
基于时序和上下文特征的中文隐式情感分类模型
2021-11-05 01:29袁景凌丁远远潘东行
计算机应用 2021年10期
袁景凌,丁远远,潘东行,2*,李 琳
(1.武汉理工大学计算机科学与技术学院,武汉 430070;2.中国建设银行股份有限公司运营数据中心,武汉 430070)
0 引言
随着网络媒体的迅速普及,大量含有主观评论的文本信息迅速传播。这些评论文本信息具有数量大、涉及范围广、传播速度快等特点,给当代社会经济发展带来了深远的影响。针对网络文本的情感分析,可以帮助研究人员更加细致了解用户对日常事件的意见和情感倾向[1],帮助商家提高服务质量以及为用户提供个性化推荐内容[2]。
在文本情感分析任务中,根据表达中是否包含显式情感词,情感分析可分为显式情感分析和隐式情感分析[3]。包含显式情感词的显式情感分析已经取得了丰富研究成果,而采用含蓄表达的隐式情感分析还处于起步阶段。隐式情感文本在互联网文本中占有较高比例的特点[4]使得针对隐式情感分析的研究不容忽视。中文隐式情感分类任务存在诸多困难,主要体现在如下几个方面:
1)在隐式情感分类中,句子大部分为事实型描述以及不存在关键情感特征[5]。隐式情感文本主要包含事实型和修辞型两个类别,统计结果显示,事实型隐式情感文本占比为70%以上[4]。显式与隐式的情感分类任务对比如表1所示。

表1 情感分类任务对比Tab.1 Comparison of sentiment classification tasks
2)隐式情感分类任务对分类方法有较高要求。隐式情感句中情感词的缺乏使得部分显式情感分类方法不再适用,如基于情感词典分类方法;另外,基于机器学习的情感分类方法很难获取有效情感特征对情感类别进行判断[4]。
3)与其他语言的隐式情感分类任务相比,中文隐式情感分类任务更加困难。在表达载体上,中文缺乏形态上的变化,只能通过字或者词语的组合表达特定语义。在获取文本特征表示时,错误的划分会使语义发生改变,另外,中文的语义关系又和社会、文化等因素密切相关。以上因素使得中文语义更难获取。
在中文隐式情感分类任务中,已有的研究方法以卷积神经网络为主[4],缺乏循环神经网络的相关研究。卷积神经网络的最大池化层会丢失词语的位置特征。而在隐式情感分类中,词语的位置特征对分类结果有重要影响,如隐式情感句“你们公司一年的销售额也赶不上我们一个月的。”包含褒义情感色彩。当调换“你们”和“我们”两个主语位置时,句子包含贬义情感色彩。卷积神经网络在处理该特征文本时,仅能保留主语编码后的特征,无法获得主语的位置特征。循环神经网络在处理距离较长的特征时,容易丢失关键信息。在已有的隐式情感分类任务中,分类模型的输入仅包含情感句本身[4]。相关研究显示,隐式情感句的上下文语句往往蕴含较为明显的情感色彩,对隐式情感的判别有重要指导作用[6]。
