
高血压性心脏病生物标志物的筛选:基于中国重庆市7 家医疗机构的数据分析研究*
2021-11-09 01:30张雪梅钟小钢陈颖哲汪曾子冉淑琼向天雨谢友红孙兴国
中国应用生理学杂志 2021年2期
张雪梅,钟小钢,,龚 军,田 君, 张 谊,陈颖哲,崔 婧,汪曾子,冉淑琼,向天雨,谢友红,孙兴国,3△
(1.重庆医科大学附属康复医院,重庆 400050;2.重庆医科大学医学数据研究院,重庆 400016;3.国家心血管病中心中国医学科学院阜外医院,北京 100037;4.首都医科大学附属北京中医院,北京 100010)
高血压是全世界导致心血管疾病及死亡的主要危险因素[1]。有研究显示,预计到2025 年,全球将有15.6 亿人受高血压的影响[2]。高血压性心脏病(hypertensive heart disease, HHD)是由高血压所引起的以左心室肥厚为特征的疾病,如得不到有效控制,则会逐渐出现代偿性负荷增加,最终导致心力衰竭[3,4]。先前的研究显示,HHD 与死亡风险增加相关,但鲜有价值的生物标志物可预测临床实践中从单纯性高血压到HHD 的进展[5,6]。因此,本文利用机器学习等算法建立高血压进展至HHD 的预测模型,为HHD 的发生提供诊断方法。
1 对象与方法
1.1 资料来源
数据来源于某医科院校医学数据研究院,该平台共包含7 家附属医院的医疗数据。根据国际疾病分类 第10 版(international classification of diseases 10th edition, ICD-10)从该平台选取2016 年1 月1 日至2019 年12 月31 日诊断为高血压性心脏病或高血压的病例,诊断标准根据中国2018 年高血压指南并参考美国AHA、ACC2017 高血压指南和欧洲ESC2018高血压指南[7-9]。