
面向图像场景转换的改进型生成对抗网络∗
2021-11-09 05:51肖进胜周景龙雷俊锋杜治一
软件学报 2021年9期
肖进胜,周景龙,雷俊锋,李 亮,丁 玲,杜治一
1(武汉大学 电子信息学院,湖北 武汉 430 072)
2(湖北第二师范学院 计算机学院,湖北 武汉 4 30205)
许多计算机视觉问题可以被看作是一个图像到图像的翻译问题,是映射一个域中的映像到另一个域中的对应映像,实际上都是像素到像素之间的映射.例如:超分辨率可以认为是将低分辨率图像映射到相应的高分辨率图像的问题,而图像着色可以看作是将灰度图像映射到相应的彩色图像.这个问题可以在有监督和无监督的学习环境中进行研究.在无监督学习中,只有两组独立的图像,其中一组图像组成一个域,另一个域包含另一组图像,但训练图像不匹配,即不是成对的训练集.由于缺乏相应的图像,无监督的图像到图像转换问题更难考虑也更难实现.在有监督学习中,可在不同的域中训练配对相应的图像[1,2],有监督学习能够使生成图像与输入图像像素之间的映射关系更加准确,能够避免类似无监督学习中出现的生成图像不可控的现象.
利用卷积神经网络(convolutional neural net works,简称CNN)进行有监督学习,在生成图像时也需要最小化损失函数,并作为网络调优的标准.然而,在采取了这种方法时,要求CNN 尽量减少预测图像与真实图像之间的欧氏距离,它可能会产生模糊的结果[3,4],其原因是欧式距离通过平均所有像素的输出而导致模糊.因此,要让CNN 网络针对特定的转换任务就需要制定特定的损失函数,但这是一个棘手的难题.如果可以指定网络只有一个高层次的目标,比如“使生成图像难辨真伪”,然后自动学习一个损失函数以实现此目标,这种方式也就是生成对抗网络的思路(generative ad versarial n ets,简称GAN)[5−8].GAN 尝试分类输出图像是真实或者伪造的,同时训练生成模型,其损失函数可以应用于传统上需要种类差别很大的任务.在这样的背景下,如何利用优化GAN 网络进行有监督学习、进行图像的各种转换,都已经渐渐成为研究热点.
图像转换包含多种类型,比如图像的风格转换,将水墨画转换成山水画、将真实图像卡通化;图像的色彩转换,比如彩色与黑白图像之间;图像的内容转换,比如卫星图像与地图的转换、斑马与马的转换;图像的场景转换,比如白天到黑夜等等.这些对图像的变换、纹理调整、风格化编辑,在艺术、科研、工程领域均有所应用.然而,由于时间、地点和相机参数等限制,通过人工方法采集同一景物不同场景的图像有很大的困难;而通过图像处理的方法,比如进行超分辨率、锐化、去噪[9]等方式对图像进行优化,提升图像质量,是一条可行性较高的途径.
作为图像转换领域的代表,图像风格转换相关领域研究趋于成熟.现有的图像风格转换有两类:一类是基于全局[10],通过匹配像素颜色的均值和方差或其柱状图来实现样式化;另一类是基于局部[11,12],通过利用低层次或高层次特征内容和风格照片之间的密集对应关系对图像进行风格化.这些方法在实践中很耗时,并且通常是为特定场景来设定的.Gatys 等人[13]提出了艺术风格的神经风格转换算法,其主要步骤是解决从内容图像和风格图像中提取深层特征与Gram 矩阵匹配.目前已有了许多方法,在此算法上[14−16]进一步提高其性能和速度.然而,这些方法有时生成的图像不够真实,所以还需要在此基础上进行后处理[17],来匹配输入图像与输出图像的梯度.
高保真的图像风格化与图像到图像的翻译问题[18−22]有关,目标是学习将图像从一个域翻译到另一个域.然而,真实照片图像的风格化并不需要学习翻译功能的内容和风格图像的训练数据集.照片写实图像的风格化,可以看作是一种特殊的图像到图像的转换,用来把照片翻译成不同的领域(例如从白天到晚上).Luan 等人[23]通过在优化目标中加入一个新的损失函数,提高了风格转换算法计算出的风格化输出的真实感,从而更好地保留图像内容中的局部结构.然而,它通常会产生不一致的风格化;此外,该方法的计算成本也很高.Pix2pix[1]将条件GAN[24]用于不同的图像转换,例如将谷歌地图转换为卫星视图等.在没有训练对的情况下,实现图像到图像翻译的各种方法[19,21,25]也陆续被提出.而Chen 等人[26]指出:由于训练的不稳定性和优化问题,条件GAN 训练难以生成高分辨率图像.为了避免这种困难,提出了感知损失[27].生成的图像是高分辨率的,但往往缺乏细节和现实的纹理.
基于以上的研究,本文提出了一种新型的基于生成对抗网络的图像场景转换算法,主要有如下3 点创新.
