
结合随机属性与集成的软件缺陷预测算法
2021-11-19 09:22王诗博米文博
现代电子技术 2021年22期
王诗博,李 勇,2,米文博
(1.新疆师范大学计算机科学技术学院,新疆乌鲁木齐 830054;2.南京航空航天大学高安全系统的软件开发与验证技术工业和信息化部重点实验室,江苏南京 211106)
0 引 言
随着各行业对软件需求的不断提高,软件的开发规模与复杂性日益提升,软件质量成为软件工程中不可回避的话题。软件缺陷预测技术是发现软件缺陷、提高软件质量的有效方法之一。软件缺陷预测技术基于历史软件开发数据结合机器学习方法实现预测算法[1],进而实现对软件开发过程中未发布软件模块的缺陷预测,已逐渐成为目前软件工程领域的研究热点。
在软件开发过程中,由于各种因素导致软件质量难以保证。质量不达标的软件在运行中可能造成难以预估的灾难,并且根除软件质量问题的时间越晚,缺陷修复的代价也越大。因此,基于机器学习的软件缺陷预测以准确、便捷以及迅速等优点持续被关注。软件缺陷预测模型是由历史软件数据的抽象[2-3]与机器学习算法相结合而成,有研究表明该方法高于人工检测的预测率,可以有效应用于软件工程实践。
在软件缺陷预测中,软件属性度量方法和模型学习算法是决定模型预测性能的关键环节,同时也是研究者关注的重点[4]。
1)软件缺陷预测的属性选择方法。属性选择是除去冗余特征,避免维度灾难的有效方法,该方法可以有效地提高模型的预测效率,减少资源的浪费[5]。Liu 等人提出了一种基于特征聚类和特征排名的特征选择框架FECAR,将冗余特征进行删除[6]。Laradji 等人提出将集成算法与特征选择方式结合起来[7]。实验结果证明以上两种属性选择算法对预测准确率有所提高。
2)基于机器学习的软件缺陷预测方法。在软件缺陷预测领域常常被使用的机器学习模型有朴素贝叶斯[8]、决策树[9]和逻辑回归[10]。其中表现最好的为朴素贝叶斯模型,其准确率[11]达到了71%。在此之后以集成学习[12]为基础,构造多个互异基分类器共同决策,同样获得了良好的成果。也有研究者提出基于迁移学习的软件缺陷预测方法,如李勇等人首先获取与目标项目特征相似的多源项目为候选[13];然后以候选项目的软件模块引导训练数据的选择;最后基于朴素贝叶斯算法实现预测模型。实验结果表明该方法可以有效地解决数据不足的问题。
