
私有云环境下基于Petri网的用户行为认证模型
2021-11-19 08:17朱玉全徐平平
计算机仿真 2021年10期
吴 菲,朱玉全,徐平平
(1.南京工业大学浦江学院,江苏 南京210000;2.江苏大学计算机科学与通信工程学院,江苏 镇江 212000;3.东南大学信息科学与技术学院,江苏 南京 210000;4.东南大学移动通信国家重点实验室,江苏 南京 210000)
1 引言
私有云(PrivateClouds)是为一个客户单独使用而构建的,因而提供对数据、安全性和服务质量的最有效控制[1],同时用户可以随时随地访问数据,不用担心管理,操作和维护资源的成本[2]。然而,网络入侵现象,导致部分云服务中的重要信息经常发生泄漏和损坏的情况,安全问题已经成为制约云存储发展的瓶颈。异常数据的错误决策可能会给企业带来难以估计的经济损失,如何保证企业云平台的安全,已经成为一个亟需解决的问题。Petri网能够表达并发的事件,云存储数据安全的学术研究主要集中在加密,安全审计和访问控制三种方法。访问控制是基于控制和限制未授权客户端,来防御数据安全的一种方法。国内外对于用户访问控制的研究有很多不同的方法。
文献[3]提出基于实时行为可信度量的网络访问控制模型,引入惩罚因子和时间因子,将用户行为评估方法从单一评估上升到全局评估,在可信网络连接架构下,设计基于用户行为可信策略的访问控制模型,提出网络连接与访问的动态授权机制,实现用户行为的可信判定,但该方法的访问权只能是在读写的情况下,一旦权限类型增加,密钥的数量就会相应增加,导致方法变得较为复杂;文献[4]基于智能眼镜触控行为的隐式身份认证方法,通过Leap Motion设备获取用户特征数据,采用Bagging集成算法完成特征数据的学习训练,将BP神经网络算法和K近邻算法作为基学习器,进而在用户正常使用智能眼镜的过程中,实现手势识别的隐式身份认证,但是缺少对用户行为具体路径的分析,认证速度较慢。
本次研究方法基于用户行为的路径分析,研究用户行为可信度。将用户行为分析分为两个阶段,使用随机Petri网构建两个过程的行为认证模型,利用改进的k-means算法计算用户行为的可信度,并通过仿真证明研究方法的有效性。
2 用户行为认证模型
2.1 私有云环境下用户行为分类
用户身份的可信度决定了使用云服务的权利。在私有云环境中,云服务提供商将为用户提供初始可信度值[5]。为了便于分析用户的行为,将其分为以下三类:
1)用户习惯行为
用户习惯行为包括登录的IP地址,使用的操作系统以及用于登录过程的位置,浏览会话的持续时间,不正确的登录尝试次数。
2)用户异常行为
用户异常行为包括用户下载的资源量,虚拟机数量,RAM大小,存储空间大小,网络带宽。这些行为受云服务提供商的约束,可以从操作日志文件中获取。
3)用户恶意行为
用户恶意行为包括密码破解,TCP floading,特洛伊木马,病毒攻击和IP spoofing。这些信息可以从入侵检测系统的反馈获取。
本次研究将包含在用户行为类型中的信息称为“用户行为证据”。一组行为证据将形成用户行为的记录。在分析用户可信度时,用户行为证据的差异可能导致行为被标记为不可信任。本次研究构建基于随机Petri网的用户行为认证模型,以分析和验证用户行为的类型。
2.2 随机Pertri网
Petri网是一种用于描述和建模信息处理系统的数学工具。它可以精确地描述并行化、异步和不确定性的系统属性,并在图形建模中具有直观的描述。通过关联转换和随机变量的延迟,将为每个转换提供一个速率,构成随机Petri网。
2.3 基于随机Petri网的用户行为认证模型
本次研究针对单用户行为,使用SPN来分析用户在云环境中的行为。当用户登录云服务器时,将分析惯常行为以确定用户是否具有访问云服务器的可信度。一旦用户在服务器上,将进行第二次用户行为分析,以确定用户身份的可信度[6]。
1)第一阶段行为分析模型
该阶段使用SPN分析传统的身份认证和用户习惯行为认证。构建的模型如图1所示:

