
利用无人机提取样本点的多源遥感影像分类方法研究
2021-12-01 12:10:30张文王志伟吴红芝毕玉芬宋雪莲阮玺睿
草原与草坪 2021年5期
张文,王志伟,吴红芝,毕玉芬,宋雪莲,阮玺睿
(1.云南农业大学草业科学系,云南 昆明 650201;2.贵州省农业科学院草业研究所,贵州 贵阳 550006)
全球喀斯特地貌面积约为2.2×107km2[1],占陆地表面积的7%~12%[1-2],约有四分之一的全球人口水源依赖于喀斯特区域的含水层[2-3]。喀斯特生态系统十分脆弱,特别容易受到环境变化的侵袭,导致区域内地表植被发生破坏,进而造成其地表景观退化为裸土区域,甚至退化为岩石区域[4],而这种石漠化现象又是一种严重的生态系统短期不可逆过程。已有研究指出[5],在我国西南喀斯特地区石漠化面积已达5.8%,其中作为喀斯特地貌中心的贵州省,其表层土壤在1974-2001年甚至每年以120 km2的速度退化为石漠化区域[6]。不过这种趋势在最近20年开始转为良性,许多地区的植被开始变得比以前更绿[6]。尽管如此,对喀斯特区域,特别是位于岩溶中心贵州省的长期监测依然不容忽视。
随着多源遥感数据的发展,遥感影像在时空分辨率和光谱分辨率方面都有极大提升[7],特别是针对喀斯特区域的植被动态和地物类型监测研究越来越成熟[6-8]。现有的地表类型分类方法日益精准[9],但是作为任意一种分类模型输入必要条件的野外实测分类样本点获取较为困难。特别是在较大尺度范围内,如果通过传统野外调查法收集分类样本点,人力、物力和时间成本的花费极高,严重阻碍大范围地表分类研究的发展[10]。近年来兴起的无人机技术发展迅速[11-12],而且伴随着相关操作软件的完善[13],为快速、廉价的获取能够长期保存的可视化数据基础资料提供了技术支撑和方法保障。
无人机低空遥感具有灵活性高、影像获取时间短、成本低、地面分辨率高等优点,在作物长势监测、产量估计、氮素含量反演、冠层叶绿素预测等方面得到了广泛应用,可灵活高效地获取中小区域农作物冠层光谱信息[14-19]。尹小君等基于中空间分辨率Landsat 8 OLI数据与高时间分辨率 MODIS数据,采用遥感数据时空融合 STARFM算法,获取中空间分辨率和高时间分辨率序列的遥感数据,并以天山北坡中段区域为试验区,结合 CASA模型,对区域内植被 NPP进行模拟[20]。