
协同过滤推荐系统综述
2021-11-10 07:19赵俊逸庄福振蒋慧琴
信息安全学报 2021年5期
赵俊逸, 庄福振, 敖 翔, 何 清, 蒋慧琴, 马 岭
1 郑州大学河南先进技术研究院, 郑州 中国 450003
2 中国科学院计算技术研究所智能信息处理重点实验室 北京 中国 100190
3 北京航空航天大学人工智能研究院 北京 中国 100191
4 郑州大学信息工程学院 郑州 中国 450003
1 引言
互联网和信息计算的快速发展, 衍生了海量数据, 我们已经进入信息爆炸的时代。然而这些信息并不完全是人们所关心的, 用户要从大量信息中寻找有用信息变得越来越困难。另一方面, 信息的生产方在绞尽脑汁把用户感兴趣的信息推送给用户, 而每个人的兴趣又不尽相同, 所以可以实现千人千面的推荐系统应运而生。简单来说, 推荐系统是根据用户的浏览习惯确定用户兴趣, 通过发掘用户的行为,将合适的信息推荐给用户, 满足用户的个性化需求。推荐系统的结构通常由在线和离线两部分组成。在线部分即前端展示部分; 离线部分由后端的日志系统和推荐算法系统组成。离线部分通过学习用户资料和行为日志建立模型, 在新的上下文背景中计算相应的推荐内容, 将其呈现于在线页面中, 如图1 所示。目前, 推荐系统已经成为产业界和学术界关注、研究的热点问题, 应用领域十分广泛, 在电子商务[1]、会话推荐[2]、文章推荐[3]、智慧医疗[4]等领域都有所应用。
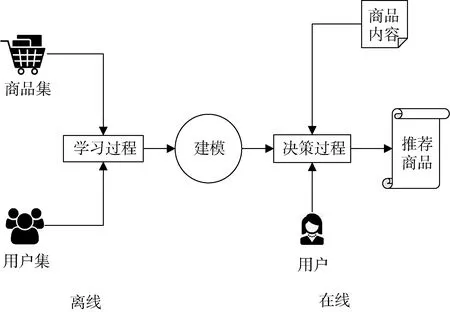
图1 推荐系统的推荐过程Figure 1 Recommendation process of recommender system
传统的推荐算法主要包括基于内容的推荐(Content-based Recommendation)[3]、协同过滤推荐(Collaborative Filtering-based Recommendation,CFR)[5]和混合推荐(Hybrid Recommendation)[6]。
(1) 基于内容的推荐。该推荐方法主要利用项目内容信息进行推荐, 是信息过滤技术的延续与发展。其通过机器学习方法从内容的特征描述中得到用户的偏好信息而不需要依据用户对项目的评价意见。
基于内容的推荐过程一般为: 首先抽取表示该项目的项目特征; 然后利用用户过去感兴趣以及不感兴趣的项目特征数据学习该用户的偏好特征; 最后通过比较用户的偏好特征和候选项目特征为用户推荐一组相关性最大的项目[3]。
(2) 协同过滤推荐。该方法假设拥有相似兴趣的用户可能会喜欢相似的项目或者用户可能对相似的项目表现相似的偏好程度。其核心思想是基于近邻的推荐算法, 利用用户或物品间的相似度以及历史行为数据以对目标用户进行有效推荐[5]。
(3) 混合推荐。该方法将多种推荐技术进行混合,使相互弥补缺点获得更好的推荐效果。最常见的是将协同过滤推荐与内容推荐相结合[6]。
表1 为上述三类推荐方法的优缺点对比。可以发现, 协同过滤推荐与基于内容的推荐相比, 其优点在于: 首先, 可以帮助用户发现新的兴趣, 协同过滤可以发现与用户已知兴趣不同的潜在兴趣偏好;其次, 通过共享他人经验, 可避免内容分析的不完全和不准确, 并且能够基于复杂概念(如个人品味)进行过滤; 最后, 能够通过使用其他相似用户的反馈信息加快个性化学习速度。因此, 协同过滤成为目前应用最广泛最成功的推荐技术之一。

表1 推荐算法优缺点对比Table 1 Comparison of advantages and disadvantages of recommendation algorithms
然而随着时代的发展, 各类应用及服务出现井喷式增长, 传统协同过滤推荐系统面对数据的快速增长逐渐暴露出一些问题, 如冷启动、数据稀疏、可扩展性、多样性以及可解释性等问题。这些问题极大地影响了推荐系统的性能, 给推荐系统的发展带来挑战。因此, 如何缓解甚至解决这些问题以提高推荐系统的推荐效果, 对用户和企业来说都具有重要意义, 学者们为此进行了大量研究。
本文首先对协同过滤推荐算法的相关技术及评价指标进行梳理与对比分析, 随后详细介绍学者们在解决传统协同过滤推荐算法存在的各种问题及挑战时做出的努力, 最后提出未来的几个发展方向。
2 基于协同过滤的推荐
协同过滤推荐系统通过计算系统中用户之间的相似度, 根据他们之间的相似模式来预测项目。该方法利用“用户-项目评分矩阵”进行推荐。如图2 所示, 在推荐系统中根据用户对项目的评分可以得到“用户-项目评分矩阵”, 其中矩阵中的值表示用户对项目的评分, “-”表示用户未对项目进行评分。实际场景中通常只存在用户对少量项目的评分, 因此矩阵往往非常稀疏。
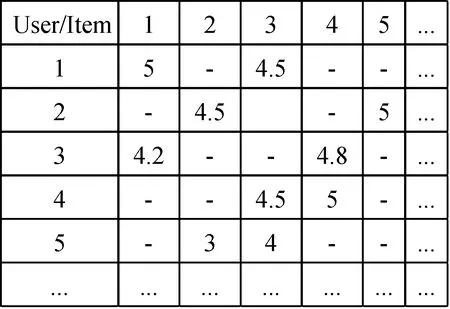
图2 用户-项目评分矩阵Figure 2 User-Item rating matrix
2.1 协同过滤推荐过程
协同过滤主要根据相似用户之间的现有评分为用户推荐项目。如图3 所示, 主要分为以下两步[7]:

图3 协同过滤推荐的一般过程Figure 3 General process of collaborative filtering recommendation
(1) 系统将整个空间表示为二维矩阵。在二维矩阵R中,U和I分别对应用户和项目。Rij是用户Ui对项目Ij的评分。如果用户未对项目评分则项目值设为0。
(2) 使用矩阵R预测用户i对项目j的评分, 以便为用户可能喜欢的N个项目做出推荐。
2.2 协同过滤方法
有两种类型的协同过滤方法被广泛研究, 即基于内存的协同过滤(Memory-based CF)和基于模型的协同过滤(Model-based CF)。
2.2.1 基于内存的协同过滤
基于内存的协同过滤方法一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离, 然后利用目标用户的邻居用户对商品评价的加权值来预测目标用户对特定商品的喜好程度, 推荐系统根据喜好程度对目标用户进行推荐。
该方法包括基于用户的方法(User-based CF)和基于项目的方法(Item-based CF)。基于用户的方法根据用户之间的评分行为相似度预测用户的评分, 如图4 所示; 基于项目的方法根据预测项目与用户实际选择项目之间的相似度预测用户评分, 如图5 所示。由于这两种方法的原理不同, 因此在不同应用场景中的表现不同。基于用户的推荐更社会化, 反映用户所在的兴趣群体中物品的热门程度; 基于项目的推荐更个性化, 反映用户自己的兴趣传承。具体对比如表2 所示。

