
基于对抗采样的社交推荐算法
2021-11-10 07:20郭贵冰姜琳颖
信息安全学报 2021年5期
赵 煜, 郭贵冰, 姜琳颖
东北大学软件学院 沈阳 中国 110819
1 引言
推荐技术虽已应用广泛, 但整个推荐领域面临的挑战却依旧存在, 如数据稀疏、数据噪声等[1-2]。其中, 数据稀疏对于推荐性能有举足轻重的影响,例如淘宝上有近百亿商品, 一个用户平均能浏览一千件商品, 那么稀疏度能达到千万分之一或以下的量级, 这就使得很多仅使用用户—物品交互数据进行训练的传统协同过滤算法效果并不是很满意。
缓解数据稀疏的一个有效办法是利用其他数据域的知识来增强原数据域, 设计更为精细的模型[3-6]。其中, 社交关系数据是非常有用的知识[7-8], 在社交领域, 人们的偏好很大程度上会被其有关联的朋友所影响[9-10]。从图1 中可知, 基于社交的推荐算法中一般涉及用户—物品域和用户—社交域, 前者代表用户与物品的交互, 后者则代表用户与用户之间的社交关系。两个数据域之间通过公共的用户作为桥梁进行信息迁移, 那么同时使用这两种信息对用户进行建模, 能有效降低用户—物品域的数据稀疏性,提高推荐性能[5-8]。
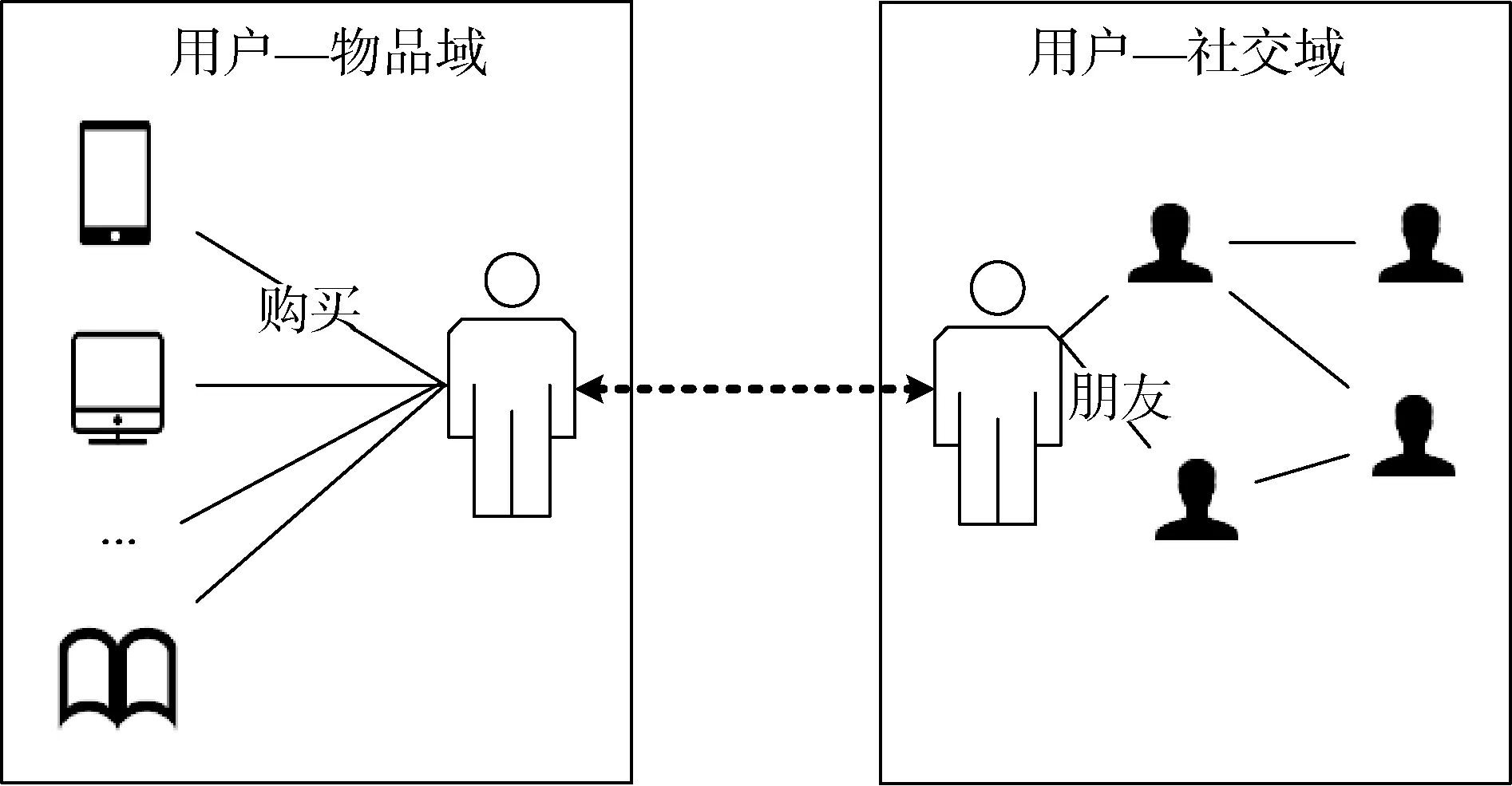
图1 社交推荐算法涉及的两个数据域Figure 1 Two data domains in social recommender
然而, 直接使用这种显式的社交关系来改善推荐性能的方法虽然通常能取得一定的效果, 但不容忽视的是社交网络非常稀疏, 并且用户结点的偏好具有差异性[3,11]。具体来讲, 线上具有显式朋友关系的用户不一定拥有相同的兴趣偏好, “朋友”这个词是广义的, 线上社交网络中的“朋友”通常包括同学、同事、亲戚等, 用户与不同朋友的兴趣偏好各有远近,那么直接利用显式朋友的兴趣偏好进行推荐就会存在噪声。因此, 基于社交的推荐算法需要在利用社交信息之前重构社交网络, 找到用户偏好真正相似的朋友, 以减少偏好差异较大的朋友带来的噪声。
除此, 目前大部分基于排序的推荐算法通常使用用户与物品的交互记录(如点击、观看历史)进行训练。如果用户与物品有交互记录, 就认为用户喜欢该物品,没有则认为用户不喜欢[7,12]。这些算法直接对用户没有交互过的物品进行随机采样, 然后将其作为用户实际交互过的物品的负样本来优化模型, 但用户没有交互过的物品不一定代表用户不喜欢, 所以直接利用上述粗略的采样策略得到的负样本也会存在噪声。文献[3]和文献[7]则利用社交信息, 不仅对用户没有交互过的物品进行随机采样, 也对用户朋友交互过的物品进行采样, 进一步细化了采样策略。其根据“相比于未交互的物品, 用户更偏爱其朋友交互过的物品”的假设, 将朋友交互过的物品作为用户实际交互过的物品的负样本, 将用户未交互过的物品作为其朋友交互过的物品的负样本, 取得了不错的推荐性能。然而,这类社交推荐算法中仍然粗略地对未交互过的物品进行随机采样, 并且受到上述社交网络差异性的影响,依然存在大量噪声。因此, 需要更为细粒度的采样方法来降低相关算法中存在的噪声影响。
近年来, 生成对抗网络因其在训练中捕获复杂数据分布的能力以及强大的鲁棒性被广泛应用到推荐系统中[13-15]。我们基于生成对抗网络, 提出了一种细粒度的对抗采样推荐模型(ASGAN)。具体地, 生成器首先为用户生成偏好相似的朋友, 然后从该朋友交互过的物品中同时采样出该用户可能喜欢的物品和可能不喜欢的物品, 判别器则利用两种排序方法来区分用户实际交互过的物品和生成器采样出的两类物品。随着对抗训练的进行, 生成器能重构出更为可靠的社交网络, 有效地进行社交朋友采样和物品采样, 而判别器能够良好地捕获用户的真实偏好分布。本文主要贡献简要如下:
(1) 针对显式社交信息和物品采样策略存在的噪声问题, 我们基于生成对抗网络提出了一个细粒度的对抗采样推荐模型ASGAN, 实现了端到端的训练与推荐。
(2) 我们在生成器中结合图表示学习思想初始化社交网络, 然后利用Gumbel-Softmax 技术进行朋友采样和细粒度的物品采样, 并在判别器中使用两种排序方法来鉴别采样出的3 类物品。
(3) 我们在3 个真实的数据集中进行了详细的实验, 并与6 个现有的相关算法对比, 证明了ASGAN的有效性。
2 相关工作
2.1 社交推荐算法
社交推荐领域早期的研究中主要使用显式的社交关系来改善推荐性能, 例如文献[16]和文献[17]通过共享一部分公共用户在物品域和社交域中的特征对用户—物品交互矩阵和用户—社交矩阵进行分解。文献[7]提出了一种经典的基于社交的贝叶斯排序方法。文献[5]则使用图卷积神经网络聚合用户多阶的显式社交关系, 以便捕获更精准的用户偏好。以上研究都把关注点放在了对显式社交关系的使用上, 却忽略了社交数据本身的稀疏性和差异性, 反而不能达到满意的推荐效果。
那么另外一种挖掘“隐式朋友”的代替方案就显得更加可靠, 所谓“隐式朋友”就是在社交网络上并没有显式连接却有着相似偏好的用户, 或者偏好真正相似的显式朋友。例如, 文献[18]基于文献[8]的模型使用Hellinger 距离来抽取隐式的社交关系。文献[11]使用一种异构网络嵌入的方式来挖掘隐式社交关系。文献[3]利用了文献[11]中获取的隐式朋友作为生成对抗网络模型的输入来生成社交关系, 但其严格意义上并不是一个端到端的模型。我们的ASGAN 则使用了类似图表示学习的方法来初始化社交网络, 同时维持社交网络的总体信息和各用户结点自身的社交信息, 然后与细粒度的对抗训练相结合来重构出更为真实可靠的社交网络, 有效降低了显式社交信息带来的噪声影响。
2.2 对抗采样推荐算法
负样本采样器在基于隐式反馈的推荐算法中不可或缺[7,12], 当前存在的负样本采样器可以大致分为两类: 静态采样器[12,19]与适应性采样器[13,20]。静态采样器使用一个固定的采样分布来抽取负样本, 而适应性采样器则根据模型的参数和状态动态地抽取负样本, 并且根据采样结果调整采样分布, 往往能取得更优的采样效果。
由于生成对抗网络优秀的拟合分布能力以及良好的鲁棒性[21-22], 其生成器能够作为适应性采样器,这衍生出了许多对抗采样推荐算法。例如, 文献[13]使用生成器采样出用户可能喜欢的物品, 并使用判别器判断该样本是用户实际交互过的物品还是生成器生成的物品, 证明了利用生成对抗网络在推荐系统中进行负采样的有效性, 但其使用的单个离散索引的训练方式使得生成器采样出的物品过早地与样本中真实的隐式反馈拟合, 致使训练后期的性能退化。类似地, 文献[23]也利用生成器生成样本来补充原始的用户—物品交互数据, 从而增强推荐性能。不同于以上的方法, 文献[15]则并没有将生成器既当做采样器, 又用做推荐, 他们提出了一种通用的成对对抗学习模型, 仅使用生成器作为采样器, 然后利用判别器对采样出的样本对进行排序, 即使用判别器进行推荐。此外, 文献[4]利用对抗采样将用户信息从社交领域迁移到物品领域以指导模型更好地进行跨域推荐。文献[3]则首先为用户生成更可靠的社交朋友, 其次再根据该社交朋友交互过的物品生成用户可能喜欢的物品作为负样本。和以上相关的方法相比, 我们的ASGAN在生成器中采用了更为细粒度的采样方式, 同时为用户采样出其可能喜欢的物品和可能不喜欢的物品, 并在判别器中采用两种不同的排序方式来鉴别采样出的物品, 有效降低了负采样策略带来噪声的影响。
3 基于对抗采样的社交推荐算法
3.1 模型概要