针对中文隐式情感分类任务更加困难和已有研究内容存在的部分缺陷,本文采用门控卷积神经网络(Gated Convolutional Neural Network,GCNN)对局部特征进行提取和筛选,在此基础上采用门控循环单元(Gated Recurrent Unit,GRU)获取单词之间的时序关系及更高层的语义特征。考虑到上下文语句在隐式情感判别的重要作用,采用双向门控循环单元(Bidirectional Gated Recurrent Unit,BiGRU)和注意力(Attention)机制从上下文语句中提取重要情感特征,在融合层将提取到的上下文特征融入到隐式情感判别中,提出了一种融合词语时序和上下文特征的中文隐式情感分类模型GGBA(GCNN-GRU-BiGRU-Attention)。本文的主要贡献如下:
1)对隐式情感句文本特征和情感词汇资源进行了分析。隐式情感文本存在字符分布集中、语句长度与数量之间满足幂律分布等特点。隐式情感句缺乏情感词汇资源,上下文语句蕴含丰富的情感词汇资源,并且情感词汇情感倾向和隐式情感句情感倾向相同占比达63%以上。
2)针对基础分类模型容易忽略目标句子中的时序信息的缺陷,本文通过GCNN 对目标句子中的局部特征信息进行提取与筛选后,将输出通过GRU 提取句子中的时序信息,提出了一种融合局部信息和时序信息的中文隐式情感分类模型GCNN-GRU,该模型为未融合上下文特征的中间模型。
3)针对隐式情感分类任务依赖隐式情感句上下文的特点,在采用GCNN-GRU 模型提取隐式情感句基础上,使用BiGRU+Attention 的组合对提取句子的上下文重要特征,提出了一种融合时序和上下文特征的中文隐式情感分类模型GGBA(GCNN-GRU-BiGRU-Attention),并在中文隐式情感分析评测数据集上进行实验。实验结果显示,在3 个评价指标上,本文提出的模型均取得了最优的综合分类性能。
1 相关工作
情感分类是指根据文本所表达的含义和情感信息将文本划分成褒扬的或贬义的两种或几种类型,是对文本作者倾向性和观点、态度的划分[7]。观点态度可以包括常见的褒、贬、中情感倾向或者喜、怒和哀等多个情绪类别[8]。现有的文本情感分类技术主要分为3 类:基于词典的情感分类方法、基于机器学习的情感分类方法和基于深度学习的情感分类方法[9]。
基于词典的情感分类方法主要是指,通过文本中情感词典和规则的组合判断整个句子的情感类别。这种方法依赖于人工设计的本体知识库和判断规则,无法解决不同领域的类似问题[10]。基于机器学习的情感分类方法从文本中提取不同特征组合,通过训练机器学习模型实现情感的分类。这种方法不易提取文本特征,难以处理文字长短不一的问题且模型不容易扩展。基于以上结论,本文在开展中文隐式情感分类研究时舍弃了基于词典和机器学习的情感分类方法。
基于深度学习的情感分类方法主要包括3 个类别,分别为擅长局部特征提取的卷积神经网络(Convolutional Neural Network,CNN)、擅长时序特征提取的循环神经网络(Recurrent Neural Network,RNN)以及相关的变体结构,相关研究如下:
1)CNN。CNN采用了局部连接、权值共享及池化操作,在局部特征提取、鲁棒性和容错能力上更具备优势[11]。Kim[12]首次将CNN 应用于文本情感分类任务,采用多个窗口的卷积核提取句子的局部特征,提出了用于句子情感分类的卷积神经网络。Zhang 等[13]对卷积神经网络中单层CNN 的敏感性进行了分析,研究了超参数对分类的影响。Dauphin等[14]在对长文本建模时,提出了一种包含门控机制的卷积神经网络。
