
基于图神经网络的具有依赖关系任务的计算卸载方法
2021-12-01 07:41覃少华谢志斌张家豪卞圣强
计算机测量与控制 2021年11期
崔 硕,覃少华,谢志斌,张家豪,卞圣强
(广西师范大学 计算机科学与信息工程学院,广西 桂林 541004)
0 引言
移动边缘计算(MEC,mobile edge computing)技术通过在网络边缘部署计算和存储资源,将云计算的部分能力下沉到无线接入网等靠近用户的网络边缘,就近为用户提供计算和存储服务,降低用户的等待时延,同时减轻了骨干网的负担,防止网络拥塞的发生[1-3]。计算卸载是MEC的关键技术[4],用户设备可以通过计算卸载技术将计算密集型的应用整体或部分地卸载到MEC服务器上运行,显著降低了处理时延和能耗。
细粒度的计算卸载将应用进一步分割为多个任务,使得任务间的并行卸载处理成为可能[5]。由于在应用程序中一个任务经常需要其它任务的输出数据作为自己的输入,因而不同任务间是具有依赖关系的。现有文献大多使用有向无环图(DAG,directed acyclic graph)对具有依赖关系的计算卸载问题进行建模,但是由于DAG结构的复杂性和多样性,基于DAG的计算卸载问题是困难的[5-7]。受制于问题的复杂性,文献[8-9]大多使用启发式算法对这一问题进行求解。然而,启发式算法难以满足MEC环境下的实时动态决策的要求[10],同时也缺乏通用性。针对这一问题,文献[10-12]提出通过深度强化学习(DRL,deep reinforcement learning)算法求解DAG任务卸载调度决策的方法,利用DRL算法较强的表示能力[13]对DAG卸载决策问题巨大的状态空间进行学习,与此同时DRL算法把最大化长期奖励作为目标,可以避免卸载决策算法陷入局部最优,更能求得全局最优解。
然而,使用DRL算法解决基于DAG的卸载调度问题时会遇到一个棘手的问题,那就是DRL算法所使用的神经网络只适用于处理欧氏空间数据[14],无法处理非欧式空间的数据,因而对这一卸载调度问题中的DAG图无能为力。为了能将DAG图输入DRL算法的神经网络中,文献[15]采取嵌入的方法,把DAG图中的每个任务节点的本地执行时延、MEC服务器执行时延和前驱后继任务的索引等信息构成一个定长的任务嵌入向量,然后输入到DRL算法的神经网络中。这种方法中每个任务的嵌入向量是定长的,同时由于嵌入向量的长度直接决定了DRL算法中神经网络的规模,因而嵌入向量的长度不能过长。但是对于很多DAG结构复杂的应用来说其中核心任务的前驱后继任务的数量可能是非常大的,这将导致DAG图转换为嵌入向量的过程会丢失很多DAG自身的结构信息,从而使制定的卸载策略不够准确。鉴于图神经网络(graph neural network,GNN)所表现出的对图结构数据出色的处理能力[16],本文针对DAG任务卸载调度问题提出一种新颖的将GNN和DRL算法相结合的方案,收到了很好的效果。