首先,设计了新的生成器网络结构.主要采用带跨层连接结构的深度卷积,通过跨层连接能够实现底层卷积与顶层卷积的信息共享,更好地保留了图像的内容结构,最终使输出图像与输入图像的结构和边缘保持一致;
其次,设计了多尺度判决器网络结构,分别对图像的不同尺度进行判决.当判决器的输入图像为大尺度时更关注图像的细节,小尺度时更关注图像的结构.这样将大小尺度相结合的方式,能够在判决时兼顾图像的细节和结构;
最后,提出了新的损失函数.基于常用的损失函数GAN 损失和L1损失,加入了VGG 损失和FM(特征匹配)损失,以利用VGG 网络和判决器网络来增加对生成对抗网络的控制,最终使生成图像与目标图像更加接近.
1 相关工作
图像转换是一个经典的计算机视觉任务,而近些年,以卷积神经网络为代表的深度学习算法的流行,让这一任务有了显著的突破.2014年,Goodfellow 提出了生成对抗网络[5],基于GAN 的算法在图像转换上表现良好,Pix2pix,CycleGAN,MUNIT 等模型陆续被提出.参考这些算法,本文提出了一种新型的基于生成对抗网络的图像场景转换算法.
1.1 生成对抗网络
生成对抗网络(GAN)[5]是一种无监督的机器学习方法,有两个网络模型:生成器(generative model)和判决器(discriminative m odel),两个网络相互对抗相互牵制.判决器是判定一个样例是来自数据集还是生成器合成的图像,生成器目的是尽可能使生成图像以假乱真以迷惑判决器难辨真伪.两个网络模型相互对抗来提升各自的算法能力,直到判决器无法分辨出合成图像与真实图像.在数据集中真实图像中,生成器想要从y中学习其分布,定义输入噪声变量pz(z),则损失函数定义为
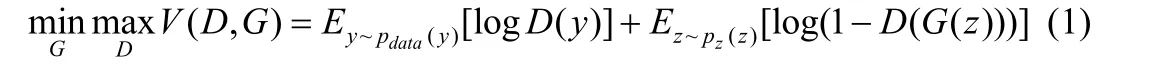
z表示输入生成器G的噪声,而G(⋅)表示G网络生成的图片.D(⋅)表示判决器D网络判断真实图片是否真实的概率,E为数学期望.由于其为无监督学习,该方法应用范围十分小,无法实现像素与像素之间的转换.
1.2 CycleGAN
CycleGAN[21]利用非成对图像进行训练,主要贡献在于提出了循环一致性损失.该损失要同时学习正向和反向两个映射,设正向映射也即G:X→Y,反向映射F:Y→X.并要求图像能够从一个方向转换后,还可以反向转换,实现一个循环.即F(G(x))≈x和G(F(y))≈y.循环一致性损失可以定义为
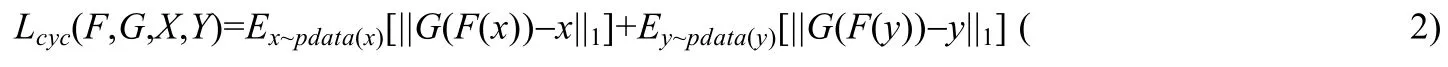
同样还引用GAN 损失.正向映射G:X→Y,定义其判决器为DY,则其GAN 损失为
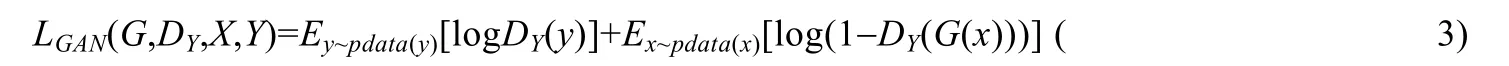
由于循环一致性,则定义反向映射的判决器为DX,由此可以同样定义LGAN(G,DX,X,Y).最终的损失就由3 部分组成:
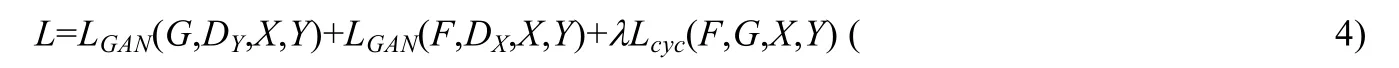
该方法在Pix2pix 基础之上修改损失函数.由于图像的训练集不需要成对的数据进行训练,该方法的应用范围更加广泛.但是由于训练集不匹配,只能通过训练去猜测真实的映射关系,因此其学习到的映射关系可能会出现偏差.
1.3 MUNIT模型
MUNIT(multimodal unsupervised image-to-image translation)即多模态非监督图像翻译算法[22],算法中通过图像编码分别获得图像集Xi的风格空间Si和共同的内容空间C.实现从图像x1转换到x2,将输入图像的内容c与转换目标的风格s2相结合.不同的风格得到不同的转换结果.该网络的损失函数包括两部分:一是双向重建损失,二是GAN 损失.
