
基于图卷积网络的重大事件趋势预测
2021-11-20 01:57:10耿小航彭冬亮
计算机工程与设计 2021年11期
耿小航,彭冬亮,张 震,谷 雨
(杭州电子科技大学 通信信息传输与融合技术国防重点学科实验室,浙江 杭州 310018)
0 引 言
在国际政治关系研究领域,重大事件一般指对国家或地区间会产生重大影响的一类事件,如:朝鲜核行为[1]、中东恐袭等。重大事件趋势预测将事件发展趋势划分为不同等级,利用已发生事件预测未来趋势等级[2],目前主要研究方法可分为基于事件数据分析法的定量分析和基于机器学习分类的方法两类[3,4]。
利用事件数据分析法进行重大事件趋势预测主要包括确定信息来源、确立编码体系并赋值、统计分析[5]4个主要步骤,这种方法预测的可解释性强,但依赖专家知识构建领域专题数据及特征指标量化,同时存在特征维度有限、时效性较弱等问题[5]。文献[6]搜集了2006年至2018年间朝鲜官方媒体所有关于其核行为的报道,借鉴专家知识确定特征集,运用相关性分析和Probit回归方法选择了朝核问题相关最优特征指标集,采用朴素贝叶斯建立关于朝鲜核行为的趋势预测模型。
随着自然语言处理、深度学习和大数据处理等相关技术的发展[7],使得基于海量公开新闻数据进行特征学习,自动化构建重大事件趋势预测模型成为可能。本课题组在这方面开展了初步研究,目前主要集中在特征的构建和优化方面。文献[8]提出了一种结合逆文档频率(inverse document frequency,IDF)和隐狄利克雷分布[9,10](latent Dirichlet allocation,LDA)的特征抽取方法,为与文献[6]进行对比分析,同样采用朴素贝叶斯分类器进行趋势预测,实验结果表明,基于主题模型[11]抽取出的特征与基于专家经验确定的特征预测精度相当,验证了基于公开新闻数据进行特征学习的可行性。文献[12]针对LDA算法中主题词个数需要人工确定的问题,首先通过融合单词贡献度提高抽取的主题词的判别性,然后采用层次聚类方法对主题词分布数目进行优化,采用多项式逻辑回归模型作为分类器,提高了重大事件趋势预测精度。上述方法采用的主题词分布[13]特征仅考虑了词频特征,通过事件抽取技术[14]对新闻报道进行解析,获取各事件的发起者、承受者和事件类型等核心要素,能够有助于趋势预测模型的构建。