
基于卷积神经网络的眼疾识别算法
2021-11-14 01:22:20娄茹珍蒋正乾申林山
无线电工程 2021年11期
娄茹珍,徐 丽,蒋正乾,申林山
(哈尔滨工程大学 计算机科学与技术学院,黑龙江 哈尔滨150001)
0 引言
图像分类是计算机视觉领域的热门研究方向之一[1],也是实现物体检测、人脸识别[2]、姿态估计[3]等研究的重要基础。图像分类技术具有很高的科学研究和实际应用价值,因此,图像分类与医学影像相结合成为研究的重点[4]。图像分类技术是指使用一种或者几种分类算法对输入的图像数据进行类别标注,应用场景较为广泛,例如:学生宿舍门口的人脸识别门闸就是人脸识别技术的一种具体实现;心脏病辅助诊断机器人通过对心电图图像的分类进行心律不齐的诊断也是图像分类技术的应用[5]。
根据数据统计发现,近年来,近视患病率呈现逐年增高的发展趋势,对人们的身体健康产生了严重的消极影响,在近视眼患者中有超过35%的患者患有重度近视[6]。近视会拉长眼睛的光轴,也有一定可能会带来视网膜或者络网膜的恶性病变。当近视度数逐渐加深会演变成高度近视便可能产生病理性病变,病理性病变会导致以下几种症状:络网膜或者视网膜发生退化、Fuchs斑和视盘区域萎缩等。因此,尽早地发现近视患者眼睛的病理性病变并及时采取治疗非常重要。在临床实践中,诊断和治疗策略的成功依赖于成像数据的评估,需要专家进行分析诊断。对眼成像数据的解释需要花费大量的经验和时间成本,因此,迫切需要具有与人类相当精度的模型来解决这个问题。利用人工智能技术能够帮助眼科医生阅读图像,并辅助医生对眼疾疾病的诊断,图像分类处理作为人工智能的热门研究领域,可以有效地应对该问题,本文运用卷积神经网络对眼底视网膜图片进行分类判定,输入视网膜图像可以给出相应的眼疾判定结果。
1 数据处理
数据处理主要包括数据采集和数据预处理过程。
本文使用的数据为眼底视网膜图像,数据主要来自百度大脑和中山大学眼科中心联合举办的人工智能比赛的数据集。该数据集包括 1 200个志愿者的视网膜图像数据。因为使用的分类算法是一种有监督学习的机器学习方法,所以要对数据集进行分割和标注,眼底视网膜图像数据集是一种公开数据集,项目方已经完成了数据标注工作。为了实现均衡,使用1∶1∶1的比例进行数据分割,即用来训练验证和测试的数据集各400张,分别存储在相应的文件夹下,使用P开头的文件名表示病理性近视、使用非P开头的文件名表示非病理性近视。方便后面进行模型训练和模型验证工作等的进行。
详细数据如表1所示。
