
基于RGB-D的反向融合实例分割算法
2021-11-09 05:51汪丹丹张旭东范之国
图学学报 2021年5期
汪丹丹,张旭东,范之国,孙 锐
基于RGB-D的反向融合实例分割算法
汪丹丹,张旭东,范之国,孙 锐
(合肥工业大学计算机与信息学院,安徽 合肥 230009)
RGB-D图像在提供场景RGB信息的基础上添加了Depth信息,可以有效地描述场景的色彩及三维几何信息。结合RGB图像及Depth图像的特点,提出一种将高层次的语义特征反向融合到低层次的边缘细节特征的反向融合实例分割算法。该方法通过采用不同深度的特征金字塔网络(FPN)分别提取RGB与Depth图像特征,将高层特征经上采样后达到与最底层特征同等尺寸,再采用反向融合将高层特征融合到低层,同时在掩码分支引入掩码优化结构,从而实现RGB-D的反向融合实例分割。实验结果表明,反向融合特征模型能够在RGB-D实例分割的研究中获得更加优异的成绩,有效地融合了Depth图像与彩色图像2种不同特征图像特征,在使用ResNet-101作为骨干网络的基础上,与不加入深度信息的Mask R-CNN相比平均精度提高10.6%,比直接正向融合2种特征平均精度提高4.5%。
Depth图像;实例分割;特征融合;反向融合;掩码优化
实例分割[1]是对图片中的各个实例进行区分,是一个像素级识别对象的任务,随着人工智能的不断发展,实例分割在计算机视觉领域的需求也逐渐提高,其需要正确识别图像中的不同个体信息,并对图像中的每一个像素进行逐个标记,还需要对同一类别的像素进行分类[2-5],最终实现分割。
目前,针对实例分割的研究主要采用RGB图像,全卷积实例语义分割(fully convolutional instance- aware segmentation,FCIS)[6]算法是首个全卷积、端到端的实例分割算法,通过引入位置感知的内/外分数映射,使图像分割与分类可共享特征图,实现分类与分割2个子任务并联。Mask R-CNN[7]算法在Faster R-CNN[8]基础上将RoIPooling层修改为RoIAlign过程,降低池化层取整过程所带来的损失,并引入由全卷积网络(fully convolutional networks,FCN)[9]构成的语义分割分支,将Mask与Class 2个问题分开处理,避免类间竞争问题。PANet[10]网络在Mask R-CNN网络的特征提取阶段引入自上而下的路径增强结构,利用低层特征准确地定位信息增强整个特征层次,从而缩短了底层与顶层特征之间的信息传递路径。CHEN等[11]结合Mask R-CNN网络和Cascade R-CNN[12]网络设计一种多任务多阶段的混合级联结构来改善信息流,并融合一个语义分割网络来增强空间上下文信息。
对于RGB图像实例分割的研究已经获取了一定的成果,但仅采用RGB图像作为输入,对图像的空间、边缘信息考虑并不充分,Depth图像作为一种特殊类型的图像,每一个像素点都包含着物体表面对应点的深度信息,将Depth图像信息与彩色图像信息融合能够丰富分割任务的输入特征信息,可以有效提高分割精度。XIANG等[13]提出局部感知的反卷积神经网络来提取特征信息,引入门式融合层来有效融合2个层次的特征信息,使得RGB与深度数据在每个像素上融合权值,从而实现图像的语义分割。