但上述研究中并没有考虑到使用随机属性子集对于构建软件缺陷预测的影响。传统预测算法中通常假设各个属性之间相互独立,但此假设在现实生活中并不成立。因此,本文结合以上研究工作提出一种结合随机属性子集与集成的软件缺陷预测算法(Software Defect Prediction Algorithm Based on Random Attributes and Ensemble,SRAE),寻求不同属性组合之间可能构成的良好预测效果。
1 结合随机属性与朴素贝叶斯的集成算法
SRAE 算法构建若干个朴素贝叶斯基分类器,以数据中不同属性子集作为训练数据,使用验证集筛选准确率高于阈值的模型进行集成。
1.1 随机属性子集
构建随机属性子集是一种对数据处理的方法,通过对源数据中所有属性的随机提取形成随机属性子集。在软件缺陷预测中往往认为属性之间相互独立,但是绝对独立的事物并不存在。因此,构建随机属性子集可发掘部分属性之间存在的关联对预测结果的影响。
1.2 集成随机属性的贝叶斯模型
SRAE 算法将机器学习中集成学习的思想与朴素贝叶斯算法进行组合,利用随机生成的多组随机属性进行训练朴素贝叶斯基模型。集成学习是将若干互异弱分类器进行组合,共同决策的过程,可有效提高算法泛化性以及防止算法过拟合。在集成学习中,为确保提升集成算法的准确率,需保证基模型的正确率比随机事件概率正确率[14-15]大于50%;为提高集成算法的泛化性,需保证集成的各个基模型互不相同。最后将各个互异基分类器进行平均投票,确定预测结果。数据标签y(x)的取值范围为:

基分类器的错分概率为:

将基分类器集成后的预测结果为:
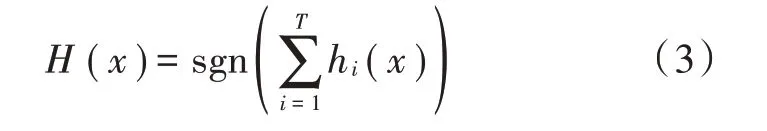
集成基分类器后的集成分类器对目标数据错分概率为:
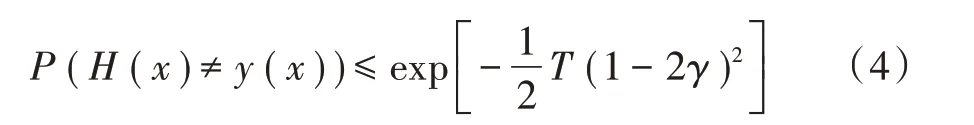
