
FPGA 加速深度学习综述
2021-11-17 08:24刘腾达朱君文张一闻
计算机与生活 2021年11期
刘腾达,朱君文,张一闻
1.武警工程大学 研究生大队,西安710086
2.武警工程大学 信息工程学院,西安710086
近年来,随着大数据时代的来临,人们在短短几年中创造的数据呈爆发式增长[1-3],得益于数据量的上涨、运算力的提升和深度学习的出现,人工智能开始迅猛发展。作为实现人工智能的重要技术和研究方向,深度学习已经广泛应用于计算机视觉[4-6]、语音识别[7-9]和自然语言处理[10-12]等诸多领域。为了提高计算性能以适应神经网络模型的增大及其参数的增多,研究者在寻找各种软、硬件解决方案上花费了大量努力,目前广泛应用的方法有CPU、GPU、FPGA 和ASIC 等加速技术,其中GPU 加速技术由于其强大的计算能力已经成为深度学习加速方式的首选。现场可编程逻辑门阵列(field programmable gate array,FPGA)由逻辑单元阵列构成,内部包括可配置的逻辑模块、输入输出模块和内部互联网连线[13]。与其他加速方式相比,FPGA 具有可重构、高能效比、高性能、便携、延迟低等优势。基于这些优势,FPGA 近年来迅速发展,逐渐成为GPU 在算法加速领域的有力竞争者。目前基于FPGA 的神经网络加速器种类较多,其设计理念和加速方案各不相同,根据设计理念和满足需求的不同,可以分为:针对神经网络模型的加速器、针对具体问题定制的加速器、针对优化策略的加速器和针对硬件模板的加速器框架[14]。本文在深度学习的典型模型的基础上,归纳列举了各种FPGA 加速器并对比了典型加速器的性能特点,理清了FPGA 加速深度学习的研究现状,为进一步深入研究深度学习的FPGA 加速技术奠定了基础。
1 深度学习典型模型简介
2006 年,加拿大多伦多大学教授、机器学习领域的泰斗Hinton 和他的学生在Science上发表了一篇文章,正式提出深度学习[15]的概念并开启了深度学习在学术界和工业界的浪潮。深度学习的概念源于人工神经网络的研究,是机器学习研究中的一个新的领域,可以简单理解为神经网络的发展,其动机在于建立模拟人脑进行分析学习的神经网络,模仿人脑的机制来解释数据。深度学习的实质,是通过构建具有很多隐层的机器学习模型和海量的训练数据,来学习更有用的特征,从而最终提升分类或预测的准确性。目前,广泛使用的深度学习模型有深度神经网络(deep neural network,DNN)、卷积神经网络(convolutional neural networks,CNN)和循环神经网络(recurrent neural network,RNN)[16]等。
1.1 深度神经网络
深度神经网络是在单层感知机的基础上通过增加隐含层的数量及相应的节点数而形成的,它的出现克服了单层感知机性能低下的缺陷[17],结构如图1所示。
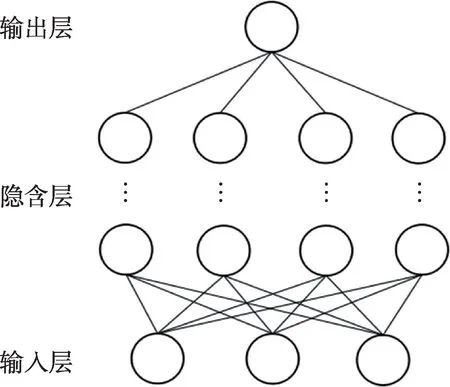
Fig.1 Illustration of deep neural network图1 深度神经网络结构示例
深度神经网络的相邻层之间全连接,其隐含层的数量和节点的数目更多,因而要训练的参数规模非常大。DNN 主要用于图像识别和语音识别领域,在图像识别时可以忽略图像的空间几何关系,将其变为一维数据进行处理,因此相比于单层感知机有着更优秀的性能表现。
随着神经网络层数的不断加深,参数数量的膨胀导致过拟合的现象愈发严重,并且优化函数越来越容易陷入局部最优解。为了克服这一问题,卷积神经网络应运而生。
1.2 卷积神经网络
