
面向车规级芯片的对象检测模型优化方法
2021-11-30 05:18:46宫大汉于龙龙陈辉杨帆骆沛丁贵广
智能系统学报 2021年5期
宫大汉,于龙龙,陈辉,杨帆,骆沛,丁贵广
(1. 清华大学 软件学院 , 北京 100084; 2. 清华大学 北京信息科学与技术国家研究中心,北京 100084; 3. 涿溪脑与智能研究所,浙江 杭州 311121; 4. 清华大学 自动化系,北京 100084; 5. 禾多科技(北京)有限公司,北京100102)
卷积神经网络(convolutional neural network,CNN)在图像识别、对象检测等视觉感知任务上取得了巨大的成功。由于其优秀的性能,使得CNN已经成为一种标准的智能结构,在智能手机、可穿戴设备、IoT终端设备、自动驾驶等智能应用中扮演着重要的角色。然而,CNN参数量巨大、计算复杂度高的特点限制了它在实际场景中的大范围落地应用。比如在自动驾驶领域,如果CNN模型部署到云端,那么网络传输的稳定性将决定系统是否能及时应对不断变化的外部环境,进而影响整体自动驾驶性能。而受限于网络传输的不稳定性,这种云端计算终端响应的方式在实际自动驾驶系统中难以广泛应用。所以,基于车载终端设备实现深度模型的部署成为一种越来越流行的解决方案。
然而,面向车载终端设备的深度模型部署存在着计算资源和模型性能的矛盾。具体来说,深度模型复杂度越高,通常它的效果越好,但其计算速率越差。考虑到终端设备上缺少高性能计算单元(如GPU)的支持,使得复杂度高的深度模型无法满足计算效率的要求。而如果采用复杂度低的小模型,又面临模型性能不佳的问题。因此,如何在计算资源受限条件下实现高精度深度模型的部署对自动驾驶至关重要。
本文面向自动驾驶场景,研究车规级芯片上的对象检测[1-2]模型高效计算方法。本文使用先进的对象检测模型CenterNet[3]作为实验模型。这种模型通过预测对象中心点的位置和包围盒的偏移量,进而确定对象的整体位置。通常使用主流深度学习模型,比如ResNet[4]作为模型的主干网络。主干网络可以将输入的视觉图像均分为网格区域,然后CenterNet判断每个网格点是否是某个对象的中心。考虑到车载系统缺乏高性能计算单元GPU,本文采用轻量型深度模型ResNet18作为CenterNet的主干网络。
ResNet18通过堆叠3×3卷积,使得在一个3×3的卷积窗口中,卷积核的中心点对应的区域可以不断“吸收”周围区域的信息来增强自身的特征表达。这种方式的缺点在于3×3卷积将中心区域的特征和周围区域的特征同等对待,容易降低中心区域的特性在特征中的表达,加大了模型混淆中心区域和其他区域的可能性,不利于Center-Net对关键点的定位。
