噪声应用空间聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)算法,基于密度对体素进行分组。然而,其缺点是基于生成的映射的大小,存储效率显著降低,因此需要长的计算时间。为了解决这个问题,将三维体素表示转换为二维栅格表示。通过将所有三维体素投影到相同的Z来实现,定义如下
(20)
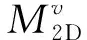
(21)
其中,Di为体素数量;Li为ith聚类的长度;ηd和ηl为相应的阈值。
3 基于语义3D地图的运动规划
如图5所示,基于以上方法构建以无人车为中心的局部语义 3D 地图后,通过语义和高度投影得到可通行性代价地图;基于投影得到2D地图后,运动规划器能够感知可通过区域(道路、草丛等)、不可通过区域(树木和其他障碍等)以及高度信息,从而选择一条可通行路径。
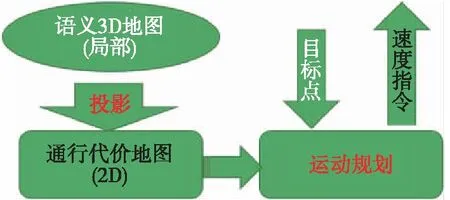
图5 基于语义地图的运动规划Fig.5 Motion planning based on semantic map
3.1 语义和高度投影
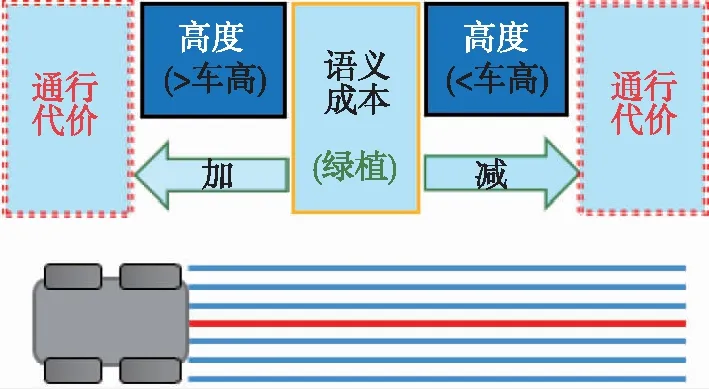
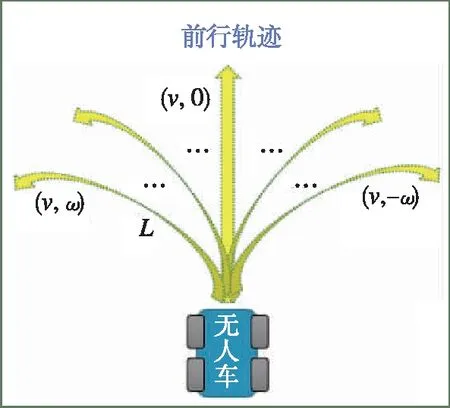
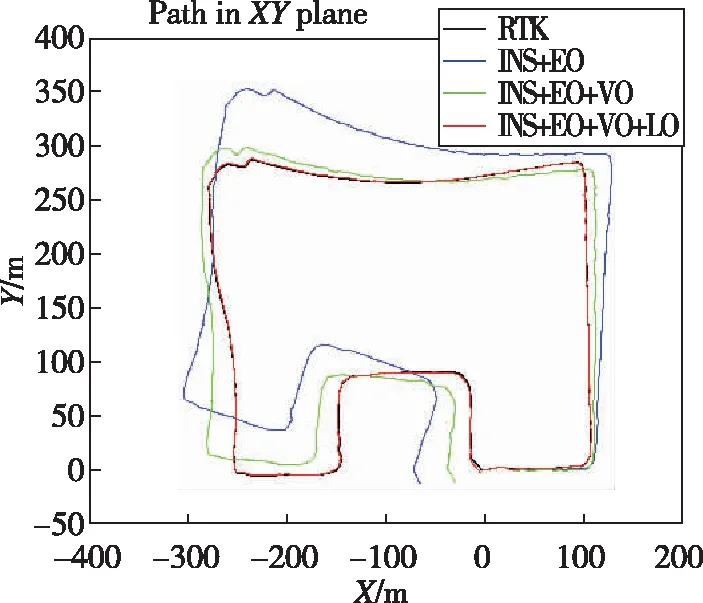
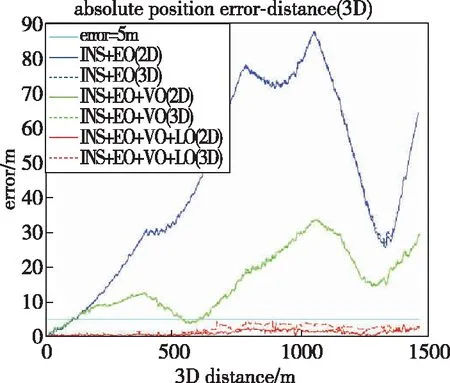
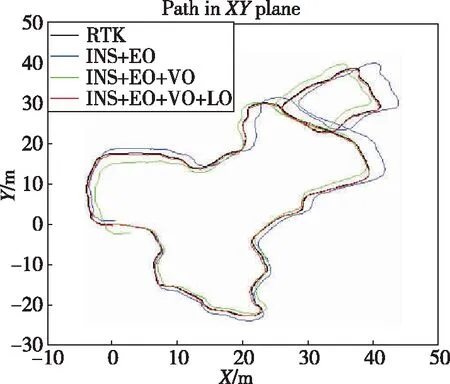
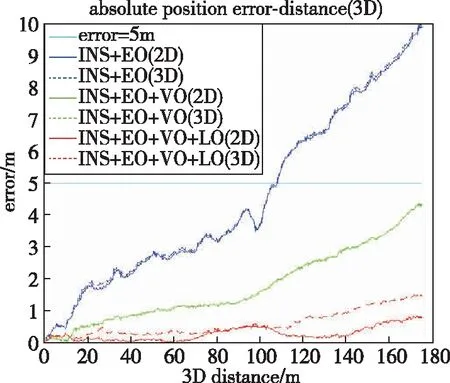
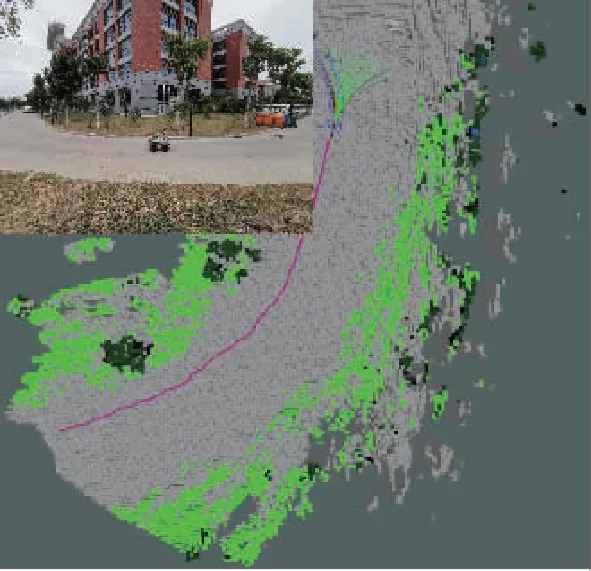
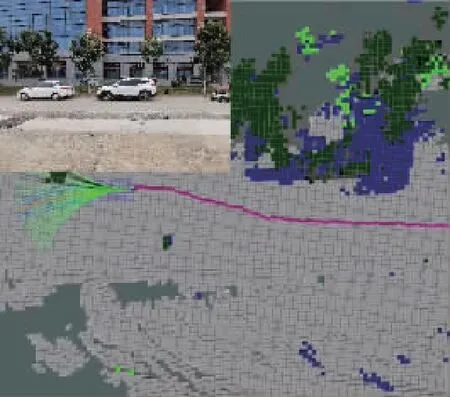
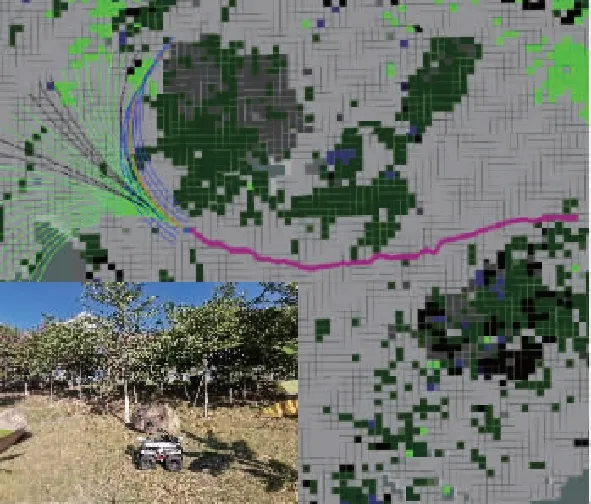
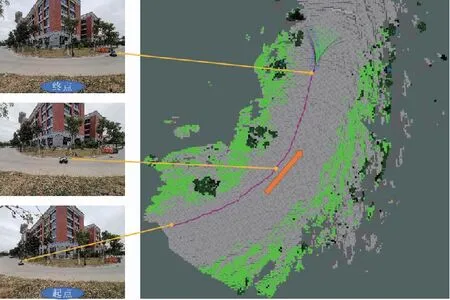