双向重建损失有两部分——图像重建和潜在重建.生成网络用G表示,E表示G的反向操作.图像重建损失表示为
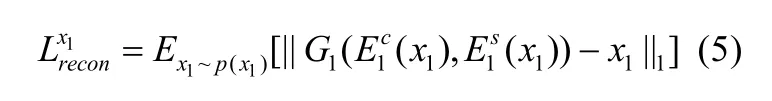
潜在重建损失表示为
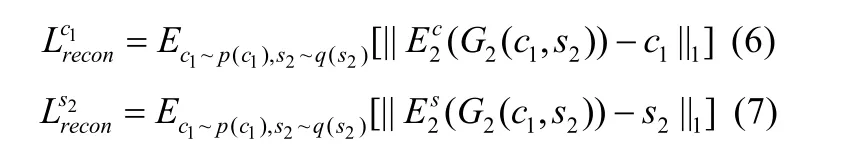
GAN 损失表示为
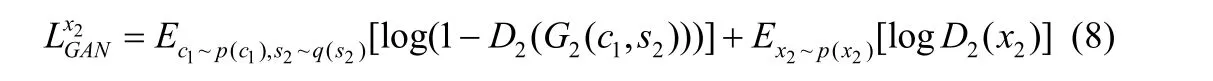
因此,网络的优化目标可以表示为
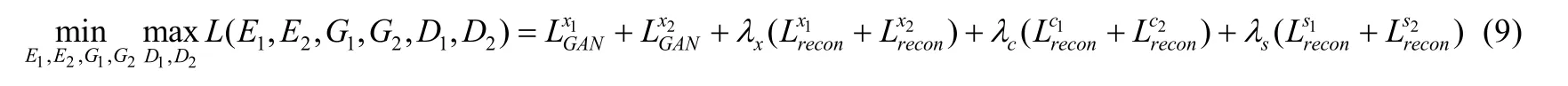
1.4 Pix2pix
Pix2pix 算法[1]是一个条件GAN 框架,用于图像到图像的转换,由生成器G和判决器D组成.生成器G网络目的是学习输入图像x到目标图像y的映射G:x→y,使生成图像与目标图像十分接近,难辨真假;判决器D网络的目的是尽可能判断出图像是生成图像还是真实图像.对以下公式进行网络优化:

其中,lossGAN为生成对抗网络损失函数,loss1L为L1损失,λ为可调参数.lossGAN定义如下:
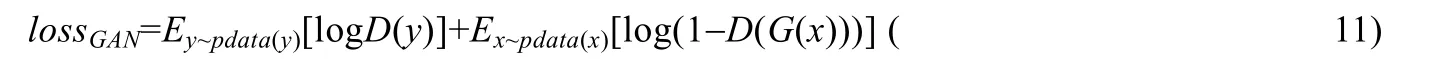
其目的是使GAN 网络生成器与判决器相互制约,共同优化.loss1L定义如下:
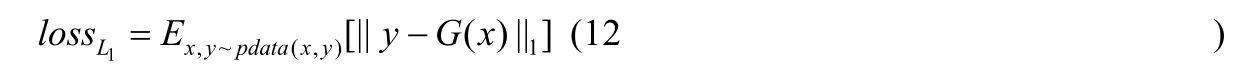
因为图像生成本质上是回归问题,所以使用L1损失对生成图像进行限制.Pix2pix 方法采用U-net 作为生成器以及patchGAN 的卷积网络[28]作为判决器.
2 基于生成对抗网络的图像转换算法
本文提出的基于生成对抗网络的图像场景转换算法主要分训练和测试两个阶段.在训练阶段将GAN 网络模型进行优化,使得在测试阶段输入图像通过GAN 网络模型得到输出图像.通过生成网络和判决网络不断迭代,优化网络参数.算法流程图以图像加雾实验作为示例,如图1所示.本节将对生成器、判决器及损失函数进行阐述.
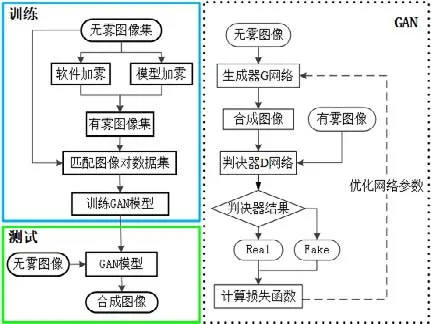
Fig.1 Algorithm flowchart图1 算法流程图
2.1 生成器结构
2.1.1 跨层连接生成网络
以图像加雾为例.本文在生成器网络G设计上采用跨层连接,是由于在图像转换中有大量的信息在输入和输出之间共享,并需要直接在网络上传输这些信息.例如进行场景转换时,输入和输出共享突出边缘的位置.网络结构如下.