本文提出的方案基于DRL中的DQN算法进行了修改以使其适用于处理DAG任务的卸载调度问题,具体的,本文使用GNN替代DQN算法中的标准神经网络来评估每个卸载动作的Q值。在GNN的结构方面,本文借鉴了消息传递网络(MPNN,message passing neural network)的结构[17],由于DAG图是有向的和无环的,本文针对DAG图的结构特点设计了一种有向无环图神经网络(DAGNN,directed acyclic graph neural network)用来更有效地提取DAG图的信息。仿真实验表明,本文提出的方案具有良好的收敛性,并在不同的节点数和网络环境下收到了优于其它对比算法的调度效果。
1 系统结构及原理
下面首先给出整个系统的实现结构流程图,如图1所示,系统首先读取待调度应用的DAG结构图,以及应用中每个任务的本地执行时延和在MEC服务器上执行的传输时延和计算时延。随后系统初始化DAGNN的参数和每个节点的输入状态。在对应用进行卸载调度时,系统首先计算每个任务的最晚开始执行时间,并按照升序进行排列,从而得到任务的优先级序列,之后系统对所有任务按照优先级的顺序依次进行调度。在对每个任务进行调度时系统首先调用下文的算法1衡量每个动作的q值,之后根据贪心策略选择要采取的动作,并更新卸载动作序列。随后系统收到环境反馈的即时奖励r,并进入下一状态s′,与此同时系统将四元组(s,a,r,s′)存入经验回放缓存区,并定时从经验回放缓存区中取出一些元组数据通过随机梯度下降法更新DAGNN的参数。
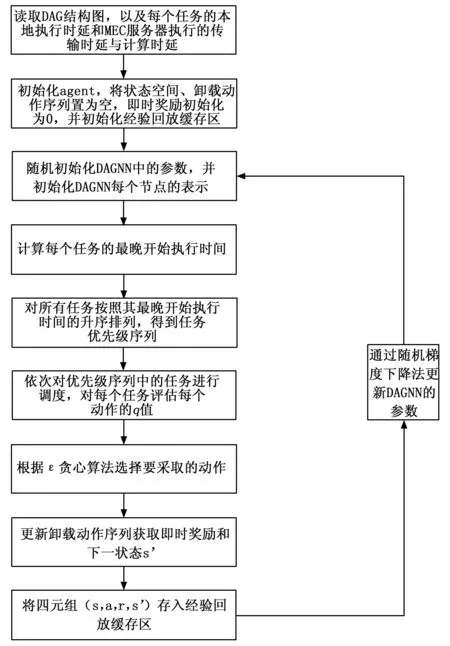
图1 系统实现结构流程图
2 系统模型


图2 系统模型
2.1 通信模型
用户设备UE和每个微基站之间通过无线链路相连,我们假设在任务的执行过程中UE与MEC服务器之间的信道保持稳定,根据香农公式可得到用户设备UE到MEC服务器间链路的传输速率为:
(1)
其中:参数B代表用户设备UE可用的信道带宽,p0代表用户设备UE的发送功率,gn表示UE与MEC服务器n之间的信道增益,N0表示高斯噪声功率。
2.2 计算模型
用户设备UE在同一时隙内只产生一个计算密集型的应用,它被进一步分割为多个相互之间具有依赖关系的任务,每个处理单元在同一时隙内只能处理一个任务,每个任务只能被一个处理单元所处理。下面分别讨论任务在本地计算和MEC服务器上计算的时延。
①本地计算:
用f0表示用户设备UE自身的计算能力,则任务i在UE本地计算的计算时延可以表示为:
(2)
由于本地计算无需进行数据的传输所以不存在通信时延,所以任务i在本地计算的全部时延为:
(3)
②MEC服务器计算:
当任务i被调度为MEC服务器n计算时,数据需要在用户设备UE和MEC服务器之间传输,因而MEC服务器计算情景下的时延由两部分构成:传输和MEC服务器执行。特别地,由于任务被执行所产生的计算结果的数据量往往很小,类似于现有大多数文献的假设[8,12,18],本文不考虑计算结果的传输时延。由此可得任务i在MEC服务器n上计算的时延为:
(4)
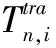
2.3 依赖关系模型