2)RNN。在网络结构上,RNN 适合处理不定长文本序列。在反向传播计算梯度时,基础循环神经网络会出现梯度消失或梯度爆炸的问题。Wang 等[15]采用LSTM 结构实现了Twitter的情感预测。
3)CNN 和RNN 的融合结构。卷积神经网络可以有效提取句子局部特征,但无法获取词语的时序关系以及词语间依赖关系。循环神经网络擅长获取特征的长短期依赖关系。合理利用两种网络结构的优点,可以实现更好的分类效果。Wang[16]针对CNN 和RNN 存在的缺陷,提出中断循环神经网络(Disconnected Recurrent Neural Network,DRNN)。实验结果表明,DRNN 可以同时获取长距离依赖关系和关键短语信息。
4)融合注意力机制的深度学习模型。当文本序列较长和文本较为复杂时,深度学习模型会丢失重要关键信息。Devlin 等[17]采用自注意力机制(Self-Attention)、Mask 方法和Transformer 编码结构设计了具备更高泛化能力的BERT 模型。Liu 等[18]改进了BERT 模型在预训练时的策略,提出了RoBERTa 隐式情感分类模型。Yang 等[19]采用双向门控循环单元(BiGRU)和层级注意力机制,提出了用于文档情感分类的模型,其中注意力机制包括词语级和句子级两个部分。
综上所述,CNN、RNN以及变体结构在特征提取上具有不同的优势,合理组合两种结构在特征提取上的优势可以提升情感分类效果。注意力机制可以为句子中的重要情感特征赋予更大权重。深度学习模型更容易扩展,可以容纳更多特征信息。
2 特征分析
在已有的中文隐式情感分类任务研究中,隐式情感句缺乏关键情感特征、隐式情感句和上下文语句在情感类别上具有高度一致性特点备受相关学者的关注,本文从文本长度和情感词汇资源的角度对隐式文本的特征进行了分析。
2.1 文本特征
句子长度对不同分类模型情感分类效果有较大影响[20],本节对隐式情感句的句子长度进行了统计分析。首先,本文将测评任务公布的训练集和验证集文本进行了合并;其次,从合并后的文本中根据句子的标签信息提取了隐式情感句;最后,统计了隐式情感句的句子长度信息,统计结果如表2所示。
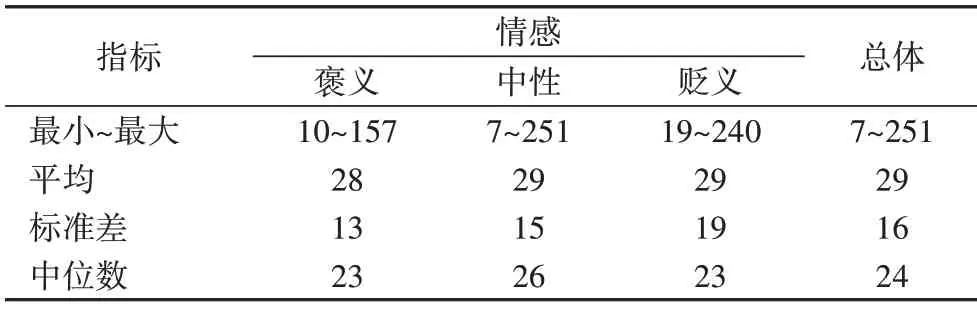
表2 句子长度统计结果Tab.2 Sentence length statistics
为了更加直观地观察句子的文本特征,绘制了隐式情感句句子长度和频数的分布图。将句子长度和频数取以10 为底的对数后,采用机器学习库(Sklearn)的线性回归模型对句子长度和频数关系进行了拟合,拟合结果如图1 所示,其中,黑色圆点代表句子长度对应的频数。在对数坐标系下,隐式情感句长度和频数满足幂律分布,函数关系式为y=-1.983 3x+4.834 8,指标R2为0.582 3。

图1 句子长度和频数关系Fig.1 Relationship between sentence length and frequency
