
Python环境下金融交易数据的API调用
2021-11-28 11:55春雨王宇栋
中国集体经济 2021年36期
关键词:网络爬虫
春雨 王宇栋
摘要:随着股票/期货市场的快速发展,股票/期货相关数据的获取是第一个需要解决的问题。通过API调用来获取数据能优化数据获取流程,节约数据获取时间。文章基于股票/期货API的沪深港股票/期货交易数据调用方法,分析对比其與网络爬虫数据调用方法的异同。由于单独使用网络爬虫或API调用不能完成数据准确完整的调用。因此,提出一种API调用和网络爬虫相结合的方法,从而解决API调用数据次数受限,网络爬虫调用数据过程复杂等问题,综合两种方法的优点以实现数据高效完整的获取。
关键词:API;API调用;数据获取;网络爬虫
19世纪70年代,Digital Research公司创造出了世界上第一个实用的软件API(Application Programming Interface,应用程序接口),这个API仅仅由20种简单的函数组成,但就是这个API的出现改变了整个计算机领域。之后比尔·盖茨等人复制了其API开发出MS-DOS操作系统,添加了一些简单的特性之后,将其推上了软件开发的主导地位。
1981年,微软公司发布Windows操作系统,但其自己开发出来的Windows API不能满足当时使用需求,大量的开发人员投入到Windows程序的开发中来,同时加快了API的发展进程。
1988年,微软公司购买了Alan Cooper开发的可视编程语言:Ruby。Ruby满足了名为VBX的软件API,这种API可以让开发人员动态地扩展Visual Basic功能。
除了微软之外,Unix世界也创造出可以在网络之间自由通信的API,这就是TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/网际协议)。到了20世纪90年代,Marc Andreessen推出了世界上第一个Web浏览器:Mosaic。正是因为有了TCP/IP API,Netscape可以在自己的计算机之外查找其他网络上的计算机,并且提取其中的文件。
今天的软件开发者很大一部分是在开发Web应用程序, Web领域的开发者们不会对Web本身有太多的研究,所以这些开发者需要把其他开发者预先编写的部分组合起来,所以他们比以前更多地依赖于为其编写的软件API。同时API在金融领域也发挥着它的优势。由于互联网技术的不断发展,股票/期货的交易数据也呈现着快速增长的趋势。目前大量股票/期货交易数据为政府、组织机构、企业所拥有,但是社会层面对股票/期货交易数据的需求也越来越强烈,越来越多的团体或个人需要按照自己的交易习惯定置个性化交易软件。股票/期货交易数据的获取量大、股票/期货数据更新频繁、数据传播迅速,并且数据获取用户相对集中,所以用API来调用股票/期货数据既满足了用户对股票/期货数据的需求同时还节省了数据获取时间。
一、API概述
API是指操作系统预先把这些复杂的操作写在一个函数里面,编译成一个动态链接库,跟随操作系统一起发布,并附上使用文档说明,使用者只需要简单地调用这些函数就可以完成一些复杂的工作。API具有以下性质,一是可用性,是指用户能否便捷运用API来完成指定任务,是衡量API质量的重要指标。二是稳定性,代表着API的质量,稳定的API可以提高调用数据的准确性完整性。三是安全性,API的不规范使用可能会导致数据在调用过程中发生错误,致使返回给用户的数据不准确甚至给操作系统带来安全风险。API按用户不同权限提供数据服务其中包括:一是支持内容创建,API 允许用户定制、获取、上传数据;二是禁止内容创建,API 只允许用户定制、获取数据,不允许对数据进行编辑更改。大部分开放给普通用户的API都禁止用户对其创建内容,主要原因是防止权威数据的漏传、误传甚至丢失,例如用户获取实时股票/期货交易数据。
API 调用是通过 API 有条件的精确获取用户所需要的数据,调用方式灵活方捷、反映速度快。
二、API调用股票/期货数据的方法与实现
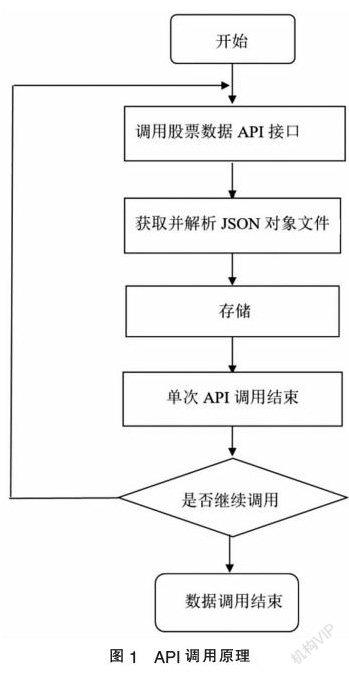
API调用数据原理如图1所示。
(一)API接口的选择
获取股票/期货数据的API接口主要有:数据超市、雅虎、新浪、Google等。