随着集成基分类器数目T的增加,预测的错误率将呈指数级下降,最终趋向于0。朴素贝叶斯算法具有较强的稳定性,即在受噪声数据的干扰时仍能保持相对较好的预测效果,并且在软件缺陷预测中的效果优于决策树、SVM 等算法。为保证基模型之间存在明显差异,使用通过互不相同的随机属性子集筛选出的数据集对基模型进行训练。每个基模型都是通过不同的属性组合进行训练的,这样最大程度上保证了基模型之间的差异。使用随机属性子集训练的基模型可能存在两种情况:其一,冗余属性集中出现,造成预测正确率严重低于理想水平;其二,数据中强关联属性集中出现,造成预测正确率远高于平均预测正确率。当然,本文更期待第二种情况出现。为保证每个基模型的预测正确率超过50%,必须将随机属性组合进行筛选。使用验证集对基模型进行验证,直接删除正确率低于随机事件概率的基模型,将保留下来的基模型进行集成。因此,结合随机属性与集成软件缺陷预测算法(SRAE)在理论上具有可行性。
1.3 SRAE 算法具体工作流程
1)实验数据分为训练集、验证集以及测试集,并且设置集成算法中基模型个数为M。
2)基于训练数据构造随机若干互异随机属性子集,使随机属性子集与朴素贝叶斯基模型一一对应。
3)基于随机属性子集,在训练集中提取数据形成基模型训练集,并且训练该基模型。
4)使用验证集对基模型进行验证,若准确率大于50%,则保留该基模型;若准确率小于50%,则删除该基模型。
5)判断符合条件的基模型个数,若符合条件基模型个数小于M,则重复执行步骤2);若符合条件基模型等于M,则输出集成模型。
SRAE 算法流程如图1 所示。
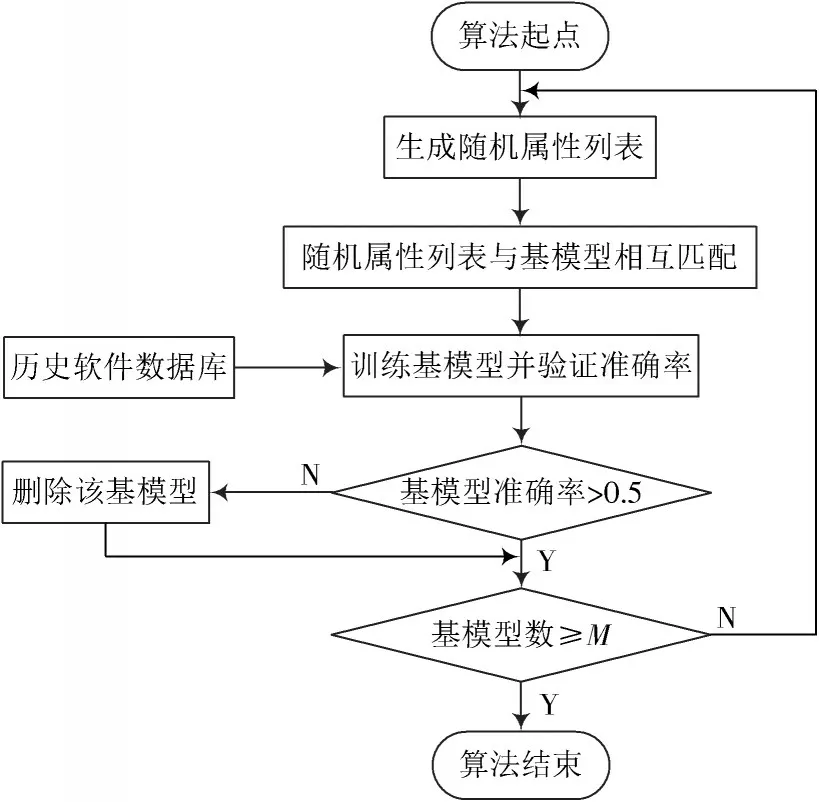
图1 SRAE 算法流程图
SRAE 算法伪代码如下:


2 实验设置
本节对实验参数设置(包括实验数据集、各项参数设置)、代价敏感分类处理以及软件缺陷预测评价标准进行描述。
2.1 实验参数设置
2.1.1 实验数据集
为了使实验结果更具有参考性和可比较性,用于实验的数据采用NASA 公开数据集中选取的10 个数据集。NASA 数据集是软件缺陷预测领域权威数据集,研究人员共同使用此数据集使实验结果具有参考价值与可比较性[16]。实验数据如表1 所示。