吴智超等[21]利用 ExG指数法和最大似然监督分类法对无人机数码影像进行处理,提出利用颜色转换空间HSI(HA法)从无人机数码影像中快速提取马铃薯覆盖信息;刘春晓等[22]根据植被指数等遥感数据产品,提取9种图像特征,并结合DEM生成的地形参数数据,利用计算机自动分类法,提出基于MODIS数据的土壤遥感分类方法具有一定的准确性和可行性。
现有的遥感数据源种类繁多[10,23],分类方法也各式各样[9,24]。为充分利用无人机提取海量、廉价分类样本点的可能性,本研究选取开源数据集作为分类的遥感数据源,如Sentinel-1/2和SRTM DEM,数据优势是可免费获取,涵盖可见光、近红外、短波红外和微波范围的影像资料,为分类方法研究提供了广泛的光谱数据。同时,本研究的分类方法选用对遥感数据分类具有较优精度的随机森林[9],相比其他机器学习分类方法(除硬件要求极高的深度学习外),随机森林具有更好的鲁棒。
1 材料和方法
1.1 研究区概况
研究区地处贵州省威宁县北部(图1-A),属云贵高原高寒山区,有“贵州屋脊”之称,海拔2 320~2 442 m,高原缓坡地貌,土壤为黄棕壤,年均温8.7℃,主要是白三叶 (Trifoliumrepens)+多年生黑麦草(Loliumperenne)和白三叶+鸭茅(Dactylisglomerata)建植的多年生人工草地。 地理位置E 104.100°~104.118°和N 27.179°~27.191°(图1-B),面积1.7 km×1.4 km,采集无人机照片120张,提取分类采样点982个。
1.2 UAV航拍相片及分类样本点数据获取
无人机航拍相片采集于2018年4月21日,使用大疆精灵4拍摄,共采集120张,飞行高度300 m,相片分辨率为1200万像素,使用FragMAP软件[13]完成操作拍摄过程。采样点通过ArcGIS软件,设置均匀分布于研究区内的矢量点完成,共计982个。如果利用传统的生态样方框完成本试验中近千个点位(图1-B)、甚至后续研究中上万、上百万点位的植被调查,所需的人工和时间成本花费极大,因此本试验尝试利用无人机影像完成分类样本点数据的提取过程。
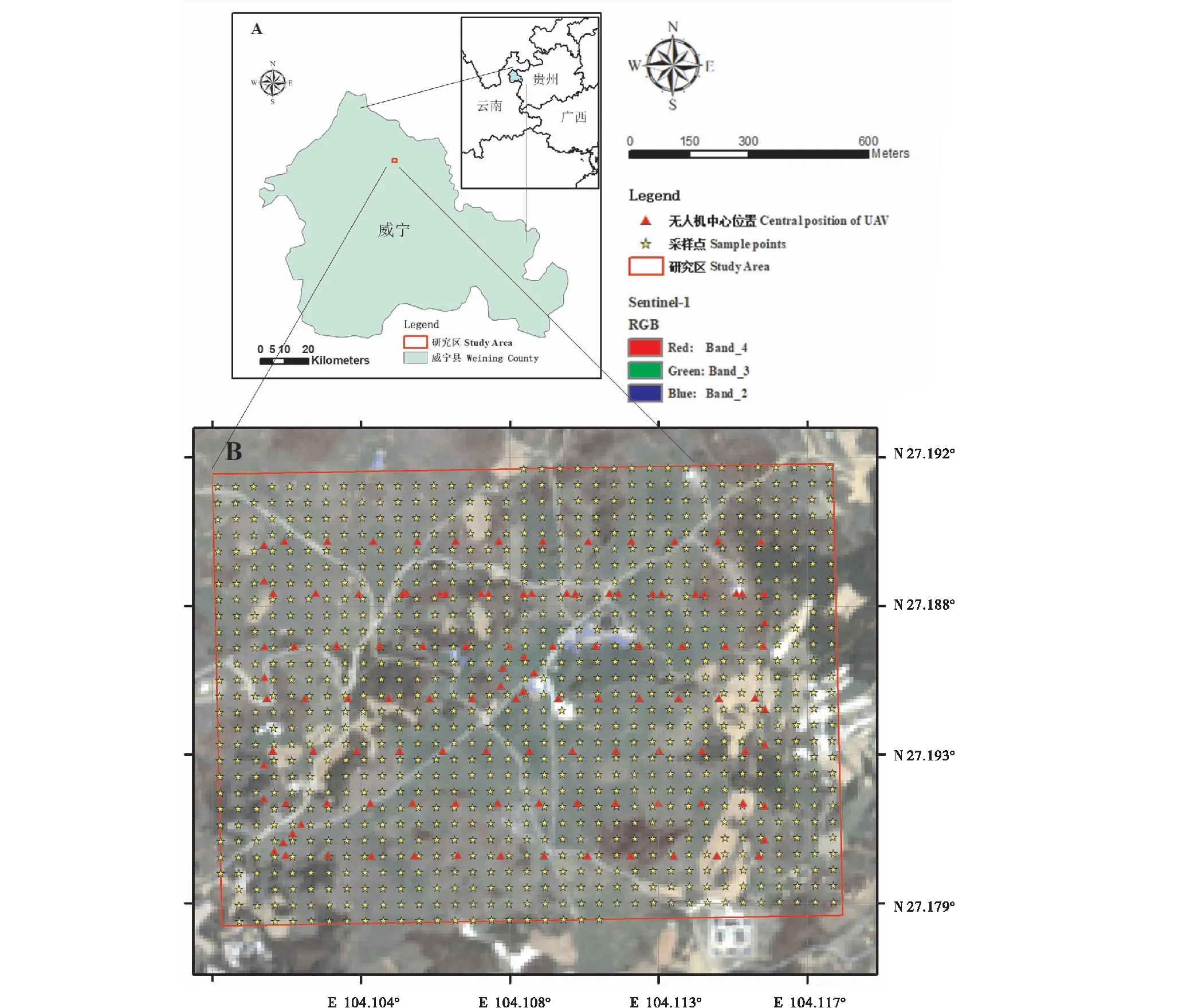