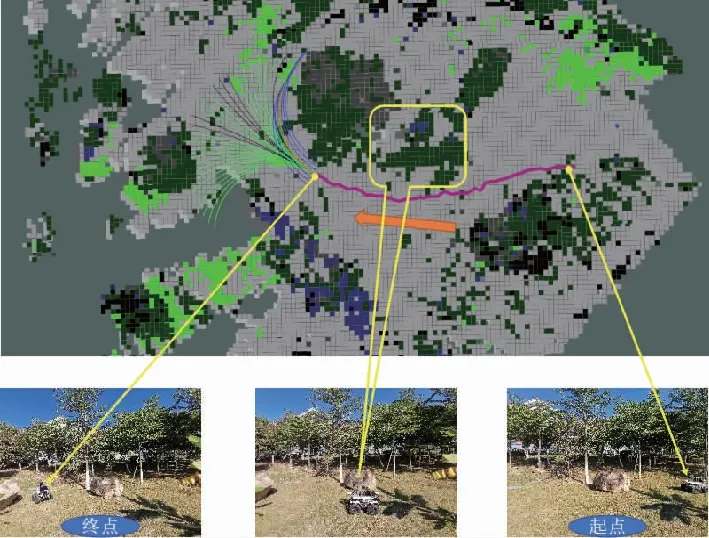
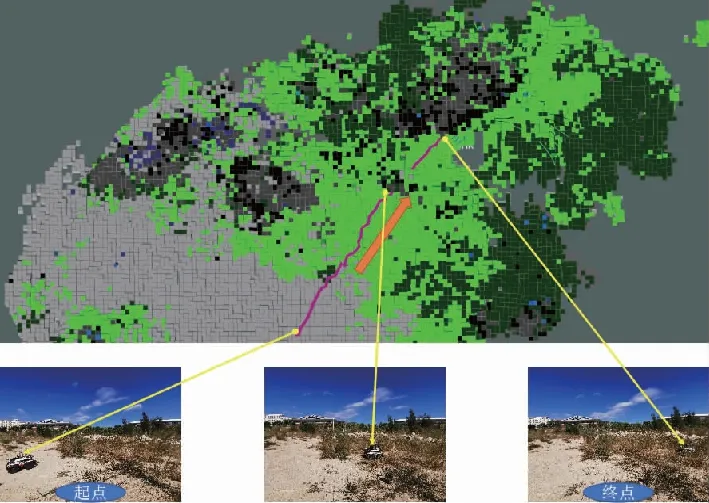
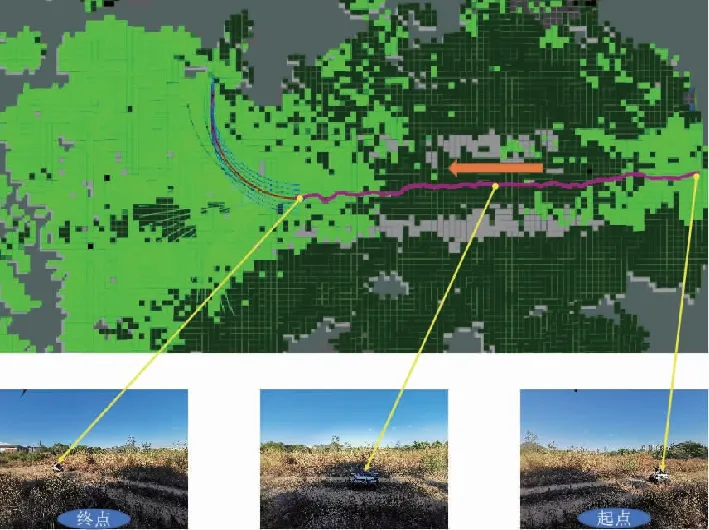
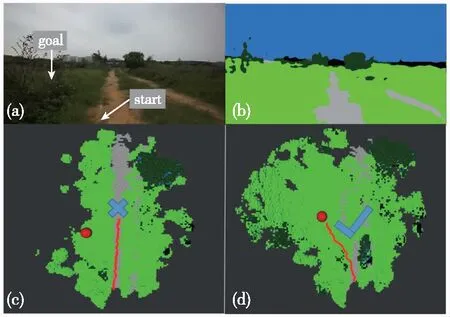
如图5所示,通过将局部语义3D地图投影成2D代价地图的方式,为无人车导航提供运动规划的代价地图。地图中可通过区域如道路、草丛等通行成本分别设为1和10,高的绿植的成本设为50,不可通过的障碍物(岩石等)成本设为200;另外,为了弥补语义分割的不足(误分类),同时对3D语义栅格的高度也进行最大值投影。语义和高度投影如图6所示,Z0<{z0,z1,…,zn} 图6 语义和高度投影示意图Fig.6 Projection of semantic and height information 在投影得到局部 2D 代价地图和某一路径后,先在该地图上计算一条采样路径中每个路径点在语义代价地图中对应的语义成本,并结合高度值进行修正得到总的通行代价;再将一条中间路径按照无人车的宽度复制6条平移轨迹,分别计算每条平移轨迹的通行代价,并将7条轨迹的通行代价累加起来作为该路径的总通行代价。单条路径通行代价的计算原理如图7所示。 图7 通行代价计算Fig.7 Passage cost calculation principle 采用DWA实现局部路径规划,主要流程如下: 1)在无人车运动空间进行速度离散采样(Δx,Δy,Δθ); 2)对每一个采样速度执行行进模拟,检测使用该采样速度移动一段时间会发生什么; 3)评价行进模拟中每个前行轨迹,评价准则有:靠近障碍物、靠近目标、贴近全局路径、丢弃非法轨迹(如靠近障碍物的轨迹); 4)挑出得分最高的轨迹(路径)并发送对应的速度给运动控制器; 5)重复上面步骤。 在每个采样周期内的线速度v和角速度ω受到电机最大最小速度和加减速度性能的限制,即 (22) 每个时刻无人车在全局坐标系下的平面位置(x,y) 分别等于上一时刻的位置加上当前Δt时间内的位移。DWA 算法在每个周期内会根据运动学模型和速度、加速度等限制进行路径采样。