DENG等[14]针对RGB与Depth图像之间的相互依赖性,提出残差融合块网络有效融合2个编码特征,在融合特征时不直接融合RGB与Depth特征,增加一个路径聚合原始特征和交互特征,减少特征信息的丢失提高语义分割效果。文献[15]通过实验表明,在数据层融合深度信息可有效提高最终的实例分割效果,在Mask R-CNN框架下融入深度信息,通过构建2种不同复杂度的特征金字塔网络(feature pyramid network,FPN)融合网络模型实现RGB-D实例分割。SHAO等[16]提出了ClusterNet网络,将RGB图像与从摄像机内经过特征转换的Depth图像XYZ经CNN层连接后,再将原始Depth图作为辅助特征连接,最终通过矩空间聚类实现实例分割。XIANG等[17]直接将RGB与Depth图像由FCN网络融合,再利用度量学习损失函数生成像素级特征嵌入,利用学习到的特征嵌入信息,使用均值漂移聚类算法来发现和分割不可见的目标,采用2阶段聚类算法实现不可见物体实例分割。
综上,RGB与Depth图像融合可有效地提取特征信息,然而在融合过程中忽略了低层特征高效地定位能力,针对这些问题,结合自底向上与自顶向下的特征提取融合方式融合2种不同特征信息。自顶向下的反向融合方式可以为物体提供一些先验知识,从而引导物体的识别。
本文算法利用自底向上与自顶向下2种方式提取并融合特征,在Mask R-CNN网络框架下加入深度信息,采用不同深度FPN对RGB与Depth图像自底向上进行特征提取,采用自顶向下方式反向融合2种特征。FPN提取特征过程中随着层级升高,所包含的语义信息更加丰富,为了有效利用不同层级的特征信息,引入反向融合过程,利用高层的语义特征作为先验特征信息,结合低层优异的特征定位能力获取更加充分的特征信息来准确识别物体,将该信息再输入到RPN (region proposal network)网络中进行RoI (region of interest)区域选定能够获取更优异的效果。
1 本文方法
本文采用自底向上特征提取与自顶向下反向特征融合方式实现RGB-D实例分割。本文在Mask R-CNN网络框架下加入Depth图像特征,改变网络输入特征,采用RGB图像与HHA[18]编码Depth图像融合特征作为输入获得更加完善的分割效果,算法采用FPN结构进行自底向上特征提取,在融合Depth图像的特征信息时,低层特征含有丰富的纹理、颜色等信息,具有精确的物体定位能力,高层特征含有丰富的语义特征,为了充分利用不同层级特征,提出一种自顶向下反向融合的方式来将图像底层特征融入网络。本文算法在反向传递过程中,首先对高层次不同尺寸的图像采用上采样过程重构为底层特征同等尺寸,再经过反向融合过程来恢复自底向上提取特征时损失的本地化信息,而针对RGB图像与Depth图像使用不同深度的FPN结构进行特征提取,降低Depth图像在特征提取时的过拟合问题。具体网络模型如图1所示。Mask R-CNN算法的掩码提取网络采用FCN网络作为语义分割分支,尽管算法流程简单,但是在掩码的提取精度上有所欠缺,造成掩码边缘信息的损失,本文在掩码分支中加入一个边缘优化网络来提高掩码的质量,具体实现过程见1.2节。

图1 RGB-D反向融合网络示意图
1.1 RGB与Depth特征反向融合