对卷积神经网络的研究始于20 世纪80 年代,卷积神经网络模仿生物视觉系统结构,其隐含层包括卷积层、池化层和全连接层三类常见构筑[18-19],网络结构如图2 所示。

Fig.2 Illustration of convolutional neural network图2 卷积神经网络结构示例
卷积层和池化层通过运算提取出数据的特征图,在全连接层将特征图映射成特征向量,从而把数据中的特征保存下来以达到识别分类的目的[20]。对于CNN 来说,并不是所有上下层神经元都能直接相连,而是通过“卷积核”作为中介,利用权重共享极大地减少了网络的参数量,使得训练大规模网络变得可行。相比于其他网络,卷积神经网络的适应性更强,正逐渐成为图像识别和自然语言处理等领域的主流网络。
由于每层信号只能单向传播并且样本处理在各个时刻相互独立,DNN 和CNN 无法对时间序列上的变化进行建模。但是在自然语言处理、语音识别、手写体识别等领域,样本出现的时间顺序十分关键,循环神经网络就是为了适应这种需求而诞生的。
1.3 循环神经网络
循环神经网络是一类以序列数据为输入,在序列的演进方向进行递归且所有节点按链式连接的递归神经网络[21]。如图3 所示,循环神经网络具有记忆性、参数共享并且图灵完备,因此更擅长学习序列的非线性特征[22],常被用于自然语言处理和时间序列预报等领域。
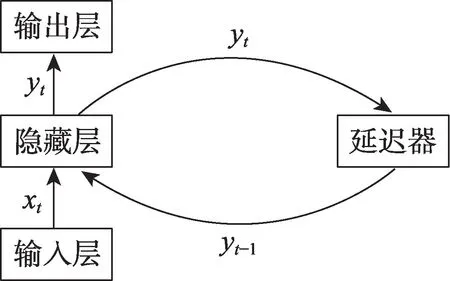
Fig.3 Illustration of recurrent neural network图3 循环神经网络结构示例
随着人工智能的迅猛发展,神经网络模型层数和节点数量日趋增多,模型的复杂程度越来越高,深度学习和神经网络对硬件的计算能力提出了更严格的要求。相比于CPU 和GPU,FPGA 加速技术因其可重构和低功耗等优势受到了人们的极大关注。根据设计理念和满足需求不同,基于FPGA 的深度学习加速器大体可分为针对神经网络模型的加速器、针对具体问题定制的加速器、针对优化策略的加速器和针对硬件模板的加速器框架等,下面作以归纳比较。
2 针对神经网络模型的加速器
针对某种神经网络模型加速思路最直接,设计目的也最明确,这种加速器在用于特定场合时,通常只需要对程序或参数作以微调便可使用,十分方便。图4 展示了基于FPGA 的神经网络加速器的发展演进历史以及在IEEE 上发表有关论文的数量趋势,从中可以看出,近年来FPGA 加速神经网络的研究愈发受到人们的重视。
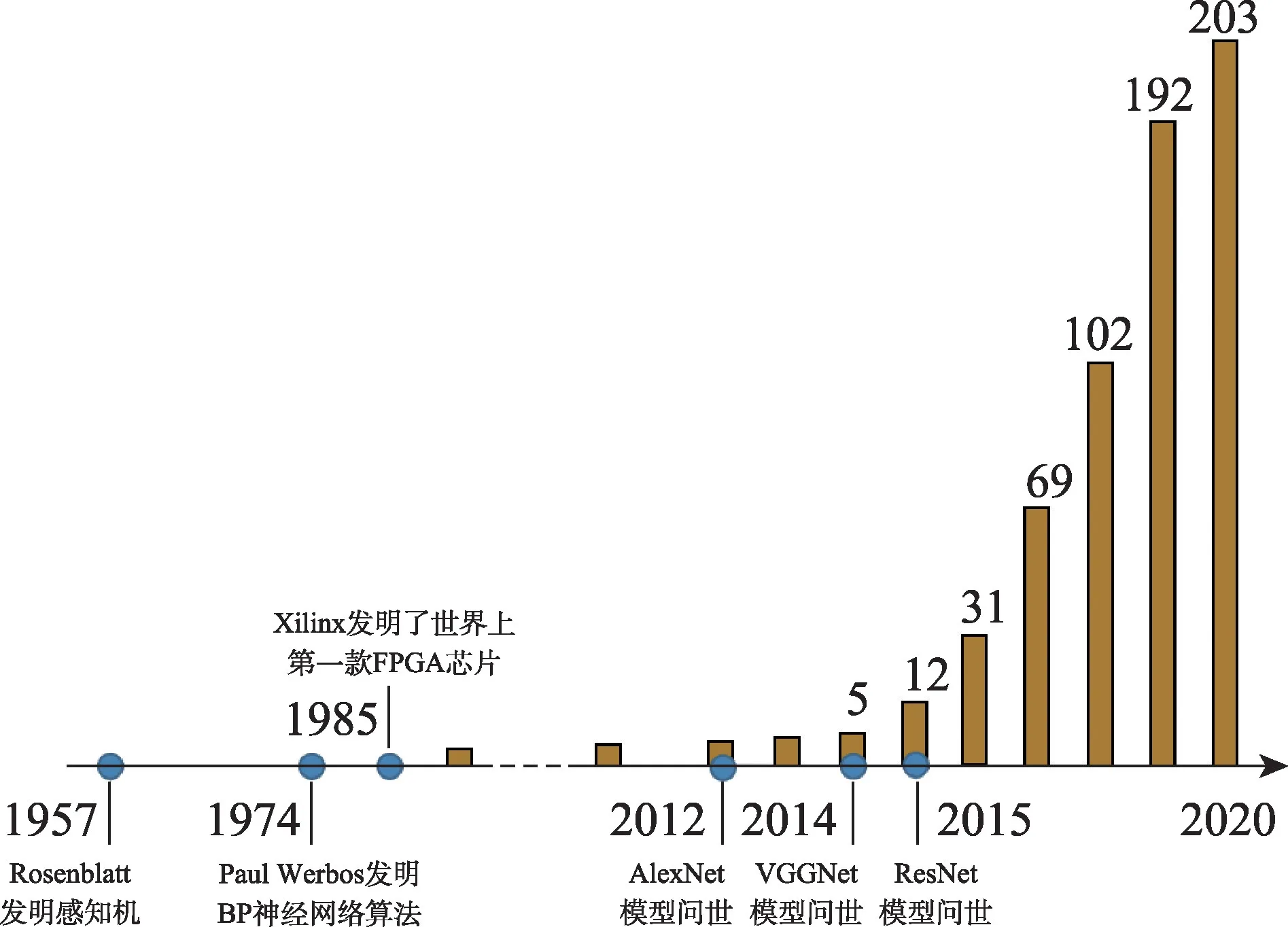
Fig.4 Development history of neural network accelerator based on FPGA图4 基于FPGA 的神经网络加速器发展趋势
2.1 卷积神经网络的FPGA 加速器
FPGA 加速卷积神经网络的关键在于提高计算能力和数据传输速度[23-26],通常采用提高卷积神经网络中并行计算能力的方法来提升计算效率以及利用减少数据量、减少访存次数等方式来解决数据传输开销大的问题。
为了解决卷积神经网络中制约计算能力的计算吞吐和内存带宽不匹配的问题进而提高计算能力,文献[27]设计了如图5 所示的硬件结构。
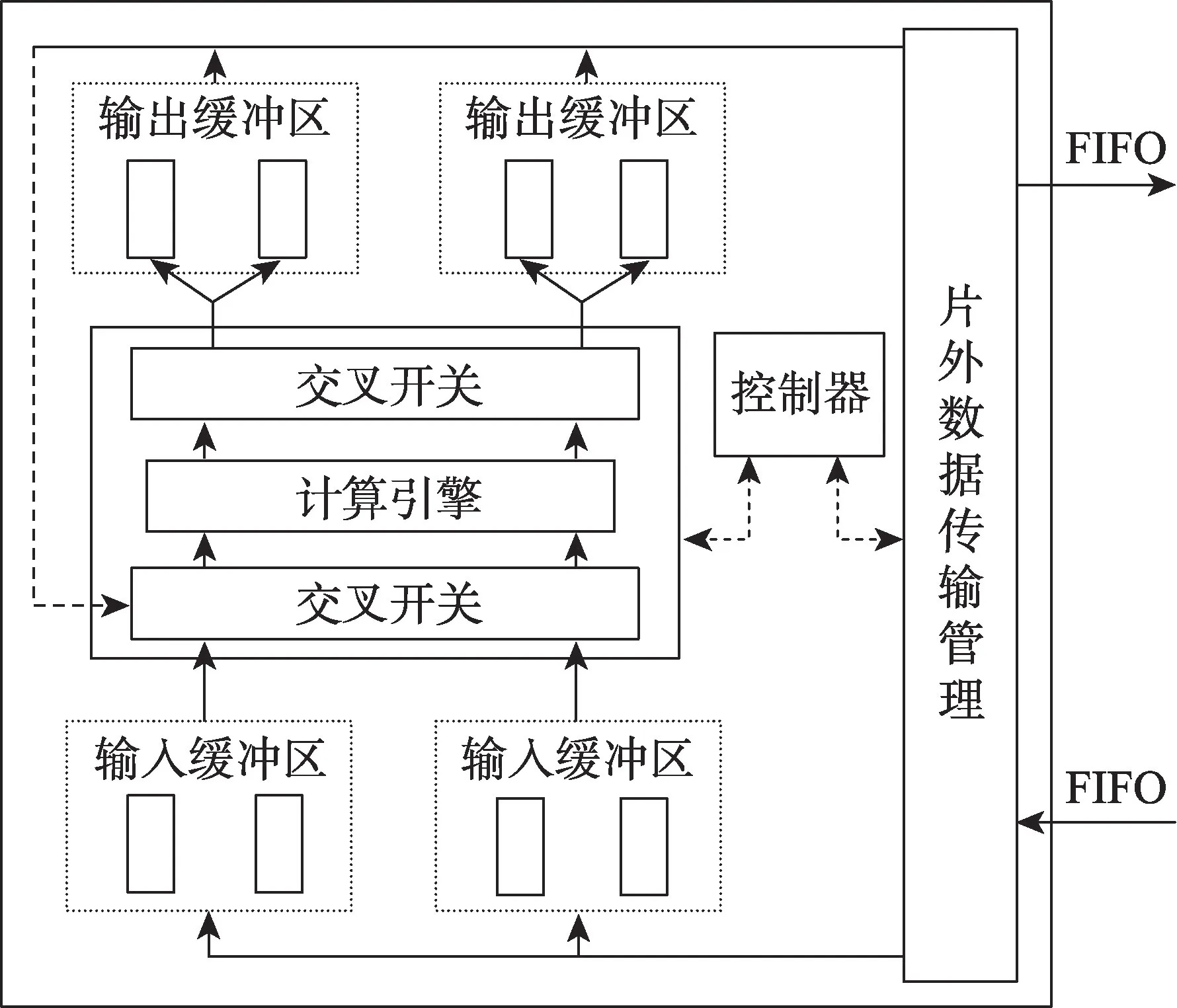
Fig.5 Block diagram of proposed accelerator图5 基础硬件结构图
