
一种检测区域动态更新的目标跟踪算法
2021-11-17 06:35尹莉莙
计算机仿真 2021年8期
尹莉莙,蒋 峥,刘 斌
(武汉科技大学冶金自动化与检测技术教育部工程研究中心,湖北 武汉 430081)
1 引言
视觉跟踪是机器视觉领域中的一个重要课题,它的应用领域非常广泛。给定视频中目标的初始状态,视觉跟踪的目的是跟踪目标在后续帧中的状态。尽管视觉跟踪研究已经取得了很大的进展[1],但仍然有很多问题得不到很好的解决。不同的光照、遮挡、姿态变化、变形、快速运动、旋转、目标尺度发生变化等因素都会提升视觉跟踪的难度。视觉跟踪算法目前主要有生成型跟踪算法和判别型跟踪算法[2]。生成型跟踪算法通过对目标区域进行建模,来找与模型区域最相似的区域作为预测位置,其中包括Meanshift跟踪算法[3]、稀疏表示[4]、增量子空间学习[5],粒子滤波跟踪算法[6]等。判别型方法建立了一个区分目标与背景的模型。判别型跟踪算法包括在线增强[7]、多实例学习[8]、Struct算法[9]、压缩跟踪算法[10]等。
TLD是一个同时包括了跟踪模块,检测模块和学习模块的长时间目标跟踪算法。跟踪模块采用金字塔LK光流法,检测模块采用级联分类器,学习模块采用PN学习模块。跟踪模块和检测模块相互独立运行,学习模块结合跟踪模块和检测模块的结果来预测检测模块的错误,并对训练样本进行校正。然而,该算法存在一些不足。金字塔LK光流法在物体发生光照变化,遮挡,旋转时就会失效;检测模块在第一帧时就产生了所有可能的扫描窗口,这些扫描窗口中包含了大量的无效窗口;学习模块每一次都是对第一帧产生的所有可能的扫描窗口进行处理,耗时巨大。为了减少初始化的时间,文献[11]应用SIFT算法识别出最佳匹配区域作为 TLD的初始跟踪区域。为了减少检测模块的耗时,文献[12]将 Kalman滤波器应用于目标检测中。在发生严重遮挡,运动模糊情况下,文献[13]提出了用卷积神经网络优化TLD算法。鉴于检测模块第一个阶段方差分类器不能有效过滤背景区域,文献[14]将前景检测分类算法用于检测模块。
本文针对金字塔LK光流法跟踪器在复杂背景下容易出现跟踪漂移的现象,提出了用压缩跟踪器替换原有的金字塔LK光流法跟踪器;针对检测模块每次检测时都需要处理大量无效窗口,提出了一种检测区域动态更新的方法;学习模块也在该检测区域动态更新的区域中来进行学习,可以减少学习模块的耗时。
2 TLD目标跟踪算法
TLD算法[15]主要包括跟踪器(tracker),检测器(detector)和机器学习(learning)三个基本模块。TLD算法的基本框架如下图1所示。
2.1 TLD跟踪模块