为了更有效地降低显式社交信息和物品采样带来的噪声影响, 我们提出了一种新颖的基于生成对抗网络的采样推荐模型ASGAN, 具体模型结构如图2 所示, 主要包含一个生成器(Gθ)和一个判别器(Dφ), 其中θ和φ代表其各自的参数。首先在生成器中使用一个自编码器重构社交网络, 更好地捕获真实可靠的社交关系, 然后利用Gumbel-Softmax 技术[24]为用户挑选出偏好相似的朋友, 接着在采样出的朋友交互过的物品集中进行细粒度的物品采样, 为当前用户挑选出其可能喜欢的物品和可能不喜欢的物品。判别器则对用户实际交互过的物品, 以及生成器采样出的两类物品组成的三元组进行排序, 捕获用户的偏好分布。如果生成器采样出的物品不符合判别器的排序目标, 那么判别器会给生成器返回梯度, 让其减少采样类似朋友以及两类物品的概率, 从而进行有效的惩罚。随着对抗训练的进行, 生成器和判别器的能力达到相对平衡,生成器能重构出更为可靠的社交网络, 并有效地进行社交朋友采样和物品采样, 而判别器能够更好地捕获用户的偏好, 达到不错的推荐效果。

图2 模型概要Figure 2 Model overview
3.2 重构社交网络
在社交领域, 人们的偏好很大程度上会被其信赖的朋友所影响[9-10], 但社交网络中各朋友的偏好具有差异性[3,11], 因此为用户生成新的朋友, 找到偏好相似的朋友, 对缓解数据稀疏和降低社交信息带来噪声的影响十分重要。为了指导生成器能够生成更为可靠的朋友, 我们设计了一个类似图表示学习[25]的自编码器(Auto-Encoder)来同时优化社交网络的总体结构信息和各用户结点自身的社交信息。挖掘朋友关系, 可以看做预测社交网络中两个用户结点的链接概率, 如果两个结点之间存在边的概率较大, 则可以认为用户偏好相似, 即可能存在朋友关系。
自编码器本身是一个半监督模型, 主要由编码器 (Encoder) 和解码器 (Decoder) 两部分组成。其目标是最小化输出和输入的重构误差, 我们基于这种结构来保持社交网络的总体结构信息。将给定用户u 的原始社交关系向量su作为输入, 对于每一个元素suv, 如果用户u 与用户v 拥有显式的社交关系则为1, 否则为0。各个隐藏层的输出可以表示为:
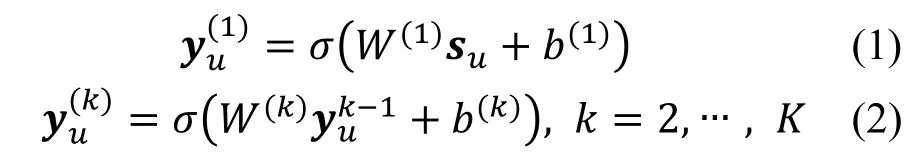
其中, k 为隐含层层数, σ为Sigmoid 激活函数。在获得后, 逆向编码器的过程可得到重构后用户u 的社交关系向量。自编码器的目标函数定义为:
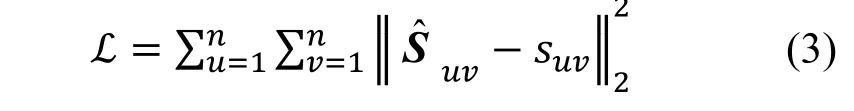
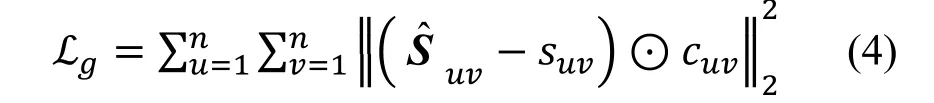
其中⊙表示Element-Wise 的乘积。cuv为惩罚矩阵C中的惩罚因子, 如果用户u 与用户v 没有显式朋友关系, 则ci,j为0, 反之ci,j大于1, 这一思想与一些基于Point-Wise 的协同过滤方法极为相似[14,26], 即只考虑非零元素的重构误差。现在通过使用修改后的惩罚矩阵C 作为输入, 保证了具有相似显式社交朋友的用户结点将被映射到相似的表示空间附近, 维持了社交网络的全局结构。
除了保留社交网络的全局结构, 捕捉局部结构也是十分必要的。当拥有显式社交关系的两个用户在映射到嵌入空间后相距很远时应给予相应的惩罚,便可使得两个彼此有社交关系的用户在映射空间中也十分靠近, 从而保持了网络的局部结构。我们使用原始的社交关系su,v来约束是否进行惩罚。目标函数设置为:


其中, Lreg为自编码器的L2 正则项, α, β和γ为对应部分目标函数的权重系数。
3.3 朋友采样
