
基于QtOpenGL的大容量图形渲染性能优化研究
2021-11-20 00:32靳慧亮张波
计算机时代 2021年11期
关键词:性能优化
靳慧亮 张波


DOI:10.16644/j.cnki.cn33-1094/tp.2021.11.001
摘 要: 随着国产计算机的推广应用,原X86平台开发的软件经常面临国产化平台适配的需求,且要求适配后的功能、性能不降低。以大批量实时图像渲染类的应用为例,性能问题是国产化平台适配时经常遇到的难题。文章以主流的国产软硬件平台为研究基准,以对比实验形式论证了基于QtOpenGL的实时渲染软件国产化适配性能优化的关键技术点及解决方法。提出了六条切实可行的显示性能优化技术途径,这些成果对于基于QtOpenGL的国产平台显示性能的优化工作有借鉴意义。
关键词: Qt; OpenGL; 国产计算机; 性能优化
中图分类号:TP311.1 文献标识码:A 文章编号:1006-8228(2021)11-01-04
Research on performance optimization for large amount graph rendering with QtOpenGL
Jin Huiliang, Zhang Bo
(China Academy of Electronic and Information Technologies, Beijing 100041, China)
Abstract: ChinaProduced computer and operation systems are gradually applied for critical equipment, meanwhile the software for these platforms is progressing rapidly. Software performance is one of the major issues while migrating software from X86 platform to ChinaProduced platforms, especially the rendering of large amount real time graphs. Taking the mainstream domestic software and hardware platforms as the research benchmark, this paper demonstrates the key technical points and solutions for performance optimization of QtOpenGL based real-time rendering software on ChinaProduced platforms in the form of comparative experiments. Six feasible technical approaches for display performance optimization are proposed, these results can be used as a reference for the optimization of QtOpenGL based display performance of ChinaProduced platforms.
Key words: QtOpenGL; ChinaProduced computer; performance optimization
0 引言
當前国产计算机在政府、企事业单位、关键型号装备等领域应用越来越广泛,主流的国产CPU处理器也达到16核心以上,并发能力更强,可以支持更多高性能的应用。在装备领域,具有人机显示界面的软件是最常见的应用场景之一[1],该类软件对计算机实时图形显示能力的要求很高。图形显示作为典型的性能密集型应用,图像渲染性能的高低能够表现计算机硬件和软件的综合效能。在硬件配置相对固定的条件下,软件层面的性能优化就起到了决定性的作用。本文从OpenGL渲染入手,用对比实验的方式,论证了国产计算机平台软件显示性能的优化技术方法。
1 国产平台介绍
按照CPU分类,当前主流的国产计算机主要有以下三类。①飞腾处理器系列CPU国产计算机,飞腾处理器是由国防科技大学研发,兼容2011年发布的ArmV8指令集,典型型号为飞腾1500A,具有16核心,主频2GHz[2]。②龙芯CPU国产计算机,龙芯处理器是由中科院计算所研发,采用MIPS指令集,典型型号为龙芯3A3000四核64位通用处理器,主频1.5GHz[3]。③申威CPU国产计算机,申威处理器是由上海高性能集成电路设计中心研发,采用自主设计的指令集,申威1621单芯片中包含16核64位处理器,主频2GHz[4]。上述三类国产CPU平台在国产计算机领域占了很大份额,并都形成了各自的应用生态。尽管是基于不同的CPU指令集,但在图形渲染方面,通常采用OpenGL技术作为底层图形库通用技术方案。
2 OpenGL渲染管线