TLD的跟踪器采用金字塔LK光流法[16]。在每一帧跟踪时,在目标模型区域选取一个10×10大小的网格,网格内均匀分布着像素点,这些像素点作为跟踪的特征点。在t帧时,运用LK光流法跟踪这些特征点到t+1帧。根据t+1帧特征点的位置,反向利用LK光流法得到这些特征点的后向跟踪轨迹。这样每个特征点都会有前向和后向两个位置,这两个位置的欧式距离作为每个特征点的前后向误差值(FB error)。计算每个特征点在两帧之间的归一化互相关匹配值(NCC)。同时小于FB error和NCC中值的特征点作为跟踪成功的点。
2.2 TLD检测模块
TLD的检测器由方差分类器,集合分类器和最近邻分类器构成。方差分类器去除掉所有灰度值方差小于被跟踪图相框灰度值方差50%的扫描窗口,剩下的扫描窗口进入集合分类器。集合分类器包括10个基本分类器。每一个基本分类器i对扫描窗口进行像素比较,得到一个包含一系列后验概率Pi(y|x)的二值编码x,其中y∈{0,1}。将上面得到的后验概率取平均值,如果大于0.5,那么扫描窗口就通过集合分类器。经过集合分类器筛选的扫描窗口进入最近邻分类器,将扫描窗口与样本库中的样本用NCC计算相似度,相似度大于最近邻分类器阈值的扫描窗口通过最近邻分类器。
2.3 学习模块
学习模块采用PN学习[17]。学习模块在第一帧初始化检测器,并在后续的运行中对检测器的错误进行校正。PN学习包括P专家和N专家。P专家用来发现错误的负样本,把它标记为正样本并添加到样本集中。N专家用来发现错误的正样本,把它标记为负样本并添加到样本集中。
3 TLD 算法的改进方法
金字塔LK光流法跟踪目标模型区域内10×10大小的网格内的像素点,这些像素点是均匀分布的,作为跟踪的特征点。在发生光照变化,尺度变化,姿态变化,旋转,快速移动时,通过NCC和FB error可能滤除掉那些代表目标模型的有效特征点。剩下的特征点可能与背景中相似的点错误配对或者无法找到对应的配对点,出现跟踪漂移现象。本文选用压缩跟踪器替代金字塔LK光流法跟踪器。检测模块在每一次检测时都要和第一帧产生的所有扫描窗口进行比较,这些扫描窗口中包含了大量的无效的扫描窗口。这里提出了一种检测区域动态更新的方法。学习模块也在检测区域动态更新的区域中进行学习,有效减少了学习模块的耗时。
3.1 TLD跟踪器的改进
压缩跟踪算法对比金字塔LK光流法有如下优势:①它对姿态和光照变化具有健壮性,因为目标的外观模型通过随机投影矩阵来构造并且采用在线更新的分类器来区分目标和背景;②它能够较好的处理遮挡,因为它的外观模型是基于局部特征的;③它能够较好的处理非刚性目标的姿态变化,因为它的外观模型是从多尺度空间中随机选取,这种特征对非刚性目标外形的变化是不敏感的;④它对平面旋转有一定的抵抗性,在发生平面旋转时,它在跟踪过程中采用分类器和多尺度图像特征来处理目标位置的模糊性。
压缩跟踪算法在t帧时从接近当前目标位置附近采集一些样本,这些样本经过多尺度变换,稀疏测量矩阵,将得到的压缩特征送入贝叶斯分类器中,分类分数最大的图片即认为是目标。在t+1帧时,在距离目标很近的位置产生正样本,离目标很远的位置产生负样本,这些正负样本经过多尺度变换,稀疏测量矩阵,将得到的压缩特征用于更新贝叶斯分类器。压缩跟踪整体流程示意图如图2,图3所示。