图1 研究区位置示意图(S2真彩色图片采集于2018年4月17日) Fig.1 Location of the study area (Sentinel-2 true color composite image collected on April 17th 2018)
仅用开源遥感影像来目视解译,即使分辨率已达10 m,仍难以清晰分辨各类地表类型。举例来说,本试验中研究区内某些裸露土地的颜色与生长不茂盛的树林颜色极为相近,十分容易错误解译为林地,如图2-B蓝色圈和粉色圈中的颜色极易误判,但是如果有无人机航拍数据作为参考(图2-A),蓝色圈和粉色圈中的地表类型就不会解译错误。本试验中的所有分类样本点都是通过目视解译,将无人机影像定位至Sentinel-2影像上,然后完成样本点提取过程。

图2 利用无人机航拍相片提取采样点 Fig.2 Using Unmanned Aerial Vehicle (UAV) to extract marked sample points注:A:无人机航拍相片效果;B:Sentinel-2真色彩合成影像
1.3 遥感数据源
Sentinel-1/2数据来源于欧空局(http://scihub.copernicus.ed/)。Sentinel-2(S2)数据共包含13个波段数据,涵盖可见光、近红外和短波红外光谱波段,其中有5个近红外波段的数据可应用于植被相关的研究[9]。经过Sen2Cor(http://step.esa.int/main/thir d-party-plugins-2/sen2cor/sen2cor_v2-8/)软件处理后,完成地形校正、大气校正和辐射校正等基础影像处理过程,最后得到除第10波段外的12层影像数据集,全部重采样至10 m分辨率与第2(蓝)、3(绿)、4(红)和8(近红外)波段分辨率一致。Sentinel-1(S1)GRD数据(C波段,VV和VH极化)分辨率也为10 m,使用SNAP(http://step.esa.int/main/toolboxes/snap/)软件进行轨道修正、热噪声去除、辐射校正、散斑滤波和距离-多普勒地形校正操作后得到VV和VH2层数据影像。本试验中所使用的S2和S1数据分别获取于2018年4月17日和2018年4月20日。DEM数据使用SRTM DEM(http://srtm.csi.cgiar.org/srtmdata/),重采样至10 m分辨率后计算获取高程(DEM)、坡度(slope)、坡向(aspect)和剖面曲率(profile curvature)4层数据影像。经过处理,上述所有遥感影像和无人机航拍数据全部使用WGS_1984_UTM_Zone_48N投影。