本文将应用中不同任务间的依赖关系建模为一个DAG,表示为G=(V,E),其中V表示DAG中节点的集合,每个节点i∈V表示UE运行的应用中的一个任务;E表示DAG中边的集合,每条边e(i,j)∈E表示任务i和j之间的依赖关系,即任务j需要任务i的输出数据作为自己的输入,并称任务i为j的前驱,任务j为i的后继,一个任务只有在其所有前驱任务完成后才能开始执行。在一个DAG中,没有前驱任务的任务被称为入口任务,没有后继任务的任务被称为出口任务,一个应用允许同时有多个入口任务和出口任务。
在应用开始卸载调度后,用AFTn,i表示任务i在处理单元n上执行时的实际完成时间。由于一个任务只有在其所有直接前驱任务都被执行完成后才能进入准备就绪状态,所以任务i的就绪时间可以表示为:
(5)
其中:pre(i)表示任务i所有直接前驱任务的集合。然而,当一个任务被分配至处理单元n上执行时该处理单元可能并未处于空闲状态,所以任务的就绪时间并不一定是它真正开始被执行的时间。我们用ATn,i表示处理单元n最早可以为任务i服务的时间,容易得到:
ESTn,i=max{RTi,ATn,i}
(6)
用ETn,i表示任务i在处理单元n上执行所花费的时间,它可以表示为:
(7)
由于用户设备UE的应用都是时延敏感型的,所以应用存在一个最大容忍时延。我们定义tmax为应用的最大容忍时延,它可以看作是应用的DAG图中出口任务的最晚执行完成时间。用LFTn,i表示 DAG图中任务i的最晚执行完成时间,它可以从应用的出口任务逐级往上递归地求出,则LFTn,i可以表示为:
(8)
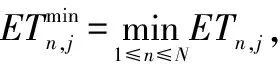
在定义了任务的最晚完成时间后我们可以相应地得到任务的最晚开始执行时间,它可以表示为:
(9)
2.4 优化目标制定
本文以使任务的时延最小为优化目标,首先定义两个0-1变量xn,i和yh,i,它们的取值分别为:
(10)
(11)
基于上文的定义,本文的优化问题可表示为:
(12)
s.t.ESTn,i≥xn,i·yn,i·AFTh
(12a)
xn,i∈{0,1},∀n∈N,i∈V
(12b)
(12c)
其中:约束式(12a)表示任务i的最早开始执行时间不能早于其直接前驱任务h的实际完成时间,约束式(12b)和(12c)表示同一任务只能在同一个处理单元上计算。
3 基于DRL和GNN的DAG任务卸载调度算法
由于DAG任务调度问题的复杂性,文献[11]等提出使用深度强化学习的方法进行卸载决策。但由于DRL算法无法处理诸如DAG图一类的图结构的信息,文献[22]采用节点嵌入的方式将DAG图的拓扑结构和节点信息转化为任务序列输入到DRL算法的神经网络中。但这种方式会损失很多DAG图的结构信息。鉴于图神经网络在处理图结构数据时的优异表现,本文提出将图神经网络(GNN,graph neural network)与DRL算法相结合用于解决DAG任务的卸载调度问题。与此同时由于DAG图是有向图,本文针对DAG图的结构特点设计了一种有向图神经网络(DAGNN)用于提取DAG图的信息,取得了较好的效果。
3.1 任务优先级