如图2所示:网络整体呈现左右对称的结构,左侧为卷积操作,右侧为反卷积操作.
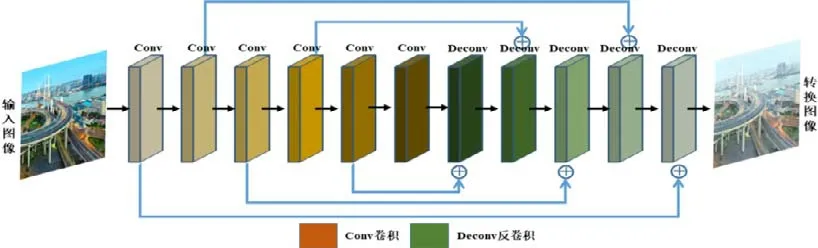
Fig.2 Generator network structure图2 生成器网络结构
将卷积层-batch Normalizati on(BN 层)-prelu 看作一个模块,记为一层.输入图像经过多层卷积操作,得到中间层,这时如图右侧表示,相应的卷积层再进行反卷积,此时,将反卷积层-batch Norm alization(BN 层)-prelu 看作一个模块,记为一层.同时,再与左侧对应的卷积层信息直接相加,最后得到图像的输出.每个卷积层和反卷积层的参数设置为卷积核大小为4×4,padding 为0,stride 为1.
2.1.2 生成器网络模型对比
本文设计的生成器网络与pix2pix 网络同样利用的跨层连接,但网络整体结构不同:pix2pix 网络采用编码器-解码器结构,先进行多层下采样再进行多层上采样,每经过一层下采样,图像的长宽各减小一半;本文的生成器网络没有进行上采样和下采样,而是单纯地进行多层卷积和反卷积操作.为了证明本文提出的算法生成器结构的优越性,比较了两种算法的实验结果.实验时,网络的判决器个数为1,损失函数为GAN 损失和L1损失.本文以图像加雾的训练集进行训练,加雾结果如图3所示.

Fig.3 Comparison of different generator structures图3 不同生成器结构结果对比
由图3 可见,两种算法的加雾效果在细节上有所不同.Pix2pix 在平坦的区域有块效应出现,而本文效果较为平滑,如图中的右下部分实线框区域.
2.2 判决器结构
2.2.1 多尺度判决网络
GAN 生成图像的难点在于让生成图像的过程可控,即生成更加真实和清晰的图像,而这对GAN 判决器设计提出了重大挑战.为了区分真实图像和生成图像,判决器需要具有大的感受野.这就需要设计更深的网络结构或者采用更大的卷积核,但两者都会增强网络能力并可能导致过拟合.此外,这两种选择由于增加了网络复杂程度,都需要更大的内存占用.为了解决这个问题,本文采用多尺度判决器,也即多个判决器在不同尺寸的输入图像下进行.本文最多使用了3 个判决器,分别记作D1~D3.当使用3 个判决器时,是分别对图像下采样一倍和两倍再进行判决.
D1~D3的网络结构如图4所示,由多个下采样层和一个输出判决层组成,只是输入图像的尺寸不同.输入图像为大尺度时更关注图像的细节,小尺度时更关注图像的结构.
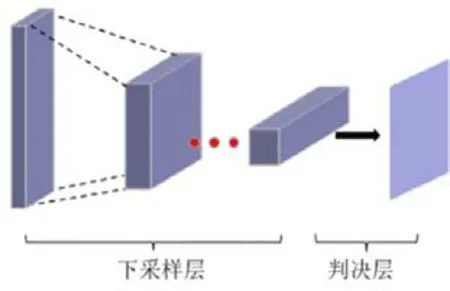
Fig.4 Discriminator network structure图4 判别器网络结构
2.2.2 多尺度判决器数目
本文采用多尺度判决器,即多个判决器在不同尺寸的输入图像下进行.因此,判决器个数的选择至关重要.因为在不同尺度下进行判决,小尺度图像作为输入时能够更多关注图像的整体结构和边缘,大尺度图像作为输入则更多关注图像的细节保留.判决器个数少,则影响生成器效果.理论上是判决器越多越好,但也并非如此.判决器越多,一是增加了网络的复杂度和计算量,影响训练时间;二是判决器个数与输入图像本身尺寸有关,如果输入本身尺寸适当,非大尺寸或超大尺寸,判决器没必要过多.于是,针对判决器的个数选择多少较为合适,在本文研究的特定情况下,进行了以下实验.本文在加雾训练集上进行训练,图像输入大小为256×256,分别测试判决器个数为1~3 的情况下,迭代60 个epoch 的效果.