文献[15]利用事件类型频次信息构建了语义与事件融合的特征,这种融合事件特征的方法已经尝试利用事件数据来提升文档语义理解程度,在统计事件类型频次信息时,对发起者和承受者进行约束,但仅考虑到高频事件的频次信息,并未充分利用事件信息数据,割裂了词汇间或事件属性间的关联,仍然存在对文档特征语义理解不足的问题,因此,需要考虑以新的形式组织利用事件信息数据,丰富特征中的文档事件语义关联信息。
受知识图谱[16,17]以图的形式组织概念知识的启发,将事件的多维度要素信息图谱化有助于更好地理解新闻文本传递的语义信息,把握事件发展的趋势。事件信息建模为图数据后,需要将其进行特征表示以辅助重大事件趋势预测,考虑图这一非结构化数据的特殊性,采用针对图的卷积网络能够提取事件信息关联的多维特征。图卷积网络[18](graph convolution network,GCN)由Kipf等提出,在半监督的节点分类任务上取得了较好的效果。图卷积网络当前在推荐系统领域应用较广,Pinterest公司和斯坦福大学的研究人员将图卷积网络应用于在线网站图片推荐[19]。也有学者将图卷积网络应用于文本分类[20],利用文档与词的共现关系建图,并构建文本图卷积网络,取得了优于传统卷积网络的结果。
针对文献[15]在特征选择时依赖关键词与事件类型频次,忽略了词汇间的关联信息,造成文档所传递语义丢失的问题,本文基于结构化事件信息数据,构建了以事件为中心的事件语义关联图(event semantic association graph,ESAG);然后在从事件语义关联图中分割出局部图,利用图卷积网络聚合局部图的节点特征并读出图特征,最终对局部图的趋势等级分类。采用图卷积网络构建的趋势预测模型,由于充分利用了事件要素的语义关联信息,故能够提高趋势预测的精度。采用朝鲜核行为等级作为预测目标,验证了提出方法的有效性。
1 问题描述与方法流程
与当前国际政治关系领域的重大事件趋势预测方法[6,8,12,15]一致,本文将重大事件趋势预测定义为趋势等级分类问题,提出了基于图卷积网络的重大事件趋势预测方法,整体流程如图1所示。首先将事件数据集根据事件要素的重叠建立事件语义关联图;由于全时间段关联网络巨大,且事件趋势等级与事件语义关联图是局部相关的,因此采用分而治之的思想将事件语义关联图切分为等时间区间的局部图;对于非结构化的图,采用图卷积网络聚合局部图中的节点关联信息,读出图特征输入分类器,预测趋势等级。
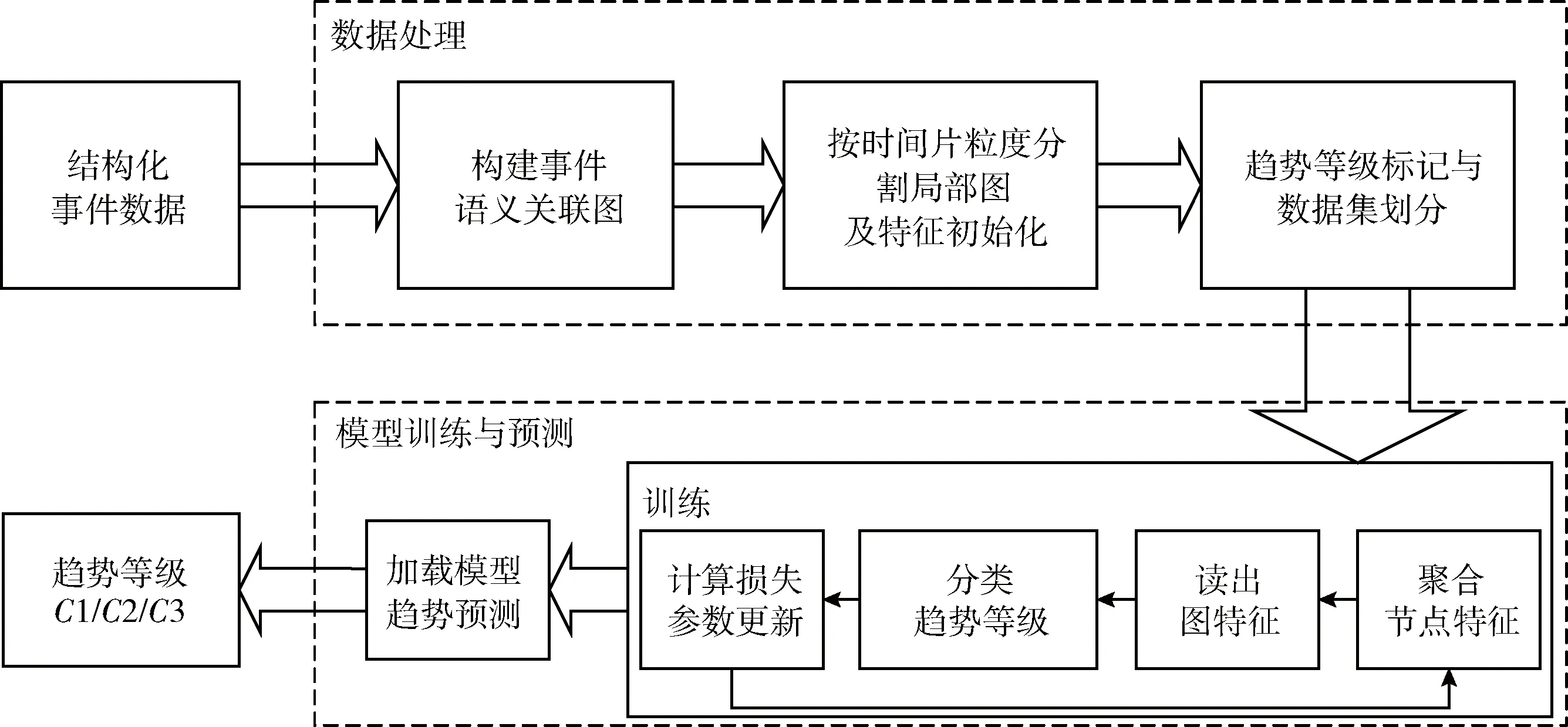
