
中医文本实体关系的联合抽取
2021-11-07 03:11卢苗苗牛亚琴王亚文王培
电脑知识与技术 2021年25期
卢苗苗 牛亚琴 王亚文 王培


摘要:中医典籍凝聚了古人的智慧结晶及临床经验。近年来,中医领域的实体识别和关系抽取任务受到了广泛关注,并且一些联合抽取方法得到了应用。为了进一步提高实体关系联合抽取的效果,采用一种分层二进制标注框架对中医领域的实体关系进行联合抽取,充分结合了预训练语言模型的优势,解决了三元组重叠问题。实验证明,该框架能有效地解决三元组重叠问题,在不同重叠模式下的中医语料数据集上F1值均超过了75%。
关键词:中医文本;联合抽取;实体识别;关系抽取;三元组重叠
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2021)25-0179-02
1引言
一直以来,医学实体关系抽取的相关研究大多都是面向英文医学文献的,且多为西医知识的获取。随着自然语言处理(NLP)的广泛应用,面向中文医学文献的研究需求不断增加。在NLP任务中,命名实体识别和关系抽取任务是构建知识库的必不可少的步骤,同时也是最重要的部分,并且基于这两个任务的联合抽取方法越来越受到关注。当前针对中医领域的相关实体识别以及实体之间的关系抽取的研究仍然非常稀少。为了能够获取大量的中医语料,并进行深入挖掘,在未标注的语料中先进行预训练,然后与下游任务模型进行结合。
实体关系联合抽取可以自动化地从输入文本中抽取出包含某种关系类型的实体对,构成实体关系三元组。因此,科研人员提出了使用联合模型,利用两个任务之间的潜在信息来解决这个难题,但是传统的联合模型一般又严重依赖于复杂的特征工程。Miwa[1]等人没有直接对整个句子建模,没有考虑同一句子中其他实体对的关系。2017年,Katiyar[2]直接对整个句子建模,但是无法处理多关系的问题。Wang[3]等人通过设计一个有向图机制将联合抽取任务转换为一个有向图问题,使用基于转移的解析框架来解决,但是只解决了一个实体和多个实体之间存在关系的重叠问题,并没有解决同一实体对存在多个关系的重叠问题。2018年,Zeng[4]等人是第一个在关系三重提取中考虑重叠三重问题的人,并尝试通过具有复制机制的序列到序列(Seq2Seq)模型来提取三元组。
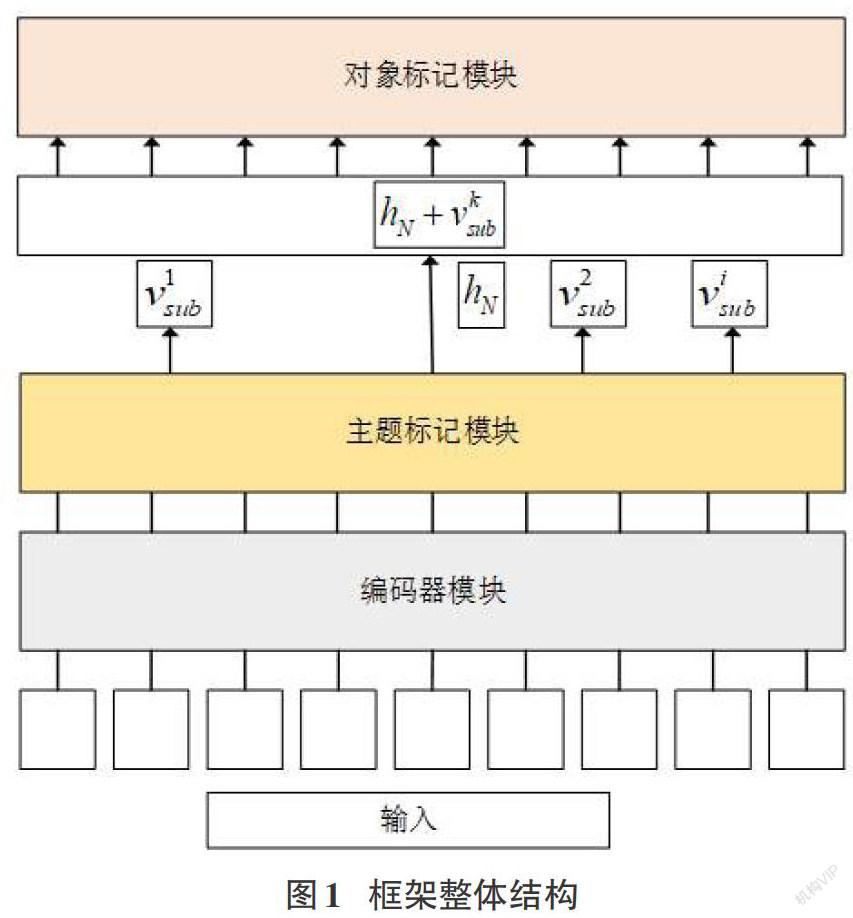
本文所采用的框架思想来源于Wei[5]等人提出了一个分层二进制标注框架,该框架由基于BERT模型的编码器模块和分层解码器模块组成。其中,分层解码器模块又由主题标记模块和对象标记模块组成,图1展示了框架的整体结构,下文称为联合框架。
2联合框架
在这种联合框架下,首先,确定中医文本句子中所有可能的主题实体,比如“前胡清肺热,化痰热,推陈致新之药也”,然后针对“前胡”这个主题实体,应用关系特定标记器来同时识别所有可能的关系和相应的对象。