这种结构在输入和输出部分分别采用两个缓冲区并使用“乒乓”的数据传输机制,得以使用计算时间来掩盖数据传输时间,并且计算引擎内部是底层乘法器联合多层加法器的“树形”结构,多个计算引擎并行进行不同卷积核的卷积操作,由此减少了程序执行时间,进而很好地改善了计算吞吐和内存带宽不匹配的问题。这种结构在Virtex7 VX485T 平台上达到了61.62 GFLOPS 的峰值性能,远超CPU(Xeon E5-2430)的12.87 GFLOPS[27]。虽然这种结构设计取得了优异的性能,但是从整体来看,该结构并未考虑全连接层的模型参数优化,因此处理更为大量的数据所产生的传输开销可能会限制实际的性能表现;并且这种“树形”结构的计算引擎只能处理规则的卷积操作,不适应于经过稀疏性处理的卷积神经网络。由此可见,随着不规则卷积计算越来越多的应用,该结构的使用场景可能会受限。
另外一些研究在努力提高卷积神经网络的计算能力的同时,通过使用大量寄存器代替BRAM 的方法来降低结构对外部接口的带宽需求[28],其最终速度在FPGA(Virtex7)平台上比CPU(i7 4790K)快16.42倍[28]。还有学者使用基于移位寄存器的串矩转换结构和基于脉动阵列的卷积层和池化层运算单元[29],这种架构可以搭建任意规模的CNN 模型,并且提高了频率和计算吞吐量,减小了输入、输出带宽需求。另外,还可以将FPGA 的片上资源划分成多个小处理器来提高计算能力[30],使用多个FPGA 加速卷积神经网络来提高整体的计算吞吐等[31-32]。为了有效解决片上存储器带宽对性能的限制,学者提出一种新的内核设计[33],在计算、片上和片外存储器访问之间提供最佳的平衡。
此外,可以使用二值神经网络来降低数据精度提高数据传输速度,进而提高卷积神经网络的计算效率[34-35]。文献[34]使用如图6 所示结构的处理单元和乘法单元。在处理单元中,使用一个本地RAM 来保持网络权重并且将权重打包成bit 值来提高处理效率;在乘法单元中,使用同或门替代乘法器来降低计算难度并提高计算效率。这种降低FPGA 片上资源的使用、减小计算难度来实现加速的优化思路十分值得借鉴,在后续其他相关研究中也有很多应用。在150 MHz的频率条件下的VGG8 模型中,此方法获得的能效比是GPU(GTX Titan X)的10 倍[34]。由于该设计重点关注的是计算结构,而忽略了数据交互相关的优化,其加速性能还有提升的空间。
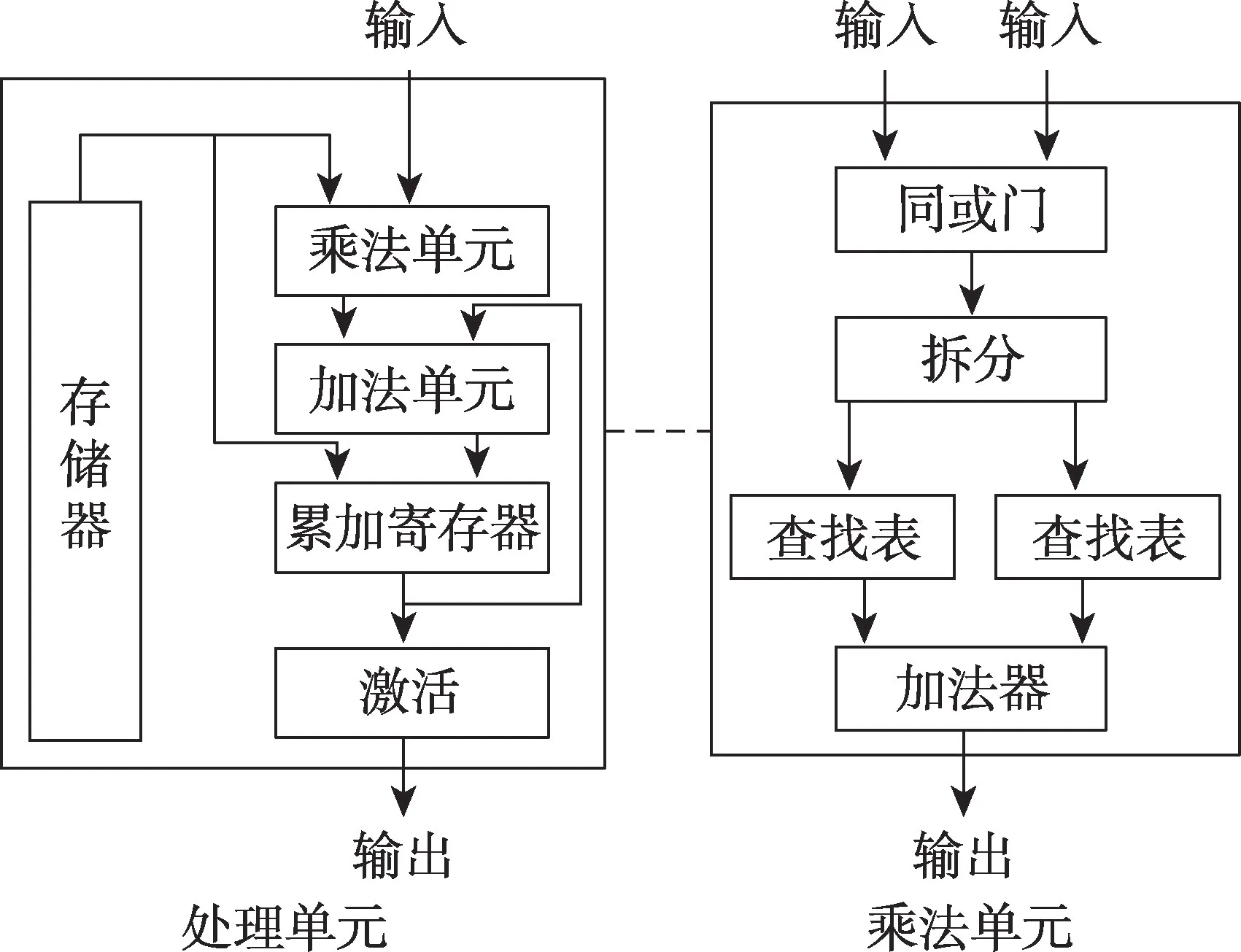
Fig.6 Proposed accelerator for binarized neural networks图6 二值神经网络硬件结构
同时,还有学者提出了一种动态精度数据量化的方法[36],这种方法可以使神经网络不同层对应的定点数的整数和小数位数不同,进而实现了在找到更短的定点数位数的同时保持需要的准确率。
2.2 递归神经网络的FPGA 加速器
基于FPGA 的递归神经网络加速器是新兴的研究领域,其设计思想在本质上与卷积神经网络加速器是一致的,都是从提高FPGA 的计算性能和资源利用的角度出发进行加速设计。目前这方面的文献主要集中在LSTM(long short-term memory)和GRU(gated recurrent unit)两种模型。
文献[37]在文献[28]设计模型的基础之上增加了LSTM 缓冲区,实现了基于FPGA 的LSTM-RNNs 加速器,这样做的好处是缓冲区可以保存状态参数而下一级计算就无需重新加载,从而降低了对带宽的要求。后面的研究利用深度压缩的算法对LSTM 进行压缩并设计了专用的编译器和处理器架构与之匹配,进一步提高了性能[38]。
对于GRU模型来说,加速的技术难点在于如何减少矩阵向量乘法操作所占用的大量时间。Nurvitadhi等通过将矩阵拆分成多个列块进而进行并行计算,最终用减少2/3 内存空间的代价换取了矩阵向量乘法减少一半的效果[39],证明了此研究方向的可行性。