1.4 植被指数的计算
为提高分类精度,本试验引入植被指数数据(Vegetation indices,VI),主要包括NDVI(Normalized Difference Vegetation Index),EVI(Enhanced Vegetation Index)和SAVI(Soil-Adjusted Vegetation Index),其计算公式如下所示:
NDVI= (NIR-Red )/(NIR+Red)
(1)
EVI=2.5×(NIR-Red)/(NIR+6.0Red-7.5Blue+1)
(2)
SAVI=(NIR-Red)(1+L)/(NIR+Red+L)
(3)
式中:NIR、Red和Blue分别对应近红外、红和蓝波段的数值,L是土壤调节系数,由实际区域条件确定,一般情况都采用L=0.5来完成运算。本试验中,NIR、Red和Blue波段数据分别对应S2数据的第8、4和2波段结果。
1.5 随机森林分类模型的构建
随机森林是一种组成式的监督分类法,以决策树为基础,实现对多决策树的集成。随机森林方法在遥感数据分类研究[9]中应用较为广泛,该分类模型从原始的训练数据集中采取有放回的抽样(bagging)方法完成子数据集的构造过程。该过程中不同子数据集的元素可以重复,同一子数据集中的元素也可以重复。同时,因其引入两个随机性属性(样本随机,特征随机),所以不容易陷入过拟合。随机森林特征重要性的大小正相关于该特征对森林中每棵树的贡献大小,当平均该特征对每个树的贡献之后,得到基尼指数(Gini index)。此外,袋外数据(Out Of Bag,OOB)错误率可以作为评估指标来衡量特征集贡献大小,通常优先选择袋外误差率最低的特征集。
本试验中,主要区分5种地表类型(表1)。

表1 试验研究区地表类型分类样本点概况
验证分类结果的准确率指标主要包括总体准确率(Overall Accuracy,OA)和Kappa系数两种,其计算公式如下:
OA=(TP+TN )/(TP+FN+FP+TN)
(4)