OpenGL是跨平台计算机图形应用程序的应用规范,广泛应用于仿真、游戏、GIS系统等领域,实现二三维图形的渲染。OpenGL渲染过程需要经历CPU、GPU两个阶段,CPU中进行图形计算,完成之后调用OpenGL开发接口在GPU中创建缓存区缓存绘制数据,将生成的几何数据(顶点坐标、几何单元等)输入到一系列着色器中进行处理。着色器(Shaders)是一段用着色器语言GLSL编写的脚本,在OpenGL渲染过程中通常依次经过顶点着色、细分着色以及几何着色阶段,然后对数据进行光栅化处理,生成片元数据,最后经过片元着色,将图形渲染到屏幕上[5]。OpenGL的可编程管线着色器能直接对GPU的数据缓存进行操作,渲染效率高, 在X86商用计算机上帧率通常能达到60FPS以上。
OpenGL的完整渲染过程如图1所示,客户端运行于CPU中,通过驱动程序将数据与渲染指令进行连接,并发送到服务端执行。服务端和客户端为异步调用,因此两端都能够不间断的工作。客户端计算完毕后,将计算结果和命令块组合在一起送入缓冲区,然后缓冲区会发送到服务端执行。服务端执行缓冲区内容的同时,客户端已经在进行下一个周期的计算,如此循环实现计算和图形资源的最大化利用。
由于国产GPU当前尚未大规模应用,国产计算机通常采用国产CPU加商用GPU的整机方案。本文作者在进行国产计算机平台的软件适配时,同样的图形渲染软件在国产计算机上无法达到商用机帧率,甚至在绘制批量大时会低于10FPS,即一个周期的图形刷新时间大于100毫秒,人在交互时会感到明显的操作卡滞和视觉延迟[6],因此需要有针对性地优化国产机软件显示性能。本文设计了五组对比试验,探讨国产计算机平台OpenGL渲染性能进行优化的技术途径。由于原生OpenGL没有提供窗口系统和用户交互的函数,本文使用跨平台软件框架Qt作为支持OpenGL的窗口和交互系统开发环境。
实验采用的硬件配置为:飞腾1500A型16核心处理器,32G内存,AMD Radeon HD7470显卡。OpenGL核心版本为3.3,mesa版本为11.2.0,采用Qt5.9.2作为界面开发环境。
3 性能优化实验设计
针对OpenGL典型渲染流程中数据存储、数据计算、数据提交等阶段,结合笔者工作中对OpenGL显示软件的优化经验,提炼出以下五种典型的可能出现性能问题的关键环节。并设计对比实验。实验采用Qt提供的计时器类QTime作为基准,计算任务开始到任务结束经过的时间,作为度量计算性能的依据。时间单位为毫秒,耗时越短,说明性能越高, 最终软件显示的帧率越高,操作越流畅。
3.1 数据存储性能
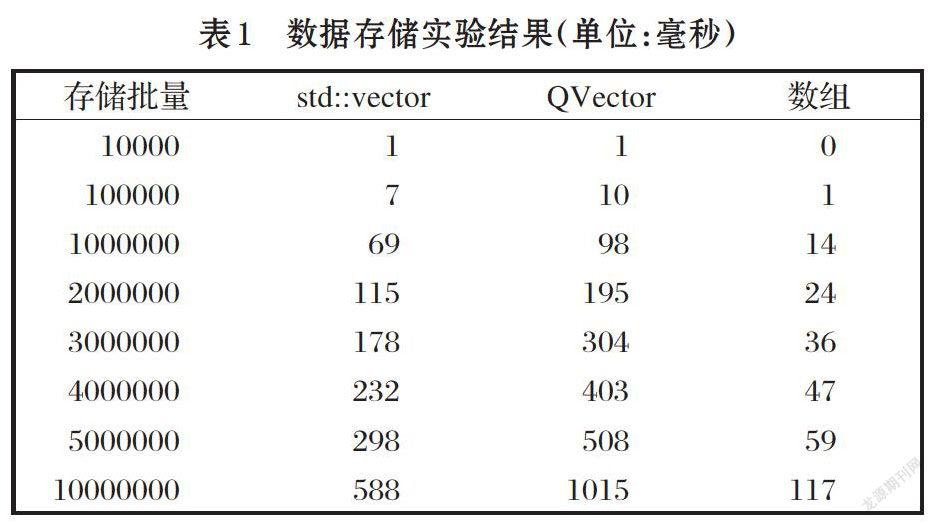
OpenGL客户端在进行顶点坐标、纹理坐标、颜色矩阵计算前,首先要将渲染对象的原始坐标存储到内存中。比如要在屏幕上绘制一些点,要先将绘制点的原始坐标存储到内存,数据存储就需要用到软件容器,如Qt提供的QVector容器和C++标准库std::vector容器。QVector在内存中连续存储数据,支持按序号快速查找,而std::vector的内部结构更为简单。此外,在数据长度相对确定时,也可以使用满足最大数据存储的数组保存坐标对象。本实验采用上述三种典型的数据容器,依次插入float类型数据,并比较三类容器数据存储的时间。实验结果见表1和图2。
从实验结果可以看出,小于100万次写入时,std::vector和QVector的性能相当,在100万次以上,QVector的耗时几乎是std::vector的两倍。而同样次数的写入,使用数组存储的速度是std::vector的五倍,是QVector的将近十倍。这是由于QVector初始化时会预先分配两倍于实际需要数据的空间大小[7],如果数据超出预先分配的空间,QVector会重新分配整个内存空间,导致耗时增大。因此,在数据量较为确定时,使用预先分配空间的数组能大大缩短OpenGL的数据存储时间,进而缩短整体的图形渲染时间。
3.2 数据计算性能
OpenGL计算顶点坐标、纹理坐标等的过程可以抽象为矩阵的平移、缩放、旋转。重新设计算法,将串行的计算过程并行化后,也能提升计算性能。本实验对比了采用单线程计算和多线程计算时,分别需要的计算时间。计算过程基于3.1中存储的float数据,对数据逐一进行一次乘法(旋转)和一次加法(平移)。多线程采用了Qt的并行计算框架QtConCurrent,使用该框架可以不用考虑线程锁的问题,并且QtConcurrent会根据可用CPU核数自动调整线程数。
实验结果见表2。从实验可以看出,在10万次计算以下时,多线程耗时要高于单线程,并且次数越少,多线程相对单线程耗时越大。在10万次计算以上时,多线程计算的优势更加明显(100万次三倍,1000万次六倍),实验结果证明,大批量计算时多线程能成倍缩短计算时间。但在计算次数较少时,多线程的上下文切换耗时可能会高于多线程计算节省的时间,导致了多线程的耗时反而高过单线程[8]。批量切换的性能门限,与计算机配置、程序算法设计有直接关系,需要根据实际情况进行摸底测试确定。
3.3 数据遍历性能