3 针对具体问题的加速器
在实际工作中,人们往往会为了解决特定的问题专门定制具有所需功能的FPGA 加速器,这种定制的加速器设计难度相对较小并且能很好地解决相应的问题,因而是目前FPGA 加速器最广泛的应用形式,尤其在语音识别、图像识别和自然语言处理等特定领域,FPGA 的表现十分优异。
3.1 针对语音识别的FPGA 加速器
语音识别是指能够让计算机自动地识别语音中所携带信息的技术,具有实时性强和集成度高的特点。近年来,深度神经网络模型的发展给处在瓶颈阶段的传统GMM-HMM 语音识别技术带来了巨大变革,将识别的准确率和实时性提升到了新的高度,微软、百度、科大讯飞等多家公司将CNN、RNN 等各种网络模型成功地应用到语音识别中并不断改善系统的识别率。可见,深度学习技术对语音识别的发展有着极为重要的影响。
在加速语音识别方面,针对LSTM 模型压缩后出现的多核并行负载不均衡的问题,学者设计了专门用来加速LSTM 的剪枝算法和相应的ESE(efficient speech recognition engine)新架构[38],其硬件结构如图7 所示。
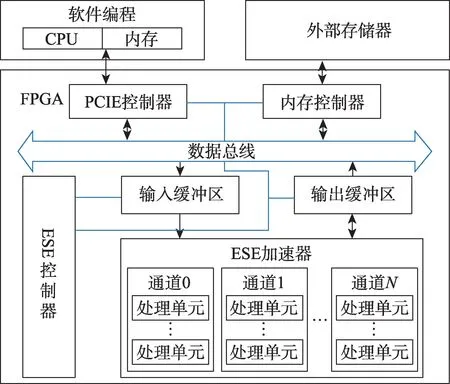
Fig.7 Overall architecture of ESE system图7 ESE 系统整体结构
该结构的核心在于FPGA 上的ESE 加速器,该加速器通过使用多个由处理单元和激活向量队列单元组成的通道单元来解决多核并行负载不均衡的问题。处理单元均采用双缓冲区结构和“乒乓”数据传输方式以提高执行效率;运行较快的处理单元可以从激活向量队列单元中获取数据继续工作而无需等待其他处理单元,从而解决了不同处理单元工作负载不平衡所带来的问题。
这种结构取得了十分优异的性能表现,在计算矩阵大小相同的前提下,与CPU(i7 5930k)和GPU(GTX Titan X)相比,Xilinx XCKU060 FPGA 平台上ESE 结构的语音识别速度分别比CPU 和GPU 快43倍和3 倍,并且能效比分别提高了40 倍和11.5 倍[38]。ESE 系统的一个优化难点也是制约其性能的关键在于FPGA 硬件加速器、CPU 软件程序以及外部存储器三者之间的任务分配和调度协调问题,处理好此问题可以使该结构在语音识别领域获得更为广泛的应用与发展。
在实际应用过程中,近几年韩国SK 公司推出的AIX(artificial intelligence axellerator)就是在ESE 结构的基础上为语音识别提供的一个解决方案,其应用于微软的开源语音识别框架Kaldi。AIX 使用了Xilinx 的FPGA 平台,充分利用了FPGA 能提供的外存访问带宽和DSP 资源。在自动语音识别中,其能效比分别是CPU 的10.2 倍和GPU 的20.1 倍,充分体现了FPGA 平台加速语音识别的强大性能。
3.2 针对图像识别和处理的FPGA 加速器
图像识别是指利用计算机对图像进行处理、分析和理解以识别各种不同模式的目标和对象的技术,是深度学习最早尝试应用的领域。2012 年,深度学习技术首次出现在ImageNet 竞赛中,成功应用到图像识别领域并以压倒性的优势超越了之前最优秀的支持向量机方案,使识别错误率大幅降低了40%,并且近年来在图像分类、图像检测、人脸识别等领域最优秀的系统都是基于深度学习开发的。
在加速图像识别方面,针对图像识别的并行计算性能受硬件资源和带宽影响的问题,屈伟根据roofline模型选取最合适的并行展开因子使得在FPGA 上具有最高的性能峰值[40]。其加速架构如图8 所示。
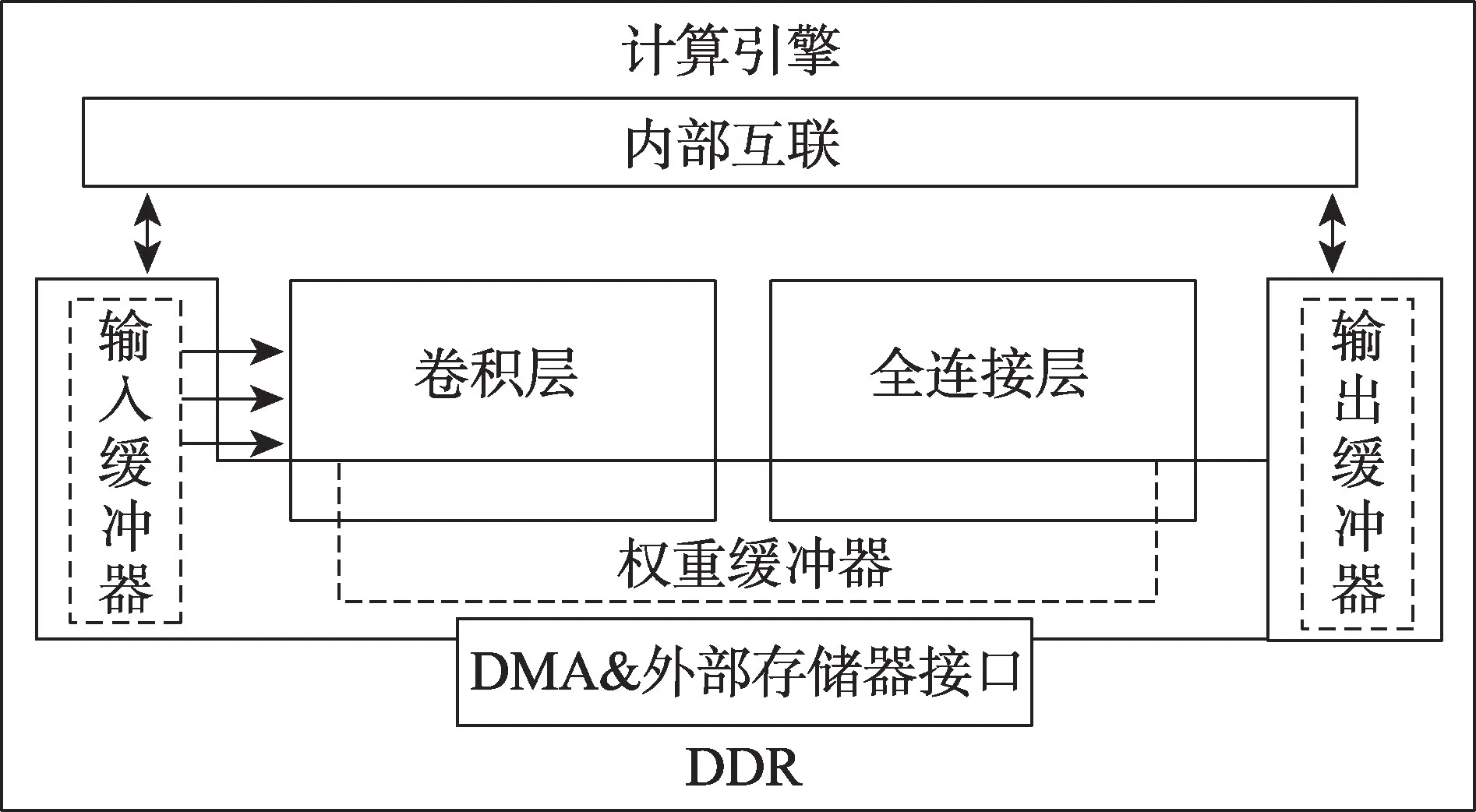