表2 基于内存的协同过滤方法对比Table 2 Comparison of Memory-based CF
在基于内存的协同过滤技术中, 计算相似度的常用方法包括皮尔森(Pearson)相关系数、余弦相似度、杰卡德(Jaccard)相似系数以及欧氏距离。这些相似度计算方法没有绝对的优劣之分, 适用场景也并非绝对。因此应根据实际的应用场景、数据特点灵活选择或进行组合。
(1) 皮尔森相关系数。皮尔森相关系数用于度量任意两变量间线性相关的程度, 系数值越大表明两者相关性越强, 系数的输出范围为[–1,1]。0 代表两者无相关性, 负值为负相关, 正值为正相关。两者的相似性可表示为:

其中, Iij表示用户i 和用户j 共同评分过的项目集合, Ri,x和Rj,x分别表示用户i 和用户j 对项目x 的评分,和分别表示用户i 和用户j 对所有项目评分的平均值。
(2) 余弦相似度。余弦相似度通过计算两个向量的夹角余弦值来评估它们的相似度。输出范围和皮尔森相关性系数一致, 含义也相似。公式为:
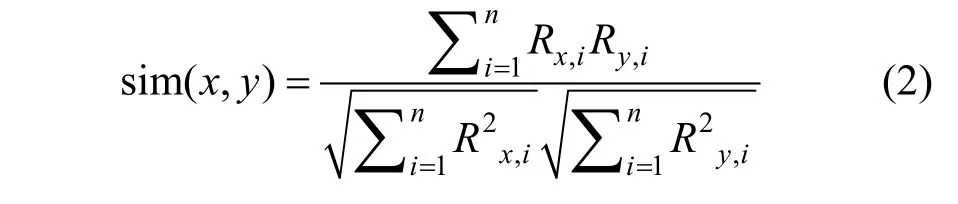
(3) 修正的余弦相似度。修正的余弦相似度利用减去用户对项目的平均评分的方式改善余弦相似度中未考虑不同用户对项目的评分标准存在差异的问题。公式为:

其中, Ixy表示用户x 和用户y 共同评分过的项目集合, Rx,i和Ry,i分别表示用户x 和用户y 对项目i 的评分,和分别表示用户x 和用户y 对所有项目评分的平均值。
(4) 杰卡德相似系数。杰卡德相似系数是衡量两个集合之间相似度的一种指标。用户u 和用户v 共同评分过的项目集合的数量与他们评分过的总项目集合的数量之间的比例称为杰卡德相似系数。由于该方法无法反映用户的具体评分偏好信息, 因此通常用于评估用户是否会对项目进行评分而不是预测用户对项目的具体评分。公式为:
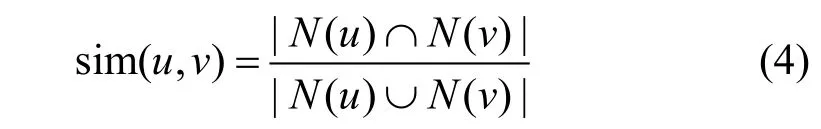
其中N(u), N(v)分别表示用户u 和用户v 评分过的项目集合。
(5) 欧氏距离。对于用户ui和uj, 欧氏距离即计算这两个用户的评分向量在n 维向量空间中的绝对距离, 公式如下:
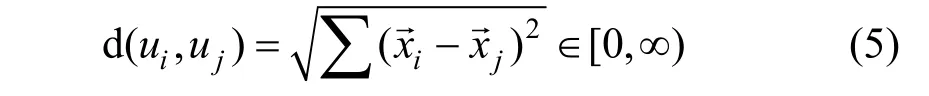
在实际使用中, 通常还需要将欧氏距离进行归一化处理, 可以得出两者之间的相似性为:

2.2.2 基于模型的协同过滤
基于模型的协同过滤方法通过建模的方式模拟用户对项目的评分行为。其使用机器学习与数据挖掘技术, 从训练数据中确定模型并将模型用于预测未知商品评分。常见模型包括聚类模型[8-10]、贝叶斯模型[11]、矩阵分解[12]等。
(1) 聚类。聚类算法基于预定义模型构造数据,是一种无监督机器学习算法。按照聚类对象的不同可以分为用户聚类模型、项目聚类模型以及用户-项目联合聚类模型。用户聚类模型[13]即将兴趣相近的用户集聚成一簇; 项目聚类模型[14-15]即将相似项目进行聚类; 还可以同时考虑用户和项目的聚类结果进行综合分析。聚类结果应该具有较高的簇内相似性和较低的簇间相似性。
通常使用闵可夫斯基距离(Minkowski Distance)和皮尔森相关性计算数据对象X=(x1, x2, x3,…, xn)和Y=(y1,y2, y3,…, yn)之间的相似度。闵可夫斯基距离定义 如下:
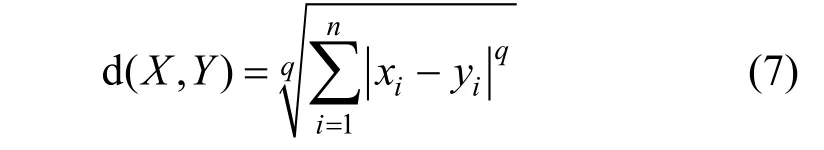
其中n 是对象的维数, xi和yi分别是对象x 和对象y第i 维度上的值。q 是一个正整数。当q=1 时该距离称为曼哈顿距离(Manhattan Distance); 当q=2 该距离称为欧氏距离。
最常用的聚类算法是K-means。该算法实现起来相对简单且具有很高的推荐精度。
(2) 贝叶斯模型。由于推荐问题可以转化为分类问题, 因此可以通过机器学习领域中的分类算法来解决推荐问题。贝叶斯网络基于条件概率和贝叶斯定理。该网络是最流行的概率框架, 能够推导出用户或项目之间的概率依赖关系[11]。其使用决策树表示概率表, 对每个推荐项都构造一个单独的树。树中节点的分支选择取决于用户对特定项目的评分。用户对预测项目评分的概率向量存储在树的节点中。
(3) 关联规则挖掘。关联规则挖掘通常基于用户购买商品之间的关联关系预测用户偏好。具体来说,关联规则基于物品维度构思考虑, 分析出数据库中所有包含属性等特征信息模块间的隐藏关联, 进而找出满足给定项集支持度和项集置信度的多个模块间存在的所有依赖关系[16]。根据关联规则推荐原理产生的推荐算法步骤如图6 所示。
(4) 矩阵分解[12]。矩阵分解是推荐系统中最常用的协同过滤模型之一。该模型利用用户-项目评分矩阵预测用户对项目的评分, 通过学习用户潜在向量U 和项目的潜在向量V, 使U 和V 内积近似于用户真实评分X, 得到预测的评分R 可以写成:

其中i 是用户索引, j 是项目索引, rij表示用户i 对项目j 的预测评分, u 是用户的潜在向量, v 是项目的潜在向量。然后计算其损失函数为:

(5) 马尔可夫决策过程(Markov decision processes, MDP)。基于MDP 的协同过滤算法将推荐转化为一种序列优化问题, 使用MDP 生成推荐。MDP 的关键优势在于它们考虑每个推荐的长期影响和每个推荐的算术平均值。MDP 可以被定义为一个四元组:〈 S, A, R, Pr〉, 其中S 表示状态集合, A 表示行为集合;R 表示每个“状态/行为”对的奖励函数, Pr表示给定任一行为的每一状态对之间的转移概率[17]。
表3 为基于内存的协同过滤方法与基于模型的协同过滤方法的优缺点对比。通过比较可以看出, 基于模型的协同过滤方法能更好的解决稀疏性、可扩展性等问题。

表3 协同过滤方法的优缺点比较Table 3 Comparison of advantages and disadvantages of collaborative filtering methods
2.3 协同过滤任务
基于协同过滤的推荐系统可以根据任务的不同分为评分预测和Top-N 推荐。
(1) 评分预测。该任务的主要应用场景为评价网站, 如豆瓣网站。通过建模用户对项目的历史评分记录得到用户的兴趣模型, 进而预测用户对未评分项目的评分。最常用的技术是矩阵分解技术。
(2) Top-N 推荐。该任务的主要应用场景为购物网站或一般拿不到显式评分信息的网站, 如亚马逊网站、淘宝网站。通过用户的隐式反馈信息为其推荐可能感兴趣的前N 个商品。最常用的技术为贝叶斯个性化排名(Bayesian Personalized Ranking, BPR)。
2.4 评价指标
不同的推荐任务使用的评价指标往往也不同,评分预测任务通常需要预测准确度, Top-N 推荐任务通常需计算查准率、查全率等准确度指标以及覆盖度、多样性等非准确度指标。
2.4.1 评分准确度
该方法用于衡量算法预测的评分与用户的实际评分之间的贴近程度。令rua表示用户u 对项目α 的真实评分, r′ua表示用户u 对项目α 的预测评分, EP表示测试集。主要的评价指标为:
(1) 平均绝对误差(Mean Absolute Error, MAE)
该方法因计算简单、通俗易懂被广泛应用。其通过计算预测评分与真实评分之间的绝对误差得到,公式为:
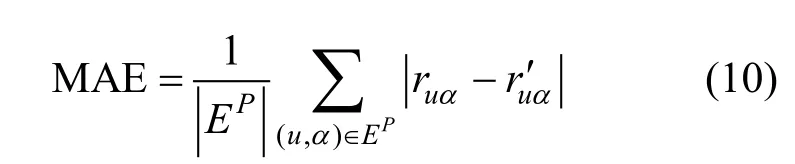
(2) 均方根误差(Root Mean Square Error, RMSE)
该方法加大了对用户项目评分的错误预测惩罚,因而对系统的评测更加苛刻。公式为:

2.4.2 排名准确度
令R(u)表示模型根据用户在训练集上的行为计算出的推荐项目列表, T(u)表示用户在测试集上的真实喜爱列表, 主要评测方式为:
(1) 查准率。该方法可得到分类正确的正样本个数占分类器判定为正样本的样本个数的比例。用于体现所预测的推荐列表中有多少物品是用户感兴趣的。公式如下:

(2) 召回率。该方法用于体现用户真实喜爱列表中的物品有多少是被推荐算法预测出的。公式如下:
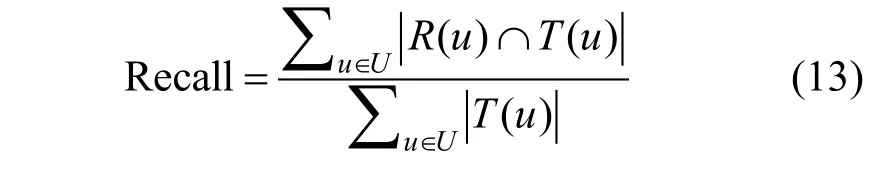
(3) F1 分数。该方法能够兼顾精确率和召回率,可以看作是模型准确率和召回率的一种加权平均。公式如下:

(4) 折损累计增益(Discounted Cumulative Gain,DCG)。目的在于让排名越靠前的结果越能影响最后的结果。公式为:
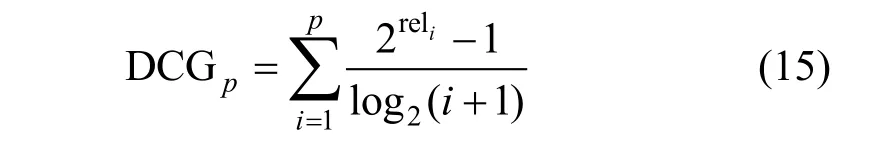
其中, reli表示i 位置上的相关度。
(5) 归一化折损累计增益(Normalized Discounted cumulative gain, NDCG)。由于搜索结果随着检索词的不同, 返回的数量是不一致的, 而DCG 是一个累加的值, 无法对两个不同的搜索结果进行比较, 因此需要归一化处理。公式如下:
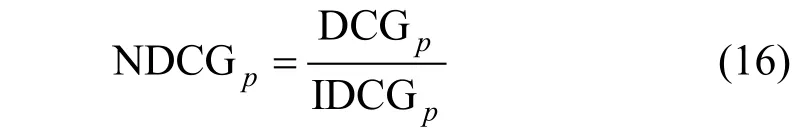
IDCGp为理想情况下的最大DCG 值, 即:
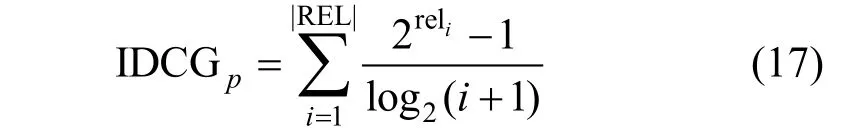
其中, |REL|表示结果按照相关性从大到小排序后,前p 个结果组成的集合。
2.4.3 覆盖度
覆盖度标识推荐系统对物品长尾的发掘能力,用以衡量系统是否能推荐到所有物品。设现有用户集合为U, 系统为每个用户u 提供Top-N 推荐列表为R(u), 则覆盖度为:

2.4.4 多样性
为提高用户满意度, 推荐应覆盖用户的所有兴趣点, 甚至包括用户未发觉的潜在兴趣, 体现推荐多样性。设sim(i,j) ∈[0,1]为物品i, j 的相似性。则用户u 的推荐列表R(u)的多样性可定义为:
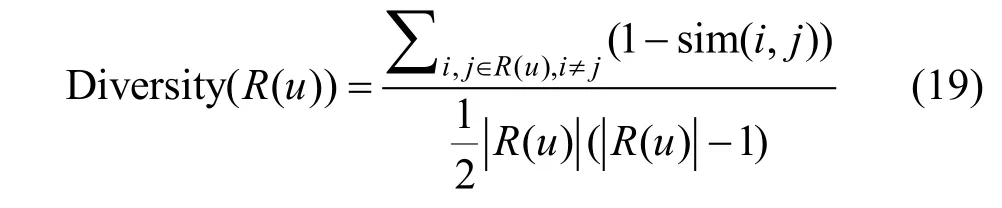
2.4.5 新颖度
新颖度指的是向用户推荐他并不知道的物品。平均流行度是评估新颖度的最简便方法。该方法为推荐列表中所有物品的度的总和平均值。推荐列表中物品的平均流行度越小, 新颖度越高。
2.4.6 健壮性
健壮性指的是系统抵御作弊的能力, 学者在研究推荐算法时可以利用算法对用户生成一个推荐列表, 然后往数据集中注入一定的噪声数据, 然后再次生成推荐列表, 最后对比两次推荐列表的相似度,以此评估算法的健壮性。
2.5 常用数据集
推荐系统中常用的数据集主要有MovieLens①https://grouplens.org/datasets/movielens/、Jester②http://eigentaste.berkeley.edu/dataset/、Book-Crossings③http://www2.informatik.uni-freiburg.de/~cziegler/BX/、Last.fm④https://grouplens.org/datasets/hetrec-2011/、Wikipedia⑤https://en.wikipedia.org/wiki/Wikipedia:Database_download#English-language_Wikipedia。具体内容如表4 所示。

表4 常用数据集介绍Table 4 An introduction to common datasets
其中, MovieLens 是电影评分的集合, 有3 种大小的数据集; Jester包含150个笑话, 大约600万评分;Book-Crossings 是关于图书评分的数据集; Last.fm 提供音乐推荐的数据集, 包含用户最喜爱的艺术家列表及其播放次数; Wikipedia 是其用户撰写的百科全书, 被广泛用于社交网络分析、图像和数据库实现测试以及用户行为研究。
3 国内外研究现状
随着数据的指数级增长, 传统协同过滤推荐系统的问题越来越明显, 主要包括: 冷启动与稀疏性问题、可扩展性问题、多样性问题以及可解释性问题。为了应对这些问题与挑战, 研究人员们做出了很多努力。本节将详细介绍学者们在解决协同过滤推荐算法相关问题与挑战时所做的工作。表5 为相关工作汇总。

表5 协同过滤算法工作梳理Table 5 Review of collaborative filtering algorithm
3.1 冷启动与稀疏性问题
在协同过滤方法中, 项目的推荐基于用户过去的偏好, 因此当出现新用户或新项目的时候无法做出推荐。该问题被称为冷启动问题。此外, 由于电子商务规模的扩大, 用户数据和项目数据急剧增加,而用户评价过的项目或用户间重叠的项目数量过少,使得用户-项目矩阵出现极端稀疏性, 导致推荐效果不理想。
协同过滤方法可以根据它们使用的信息源分为三条通路。开创性的工作是仅利用评分数据或签到数据作为单一来源用于推荐; 为了进一步提高推荐性能, 随后一些算法考虑了额外的信息(如用户的社交网络或商品的属性); 第三是迁移协同过滤(Transfer Collaborative Filtering, TCF),它尝试从源域学习知识应用到目标域以实现更好推荐。
3.1.1 利用评分数据
矩阵分解技术是协同过滤最流行的模型, 其将一个用户-项目评分矩阵分解为两个低秩的用户特定矩阵和项目特定矩阵, 然后利用分解后的矩阵进行进一步的预测。非负矩阵分解(Non-negative Matrix Factorization, NMF)[18]是一种有效的多元数据分解方法, 可以将评分矩阵分解为用户和项目信息。Paterek[19]提出改进正则奇异值分解来预测用户对项目的偏好。Salakhutdinov 和Mnij 进一步提出概率矩阵分解(Probabilistic Matrix Factorization, PMF)[20]和贝叶斯概率矩阵分解(Bayesian Probabilistic Matrix Factorization, BPMF)[21]。其中, PMF 使用一种带有高斯观测噪声的概率线性模型来表示用户和物品的潜在特征, 该模型在大且稀疏的评分数据上表现良好。BPMF 通过综合所有模型参数和超参数自动控制模型容量。Zhou 等[22]将矩阵分解与决策树算法相结合,提出功能矩阵分解模型(Functional Matrix Factorization, FMF), 在冷启动过程中为用户选择合适物品,通过对物品打分学习用户的偏好。Gu 等[23]考虑了相似用户分布与相似项目分布之间的关系, 即用户部分和项目部分对推荐结果的贡献取决于它们的相似度, 对此提出一种动态加权协同过滤方法(Dynamicweighted Collaborative Filtering approach, DWCF)来解决稀疏性问题。
随着深度学习的发展, 学者们将深度学习技术用于评分矩阵中以提高推荐性能。Salakhutdinov 等人[24]首次使用RBM 对数据进行建模。Phung 等人[25]探索并扩展了用于协同过滤任务的玻尔兹曼机, 其以原则性的方式集成了相似性和共现性。Zhuang等[26]提出一种基于自动编码器的表示学习框架(Recommendation via Dual-Autoencoder, ReDa)。如图7所示, 该框架将深度学习直接用于评分信息, 可以通过广泛利用评分信息获得更好的用户和项目的隐语义。具体来说, ReDa 使用堆叠自动编码器(Stacked Autoencoders, SAE)同时分别学习用户和项目的潜在表示, 并利用学习到的表示使训练数据的误差最小化。Zhuang 等[1]认为推荐系统的主要目标是预测用户对一些他们之前没有注意到的商品的兴趣, 在训练已知数据用于预测未知数据时不仅要保持已知数据值的一致性, 还要保持值排序的一致性。同时考虑值和值排序可能比只关注一方更为合理, 也更可能具有高准确性。因此, 在ReDa 基础上考虑了用户-项目对的成对排序损失, 提出一种基于成对约束表示学习的协同排序框架(Representation Learning with Pair-wise Constraints, REAP), 进一步提升推荐系统的性能。