图2 在第t帧更新分类器

图3 在第t+1帧确定目标位置
压缩跟踪算法主要步骤如下:
1)多尺度变换
对于每一个样本Z∈Rw×h(R表示实数集,w和h分别表示样本图像的宽度和高度)分别与一组多尺度矩形滤波器{h1,1,…,hw,h}进行卷积,获得多尺度的样本特征向量。每一种多尺度矩形滤波器的定义如下:
(1)
2)稀疏测量矩阵生成
压缩感知理论指出通过满足约束等距性(RIP)准则的稀疏测量矩阵[18],多尺度图像特征可以投影到低维图像空间。采用稀疏测量矩阵R=Rn×m,将数据从高维图像空间x∈Rm投影到低维数据空间v∈Rn。
v=Rx
(2)
矩阵R中每个元素如下所示
(3)
3)朴素贝叶斯分类
提取的特征经过贝叶斯分类器分类,分类公式为:
(4)
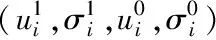
(5)
式(5)中的标量参数通过下面的公式更新,如式(6)所示
(6)
这里增加了对压缩跟踪效果的评估,将压缩跟踪得到的跟踪框与样本库中的样本用NCC计算保守相似度,作为跟踪器的保守相似度,用同样的方法得到检测器的保守相似度。在检测器检测到的扫描窗口中,寻找与跟踪器跟踪到的跟踪框距离较远的类,且它的保守相似度比跟踪器的要大,如果满足以上条件的扫描窗口只有一个,就用该扫描窗口重新初始化跟踪器,否则寻找距离跟踪器预测到的跟踪框很近的扫描窗口,这些扫描窗口与跟踪器本身预测到的跟踪框进行坐标与大小的平均,作为最终的目标跟踪框,其中跟踪器的权值较大。
3.2 TLD检测器的改进
TLD检测器通过扫描窗口对每个视频进行处理,每次扫描一个图像块,给出其中是否有待检测目标。这些扫描窗口在第一帧的时候就已经产生好了,检测模块在每次确定目标位置时都要和这约50000个扫描窗口进行比较,耗时巨大[19-20]。本文提出了一种动态更新检测区域的方法。
1)确定运动目标的搜索半径
在每一帧时,根据要跟踪目标的速度,来确定搜索半价r。具体的步骤如下:在每一帧时把TLD算法跟踪到的目标的位置存起来,在t帧的时候得到t-2帧到t-1帧的位移Δst-1。
前面5帧的平均速度作为t帧的速度
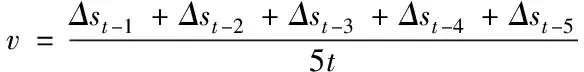
(7)
根据t帧的速度v来确定搜索半径r
(8)
t是每一帧算法运行的时间,r的单位是像素,v的单位是像素/秒,t的单位是秒。r′和Δs1是根据选定的10个视频设定的参数值。本文把每一帧的Δs1存入1.txt文档中,根据1.txt中的数据选取Δs1为8.5,根据这10个视频进行反复实验,选取r′为10。本文的r′和Δs1为参数值,根据不同的测试视频可以进行改变。
2)产生正样本和负样本
