
基于改进Faster R_CNN的苹果叶片病害检测模型
2021-11-18 02:19:30李鑫然李书琴
计算机工程 2021年11期
李鑫然,李书琴,刘 斌
(西北农林科技大学信息工程学院,陕西杨凌 712100)
0 概述
苹果具有较高的营养价值,是世界四大水果之一[1]。苹果生产对我国经济的发展和满足广大人民的需求发挥着重要作用。然而苹果在生长过程中,因受到环境、真菌等影响会产生许多病害,这些病害大多发生在苹果叶片部位,严重影响了苹果的产量与质量,从而造成巨大的经济损失[2]。因此,及时有效地检测苹果叶片病害对于确保苹果产业健康发展至关重要。目前苹果叶片病害检测主要依靠果农经验和病害知识进行分析和判断,然而苹果病害病斑症状复杂,且特征不够明显,人工识别的方法耗时耗力且效率较低[3]。计算机视觉的发展给农作物病害检测带来了新的方向,近年来,涌现出众多基于机器学习[4-7]和深度学习[8-11]的叶片 病害检 测方法。ZHANG 等[12]采用改进的mean-shift 图像分割算法分割病斑,以病斑的颜色特征和差值方图作为苹果病害的分类特征,并利用支持向量机(Support Vector Machine,SVM)进行模型训练,该方法对3 种常见苹果叶片病害的识别精度达96%以上。但该方法仅适用于简单背景的苹果叶片病害图像,在实际复杂背景应用中存在一定局限性。SHI 等[13]利用苹果叶片同类病害及其病斑图像的形状、颜色和纹理之间的差异性,提出了一种基于二维子空间学习维数约简(2DSLDR)的苹果叶片病害识别方法,识别精度高达90%以上。但该方法同样仅适用于背景简单的苹果叶片病害图像。ZHANG 等[14]采用遗传算法(GA)和基于相关性的特征选择算法(GFS)对苹果叶片的多重组合特征进行筛选,再通过支持向量机对多种苹果叶片病害进行识别,精度可达90%,但该方法所需样本需在非自然光下采集。BARANWAL 等[15]提出一种基于卷积神经网络的苹果叶片病害检测模型,其检测精度高达98.54%,但该方法对于叶子姿态要求严格,必须均以向上方式整齐放置。
针对现有苹果叶片病害检测方法对苹果叶片环境要求严格、无法在实际条件下进行实时检测的问题,本文结合苹果叶片病害图像背景复杂、病斑较小的特点,提出一种以Faster R_CNN 模型[16]为基础的苹果叶片病害检测模型。使用特征金字塔网络[17]将仅由特征提取网络最后一层生成的深层特征图,改为由多层网络融合生成具有丰富语义信息和细节信息的特征图,以充分利用不同卷积层的优势。在精确感兴趣区域池化[18]的基础上,通过双线性插值和二重积分的方式进行池化,从而避免Faster R_CNN 模型中感兴趣区域池化中的2 次量化操作造成精度损失。
1 苹果叶片病害检测模型
1.1 特征金字塔网络
Faster R_CNN 的特征提取网络仅使用具有最丰富语义信息的深层特征[19]。深层特征对于大目标的检测很有效,但对于小目标的检测效果不佳[20]。在对苹果叶片病害图像进行采集的过程中发现,实际条件下的病害图像中的病斑面积小,所包含的像素少,因此使用深层特征难以提取到丰富的语义信息。而对特征提取网络而言,浅层特征包含更多的细节信息,能够帮助目标准确定位,因此适用于小目标。因此,为提高模型对苹果叶片病害的检测精度,在Faster R_CNN 的特征提取网络中引入特征金字塔网络模块,融合具有细节信息的浅层特征和具有丰富语义信息的深层特征,以达到提升模型检测效果的目的。
特征金字塔网络采用了自顶向下与横向连接结构,充分利用不同卷积层,其网络结构如图1 所示。首先将深层特征通过2 倍上采样使其与浅层特征大小统一,随后将其与1×1 卷积之后的浅层特征横向连接,使用1×1 卷积层的目的是为了减少特征图个数;最后在卷积特征进行横向连接之后,通过1 个3×3 的卷积层来减少上采样所带来的混叠效应。图中{P2,P3,P4,P5,P6}为最终的特征金字塔,其中P6由P5进行2 倍下采样得到,其锚点尺度为512×512。
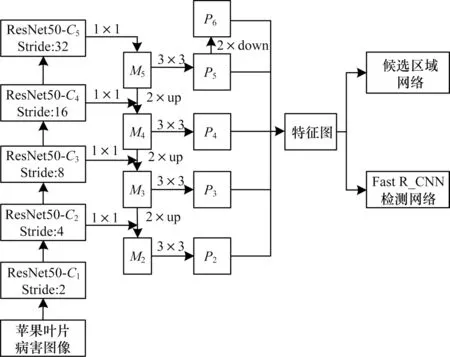
图1 特征金字塔网络结构Fig.1 Structure of feature pyramid networks
融合后特征图即可被后续候选区域网络和Faster R_CNN 检测网络使用,候选区域网络根据每一层金字塔对应的锚点尺度{32×32,64×64,128×128,256×256,512×512},分别应用3 种比例{1∶2,1∶1,2∶1},共产生15 种类型的锚点对苹果病害叶片图像中的病斑进行位置预测,得到目标候选框位置。在Faster R_CNN 检测网络进行池化操作之前,根据特征图尺度的不同来选择不同层级的金字塔层。映射公式如式(1)所示:

其中:w和h分别对应候选框的宽和高;224 为预训练数据集图像大小;k0为4;k对应为特征金字塔网络中的Pk层。
1.2 精确感兴趣区域池化
Faster R_CNN 在感兴趣区域池化过程中存在2 次量化(即浮点数取整)操作,如图2 所示。将候选区域网络得到的感兴趣区域坐标(分别为候选框左上角和右下角2 个点的4 个坐标值)映射到特征图上。由于卷积神经网络的池化操作,特征图的尺寸缩小为原图的32 倍,在此过程中进行取整以消除计算产生的小数;然后将每一个映射到特征图上的感兴趣区域均分成7×7 个区域,即进行7×7 的池化操作,此过程中还需进行量化操作,以此消除计算产生的小数。2 次量化操作给感兴趣区域造成了像素偏差,这对于一般尺度的目标影响很小,但对于病斑尺度较小的苹果叶片病害将造成严重的误差。
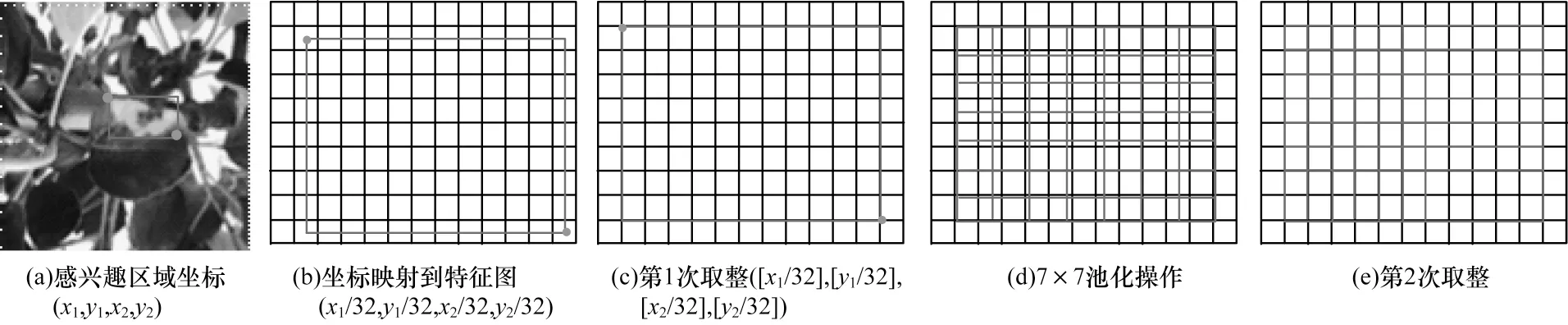
图2 两次量化取整过程Fig.2 The process of twice quantization rounding
为消除感兴趣区域池化中2 次量化操作对病斑较小的苹果叶片病害造成的像素偏差,本文采用精确感兴趣区域池化。首先对输入的感兴趣区域进行双线性插值处理,将其离散的特征图映射到一个连续空间中,映射公式如式(2)所示:

其中:wi,j为离散特征图;f是经过插值后连续的特征图;IC(x,y,i,j)为插值系数,如式(3)所示:
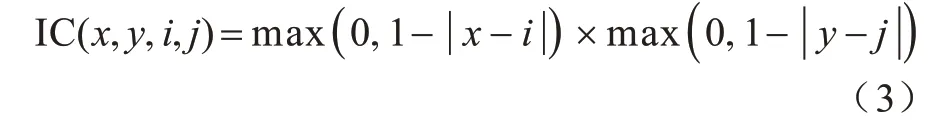
通过使用二重积分进行求均值完成池化操作,如式(4)所示:

PrROI Pooling 通过双线性插值和二重积分彻底避免了感兴趣区域池化中的量化操作,从而有效降低量化操作对苹果叶片病害检测带来的精度损失。
1.3 模型框架
苹果叶片病害检测模型如图3 所示。

图3 苹果叶片病害检测模型Fig.3 The detection model of apple leaf disease
检测步骤如下:
1)提取苹果叶片病害特征。通过特征金字塔网络对含有苹果叶片病害任意尺寸的图像进行特征提取,将所得到的特征图作为候选区域网络和Faster R_CNN 目标检测网络的输入。
2)生成苹果叶片病害候选框信息。候选区域网络以特征图上每个像素点为中心,生成15 种不同尺寸锚点,再通过Softmax 分类器判断锚点属于前景还是背景,并通过锚点回归得到高质量的候选框,以预先找到苹果叶片病害可能出现的位置。
3)确定苹果叶片病害的位置和种类。Faster R_CNN检测网络融合特征图与候选框信息,通过精确感兴趣区域池化对融合信息进行长度固定的特征张量提取,并对提取的特征张量进行分类和位置回归,以确定最终的苹果叶片病害检测框精确位置和病害种类。
2 实验结果与分析
2.1 实验数据集
本研究以5 种苹果叶片病害为研究对象,分别为斑点落叶病、褐斑病、花叶病、灰斑病和锈病。数据集由Plant Village 中苹果叶片的数据集和采集的图像数据集组成。图像采集工作于2018 年9 月在西北农林科技大学白水苹果试验站、洛川苹果试验站和庆城苹果试验站中完成,采集设备为数码相机(Canon EOS 40D)。图像采集在晴天、阴天等不同自然光线下进行,模拟苹果叶片生长可能的环境条件。本文采集的大部分图像背景复杂,与实际应用情况相同,如图4 所示。

图4 5 种苹果叶片病害图像Fig.4 The images of five apple leaf diseases
为避免图像冗余,使用人工对静态图像进行筛选,从3 156 张采集图像中筛选出2 029 张图片。由于采集的原始图像数量有限,因此无法满足网络训练的要求。为减少模型过拟合,加强模型的稳定性,对筛选后的图像进行旋转(旋转角度分别是90o、180o和270o)、明亮度和对比度的变化,以扩充至原始数量的10 倍。数据集构成如表1 所示。

表1 数据集Table 1 Dataset
由于Faster R_CNN 模型能自动从不同大小的图像中提取特征,因此样本图像可以直接用于本文试验方法的训练与测试,不需要进行缩放等预处理操作。采用LabelImg 工具对数据集图像中5 类苹果叶片病害进行手工标注,以获得每张图像的标签矩阵。
2.2 实验环境及参数设置
实验环境配置如表2 所示。本研究模型使用预训练的参数进行初始化,学习率的初始值为0.001,Epoch 为1 000,动量为0.9,迭代次数为90 000,每迭代一个Epoch 保存一次模型,最终选取精度最高的模型。模型的超参数学习率优化采用热身(Warm up)策略,即一开始使用较小的学习率,慢慢增大学习率[21-23]。该策略可以有效提高模型的检测精度,使模型收敛速度加快。

表2 实验环境配置Table 2 The configuration of experimental environment
将数据集按6∶2∶2 的比例划分为训练集、验证集和测试集。使用12 030 张训练集样本对本研究提出模型进行训练。模型训练精度损失曲线如图5 所示。由图5 可知,随着迭代次数的不断增加,网络模型的精度损失逐渐降低,当迭代到60 000 次后,模型开始收敛到稳定值,表明本研究提出的模型达到预期训练效果。