图7 ReDa 框架(R 为评分矩阵)Figure 7 ReDa Framework (R is the rating matrix)
Lee 等[27]考虑到以往采用负采样可能将实际为正但却未观察到的信息作为负样本这一局限性, 提出BUIR 框架。该框架不需要负采样而是采用两个相互学习的不同编码网络来保证正相关的用户表示和项目表示彼此相似, 并将随机数据增强应用于编码器输入中以缓解数据稀疏问题。Zhu 等[28]考虑了解决项目冷启动时存在的偏向问题, 提出一种可学习的后处理框架作为增强公平性的模型蓝图, 在此基础上提出联合学习生成模型和分数缩放模型, 使模型在保持推荐效用的同时提高公平性。Lin 等[29]为解决用户冷启动问题提出一种新的元学习推荐器, 即任务自适应神经过程(Task-adaptive Neural Process,TaNP)。该模型将观察到的每个用户的交互直接映射到预测分布中, 避免了基于梯度的元学习模型的一些训练问题。此外还引入任务自适应机制以平衡模型容量与自适应可靠性之间的平衡。
3.1.2 添加辅助信息
通过在协同过滤方法中加入辅助信息能够进一步缓解冷启动与稀疏性问题, 提高推荐性能。
Vandenoord 等人[30]将主题模型引入到学习过程中, 从文本信息中学习隐语义; McAuley 和Leskovec[31]提出了一种利用主题模型来理解评论文本评分的方法。在文献[32]中进一步利用评分和评论, 使主题与评级维度保持一致, 以提高预测准确性。Ren 等人[33]提出了一个潜在变量模型, 该模型可以根据用户意见和社会关系生成解释并预测项目评分。Rodrigues[8]提出一种将基于项目的协同过滤与用户人口统计信息结合到聚类加权机制中的框架, 能为新用户提供良好的推荐服务。Ji 等[34]提出一种基于矩阵分解的可伸缩协同过滤算法, 利用用户类别和用户关键字这两个决策矩阵代替单一的用户-项目评分矩阵进行预测。Yan 等[13]利用用户的年龄、性别、职业等特征对用户进行聚类, 之后计算属于每个聚类的所有用户对每个项目的评分的平均值, 以此来解决新用户问题。
Kim 等[35]将卷积神经网络(Convolutional Neural Networks, CNN)无缝地集成到PMF 模型中, 提出卷积矩阵分解模型(Convolutional Matrix Factorization,convMF), 该模型可以捕获上下文信息用于评分预测。Wang 等[36]提出了一种深度知识感知网络(Deep Knowledge-aware Network, DKN), 它将知识图表示融入到新闻推荐中。Wang 等[37]将使用堆叠去噪自动编码器模型的内容信息与使用协同过滤的评分矩阵相结合。此外, 其在文献[38]中还利用CNN 从音乐信号中学习潜在表示用于音乐推荐。Wei 等[39]结合时间感知CF 和深度学习方法解决项目冷启动问题。Bansal 等[40]使用循环神经网络(Recurrent Neural Network, RNN)将文本序列编码为隐语义, 然后使用顺序敏感编码器结合隐语义模型解决冷启动与稀疏性问题。文献[41]表明协同过滤可以看作一个序列预测问题, 将RNN 用于解决冷启动问题具有很强的竞争性。
Li 等[42]将矩阵分解与边缘化去噪自动编码器耦合并结合来自用户和项目的辅助信息对矩阵分解进行了泛化。He 等[43]提出一种贝叶斯二元神经网络框架(Bayesian Dual Neural Network framework, BDNet),不仅考虑用户和项目的辅助信息, 同时还考虑权重的不确定性问题。具体来说, 该框架由两个神经网络组成, 首先使用MLP 学习用户和项目的one-hot 编码的公共低维空间, 然后使用元素相乘的方法联结这两个隐藏表示到新向量中。同样通过MLP 将用户和项目的辅助信息投影到另一个共享的潜在空间中,并使用元素相乘的方法将用户和项目的辅助信息隐藏表示联结成一个新的辅助信息向量。面对辅助信息的不同类型, 采用不同类型的神经网络建模(如,对文本使用循环神经网络, 对图片使用卷积神经网络)。最后将两个神经网络的输出合并以产生最终预测。此外, 将高斯先验添加到所有的权重和偏置中可得到校准的概率分布, 以做出更稳健的预测。
由于好友推荐可以增加推荐的信任度且可以解决冷启动问题, 学者们开始考虑利用用户的社交关系进行推荐。Lin 等[44]利用社交信息解决项目冷启动问题。Ma 等[45]同时利用用户的社交网络信息和评分记录, 解决了数据稀疏和预测精度差的问题。其在文献[46]中提出了额外的社会正则化项, 确保两个具有相似口味的朋友的潜在特征向量之间的距离更近。Yang 等人[47]将现有的评分数据与朋友关系结合,推断出特定类别的社会信任圈。Cantador 等人[48]利用用户和项目信息, 根据社会标签的加权列表来定义Top-N 推荐。此外, 他们还在文献[49]中对社交系统中不同类型信息对项目推荐的影响进行了比较研究。
由于注意力机制在机器翻译中被证明是非常有效的, 基于注意力的推荐模型近年来得到了发展。Chen 等人[50]将隐语义模型(latent factor model, LFM)与基于项目和成分级注意力的邻域模型相结合, 对多媒体推荐中的隐式反馈进行建模, 取得了较好的效果。Han 等[51]提出一种考虑个体多样性的自适应深层隐语义模型(Adaptive Deep Latent Factor Model,ADLFM), 首先使用CNN 和LFM 生成项目的潜在表示, 然后使用余弦相似度计算项目之间相关度表示为注意力因素, 并将其作为项目权重, 最后将用户已评分项目的加权和作为用户表示。ADLFM 是第一个利用项目描述及注意力因素建模用户表示的工作。Chen 等[52]提出了一个基于协同过滤的模型, 即注意力驱动因子模型(Attention-driven Factor Model,AFM), 根据用户对商品不同角度的关注程度进行推荐。模型中的门控注意单元(Gated Attention Unit,GAUs)利用评分和商品特征评估用户偏好, 如图8 所示, 将用户ui的评分表示与商品的不同特征表示xj通过GAU 筛选出一个最有价值的输出用于预测。该方法可以针对不同用户生成注意力分布, 根据用户的注意力分布, AFM 可以得到很高的预测精度。此外,还可以通过向用户展示注意力分布图来帮助提高用户对推荐的信任。