Fig.8 Overall architecture of FPGA acceleration图8 FPGA 算法加速架构
这种架构将图像从DDR 输入到FPGA 片上缓存,并且在片上本地缓存只缓存正在计算的权值,缓存的特征图作为下一卷积层的输入与卷积核再次卷积,直到得到最后输出。该方法还使用流式架构分别优化卷积层和全连接层,并且将全连接层并行展开来充分利用FPGA 的片上资源。使用ZCU102 评估板,该方法的性能峰值可达81.2 GFLOPS,远超CPU(i7 8750H)的11.7 GFLOPS,而功耗只有CPU 的25%,模型的识别精度也比GPU 高出3%[40]。此架构在实际应用过程中,由于很大程度受到计算和内存访问不具有连续一致性的影响,导致实际性能并无明显提升的同时反而增加了数据流控制的复杂性,因而从整体实用性来看,在图像识别领域相比于GPU 并无绝对优势。
在产品实现方面,针对工业、物联网和机器视觉等专业视觉应用领域,米尔科技推出的FPGA 图像处理平台展现出强大的图像处理能力,在图像识别、图像去噪和图像还原等方面均有优异的表现,具有4K级视觉处理能力的同时将延时控制在了亚毫秒级。
3.3 针对自然语言处理的FPGA 加速器
自然语言处理(natural language processing,NLP)也是深度学习的一个重要应用领域,目前基于统计的模型已成为NLP 的主流,同时人工神经网络在NLP 领域也受到了理论界的足够重视。在自然语言处理领域,基于FPGA 的处理器模型具有最先进的成果,推进了人类与嵌入式设备自然交互的应用。
在加速自然语言处理方面,针对自然语言模型数量巨大且更新较快的特点,Khan 等提出的基于FPGA的覆盖式处理器NPE(FPGA-based overlay processor for NLP model inference at the edge)可以高效地执行各种自然语言处理模型,其架构如图9所示[41]。该架构的设计思路是利用各种功能单元和对应的内存缓冲区以及FPGA 配置灵活性的特点搭建一个具有类似软件可编程性的架构以适应自然语言处理极为广泛多样且复杂多变的应用环境。
这种结构的矩阵乘法单元(matrix multiply unit,MMU)包含大量的处理单元来高速执行矩阵乘法,并将结果写入存储器,非线性向量单元(nonlinear vector unit,NVU)从MMU 存储器读取,并将结果写入MIB(MMU input buffer)[41]。其中NVU 是一个数据并行向量加载/存储体系结构,它在每个时钟周期中对多个元素执行算术和逻辑操作,可以在最小的资源开销下处理高通量非线性函数计算,由此来达到预期的加速效果,并且为了满足每个加速器不同的FPGA的设计,可以为未来的NLP 模型升级,而无需重新配置,因此NPE可以有效地执行各种NLP模型。
在Ultrascale+VCU118 FPGA 平台上,NPE 在可以满足实时对话式AI 延迟目标的同时,其功耗是CPU(i7 8700k)的1/4,是GPU(RTX 5000)的1/6[41]。除了优异的性能表现,NPE 高适应性的特点十分契合NLP 的未来发展形式,这展示出该架构以及FPGA在自然语言处理领域的广阔应用前景。
4 针对优化策略和硬件模板的加速器
4.1 针对优化策略的加速器
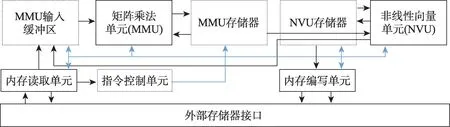
Fig.9 Overall architecture of NPE图9 NPE 整体架构
研究人员在设计FPGA 加速器时也要考虑优化策略,合理的优化可以明显提高加速器的性能以及资源利用率,目前研究较多的优化策略主要包括计算优化和内存优化。