本文提出将RGB图像与Depth图像2种不同特征信息进行反向融合,因为在使用FPN进行多尺度特征提取时,提取的低层特征分辨率高,具有更多的位置、细节信息,但语义信息低、噪声多,而高层特征分辨率低,包含丰富的语义特征,但细节的感知能力差,进行反向融合能够充分利用低层特征的边缘细节信息。图2为RGB与Depth图像不同层级输出特征可视化图像,其中,第2行为HHA编码的Depth图像,第3行为原始Depth图像。HHA编码的Depth图像为原始Depth图像进行重新编码后获取的图像,其将原始Depth图像信息转化为水平差异,对地高度以及表面法向量的角度3种不同通道输入,相比较普通的Depth图像包含有更加丰富的特征信息,强调3个不同通道信息之间可互补。第1行表示RGB图像FPN1到5的特征输出;第2行表示HHA编码Depth图像FPN_1到_5的特征输出;第3行表示原始Depth图像FPN_1到_5的特征输出。由第2列可以看出1,_1和_1边缘细节信息突出,有利于获取实例的边缘信息,将高层级的语义特征信息反向融合到低层级的边缘细节信息中,充分利用低层特征的精准定位能力。由第4列RGB图像与HHA编码图像的输出可以看出由于多通道之间的信息互补还可识别出物体边缘,而原始Depth图像因其单一通道使特征信息分散。本文采用自顶向下的反向特征融合方式,以高层特征作为先验知识的过程中,HHA编码的Depth图像不同通道之间提供互补信息,使得传递到低层特征补充更加完善,从而获取更加丰富的特征信息。

图2 不同层级输出特征
特征反向融合结构如图1橙色虚线框所示,对于RGB与HHA编码的Depth图像采用不同深度特征金字塔结构提取不同尺度特征,RGB图像的每层级输出为2,3,4,5,Depth图像的每层级输出为2,3,4,5,每个层级输出特征大小分别为128×128,64×64,32×32,16×16,最后层级的6,6为5,5经由max Polling获取的特征输出,其输出大小为8×8,FPN网络进行特征提取时1,1表示的是特征最底层特征,其输出的大小为256×256,在采用自顶向下反向融合特征时,将除1,1层以外的其他输出层上采样为256×256,对上采样后的同层特征按元素相加,再将顶层特征逐级按元素相加到下一层,7,8,9,10,11分别表示自顶向下融合过程中每层的输出特征,0表示最底层特征1,1的融合结果,特征融合方式均采用简便的按元素相加方式,降低融合时特征损失,即
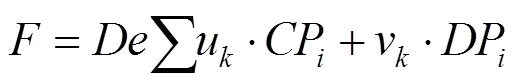
其中,CP为彩色图像的不同层次信息;DP为Depth图像的不同层次信息;u,v分别为2个特征相比较其第一层缩小的比例;为反向相加的过程。
在RGB与Depth图像采用FPN进行自底向上特征提取时,Depth图像本身包含的特征信息并没有彩色图像丰富,Depth图像含有丰富的边缘信息,同一深度的图像信息十分平滑,将Depth图像经过深层卷积神经网络,在提取Depth图像特征信息过程中会造成其边缘信息损失。针对此问题,本文提出降低对Depth图像的特征提取深度,不改变残差网络的卷积核,使用1×1,3×3,1×1等3种卷积核共同作用,其中第1和第2个1×1卷积核分别对残差网络起到削减维度和恢复维度作用。