为了解决这个问题,本文提出一个基于中心卷积的对象检测模型。具体来说,本文为3×3卷积增加一个1×1卷积旁路,这种旁路对应3×3卷积核的中心区域,可以充分学习中心区域的隐藏特性。本文对3×3卷积和1×1卷积的输出进行加和融合,并将这种结构命名为中心卷积。所设计的中心卷积可以独立学习中心区域的特性和周围区域的关联信息,有效增强中心区域的特征表达,促进关键点的预测。3×3卷积和1×1卷积都是线性变换,因此在模型部署推理时,可以很方便地将1×1卷积旁路的参数融合到3×3卷积核的中心点上,恢复成标准3×3卷积,大大降低了推理时的模型大小。相比于标准的3×3卷积,所提出的中心卷积不增加推理复杂度,但是具有更强的特征学习能力,使得模型检测效果更佳。
本文用中心卷积替换了ResNet18中的3×3卷积,构建了基于中心卷积的CenterNet模型,并在实际的车规级计算芯片上进行了模型部署验证。尽管ResNet18的计算复杂度不高,但为了充分利用车载系统的计算资源,希望尽可能在保持精度的情况下,提升CenterNet的计算效率。为此,本文采用一套基于量化的部署流程:首先使用量化感知的训练方式对给定的CenterNet进行重训练,得到int8数值精度的CenterNet模型,然后调用底层开放接口,将模型部署在芯片上。通过这种量化感知训练,可以得到低比特的模型,减少了模型的大小,并且保持了足够高的模型精度。而在芯片线上推理过程中,模型以低比特int8进行运算,相比于float32运算,处理速度更快。
综上所述,本文提出了一种中心卷积来替代ResNet18中的3×3卷积,构建了基于中心卷积的CenterNet对象检测模型;进一步,采用基于量化的模型部署方法,实现在车规级芯片上的模型效果验证。
1 相关工作
对象检测领域的研究热点经历了由基于锚点框(anchor-based)检测模型到无锚点框(anchorfree)检测模型。其中,以CornerNet[5]为代表的基于关键点预测的对象检测模型的出现引起了研究者的广泛兴趣,anchor-free的方法渐渐兴起。CornerNet首次提出预测包围框的一对角点来检测目标,并使用角池化操作来更好地定位包围框的角点。之后,Zhou等[6]提出ExtremeNet来预测对象的极值点和中心点进而实现目标检测的目的,后面又进一步提出CenterNet只预测中心点来检测目标。Liu等[7]改进了CenterNet,提出了TTFNet,使用高斯核编码来引入更多的回归样本,极大地加快了模型的训练速度。而Zhou等[8]又将中心点预测的思想引入到两阶段(two-stage)检测模型中,获得了显著的性能。
需要指出的是,本文重点关注深度模型在车规级芯片上的高效推理。具体来说,本文希望在有限的计算资源条件下实现高性能和高效率的对象检测模型。考虑到CenterNet具有简单易扩展的优点,所以本文采用CenterNet为实验模型进行探索,而不采用近期对CenterNet的改进工作进行实验,如CenterNet2[8]、TTFNet[7]。
2 基于中心卷积的对象检测模型
2.1 中心卷积
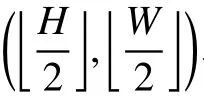