图1 第一阶段行为认证模型
上述图1中,p表示用户所处的位置,T表示时间变迁,t表示瞬间变迁。模型位置的含义如表1所示:

表1 第一阶段位置含义
第一阶段模型对用户身份进行了两次认证,分别是基于账号密码的认证,以确保用户账号密码的正确性;基于行为的身份认证,通过对用户行为数据的分析,再次确认用户身份是否可信,若可信则进行下一阶段的行为分析。
2)第二阶段行为分析模型
通过第一阶段的身份认证以后,如果用户已经在云服务器中拥有检索资源的权限,则用户将到达P6。在第二阶段行为分析中,使用SPN构建用户行为身份验证模型,来分析云服务器中的用户行为,以确定其身份的可信度。第二阶段的用户分析模型如图2所示,这个阶段云服务器中用户行为的认证,主要涉及用户异常行为和用户恶意行为。
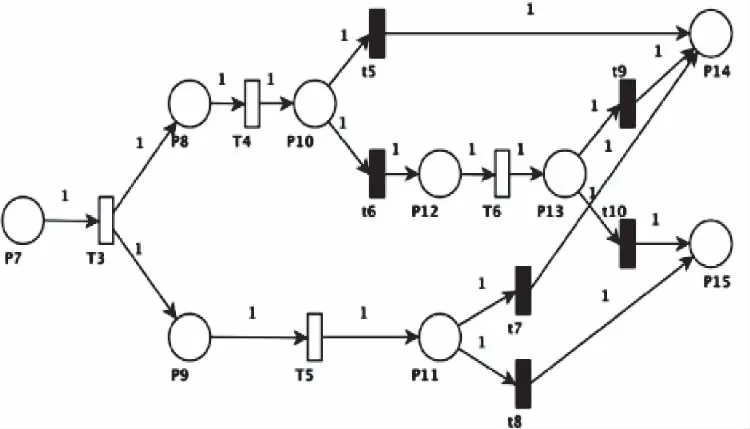
图2 第二阶段行为认证模型
图2中位置与变迁的含义如表2所示。
模型2主要将用户资源访问行为转换为行为路径,以分析用户的异常行为和恶意行为,最后得出用户身份可信或不可信[7]。
3 单用户行为可信度计算
在通过建模分析用户行为之后,利用改进的K-means算法定量分析用户行为的合理性。
3.1 改进的k-means算法
传统的K-means算法只能处理数值型的数据,而不能处理非数值的属性数据,如登录的系统等。原始的算法不能满足用户行为中的非数值类数据的量化处理,所以本次研究对k-means算法进行改进,主要改进对象与中心之间的相异性度量。
设n个对象构成的非空集合X={X1,X2,X3,…,Xn},E={E1,E2,E3,…Em}表示每个对象的属性,Xi可表示为Xi={Xi1,Xi2,Xi3,…Xim},对象与中心之间的相异性度量d(Xi,Cl)如式(1)所示
(1)
式中,∂(Xi,j,Cl,j)表示对象的各属性与类中心之间的相异性,若为数值型数据,则通过两者之间的欧式距离来表示;若为非数值型数据,则∂(Xi,j,Cl,j)的定义如式(2)所示。
阅读课前,孩子们早已整装待发,摘抄本和钢笔放在桌子上,安静地坐在位子上,就等着集合整队了。“想知道答案吗?快去翻翻我国四大名著之一的《水浒传》吧。”果不其然,学校阅览室的《水浒传》借阅一空,借不到的同学正两两合作一起读呢,安静的阅览室里不时传来“沙沙”的笔记声和翻书声。我也拿起随身携带的《水浒传》读了起来……一起课堂的小插曲就此变成了促进师生共读的小引线。
(2)
当Xi,j=C时,表示对象与中心的m个属性值是相同的,当Xi,j≠Cl,j时,表示对象与中心的m个属性值不同,但是用0,1来表示属性的相同或不同时,评判准确度较差,因此对∂(Xi,j,Cl,j)
的计算进行改进,如式(3)所示:

(3)
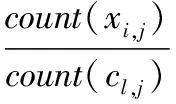
3.2 用户习惯行为标准
将用户行为发生频率较高的动作定义为用户行为习惯标准。在时间转换T2的分析过程中,需要通过使用用户习惯行为标准,来分析用户的行为可信度。本文采用改进的k-means算法获取用户习惯行为标准。
假设用户的n个行为记录为X={X1,X2,X3,…,Xn},每个行为记录Xi由m个行为属性描述,E={E1,E2,E3,…Em}。Xi可表示为Xi={Xi1,Xi2,Xi3,…Xim}。
根据K-means算法的思想,选择k个聚类中心作为初始聚类中心。根据用户习惯行为标准的定义,每个属性需要选择两个集群中心,将每个属性划分为两部分。其中一个聚类中心HC代表共同的行为证据属性聚类中心,被称为“习惯中心点”。另一个集群中心AC是不常见的行为证据属性的集群,称为“辅助中心点”。习惯中心的强度大于辅助中心的强度[9]。定义C1={HC1,HC2,…HCm}表示用户习惯行为标准,定义C2={AC1,AC2,…ACm}表示用户偏离行为标准。
选定中心集以后,计算每个行为记录中心集的相异度H,计算公式如式(4)、(5)所示
(4)
(5)
式(4)中wj表示第j个行为证据属性在整个行为中的影响权重。采用AHP算法计算行为证据权重。AHP是一种模拟人类思维,并将复杂问题分解为层次的方法[10]。算法步骤如下:
1)建立3层用户行为模型。底层由行为证据属性构成,中间层是用户行为的三种类型,顶层是用户行为的可信度。
2)每一层使用9分位比率构造判断矩阵。
3)计算特征向量以测试矩阵的一致性。
4)如果测试失败,则必须重建判断矩阵。
基于上述四个步骤,可以计算出每个行为证据的权重wj。
在求解相异值h的值时,对于数值型数据使用式(6),对于非数值型数据使用式(7)
(6)

(7)
3.3 用户行为可信度计算
用户行为可行度的计算,对确定云服务提供商是否信任用户访问具有直接影响。在获得用户行为聚类中心之后,获得用户习惯行为标准,并找出用户与习惯行为H(X,Cl)之间的相异度值。相异度值越大,行为可信度越低。将单用户的行为可信度(UTD)定义为:
UTD=γ*(1-H),γ∈(0,1)
(8)
式(8)中的γ表示用户可信度影响因子,并由用户的历史行为确定[11]。如果历史记录显示UTD较低,则γ值将低于普通用户的γ值。
由于每个行为的类别和属性不同,因此在T6时间转换中,由云服务提供商提供可信度的分析标准,例如允许使用的资源量和存储空间的大小。通过关联行为标准来分析云服务器中的用户行为。单用户行为差异度H计算如下所示
(9)