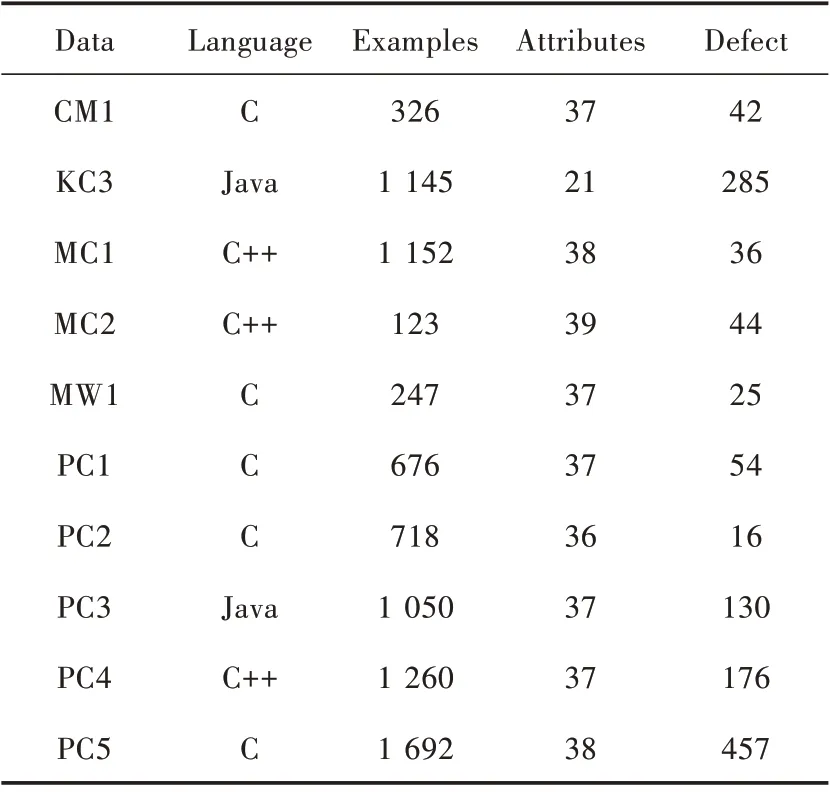
表1 实验数据
2.1.2 实验参数设置
SRAE 算法使用到的参数有:代价敏感技术中的代价因子、基模型的个数、随机的属性个数和K折交叉验证。参数设置如表2 所示。

表2 参数设置
文献[17]通过实验验证了代价因子选择50 时,分类器分类效果最好,所以实验中代价因子设置为数值50。基模型个数为50 个。随机的属性子集中个数选定为数据集中总属性的25%。SRAE 算法采用的是5 折交叉验证。K折交叉验证是将数据集分为K份,取其中1 份作为测试集,其余K-1 份作为训练集。需要注意的是每次选取的测试集都要与之前的不相同。最后将程序执行K次的结果求平均作为最终结果。
2.2 代价敏感分类处理
软件缺陷历史数据包含少量缺陷数据和大量非缺陷数据。历史软件数据中两类数据分布高度倾斜,此现象的数据被称为类不平衡数据[18]。以此不平衡数据训练得到的模型预测结果将高度偏向多数类[19],造成预测结果不理想。在实际应用中难以估量因分类错误造成的后果,因此引入代价敏感技术来缓解类不平衡现象。代价敏感技术是由算法对目标项目错误分类的代价不同而产生[20]。由于算法偏向多数类,代价敏感技术综合分类错误代价通过调节两个分类结果不同的权重,使少数类与多数类之间达到相对平衡[21]。代价矩阵如表3所示。
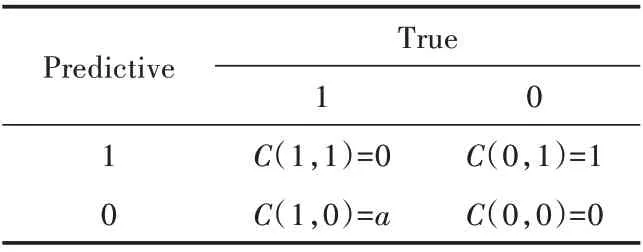
表3 代价矩阵
在代价矩阵中:1 表示有缺陷模块;0 表示无缺陷模块;C(x1,x2)为代价表达式。当x1=x2时代价表达式值为0,即预测正确;当x1≠x2时,有代价表达式C(1,0)和C(0,1)。其中,C(1,0)表示将有缺陷模块预测为无缺陷;C(0,1)表示将无缺陷模块预测为有缺陷。根据错分代价不同得C(1,0)>C(0,1)。当分类器错分时,设代价函数F(x)=P{(x,1)}·C(0,1)+P{(x,0)}·C(1,0),P表示概率,C(0,1)=α。通过设置代价因子α使F(x)代价函数取得最小值,降低错分代价使类间相对平衡。
2.3 软件缺陷预测模型评价指标