图8 门控注意单元Figure 8 GAUs
异质信息网络作为一种有效的信息建模方法,也逐渐受到人们的关注。该种网络可以通过构建多种类型的实体以及实体之间的联系表示各种数据信息, 将不同数据信息应用到推荐任务中以带来更好的推荐效果。基于元路径进行相似度度量是最重要和最基础的一个方向。Sun 等[53]提出PathSim 算法,通过抽取用户间对称的元路径度量用户之间的相似性。Shi 等[54]提出基于元路径的双向随机游走算法HeteSim, 用于度量网络中任意节点间的相关性。Wang 等[55]提出OptRank 算法, 通过利用社会标签系统中包含的异质信息来缓解冷启动问题。Luo 等[56]提出一种基于异质关系的社会协同过滤算法。Shi 等[57]提出加权异质信息网络的概念, 提出SemRec 算法用于个性化推荐。随着网络表示学习的兴起, Shi 等[58]提出HERec 方法, 该方法基于元路径的随机游走生成节点序列以学习节点的嵌入表示, 并将其集成至矩阵分解框架用于推荐。Zhao 等[59]提出一种基于异质网络嵌入的推荐方法HetNERec。该方法从异质信息网络中提取多个共现关系来构建共现网络以解决基于元路径方法产生的稀疏性问题。
3.1.3 迁移协同过滤
迁移学习通过将一个领域(即源领域)的知识迁移到另外一个领域(即目标领域)使目标领域能够取得更好的学习效果。跨域推荐系统(Cross Domain Recommendation System, CDRS)通过迁移学习, 利用其他域的评分信息解决稀疏问题以提高目标域的预测。现有的CDRS 大致可分为迁移知识的方法和聚合知识的方法。
(1) 迁移知识。该方法将从源域学习的模式直接转移到目标域以提高目标域的推荐精度, 如图9所示。
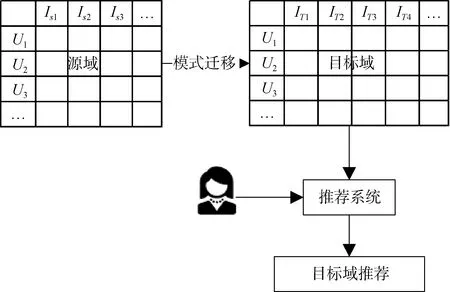
图9 基于迁移知识的跨域推荐Figure 9 CDRS based on transfer knowledge
Lee 和Seung[60]提出第一个用评分模式进行跨域推荐的方法。该方法根据域的相似度得分识别全局最近邻, 然后使用关联规则发现由一组邻居用户共同评价的项目, 最后使用基于用户的CF 算法进行评分预测, 使用包含目标项目的用户规则进行增强。码本迁移(Codebook Transfer, CBT)[61]将用户-项目评分模式从源域中的密集评分矩阵转移到目标域中的稀疏评分矩阵中, 该方法不需要用户或项目的重叠。Li等[62]将该思想扩展到概率框架的方法中, 提出评分矩阵生成模型(Rating-Matrix Generative Model,RMGM), 该模型不根据密集的源域数据来构建代码本, 而是提取所有评分矩阵的共享模式。此外, 用户或项目并不只属于单独的集群而是引入概率分布,允许用户和项目属于多个集群, 具有不同的参与度。
(2) 聚合知识。该方法同时从源域和目标域中学习模型, 并期望这些域能够相互补充。在此类方法中,源域和目标域应共享同一用户表示[63], 如图10 所示。
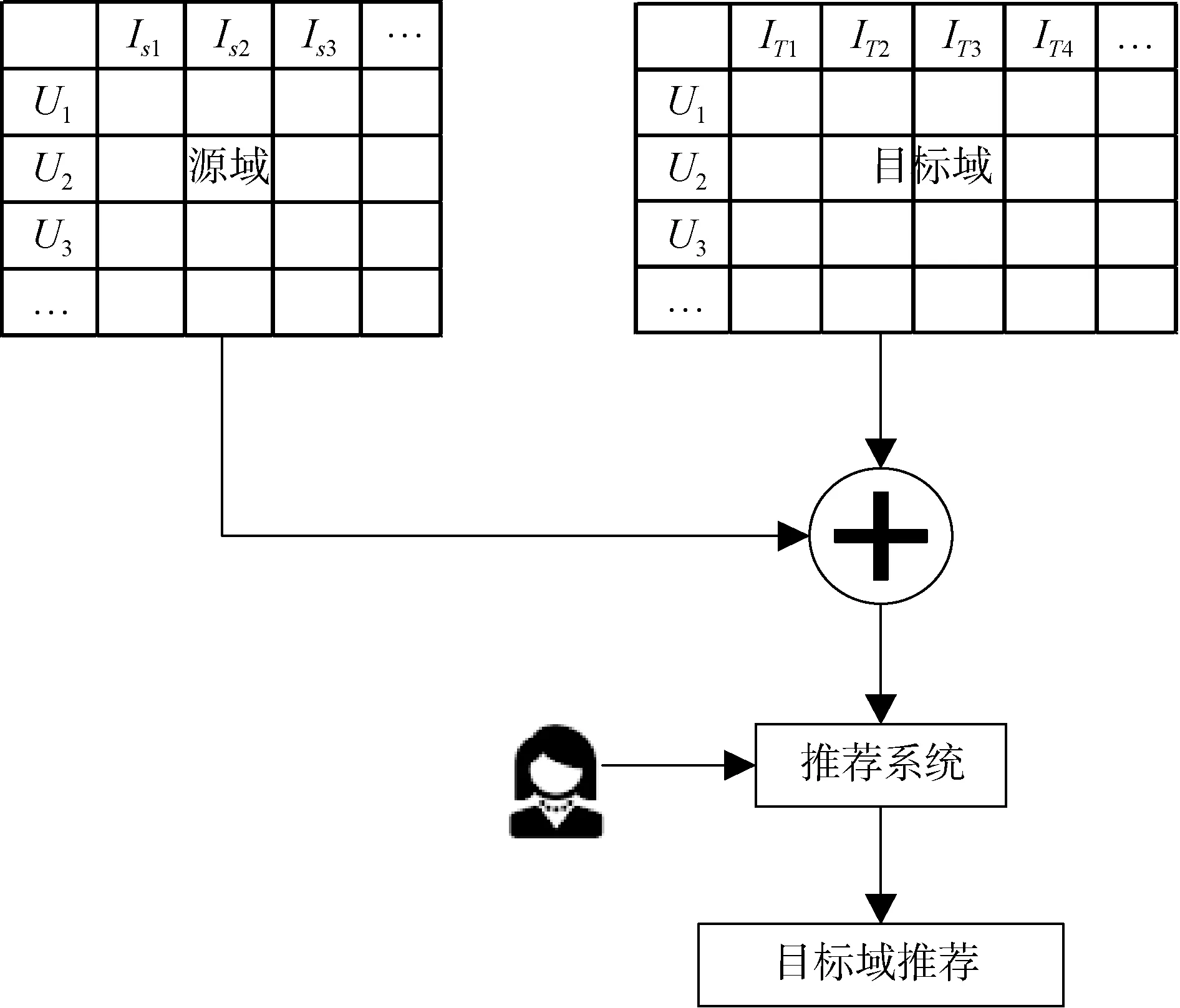
图10 基于聚合知识的跨域推荐Figure 10 CDRS based on aggregated knowledge
Shapira等[64]将Facebook点赞组成的数据集作为用户偏好证明了当可用用户偏好稀疏时, 使用聚合的方法能显著提高准确性。Shi 等[65]利用用户贡献标签作为共同特征, 提出一种广义标签诱导的跨域协同过滤模型。文献[66]提出多视图深度神经网络(Multi-View Deep Neural Network, MVDNN), 该模型是推荐系统中一种跨域的多视图深度学习方法, 其使用深度学习方法将用户和项目映射到潜在空间中,在该空间中用户与他最喜欢的商品之间具有最大相似度并且商品特征从不同域中联合学习。Lian 等[67]提出基于神经网络的跨领域推荐模型(Contentboosted Collaborative Filtering Neural Network For Cross Domain Recommender Systems, CCCFNet), 该模型利用神经网络将项目的辅助信息引入协同过滤中。文献[68]考虑到MVDNN 只使用辅助信息而没有考虑协同过滤, 没有利用用户和项目之间相关性这一优势, 因此将BDNet 框架中考虑了权重不确定性的协同过滤方法与MVDNN 框架中的跨域方法相结合, 提出一种使用贝叶斯神经网络的通用跨域框架(General Cross-domain framework via Bayesian Neural network, GCBAN)。Yu 等[69]考虑到源域和目标域中没有用户或项目重叠时直接共享两个域的嵌入可能会导致嵌入错位, 因此引入评论文本信息, 将两个域的嵌入分别与对应的文本语义空间对齐, 由此保证两个域的嵌入可以进行更准确的空间对齐。Zhang等[70]提出一种双迁移学习框架以解决数据带来的长尾问题, 该框架从模型级和项目级两个层面联合学习知识迁移, 通过合并两种迁移确保头部项目学习的知识可以很好地应用于长尾分布中的尾部项目表示学习。
由于现实场景中的许多应用往往涉及到不同领域, 学者们开始考虑利用多个源域的信息辅助目标域做出推荐。Moreno 等[71]提出多域迁移学习方法(Transfer Learning for Multiple Domains, TALMUD),该方法首先从不同源域中生成多个输出, 然后分配权重将它们整合在一起。Zhuang 等[72]提出一种基于共识正则化的多源迁移协同过滤框架(Transfer Collaborative Filtering Framework from Multiple Sources via Consensus regularization, TRACER)。该框架基于CBT 跨域协同过滤方法, 从多个源域迁移知识用于协同过滤, 并设计处理不同领域产生预期结果不一致问题的共识正则化。Yan 等[73]通过在跨域模型参数上加入很小却很重要的干扰, 发现模型性能下降很多, 认为跨域模型的鲁棒性不如单域模型。因此提出一种对抗跨域网络( Adversarial Cross-Domain Network, ACDN), 通过动态生成对抗样本来训练跨域推荐模型, 从而提高泛化性能。该对抗样本通过在输入样本中添加很小却有意义的干扰来生成, 使模型以高置信度给出错误输出。由于在输入层添加噪声可能会改变语义, 因此将对抗样本应用于底层推荐模型的参数中。ACDN 将MLP++[74]作为基础模型, 在MLP++目标函数中加入对抗样本以使其最小化。ACDN 的目标函数为:

其中nadv表示嵌入参数θemb的对抗干扰, θemb+nadv是对抗样本的表示。
文献[75]是跨域推荐在实际场景的一次应用, 利用线上网购行为与线下消费行为共同推动线下零售推荐。提出概率图模型, 即线上到线下主题模型(Online-to-Offline Topic Modeling, O2OTM)。该模型使用隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)主题模型对线上和线下活动进行主题建模并建立线上线下主题之间的关系。
3.2 可扩展性问题
随着互联网和信息计算的发展, 用户和项目的数量也急剧增长, 传统协同过滤推荐算法的计算过程和运算量将呈指数型增长, 会使推荐系统遭受很严重的可扩展性问题; 此外, 系统需要准确、实时地为系统中的所有用户进行推荐, 而这需要推荐系统具有较高的可扩展性。在协同过滤技术中, 基于模型的方法更易解决系统的可扩展性问题。
Yu 等[76]考虑了非参数矩阵分解方法, 令SVD 和概率主成分分析(probabilistic Principal Component Analysis, pPCA)的隐语义由数据驱动, 维数随着数据规模的增加而增加, 使非参数矩阵分解模型在大规模问题上更加有效。李聪[5]提出基于PCA 和竞争网络(Self-Organizing Map, SOM)聚类的协同过滤模型, 该方法首先利用基于项目的协同过滤补全空值评分, 然后利用主成分分析数据补全之后的项目,最后在主成分空间中对用户进行SOM 聚类。
基于用户聚类的工作中, Schafer等[9]首先对用户聚类以生成若干聚类中心, 然后计算用户与聚类中心的相似度生成类别所属的程度矩阵, 最后在矩阵中搜寻目标用户的最近邻。Gao 等[10]考虑到聚类算法容易将附近用户划分为不同集群, 而只为同一集群的用户进行推荐, 导致附近用户流失错过推荐。因此, 提出一种基于交叉聚类的方法, 首先定义关联度来寻找相邻的聚类, 然后合并用户聚类中的邻居来考虑近邻用户, 从而获得更多推荐机会。Koohi等[77]采用子空间聚类的方法寻找邻居用户来解决稀疏性问题。其通过将评分矩阵构造为三个子集来为用户的邻居创建了三层树, 实验证明在解决稀疏数据时是有效的。Xue 等[78]利用K-means 聚类算法, 根据用户的评分对用户进行聚类, 然后在聚类基础上进行平滑和邻域选择以填充用户-项目矩阵中的空白元素。Wang 等[79]利用K-means 算法对用户评分进行聚类, 解决协同过滤中用户和项目数量非线性增长时的稀疏性和扩展性问题。Kim 等[80]将K-means 聚类应用于网上购物系统, 根据用户的购买行为对其进行分类, 并利用遗传算法解决K-means 聚类中的局部最优问题。
基于项目聚类的工作中, 文献[4]将项目聚类与注意力因素相结合, 将其应用于疾病诊断中。Verma等[14]提出一种使用协同过滤与模糊C 均值(Fuzzy C-means, FCM)聚类算法的推荐系统。该系统利用FCM 聚类方法进行项目聚类, 使用协同过滤聚类进行评分预测。文献[15]基于Hadoop 进行项目聚类, 解决系统扩展性差、性能低的问题。文献[81]认为在找到用户邻居时应考虑目标项与每个共评项目之间的相似性。
3.3 多样性问题
该问题是指用户只能获得其用户画像中已知的或已定义的物品推荐, 阻碍用户发现新物品或其他选择。然而推荐多样性是一切推荐系统的目标。
Acker 和McReynolds[82]首次提出“新颖性”这一概念。随后, Rajus[83]研究了在人格特征、人口统计学变量和消费者背景下的探索性行为。Zhang 等[84]利用观察到的用户行为探索猎奇特征, 在单一领域对其建模, 如图11 所示。其中Z 表示猎奇水平; φ 表示选择效用分布, 即个体对每个选择的偏好; X 表示动作序列, 取值取决于此时的猎奇水平、选择效用分布φ和先前选择的动作。

图11 猎奇模型Figure 11 Novel Seeking Model (NSM)
Zhuang 等[85]受其启发, 在多个域中探索猎奇行为, 提出跨领域猎奇模型(Cross-domain Novelty Seeking Trait, CDNST), 该模型基于序列行为从辅助域迁移知识, 有效提高了推荐性能。Cheng 等[86]将多样化推荐视为一项监督学习任务, 定义了两个耦合优化问题, 提出一种多样化协同过滤算法来解决这两个问题。Gogna 和Majumdar[87]利用矩阵补全来平衡准确性和多样性。Xu 等[88]定义了一个具有高满意度和低初始兴趣度的新概念: Serendipity。基于此概念提出一个两阶段推荐问题, 包括Serendipity 预测和个性化推荐。在此基础上, 开发了神经意外发现的推荐(Neural Serendipity Recommendation, NSR)方法。如图12 所示, NSR 利用MF 来保证推荐的准确性, 利用MLP 来捕获新颖度, 通过合并MLP 和MF去预测Serendipity, 然后提出一种候选过滤方法, 它可以最大限度的从预测的Serendipity 中获取知识,缓解数据稀疏问题并给出个性化的推荐。