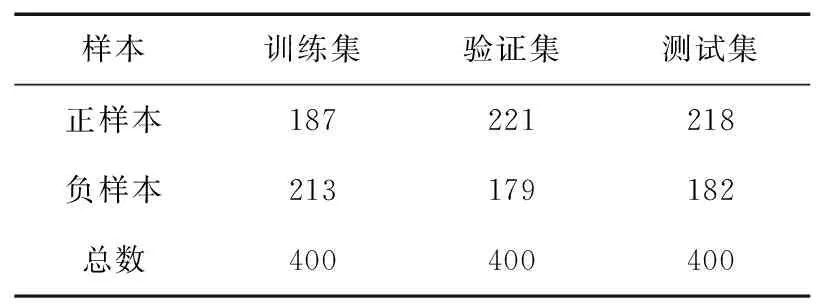
表1 数据统计Tab.1 Data statistics sheet 单位:张
预处理过程主要包括图像压缩和数据的标准化处理,图像压缩将读取的图片缩放到224 pixel×224 pixel大小的格式,便于后面神经网络的读入和处理。
数据的标准化是将数据按比例缩放[7],使用一定的方式将原数据映射到一个相对较小的特定区间内,一般为[-1,1]。在进行比较和评价时经常使用数据的标准化方法对指标进行处理,通过数据的标准化可以去除数据的单位限制,将带有单位或者不同量级的数据转化为没有量纲的纯数值形式,便于不同单位或量级的指标能够进行比较和加权,具体处理过程为使用式(1)和式(2)将数据映射到[-1,1]范围上:
(1)
x**=2×x*-1,
(2)
式中,x表示原变量;min表示变量中的最小值;max表示变量中的最大值;x*是将x缩放在[0,1]之间的值;x**表示映射到[-1,1]范围上的结果。经过标准化处理后的数据可以在一定程度上提升模型的收敛速度和精度。
2 分类方法
有监督学习的图像分类方法中使用最多是卷积神经网络[8],本文运用的卷积神经网络的几种变形实现图像分类。分类算法的总体流程如图1所示。

图1 分类算法流程Fig.1 Flow chart of classification algorithm
使用的神经网络分类模型分别是AlexNet模型[9]、VGG[10]模型和GoogLeNet模型[11]。
2.1 卷积神经网络
卷积神经网络是一种专门用于处理二维图像数据的神经网络模型,可以提取特征时保留相邻像素的关系,在视觉处理方面应用广泛。卷积神经网络一般由5部分组成:卷积层、池化层、激活函数、批量标准化层和全连接层。卷积神经网络的核心是卷积层,该层执行称为“卷积”的操作。
卷积层和池化层是卷积神经网络的关键层。卷积其实是一个数学运算符,它通过2个函数f和g结合产生第3个函数,每个卷积层包含一系列称为卷积核的滤波器,滤波器的形状是一个整数矩阵,其大小与内核相同,用于输入像素值的子集。每个像素乘以内核中的相应值,然后将结果求和为一个简单的值,以简化表示输出通道/功能图中的像素之类的网格单元,通过使用不同的卷积核可以实现提取图像不同特征的功能。