采用残差网络作为主干网络保证特征提取时降低特征信息损失,跳跃连接使得特征处理中信息匹配完善,对Depth图像减少网络层数,降低特征提取过程中的过拟合问题。以ResNet101[19]为例,残差块结构如图3所示,对于RGB图像而言,主干网络采用完整的ResNet101,其con2_x,con3_x,con4_x,con5_x层数为3,4,23,3,而针对Depth图像而言,不改变每个残差块,降低con2_x,con3_x,con4_x,con5_x的卷积层数,每个卷积块层数都降低为一层,降低Depth图像特征过度提取。
1.2 掩码网络提取优化
Mask R-CNN算法对于掩码输出网络采用FCN结构,可以快速地实现掩码分割,但是掩码提取的精度并未有很高,为了提高掩码精度,本文在掩码分支加入一个边缘优化结构[20],实现结构如图4中虚线框出位置,本文使用的边缘优化网络具体结构如图4黄色框,多层卷积结构在提取信息时会造成一些本地化信息的缺失,在增加卷积层数同时加入跳跃连接恢复损失信息,从而获得更加完善的掩码信息,降低掩码损失。Mask R-CNN中Mask分支采用全卷积网络,对于RPN输出的RoI经过5层卷积结构,最终输出28×28×80的Mask掩码。本文的掩码优化网络将5个卷积层中第二和四层用新的优化结构代替,且卷积内核采用3×3,利用残差结构连接确保特征充分提取也不造成过多损失,2个优化结构的输入与输出都为14×14×256,第二层优化结构的输出再经过最后一层卷积层最终输出更加完善掩码信息。

图3 ResNet101网络与修改网络
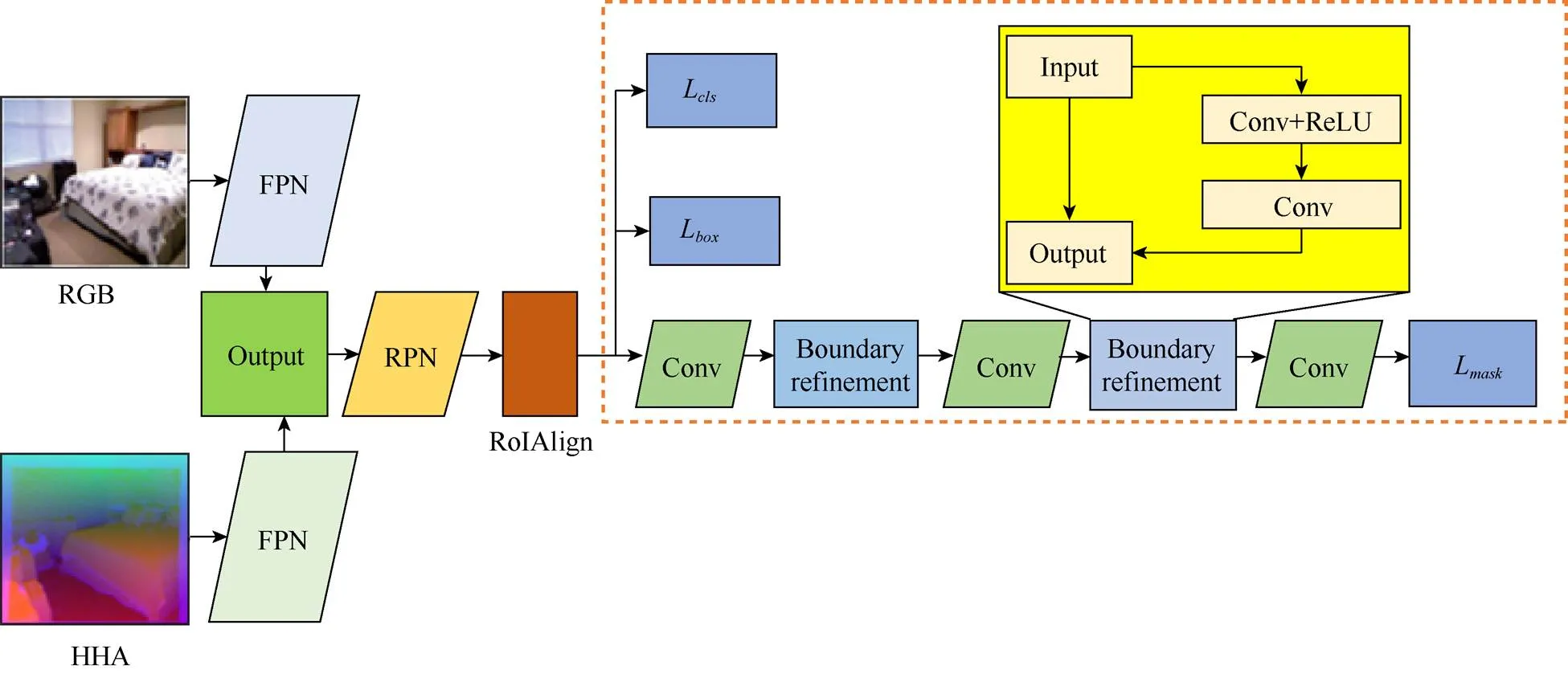
图4 掩码优化网络框架
2 实验结果与分析
2.1 实验设置
本文实验分别采用COCO 2014[21]日常RGB场景数据集和NYUD2[22]室内RGB-D数据集。由于NYUD2数据集包含的图像数量有限,若训练的数据量太小则会造成训练模型产生过拟合、异常值无法避免以及难以进行优化等问题,因此对NYUD2数据集的单一图像均进行旋转、缩放比例、翻转和剪裁等方式增加数据量,再将扩充后的数据集进行划分为训练集、确认集和测试集。实验借助COCO数据集训练的权重作为辅助,在对获取NYUD2数据集训练权重时降低了时间的消耗。本文实验在NVIDIA TitanGPU上运行,平台系统为Ubuntu 16.04,使用PyTorch深度学习框架进行模型代码编程,实验所用的评价标准为检测精度AP值,其表示精准率与召回率之间的关系,即
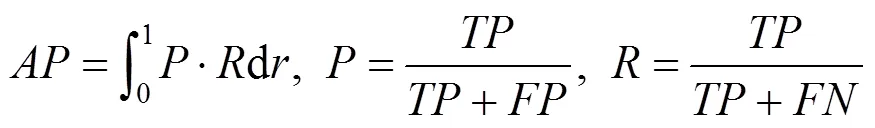
其中,为预测与实际标签相同的正样本数量;为预测与实际标签不同的负样本数量;为以实际为背景但预测为标签的负样本数量。考虑到不同的IoU (intersection over union)对实验结果的影响,选用0.5,0.75不同的IoU阈值进行比较。
2.2 掩码优化网络实验结果
为了验证掩码优化网络的效果,首先在COCO数据集上进行实验,获得的最终实验数据见表1,其中本文的分割结果提升了1%~2%。图5为加入与未加入掩码优化网络分割结果的定性分析,第1行为未加入结果,第2行为加入结果,由前两列分割结果可以明显对比出本文提出的掩码优化网络对于小目标的分割有优势,由后两列分割结果可以看出掩码优化网络能够分辨出人群后的树、地面上的地毯等不易区分的物体。