式中:TP为真正,即被模型分类正确的正样本;FN为假负,即被模型分类错误的正样本;FP为假正,即被模型分类错误的负样本;TN为真负,即被模型分类正确的负样本;OA为总体分类精度,即分类正确的样本个数占所有样本个数的比例。
Kappa=(Po-Pe)/(1-Pe)
(5)
式中:Po为对角线单元中观测值的总和,也就是总体分类精度OA;Pe为对角线单元中期望值的总和;Kappa为评价一致性的测量值,表示分类与完全随机的分类产生错误减少的比例。
2 结果与分析
依据试验部分中的数据和随机森林分类模型完成的制图结果如图3所示,除S2&VI&DEM数据集的分类结果较差外(表2),其余分类结果都相对稳定,OA在75%以上,Kpppa系数在65%以上,同时各分类结果的空间分布位置基本一致。其中,2个数据集S2&VI的分类精度最高,但是OOB的数值以3个数据集S2&VI&S1的分类结果为最高。本试验的研究结果基本呈现数据资料越多,分类精度越高的规律。不过,DEM及其相关计算结果的引入会明显产生噪声,导致分类结果降低。因此,以后的分类研究也应注意筛选变量,以免冗余变量的引入产生误差,导致分类精度降低。

表2 分类结果精度评价
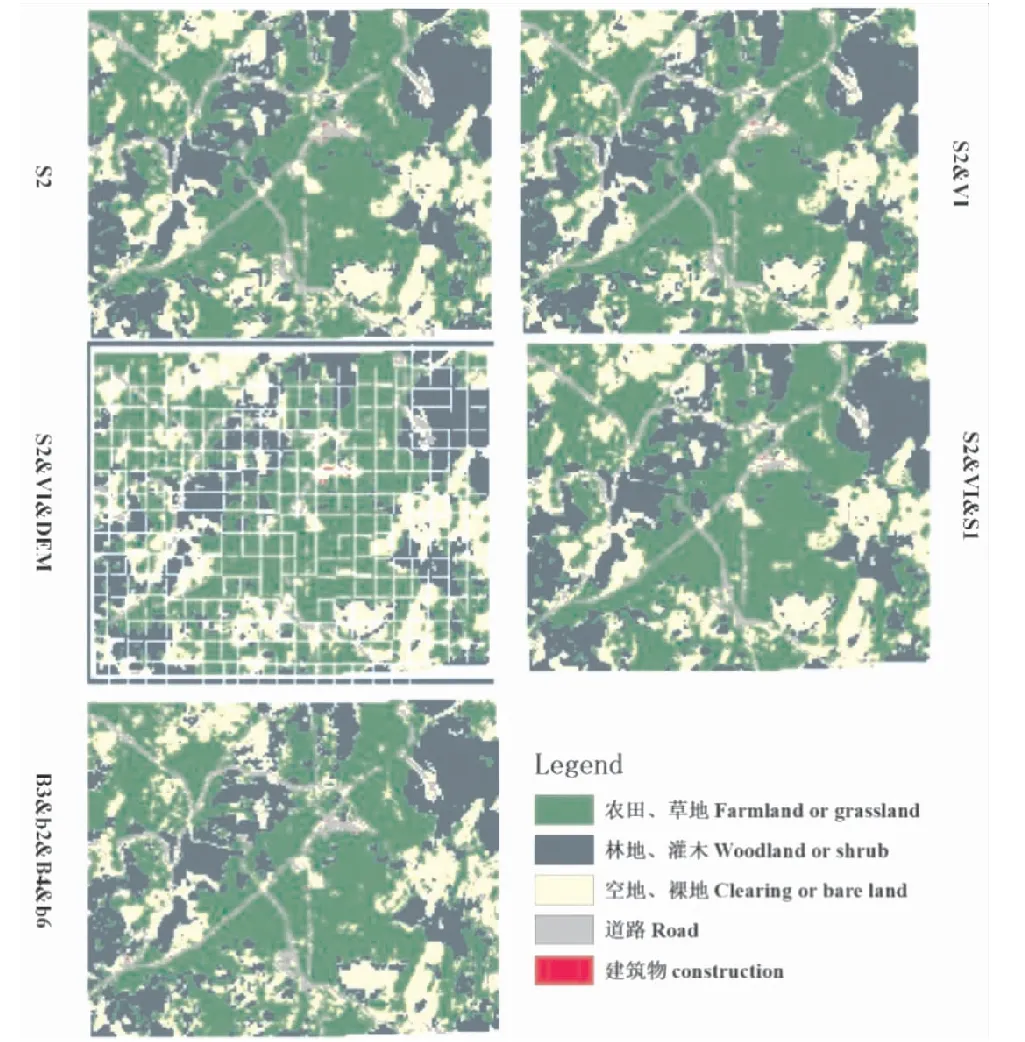
图3 随机森林分类结果Fig.3 Random Forest classifications
结果表明,分类样本点越多的地表类型,分类精度越高;分类样本点越少的地表类型,最终分类精度越低(图4)。特别是具有最少采样本点的建筑物分类,在测试集的5种分类结果中都没能正确区分。

图4 分类结果混淆矩阵图Fig.4 Confusion Matrixes of Random Forest classifications
图5展示了各分类数据集中,不同遥感图层的基尼指数值。在前4种数据集中,S2数据的第2、3、4和6波段都具有较高的基尼指数数据值,因此仅用上述4层数据波段完成分类后发现,其分类后的空间分布形式基本同其他多数据图层分类结果相似(图3)。特别是仅用以上4层数据波段完成的分类结果精度略低于最高分类数据集的结果精度,远高于引入冗余数据集(DEM)后的分类精度(表2和图4)。以上结果也说明,数据降维的操作方式,在大数据量处理时会有效的节约时间,同时又保证较高的分类精度。

图5 基尼指数Fig.5 Plots of Gini index
3 讨论
3.1 边缘分类样本点(混合像元)对分类结果准确率的影响