池化层通常位于卷积层之后,主要作用是缩小下一个卷积层的输入体积的空间尺寸(宽度×高度),但是池化操作并不会影响体积的深度尺寸。池化层与卷积层操作非常相似,它采用的是一个滑动窗口或某个跨输入的步幅移动的特定区域,然后将这些值转换为要代表的值。通过从窗口中可观察到的值中取最大值(称为“最大池”)或取这些值的平均值来执行转换。
2.2 AlexNet模型
AlexNet是Alex Krizhevsky等人在ImageNet比赛中以很大优势获得冠军后,将比赛中使用的模型整理后发表在论文中介绍的一种网络结构,AlexNet卷积神经网络模型由5个卷积层和3个全连接层组成[12]。模拟测试中验证,如果改变其中任何网络层次都会使得实验效果变差。AlexNet首次在卷积神经网络中使用ReLU和Dropout[13]技术,使用Dropout在一定程度上避免了模型过拟合情况的发生,激活函数选择ReLU能够有效地减少梯度消失现象的出现。AlexNet的具体结构示意如图2所示。
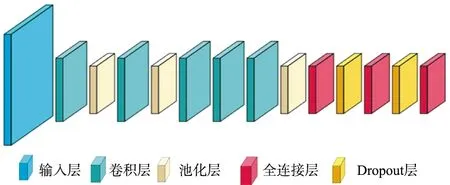
图2 AlexNet模型结构Fig.2 Structure diagram of Alexnet model
AlexNet使用卷积层和池化层来提取图像特征,使用随机梯度下降法来对模型进行训练。AlexNet模型的学习率设为0.001,经过前向神经网络计算后会得到预测值,预测值以0.5的sigmoid为阈值进行二分类。然后计算损失函数和反向传播更新参数值,最终达到预设的迭代次数后保存训练的模型,方便后面进行模型测试。
AlexNet模型所使用的损失函数为交叉熵损失函数:
loss=-[y×lnx+(1-y)ln (1-x)],
(3)
式中,x表示sigmoid(logit),logit为概率值概率,用来表示预测结果;y表示真实值。AlexNet和后面的2种有监督学习的图像分类算法均由Paddle框架实现。
2.3 VGG模型
VGG卷积神经网络模型是轻量级卷积神经网络中分类性能表现优秀的网络模型之一[14]。与AlexNet网络相比,最主要的特点为采用多个堆叠的入3×3卷积核代替AlexNet网络中较大的单个卷积核,如5×5,7×7,11×11。在使用相同的感受野情况下,相比单个大卷积核,采用小卷积核堆叠的方式能够以更少的参数量代价获得更好的非线性结果。VGG网络全部使用大小相同的最大池化层(2×2)和卷积核(3×3),保证了网络结构的简洁性模型的效果。VGG模型的具体结构示意如图3所示。
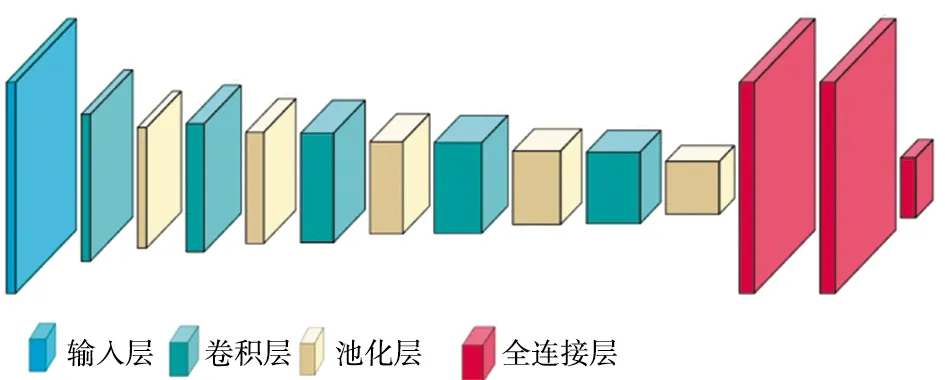