由于计算机技术的发展以及数据获取手段的普及,现在出现了许多数据超市,可以更加高效快捷的获取股票/期货数据,不仅节约了获取者的时间,同时也有利于获取更多准确及时的数据。下面介绍三种数据接口从中选择一个作为接下来实验的数据接口。
1. 雅虎
缺点:部分美国假期数据缺失;调用数据的次数有限制,超过规定次数就会被警告并封锁IP地址。优点:数据比较权威,准确性有保障,可以获取其他国家市场数据;返回数据解析方便,较好提取。
2. 新浪
缺点:股票/期货历史数据不够完整。优点:速度非常快;返回数据容易处理;可以按照使用者要求获取单一方面的数据。
3. Google
缺点:数据都是从新浪获取,获取自由度低。优点:数据准确可靠。
综合以上接口的优缺点,通过对比分析选择数据更加全面完整,获取范围更加广泛的雅虎接口作为实验中的API接口。
(二)API调用股票/期货数据
从新浪财经网络接口直接调用股票/期货数据。
基本步骤:import requests
r=requests.get("http://hq.sinajs.cn/list=股票/期货代码")
print(r.text)
注意:上证股票在输入股票代码时要在前面加上sh,深圳股票在股票代码前面加上sz,港股在股票代码前面加上hk
下面分别调取了沪股浦发银行sh00000、深股平安银行sz000001、以及港股颐海国际hk01579、海底捞hk06862的股票交易数据和玉米、白银、黄金的期货交易数据。
浦发银行股票交易数据:
import requests
r=requests. get("http://hq. sinajs. cn/list-s600000")
print (r. text)
var hq_ str_sh600000="浦发银行,12. 170, 12. 230, 12. 040, 12. 220, 12. 010, 12.030, 12. 040, 38092059, 460234691. 000, 62300, 12.030,239567, 12. 020, 729627, 12.010, 1215100, 12. 000, 2099000,11. 990, 82800, 12. 040, 192900, 12. 050, 390800 12. 060, 238700, 12. 070, 296100, 12. 080, 2019-11-20, 15:00:00, 00,"
平安银行股票交易数据:
import requests
r=requests. get("http://hq. sina js. cn/list=sz000001")
print (r. text)
var hq_str_sz000001="平安银行16.300, 16.410, 15.850, 16.300, 15.770, 15.850, 15.860, 172438353, 2747598383. 400, 303297, 15. 850, 133200, 15. 840, 64083, 15. 830, 36600, 15. 820, 84700, 15. 810, 36200, 15. 860, 256000 15. 870, 1405307, 15. 880, 51100, 15. 890, 166385, 15. 900, 2019-11-20,15:00:03, 00"
颐海国际股票交易数据:
import requests
r=requests. get("http://hq. sina js. cn/list=hk01579")
print (r. text)
var hq_str_hk01579="NULL,颐海国际,50.400, 50.400, 51.750,49.500, 5l.350,0.950, 1.885, 51.300, 51.350, 89306132, 1760506, 84.180, 0.000,56.050, 18.020,2019/11/20, 16:08"
海底捞股票交易数据:
import requests
r=requests. get ("http://hq. sina js. cn/list =hk06862")
print (r. text)