本试验中分类样本点是按照均匀分布规则设置的,因此有接近1/3的样本点位于不同地表类型的边缘处(即混合像元)(表1)。在此,通过剔除表1中318个边缘样本点探讨所有样本点只是位于一致性极高区域后的分类精度。将位于一致性较高地表类型的664个样本点输入分类模型中分类结果精度最高的3个数据集进行分类,结果如图6所示,其分类精度存在明显提升(表3),OA和Kappa都在85%和79%以上。因此,剔除边缘分类样本点(混合像元)对分类精度的提高十分重要,本试验中对OA和Kappa的提升,一个接近10%,一个超过10%。
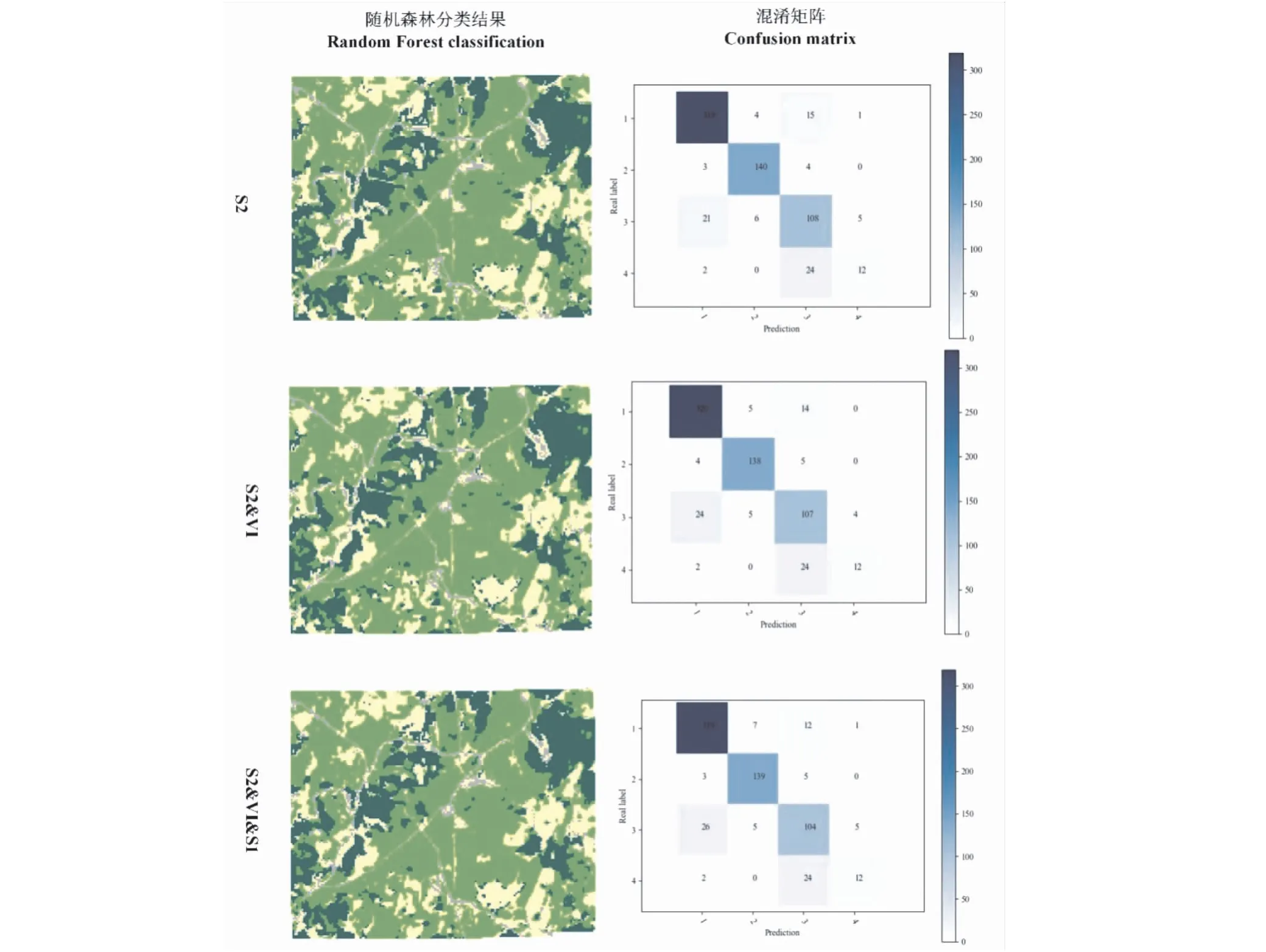
图6 数据集S2、S2&VI和S2&VI&S1随机森林分类结果和混淆矩阵Fig.6 Random Forest classifications and confusion matrixes of S2,S2&VI and S2&VI&S1
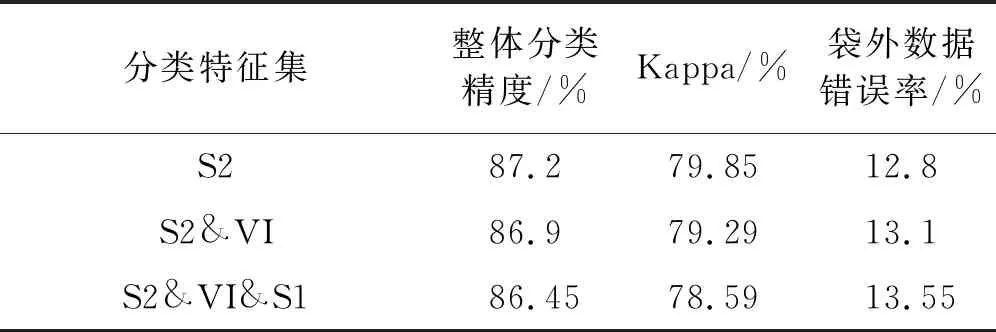
表3 数据集S2、S2&VI和S2&VI&S1分类结果精度评价指标表
3.2 基于无人机提取分类样本点的分类方法能够有效识别枯萎植被
常规目视解译,特别是没有无人机航拍相片作为参考资料时,可见光遥感影像目视解译对枯萎林地和某些裸地的区分相对困难,如图7-A所示从S2的真彩色合成图像上判读枯萎林地和裸地的颜色十分接近。不过,本试验利用无人机提取分类样本点完成分类后,对枯萎林地和裸地的区分会准确很多(图7-B)。特别是图7B深蓝色圈中对枯萎林地的分类,基本可以有效地衔接旁边的旺盛林地。

图7 区分枯萎植被和裸地Fig.7 Identification of weathered vegetation and bare land注:蓝色和红色圈内地表类型分别为森林和裸地
3.3 细小斑块和杂乱斑块
图8展示了分类对细小、杂乱斑块的区分效果。图中蓝色圆圈中的分类效果基本可以满足常规地表类型分类需求,不过该结果也存在部分椒盐效应现象,而且部分道路也存在不连贯现象。此外,需要着重关注的是对建筑物区分效果很差,如图8红色圆圈中的房屋完全没有区分出来,在图7中更多的建筑物中也仅区分出部分样本。