为了简化卸载调度决策过程同时也满足任务之间的依赖性,与其它基于DAG图的任务卸载调度问题文献一样[7,19],本文首先确定任务的调度顺序。由于计算卸载的任务大多是时延敏感型的,所以在确定任务调度的优先级时应主要考虑任务的时延约束。如上文所述,任务的最晚完成时间可以看作是每个任务的时延约束,每个任务的最晚完成时间可以从出口任务开始逐层向上递归地求出,基于此我们可求得所有任务的优先级。
3.2 MDP的构造
3.2.1 状态空间
MDP的状态空间应该能够反映当前应用的DAG结构、已经完成调度决策的任务情况等,基于此状态空间应包括以下部分:①当前已完成调度的任务序列;②已完成调度任务的卸载动作的集合;③DAG图。每当完成一个任务节点的调度,系统更新已完成调度任务序列及其动作集,并进入下一状态。
3.2.2 动作空间
动作空间中的动作表示的是G中每个任务的卸载调度决策,由于本文中每个任务都可以被分配给N个处理单元中的任意一个进行执行且分配给每个处理单元的概率是相同的,所以动作空间具体可以表示为:
A={0,1,2,…,n,…N}
其中:动作a={0}表示任务被分配在本地执行,a={n}表示任务被分配给了第n台MEC服务器执行。
智能体在执行选定的动作a后,环境将会反馈给智能体一个即时奖励r,在本章中即时奖励被设定为任务节点调度前后应用执行时延的差值,特别地,如果任务的执行时间超过了其最大容忍时延,即时奖励被设定为0。
3.3 有向无环图神经网络
由于DAG图是有向的、无环的,所以我们针对DAG的结构特性对标准的GNN做了改动使其能够处理DAG图。由于文献[16]归纳并抽象出各种GNN模型的共性,提出了一种通用的GNN处理框架信息传递网络(MPNN,message passing neural network),鉴于其在各领域的应用中展现出的良好的GNN信息提取能力[17],本文的DAGNN借鉴了MPNN的基本结构,具体的结构如图3所示。
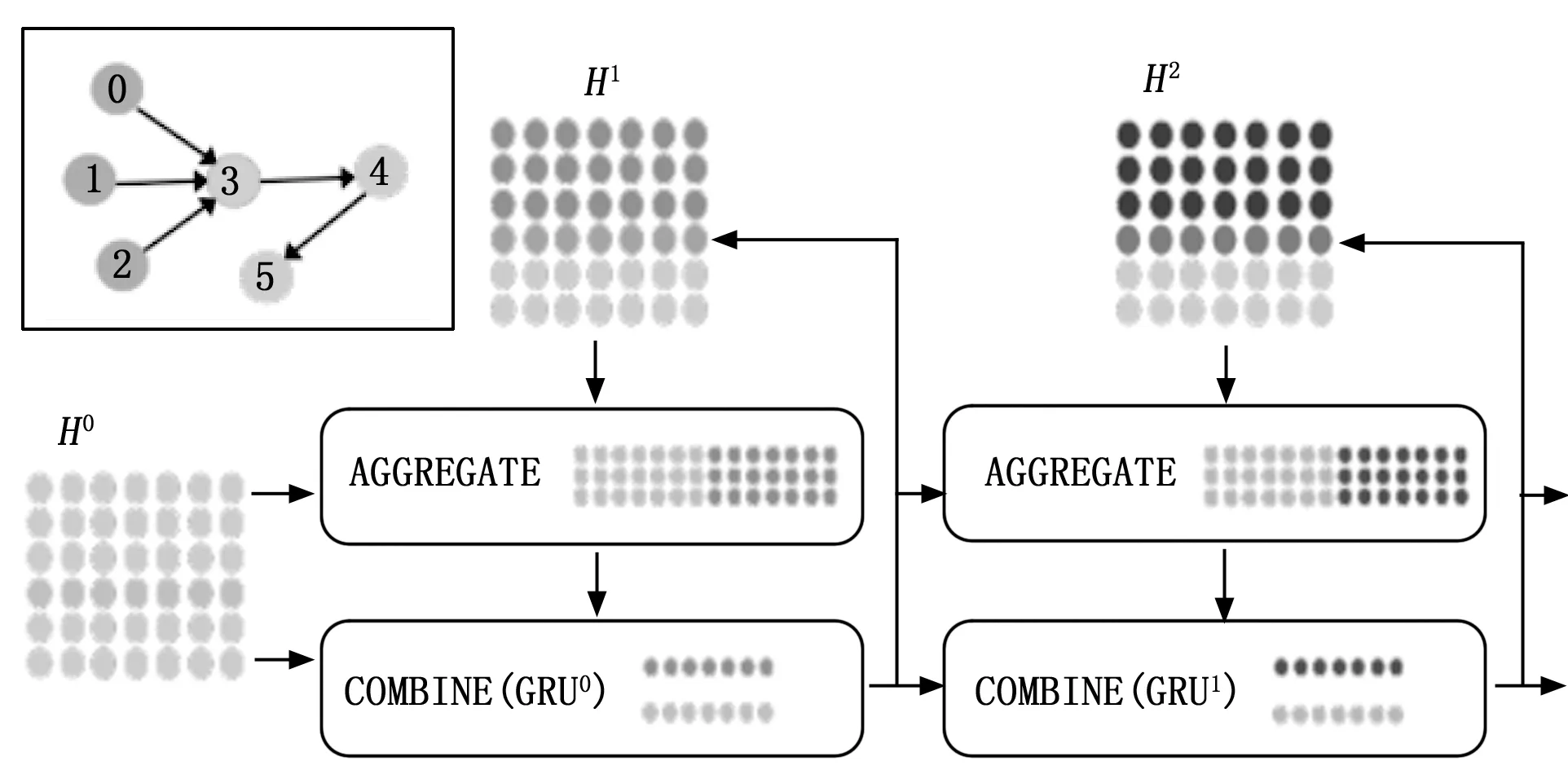
图3 DAGNN结构图
DAGNN中每个节点代表应用的一个任务,共包含L层网络。DAGNN通过聚合函数对每个节点的直接前驱节点的节点表示进行聚合,并把得到的聚合信息用连结函数与该节点在当前网络层的节点表示进行连结,用以更新节点表示。在所有节点间迭代进行这一过程,最后使用最大池化的方法将所有网络层的出口节点的节点表示进行聚合,通过读出函数将聚合后的信息读出,生成最终的图表示。DAGNN总的计算过程如式(13)和式(14)所示:
(13)
(14)

由于每个任务的执行时延只受其前驱任务的影响,因此我们在进行信息聚合时只考虑节点的前驱任务。除此之外,本文在聚合函数计算过程中引入注意力机制以便更好地聚合相关节点的信息,具体的计算方式如式(15)所示:
(15)
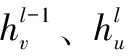
(16)

(17)
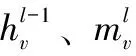
是仪也,不可谓礼。礼,所以守其国家,行其政令,无失其民者也。今政令在家,不能取也。有子家羁,弗能用也。奸大国之盟,陵虐小国。利人之难,不知其私。公室四分,民食于他,思莫在公,不图其终。为国君,难将及身,不恤其所。礼之本末,将于此乎在,而屑屑焉习仪以亟。言善于礼,不亦远乎?