在t帧的时候,清理掉t-1帧产生的所有扫描窗口,以t-1帧跟踪框为中心,根据历史的速度来确定搜索半价r,根据搜索半径r来产生新的扫描窗口。将所有产生的扫描窗口放入网格容器中,并求出这些扫描窗口与上一帧的跟踪框的重叠度。根据重叠度对所有的扫描窗口进行分类,产生好的扫描窗口和坏的扫描窗口,重叠度最大的扫描窗口归一化为15*15像素的大小,作为最好的扫描窗口。根据最好的扫描窗口的积分图计算出最好的扫描窗口的方差,方差的一半作为检测模块第一阶段方差分类器的阈值。清理掉t-1帧产生的所有正样本和负样本。从产生的好的扫描窗口中选出10个重叠度最大的扫描窗口,对每一个扫描窗口进行10次仿射性变换,产生了100个正样本;根据最好的扫描窗口的方差对坏的扫描窗口进行筛选,产生负样本。
3)级联分类器进行分类。
将产生的负样本归一化为15*15像素的大小,作为标准的负样本。将一半负样本和100个正样本用来训练集合分类器。另外一半负样本和一半标准的负样本用来评价集合分类器和最近邻分类器的阈值。所有的扫描窗口经过方差分类器(Cascsded classifier),集合分类器(Ensemble Classifier),最近邻分类器(NN Classifier)来进行筛选。只有通过了3个分类器的扫描窗口才被认为是目标。
针对Basketball这个视频,进行了原始TLD算法和改进后的TLD算法进入分类器的扫描窗口数量的比较。如图4所示,横坐标表示视频帧数,纵坐标表示进入分类器的扫描窗口数量,纵坐标选用对数来表示。可以看出,原始TLD每帧进入分类器的扫描窗口数量为231526个,而改进TLD每帧进入分类器的扫描窗口数量大多小于1000个。可以看出经过改进后,进入分类器的扫描窗口数量减少了,检测模块耗时减少了,检测模块的实时性提高了。
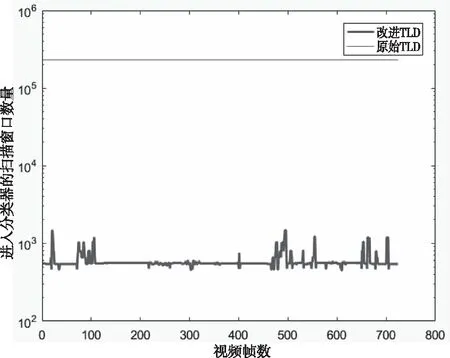
图4 进入分类器的扫描窗口数量
3.3 学习模块的改进
原本的学习模块每一次都是对第一帧产生的所有可能的约5万个扫描窗口进行处理,耗时巨大。本文采用在动态更新的检测区域中来进行学习。在每一帧时,把经过跟踪器和检测器综合得到的跟踪框作为最终的目标跟踪框,目标跟踪框同检测器每一帧产生的扫描窗口计算重叠度,将重叠度最大的扫描窗口作为最好的扫描窗口,将该最好的扫描窗口的大小归一化为15*15像素的大小,作为最好的样本。筛选出检测器检测得到的检测目标同最终的目标跟踪框重叠度小于0.2的检测目标,同最好的样本一起作为最近邻NN分类器的训练样本。通过采用在动态更新的检测区域内进行处理,减少了学习模块的耗时。
3.4 改进算法的实现过程
改进TLD算法的实现过程如下所示。
步骤1:读取视频文件,视频相关文件中给出初始跟踪框的大小,位置。
步骤2:初始化CT跟踪器,完成TLD的初始化。
步骤3:第一帧时CT跟踪器进行跟踪,检测模块在第一帧不进行检测,第一帧时跟踪器的结果作为最终结果。