为了在投影的2D代价地图中计算通行成本,修改了 DWA 算法,不同之处主要为:增加了语义代价函数;在固定窗口内采样等长度路径。固定窗口参数:固定车辆速度为v,角速度范围为[-ω,ω],角速度增量为Δyaw,在每次采样周期内采样n条长度为L的轨迹,如图8所示。 图8 局部语义规划器采样空间Fig.8 The sampling space of the local semantic planner 验证平台如图9所示,为四轮驱动的无人地面车辆,自主导航系统的主要传感器有安装在车辆顶部的3D激光雷达(Robosense-16E)、安装在车辆前方的双目相机(ZED2)、安装在车辆中心的 IMU(Xsens MTi-30)、安装在驱动电机后的编码器,以及GNSS模块(司南M600 mini GNSS)。 图9 地面无人平台SCOUTFig.9 Unmanned ground platform SCOUT 图1融合定位系统中,用INS表示惯性定位,EO为轮式里程计(编码器)定位,VO为视觉定位(VINS),LO为激光雷达定位(LeGO-LOAM)。 (1)街道场景(校园) 路程D≈1460m,定位结果如图10所示。采用INS/EO/VO/LO多传感器融合定位,其平均误差(2D/3D)为2.210m/2.916m,相对定位误差<0.2%D。 (a)实景图 (b) 定位轨迹/路径(平面) (c) 全局定位误差曲线图10 街道场景(校园)定位结果(参考值:RTK)Fig.10 Positioning results in street scene (campus) (2)树林场景(夜晚) 路程D≈242m,定位结果如图11所示。采用INS/EO/VO/LO多传感器融合定位,其平均误差(2D/3D)为0.289m/0.357m,相对定位误差<0.2%D。 (3)野外场景 路程D≈175m,定位结果如图12所示。采用INS/EO/VO/LO多传感器融合定位,其平均误差(2D/3D)为0.304m/0.650m,相对定位误差<0.4%D。 (a)实景图 (b) 定位轨迹/路径(平面) (1)语义分割 真实环境测试(厦大翔安校区及荒地)的语义分割结果示例如图13所示,第1列为原始图像,第2列为MiniLedNet语义分割结果;其中第1行为校园环境,第2行为未开发的荒地。