造成这种现象的原因主要有两方面:1)分类样本点过少,建筑物的分类样本点仅有4个,而且全部是边缘样本点;2)建筑物面积小,多数个体难以覆盖一个2×2的像素单元。根据实际分类制图需求,如果确实需要对这类个数少、面积小的地表类型进行分类,建议人为加大采样样本点,而不单纯依靠均匀布点所设置的样本点。此外,如果条件允许,考虑使用更高分辨率的遥感影像(一般非开源)进行分类制图,加强对小面积样本的识别能力。

图8 细小、杂乱斑块分布图Fig.8 Distribution of tiny and disordered patches
4 结论与展望
1) 本研究均匀提取分布于研究区内的982个分类样本点,利用包括Sentinel-1/2(S1/2)数据集、S2数据计算获得的植被指数数据集和数字高程模型(Digital Elevation Model,DEM)数据集的遥感影像资料,然后借助随机森林分类模型完成研究区地表类型分类。上述遥感数据集不仅涵盖可见光数据,还包括近红外、短波红外和微波光谱波段数据资料。分类后的结果显示,除包含DEM数据集的分类结果外(总体精度和Kappa系数分别为74.54%和61.73%),其他4种数据集组合(S2数据集、S2&VI数据集、S2&VI&DEM数据集,以及4个S2波段b3&b2&b4&b6组成的数据集)的制图总体精度(Overall Accuracy,OA)和Kappa系数精度都在75%和65%以上。此外,在不考虑位于边缘的样本点(即混合像元)后,分类制图结果具有更好的鲁棒,3种分类精度最高的数据集(S2数据集、S2&VI数据集和S2&VI&DEM数据集)OA和Kappa系数精度都提高至85%和79%以上。特别是kappa系数的精度更优,提高了近15%。
2)该方法能够有效区分枯萎植被和裸露土地,即使仅使用可见光波段组合生成的影像,也可以参考无人机影像较方便地分辨各类地表类型。以上结果说明,在今后的研究中,可以扩大分类样本点的采集时间,不只局限于植物生长最旺季。同时,该方法也减少对植物生长季运算过程的时间消耗,不需利用长时间序列的植被研究数据反演整个植被物候过程来完成分类。
3) 本研究基于无人机提取分类样本点的多源遥感数据随机森林分类方法,可以快速、有效、廉价地实现地表类型分类制图过程,同时也可为今后上万、上百万级的海量样本点提取过程提供技术支持和方法基础,但是涉及混合像元的分类样本点存在问题,在剔除边缘分类样本点(混合像元)的影响后,分类精度明显提高。因此,建议在以后的相关研究中布点时,尽量避免提取边缘处的分类样本点,应选取地物类型均匀一致的区域提取样本点。