图3 VGG模型网络结构示意Fig.3 Schematic diagram of VGG model network structure
VGG卷积神经网络模型由3层全连接层和13层卷积层组成。该模型的设计严格使用3×3的卷积层和最大池化层来进行特征提取,提取完特征后使用3层全连接层进行分类,3层全连接层最后的输出代表预测概率,大于0.5的表示正例,否则为负例。VGG模型的卷积层使用ReLU函数作为激活函数,每个全连接层后使用dropout来防止模型过拟合。
2.4 GoogLeNet模型
GoogLeNet模型针对CNN的改进主要提出了Inception 的结构[15],一般的CNN结构只是单纯地增大网络,这样会产生过拟合和计算量的增加这2个缺点,增加网络宽度和深度的同时对模型的参数进行减少可以有效解决这些问题。为了减少模型参数,全连接层的稠密连接需要变成稀疏连接,在具体的实现过程中,由于目前用于神经网络训练GPU主要是针对密集矩阵的计算进行优化的,当全连接层由稠密连接变成稀疏连接后并不会大幅度减少实际计算量,虽然稀疏矩阵的数据量极大减少,但是模型训练的时间却很难减少。GoogLeNet模型使用的Inception结构在保持网络结构的稀疏性的同时,可以使用密集矩阵的高计算性能。Inception结构示意如图4所示。
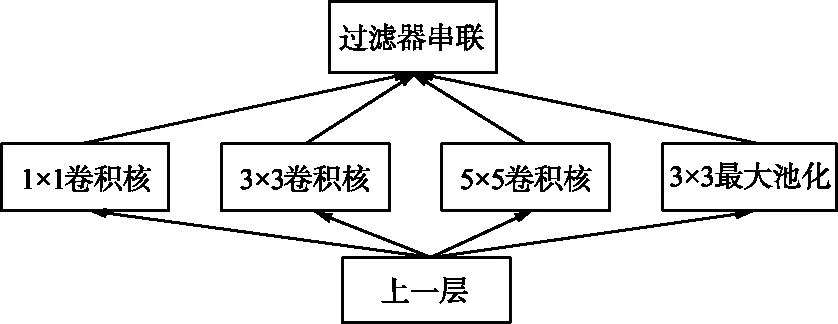
图4 Inception结构示意Fig.4 Schematic diagram of Inception structure
Inception结构由3个不同大小的卷积核和1个最大池化结构组成,4种操作同时进行,使用过滤器串联的方式将这4种操作的输出进行拼接,形成输出特征图,因为不同大小的卷积核可以提取图像的不同特征,因此Inception结构输出的特征图将汇合3种卷积核提取的不同特征。
GoogLeNet模型的具体结构示意如图5所示:

图5 GoogLeNet模型网络结构示意Fig.5 Schematic diagram of GoogLeNet model network structure
GoogLeNet模型中使用了3个softmax分类器,训练时将3个分类器的损失函数进行加权平均,可以很好地缓解梯度消失的现象。
3 实验分析
本节主要使用Python语言对眼疾图像分类进行实验,眼疾识别所使用的实验环境如表2所示。

表2 训练测试环境Tab.2 Training and testing environment