式中:∗表示矩阵元素相乘;Mi,j是从M中以 (i,j)为中心截取的一个大小为H×W×C的矩阵;Fk表示第k个大小为H×W×C的矩阵。3×3卷积和1×1卷积都可以用式(1)来描述。
图1展示了3×3卷积运算。卷积以3×3为滑动窗口对输入的特征图M进行处理,处理时,将中心区域 (i,j)信息和窗口内的区域信息进行融合,输出的特征可作为中心区域 (i,j)的更高层次的特征表示。可以看到,这种方式直接对窗口内的区域特征进行融合,没有考虑到每个区域的不同,这样就容易减弱中心区域的特性信息在更高层次特征中的表达,使得在CenterNet中对关键点的预测效果不佳。
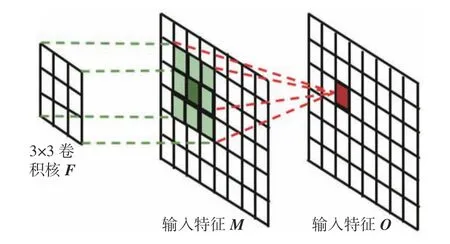
图1 3×3卷积运算Fig.1 3×3 convolution operation
为了解决上述问题,本文提出中心卷积(center-convolution)来增强中心区域的信息。中心卷积被设计为双分支的架构,其中一个分支是标准的3×3卷积后接一个批规范层(batch normalization,BN)[9],用于融合领域的信息,另外一个分支是一个1×1的卷积旁路,同样后接一个批规范层,用于增强中心区域自身的信息。需要注意的是,两个分支学习到的信息是不一样的,所以学习到的特征空间中的分布不一样。因此,双分支的两个BN层的参数是不共享的。在BN层将不同信息进行规范化约束后,对两个分支进行加和操作得到最终的中心区域的特征。图2展示了标准的3×3卷积和所提出的中心卷积的差异。
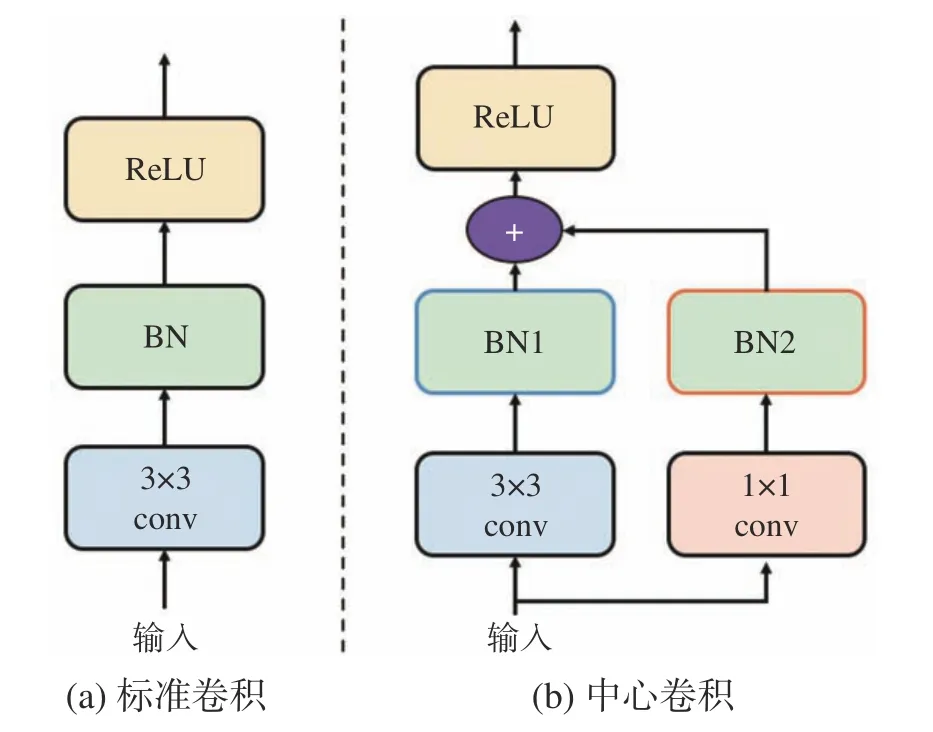
图2 标准卷积和中心卷积Fig.2 Standard convolution and center-convolution
中心卷积尽管因为引入了旁路分支而增加了模型的复杂度,但实际上,所引入的1×1卷积以及BN层可以融合进3×3卷积中,因此,形式上就等价于标准的3×3卷积。具体来说,给定中心卷积,其中的3×3卷积设为F3×3∈R3×3×C×D,1×1卷积设为F1×1∈R1×1×C×D,对于给定的输入特征中的一个3×3的分块M∈R3×3×C,卷积层的输出O∈RD为
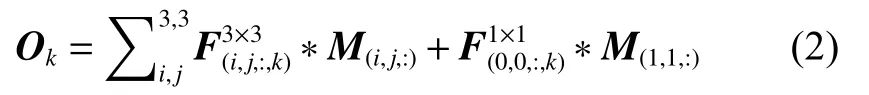
式(2)可 以很容 易 地将F1×1融合 到F3×3中 的(1,1)的张量上,得到新的 3×3 卷积Fnew∈R3×3×C×D:
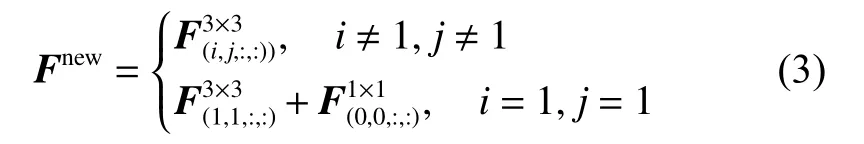
图3展示了中心卷积的融合过程。在模型训练时,本文将中心卷积设计为图2所示的双分支的结构,这样可以利用冗余的1×1旁路分支来增强模型对图像显著性特征的学习,提高网络的学习性能,而在推理阶段,利用图3所示的分支融合机制,可以很好地将冗余参数融合进主干3×3分支中,融合后的计算等价于标准的3×3卷积,不会提高模型的推理复杂度。