图1 基于图卷积网络的重大事件趋势预测流程
基于图卷积网络的重大事件趋势预测方法主要分为以下两个模块。
数据处理模块,主要实现以下功能:
(1)从关系型数据库读取结构化事件信息数据,生成全局事件语义关联图并存入图数据库;
(2)选择时间片粒度分割出局部图,利用预训练词向量初始化节点特征;
(3)为每一张局部图标记趋势等级,划分训练集与测试集。
模型训练与预测模块,主要实现以下功能:
(1)按批次分别输入多张事件语义关联图,聚合节点特征;
(2)对聚合后的所有节点特征取均值读出局部图特征表示;
(3)将图特征表示输入分类器,分类趋势等级;
(4)计算损失并更新参数,训练趋势预测模型;
(5)加载训练好的模型,输入测试集局部图,预测趋势等级。
2 基于图卷积网络的事件趋势预测模型构建
2.1 事件语义关联图构建
利用基于模式匹配的事件抽取技术抽取出事件描述、时间、地点、参与者、事件类型等结构化的事件信息数据。将原始单篇新闻文档解析为多条事件数据,为事件语义关联图中的节点服务。
受制于中文的事件及事件间关系的标注语料匮乏、标注体系不统一,目前,难以准确识别事件间直接关系。本文所构建的事件语义关联图侧重于事件属性关联,即事件间通过共有事件属性(如:时间、地点、发起者、承受者等)相关联。节点类型有事件句、时间、地点、参与者、事件类型、事件所属领域、事件来源7种,边的类型有时间、地点、发起、承受、事件类型、领域、来源7种。事件语义关联图示例如图2所示。
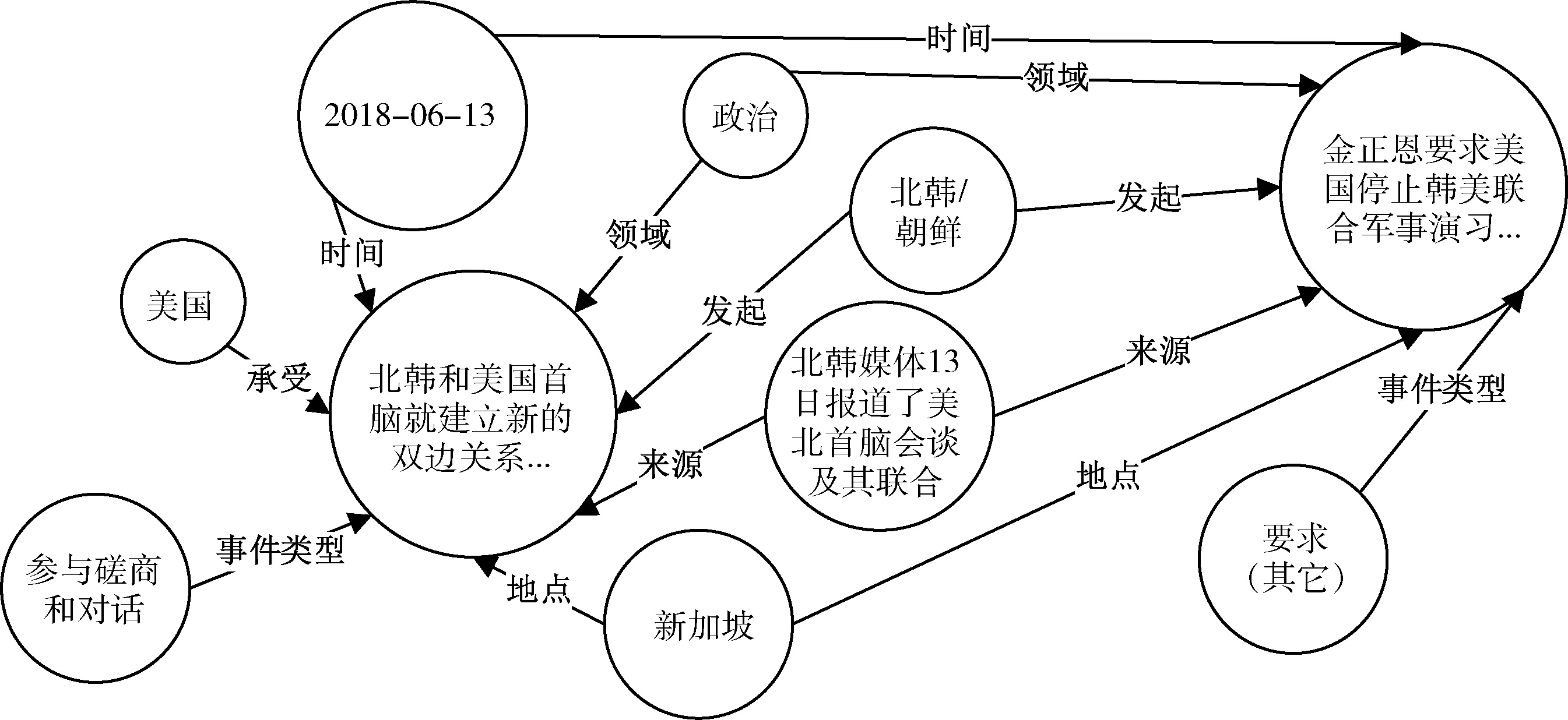
图2 事件语义关联图示例
事件语义关联图中的中心节点为事件描述,其直接关联的节点为事件属性,由重叠的事件属性扩展链路关联到其它事件。例如,北韩媒体报道了美北首脑2018年6月12日会谈及其联合声明的内容。从原始新闻报道中抽取出两条事件数据,两事件共有的事件属性有新闻来源、时间、地点、发起者、事件所属领域,进而将两事件通过共有属性间接关联起来。
图的存储过程如下:从事件数据库中逐条读数据,字段名对应节点类型、字段值对应节点,以事件句为核心节点、事件属性为从节点建立关联,存储到Neo4 J图数据库中;在每次存入新的节点数据,查询节点是否已存在,若已存在,则不重复在图数据库中存储节点,进而拥有相同事件属性的事件建立起了间接关联。将事件数据库中所有数据经过上述处理过程后,事件语义关联图构建完成,可对事件语义关联图进行检索及进一步利用。