在重构社交网络后, 我们对自编码器的输出层使用Softmax 函数得到了包含用户社交信息的概率分布, 即用户u 对于所有用户的一个关系概率向量,那么直觉上可以选择概率最大的用户v 作为用户可靠的朋友, 但这种方式面临以下两个问题。首先, 概率最大的用户虽然会在模型的优化过程中发生变化,但本次概率最大的用户v下一次被选择作为u的朋友的可能性依然会很大, 进一步导致用户v交互过的物品集将多次被采样, 容易引起模型过拟合。除此, 离散的采样过程是不可微的, 这意味着不能进行端到端地训练。一些模型使用Policy Gradient 策略来解决离散空间内采样不可微的问题[13], 然而这种方法经常由于采样造成的不稳定损失加剧训练的不稳定,并且收敛缓慢, 特别涉及大规模候选集采样时, 更会造成性能的进一步恶化[15]。基于以上问题, 为了提高模型鲁棒性, 并能在采样时通过反向传播进行端到端的训练, 我们选择了Gumbel-Softmax[24]进行朋友采样和物品采样。
Gumbel-Softmax 通过一个可微的重参数化过程来近似分类样本[24]。对于每一个用户u, gi表示从Gumbel(0,1)分布中得到的随机噪声向量, 则朋友采样过程可以表示为:

v 是经过Gumbel-Softmax 生成的类似One-Hot的向量, 代表生成器为用户u 采样出的朋友。pu为用户u 经过社交重构后输出的社交关系概率向量。超参数τ按照惯例称为温度, 选择大的温度τ相当于对社交关系概率向量进行平滑操作, 即减小原始分布中各标签概率的差距。相反地, 当τ越接近于0, v越逼近One-Hot 向量, 将增大原始分布中概率最大的标签的概率, 也就代表了离散的朋友采样过程,如图3 所示。
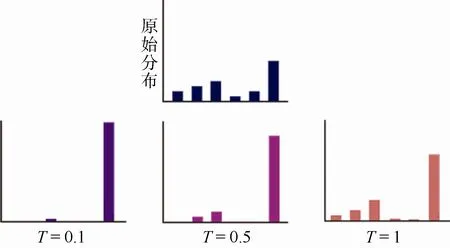
图3 Gumbel-Softmax 最大概率采样Figure 3 Max sampling based on Gumbel-Softmax
通过这种重参数化的技巧使得采样过程中梯度能够反向传播, 同时Gumbel 噪声给采样带来了一定的随机性, 如果能够在随机性和可靠性之间找到一个平衡点, 将有助于避免过拟合, 增强模型的鲁棒性。
3.4 物品采样
经过采样得到偏好相近的朋友v 之后, 从用户-物品交互的隐式反馈矩阵中找出该朋友对数据集与所有物品的交互向量。注意, 物品采样不同于朋友采样, 朋友采样的概率分布由重构社交网络部分的自编码器所得, 所以为了将朋友v 的偏好向量变成与用户u 直接关联的物品采样概率分布, 我们同文献[3]和文献[15]一样, 定义一个嵌入矩阵H 表示各用户对其朋友交互过的物品的偏好, 从而来动态地表示用户的物品采样概率分布, 该采样过程可以表示为:
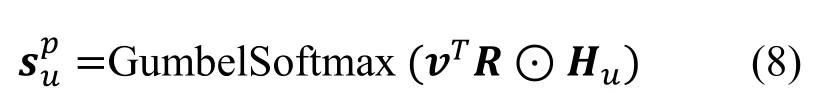
同样地, 我们再次利用Gumbel-Softmax 根据假设“用户对他们可信赖的朋友们不喜欢的物品也同样不感兴趣”, 在采样朋友v 的交互向量中为用户抽取出其可能不喜欢的物品。根据使用温度小于1 的Gumbel-Softmax 抽取用户可能喜欢的物品时, 会将分布标签之间的差距拉大, 即将可能性大的物品的概率增大, 将可能性小的物品的概率减小, 起到Max函数的作用, 我们发现在同样的候选集中, 仅需要将传入的采样概率分布向量中各元素变成对应的负值, 则Gumbel-Softmax 就可变为原始分布的最小概率样本采样器, 即将可能性大的物品的概率变小,将可能性小的物品的概率增大, 达到Min 函数的作用。如图4 所示。

图4 Gumbel-Softmax 最小概率采样Figure 4 Min sampling based on Gumbel-Softmax
那么, 用户u 可能不喜欢的物品的采样过程可以表示为:
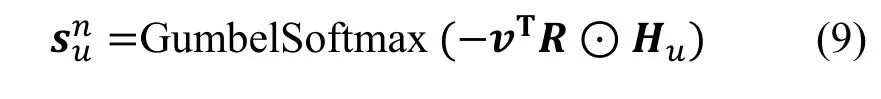
3.5 对抗训练