从整体上来看,判决器的个数对生成图像的内容影响不大,但在细节上会有所差别.由图5 可见,当num_D=1时,景物的细节会出现缺失.比如图5 中建筑的横线,而当num_D为2 或3 时,两张图片相差不多,细节保持都较好.num_D=3 时,图像颜色更亮一点,只是略有提升,但是效果并不明显.同时,图5 中的天空部分,当num_D=1 时会出现失真.而由于原始生成图像天空区域较亮,放大后依然很难观察到差别.于是,本文对天空区域进行了处理,变换公式如下:

其中,im_newr,g,b为输出的图像,imr,g,b为变换前图像.变换后图像如图放大区域所示,当num_D=2 或3 时,天空颜色则较为均匀.考虑到网络复杂度和计算量,在本文所有实验中,判决器的个数num_D=2.

Fig.5 Comparison of different number of discriminators图5 不同个数判决器结果对比
2.3 损失函数
2.3.1 损失函数组成
本文损失函数共使用了4 种,GAN 损失、L1损失、VGG 损失和FM(feature matching,特征匹配)损失.首先,对于生成对抗网络,由于本文使用多尺度判决器,因此生成对抗网络的优化问题表示为

x为输入图像,y为目标图像.其中,GAN 损失表达为
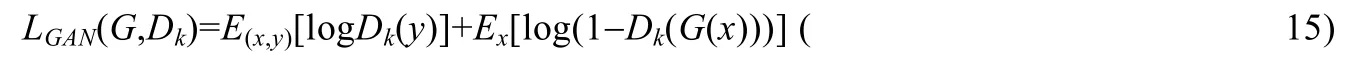
该算法对于生成器的生成结果还要加入限制,对生成图像进行评价,引入L1损失:

为了使输出图像更加逼近真实图像,引入特征匹配(FM)损失.具体来说,从判决器多个层来提取特征并学习来匹配真实图像和合成图像的中间特征.表示第i层特征提取器(从输入到Dk判决器的第i层).然后计算FM损失LFM(G,Dk)如下:
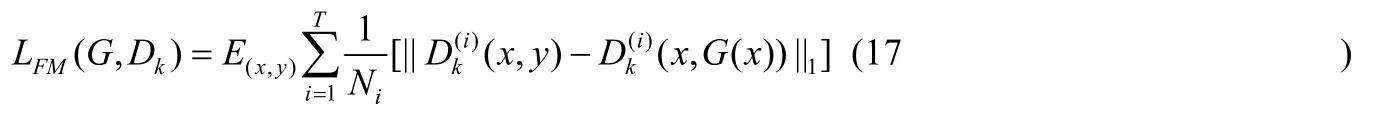
其中,T是判决器总层数,Ni表示层数每层中的元素数量.为了两个图像特征之间的差距,引入VGG 损失,通过预先训练的VGG 网络,提取图像的特征,定义FM 损失为
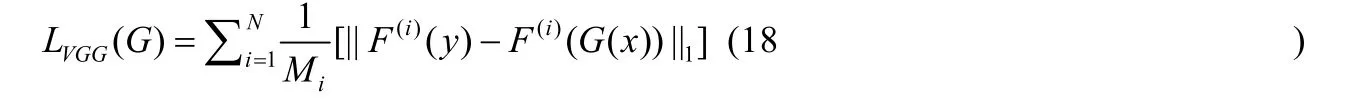
其中,F(i)表示VGG 网络的第i层,Mi表示该层的元素个数.因此,本文算法最终总的损失函数优化目标表示为
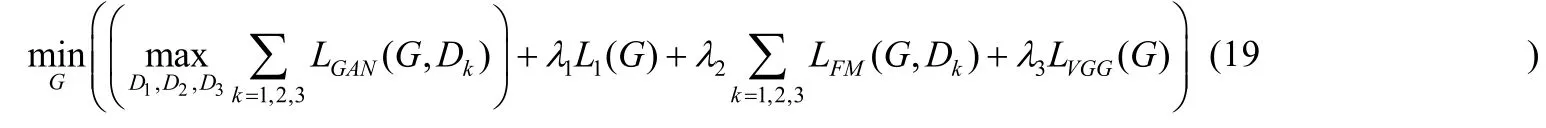
而对于损失函数各个部分的作用,本文将在第2.3.2 节中进行实验分析,验证本文算法改进的损失函数的有效性和必要性.
2.3.2 损失函数的设置
本文的损失函数一共由4 部分组成,分别为:GAN 损失,L1损失,FM 损失,VGG 损失.本文算法是基于GAN框架,故对比了总损失(total loss)、不使用VGG 损失(no_VGGloss)、不使用L1损失和FM 损失(no_matchingloss)这3 种情况下的实验结果.
由图6 可以看出:在不使用VGG 损失时,则会出现图像失真,比如图6 中,线框区域,在天空、跑道等位置会出现不规则椭圆形的近似白色的“异物”.没有了VGG 损失的限制,会出现图像的失真.当没有L1和FM 损失时,图像不会出现失真,但是图像的色彩会出现偏差.在没有L1和FM 损失时,雾气整体偏深色;而使用了L1和FM 损失后,颜色正常.