表1 优化网络在不同主干网络下的训练数据

图5 COCO数据集下掩码优化网络的分割结果
2.3 特征融合网络消融实验
从基于RGB图像实验结果可知,掩码优化网络可以获取更加优异的分割效果,本节采用NYUD2三维数据集验证本文提出的反向融合网络对于分割结果的优化作用。训练实验时采用随机梯度下降(stochastic gradient descent)对最终实验结果进行优化,学习率参数设置为0.002,在不同训练阶段采用不同的学习率,训练HHA的头网络学习率为初始学习率的十分之一,训练RGB的头网络采用原始的学习率,采用不同的学习率保证目标函数在合适的时间收敛到局部最小值。实验动量设置为0.9,权重衰减系数设置为0.000 1,在经过NMS结构之后保留1 000个RoI,选择前景分割过程中得分最高的100个实例进行分割。
针对不同的特征信息,分别进行了RGB,RGB+Depth,RGB+HHA+正向融合和RGB+HHA+反向融合几种情况下的对比试验,正向融合相较与本文反向融合,是将底层特征逐级融合到高层且融合RGB与Depth图像特征信息。表2为在NYUD2数据集下定量分析结果,同时比较采用不同的主干网络对实验数据的影响,从表中可知,只采用RGB图像作为特征输入获得的AP值很小;加入Depth图像信息即采用RGB+Depth+F图像,其不同特征在多层次的融合过程为前向融合,实验结果在主干网络为ResNet-101下达到了3.9%的提升;在RGB+ HHA+F中,将HHA编码的Depth图像信息与RGB图像结合,并以正向融合的方式使实验结果在ResNet-101网络中提升了6.1%;在RGB+HHA+R中,HHA编码采用本文的反向融合方式,将Depth图像信息与RGB图像由高层次向低层次中融合,充分利用语义特征信息与边缘细节信息,本文方法将主干网络ResNet-101提升了10.6%,效果显著,同时在Depth图像的多层次特征提取过程中,降低提取深度特征信息网络的深度,减少了深度特征信息损失同时降低了时间的消耗。
不同场景下的分割效果如图6所示,每一列表示不同的分割场景,第1行为图像的标签,第2行以RGB图像作为输入图像后的分割效果,第3行为加入HHA编码的Depth图像信息,RGB与Depth图像特征融合方式为正向融合,主要考虑的是提取高层次语义特征信息,第4行为加入HHA编码的Depth图像信息,RGB与Depth图像特征融合方式为反向融合,将高层次的语义特征信息融合到低层次的空间边缘信息,即本文方法。第3行较第2行能够分割出更多不易发现的物体,由于NYUD2数据集为室内采集的图像,场景3和4相较于场景1,2,5,6,其光线更加暗,对于颜色相对比较深的图像信息不容易识别。以场景4为例,采用正向融合HHA编码的Depth图像信息的方式无法分割出窗户的信息,而采用加入HHA Depth图像信息的方式,能够分割出窗户的信息。场景7光线较充分,场景前的桌子与椅子等目标明显的物体容易识别,但对于目标小的屋顶的灯无法识别,采用本文方法细节信息考虑相对充分,在反向融合过程中不会忽略边缘细节信息,从而获得了更加完善的分割效果。针对场景1,2,5,6的明亮场景下,分割效果优势明显。