图5 训练损失曲线Fig.5 Loss curves of training
2.3 评价指标
为验证本研究所提出的模型,采用浮点运算次数(Floating Point of Operations,FLOPs)[24]、平均处理时间与平均精度(Average Precision,AP)作为评价指标。平均处理时间能有效地评价模型识别速度,可作为模型实时性的评价标准,如式(5)所示:

平均精度与精确率(Pre)和召回率(Rec)有关。精确率和召回率的计算公式如式(6)和式(7)所示:

其中:Tp为被正确划分为正样本的数量;Fp为被错误划分为正样本的数量;FN为被错误划分为负样的数量。
根据上述公式绘制精确率-召回率曲线,曲线的横轴召回率反映了模型对正样本的覆盖能力,纵轴精确率反映了模型的预测样本的精确度。平均精度是对精确率-召回率曲线进行积分,积分公式如式(8)所示。平均精度体现模型检测效果,其值越大,效果越好,反之越差。

此外,本文采用FLOPs,即浮点运算次数,来衡量模型的复杂度。
2.4 不同模型检测性能对比
为验证本研究提出模型的有效性,选取YOLOv3[25]和Mask R_CNN[26]2 种模型,在其他条件和参数设置均保持一致的前提下,采用平均精度、平均精度均值(mean Average Precision,mAP)、平均处理时间、参数量和FLOPs 作为评价指标进行对比实验。参数量和FLOPs 反应了模型的空间复杂度和计算复杂度。
由表3 可知,从检测精度来看,本模型对5 种病害的检测精度均达到最高,其mAP 为82.48%,与YOLOv3和Mask R_CNN 相比,mAP 分别提升了14.12、5.06 个百分点。YOLOv3 模型的检测精度最低,这是因为YOLOv3 模型没有候选区域网络,其检测流程为直接通过生成与特征图大小相同的预测图进行回归分类,以得到目标检测位置。虽然YOLOv3 模型同样采用特征金字塔结构,但对于本实验中苹果叶片病害背景复杂、病斑较小的特点,不具有良好的适用性。Mask R_CNN模型在候选区域网络采用ROI Align 代替ROI Pooling,避免了量化操作,但其仍存在区域划分数量难以自适应的问题,因此该模型的候选框位置仍存在极大的像素偏差。Mask R_CNN 模型对于斑点落叶病、褐斑病和灰斑病检测精度较低,本研究提出的苹果叶片病害检测模型与其相比,在这3 类病害检测中精度分别提升了7.19、6.86 和5.79 个百分点。

表3 不同模型的检测性能对比Table 3 Comparison of detection performance of different models
从表3 中其他其余指标可知,YOLOv3 的平均处理时间最短,所提模型次之,Mask R_CNN 的平均处理时间最长。虽然YOLOv3 的平均处理时间最短,但无法保证预测的准确性,尤其是在对1 张图像中含有多种病害的图像检测时,存在着大量漏检情况。与此同时,YOLOv3 模型的参数量与FLOPs 最高,说明模型的空间复杂度和运算复杂度很高。所提模型在保证预测准确性的前提下,将平均处理时间控制在可接受的范围内,确保了检测的实时性。此外,所提模型的参数量和FLOPs 均为最低,在3 种模型中性能最优。因此,综合检测精度、模型空间复杂度、时间复杂度和实时性等多方面考虑,所提模型可以更好地对5 种苹果叶片病害进行检测。
2.5 特征提取网络比较
在目标检测领域,将Faster R_CNN 中的VGG16 替换成残差网络(Residual Network,ResNet)可以提高模型性能[27]。为确定苹果叶片病害检测模型中ResNet的最佳层数,选取ResNet18、ResNet50 和ResNet101 3 种结构,在其他条件和参数设置均保持一致的前提下,将5 种苹果叶片病害的平均精度均值作为评价指标进行对比实验,实验结果如表4 所示。