基于“用户对他们可信赖的朋友交互过的物品更感兴趣, 对他们可信赖的朋友们不喜欢的物品也同样不感兴趣”的假设, 我们利用生成器进行了更为细粒度的采样, 得到用户可能喜欢的物品p 和用户可能不喜欢的物品n。然后, 我们再从用户交互过的物品中随机采样出用户交互过的物品i, 并与上述3个物品组成三元组作为判别器的输入。注意, 这里对物品i 进行的随机采样通常认为是理论无噪的, 因为在线下训练或测试时, 实验前提就是将用户实际交互数据当做用户真实的偏好。
首先, 根据假设“相比于未交互过的样本, 用户更偏爱于其可信赖的朋友交互过的物品”, 则偏好排序可表示为:

xui表示用户u 对其交互过的物品i 的偏好, xup表示用户u 对其朋友们喜欢的物品的偏好, 也就是用户u对生成器为其生成的其可能喜欢的物品p 的偏好, xun表示用户u 对其朋友不喜欢的物品的偏好, 即用户u 对生成器为其生成的其可能不喜欢的物品n 的偏好。同样地, 我们也可以认为用户u 对物品i 的偏好应该同时大于其对物品p 和n 的偏好, 则偏好排序也可以表示为:
根据以上两个社交约束, 生成器设计的目标是尝试从用户的朋友们交互过的物品候选集中采样出与用户交互过的物品偏好相当的物品, 则生成器的目标函数可以记为:

其中, 最后一项为正则化项, λθ为正则化系数。σ为Sigmoid 激活函数, 当用户u 对其可能喜欢的物品p的偏好xup越接近用户u 对其已交互过的物品i 的偏好xui时, 生成器的目标函数值就会越大, 所以最大化生成器的目标函数, 可以让生成器生成与用户交互过的物品偏好相当的物品, 并且增大采样偏好相似的朋友的可能性。
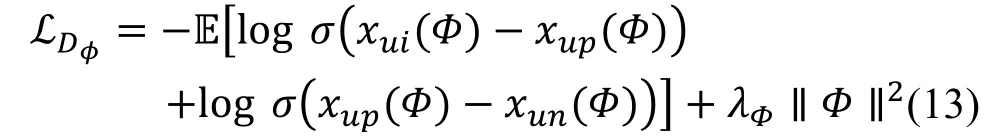
其中, 最后一项为正则化项, λφ为正则化系数。当最小化判别器的目标函数时, 可扩大xui与xup的差值和xup与xun的差值, 即让判别器更好区分出三类不同的物品。
此外, 根据式(11), 在判别器中也可以将生成器采样出的用户可能喜欢的物品p 和用户可能不喜欢的物品n 同时作为用户实际交互过的物品i 的负样本[7]。那么判别器的目标函数也可以定义为:
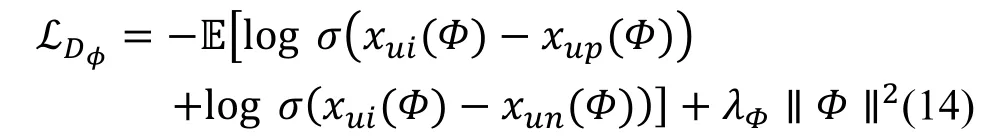
根据生成对抗网络的原理[21], 生成器和判别器的目标是相反的, 那么通过这个最大最小化游戏,训练过程最终将达到一个平衡状态, 生成器可以生成用户更为可靠的朋友, 以及用户喜欢的物品和其不喜欢的物品, 而判别器可以鉴别出三类候选物品,并捕获到用户真实的偏好, 从而得到不错的推荐性能。ASGAN 模型的算法训练过程具体如算法1 所示:
算法1:ASGAN 模型的训练过程.
输入: 社交网络邻接矩阵S, 基于用户—物品交互的隐式反馈矩阵R
输出: 生成器(Gθ)与判别器(Dφ)可训练的参数
1. 初始化生成器(Gθ)与判别器(Dφ)
2. 根据式(6)预训练社交重构模块
3. FOR 迭代次数DO
4. FOR 每一位用户DO
5. 向生成器中输入用户显式的社交朋友
6. 经过社交重构模块得到新的社交概率分布
7. 根据式(7)为用户采样出的朋友v
8. 根据式(8)为用户采样其喜欢的物品p
9. 根据式(9)为用户采样其不喜欢的物品n
10. 将采样生成的物品p 与物品n 传给判别器
11. 根据式(12)计算生成器损失, 并更新其参数
12. END
13. FOR 每一位用户DO
14. 通过生成器得到为用户采样出的物品p 和物品n
15. 从R 中为用户采样出其实际交互过的物品i
17. 根据式(13)(或式(14))计算判别器损失, 并更新其参数
18. END
19. END
4 实验
4.1 实验设置
4.1.1 数据集
实验采用了三个公开的数据集 LastFM①http://files.grouplens.org/datasets/hetrec2011//、Delicious①和Douban②http://smiles.xjtu.edu.cn/Download/download Douban.html, 数据集详细信息如表1 所示。我们将整个数据集划分为训练集和测试集, 测试集占总数据集的30%, 其他70%为训练集。