实验组纳入标准:(1)主要诊断为HHD;(2)病案首页中有明确的原发性高血压诊断。排除标准:(1)由其他疾病引发的心脏病[7-9]。对照组纳入标准:(1)主要诊断为明确的原发性高血压[7-9]。排除标准:(1)继发性高血压[7-9];(2)其他疾病引发的高血压[7-9]。
1.2 分析指标
选取研究对象的人口学信息,包含性别、年龄、饮酒、吸烟等;相关的实验室检查、检验指标,包含血细胞分析、生化检查、血清离子、凝血功能检查等共计85 项指标。
1.3 统计学处理
采用Excel 2013 录入并核对数据,SPSS 和R 3.6.1 进行统计学分析。采用t检验、卡方检验、非参数秩和检验进行单因素分析。采用logistics 回归模型(α入=0.05,α出=0.10)进一步筛选影响因素。采用random Forest 包、xgboost 包分别建立随机森林(random forest, RF)模型、极限梯度上升(extreme gradient boosting, XGBoost)模型。采用曲线下面积(area under the curve, AUC)等指标评价模型的性能。对于缺失率≤30%的指标采用missForest 包进行填补[7]。
2 结果
2.1 基本信息
共计获得有效病例5 155 例,其中HHD 3 020 例,原发性高血压2 135 例。病例以老年人为主。男性比例低于女性比例。删除缺失率大于30%的指标,对缺失率小于等于30%的指标进行填补[10],共有78 项指标纳入后续分析。
2.2 单因素分析