在软件缺陷预测中对于模型的评价主要在3 个指标上体现,分别是预测率PD、误报率PF 以及综合评价指标AUC[22-23]。在软件缺陷预测的目标是尽可能多地找到有缺陷的模块并且将其成功判定为有缺陷;同样的在预测过程中需要让模型尽可能少地将无缺陷的模块判定为有缺陷的模块;AUC 综合评价指标,模型的AUC值越高说明模型性能越出色。引入混淆矩阵帮助理解以上3 个指标。混淆矩阵如表4 所示。

表4 混淆矩阵
1)预测率(Probability of Detection,PD)

2)误报率(Probability of Alarm,PF)

3)AUC(Area Under the Curve)
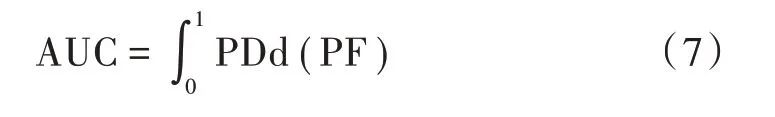
AUC 的值是ROC(Receive Operating Characteristic)曲线下的面积。ROC 是描述PD、PF 的一种曲线,ROC以PF 作为坐标系横轴、PD 作为坐标轴纵轴。AUC 的取值范围为0 <AUC ≤1,当AUC=1 时模型为最佳模型;AUC=0.5 时表示模型预测结果等同于随机事件概率;AUC <0.5 表示模型差。AUC 的值越接近于1 表示模型预测效果越好。
3 实验结果分析
3.1 实验结果对比分析
为方便实验结果的对比与分析,本文实验采用的数据集是NASA 公开数据集,以PD 值、PF 值以及AUC 值作为评价指标。选择以下两类模型算法作为实验基准比较方法。
1)通用机器学习算法。逻辑回归算法(LR)和朴素贝叶斯算法(NB)。文献[10]表明LR 算法具有较好的分类精度且常用于对比算法。文献[11]表明NB 算法通常可以获得较好的预测性能且NB算法具有较好的稳定性。
2)集成模型学习算法。随机森林算法(RF)[12]、欠抽样集成算法(RE)[24]、代价敏感的集成算法(CSCE)[17]。文献[12]表明RF 算法可良好应对噪声数据且通常具有较好的分类准确率。RE 算法[24]以及CSCE 算法[17]为软件缺陷预测常用算法,可有效针对软件数据中类不平衡问题进行准确分类。
3.1.1 预测率PD 实验结果比较分析
表5 所示为6 种方法构建的软件缺陷预测模型的PD 值实验结果。