在渲染数据计算时,由于绘制对象的不同,会产生一些大小不确定的中间数据,由于数据量大小未知,无法使用预先分配的數组存储,只能采用标准的数据容器。而对这些数据的遍历时间也会对整体渲染时间产生影响。本文选取了三类Qt标准容器(QVector,QList和QLinkedList),对比数据遍历性能。QVector存储时占用连续存储的内存空间,而QList的数据存储在堆上。QLinkedList是链表存储,使用迭代器而不是索引进行遍历。实验结果见表3,实验证明,在三类容器中,QVector的顺序遍历速度在三类容器中最优,但结果差距不明显,结果与Qt官方推荐的结果一致。
3.4 数据绘点性能
点绘制是雷达等传感器应用的典型场景[9],本实验对OpenGL的点绘制性能进行对比。OpenGL绘制管线中,提供了单点单次提交绘制的形式glVertex,和坐标缓存批量提交绘制方式glDrawArrays,本实验对比了在不同点批量的情况下,采用单次和批量提交时绘制时间的差别,实验结果见表4和图3。
结果证明在50万点以下,两种点绘制方式的时间相差不大,在50万点以上,批量绘制点的时间明显要短于单次提交。因为在大批量绘制时,采用批量提交的形式能减少CPU到GPU的数据提交次数,成倍提升绘制速度。
3.5 调试打印
软件人员在调试阶段会在代码中增加打印调试信息,如果软件发布后没有将打印删除,频繁的打印会严重拖慢性能,而打印耗时却容易被忽视。本实验在3.2节计算处理基础上,在每次计算时使用qDebug打印计算结果。对比在单线程和多线程情况下,需要的处理时间,实验结果见表5。对比表5和表2可见,从10000次开始,单线程增加打印的时间已经是无打印计算的80倍,随着计算次数的增加,这种差距不断扩大。而在多线程计算时,打印耗时抵消了多线程计算缩短的时间。在1000万次计算时,单线程和多线程的耗时均已经超过了8分钟,单线程下增加打印的耗时达到无打印耗时的400倍,多线程达2400倍。实验证明,在开发那些对时间性能要求高的软件时,必须避免频繁打印,从而提升软件的性能。
4 结论
在OpenGL图形渲染过程中,CPU客户端的计算时间在整体渲染时间中占比很高。在国产化适配时,降低CPU端的计算时间,就能够显著缩短整体的渲染用时。可以从如下六个方面做CPU端性能优化:
⑴ 在数据批量可预测的情况下,采用预先分配的数组进行数据存储,提升数据存储效率;
⑵ 采用多线程并行计算,降低图形坐标计算时间,充分利用国产处理器的多核性能;
⑶ 采用性能最高的数据容器,缩短大批量数据遍历的耗时,并且避免频繁的随机查找数据;
⑷ 去掉减少代码中的无效打印,减少由于打印带来的CPU时间损耗;
⑸在图形渲染阶段,采用OpenGL批量绘制方式提交,加快渲染速度。
此外,在OpenGL绘制时,可以根据渲染类型或者频次的差别,应用分层渲染的方式,将高频渲染和低频渲染元素放在不同的图层中处理,以降低性能负载。
参考文献(References):
[1] 赵星汉,于洋.基于自主可控计算平台的信号采集处理系统
设计与实现[J].中国电子科学研究院学报,2013.1:100-105
[2] 孙立明,吴庆波.国产飞腾1500A處理器的显存管理优化[J].
计算机技术与发展,2017.27(5):6-9
[3] 孟小甫,高翔,从明,张爽爽.龙芯3A多核处理器系统级性能
优化与分析[J].计算机研究与发展,2012.49(S1):137-142
[4] 胡向东,杨剑新,朱英.高性能多核处理器申威1600[J].中国
科学:信息科学,2015.45:513-522
[5] Dave Shreiner等.OpenGL编程指南[M].机械工业出版社,
2016.
[6] A. B. Watson, "High Frame Rates and Human Vision: A
View through the Window of Visibility," in SMPTE Motion Imaging Journal[J].2013.122(2):18-32
[7] Marc Mutz, Understand the Qt Containers[], https://www.
cleanqt.io/blog/exploring-qt-containers, 2018.
[8] Jonas Trümper,Johannes Bohnet,Jürgen D?llner.
Understanding complex multithreaded software systems by using trace visualization[P].Software visualization,2010.
[9] 吉军.雷达点迹的目标智能特征提取方法研究[J].信息技术,
2013.6.
猜你喜欢
电脑知识与技术(2016年31期)2017-02-27
无线互联科技(2016年14期)2017-02-06
中国新通信(2016年22期)2017-01-13
电子技术与软件工程(2016年20期)2016-12-21
电脑知识与技术(2016年10期)2016-06-16
科技视界(2016年1期)2016-03-30
无线互联科技(2015年20期)2016-03-05
科技资讯(2015年7期)2015-07-02
电子技术与软件工程(2015年6期)2015-04-20