Fig.6 Comparison of different loss function
图6 不同损失函数结果对比
2.4 训练过程参数设置
•生成器网络:卷积核大小为4×4,步长为1,padding 为0,网络为左右对称的卷积,设置网络左侧卷积层6层,右侧带跨层连接反卷积层5 层,整个网络共11 层;
•判决器网络:下采样层卷积核大小为4×4,步幅为2,下采样层个数3 层,判决器的个数为2;
•损失函数:λ1=10,λ2=10,λ3=10,学习率(learning rate)为0.0002.
3 实验结果
3.1 实验环境
算法的实验环境如下.
•硬件设备:CPU:Intel Core i7-5820K @ 3.30GHz x 12;GPU:NVIDIA GeForce TITAN X;内存:16GB;
•软件配置:操作系统为64 位ubuntu 14.04 LTS;CUDA Toolkit 7.0.
本文使用深度学习的框架为Pytorch.
•加雾训练集[29]:利用软件Adobe lightroom CC 加雾功能,对Middlebury Stereo Datasets 和网上收集的无雾图像进行加雾.分别对76 张无雾图像集加浓度为30,40,50,60,70,80,90,100 的雾,其中,室外场景26张,室内场景50 张,最终形成608 对含不同浓度雾的有雾图像与无雾图像的匹配图像对做训练集;
•SAR 图像训练集:网络上匹配图像裁剪,共1 048 对256×256 匹配图像;
•白天黑夜转换训练集[11]共17 112 张;
•谷歌地图训练集[1]共1 096 张.
3.2 主观结果分析
3.2.1 SAR 图像生成
之所以进行SAR 图像合成,是由于目前通过可见光图像和SAR 图像获得一致的匹配图像对有一定的难点.由于时间、地点、噪声干扰等问题限制,再加上图像的校准也需要消耗大量的人力物力,因此可以尝试通过图像生成的方法,从可见光图像中生成SAR 图像,来获得特殊的地形地貌在SAR 图像下的成像效果.
在SAR 图像生成上,其他相似的GAN 图像生成的算法并未有类似的转换测试,也无法评测用何种方法生成SAR 图像更加真实.为了更客观地评价从可见光图像向SAR 图像转换,本文对比了其他GAN 图像生成算法.以下几种算法分别各有特点,都能够实现图像场景和内容的转换:Pix2pix[1]是利用匹配图像对进行图像生成;CycleGAN[21]能够利用非匹配图像训练集进行训练提取特征;MUNIT[22]同样可以提供图像的内容转换,可以从场景、内容上进行变化,在CycleGAN[21]基础上可能实现多种映射,同时生成多幅不同的转换图像.本文通过对可见光图像和真实SAR 图像组成的训练集对CycleGAN[21],MUNIT[22],Pix2pix[1]和本文算法进行训练,在相同训练集,不同算法得到如下对比结果,如图7所示.
由图7 可见:
•CycleGAN 能在该训练集下生成呈黑白色图像,且在图像的内容上与可见光图像保持高度一致,但并不能够学习到SAR 图像的特定特征.比如图中树的形态在真实SAR 图像和可见光图像中有很大差别;再如街道在可见光图像中呈现近白色,而在真实SAR 图像中是近黑色.而CycleGAN 则并不能够学习到这些SAR 图像的特点,且CycleGAN 更类似于把彩色图像转换成黑白;
•而MUNIT 则表现得更糟,甚至对于图像的内容都不能生成,这主要是由于MUNIT 更多地会自己生成一些内容;
•Pix2pix 和本文算法则更接近与真实的SAR 图像.从图像的内容和景物上都能够明显体现,对于道路、树、房屋的生成纹理和颜色都能够以假乱真.但是,Pix2pix 算法相比本文算法图像整体偏模糊且图像会有一些不必要的纹理出现,如图中右下角的草坪.

Fig.7 Comparison of SAR image synthesis results图7 SAR 图像合成结果对比
3.2.2 图像加雾
图8 是分别利用GAN 算法在本文的训练集下的效果,对比算法包括Pix2pix[1],CycleGAN[21],DRPAN[6]和软件加雾效果.
由图8 可见:Pix2pix 处理后图像呈现加雾效果,且图像的内容较为清晰,细节没有丢失,但图像加雾后导致图像的整体色彩有偏差(从树干部分可以看出);CycleGAN 效果则最差,内容模糊,色彩严重失真,其整幅图像色彩有偏差;软件加雾效果与本文效果十分相近,加雾均匀,雾的颜色没有偏差,且图像的细节保留较好;DRPAN 效果则略差,整幅图像虽然色彩鲜艳度有所下降,但是其图像较模糊,尤其图像上方树干、树叶部分,没有边界,十分模糊.