MiniLedNet能对道路、人行道、建筑物、路灯/杆类、交通标志、行人、汽车、天空、高植和草丛等物体进行分割。 (a)实景图 (c) 全局定位误差曲线图12 野外场景(山区)定位结果(参考值:RTK)Fig.12 Positioning results in wild scene (mountainous area) 图13 真实环境语义分割测试结果(道路 人行道 建筑 路灯(杆类) 交通标志 天空 高植 草丛 未知)Fig.13 Real environment semantic segmentation results 在Cityscapes数据集测试中,MiniLedNet相较于LedNet速度提高了31.2%,达到了20Hz的处理速度,精度损失只有3.1%;在Freiburg森林数据集测试中,MiniLedNet模型对12类的平均交并比(Mean Intersection over Union, MIoU)达到79.32%,高于CNNS-FCN和Dark-Fcn。 (2)地图构建 无人车在校区街道场景下行驶,建立的局部地图如图14和图15所示。通过点云和语义信息的融合、更新,实现了路面、草丛、高植、建筑、汽车准确感知与3D建模,建图速度达到15Hz。 无人车在荒地和树林环境下行驶,建立的局部地图如图16和图17所示,实现了路面、草丛、高植、岩石的准确感知与3D建模,建图速度达到15Hz。其中过高的草丛在语义分割中被识别为高植。 图14 城区环境局部语义3D地图Fig.14 Local semantic 3D map of urban environment I 图15 城区环境局部语义3D地图Fig.15 Local semantic 3D map of urban environment II 图16 荒地局部语义3D地图Fig.16 Local semantic 3D map of wasteland 图17 树林局部语义3D地图Fig.17 Local semantic 3D map of forest (1)路沿避让测试 本测试中路沿区域也被误分类为地面,路径规划对于高度大于指定高度的体素(非草丛或高植),认其为障碍物。