步骤4:CT跟踪器在每一帧进行跟踪,并得到跟踪器的保守相似度tconf,检测模块清理掉之前的扫描窗口,正样本,负样本。根据跟踪目标的速度,来确定搜索半价r。根据半价r产生新的扫描窗口,以新的扫描窗口为基础,生成新的正样本和负样本,训练集合分类器,检测器对新的扫描窗口进行检测。
步骤5:根据跟踪模块的保守相似度tconf和检测器的保守相似度dconf,综合模块得到目标在下一帧中的位置。
步骤6:将综合模块得到的跟踪框的位置传给CT跟踪器,进行下一次的跟踪。
步骤7:学习模块根据综合模块传进来的跟踪框,从检测器产生的新的扫描窗口中找出重叠度最大的扫描窗口,将重叠度最大的扫描窗口的大小归一化为15*15的大小,作为最好的样本。最好的样本同与最终的目标跟踪框重叠度小于0.2的检测目标一起作为最近邻NN分类器的训练样本。
步骤8:重复步骤4到7。
4 实验分析
本文将改进后的 TLD 算法与原始 TLD 算法进行了比较。实验中采用了10组视频进行测试,分别是TLD原作者实验中使用到的数据集jumping,panda,以及OTB100里面的数据集包括Bolt2,Basketball,ClifBar,FaceOcc2,Tiger1,Coupon,Twinnings,Walking共10个视频。这些场景包含了光照变化,尺度变换,遮挡、形变,运动模糊,快速移动,低分辨率,目标的某些部分离开视图,目标在图像平面外旋转,背景杂波,平面内旋转,快速移动等情况,此外算法开发平台为windows7,开发工具为 Visual Studio2010 和 OpenCV2.4.10,处理器为i5-7500,CPU为3.4GHz,内存为4G。
4.1 定性分析
在这里本文选取了Panda,Basketball,Bolt2,FaceOcc2,Tiger1这些视频进行定性分析。
1)Panda包含了目标姿态变化,外形变化。开始的几十帧里原始TLD和改进TLD都可以跟踪到。122帧时,目标姿态发生了变化,金字塔LK光流法出现了错误的运动矢量场,原始TLD算法跟踪错误,改进TLD算法由于采用了对尺度和姿态变化具有一定健壮性的Haar-like特征,在姿态变化,外形变化下都可以跟踪到。
2)Basketball包含相似目标。15帧时,相似目标出现,金字塔LK光流法跟踪特征点错误配对导致跟踪失败,而改进后的TLD算法采用的压缩跟踪器的分类器是在线更新的,可以有效地区分目标和背景。
3)Bolt2包含了非刚性目标,快速移动。开始的时候,运动员的四肢和躯干时刻发生着复杂的运动,原始TLD算法跟踪错误。后来运动员快速奔跑,原始TLD算法跟踪错误,而改进TLD算法由于压缩跟踪算法的外观模型是基于局部特征的,这种特征对非刚性目标不敏感,对快速移动的处理能力强。
4)FaceOcc2包含了遮挡情况。在出现遮挡的情况下,金字塔LK光流法容易形成错误的运动矢量场,出现跟踪漂移现象,而改进的TLD算法采用了从多尺度空间随机选择的特征,这种特征对遮挡不太敏感。