在进行图表示的读出时,类似于以往图表示学习文献,我们用最大池化的方法把同一节点在每个网络层的表示进行连结,之后用一个全连接层产生图表示的读出。但与以往文献不同的是,根据DAGNN特殊的结构我们只把出口节点在每个网络层中的节点表示进行连结,之后用一个全连接层得出最终的图表示。具体计算过程如式(18)所示:
(18)

算法1:基于DAGNN的信息传递算法
2.输出:动作的q值
3.forl=1 toLdo
4.forv=1 toVdo

8.end for
9.end for
10.forvinTdo
11.通过式(3.25)将出口节点在所有网络层中的节点表示进行连结
12.用最大池化方法处理连结后的信息
13.将上一步处理过的信息输入全连接层,生成最终的图表示
14.end for
3.4 卸载调度流程
卸载调度的具体过程如算法2所示。在算法开始时,DRL算法的智能体收到要进行卸载调度决策的应用及其自身的DAG图,并获取每个任务节点的本地执行时延、MEC服务器上传输和执行时延等信息,生成每个任务节点的节点表示,将累积奖励和动作空间分别初始化为0和Ø,并创建一个经验回放缓存区。与此同时,用户设备产生一个待调度的应用,之后算法首先根据3.1节中所说的方式确定该应用中所有任务的调度优先级,然后按照任务优先级降序的顺序依次对任务进行调度决策。在对每个任务做决策时,智能体使用算法1评估每个动作的q值,得到每个动作的q值后根据ε贪心策略选择动作,在实施所选择的动作后系统进入下一状态s′,并获得环境反馈的即时奖励r,同时系统将当前状态s,采取的动作a,下一状态s′,即时奖励r等信息存入经验回放缓存区,用于对图神经网络进行训练和更新参数。卸载动作序列即为卸载调度决策。
算法2:基于DAGNN的卸载调度算法
2.输出:卸载动作序列β
3.初始化agent,状态空间S←{Ø},卸载动作序列β←{Ø},即时奖励r←0,初始化经验回放缓存区buffer
4.随机初始化DAGNN中的参数,初始化DAGNN每个节点的表示
5.根据2.3节中所述方式计算每个任务i的最晚开始执行时间LSTn,i
6.将所有任务按照其LSTn,i升序排列,得到优先级序列φ={x1,…,xv}
7.forx1toxvinφdo