2.2 局部图分割与节点特征初始化
本文所研究的面向国际政治领域的重大事件趋势一般以月为单位进行预测,按2.1节方法构建的事件语义关联图是包含整个时间段的,而某一阶段的重大事件趋势仅与前一个月或几个月发生的事件有关;因此,需要按时间片从事件语义关联图中分割出局部图作为当前阶段的特征图gt={VT,ET,T∈[t-n,t-1]}, 其中,t属于事件数据集中某一月,n表示时间片粒度,T表示时间片,V表示节点集,E表示边集。以预测2018年3月趋势等级为例,假设时间片粒度n为2,即从事件语义关联图中检索出事件时间属性在2018年1至2018年2月间的所有节点及边,生成局部事件语义关联图(local-event semantic association graph,L-ESAG)。
图中节点均为中文描述,事件描述节点一般为长句,取分词后的文本词向量均值,其余直接成词的属性节点直接获取词向量,未登陆词用零向量代替。采用涵盖八百万词汇的腾讯预训练词向量将图中的文本节点特征向量化表示vi=[0.001,0.365,0.128,…], 为后续模型输入服务。若两节点间存在边,则将邻接关系矩阵相应位置置1,否则置0,局部图分割与节点特征初始化如图3所示。
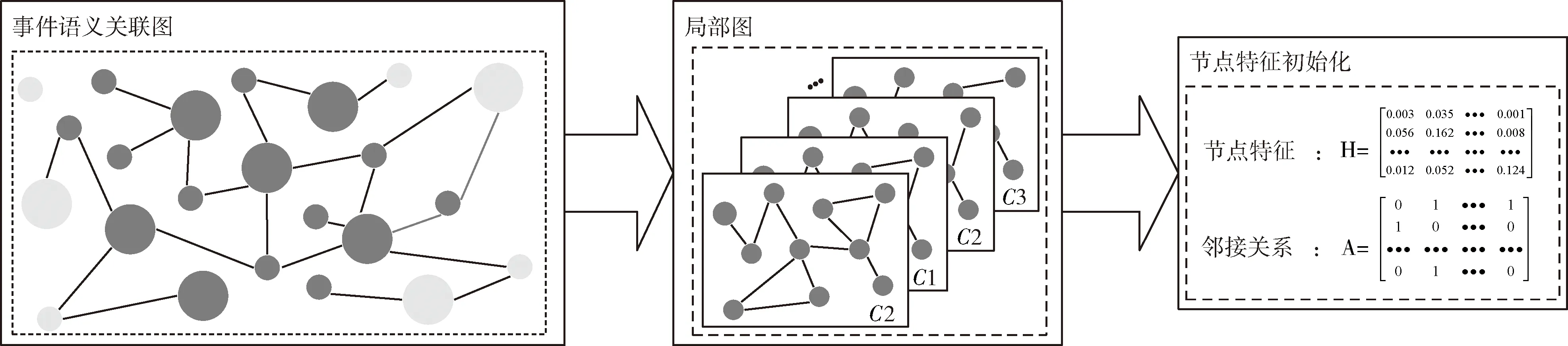
图3 局部图分割与节点特征初始化
2.3 基于GCN的趋势预测模型
区别于以往预测方法输入的结构化特征向量,本文趋势预测模型输入为非结构化的图,传统的深度卷积网络可以对结构化数据(图像、语音、序列等)进行特征提取,但图数据具有非结构化、无序、随机的特点,本文构建的L-ESAG节点及关系数不是固定的,表达形式更灵活,无法将其对齐成固定尺度的特征矩阵,利用传统卷积网络进行特征提取,因此,需要采用针对图的卷积网络,图卷积网络在捕获特征时不受限于二维结构上的依赖关系,能够聚合更丰富的关联节点信息。本文结合图卷积网络,构建了基于GCN的趋势预测模型。将重大事件趋势预测转化为分类问题,模型输入为局部事件语义关联图,输出为趋势等级。
基于GCN的趋势预测模型构建过程如下:首先,选择时间片粒度n, 即利用前n个月的事件数据生成L-ESAG,预测当前月趋势值;其次,将训练集中多组L-ESAG输入到图卷积网络并选择卷积层数,利用图卷积网络聚合节点领域信息,不断迭代更新节点特征,每张图中节点数不一,对图中所有节点特征读出后取平均得到图的特征表示;再次,将图的表示输入分类器,分类器对图的表示做线性变换后计算每类的概率,训练过程采用反向传播和梯度下降更新权重参数;最后,将测试集的事件语义关联图输入训练好的模型进行分类并输出预测结果。