(1)计算优化。包括提高并行计算能力、循环流水技术、循环分块和循环展开等。对于计算并行优化,Motamedi 等指出神经网络中的并行方式主要有四种,即不同层之间的并行、不同输出特征图之间的并行、像素点之间的并行和像素点计算的并行[42]。由于相邻的层与层之间存在数据依赖,实现不同层之间的并行优化最为复杂,其他三种并行方式的优化通常是研究人员考虑的重点。
对于循环展开和循环流水技术,学者通过使用循环展开形成有效的流水,流水线架构能够缩短整体执行时间[43]。
循环展开在消耗一定硬件资源的前提下形成流水线型架构,从而提高了并行度,节省了计算所需时间。文献[43]使用循环展开大幅降低了load 模块和store 模块的操作数,内核的执行时间也从未展开时的1 110.096 ms 降低为循环展开后的46.620 ms。但循环展开并不是万能法则,在使用循环展开时必须要充分考虑循环中数据之间的关系、卷积核大小等问题并以此来确定对应的硬件设计,防止出现事倍功半的结果。
(2)内存优化。包括减小数据精度和层间数据复用等。对于计算的操作数,在不损失准确率或者准确率损失较小的情况下用定点数代替浮点数是可行的[44]。
神经网络通常是流式结构,因此每层的计算都需要片下存储的访问,文献[45]使用了层与层之间融合的方法,更好地解决层与层之间数据复用的问题。这种方法使用金字塔状的多层滑动窗口对输入数据进行处理,进而可以得到后面几层的结果。四层单金字塔和多金字塔结构示例如图10 所示。
在单金字塔结构中,所有层都融合成一个金字塔,这样只能加载第一层的数据并且只有第四层的输出存储到动态随机存储器。相比之下,在多金字塔结构中,第三层输出必须存储到动态随机存储器并且需要读回以组成第二个金字塔,这种结构使得输入和输出的结果更小,从而减少了所用模型的计算量。

Fig.10 Example of single pyramid and multi-pyramid applied over four layers图10 四层单金字塔和多金字塔示例
实验使用VGGNet-E 中的前五个卷积层融合的CNN 加速器与赛灵思Virtex-7 FPGA 加速器进行比较,结果证明这种多金字塔融合卷积层的方法减小了95%的片外存储访问[45],计算效率得以提高。
不论是面向计算还是内存的优化,其目的都在于降低FPGA 的计算复杂度,提高数据交换能力以及资源利用率。由于其思路简洁、成效颇丰,这些针对优化策略的加速设计在未来将会获得科研人员持久且广泛的关注与重视。
4.2 针对硬件模板的加速器
研究人员使用现成的硬件模板来设计加速器是另一种可行方案,因为这些FPGA 硬件模板已经实现了某些编程模型,人们只需针对自己的具体问题再进行模块完善和配置参数即可,但是目前对于这种通用硬件加速器框架的研究还很少。在深度神经网络研究中,传统的加速器设计流程可能使得FPGA 开发人员难以跟上深度神经网络创新的快速步伐,针对这一问题,有学者提出了一种FP-DNN 的框架[46],如图11 所示。
这种端到端的框架使用TensorFlow 描述的DNN作为输入,并用RTL-HLS 混合模板作为硬件生成器在FPGA 上自动生成硬件实现:使用RTL 来设计高性能计算引擎并使用基于OpenCL 的HLS 框架来实现RTL 部分的控制逻辑,从基于软件的模型描述到基于FPGA 的模型推理实现,此程序都是自动完成,无需任何人工干预。
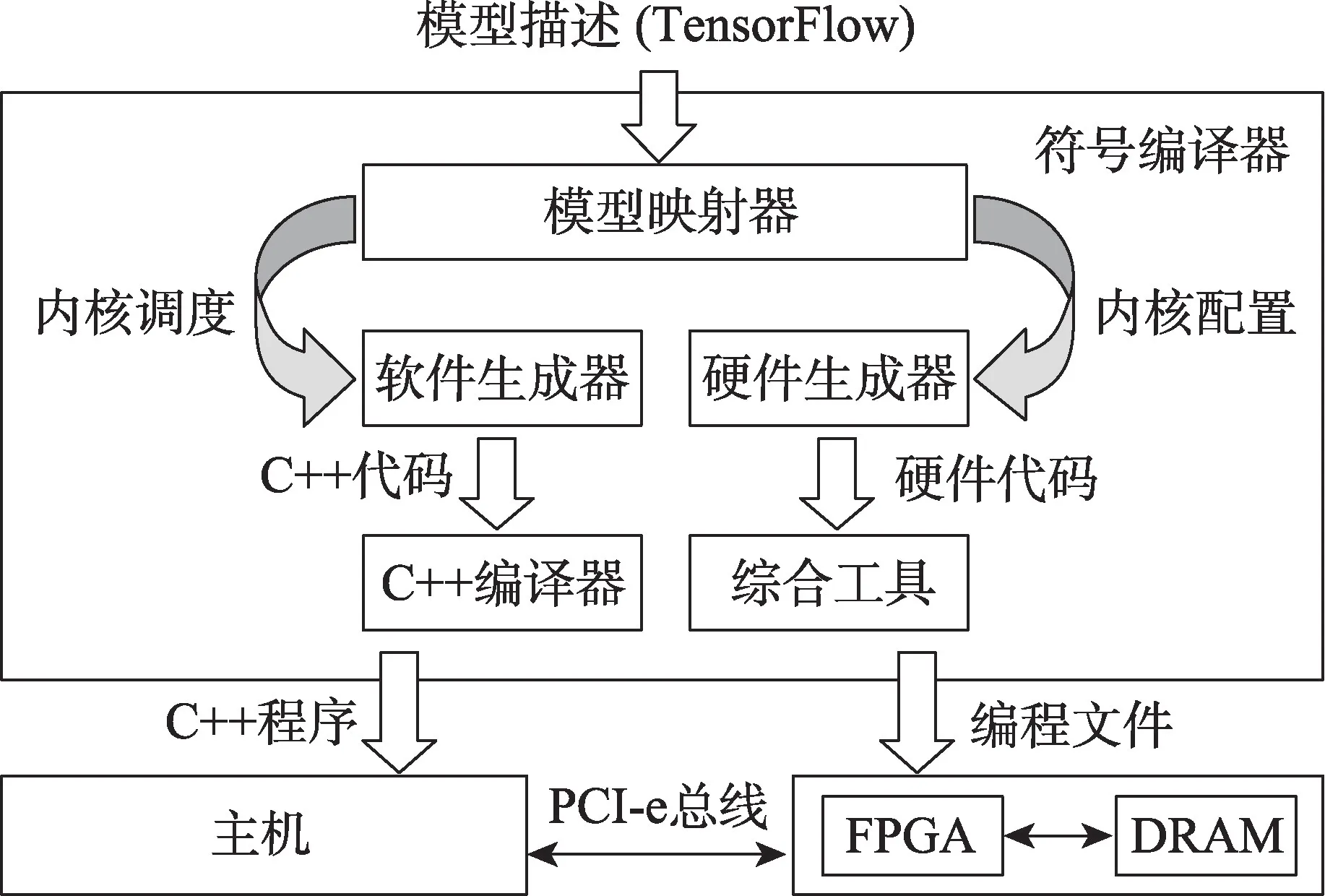
Fig.11 FP-DNN framework图11 FP-DNN 框架