眼疾识别在计算机视觉领域属于图像分类问题,图像分类问题的损失函数一般使用交叉熵损失函数,交叉熵损失函数的计算如式(3)所示。为了对比3种模型的效果,对3种模型分别使用相同的数据集进行各100个epoch的独立实验,首先是对比3种模型的交叉熵损失函数值,横坐标表示epoch的轮数,纵轴表示交叉熵损失函数大小,结果如图6~图9所示。
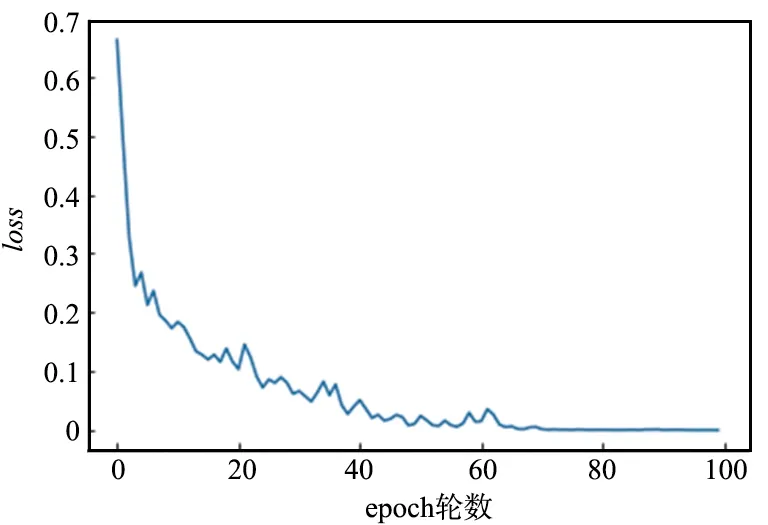
图6 AlexNet模型损失函数Fig.6 Loss function of AlexNet model
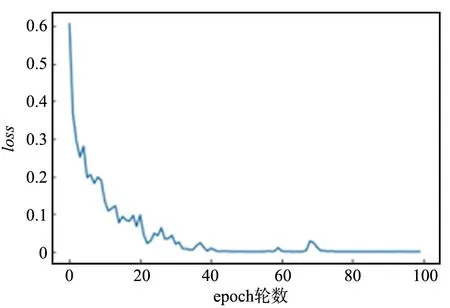
图7 VGG模型损失函数Fig.7 Loss function of VGG model
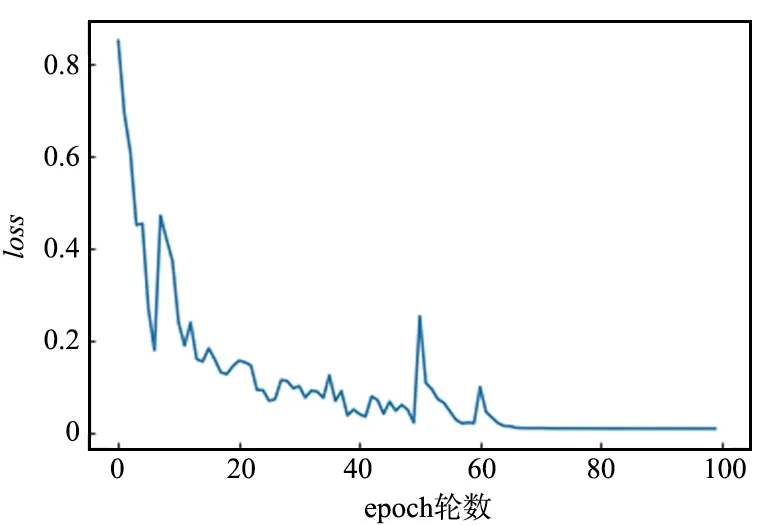
图8 GoogLeNet模型损失函数Fig.8 Loss function of GoogLeNet model
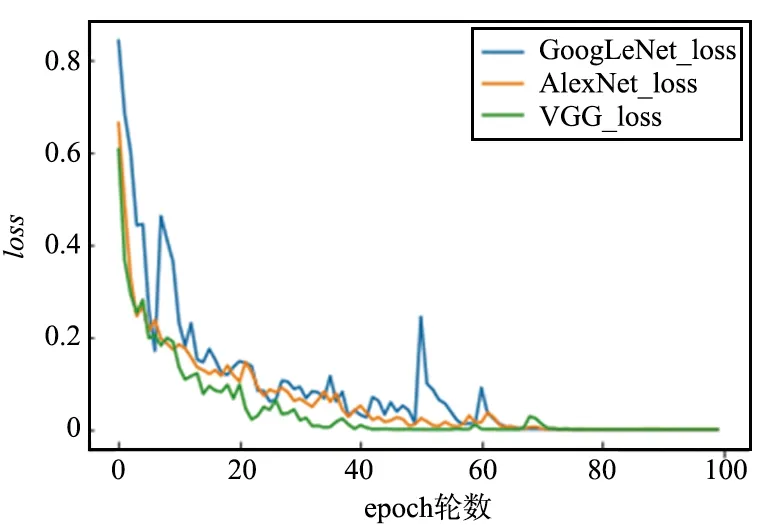
图9 3种模型损失函数对比Fig.9 Comparison of loss functions of three models
经对比分析可知,VGG模型的损失函数最先开始收敛,在第50轮epoch左右时GoogLeNet模型损失函数出现了较大起伏,但经过100个epoch的训练,3种模型的交叉熵损失函数值都达到了极小。可以看到,3种模型对于眼疾识别的训练都是有效的。
神经网络模型参数量的大小反映了模型大小,参数量越小表示模型越小巧,训练模型所使用的硬件资源越容易实现,效果相同情况下优先使用参数量小的模型。本文使用的训练数据为[400,3,224,224],其中400代表一个epoch使用的图片数量为400,3表示神经网络的输入通道数为3,2个224表示图像数据大小为224 pixel×224 pixel,使用该数据时3种模型的具体参数量如表3所示。
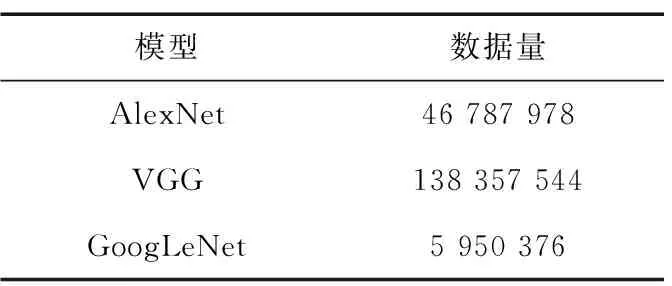
表3 模型参数量Tab.3 Parameters of three models
由表3可以看出,GoogLeNet具有最少的参数量,VGG模型的参数量最多。
准确率是衡量图像分类问题效果的重要指标,在正负样本分布均匀时,精确率可以衡量模型效果。本文使用测试集中的正负样本数量基本相等,所以选择使用准确率来衡量眼疾识别效果。精确率的计算如下:

(4)
对3种模型的准确率进行对比,几种卷积神经网络的眼疾识别算法结果如图10所示。
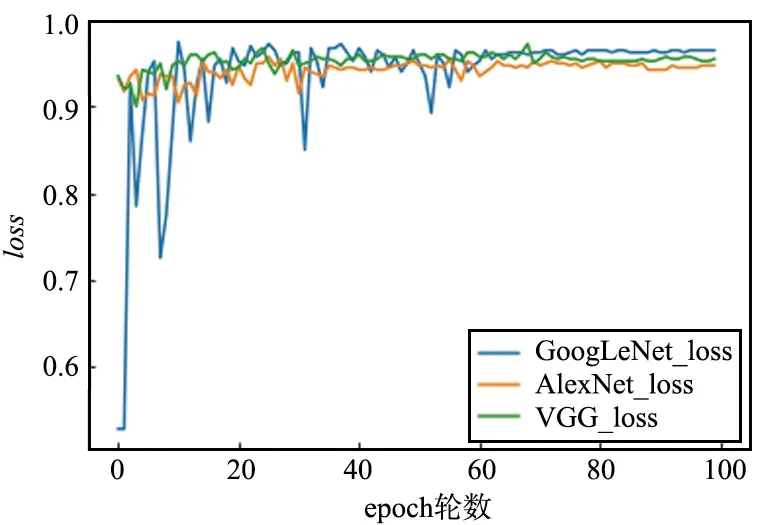
图10 3种模型准确率对比Fig.10 Comparison of accuracy of three models
由图10可以看出,经过60轮左右的训练,3种模型的准确率都达到了平稳状态。尽管GoogLeNet模型的准确率在最初的震荡最为剧烈,但达到稳定状态后GoogLeNet模型表现出了最优秀的结果。达到平稳状态后3种模型的准确率如表4所示。
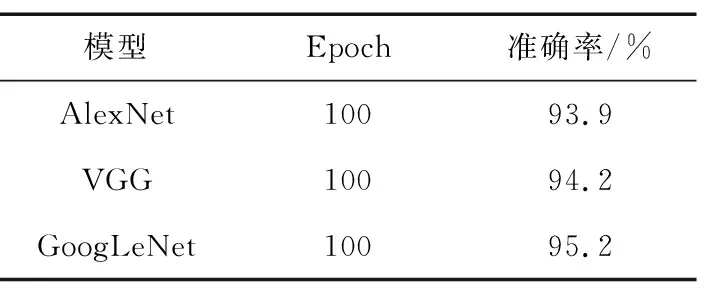
表4 分类算法结果Tab.4 Results of classification algorithm
由表4可以看出,经过100个epoch的训练,3种模型都达到了93%以上的准确率, GoogLeNet模型更是达到了95.2%的准确率,可以验证3种模型在眼疾识别问题上表现良好。由于数据集中图片数量较少,仅有1 200张,可以合理预测,如果数据集的数量级增大,模型的效果还有提升空间。
4 结束语
本文将卷积神经网络中的AlexNet模型、VGG模型和GoogLeNet模型应用于患者眼底视网膜图像进行重症近视识别,取得了良好效果。从损失函数值、模型参数量和准确率等指标对3种模型的性能进行对比实验分析,实验结果表明,GoogLeNet模型具有最高的准确率,已经达到甚至超过一般医生识别准确度,该模型可以在一定程度上辅助医生进行眼疾诊断,具有较好的应用前景。另外,在本文工作的基础上,还有以下工作有待于深入研究:细化眼疾类型进行诊断,以提升模型的功能;完善模型,在识别眼疾的同时标记出眼疾病变位置,从而进一步提高医生的诊断效率。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
中国民间疗法(2021年9期)2021-07-22 08:05:54
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
家庭医学(下半月)(2020年2期)2020-05-11 02:07:36
家庭医学(下半月)(2020年1期)2020-05-11 02:05:40
小读者之友(2019年9期)2019-09-10 07:22:44
今日农业(2019年15期)2019-01-03 12:11:33