定义一个时间片粒度为n的L-ESAG为无向图G=(V,E), 其中,每个节点vi∈V, 每条边(vi,vj)∈E。 在GCN中,定义每个节点的隐藏状态为hi, 每个节点的邻居集合为N(vi)。 对于图中的每个节点v, 它的信息传播公式如式(1)所示。图卷积的目的是聚合邻居节点的属性特征,得到节点在图中的表示
(1)
式中:h为节点特征,N为节点集合,l表示GCN层的数量,w(l)表示l层上共享的可学习的权重向量,b为偏置项,Relu为线性激活函数。
通过图卷积网络得到的是每个节点的特征表示,而最终的任务是对图进行分类,本文对单个图经过图卷积后需要读出图的表示,通常L-ESAG中节点数是不一致的,本文对所有经过信息聚合后的节点取平均读出图特征,如式(2)所示
(2)
式中:hg为图特征表示向量, |N(v)| 为节点数目。
再将读出的图特征表示经过全连接层线性变换再输入softmax层进行多分类,如式(3)所示
(3)
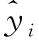
训练时采用交叉熵损失函数,如式(4)所示
(4)

以图卷积层数l=2为例,单张局部事件语义关联图的分类过程如图4所示。
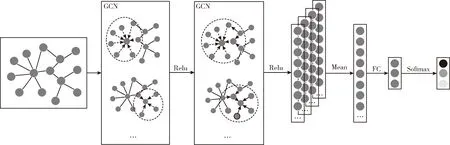
图4 局部事件语义关联图分类过程
分类过程具体步骤如下:
(1)将带有节点属性的局部事件语义关联图输入第一层图卷积网络,聚合事件一阶自相关属性节点信息;
(2)为聚合事件间的关联特征,将第一层图卷积的结果输入到第二层图卷积网络中,聚合二阶节点信息;
(3)获取经过最后一层图卷积后的每个节点表示,对所有节点特征取平均获得图的特征表示;
(4)对图的表示做线性变换,得到为归一化前每一类的概率;
(5)经过softmax计算每一类的概率,并用交叉熵计算损失;
(6)训练过程采用反向传播和梯度下降更新权重参数。
3 实验结果分析
3.1 朝鲜核行为趋势预测实验