8.fora=0 toNdo
9.调用算法1计算每个动作a的q值
10.根据ε贪心算法选择要采取的动作a
11.s←s’,更新动作序列β,获取即时奖励r
12.将四元组(s,a,r,s’)存入经验回放缓存区buffer
13.随机从buffer中取出若干个元组
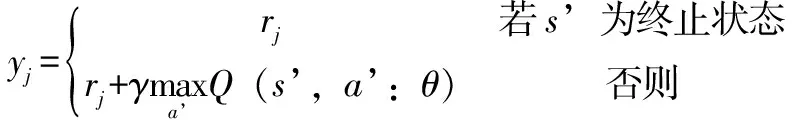
15.使用随机梯度下降算法SGD更新DAGNN的参数
16.end for
17.end for
4 仿真实验
本节将对本文提出的算法进行实验验证,主要以应用的完成时延作为标准来衡量各算法的性能,除此之外还考虑了在改变某些环境因素的情况下验证本文算法的通用性和稳定性。
4.1 实验设计
本节的实验情景包括多个微微基站(均配备有MEC服务器)和一个用户设备UE,具体的实验参数仿照文献[20]设置,如表1所示。

表1 仿真实验参数
为了模拟DAG应用的多样性,本节的实验使用文献[19-21]所采用的DAG生成器,本节实验中所用到的训练和测试DAG均通过该生成器生成。与此同时,本节设置了4个基线算法用以与本文提出的算法作对比,具体为:①本地执行(LE,local execution):应用的所有任务均在UE本地执行;②卸载执行(OE,offloading execution):DAG图中的所有任务均被调度为卸载执行;③随机调度(RS,random scheduling):对DAG图中所有任务均随机确定调度决策;④DRLOSM算法(DRLOSM):文献[22]提出的用来解决DAG应用卸载调度问题的算法,它采用图嵌入的方式将DAG图转化为节点信息向量的集合输入DRL算法的DNN网络中,并取得了同类文献中较好的调度效果。
图的密度是描述DAG中两个相邻的任务层之间依赖关系数量的参数,若该参数较大则表明DAG图中任务的前驱和后继节点较多。由于本文处理的主要是DAG结构复杂、模块的前驱和后继较多的应用,因而本节实验还将在改变DAG图的密度的条件下验证本文算法的性能。
4.2 实验结果分析
首先,对本章算法的收敛性进行评估。在上文所述的仿真参数下,随机生成3 000个DAG样本用于训练以得到对该批样本的卸载调度方案,然后将该调度方案在同样的仿真环境中对该批样本进行模拟调度,并记录该批样本所获得的平均累积奖励。如图4所示,该批样本的平均累积奖励在经历700此迭代后逐渐趋于稳定,证明了该算法具有良好的收敛性。