图3 将1×1卷积融合到3×3卷积中Fig.3 Merging 1×1 into 3×3
2.2 基于中心卷积的CenterNet检测模型
本文选择CenterNet来构建检测模型。CenterNet抛弃了传统的基于锚点框(anchor)[10]的对象检测方法,而是通过预测目标对象的中心点位置和大小来预测对象的包围框。
使用本文提出的中心卷积来构建ResNet18模型,并在ImageNet[11]上进行预训练。为了方便描述,本文将得到的模型命名为C-ResNet18。并基于C-ResNet18卷积神经网络设计主干网络构建CenterNet对象检测模型,得到的模型称为CRCenterNet。为了对比,本文也基于ResNet18构建了CenterNet,得到的模型称为R-CenterNet。对比效果详见实验部分。
3 基于量化的深度模型部署
考虑到在自动驾驶车辆上,通常部署一些专用的终端芯片和设备来执行相关算法和模型。计算资源受限是该类设备的一大缺陷,这给复杂度高的智能模型的应用带来了巨大的挑战。面向终端设备的深度模型加速技术能够显著降低深度模型的复杂度,有利于深度模型在终端设备上的部署。
本文采用基于量化的模型加速方法,以最大化车载系统底层计算模块的计算效率。深度模型在训练过程中使用浮点精度来表示参数和数据的数值,从硬件原理来说,整数运算比相同位数的浮点运算更快且更省电,如果将深度模型的计算全部转化为整数运算,势必带来极大的加速效果。基于量化的模型加速方法就是通过将浮点(float32)精度数值量化到短型整数(int8)精度数值,实现了模型的高效运算。
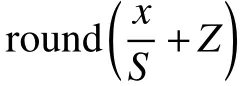
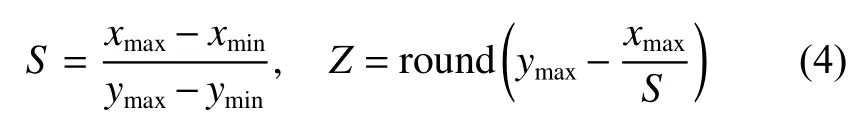
式中:xmax和xmin分别表示x的最大值和最小值;ymax和ymin分别表示y的最大值和最小值;round函数表示四舍五入运算。
基于上述的数值量化方法,可以很容易地将预训练好的深度模型进行参数量化。但是实验表明,这种后量化的方式存在量化误差累积的缺陷,使得量化后的模型性能产生了极大的损失。目前的很多深度学习框架,比如pytorch[12]和TensorFlow[13]都使用了一种量化感知的方法,将参数量化的过程融合进模型训练过程中,让网络参数能够适应量化带来的信息损失。本文采用同样的方法对深度模型进行处理。具体来说,将量化算法集成为一个模块,并串联在卷积参数层的后面参与特征计算,流程如图4所示。因为量化操作里面的round函数不是可导的,所以在反向传播的时候无法将梯度准确地传给前面层的参数。为了解决这个问题,本文重构了量化层的前向和后向操作,在前向时按照量化操作正常进行,反向时跳过量化层,直接把卷积层的梯度回传到量化前的卷积参数中来。因为卷积层的梯度是经过量化操作的,因此可以模拟量化误差,把误差的梯度回传到原来的参数上,使得原来的参数去自适应地感知量化产生的误差。本文的实验结果表明,量化感知训练的方式可以避免模型的性能下降,而其计算效率成倍提升。