为验证本文提出预测方法的有效性,也为了与基于专家知识和自动提取关键词特征的预测方法进行对比。本文对朝鲜核行为趋势进行预测研究,鉴于该研究问题的敏感性,国内新闻网站报道较少,本文数据源选择韩国国际广播电台北韩专题页,爬取了该网站2006年1月至2018年3月间的4774条原始新闻报道。根据文献[6]专家知识在朝核问题上的分析结果确定如表1所示的事件趋势量化标准。

表1 事件趋势量化标准
结合趋势量化公式与原始新闻报道,对各月的朝核行为趋势进行量化打分。例如2006年10月所有新闻报道中,朝鲜于10月9日进行了一次核实验,对照量化标准,2006年10月的朝鲜核行为趋势值为15。进一步,对各月下量化的趋势值进行离散化表示,与文献[6]及文献[15]保持一致,本文将朝核行为分值由0至15划分成3类趋势等级:0为无核行为(C1)、1-14为轻度核行为(C2)、≥15为重度核行为(C3)。
本文针对朝鲜核行为问题验证所提出趋势预测方法的有效性,该问题背景属于军事政治领域,为保证事件抽取的准确性,在确定领域内,一般采用基于模式匹配的事件抽取技术对原始非结构化文本数据进行事件抽取。由领域专家确定事件类型、制定事件描述模板,根据专家制定的模式抽取,得到结构化的事件信息数据,抽取后的事件信息数据见表2。

表2 事件信息数据示例
对结构化的事件信息数据,采用2.2节的方法取时间片粒度n个月范围内的局部事件语义关联图,每批次训练样本为12个带有节点特征的图,标签为相应的趋势等级,将训练数据输入图卷积网络提取图特征,再输入分类器分类,并计算损失,利用反向传播更新权重值,得到训练好的分类模型后,对测试集和全时间段数据进行测试并输出结果。
3.2 预测结果分析
与文献[6]一致,选择2006年4月至2017年2月间数据进行训练,选择不同时间片粒度进行训练并测试,例如时间片粒度n为1,则将前一个月的局部事件语义关联图输入图卷积网络提取特征,实验共测试了时间片粒度n从1到6变化对预测结果的影响;同时考虑了卷积层数的影响,共对比了卷积层数从1到3准确率变化情况。测试集(2017年3月至2018年3月)以及全时间段(2006年4月至2018年3月)测试结果的准确率(accuracy)及召回率(recall)对比如图5所示。
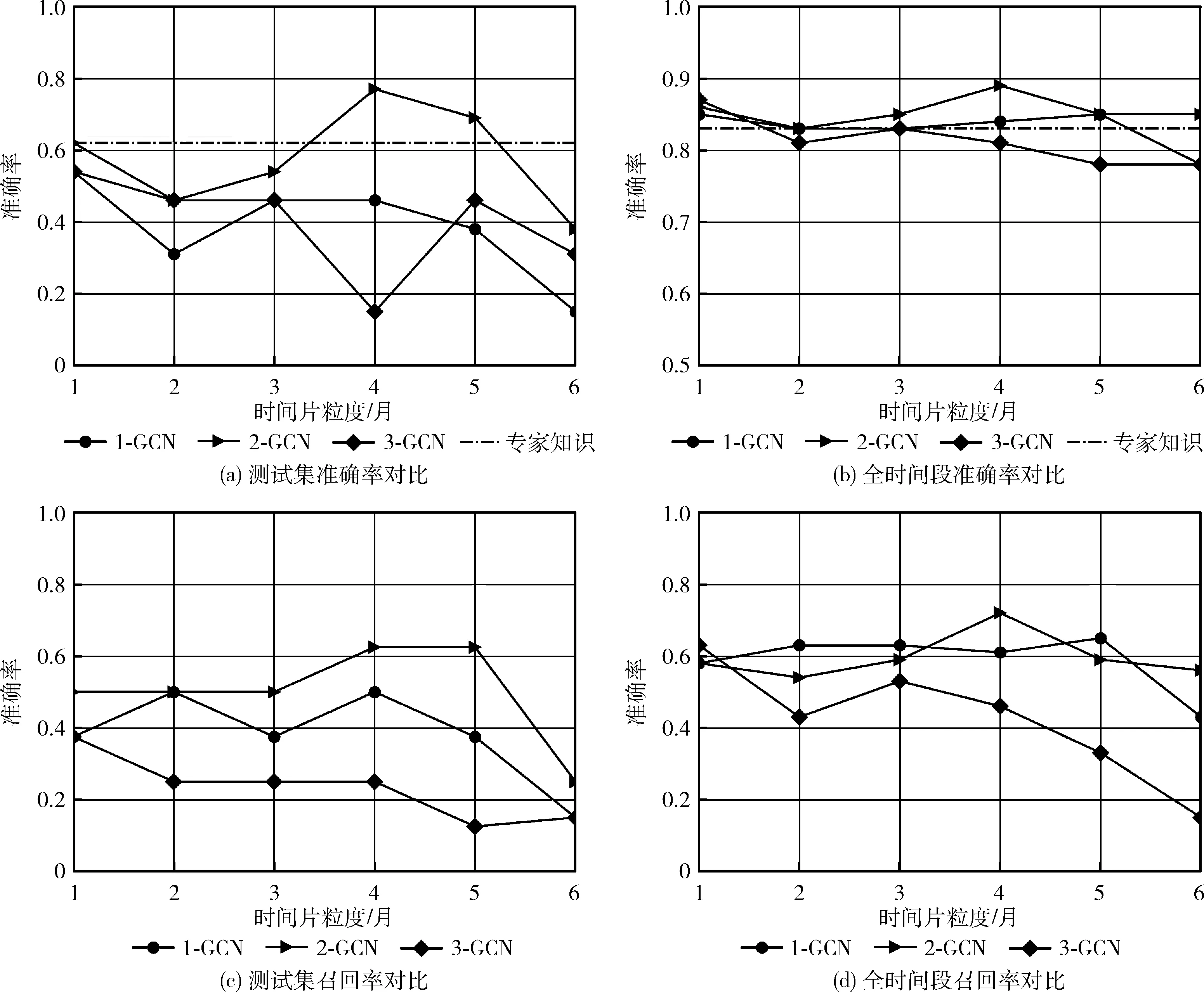
图5 不同偏移量及不同卷积层数下预测结果对比