实验结果表明,在VGG-19 模型中,Stratix-V GSMD5 FPGA 平台的16 位定点计算性能大概是CPU(Xeon E5-2650v2)平台的2 到3 倍,能量利用率也达到了20 倍,并且相比于传统开发设计流程,所用开发实现时间缩短了20%左右[46]。在实际使用过程中,由于计算内核需要与芯片外的DRAM 进行输入输出通信,带宽问题可能会成为整体性能的瓶颈,因此必须选择恰当的方案来优化不同层的DRAM 带宽,例如在卷积层使用Row-major 的方式存储输入特性以避免数据重复,或者使用Channel-major 的方式来扁平输入矩阵等。
5 性能比较
通过前面对各种FPGA 加速深度学习的模型和框架的分析,将其测试和仿真结果与相应的CPU 和GPU 平台的结果相比较,客观评价FPGA 加速深度学习的各种性能表现。
5.1 针对网络模型和硬件模板的加速性能分析
在LSTM、VGG 和Res-Net 三种模型中,FP-DNN(Stratix-V GSMD5)、CPU(Xeon E5-2650v2)和GPU(GTX TITAN X)性能对比如表1[46]所示。
根据表1 可以得到,FPGA 加速VGG 模型的效果最好,其性能稍高于LSTM,明显高于Res-Net,并且16 位定点数相比于32 位浮点数的表现更为出色[46]。不论何种网络模型,采用16 位定点数的FP-DNN 的功耗和能效相对于CPU 和GPU 有较大优势,其性能峰值是CPU 的1.9~3.06 倍。
虽然FP-DNN 在性能上无法与GPU 竞争,但是这种设计和使用通用加速器框架的思路仍然具有进一步的研究价值。同样,由于人工智能的网络结构越来越不局限于传统的卷积形式,具有可重构性的FPGA 便脱颖而出,未来关于FPGA 加速神经网络的研究成果会越来越多,其应用也会越来越广泛。

Table 1 Performance comparison of different networks on different platforms表1 不同模型在不同平台的性能对比
5.2 针对具体问题的加速性能分析
针对语音识别的加速器性能对比如表2[38]所示,所用硬件平台为i7 5930k(CPU)、GTX Titan X(GPU)和XCKU060(FPGA),网络模型为LSTM。

Table 2 Performance comparison of speech recognition on different platforms表2 语音识别在不同平台的性能对比
针对图像识别的加速器性能对比如表3[40]所示,所用硬件平台为i7 8750H(CPU)、GTX 1070(GPU)和ZCU102(FPGA),网络模型为VGG。

Table 3 Performance comparison of image recognition on different platforms表3 图像识别在不同平台的性能对比
针对自然语言处理的加速器性能对比如表4[41]所示,所用硬件平台为i7 8700K(CPU)、RTX 5000(GPU)和Zynq-7100(FPGA),所用基准为FTRANS(Ultrascale+VCU118)加速器。
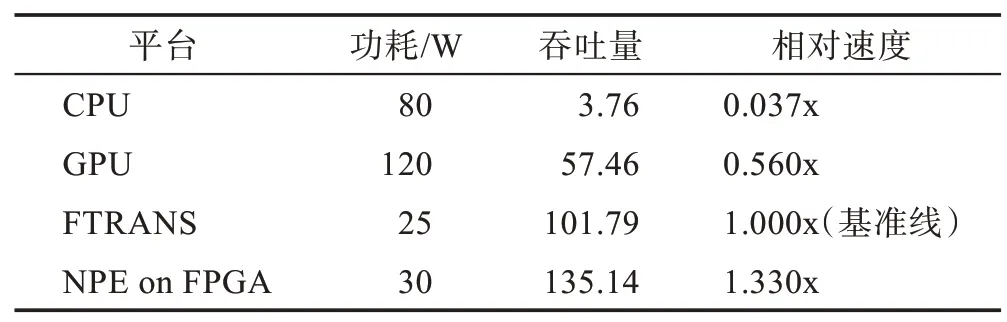
Table 4 Performance comparison of natural language processing on different platforms表4 自然语言处理在不同平台的性能对比