此外,本研究试验中仍然存在一些问题需要改进,如分类中未能区分农田和草地,以及裸地与休耕地(空地)。以后的研究如有该方面的需要,可以通过以下两种手段来完成对农田和草地,以及裸地与休耕地(空地)的分类。一是降低飞行高度。该技术手段,操作简单、人力成本低。不过会增加航拍时间,研究前需对实验的野外采集时间科学合理规划。二是加入植物生长物候期数据拟合。该技术手段运算数据的时间成本相对较高,特别是遥感影像(长时间序列数据集)易受云的影响也是研究中需要着重考虑的一个方面。
4)本研究的另一个局限是未考虑面向对象方法的分类图斑提取,如图7-B红色圈中仍然存在椒盐效应现象。本文中未使用面向对象方法的原因是研究区域面积相对较小,而10 m分辨率的遥感影像在对本研究区范围内数据进行面向对象图斑分割时像元过大,导致提取到的图斑线条锐化明显,分类图斑的边界并非常见面向对象分割后的圆滑曲线,对分类结果精度和视觉效果都存在影响。
随着遥感技术和无人机航拍技术的快速发展,基础数据的积累量会日益壮大。面对海量数据的地表类型分类研究,实现航拍影像的分类采样点自动化提取迫在眉睫。少量样本点数据可通过目视解译完成,但是为服务深度学习和人工智能的大数据量航拍相片提取分类样本点过程仍然困难。该领域研究内容的更新与突破,将会是未来利用无人机技术进行地表类型分类制图研究的热点。
猜你喜欢
中外文摘(2021年10期)2021-05-31 12:10:40
数学物理学报(2019年3期)2019-07-23 01:15:40
家庭影院技术(2018年9期)2018-11-02 05:31:32
电子制作(2018年11期)2018-08-04 03:25:38
小学生优秀作文(低年级)(2018年6期)2018-05-19 01:54:27
作文通讯·高中版(2017年6期)2017-07-10 03:21:34
自动化学报(2017年5期)2017-05-14 06:20:52
成都信息工程大学学报(2017年6期)2017-03-16 03:04:32
陕西画报(2017年1期)2017-02-11 05:49:48
测绘科学与工程(2016年5期)2016-04-17 06:51:15