var hq_str_hk06862="NULL, 海底捞35.000, 35.000, 35.400, 34.850, 35.300, 0.300, 0.857, 35.200, 35.300, 89417573, 2541754, 93.634, 0.000, 39.000, 16. 420, 2019/11/20, 16:08"
玉米期货交易数据:
import requests
r=requests. get ("http://hq. sina js. cn/list=C0")
print(r. text)
var hq_str_C0="玉米连续,150040, 1857. 00,1857. 00,1844. 00, 1854. 00, 1845. 00. 1846 00, 1846. 00, 1848. 00, 1857. 00, 2316, 165, 1189024,473098,连,玉米,2019-11-20, 0, 1865. 000, 1833.000, 1868.000, 1833.000, 1895. 000, 1823. 000, 1901.000, 1810 000, 16.838"
白银期货交易数据:
import requests
r=requests. get("http://hq. sina js. cn/list=AG0")
print (r. text)
var hq_str_ AG0="白银连续, 145955, 4170. 00, 4192. 00, 4132. 00, 4185. 00, 4169. 00, 4170. 00, 4170. 00, 4165. 00, 4147. 00, 127, 7, 624046, 1391504, 滬,白银, 2019-11-20, 0, 4192. 000, 4091. 000, 4280. 000, 4036. 000, 4487. 000, 4036. 000, 4843. 000, 4036. 000, 78. 485 "
黄金期货交易数据:
mport requests
r=requests. get("http://hq. sina js. cn/list =AU0")
print(r. text)
var hq_ str_AU0="黄金连续,145954, 337.85,339. 55, 336. 70, 388.30, 339.15, 339. 40, 339.15, 0.00, 337. 75, 25, 6, 169804, 78028,沪,黄金, 2019-11-20,0, 339.550,334.600, 339.550, 327. 600, 347.750, 327. 600, 363. 850, 327. 600, 3.429"
三、API调用与网络爬虫对比分析
(一)关于API调用数据方法的分析
API调用数据方法的普及主要原因有:
API 提出了一种代码的编制复用机制,用户可以直接使用已有的API接口,复用他人编制出来的代码完成数据的调用。
API开发出一种信息隐藏的机制,用户在不知道具体细节的情况下,就可以完成相应的数据调用功能。
API 提供了访问某些数据资源的接口,用户通过这些API接口就能直接访问到想要的资源,不用进行接口的寻找,节省数据调用时间。
API调用数据支持多项目、多模块的数据调用,同时支持私有项目、公开项目、加密项目的数据调用。
API调用数据支持协同管理,支持添加项目成员,并且可精确控制每个成员的权限。
API接口支持普通接口、restfull、josn、xml等各种接口的数据的调用,接口返回数据也支持word、pdf格式下载,可单个下载也可按模块下载。
通过调用 API 接口可以实现股票/期货数据便捷高效的获取与解析。但所有的数据提供商都不会无条件无限制的提供给普通用户完整数据,例如在股票/期货数据获取过程中,有许多拥有重要查询功能的 API 是不提供给普通用户的,同时对于开放的 API,一次调用的返回结果数量有限制。同时因为 API 接口自身的复杂性以及数据本身的缺失和疏漏等原因,使用者经常会对API进行错误的使用,导致调用数据和现实不符合甚至出现重大误差。因此使用 API 调用数据的方法只能解决数据获取中的一部分问题。
(二)API調用数据与网络爬虫对比分析
爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序。