图12 神经意外发现推荐模型Figure 12 Neural serendipity recommendation model
3.4 可解释性问题
该问题是由于没有解释和理由的推荐是缺乏说服力的。给出合理解释可以提升推荐系统的透明度,提升用户对推荐系统的信任度和接受度, 进而提升用户对推荐产品的满意度。例如, 文献[2]在对话推荐中加入解释, 有效的提高推荐可信度。如图13 所示。

图13 可解释性会话推荐Figure 13 Interpretable conversation recommendation
文献[89]提出一种可解释矩阵分解模型(Explainable Matrix Factorization, EMF), 计算一个可解释的Top-N 项目排名列表。此外, 引入新的解释质量指标, 分别是平均解释精度(Mean Explainability Precision, MEP)和平均解释召回(Mean Explainability Recall, MER)。Zhang 等[90]提出一种基于模型的协同过滤方法, 即显因子模型(Explicit Factor Model,EFM)。该模型除了使用评分数据以外, 还基于项目特征和用户评论的情感分析作为数据源来生成可解释推荐。随后, 在文献[91]中将词云用于推荐中提供解释。Chen 等[92]将EFM 扩展为张量分解, 通过从文本评论中提取项目特征构造了用户-项目-特征立方体。基于这个立方体进行成对学习以预测用户对特征和项目的偏好并以此做出个性化推荐。Bauman等[93]提出情感效用逻辑模型(Sentiment Utility Logistic Model, SULM), 该模型通过提取特征及用户对这些特征的情感, 将两者整合到矩阵分解模型中, 对未知情感和评分进行拟合生成推荐。该方法不仅能为用户提供推荐的项目还能为项目提供推荐特征,特征即为推荐的解释。Qiu 等[94]和Hou 等[95]通过整合项目评分和评论, 研究了基于方面级别的隐语义模型。
Su 等[96]提出多矩阵分解(Multi-Matrix Factorization, MMF)模型。MMF 方法中具有权重的属性评分能得到每个属性对推荐的贡献程度, 从而可以提供可解释性。Kouki 等[97]基于概率模型提出一个混合推荐模型, 利用混合模型分析用户偏好, 并通过对在线用户的调查评价了文本、可视化及图形化的解释。Shulman 和Wolf[98]建立了基于每个用户决策树的可解释推荐系统以及基于单个属性值的决策规则, 从而得到一个协同过滤解决方案, 该方案可以直接解释它提供的每个评分。Hada 等[99]提出可以提供推荐解释的端到端框架ReXPlug, 其利用即插即用语言模型生成可解释性推荐, 并利用联合训练的交叉注意力网络来个性化推荐解释。Ghazimatin 等[100]提出人机协同框架Elixir, 利用推荐和解释的反馈去学习用户特定的潜在偏好向量, 同时通过基于项目相似性的邻域标签传播可以克服稀疏性。
4 未来研究方向
随着信息技术和互联网行业的发展, 信息过载成为人们处理信息的挑战。推荐系统能根据用户的浏览习惯, 确定用户的兴趣, 通过发掘用户的行为,将合适的信息推荐给用户, 满足用户的个性化需求。随着图神经网络、知识图谱等研究的发展, 将其与推荐系统相结合以做出更准确的推荐是必要的。
(1) 推荐系统与图神经网络
近年来, 由于图结构的强大表现力, 用机器学习方法分析图的研究越来越受到重视。图神经网络是一类基于深度学习的处理图域信息的方法。由于其较好的性能和可解释性, GNN 最近已成为一种广泛应用的图分析方法。推荐系统中的用户-项目交互关系可以看作一个图, 即用户和项目作为节点, 两者之间的交互作为边。同时还可以融入用户的社交网络、项目的属性信息等。
面对推荐中的用户与项目为不同类型的节点,可以应用异质信息网络; 面对数据稀疏以及长尾问题, 可以引入邻居采样等技术; 面对图的大规模问题, 可以进行采样以及子图训练等优化方式。
(2) 推荐系统与知识图谱
在多数推荐场景中, 物品中可能包含丰富的知识信息, 刻画这些知识的网络结构被称为知识图谱。一方面, 知识图谱中的结构化知识有助于缓解推荐中的冷启动等问题; 另一方面, 使用知识图谱能极大扩展物品信息, 强化物品之间的联系, 为推荐提供丰富的参考价值, 为推荐结果带来额外的多样性和解释性。由于现有的模型网络结构大多都是静态的, 而在真实场景中, 知识图谱具有一定的时效性。如何刻画这种时间演变的网络并在推荐时充分考虑时序信息是需要我们考虑的。
(3) 交互式推荐系统
目前的推荐结果大多由平台和算法主导, 用户比较被动, 只能接收推荐引擎输送过来的推荐结果。推荐过于单一或者推荐不感兴趣时用户没有调优与反馈的权利。可交互的推荐系统不仅可以通过数据的迭代来更新推荐算法, 还可以通过人机交互的方式帮推荐算法感知人们的情感色彩, 使推荐系统不仅能推断用户对物品的喜好, 还能感知用户对推荐算法本身的调优方向。
交互式推荐系统可分为两种思路: 一种是结合自然语言处理, 构建对话机器人, 通过与用户交谈来获得用户意图和偏好。其难点在于对话的理解与生成, 以及如何在对话过程中对推荐场景有所感知;另一种是交互式的意图挖掘, 利用用户的少量交互行为, 快速得到用户偏好以完成推荐任务。其难点在于交互形式倾向于强化学习算法的应用。
(4) 推荐系统的可解释性
近年来, 学者们发现在推荐时给出推荐理由会增加用户对推荐的认可度和接受度, 没有解释和理由的推荐是缺乏说服力的。互联网上的虚拟物品推荐, 如果能够像线下推荐一样, 在给出推荐的同时提供推荐解释、说明推荐原因, 可以提升推荐系统的透明度, 还能提升用户对推荐系统的信任度和接受度, 进而提升用户对推荐产品的满意度。在可解释性研究中, 一方面, 可以通过知识图谱来增强解释能力; 另一方面, 可以建立模型无关的可解释推荐框架。此外, 还可以考虑结合生成模型进行对话式推荐。
5 结论
通过对协同过滤推荐算法进行回顾, 可以发现在解决传统协同过滤算法存在的冷启动与稀疏性、可扩展性、多样性以及可解释性问题时, 目前的工作主要是利用评分数据、社交网络信息以及其他领域信息等辅助信息, 结合深度学习、数据挖掘等技术提高推荐效果、提升用户满意度。随着图神经网络、知识图谱等研究的发展, 将其与推荐系统相结合以做出更准确的推荐是未来一个重要的发展方向。
猜你喜欢
新班主任(2022年4期)2022-04-27
科学大众(2020年23期)2021-01-18
铁道通信信号(2019年6期)2019-10-08
汽车观察(2019年2期)2019-03-15
雷达学报(2017年6期)2017-03-26
中国卫生(2016年5期)2016-11-12
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
互联网天地(2016年1期)2016-05-04
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