Fig.8 Comparison of imagehazing results图8 加雾结果对比
3.2.3 卫星图像到地图转换
同时,本文测试了卫星图像到地图的转换,训练集和测试集采用Pix2pix[1]的公共训练集,并测试了本文算法与其他基于生成对抗网络算法的转换效果.对比算法包括Pix2pix[1]、CycleGAN[21]和DRPAN[6],如图9所示.
从整体来看,均能生成类似地图效果的图像较为逼真.DRPAN 算法对图像进行的增强处理,对比度较强,但不影响整体的比较.Pix2pix 中,对于左下草坪区域大部分能够恢复出来,且草坪与道路相连的虚线框中区域、道路恢复得比较直,同时,最下面的湖水区域边界明显,而对于草坪中的小路则出现内容缺失;而CycleGAN 算法对于草坪区域均不能够着色,草坪与道路相接的虚线框中虽然能够恢复道路,但道路不直且没有连贯,而对于草坪中的小路同样没有转换成功;DRPAN 算法对于湖水、草坪、草坪间的小路均明显地生成,但草坪与道路相接的区域,道路的内容模糊缺失;本文算法能够生成草坪与道路之间的路,且道路较连贯,对于草坪区域、湖的区域则着色不均,也有所缺失.
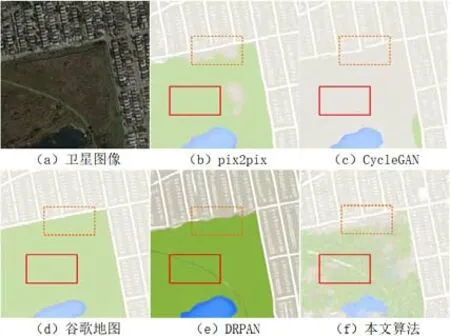
Fig.9 Comparison of map synthesis results图9 地图合成结果对比
3.2.4 白天到黑夜转换
在本节中,本文对白天到黑夜的转换进行了训练和测试,如图10所示.训练集同样来自Pix2pix[1].同时,在训练测试过程中发现:本文算法在该训练集下,判决器个数设置为1 时效果更好.考虑到是由于input 和label 并不完全匹配,数据集的图像虽然为同一地点同一位置,但仍有不同:一是拍摄时间不同,二是其他内容不同,比如马路上的车辆个数和位置、季节变化等的差异,而采用多个多尺度判决器原本目的是对于图像细节进行矫正,但在白天黑夜转换中则应该忽略掉小的细节上的差异,并对这些差异有所保留.
从图10 中可见,本文算法生成图像的内容基本不变,但对于天空区域则均变为黑色,埃菲尔铁塔则亮起了灯.视觉效果上,pix2pix 和DRPAN 算法生成的黑夜图更接近真实的夜晚图像,即色彩和亮度上的相似性,但是图很明显地出现了块效应,尤其是在天空与地面的交界处.图CycleGAN 生成的图像下沿即建筑物区域一片模糊,很明显没有转换成功.而本文提出的算法虽然在色彩和亮度上没有更接近与真实夜晚图,但是生成的图片减少了块效应,很好地保持了纹理结构,且更具真实感.

Fig.10 Comparison of night image synthesis results图10 夜晚场景合成结果对比
3.3 客观指标分析
3.3.1 图像加雾客观指标分析
首先,Choi 等人[30]计算雾浓度用了算法FADE(fog aware density evaluator),利用该算法对本文40 张测试集分别求出雾浓度指标.雾浓度结果见表1.指标越高,说明雾浓度越大.计算了40 张图的平均值及均方差,并对比无雾图像、CycleGAN、Pix2pix、DRPAN 和软件加雾效果.

Table 1 Comparison of FADE indicators表1 FADE 指标对比
由表1 可见:在利用Pix2pix、CycleGAN、DRPAN、软件加雾和本文算法处理后,图像的fog dens ity 指标明显上升,相对DRPAN 加雾程度最低,CycleGAN 程度最高.Pix2pix 和本文算法以及软件加雾的加雾程度相近.这也与主观效果相似.CycleGAN 之所以该项指标更高,也是由于图像色彩较少,整体图像色彩偏黄绿色.
本文也采用PSNR 和SSIM[31]指标对进行真实图像定性对比分析.PNSR 值越高,说明生成图像与原图更加相似,失真越少.当SSIM 值越接近1 时,则生成图像与原图的结构越相近,表明生成图像效果越好.对比结果见表2,将原始图像做基准图像,分别对本文算法加雾结果,将本文算法得到的加雾图像利用DCP 算法得到去雾图像求PSNR 和SSIM 指标.在表2 中,对40 张测试图的PSNR 和SSIM 进行统计,其平均值和均方差结果如下.