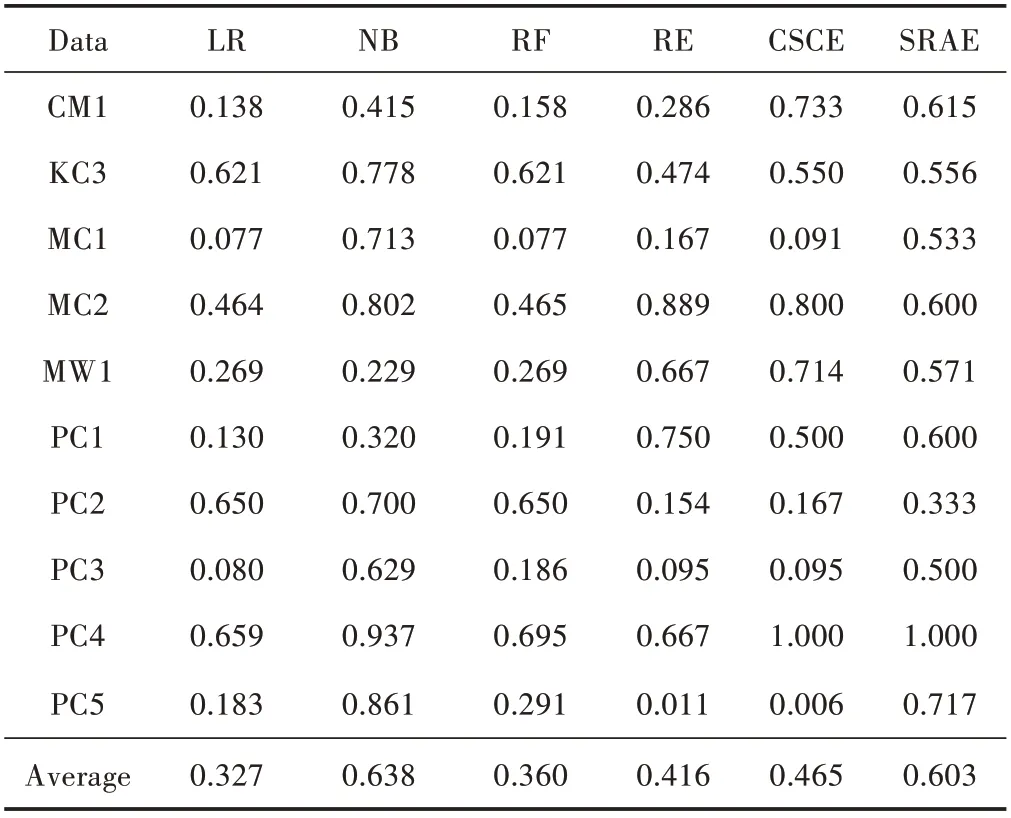
表5 PD 实验结果
通过比较实验结果可以看出:
1)NB 算法在预测率PD 上表现最优。NB 算法在5 个数据集中获得最高的PD 值,平均PD 值明显高于其他算法,且具有较好稳定性。同时NB 算法高于SRAE算法3.8 个百分点,并无显著差异。
2)SRAE 算法平均PD 值仅低于NB 算法,分别高于集成学习模型算法中RF 算法24.3 个百分点、RE 算法18.7 个百分点、CECE 算法13.8 个百分点。
3.1.2 误报率PF 实验结果比较分析
表6 所示为6 种方法构建的软件缺陷预测模型的误报率PF 实验结果。
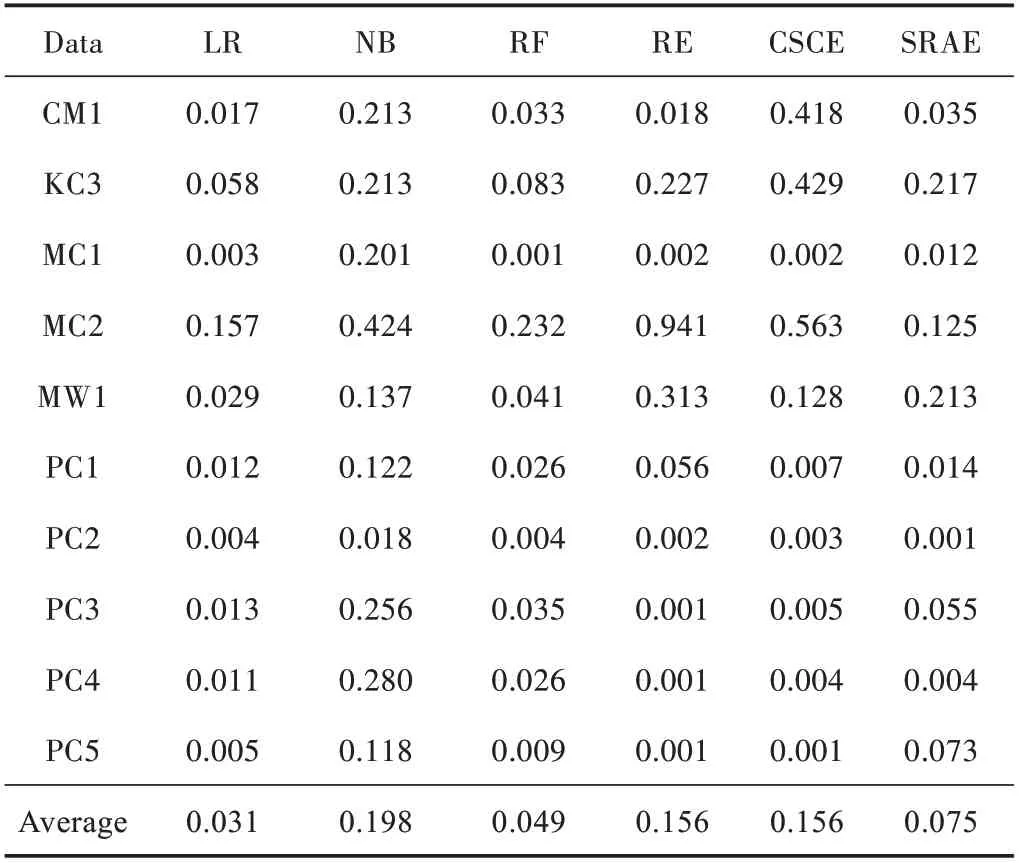
表6 PF 实验结果
通过比较实验结果可以看出:
1)LR 算法在误报率PF 指标上表现最优,但与RF算法SRAE 算法平均误报率接近,并无明显差距。
2)SRAE 算法平均误报率略高于LR 算法与RF 算法,差距在4.4 个百分点之内,同时低于集成模型学习算法RE 与CSCE 8.1 个百分点。
3.1.3 综合评价指标AUC 实验结果比较分析
表7为6种方法构建的软件缺陷预测模型的综合评价指标AUC值实验结果。通过比较实验结果可以看出:
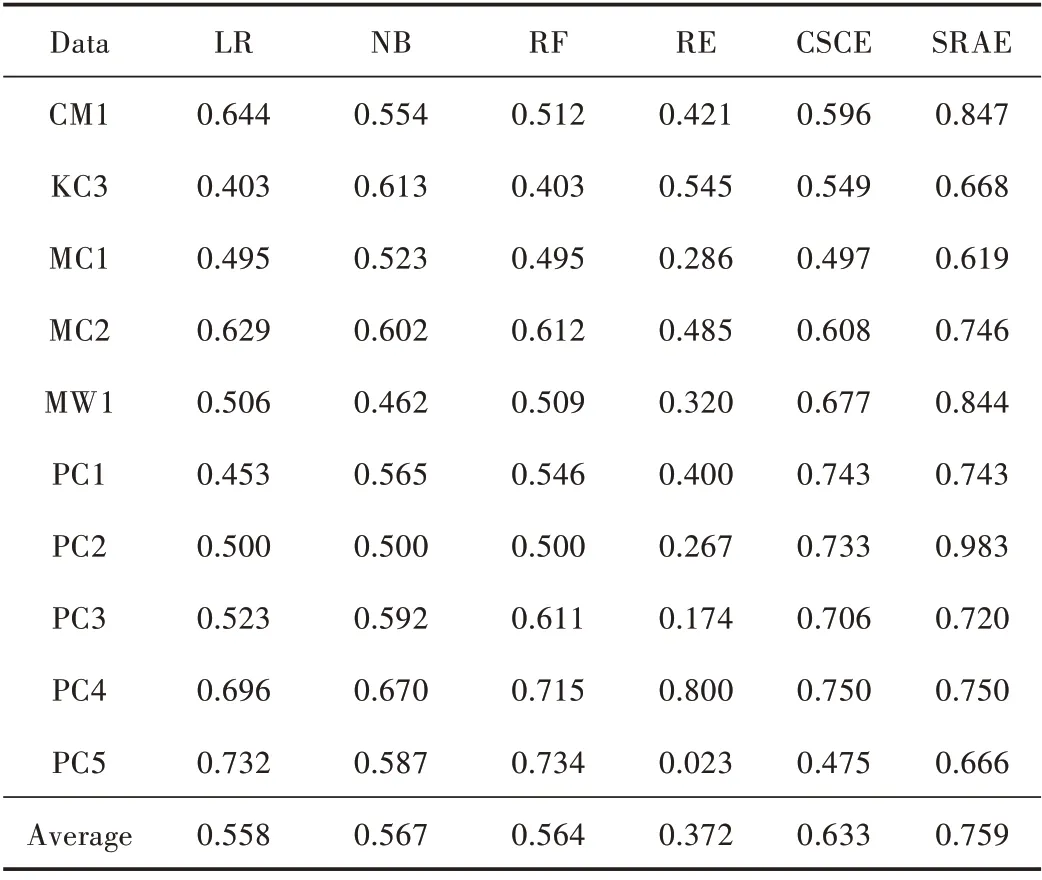
表7 AUC 实验结果
1)SRAE 算法在综合评价指标AUC 值上表现最优,并且9 个数据集上均获得最优AUC 值。SRAE 算法平均AUC 值明显优于其他对比算法。
2)SRAE 算法在平均AUC 值上分别高于通用机器学习算法中LR 算法20.1 个百分点、NB 算法19.2 个百分点;分别高于集成模型学习算法中RF 算法19.5 个百分点、RE 算法38.7 个百分点、CSCE 算法12.6 个百分点。
3.2 实验结论
根据以上6 个软件缺陷预测算法在10 个数据集的实验结果数据对比可以得出以下结论:
1)SRAE 算法在与常用机器学习算法、集成算法以及代价敏感的集成算法比较的过程中,其平均AUC 值具有显著优势。SRAE 算法相比同类型算法CSCE 平均AUC 值提升0.126;相比集成算法RF 与RE 平均AUC 值提成超过0.195;相比常用机器学习算法LR 与NB 平均AUC 值提升超过0.192。
2)在PD 值与PF 值比较过程中分别获得第2 名与第3 名的成绩,且均优于同类型算法。SRAE 算法在预测率PD 与误报率PF 保持在平均水平的情况下获得了AUC 值的大幅度提升。软件缺陷预测的目标是确定决策软件中的模块是否存在缺陷,因此在保证预测率与误报率的条件下,更加准确地对软件模块进行决策更加符合当前工业需求。根据“没有免费午餐定理”说明没有绝对的双赢,在保证预测率PD 与误报率PF 的条件下大幅度提升AUC 值以及分类精度是有意义并且可行的。
4 结 语
软件缺陷预测的目的是尽可能多地找到软件中存在的有缺陷模块。本文提出一种结合随机属性与集成的软件缺陷预测方法,通过在NASA 数据集中选取10 个数据集进行实验,结果表明在保证预测率PD 与误报率PF 的条件下大幅度提升AUC 值。此实验结论表明SRAE 算法可显著提升分类精度,降低错分代价,并且证明符合软件工程中对软件缺陷预测的要求。
基于该研究下一步的主要工作包括:
1)结合当前热点问题将SRAE 模型应用于跨项目跨版本的软件缺陷预测中;
2)通过随机属性的组合筛选出相互之间关联性较高的若干种属性作为软件缺陷预测中属性选择的方式。
猜你喜欢
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11
成都信息工程大学学报(2018年3期)2018-08-29
电子测试(2018年1期)2018-04-18
海峡姐妹(2017年12期)2018-01-31
作文与考试·初中版(2017年12期)2017-04-19
电子元器件与信息技术(2017年4期)2017-03-08
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中学生(2015年12期)2015-03-01
电测与仪表(2014年15期)2014-04-04