实验组和对照组在性别、吸烟、饮酒、年龄、收缩压、舒张压、中性粒细胞计数、中性粒细胞百分比、单核细胞计数、单核细胞百分比、嗜碱性粒细胞计数、嗜碱性粒细胞百分比、嗜酸性粒细胞计数、嗜酸性粒细胞百分比、大型血小板比率、平均红细胞体积、平均红细胞血红蛋白含量、平均红细胞血红蛋白浓度、淋巴细胞计数、白细胞计数、红细胞分布宽度变异系数、红细胞分布宽度标准差、红细胞计数、血小板分布宽度、平均血小板体积、血小板计数、血红蛋白、γ.谷氨酰基转移酶、丙氨酸氨基转移酶、乳酸脱氢酶、低密度脂蛋白胆固醇、前白蛋白、天门冬氨酸氨基转移酶、尿素、尿酸、总胆固醇、总胆红素、总蛋白、球蛋白、甘油三酯、白蛋白、直接胆红素、碱性磷酸酶、肌酐、葡萄糖、载脂蛋白A1、载脂蛋白B、间接胆红素、高密度脂蛋白胆固醇、氯、磷、钙、钠、钾、镁、D.二聚体、凝血酶原时间、活化部分凝血活酶时间、纤维蛋白原这59 项指标有统计学差异(P<0.05,表1)。
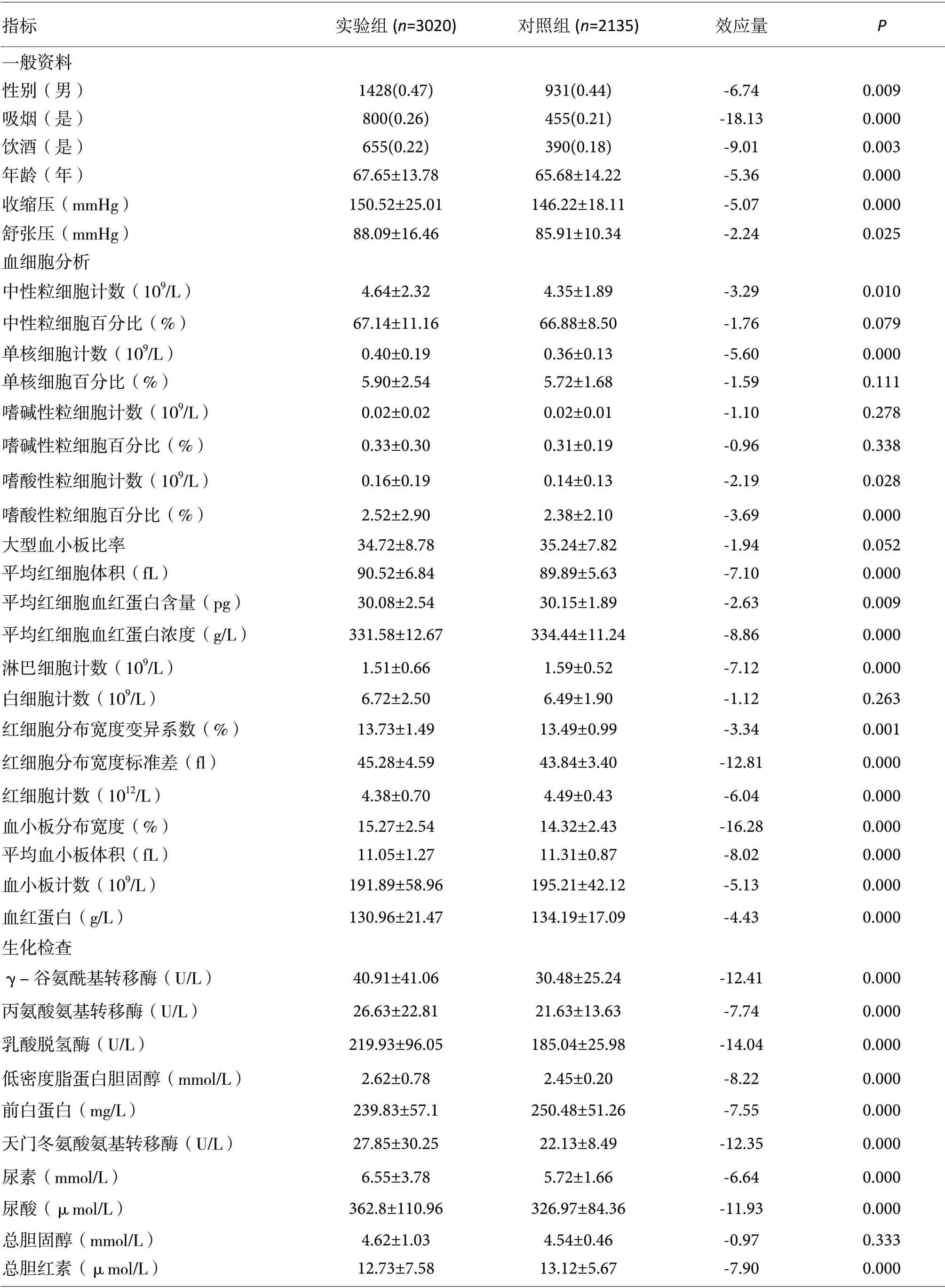
表1. 高血压性心脏病(HDD)相关指标单因素分析
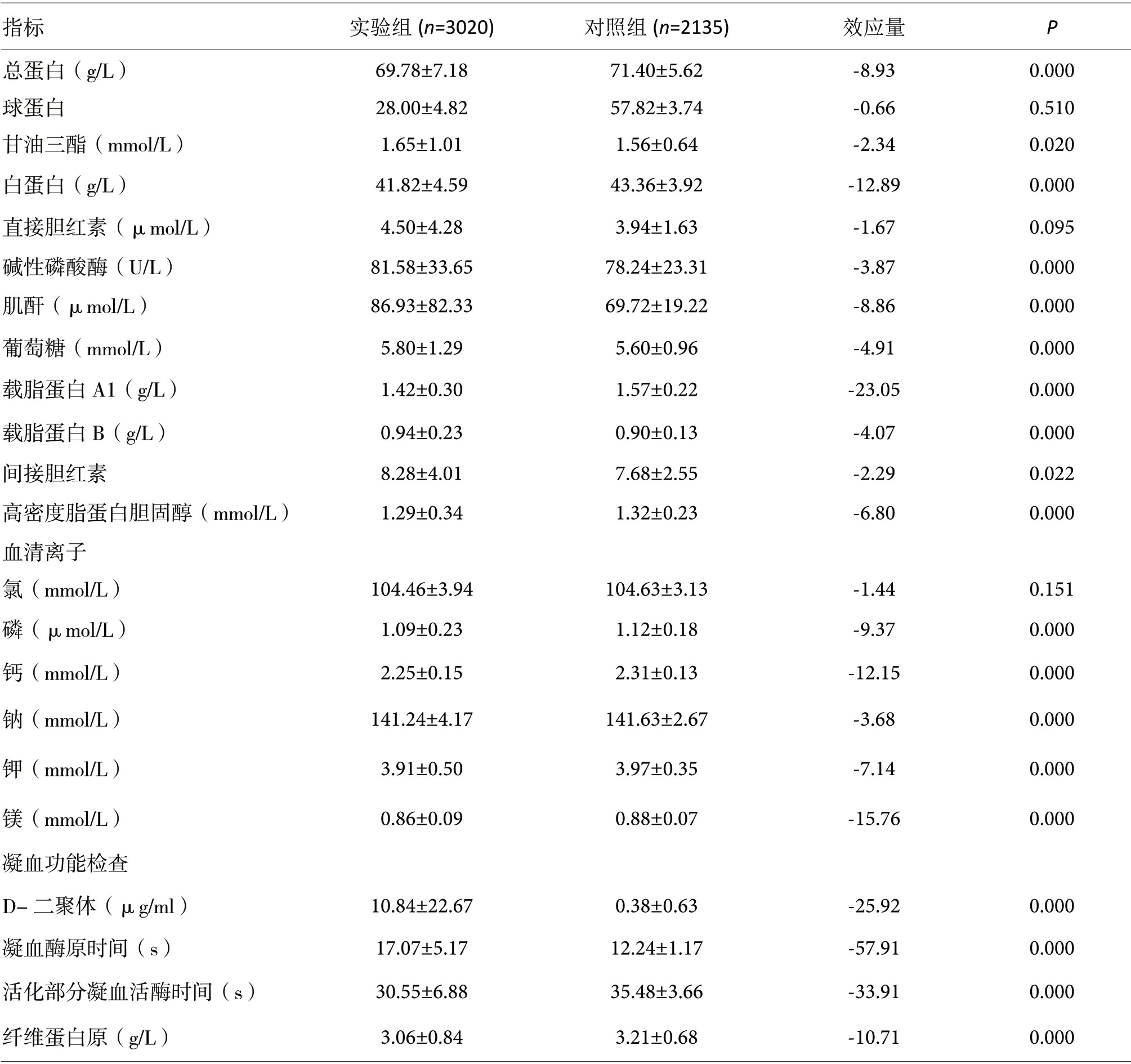
续表1. 高血压性心脏病(HDD)相关指标单因素分析
2.3 多因素分析
为进一步探索HHD 的影响因素,我们将单因素有统计学差异的指标纳入二元Logistics 回归模型分析,结果显示γ-谷氨酰基转移酶、乳酸脱氢酶、凝血酶时间、天门冬氨酸氨基转移酶、平均红细胞血红蛋白浓度、总胆红素、活化部分凝血活酶时间、淋巴细胞计数、红细胞分布宽度变异系数、纤维蛋白原、肌酐、血小板分布宽度、平均血小板体积、载脂蛋白A1、间接胆红素、高密度脂蛋白胆固醇、磷、镁这18 项指标仍具有统计学差异(P<0.05,表2)。
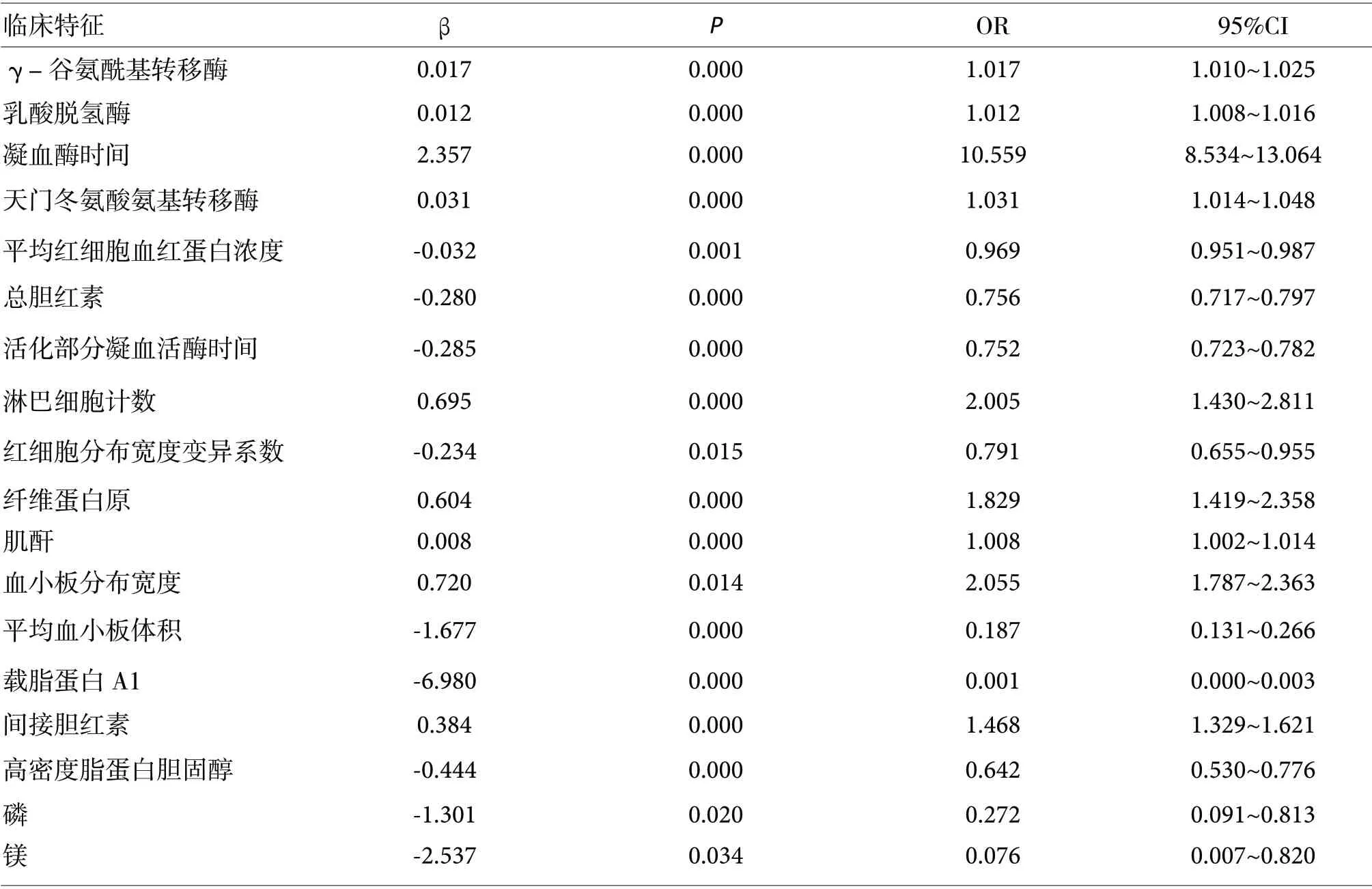
表2. 高血压性心脏病(HHD)差异性指标Logistic 回归分析
2.4 机器学习算法模型