表1 数据集Table 1 Dataset
在LastFM 数据集中, 我们为用户推荐艺术家,使用了用户与艺术家的交互记录和用户的社交信息,并过滤了用户和艺术家的交互数据中仅有一次交互的记录, 然后将剩余数据转换成隐式反馈[3,11]。在Delicious 数据集中, 我们将所有的用户与书签的交互记录转换为隐式反馈。在Douban 数据集中, 我们则将用户评分大于1 的交互数据转为隐式反馈来训练、测试ASGAN 与对比算法。
4.1.2 评估指标
实验中, 我们采用了三个推荐任务中常用的评估指标来定量衡量模型的推荐性能: 精确率(P@k)、召回率(R@k)和归一化的累计折损增益(NDCG@k)。其中, 精确率和召回率是无序评估指标, 仅考虑推荐列表中的物品是否与用户喜欢有关, 而归一化的累计折损增益则评估了推荐列表中各物品在列表中的相对位置和排序。在TopK 推荐任务中, 推荐列表顶部的物品更为重要, 实验中取K 为5 和10。
4.1.3 对比算法
为了证明本算法的优越性, 我们选择与现存的六个相关算法进行了详细的对比实验:
POP(Popularity): 是一种基于物品流行度的非个性化推荐算法, 其根据用户与物品的交互次数对物品进行排序, 为每一位用户给出相同的推荐列表。
BPR(Bayesian Personalized Ranking)[12]: 是一种基于隐式反馈的经典成对排序算法, 其对用户未交互过的物品进行随机采样, 然后作为用户实际交互过物品的负样本来优化贝叶斯后验概率。
SBPR(Social Bayesian Personalized Ranking)[7]:是一种利用社交信息的经典成对排序算法, 其将随机采样的朋友交互过的物品和用户未交互过的物品作为用户实际交互过物品的负样本, 然后利用该物品三元组进行排序优化。
IRGAN(Information Retrieval Generative Adversarial Nets)[13]: 是一种将离散值采样与生成对抗网络相结合的经典算法, 其将生成器采样出的样本视为负样本, 证明了在推荐系统中使用生成对抗网络进行动态采样的有效性。
APR(Adversarial Personalized Ranking)[22]: 是一种通用的基于对抗学习的成对排序算法, 有效提高了成对学习模型整体的鲁棒性与泛化能力, 但其并没有引入额外的社交信息。
RSGAN(Reliable Social Generative Adversarial Nets)[3]: 是一种基于社交朋友生成的对抗学习算法,其首先利用自定义的异构网络生成各用户偏好相似的朋友, 然后使用生成对抗网络进行朋友采样与物品采样, 但其在生成器中进行物品采样时, 仅对用户可能喜欢的物品进行采样, 而且本质上并不是一个端到端的模型。
针对不同的数据集, 我们对本文所提出模型ASGAN 的重要参数进行设置。社交重构模块中的权重系数α在{0.5, 1, 1.5}之间进行调整, 权重系数β则在{80, 90, 100}之间进行调整, 惩罚因子c在{20, 25,30, 35}之间进行调整。正则化系数γ、λθ和λφ在{0.01,0.05, 0.1, 0.2}之间进行调整, Gumbel-Softmax 中的温度系数τ则在{0.05, 0.1, 0.15, 0.2, 0.25}之间进行调整, 其他常见的超参数如学习率、批次大小和迭代次数则根据具体情况进行调优。
4.2 推荐性能对比
根据上述实验设置, 我们在三个数据集上对ASGAN 和六个对比算法进行了充分的实验, 实验结果如表2 所示, 包括了所有的六个评估指标, 其中每个评估指标的提升比例根据式(15)计算而得。我们可得到以下结论:
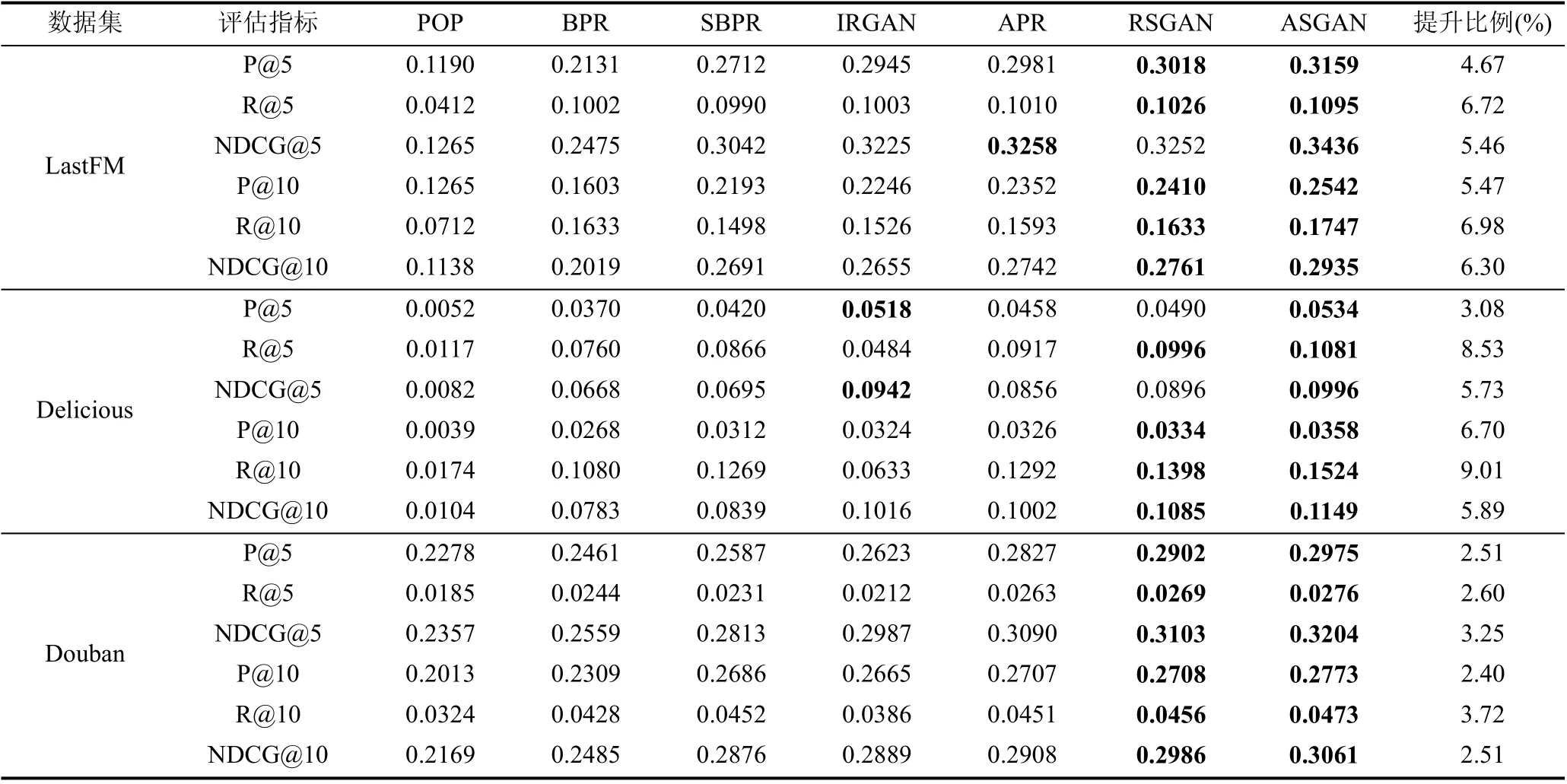
表2 在三个数据集中的推荐性能对比Table 2 Comparison of recommendation performance in three datasets

个性化推荐算法的性能明显优于基于物品流行度的非个性化推荐算法POP。SBPR 的推荐性能在大部分指标中都明显优于BPR, ASGAN 和RSGAN 在大部分指标中也比仅使用用户—物品交互信息的IRGAN 和APR 具有优势, 证明了有效利用社交数据有利于提高推荐性能。基于对抗学习的推荐算法IRGAN、APR、RSGAN 和SAGAN 在大部分指标中普遍比传统算法POP、BPR 和SBPR 拥有更好的性能, 表明在对抗训练可以减少噪声对模型的干扰,提高模型的鲁棒性, 从而更好地捕获用户的偏好。
ASGAN 在各指标上均高于六个对比算法。对比传统推算法, ASGAN 具有更为明显的性能优势, 进一步说明基于深度学习和对抗学习的模型具有更强的学习能力。对比仅使用用户—物品交互数据的对抗模型IRGAN 和APR, ASGAN 优势也十分明显, 再次证明了有效利用社交信息进行对抗训练的优势。此外, 在与同样基于社交信息和生成对抗网络的RSGAN 的对比中, 我们的ASGAN 也具有明显的优势, 证明了细粒度采样有效缓解了社交信息和粗粒度采样策略带来的噪声问题, 提高了推荐的准确率。
进一步地, 为了定量分析ASGAN 性能提升的显著性差异, 我们选取对比算法中性能较好的RSGAN 与我们的ASGAN 在每个数据集上都进行五次重复实验, 然后在精确率(P@5)上进行T-test 检验, 假设二者性能相等的显著性水平为0.01, 检验结果P-value 都远小于0.01, 所以ASGAN 的性能提升显著。
4.3 负采样的影响
负采样对基于隐式反馈数据进行训练的模型至关重要。在ASGAN 中, 我们基于社交信息利用生成对抗网络的生成器进行了更为细粒度的采样, 同时采样出用户可能喜欢的物品和可能不喜欢的物品,在判别器中则随机采样出用户交互过的物品, 并使用了两种排序方式利用采样出的物品三元组。为了探究判别器中不同排序方式的推荐性能情况, 我们将利用式(11)对应的排序方式训练判别器的模型记为AS-1, 将利用式(12)进行训练的模型记为AS-2。此外, 为了探究ASGAN 细粒度采样方法的有效性,我们同文献[3]一样, 在生成器中仅采样出用户可能喜欢的物品, 在判别器中对用户交互过的物品和用户未交互的物品都进行随机采样, 然后同样利用两种排序方式优化判别器, 记为模型RS-1 和RS-2。
实验结果如表3 所示, 首先在两个数据集中分别将AS-1 与RS-1 进行对比, AS-2 与RS-2 进行对比,并利用五次重复实验的精确率(P@5)对两组实验实施T-test 检验, 检验结果P-value 都远小于0.01, 证明在判别器排序方式相同的情况下, ASGAN 生成器中采用的细粒度采样方式比粗粒度的随机采样效果更优, 并且推荐性能提升显著。
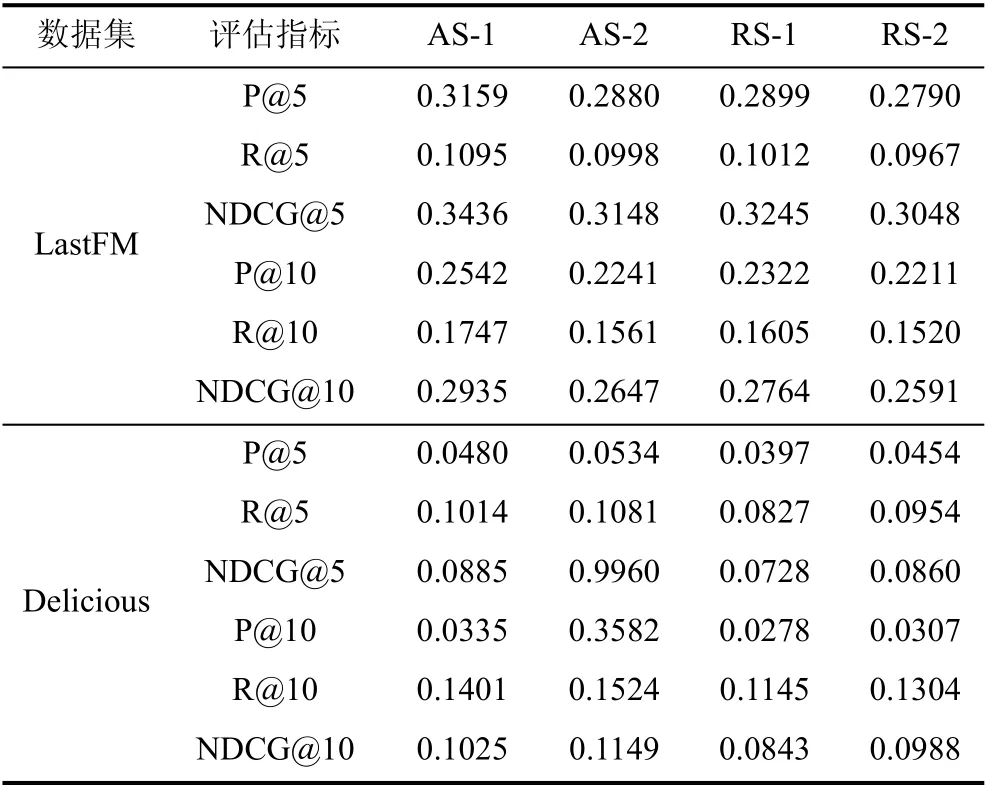
表3 负采样的影响Table 3 Effects of negative sampling
此外, 在两种采样方式中对比判别器中不同排序方式对推荐性能的影响, 可知在LastFM 数据集中, 使用第一种排序方式性能较好, 而在Delicious中, 第二种排序方式性能更佳。导致这种情况出现的一个合理解释是不同数据集中采样出的两类细粒度样本携带的相对噪声大小是未知的, 所以在实际的推荐数据和背景下, 我们无法在真实数据中直接观察到这两种排序方式中的优劣, 需要实验确定。类似地, 文献[7]中也同样说明了这两种排序方式的不确定性。