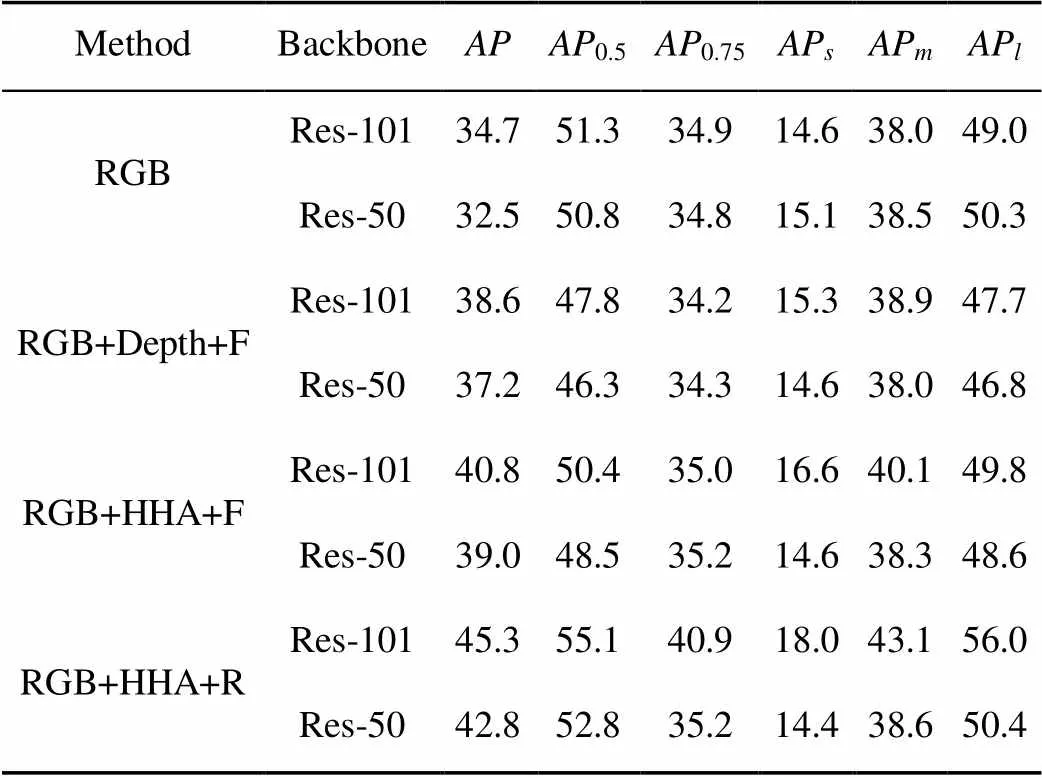
表2 NYUD2数据集下分割效果的定量分析(%)
2.4 RGB-D实例分割对比实验
通过实验证明了本文方法在RGB-D实例分割任务中的有效性。为了进一步验证本文方法在实例分割中的优越性,在SHAO等[23]的合成数据集上进行了对比实验,该数据集包含有大量刚性物体的RGB-D图像,表3为本文方法与现有RGB-D的实例分割方式结果,从表中可以看出本文方法相比较其他模型在RGB-D实例分割方向上的准确率更高。

图6 NYUD2数据集下不同场景分割效果

表3 与现有方法在合成数据集下分割效果的定量分析(%)
3 结 论
本文结合RGB-D三维图像数据集,设计一种反向融合特征网络,在网络中将RGB图像与HHA编码的Depth图像信息结合,使用深度不同的FPN进行自底向上的特征提取过程。采用不同的网络深度能够有效降低特征提取过程中过拟合问题,再结合由顶向下的反向融合方式更好地体现底层的定位信息,同时在掩码分支引入掩码优化网络提高实例分割效果。实验结果表明,本文算法能够更好地识别小目标以及难以分辨的物体。目前所使用的分割数据集均具有像素级标签,下一步研究弱监督实例分割算法,针对图像级别的标签数据集进行处理。
[1] ROMERA-PAREDES B, TORR P H S. Recurrent instance segmentation[C]//European Conference on Computer Vision. Heidelberg: Springer, 2016: 312-329.
[2] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
[3] RASTEGARI M, ORDONEZ V, REDMON J, et al. XNOR-net: imageNet classification using binary convolutional neural networks[C]//ECCV -Lecture Notes in Computer Science 2016.Heidelberg: Springer, 2016: 525-542.
[4] SMIRNOV E A, TIMOSHENKO D M, ANDRIANOV S N. Comparison of regularization methods for ImageNet classification with deep convolutional neural networks[J]. AASRI Procedia, 2014, 6: 89-94.
[5] YAO L, MILLER J. Tiny imagenet classification with convolutional neural networks[J]. CS231N, 2015, 2(5): 1-8.
[6] LI Y, QI H Z, DAI J F, et al. Fully convolutional instance-aware semantic segmentation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 4438-4446.