本试验高度设置为0.24m,测试结果如图18所示,无人车能够绕行90°到达目标点,没有与高的路沿发生碰撞(如果不考虑高度则将发生碰撞)。 图18 路沿避让测试结果(轨迹)Fig.18 Roadside avoidance test results (track) (2)岩石避让测试 测试中岩石被当作未知类别(默认为障碍物),语义地图中岩石可能是黑色或深绿色。如图19所示,无人车遇到大的石头时,能够成功绕行。 图19 岩石避让路径规划结果Fig.19 Rock avoidance path planning results (3)草丛可通行测试 如图20所示,无人车能够在有路面和草地的环境中选择最优路径行驶达到目标点,草丛尽管有一定高度但不会造成绕行行为。 (4)高植通行对比测试 对于高度比车高低的绿植,路径规划器会根据高度信息对高植的语义代价进行修正,得到行驶轨迹如图21所示,可以看出高度较低的绿植(主要是在语义分割中误认为高植的草丛)并没有影响通行性。 图20 穿越草丛的通行测试(轨迹)Fig.20 Passage test through grass (track) 图21 高植语义代价修正后的路径规划结果Fig.21 Path planning results after high plant semantic cost modification (5)有无语义代价的DWA测试 (a)测试场景;(b)语义分割结果;(c)不使用草丛语义信息的 规划路径(失败);(d)使用草丛语义信息的规划路径(成功)图22 有无语义信息下的路径规划对比实验Fig.22 A comparative experiment of path planning with or without semantic information 为验证语义信息的存在与否对DWA算法产生的作用,如图22(c)所示,传统的基于几何的DWA规划不会进入草丛,因为它总是把有一定高度的点云当作障碍物;如图22(d)所示,当考虑草丛的语义信息后,因为草丛是可以通过的(代价低),因此会选择直接进入草丛到达目标点goal,说明增加语义信息可以让DWA规划器在实际可通行的区域(草丛)表现出类似人的驾驶行为。 