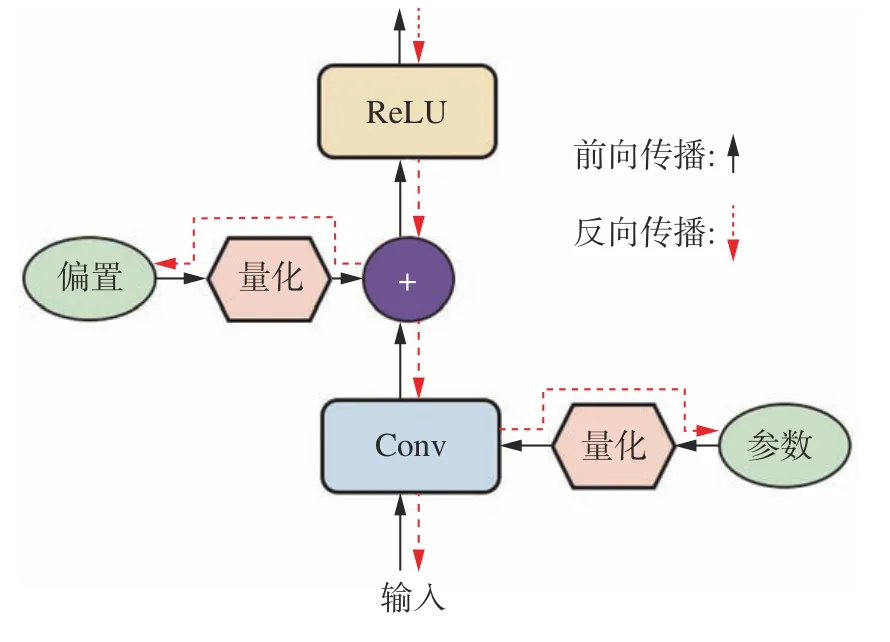
图4 带量化层的卷积操作Fig.4 Convolution with the quantization layer
4 面向车规级芯片的检测验证系统
本文在车规级计算芯片上搭建了对象检测系统。为了达到这个目标,本文首先针对真实的自动驾驶场景收集了一批数据,并采用人工的方式进行数据标注。本文一共收集了两批数据:泊车数据和公路数据。泊车数据在室外泊车场景采集,共有7 848张RGB图像,每张图像标注了2D的包围框和物体接地点位置。如图5所示,红框是车辆的包围框,彩色点是车辆的接地点。公路数据是在公路场景采集的,由22 213张RGB图像组成,标注了3D的包围框。

图5 泊车数据和公路数据Fig.5 Parking data and road data
成本是智能算法在自动驾驶场景面临的一个重要的问题。自动驾驶场景复杂广泛,如果使用全监督的方式进行数据标注,标注成本将不可估量。其次,对象的3D信息是保障自动驾驶安全可行的一种重要数据,但其采集设备代价昂贵,不适合车辆量产。对此,本文设计了一套从2D图片到3D空间推断的对象检测流程。具体来说,本文用泊车数据中的2D包围框和接地点训练了所提出的基于中心卷积的对象检测模型CRCenterNet,然后利用输出的2D框和接地点信息,逆投影到世界坐标系中,得到对象的3D位置信息,即输入是2D图像,输出是3D位置信息(这里用鸟瞰图表示,如图6所示)。在训练阶段,CRCenterNet只在泊车数据上训练,测试时只在公路数据上进行测试。实验发现,尽管模型在训练过程中没有感知到公路数据上的对象信息,但是在公路数据上仍然具有较好的性能,说明模型具有较好的泛化能力。
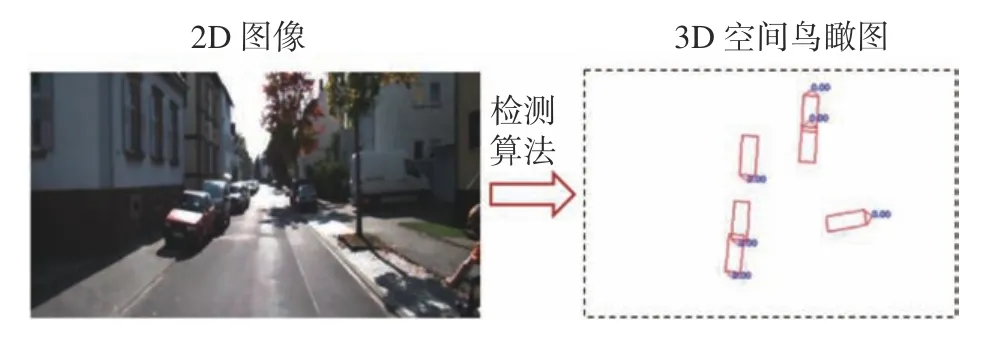
图6 自动驾驶的检测任务Fig.6 A detection task toward the autopilot
芯片的计算效率是限制深度模型在车载系统上应用的一个关键因素。本文采用常用的tda4芯片来搭建对象检测算法验证系统。首先将训练好的CR-CenterNet模型进行量化(如第3节内容所述),然后注入到tda4芯片上进行运算。整体的开发流程如图7所示。
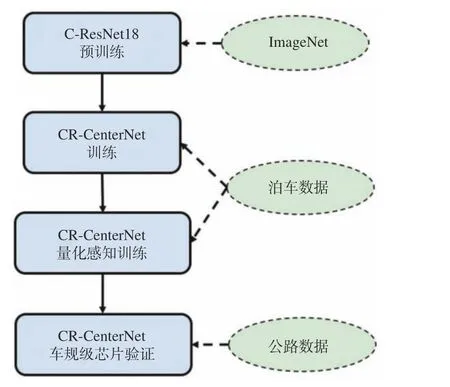
图7 面向车规级芯片的检测系统构建Fig.7 Constructing the detection system on car-level chips
5 实验
5.1 中心卷积