[7] HE K M, GKIOXARI G, DOLLAR P, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 386-397.
[8] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[9] SHELHAMER E, LONG J, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640-651.
[10] LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 8759-8768.
[11] CHEN K, PANG J M, WANG J Q, et al. Hybrid task cascade for instance segmentation[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 4969-4978.
[12] CAI Z W, VASCONCELOS N. Cascade R-CNN: delving into high quality object detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 6154-6162.
[13] XIANG Y, XIE C, MOUSAVIAN A, et al. Learning RGB-D feature embeddings for unseen object instance segmentation[EB/OL]. [2021-01-20]. https://xueshu.baidu. com/usercenter/paper/show?paperid=135w0am0tu5a0r80pr280ar0gg365359&site=xueshu_se.
[14] DENG L Y, YANG M, LI T Y, et al. RFBNet: deep multimodal networks with residual fusion blocks for RGB-D semantic segmentation[EB/OL]. [2021-01-20]. https://xueshu.baidu. com/usercenter/paper/show?paperid=1m7804p0nw500j606u3r0jp0dq782639&site=xueshu_se&hitarticle=1.
[15] 张旭东, 王玉婷, 范之国, 等. 基于双金字塔特征融合网络的RGB-D多类实例分割[J]. 控制与决策, 2020, 35(7): 1561-1568.
ZHANG X D, WANG Y T, FAN Z G, et al. RGB-D multi-class instance segmentation based on double pyramid feature fusion model[J]. Control and Decision, 2020, 35(7): 1561-1568 (in Chinese).