(10)
式中的Xi,j是归一化行为属性数据后的第j个属性的值,Sj表示由云服务提供者提供的第j个属性的标准值。根据式(8),UTD∈(0,1),将UTD的值分为5个等级:{(0,0.2),(0.2,0.6),(0.6,0.8),(0.8,0.9),(0.9,1]},分别代表{非常不值得信赖,不值得信任,稍值得信赖,值得信赖,非常值得信赖}。根据该等级来确定单用户行为可信程度,实现基于Petri网的用户行为认证。
4 实验及结果
4.1 实验环境
使用Hadoop技术搭建的云平台为实验环境,在平台上模拟用户行为,如操作行为和攻击行为,并利用软件来收集操作过程中的各阶段用户行为属性,通过建立的模型来分析用户行为可信度。设普通用户的γ=1,异常用户随机生成的γ在0.8到0.9之间。为了简化分析过程,假设有三种类型的用户习惯行为标准,所有用户都遵循这三种习惯行为标准,并且在给定范围内生成行为数据。利用UTD公式计算用户提供可信度,并且阈值设置为0.6。
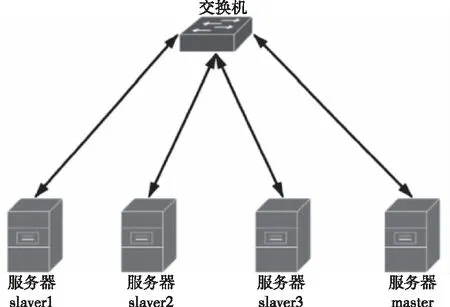
图3 云平台集群简易拓扑结构图
4.2 实验结果
首先进行用户认证准确度对比实验,准确度越高表示方法的认证可信度越高,实验结果如图4所示。

图4 行为认证准确度对比图
通过图4可以得知,文献[3]模型方法的平均准确度在80%,而研究方法的平均准确度在90%以上,证明研究方法的可信度更高,这是由于该模型算法考虑了用户历史行为的影响,能够限制波动对用户可信度的影响。在任何正常操作中,不值得信任的用户很难从云服务器获得信任,从而有效防止用户的非法认证。
误报率是具有低可信度的用户被分类为不可信用户的概率,误报率越低表示方法的有效性越好。误报率计算方法如下:
(11)
上式中,η表示被误报为可信的危险用户样本数,μ表示可信用户样本数。
从图5可以看出,不同实验次数下,文献[3]模型的误报率在5%左右,研究模型的误报率在2%左右,可以看出其整体误报率低于文献[3]模型,误报率越低表示方法的有效性越好,可以证明研究模型比文献[3]模型具有更好的性能。这是因为该模型方法将认证过程分为两个阶段,相当于从两个不同方面对用户身份进行双重认证,能够增强认证过程的稳定性,同时降低了误报率。

图5 用户行为误报率
检测率是在模型的认证过程中正确识别不可信行为的概率,检测率越高表示方法的性能越好。计算方法如下:
Pd=Nd/Nnt
(12)
式中,Nd表示被检测出来的平均不可信行为数,Nnt表示经过认证的不可信平均行为总数。
通过表3可以得知,而研究模型的检测率在80%-90%之间,通过实验数据可以看出研究方法的检测有效性更好,具有更好的用户行为认证性能。主要原因在于本文模型在私有云环境中,针对单用户,利用SPN构建用户行为身份验证模型,解决了多用户行为同时认证环境中,并发事件出现频繁的问题。

表3 用户行为检测率
5 总结
本次研究提出的模型对用户的行为分为两个阶段分别验证,在模型分析过程中提出了改进的 K-means算法的计算用户行为可信度,并确定了可信度的阈值。通过仿真,分析了用户历史行为的影响,验证了研究模型和传统模型在准确度、检测率和误报率方面有效性均更好。
本次研究提出的模型仅解决用户身份认证的问题。云环境中安全问题还存在进一步的挑战,例如隐私数据的安全性。同时研究模型也存在一些缺陷,例如:①在分析用户当前行为之前必须分析用户的历史行为,②为新用户建立初始可信度值可能很难。这些问题有待进一步地研究和验证。
猜你喜欢
小学生学习指导(低年级)(2021年12期)2021-12-31
小天使·一年级语数英综合(2020年9期)2020-12-16
阅读与作文(英语初中版)(2019年8期)2019-08-27
文苑(2018年20期)2018-11-09
文苑(2018年19期)2018-11-09
小火炬·阅读作文(2014年7期)2018-06-09
时代英语·高二(2017年4期)2017-08-11
学生天地·小学中高年级(2017年5期)2017-06-09
红领巾·成长(2016年10期)2017-05-10
中学生数理化·高一版(2017年1期)2017-04-25