表4 特征提取网络比较Table 4 Comparison of feature extraction network
由表4 可知,ResNet101 的平均精度均值在3 种模型中最佳,其mAP 达到77.39%;ResNet50 次之,mAP 为76.47%;ResNet18 最差,mAP 为72.54%。值得注意的是,从ResNet18 到ResNet50,mAP 提升幅度最大,达到了3.93 个百分点;但从ResNet50 到ResNet101,在所需空间增加82.08 MB,网络参数增加20.87×106的情况 下,mAP 提升幅 度较小,仅 为0.92 个百分点。这是因为虽然ResNet101 在锈病和花叶病的检测精度提高,但对其他病害的检测精度均无明显变化。考虑后期该模型将移植于移动端,本研究选择ResNet50 作为Faster R_CNN 苹果叶片病害检测模型的特征提取网络。
2.6 FPN 和PrPOI Pooling 影响对 比
为增强实验结果的准确性,验证本研究提出的改进点对于模型检测性能的影响,将FPN 和PrROI Pooling 与Faster R_CNN 模型分别组合进行对比实验,4 组模型如下:
1)模型1:Faster R_CNN。
2)模型2:Faster R_CNN+FPN。
3)模型3:Faster R_CNN+PrROI Pooling。
4)模型4:Faster R_CNN+FPN+PrROI Pooling。
由表5 可知,与模型1 相比,引入FPN 的模型2在除花叶病之外的4 种病害检测精度均有显提升,其中斑点落叶病、灰斑病和褐斑病检测精度提升明显,分别提升了9.25、9.19 和6.19 个百分点。这是因为这4 种病害叶片病斑较小,通过结合浅层特征与深层特征可以有效提高模型对其的检测精度。模型2对于花叶病的检测精度低于模型1,这是因为苹果花叶病在叶片上往往呈现出大片病斑区域,只使用深层特征更有利于该病害的检测。从检测时间角度分析,模型2 的平均处理时间比模型1 减少了59 ms,这是因为加入FPN 模块使原本的特征维度由1 024 维降至256 维。加入PrROI Pooling 的模型3 在5 种病害检测精度上均有提升,这说明模型1 中ROI Pooling的2 次量化操作,使得候选区域网络回归生成的候选框位置与真实位置存在极大的像素偏差,从而造成模型检测精度的下降。而实验结果也充分证明PrROI Pooling 可弥补该精度损失。但由于PrROI Pooling 通过双线性插值和二重积分以得到候选框的位置,比2 次量化操作更为复杂,因此模型3 的平均处理时间高于模型1。

表5 FPN 和PrPOI Pooling 模型对检测精度的影响Table 5 The impact of FPN and PrPOI Pooling model on detection precision
对于同时加入FPN 和PrROI Pooling 的模型4,mAP 达到了82.48%,相比于模型1、模型2 和模型3分别提升了6.01、0.96 和2.88 个百分点。这说明本文所提模型4,结合了FPN 和PrROI Pooling 的优势,在缩短平均处理时间的同时,大幅提升了对5 种苹果叶片病害的检测精度。
3 结束语
本文提出一种基于Faster R_CNN 的苹果叶片病害检测模型,利用特征金字塔网络提升模型的特征提取能力,使用PrROI Pooling 避免ROI Pooling 2 次量化操作对病斑较小的苹果叶片病害造成严重检测偏差。实验结果表明,本文模型对5 种苹果叶片病害检测的平均精度均值达82.48%,在苹果叶片病害检测方面具有实用性。但在实际应用中,仅能对5 种病害进行检测远远不够,下一步将采集更多种类苹果叶片病害图像,扩大模型可检测病害种类的范围。
猜你喜欢
今日农业(2022年3期)2022-06-05 07:12:02
今日农业(2021年8期)2021-11-28 05:07:50
烟台果树(2021年2期)2021-07-21 07:18:28
今日农业(2020年19期)2020-11-06 09:29:38
农业工程学报(2018年24期)2019-01-14 10:41:30
中国蚕业(2018年4期)2018-12-05 05:45:12
江苏林业科技(2018年4期)2018-09-14 09:31:06
作文与考试·小学高年级版(2016年17期)2016-12-23 20:21:17
小朋友·快乐手工(2016年10期)2016-12-08 06:15:06
小学生导刊(低年级)(2016年8期)2016-09-24 22:22:30