根据多组实验,在时间片粒度n为4个月,卷积层数l为2时,预测效果最佳。首先,考虑时间片粒度对预测结果的影响,由图5可以看出,当n为1时,即以前一个月数据预测当前月趋势等级时,预测结果准确率与专家知识基本相当,随着n的增加,准确率出现局部下降之后又反弹,在n为4时达到了最高点,之后在n增加到5至6后,呈现下降趋势。究其原因,新闻的报道存在一定的滞后性,且针对朝核问题的相关报道尤为稀疏,因此在随着时间片粒度的增加,局部事件语义关联图中囊括了更多的事件信息,预测准确率也随之上升;但并不是事件知识包含的越多越好,在局部事件语义关联图扩展到5至6个月时,会出现事件冗余,相应的准确率也随之下降。
另一方面,考虑到图卷积层数l对预测结果的影响,将卷积层数l设置了1至3进行对比,从预测结果来看,当l为2时,在测试集与全时间段的预测准确率上均优于l为1和3。当l为1时,图特征聚集了节点的1阶邻域信息,即事件与事件属性间的关联信息;当l为2时,可以聚集节点的2邻域信息,即可关联事件—事件属性—事件间的信息,从而获得事件与事件间的关联;当l增加到3时,图中节点会进行三重关联,即关联事件属性间的关联,此时可能产生部分冗余特征。
本文预测方法测试集准确率为76.92%、召回率为62.50%,全时间段准确率为89.58%、召回率为71.74%均高于文献[6]基于专家知识的传统方法、基于改进主题模型HC-TC-LDA[12]、IDFLDA-EVENT[15]两种自动选取特征词的方法,验证了本文所提预测方法的有效性,预测结果准确率对比见表3。与文献[6]预测结果对比见表4,以2018年3月数据为例,预测出C1的概率为0.9202,C2的概率为0.0377,C3的概率为0.0421,概率最大值对应的标签即为当月趋势等级,则预测该月趋势为无核行为发生,与实际情况相符。

表3 预测结果准确率对比/%
由表4可以看出,本文方法预测结果的提升主要是由于虚警的降低,即无核行为C1等级未出现误判,全部预测正确。基于主题词特征提取的方法在核行为趋势等级较低的月份,也会出现与高趋势等级月份相同的特征词,造成误分类,导致虚警上升。以2017年12月为例,有报道关于北韩最高领导人在平壤举行的第8届军需工业大会上的讲话内容,报道中出现了导弹、核武器、核力量、军事强国等与高趋势等级强相关的主题词,而报道本身传递的语义信息是领导人对过往取得成绩的总结,并非暗示核行为趋势等级的提升,因此基于主题词提取特征方式造成了断章取义的现象,导致2018年1月预测结果的误判;本文构建以事件为中心的与语义图建立起词汇间事件语义关联,对

表4 与文献[6]预测结果对比