5)Tiger1包含光照变化,旋转。35帧时,目标发生了光照变化,金字塔LK光流法受到光照的干扰,原始TLD算法跟踪丢失,此后目标出现了旋转,图像中的像素点难以形成运动矢量场,原始TLD算法跟踪丢失。而改进TLD算法由于压缩跟踪采用分类器和区分特征来处理目标位置的模糊性,在光照和平面旋转情况下都可以跟踪到。
综上所述,改进的TLD算法在目标姿态变化,外形变化,快速移动,有相识目标出现,非刚性目标,遮挡,光照变化,旋转的情况下效果都很好。图(a)(b)(c)(d)(e)为原始TLD算法与改进TLD算法跟踪效果比较图,其中红色框是改进TLD效果图,白色框是原始TLD效果图。

图5 原始TLD算法与改进TLD算法跟踪效果比较图
4.2 定量分析
本文选用跟踪成功率作为视频目标跟踪结果的评价标准,它是指成功跟踪的帧数占总帧数的比例。原始TLD算法与改进后算法跟踪成功率的比较见表2,可以看出较原始算法相比改进后算法跟踪成功率得到了提高。原始TLD算法在选定的很多个测试视频的后期检测器没有发挥作用,跟踪失效。跟踪速度代表的是整体的平均跟踪速度,包含了跟踪失效的帧数。选择在跟踪不失效的情况下比较算法的实时性。这里选取视频每一帧的运行时间作为跟踪实时性的评价标准。图6显示了对于Twinnings这个视频原始TLD算法与改进TLD算法每一帧运行时间的比较。可以看出原始TLD算法每一帧的运行时间大都在100ms到1000ms之间,而改进TLD算法每一帧的运行时间在100ms以下。由于检测模块采用了动态更新的扫描区域,跟踪实时性得到了提升。
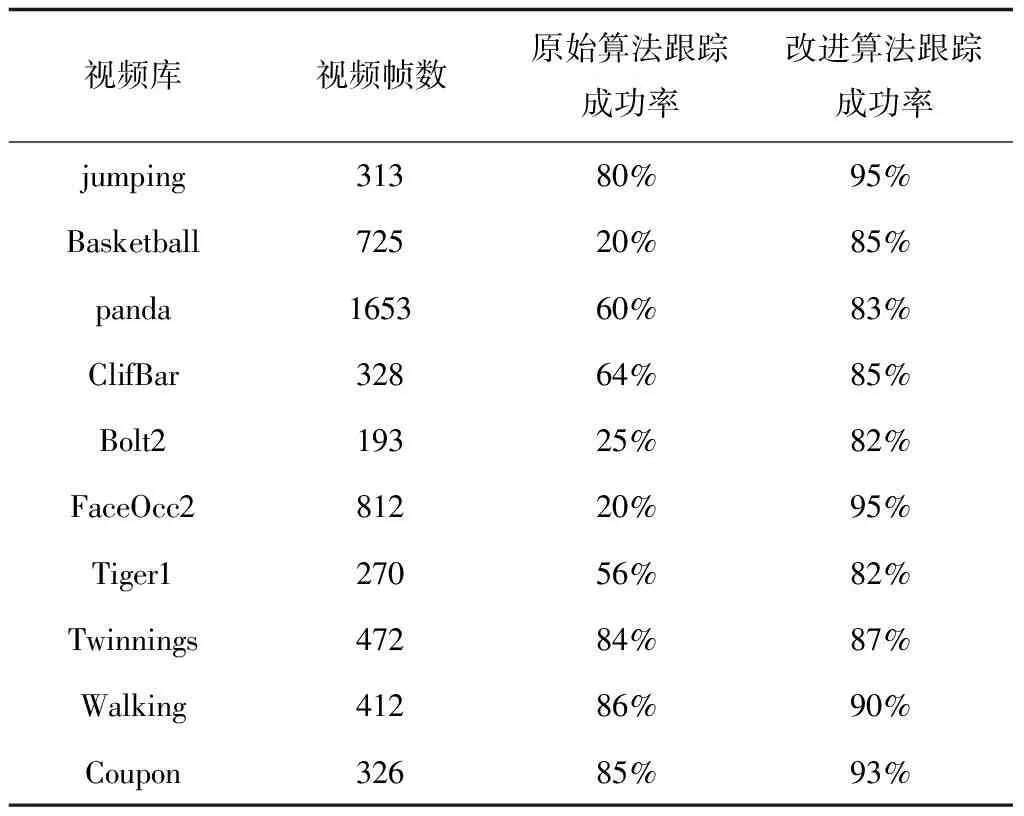
表2 原算法与改进算法跟踪成功率比较
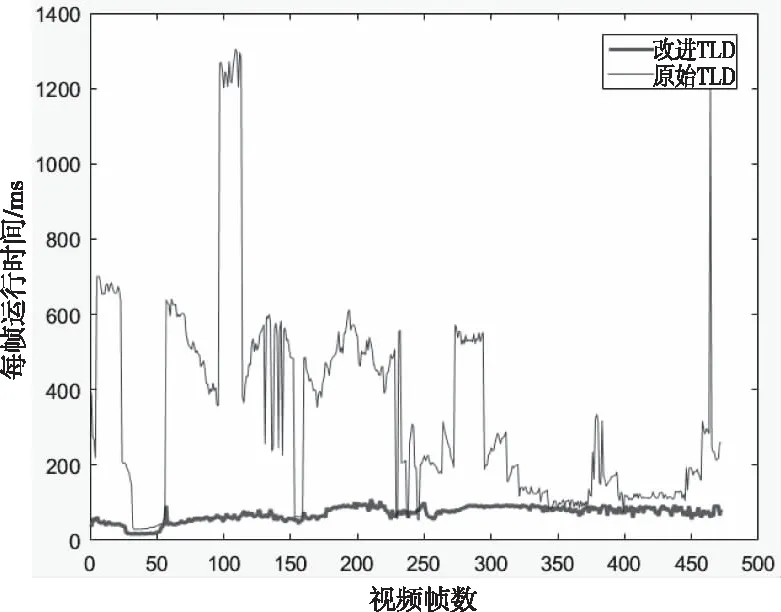
图6 每一帧运行时间比较
5 结语
本文的主要改进如下:
1)对于原始的TLD中所采用的金字塔LK光流法做出改进,使用压缩跟踪器作为TLD的跟踪器,有效解决了光流法无法有效跟踪物体快速移动,遮挡,形态发生剧烈变化等问题,并且增加了对压缩跟踪器跟踪效果的评估;
2)在每次检测之前,根据目标的历史速度,设定了一个动态更新的检测区域,减少了检测模块的耗时;
3)学习模块每次都在动态更新的检测区域中来进行学习,加快了学习模块的速度。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
测控技术(2022年4期)2022-04-27
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
领导决策信息(2018年16期)2018-09-27
科技风(2018年15期)2018-05-14
人大建设(2017年10期)2018-01-23
软件导刊(2017年4期)2017-06-20
数学学习与研究(2017年3期)2017-03-09
西南学林(2011年0期)2011-11-12