[16] SHAO L, TIAN Y, BOHG J. ClusterNet: 3D instance segmentation in RGB-D images[EB/OL]. [2021-01-20]. https://xueshu.baidu.com/usercenter/paper/show?paperid=49eb75109143bb1df266ad9fda02ae0f&site=xueshu_se.
[17] XIANG Y, XIE C, MOUSAVIAN A, et al. Learning RGB-D feature embeddings for unseen object instance segmentation[EB/OL]. [2021-01-20]. https://xueshu.baidu. com/usercenter/paper/show?paperid=135w0am0tu5a0r80pr280ar0gg365359&site=xueshu_se.
[18] GUPTA S, GIRSHICK R, ARBELÁEZ P, et al. Learning rich features from RGB-D images for object detection and segmentation[C]//European Conference on Computer Vision. Heidelberg: Springer, 2014: 345-360.
[19] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 770-778.
[20] PENG C, ZHANG X Y, YU G, et al. Large kernel matters—improve semantic segmentation by global convolutional network[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 1743-1751.
[21] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]//European Conference on Computer Vision. Heidelberg: Springer, 2014: 740-755.
[22] SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor segmentation and support inference from RGBD images[C]//European Conference on Computer Vision. Heidelberg: Springer, 2012: 746-760.
[23] SHAO L, SHAH P, DWARACHERLA V, et al. Motion-based object segmentation based on dense RGB-D scene flow[J]. IEEE Robotics and Automation Letters, 2018, 3(4): 3797-3804.
A reverse fusion instance segmentation algorithm based on RGB-D
WANG Dan-dan, ZHANG Xu-dong, FAN Zhi-guo, SUN Rui
(School of Computer and Information, Hefei University of Technology, Hefei Anhui 230009, China)
The RGB-D images add the Depth information with the given RGB information of the scene, which can effectively describe the color and three-dimensional geometric information of the scene. With the integration of the characteristics of RGB image and Depth image, this paper proposed a reverse fusion instance segmentation algorithm that reversely merged high-level semantic features to low-level edge detail features. In order to achieve RGB-D reverse fusion instance segmentation, this method extracted RGB and depth image features separately using feature pyramid networks (FPN) of different depths, upsampling high-level features to the same size as the bottom-level features. Then reverse fusion was utilized to fuse the high-level features to the low-level, and at the same time mask optimization structurewas introduced to mask branch.The experimental results show that the proposed reverse fusion feature model can produce more excellent results in the research on RGB-D instance segmentation, effectively fusing two different feature image features of Depth image and color image. On the basis of ResNet-101 serving as the backbone network, compared with mask R-CNN without depth information, the average accuracy was increased by 10.6%, and that of the two features was increased by 4.5% with the direct forward fusion.
Depth images; instance segmentation; feature fusion; reverse fusion; mask refinement
TP 391
10.11996/JG.j.2095-302X.2021050767
A
2095-302X(2021)05-0767-08
2021-01-15;
2021-03-08
15 January,2021;
8March,2021
国家自然科学基金项目(61876057,61971177)
National Natural Science Foundation of China (61876057, 61971177)
汪丹丹(1996-),女,安徽安庆人,硕士研究生。主要研究方向为智能图像处理、人工智能。E-mail:2018170868@mail.hfut.edu.cn
WANG Dan-dan (1996-), female, master student. Her main research interests cover intelligent image processing and artificial intelligence.E-mail:2018170868@mail.hfut.edu.cn
张旭东(1966-),男,安徽合肥人,教授,博士。主要研究方向为智能信息处理、机器视觉。E-mail:xudong@hfut.edu.cn
ZHANG Xu-dong (1966-), male, professor, Ph.D. His main research interests cover intelligent image processing and machine vision.E-mail:xudong@hfut.edu.cn
猜你喜欢
计算机技术与发展(2022年5期)2022-05-30
密码学报(2021年2期)2021-05-15
网络安全和信息化(2019年7期)2019-12-22
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
电脑知识与技术(2015年12期)2015-07-18
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