于上述报道语义重心落在领导人讲话总结过往取得的成绩,并非讲话内容中列举出的相关武器,因此可以更准确地表征文档传递的事件语义信息,进而更好地辅助趋势等级分类。
为进一步验证本文所提出方法在朝鲜核行为趋势预测问题上的可行性,以2006年1月至2018年3月间数据为训练集,预测了2018年4月至2019年5月间的趋势等级,预测结果见表5。

表5 2018年4月至2019年5月预测结果
如表5所示,在预测的14个月中,预测正确13个月,整体预测准确率为92.86%,再次验证了本文所提预测方法的可行性。预测错误的月份为2019年4月,标记趋势值为1,趋势等级为C2,预测结果为C1,考虑到前几个月的新闻事件中并未出现与核行为潜在的相关事件,2018年4月20日朝鲜最高领导人宣布停止核和导弹实验,且在2018年9月朝鲜最高领导人承诺实现半岛无核化,因此,2019年4月的射导带有突发性质。
4 结束语
本文针对重大事件趋势预测的研究思路从传统基于频次统计的角度转换到面向事件认知的角度,构建了事件语义关联图,提出了基于图卷积网络的重大事件趋势预测方法,在朝鲜核行为趋势预测问题上,测试集准确率达到76.92%,全时段准确率为89.58%,验证了所提出方法的有效性与可行性。随着事件抽取技术的发展,事件数据信息有进一步优化的空间,本文所构建的事件语义关联图是利用事件属性相关联的间接事件关联图,对于事件间直接关系的识别也是当前研究的热点与难点,如何建立事件间的直接关联,提升事件语义关联图的置信度,将是下一阶段研究的重点。
猜你喜欢
第一财经(2021年6期)2021-06-10 13:19:08
开放教育研究(2020年2期)2020-03-31 01:54:14
当代陕西(2019年15期)2019-09-02 01:52:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年9期)2017-09-07 21:23:49
读者(2017年5期)2017-02-15 18:04:18
现代语文(2016年21期)2016-05-25 13:13:44
纺织服装流行趋势展望(2016年2期)2016-05-04 03:47:15
汽车科技(2015年1期)2015-02-28 12:14:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