将所有样本以7 ∶3 的比例随机分配到训练集和测试集中(训练集中实验组样本2 107 例,对照组样本1 502 例;测试集中实验组样本913 例,对照组样本633 例),训练集用于探究模型最优参数,测试集用于评价模型。通过训练集发现当max-depth 为0.8 时,XGBoost 模型的性能最优;当mtry 为5 时,随机森林模型的性能最优。此时测试集XGBoost 模型、随机森林模型的AUC 分别为0.990 和0983(表3)。

表3. 不同模型性能评价表
3 讨论
HHD 是由高血压所引发的并发症,通常以左心室肥厚、血管及心室硬化、心室充盈受损为主要临床表现,如不积极治疗,会导致心力衰竭[11]。临床上,主要采用心电图、超声、心血管磁共振特征追踪等手段对HHD 进行诊断[12,13]。但有相关研究显示,心电图对于左心室肥厚的测量,尤其是对于肥胖患者,具有敏感度低等特点,而心血管磁共振特征追踪技术存在价格较高等特点[8]。因此,寻找用于诊断HHD 的生物标志物非常必要。
本文通过某医学数据研究平台,选取了高血压和HHD 患者共计5 155 例患者的85 项指标。相对于高血压患者,通过单因素和多因素分析发现HHD 患者的γ-谷氨酰基转移酶等18 项指标存在统计学差异。本文建立的3 种预测模型发现XGBoost 机器学习算法模型最优,可实现γ-谷氨酰基转移酶等18 个指标的敏感度为0.993,特异度为0.984,曲线下面积为0.990的良好预测模型。
研究显示国内外进行了多项针对HHD 诊断标志物的筛选,如学者Kangxing Song 等人通过meta 分析发现HHD 患者血浆中的心肌营养素-1(cardiotrophin-1)明显升高[6]。