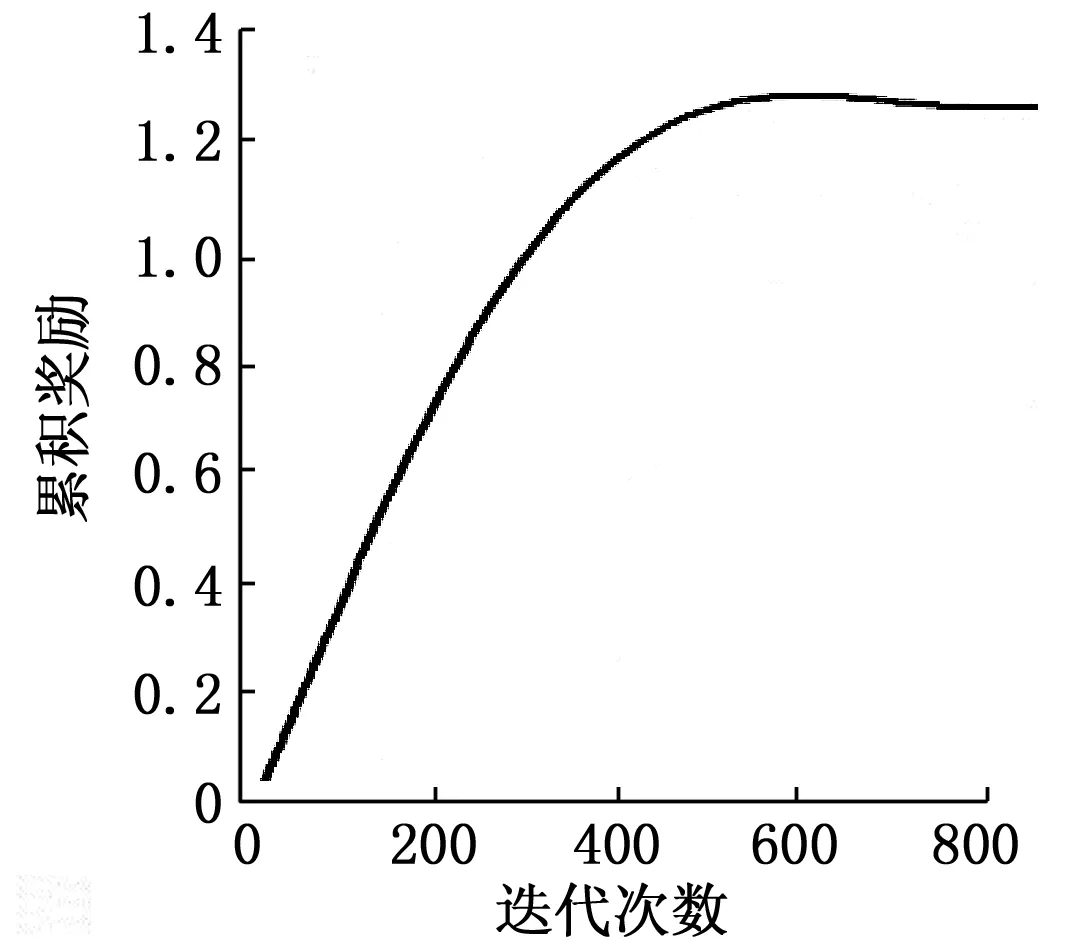
图4 收敛性曲线
然后,基于使应用的总处理时延最小的优化目标,在默认环境下对任务节点数量不同的DAG应用的处理时延进行了比较,图5展示了实验结果。可以看出在不同节点数的条件下,完全本地执行(LE)的方式的时延都是最高的,本文提出的算法(TOSA-DAGNN)都要优于其它对比算法。值得注意的是,虽然文献[22]提出的DRLOSM算法在节点数较少时也体现出了较好的性能,但是在节点数增加至50个后本文的算法开始明显优于DRLOSM算法,这是由于DRLOSM算法将所有节点的信息转化为统一长度的向量来输入DRL算法的神经网络中,这种方式在处理节点数较多且DAG结构复杂的应用时会丢失很多DAG图的结构信息,导致做出的卸载决策不够准确。
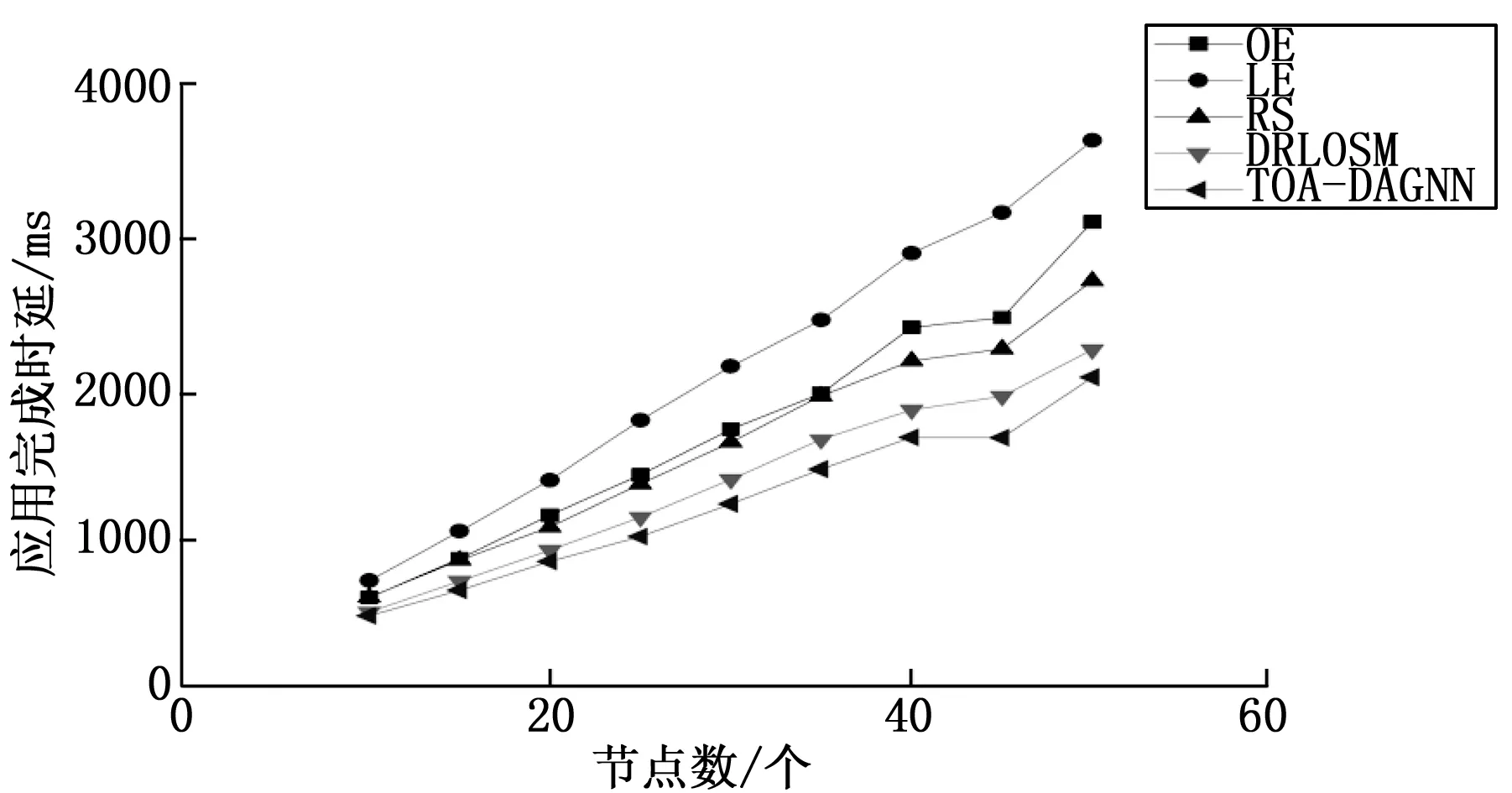
图5 应用的完成时延随任务节点数的变化
下面将在改变DAG图的密度的条件下验证本文算法的性能,如图6所示,在节点数量均为40的条件下,本节实验分别在DAG图密度为0.3、0.6、0.8和0.9时进行验证。从图中可以看出,随着图密度的增加本地执行(LE)、卸载执行(OE)和随机调度(RS)3种方式变化不大,这是由于在这3种方式中每个任务的执行方式是固定不变的,因而并不受到图密度变化的影响。但DRLOSM算法受图密度变化的影响较为明显,这是因为DRLOSM算法在处理过程中将任务的前驱和后继节点的信息转化为固定长度的向量,如果某个任务的前驱和后继节点过多就将超出的部分舍弃,而图的密度较大时DAG图中任务的前驱和后继节点往往是比较多的,因而此时DRLOSM算法的处理方式会舍弃大量的DAG图的结构信息,导致做出的卸载决策不准确。相较之下,本文的算法在各种图密度的条件下都能保持较好的卸载调度效果。
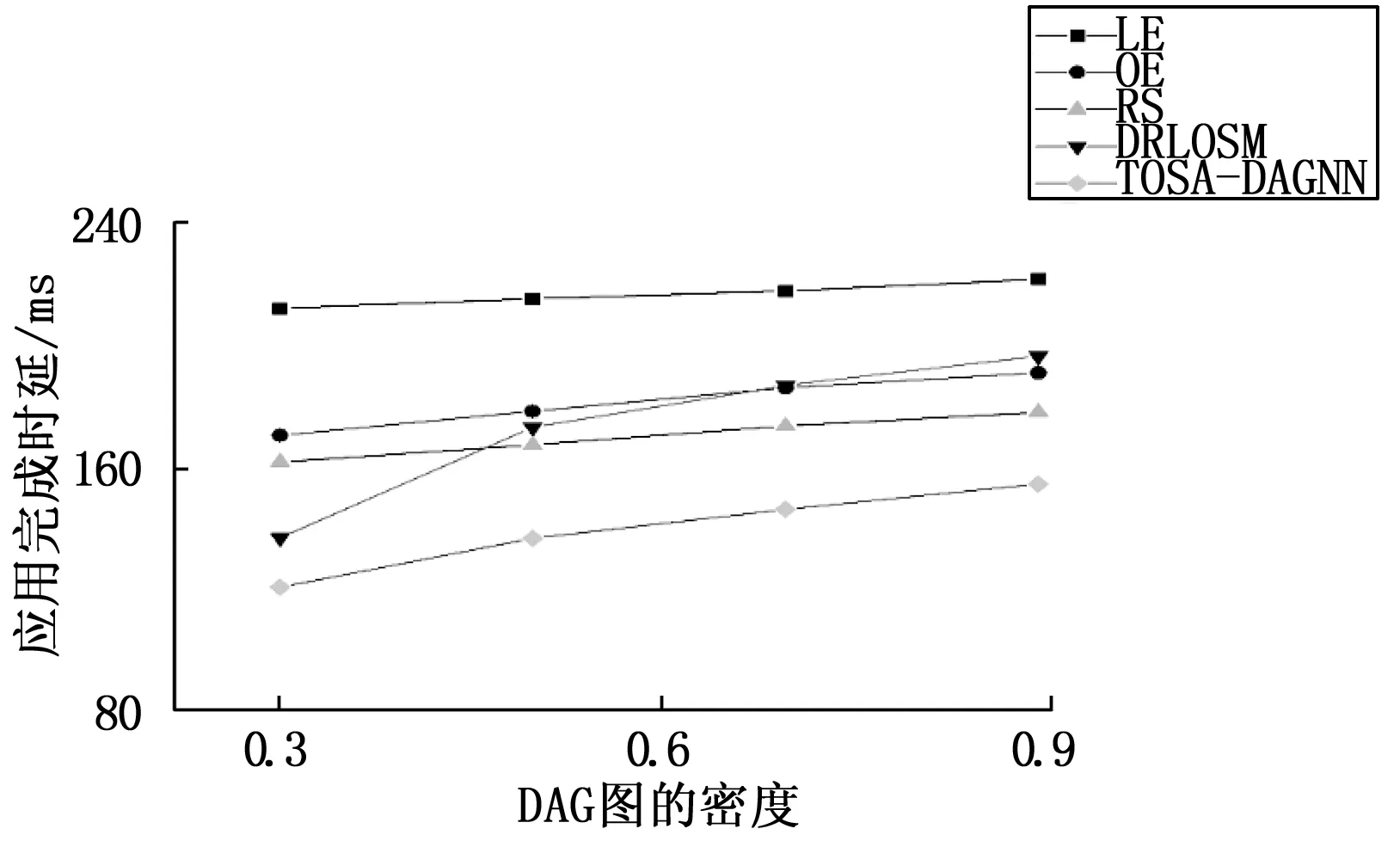
图6 应用完成时延随图密度的变化