在本节中,将验证所提出的中心卷积的有效性。ImageNet是目前国际上主流的大型图像分类评测集,在人工智能的发展史上具有举足轻重的地位。AlexNet[14]、VGGNet[15]、GoogleNet[16]、ResNet[4]和DenseNet[17]的成功都离不开ImageNet,ImageNet也已经成为计算机视觉领域的标准数据集。研究者通常会使用ImageNet来验证新提出的模型的有效性,然后在下游任务上进行验证,如对象检测[1-2,18]、实例分割[19-21]、行人重识别[22-24]等。
因此,本文在ImageNet上对C-ResNet18进行了预训练,并在图像分类任务上展示其有效性。在训练时,本文采用批训练(batch)的方式来训练C-ResNet18,每批次采样256张图片,并训练120轮。模型的训练学习率设置为0.1,采用简单的数据增广策略,如随机裁剪和随机水平翻转。
为了展示所提出的中心卷积的有效性,本文把ResNet18作为基线模型,并和C-ResNet18进行对比。对比结果如表1所示。
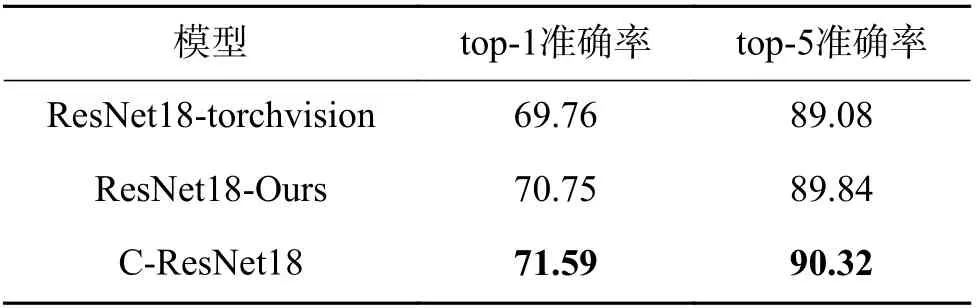
表1 在ImageNet上的分类准确率Table 1 Classification accuracy on ImageNet %
为了对比公平,这里展示了由pytorch官方提供的ResNet18结果(ResNet18-torchvision)和本文复现的ResNet18的结果(ResNet18-Ours)。从表1的实验结果可以看出,相比于ResNet18-torchvision,本文复现的ResNet18获得了更高的分类准确率,原因是本文采用更好的训练技巧。而本文所提出的C-ResNet优于ResNet18-torchvision和ResNet18-Ours,其中,相比于ResNet18-torchvision,C-ResNet18在 top-1准确率上提高了1.83%,在top-5准确率上提高了1.24%;相比于ResNet18-Ours,C-ResNet18在 top-1准确率上提高了0.84%,在top-5准确率上提高了0.48%。和ResNet18-Ours的性能对比,可以看出所提出的中心卷积对模型性能的增益效果显著,很好地证明了所提出的中心卷积的有效性。
5.2 CR-CenterNet
本节验证所提出的中心卷积在本文所构建的面向自动驾驶真实场景中的对象检测任务的应用效果。本文使用所构建的基于中心卷积的对象检测模型(CR-CenterNet,见1.2节)在泊车数据上进行模型训练,实现接地点的预测。尽管泊车数据上提供了2D框的标注数据,但本文致力于研究从2D数据中推断出对象的3D空间位置。因此,本文构建CR-CenterNet时只预测跟对象有关的接地点位置,然后使用逆投影算法[25]推断对象的3D空间位置信息,并可视化真实场景的鸟瞰图。