Table 2 Comparison of PSNR and SSIM indicators表2 PSNR 和SSIM 指标对比
由表2 分析PSNR 和SSIM.首先,本文算法在进行去雾后,图像的PSNR值明显上升,其中,红色为本文加雾后结果,深蓝色为本文算法的结果进行去雾后的效果.同时,本文算法和软件加雾以及Pix2pix 算法在对图像进行加雾后,图像的PSNR 值基本维持在一定范围内波动较小,而DRPAN 和CycleGAN 波动较大,则证明DRPAN和CycleGAN 算法加雾效果较差.这一点,从主观效果中也能够明显体现.而CycleGAN 在几个加雾算法中PSNR值基本最低,也是由于该算法生成的图像内容出现误差和缺失.而DRPAN 的PSNR 值整体偏高,并非该算法的加雾效果好,而是证明该算法更与无雾图像接近,也即加雾效果并不明显.
SSIM 指标只能做参考,因为去雾算法并不能够实现完全去雾,且任何去雾算法或多或少都会出现雾的残留、块效应、光晕、天空色彩失真等现象.而本文算法的结果在进行去雾之后,SSIM 指标有所上升.CycleGAN算法的SSIM 指标则十分低,说明生成图像的内容与输入图像差别较大;其余4 个方法的加雾效果则基本维持在同一个水平.相比之下,DRPAN 的SSIM 值较高,因为其与输入图像相近.
3.3.2 SAR 图像转换客观指标分析
在Pix2pix[1]算法中,对于图像转换后生成的图像采取人为进行观察评价的方法.于是,本文对SAR图像转换以及地图转换进行调查问卷调查,对多种算法进行对比,并对图像的真实程度评分(未给出真实图像),当生成图像越真实,真假难辨评分越高.最高5 分,最终在随机人群中回收到的21 份问卷评分统计结果见表3.

Table 3 Comparison of SAR image conversion scores表3 SAR 图像转换得分对比
由结果可见:MUNIT 得分最低,主要是由于其图像的边缘基本都难以分辨;CycleGAN 得分仅比Pix2pix 略低,原因在于CycleGAN 能够保留较为清晰和准确的图像边缘,图像整体也呈现灰白色彩,但其对于SAR 图像的特征转换的不够准确;而本文算法得分略高,原因在于不论色彩还是边缘,本文算法效果均突出,且没有块效应的出现.
3.3.3 地图转换客观指标分析
同样采取SAR 图像转换一样的问卷调查,对于21 份回收结果进行分析——平均值及均方差,结果见表4.
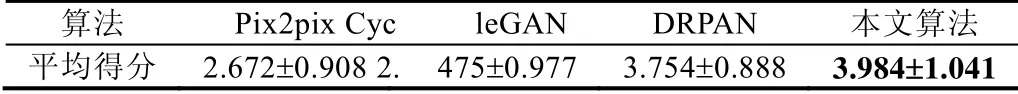
Table 4 Comparison of map conversion scores表4 地图转换得分对比
由图像的得分可见:Pix2pix 和CycleGAN 得分相近,均为中等分数,图像转换效果可圈可点,道路、草地等转换也都较为准确;本文算法和DRPAN 得分相近且略高,DRPAN 的色彩鲜艳,且分割完整,线条流畅;而本文算法色彩较暗,分割完整,但在线条上更加笔直.
3.3.4 白天夜晚转换客观指标分析
同样采取SAR 图像转换一样的问卷调查,对于21 份回收结果进行分析——平均值及均方差,结果见表5.
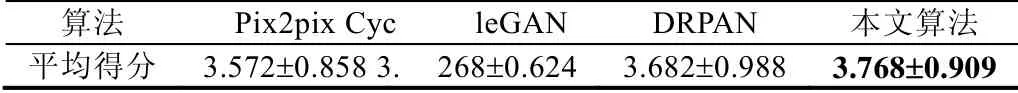
Table 5 Comparison of day-night conversion scores表5 白天夜晚转换得分对比
由图像的得分可见:Pix2pix,DRPAN 和本文算法得分相近,且波动范围较大,夜晚图像转换效果可圈可点;Pix2pix 和 DRPAN 在色彩与饱和度方面做得更好,本文算法则在纹理结构以及图像失真方面做得更好;CycleGAN 算法在这一转换任务上表现较差,色彩上较为暗淡,图像的纹理结构也大多丢失.
4 结论
本文介绍了基于生成对抗网络的图像场景转换算法的具体内容.首先介绍了算法的跨层连接生成器网络设计、多尺度判决器网络设计以及损失函数的4 种组合;接着对网络模块性能进行分析,从实验证明本文算法设计的合理性;接着介绍实验的平台、硬件软件等,之后分别从主观效果和客观指标进行分析.在主观效果上,分析了本文算法与其他基于生成对抗网络的图像转换算法对于场景转换的效果,包括雾霾场景转换、SAR 图像转换、谷歌地图转换以及白天黑夜转换.在客观指标上,本文算法效果表现也略为突出.
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·中考版(2021年3期)2021-07-22
数学小灵通·3-4年级(2021年5期)2021-07-16
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