4.4 采样温度的影响
ASGAN 采用Gumbel-Softmax 进行社交朋友采样和物品采样, 这种方法使得采样过程中梯度能够反向传播, 同时Gumbel 噪声给采样过程带来了一定的随机性, 温度系数τ则控制了采样结果所携带的信息熵含量, 如果能够在随机性和可靠性之间找到一个平衡点, 有利于增强模型的鲁棒性。温度τ的取值越小, 则采样得到的结果向量越接近于一个One-Hot 向量, 但所携带信息熵含量也越少。注意,从表3 中可知, 在两个数据集采用两种不同的排序方式性能差距较大, 因此我们选择对两个数据集中分别表现较优的模型(即LastFM 数据集中的AS-1 模型和Delicious 中的AS-2 模型)不同的τ值进行实验。图5 展示了在两个数据集中, 不同采样温度τ的取值对召回率(R@10)的影响, 从图中可知两个数据集中τ在0.1 附近取值性能最优, 并且都呈现先上升后下降的趋势。
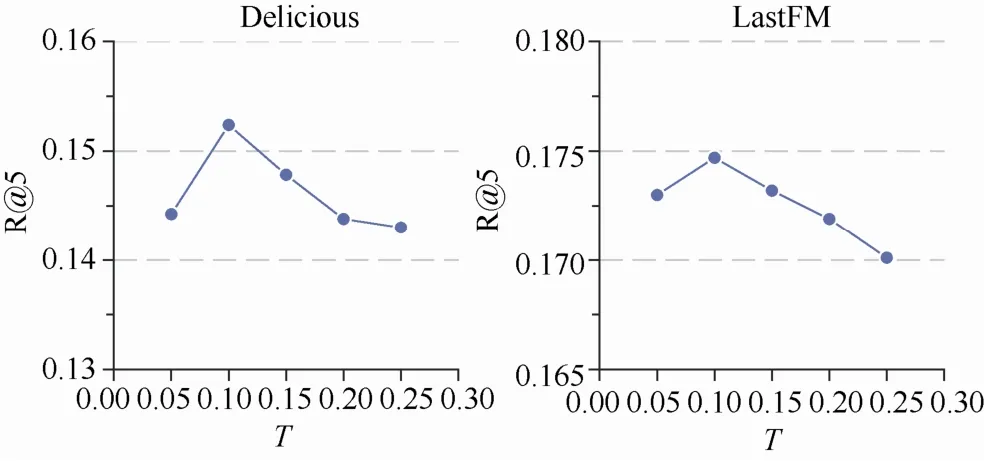
图5 采样温度的影响Figure 5 Effects of sampling temperature
4.5 社交重构的影响
社交重构模块对于找到与用户偏好真正相近的朋友, 降低社交信息带来的噪声影响必不可少。ASGAN 中对社交重构模块参数的调整来自于重构模块的预训练以及对抗训练过程中带来的惩罚。表2和表3 可以证明对抗训练对于减少社交信息携带噪声的有效性。为了证明对社交重构模块预训练带来的影响, 我们去除对社交重构模块的预训练过程,直接进行对抗训练。对应两种排序方式并拥有完整训练过程的AS-1 和AS-2, 分别得到未进行预训练的模型AS-1-P 和AS-2-P。
如图6 所示, AS-1-P 和AS-2-P 在两个数据集中的召回率(R@10)上都要低于相应的经过预训练的模型, 证明了我们使用类似图表示学习的方法对社交重构模块进行预训练对减少社交信息携带噪声, 提升推荐准确率的有效性。

图6 社交重构预训练的影响Figure 6 Effects of social reconstruction pretrain
5 结论
本文针对显式社交信息和物品采样策略中存在的噪声问题, 基于生成对抗网络提出了一种对抗采样推荐模型ASGAN。具体地, 生成器首先结合图表示学习方法初始化社交网络, 然后使用 Gumbel-Softmax 进行朋友采样和细粒度的物品采样。在判别器中, 我们使用两种排序方式来区分采样出的物品三元组(用户喜欢的物品、用户不喜欢的物品和用户实际交互过的物品), 并指导生成器进行更为有效的采样, 实现了端到端的推荐。最后, 我们在三个真实的数据集中进行了充分的实验, 证明了ASGAN比现有的相关工作具有更优秀的推荐性能, 所提出的采样方法对于降低显式社交信息和物品采样带来噪声的影响是有效的。在未来的工作中, 我们将会把图表示学习初始化社交网络的方法融入对抗训练的过程中, 从而更好地利用社交信息进行推荐。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
哈尔滨工业大学学报(2022年5期)2022-04-19
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
摄影世界(2022年1期)2022-01-21
疯狂英语·初中天地(2021年11期)2021-02-16
科普童话·学霸日记(2020年1期)2020-05-08
少年漫画(艺术创想)(2019年2期)2019-06-06
小天使·一年级语数英综合(2019年2期)2019-01-10
知识经济·中国直销(2018年12期)2018-12-29
商周刊(2017年6期)2017-08-22