考虑到对象检测模型的复杂度较高,因此,本文训练CR-CenterNet时采用分布式训练方式。具体来说,本文使用3张2 080Ti的英伟达显卡训练模型,每张卡在一个批次内训练3张图片,即批次大小是9。本文设置CR-CenterNet的学习率为3e-5。整体训练进行了300轮,并保存最后一轮的结果进行模型评测。
为了验证CR-CenterNet的性能,本文也基于ResNet18训练了CenterNet模型(R-CenterNet)。在模型评测时,本文计算鸟瞰图模式下,算法推断的包围框和人工标注的包围框的交并比,将交并比大于0.5的预测当作是正确的预测。表2展示了基线模型R-CenterNet和本文的CR-Center-Net的整体性能对比。
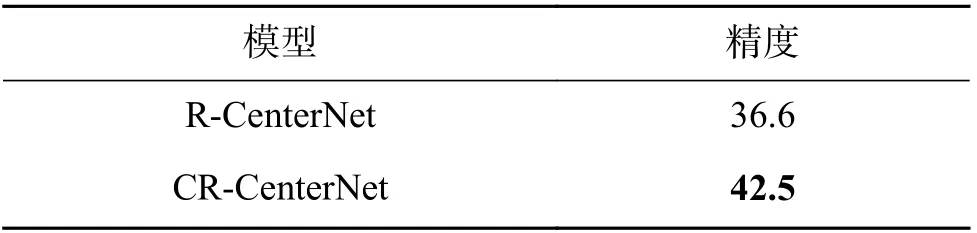
表2 R-CenterNet和CR-CenterNet的性能对比Table 2 Performance comparison between R-Center-Net and CR-CenterNet %
从表2可以看出,CR-CenterNet可以比RCenterNet获得5.9%的提升,进一步证明了所提出的中心卷积在这个任务上的有效性。
图8展示了算法的对象检测效果,包括CRCenterNet预测的接地点,以及逆投影后的鸟瞰图效果。图8(a)中也展示了标注的包围框,图8(b)中绿色的是标注的鸟瞰图矩形框,红色的是使用R-CenterNet得到矩形框,橙色的是使用CR-CenterNet得到的矩形框。可以看到,即使因为遮挡问题而无法从图像中直接看出接地点,所提出的CR-CenterNet也可以有效推断出对象的接地点;相比于R-CenterNet,CR-CenterNet对对象的3D空间位置推断(鸟瞰图)更加准确,也侧面说明了所提出的CR-CenterNet的有效性和优越性。
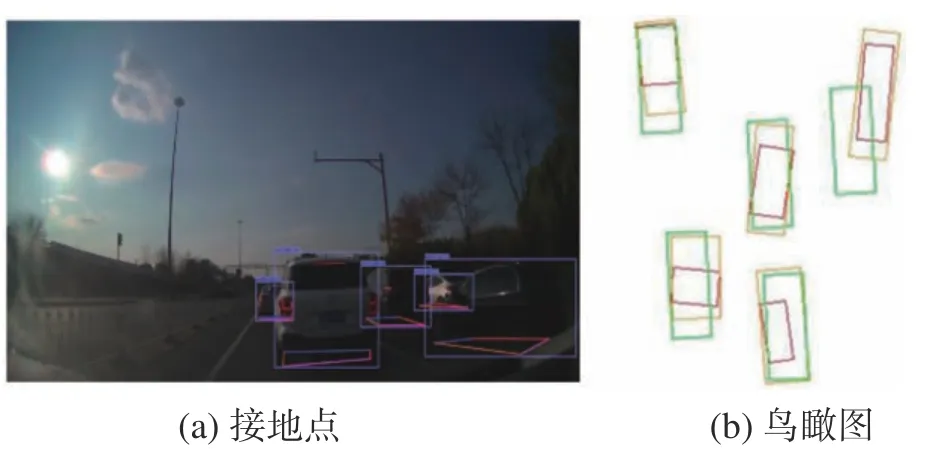
图8 对象检测效果可视化Fig.8 Visualization of detected objects
5.3 面向车规级芯片的模型验证系统
Tda4芯片是一款由世界第三大半导体制造商德州仪器(TI)推出的面向新一代智能驾驶应用的车规级芯片,具有性能强、成本低、功耗低、安全性较高等优势,因此被许多汽车厂商和一级供应商选为计算平台。本文采用基于量化的方法成功将所提出的基于中心卷积的对象检测模型部署到该款车规级芯片tda4上。为了展示模型在tda4上的推理性能,在不同的计算平台上部署了本文提出的CR-CenterNet,并测试了模型处理单张图片的时间开销。表3展示了各个平台上的时间开销对比情况。

表3 不同平台上CR-CenterNet的时间开销Table 3 Time consumption of CR-CenterNet in various platforms.