网络爬虫的基本原理:发起请求,使用http库向需要的数据所在的网站发起请求,即发送一个Request;获取响应内容,如果服务器能正常响应,则会得到一个返回数据;解析返回数据,通过第三方解析返回的数据,从中获取所需要的部分;保存数据。将提取的有用的数据保存到本地。
与基于API 的数据调用相比,基于网络爬虫的数据调用效率与性能有明显差距,同时网络爬虫调用数据还要解决网页的模拟登录问题,调用过程复杂。但是通过网络爬虫进行数据调用,能够解决用户反复调用API接口带来的数据量限制等问题,使能够调用的数据量明显增加,调用过程稳定。
但是在只需要部分特定的数据时,基于网络爬虫的数据调用方法速度较慢,在处理数量相同的信息时需要解决更多的问题,在数据的返回解析方面也更加复杂。而通过API调用数据可以一次性完成数据调用、返回、解析、存储,不需要像网络爬虫获取数据一样,一个一个页面解析提取的数据,同时API调用返回数据大小较小,速度快使调用更有效率。
四、对数据调用方法的思考
API 调用数据的抓取方式效率高,但因为服务器限制,不能获得完整数据集,而基于网络爬虫的数据获取方案可以获得较大的数据,但无法一次性抓取用户想要的数据,获取效率比较低。所以需要将两者结合起来,以实现最佳数据抓取获取效果。
首先,计算需要抓取的数据大小,如果需要获取的数据量小于用户使用的API接口规定访问的最大限制次数,则自动调用API接口获取数据。反之就使用网络爬虫获取用户所需要的数据。如果在使用API接口的过程中,累计数据量超过了接口所允许的最大访问次数,这时也可以自动转换为网络爬虫获取剩下部分的数据。获取完整数据后将数据放入一个数据库中,数据库自动检测对比数据的真实准确性,从而输出用户所需要的数据。
五、结语
本文主要介绍一种基于API接口获取股票/期货数据的方法,将其与传统网络爬虫获取数据方法进行对比。提出两者相结合的方法,一方面弥补了API调用数据的调用次数限制问题,另一方面解决了网络爬虫调用数据需要模拟登陆和大量的页面解析的问题。结合两者优点提高调用效率保证数据的准确性与完整性,但是从大数据的发展角度出发,在不考虑API访问次数限制的情况下,基于API的数据获取方法在获取效率方面还有很大的发展空间,之后的研究可以从如何降低API接口的限制访问次数入手提出更加符合要求方便快捷的数据获取方法。
参考文献:
[1]廉捷,周欣,曹伟,刘云.新浪微博数据挖掘方案[J].清华大学学报(自然科学版),2011,51(10):1300-1305.
[2]冰雨梦.软件接口的历史和未来[J]. 中文信息:程序春秋,2002(06):18-19.
[3]李正,吴敬征,李明树.API使用的关键问题研究[J].软件学报,2018,29(06):1716-1738.
[4]赵前东,叶猛.微博热点话题检测系统的设计与实现[J].电视技术,2013(03):211-214.
[5]王佳秋.基于用户行为及关系的微博电商企业影响力度量[D].哈尔滨:哈尔滨商业大学,2013.
[6]徐雁飞,刘渊,吴文鹏.社交网络数据采集技术研究与应用[J].计算机科学,2017(01):277-282.
[7]石磊.新浪API与网络爬虫结合获取数据的研究与应用[J].中国电子商务,2013(22):58-59.
[8]李良.基于Python的测井数据校验对比[J].信息系统工程,2014(06):142.
[9]余斌.基于Bottle的Python网络应用开发[J].无线互联科技,2014(06):29+103.
[10]刘海房,莫世鸿,龚振,范冰冰.面向API调用的开放数据存储管理研究[J].计算机应用与软件,2018,35(08):93-97.
(作者单位:昆明理工大学公共安全与应急管理学院)
猜你喜欢
电脑知识与技术(2017年1期)2017-03-24
电脑知识与技术(2017年1期)2017-03-24
计算机时代(2017年2期)2017-03-06
中国新技术新产品(2017年4期)2017-03-04
中国新通信(2016年21期)2017-01-06
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年17期)2016-07-23
中国市场(2016年23期)2016-07-05
科技经济市场(2016年2期)2016-06-16
电脑知识与技术(2016年7期)2016-05-19