2.1 编码器模块
采用预训练的BERT模型对输入的中医文本上下文进行编码。从句子中提取特征信息,并将提取的[hN]、[vksub]等信息放入后续的标记模块中。BERT是基于多层双向Transformer的语言表示模型,其中[x]表示输入向量。具体操作如公式(1)(2)所示:
其中[S]是输入句子中子词索引的一元向量的矩阵,[Ws]是词嵌入矩阵,[Wp]是位置嵌入矩阵,其中[p]代表输入序列中的位置索引,[hα ]是隐藏状态向量,即输入句子在第[α]层的上下文表示,[N]是Transformer块的数量,[Trans(·)]—Transformer块。
2.2 解码器模块
分层解码器由主题标记模块和特定于关系的标记模块组成。主题标记模块通过直接解码[N]层BERT编码器产生的编码向量[hN]来识别输入句子中的所有可能主體。更准确地说,它通过选择两个相同的二进制分类器分别为每个标签分配0或者1的标签来指示主实体的开始和结束位置,从而分别检测实体的开始和结束位置。主题标记器对每个标签的详细操作如公式(3)(4)所示:
其中[pistart_s]和[piend_s]分别表示将输入序列中的第[i]个标签识别为对象的开始和结束位置的概率。如果概率超过某个阈值,则将为相应的标签分配为1,否则分配为0。[xi]是输入序列中第[i]个标签的编码表示,即[xi=hN[i]],其中[W]表示可训练的权重,[b]是偏差,而[σ]是sigmoid激活函数。
3实验
3.1实验数据
本文以中医古籍文本为实验对象,研究中医文本实体关系的联合抽取。首先通过中医相关的医学专业网站对中医文本爬取了总计约700本中医古籍。并用正则的表达式对字符串进行清洗,除去汉字以外的字符、换行符以及空格等。例如,将“淡白而瘦小,- -气血两虚”这句话,经过正则方式处理完之后就变成了“淡白而瘦小,气血两虚”。接着以句子为单位对文档按照句号,问号进行拆分,得到大约180万个句子。由于中医文本具有中国古代的语言风格,通常也会出现一些虚词,停用词,且对句子含义的理解毫无意义,我们通过剔除停用词表中出现的词,进行特征提取,这本质上也属于特征选择工作的一部分。最后,对句子使用jieba分词工具加载词典的方法来为中医文本分词,得到对应的词序列。
经过以上处理,得到一批训练、测试数据,将数据按照关系三元组是否存在共享同一实体的情况,即存在重叠关系,按照不同重叠模式将句子划分为两类:一对一实体无关系重叠,多实体多关系重叠共享,并对这些中医实体关系三元组进行详细实验。
3.2实验结果
为进了证明联合框架具有良好的解决三元组重叠问题的能力,本文分别在不同重叠情况的中医语料数据集上统计联合框架的查准率、召回率和F1值。表1为联合框架在中医语料数据集上不同重叠模式下的F1值。
实验结果表明,在不同重叠程度的中医数据集上F1值都高于75%,说明该联合框架具有优越的解决三元组重叠问题的能力。