国外学者Begon˜aLo´pez 等人发现血浆中心肌营养素-1 浓度用于预测HHD 的敏感度为0.70,特异度为0.75[14]。学者张光彩等人发现相对于高血压患者,HHD 患者的血清超敏反应蛋白和同型半胱氨酸升高,可作为预测HHD 不良事件发生的效应指标[15]。学者初志辉等人发现超声心电图联合亲环素A 和亲环素B 诊断HHD 可实现敏感度为0.94,特异度为0.90,曲线下面积为0.987,具有良好的诊断结果[16]。本文建立的XGBoost 预测模型无论是灵敏度、特异度还是曲线下面积,均优于上述的预测模型。其次,本文还基于上述18 个差异指标同时建立了Logistics 回归模型、随机森林模型,所有模型的灵敏度、特异度和曲线下面积均超过了0.90,说明指标比较稳定,模型比较可靠。
本研究的优势包括:(1)选取的指标广,包含了生化检查等78 项指标;(2)样本量大,数据来源于7 家医疗机构;(3)得出的结论相对可靠,同时使用了3 种预测模型,且分成了训练集与测试集。本研究也存在一些不足之处,比如(1)对于缺失率超过30%的指标,采取了直接删除,其于HHD 的关系有待进一步探索;(2)本文预测模型包含18 个指标,指标个数相对较多,有待进一步精简及优化。
猜你喜欢
家教世界(2022年34期)2023-01-08
中老年保健(2022年2期)2022-08-24
中老年保健(2022年5期)2022-08-24
现代临床医学(2021年6期)2021-11-20
妈妈宝宝(2017年4期)2017-02-25
医学研究杂志(2015年3期)2015-06-10
中国当代医药(2015年21期)2015-03-01
云南畜牧兽医(2015年4期)2015-02-28
中学科技(2014年12期)2015-01-06
中国实用医药(2014年31期)2014-11-12