为了验证本文算法的通用性和稳定性,下面在节点数均为40的情况下改变网络的传输速率来验证各算法的性能,如图7所示。可以看出随着网络传输速率的增大,除本地执行(LE)以外的各算法的完成时延都处于下降趋势,这是因为网络传输速率的加大降低了任务从用户设备UE到MEC服务器之间的传输时延,而本地执行(LE)的方式由于其所有任务都在本地执行,所以其完成时延不受网络传输速率的影响。卸载执行(OE)的方式由于其所有任务都被卸载至MEC服务器执行,所以随着网络传输速率的增加它的完成时延大幅降低,并在网络传输速率超过8 Mbps后其完成时延逐渐超过DRLOSM算法。同时可以看出,本文提出的算法(TOSA-DAGNN)始终在完成时延方面优于其它算法。
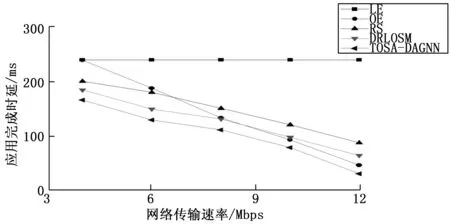
图7 应用完成时延随网络传输速率的变化
5 结束语
本文研究了MEC中具有依赖关系任务的计算卸载问题,通过DAG对任务间的依赖关系进行建模,将卸载调度建模为MDP过程进而使用DRL算法进行求解。为了解决其它文献在将DAG图输入DRL算法的神经网络时存在的丢失DAG图的结构信息的问题,创新地将GNN与DRL算法相结合用于解决卸载调度的问题。同时为了适应DAG图的结构特点将MPNN进行了改进,提出有向无环图神经网络(DAGNN),最后的实验结果表明,与其它基线算法相比本文提出的方案收到了最好的调度效果,尤其是在处理DAG结构复杂、任务的前驱和后继节点较多的应用时本文的方案明显优于其它算法,并在网络环境改变时始终优于其它算法,体现了本文方案的通用性和稳定性。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
计算机与数字工程(2022年7期)2022-08-26
北京航空航天大学学报(2022年5期)2022-06-06
南方农业·下旬(2022年4期)2022-05-24
电脑知识与技术(2021年22期)2021-09-14
电脑知识与技术(2021年22期)2021-09-14
现代信息科技(2021年21期)2021-05-07
证券市场周刊(2020年46期)2020-12-28
牡丹江师范学院学报(自然科学版)(2019年2期)2019-09-10
花火B(2019年3期)2019-04-27