以上实时路径规划的频率(1/周期)达到10Hz。图14~图22中,不同颜色代表的含义为:道路草丛高植建筑车辆天空未知障碍;存在误分割的情况。 本文针对复杂环境下地面无人平台的连续导航和智能感知规划问题,提出了卫星拒止下IMU/磁力计/轮式里程计/双目视觉/3D激光雷达的融合定位、基于多模态感知的语义3D地图构建与路径规划方案。算法分析与试验结果表明: 1)基于序贯式ESEKF的融合定位算法,扩展性好、场景适应性强,为后续全源导航的传感器即插即用及在线配置问题提供了解决思路。 2)改进的深度学习(图像)语义分割算法 —— MiniLedNet,在保持精度的同时具有快速推断能力;语义与点云的融合为自主导航提供了类人的智能感知规划能力,克服了基于几何地图方法的不足。 3)在真实环境中进行了整个系统的试验验证,表明该系统能够使无人车实时完成导航任务。为了进一步验证和完善所建立的导航定位、感知、规划方法,今后将在雨天、灰雾、复杂地形、电磁干扰环境下进行更充分的测试和完善。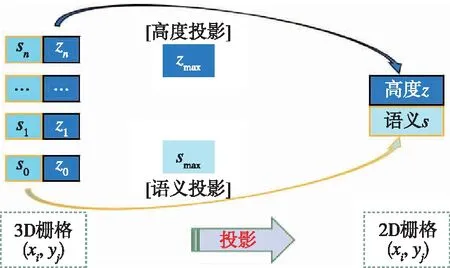
3.2 单条路径通行代价计算
3.3 基于DWA的运动规划
4 试验验证

4.1 融合定位试验结果


4.2 环境感知试验结果



4.3 运动规划试验结果
5 结论
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
作文评点报·低幼版(2020年40期)2020-12-15
满族文学(2020年1期)2020-02-14
小猕猴学习画刊(2019年11期)2019-12-09
诗潮(2019年8期)2019-08-23
小哥白尼·趣味科学画报(2019年12期)2019-02-28
发明与创新·中学生(2017年4期)2017-03-31
女友·家园(2016年7期)2016-08-11
科学大众(中学)(2016年8期)2016-05-14
长江学术(2015年1期)2015-02-27