本文选择了6种不同的计算平台,包括服务器端CPU和GPU、笔记本CPU和GPU、芯片模拟器和车规级芯片tda4,对比结果如表3所示。可以看到,在服务器端,无量化版的CR-CenterNet在CPU上达到776 ms的时间开销,而量化版的CR-CenterNet在tda4上可以提升超10倍,时间开销下降到64 ms。由此可见,量化版的深度模型可以在计算性能更受限的车规级芯片上取得比服务端高性能CPU更优的计算速率。
此外,本文所采取的量化方法在训练过程中进行,可以抵抗由于量化所导致的模型精度的骤降。表4展示了CR-CenterNet在量化前后的检测性能的对比,可以观察到,经过量化感知训练的模型在检测效果上跟量化前的模型差异不大(仅下降了1.4%)。

表4 量化对模型效果的影响Table 4 Impact of the quantification method on the detection performance %
从上述分析可以看到,基于量化的部署方法可以提升模型的计算效率且保持模型的精度,满足了车规级芯片的计算需求,因此,本文将整套算法集成到支持tda4芯片的开发板上,形成一套面向车规级芯片的检测模型验证系统。图9展示了利用tda4进行计算得到的检测效果。可以看到,对于输入的RGB图片,所构建的车规级芯片验证系统能够准确地给出3D空间位置信息(鸟瞰图)。

图9 面向车规级芯片的对象检测模型验证系统Fig.9 Object detection model verification system for carlevel chips
6 结束语
本文针对自动驾驶场景下智能模型计算效率要求高和终端设备计算资源受限的矛盾,提出了基于中心卷积的轻量化卷积神经网络和基于量化的深度模型部署方法。所提出的中心卷积在训练时为标准3×3卷积引入了1×1卷积旁路,可以增强模型对视觉信息的学习,而在推理时,可以方便地将旁路融合进3×3卷积中,减少了计算量且保持了和原来模型一样的性能。所采用的量化模型部署方法可以降低模型的大小,在保持量化前模型精度的情况下成倍提升模型的计算效率。基于轻量化中心卷积结构和量化技术,本文成功将深度对象检测模型在车规级芯片tda4上部署,在自动驾驶场景上取得了良好的检测性能。未来,有望集成到真实车辆驾驶系统中,在真实自动驾驶场景下发挥更大的作用。
猜你喜欢
睿士(2023年2期)2023-03-02 02:01:09
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
意林(2018年3期)2018-03-02 15:17:24
厦门理工学院学报(2016年1期)2016-12-01 04:50:48
发明与创新(2016年23期)2016-10-13 02:16:14
湖北工业大学学报(2016年5期)2016-02-27 13:14:51
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:48
电视技术(2014年19期)2014-03-11 15:38:20