观察表2~表4 可以得出,在三个领域之中,FPGA在语音识别和自然语言处理领域获得的加速效果更明显,在功耗以及速度方面均击败了CPU 和GPU,但FPGA 在图像识别领域的峰值速度不及GPU,在这种情况下,FPGA 的优势在于其识别精度略高于后者。
综合仿真结果以及FPGA 在这些领域的发展现状,FPGA 在语音识别以及自然语言处理领域有着巨大的发展潜力和广阔的应用前景,尤其在人工智能实时会话等实时性要求很高的领域,FPGA 凭借其低延时、高性能的优势可以很好地满足人们的需要。相比之下,FPGA 在图像识别和处理领域也有其一席之地,特别是在可定制、可升级、需求量不大的军工和医疗等领域,但是就总体的应用广泛程度而言,FPGA 还远不能撼动GPU 的地位。
5.3 关于FPGA 集群
FPGA 集群的性能对比如表5[32]所示,所用硬件平台为Virtex7 XC7VX690T(FPGA)、GTX Titan X(GPU),网络模型为VGG。
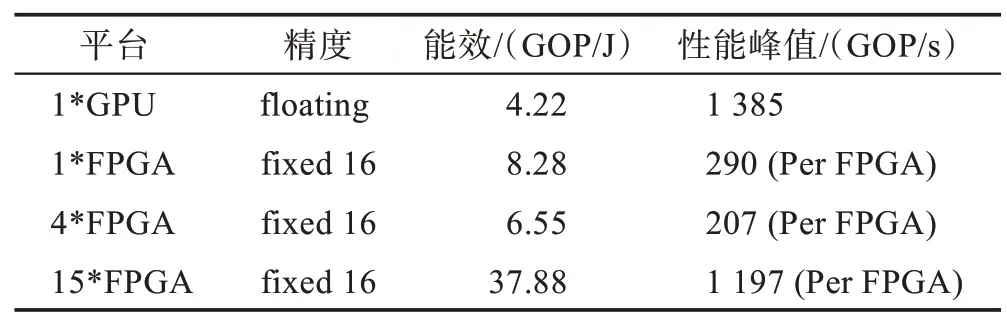
Table 5 Performance comparison of different cluster-levels表5 不同集群级的性能对比
从表5 结果可以得出,15*FPGA 集群相比于单FPGA 在性能和能效上有较大提升,并且性能峰值已经接近GPU,但是4*FPGA 集群性能和能效却不及单FPGA,这说明了多FPGA 集成时需要注意的问题:各个FPGA 之间的权重分配、各种映射策略的平衡以及通信带宽的限制,一旦没有很好地解决这些问题,FPGA 集成取得的结果可能是事倍功半,这也在一定程度上限制了其发展。
6 总结与展望
随着深度学习的不断发展,加速深度学习的研究近年来备受关注,虽然FPGA 凭借其可重构、低能耗等优势在加速深度学习方面取得了一定成绩,但是也存在硬件编程困难以及重构过程时间成本较大等不可忽视的劣势,因此FPGA 要达到更加为人们所熟知和更为广泛应用的阶段仍然有很长的路要走。根据目前的发展形势可知,未来重点研究方向主要为以下几点:
(1)激活函数优化。目前在FPGA 计算优化中对矩阵运算的循环部分研究居多,而对激活函数优化改进的研究很少,因而这是一个有待挖掘的领域。
(2)数据优化。采用低位数据可以提高模型的加速性能,但是也带来了精度较低等劣势,未来可以加强动态精度数据量化的研究,使神经网络不同层对应的定点数的整数和小数位数不同,进而实现在找到更短的定点数位数的同时保持需要的准确率。
(3)FPGA 集群。集成多个FPGA 芯片的性能表现十分优异,问题在于如何处理好各个芯片之间的处理调度和分配问题,下一步可以从各种细粒度的划分以及各芯片之间的权重分配出发来研究提高片上存储器利用率,降低存储需求。
(4)通信效率的提升。带宽始终限制着FPGA 加速深度学习的实际效果,在未来可以从减少深度学习模型的带宽需求以及变更体系结构的角度出发优化通信机制,进而提高FPGA 与其他硬件之间的通信效率。
可以预见,深度学习作为机器学习的革命性实现方法在未来有广阔的发展前景。同样,基于FPGA的深度学习加速技术也会渐入佳境、日新月异,最终促进整个人工智能领域的变革和发展。
猜你喜欢
现代装饰(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
小哥白尼(趣味科学)(2022年5期)2022-08-15
现代仪器与医疗(2022年3期)2022-08-12
舰船科学技术(2022年11期)2022-07-15
国际商业技术(2022年4期)2022-04-21
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
数码世界(2019年6期)2019-09-09