由图1可以发现:情感句长度分布较为集中,由图1(a)可以看出,本文隐式情感句子长度多数集中在[20,160],在部分子区间内会出现峰值,句子长度较长(>160)和较短(<20)的数量较少。在文本研究领域,句子长度低于160 个字符被定义为短文本[21]。隐式情感句长度低于160 个字符占比约为99%,因而隐式情感分类属于短文本分类研究领域。在采用循环神经网络提取隐式情感特征时,预测模型擅长获取句子的距离依赖和位置特征,但模型每一时刻的隐层状态都和前面所有词语相关,会忽略关键的短语特征[21]。隐式情感句中词语的位置特征对分类结果有重要影响。在采用卷积神经网络提取隐式情感特征时,预测模型擅长获取句子的关键短语特征,但模型的池化操作会丢失句子的位置特征[22]。根据两种模型的特点,本文采用GCNN 和GRU 的组合提取隐式情感句特征。
2.2 情感词汇资源特征
本文采用如下步骤对隐式情感句和上下文语句词汇资源进行分析:
步骤1 构建表情符号词典。微博平台用户会使用表情符号来表达部分隐式情感[23]。在采用分词工具对句子进行切分时,表情符号作为新词会被错误切分,如表情符号“[嘻嘻]”会被分成“[”“嘻嘻”“]”三部分。在隐式情感研究中,本文将完整的表情符号作为单独词语。在分词工具中,本文通过自定义表情符号词典的方式将表情符号进行完整保留。本文从微博平台上收集了常用的1 691个表情符号,具有代表性的表情符号与情绪类别对应关系如图2所示。

图2 表情符号与情绪类别对应Fig.2 Emoticons correspond to emotional categories
步骤2 将隐式情感句与上下文情感词汇进行分词。采用带有自定义表情符号词典的jieba 分词工具将隐式情感句划分为单独的词语。
步骤3 查询与统计。查询词语组中的词语在词汇本体库中是否出现,统计出现过词语的情感类别和强度等信息。
采用算法1 对隐式情感句与上下文进行识别,统计结果如表3所示。

在表3 中,“句子总数”代表隐式情感句(上下文)的总数;“含有情感词汇的句子总数”代表隐式情感句(上下文)中含有情感词汇的句子。由于并非所有的隐式情感句(上下文)都含有情感词汇,“含有情感词汇”代表隐式情感句(上下文)中含有情感词汇的句子数。“隐式情感类别/情感词汇类别”用于记录隐式情感句(上下文)情感词汇与句子情感倾向相同的数量。

表3 隐式情感句与上下文词汇资源统计结果Tab.3 Statistical results of implicit sentiment sentences and context lexical resources
对统计结果进行分析,在占比上,隐式情感缺乏情感词汇资源,训练集中含有一个及以上数量标记词汇的句子约占总体的29.18%,验证集中含有一个及以上数量标记词汇的句子约占总体的29.26%。而在上下文中,含有情感词汇的句子占总数的比例较高,分别为训练集73.55%与验证集72.29%。在占比上,上下文语句的情感词汇资源明显高于隐式情感句,这一特点说明了上下文语句中蕴含丰富的情感词汇资源。
情感词汇拥有的情感强度较弱,即词汇不带有明显情感倾向。为了直观衡量标记词倾向与句子整体倾向,本文统计了情感词汇分别与隐式情感句和上下文语句情感倾向相同的句子,统计结果见表4。
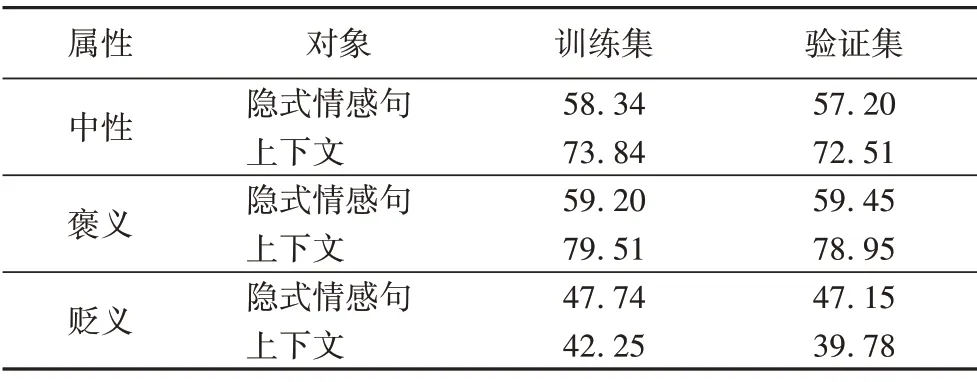
表4 情感词汇与隐式情感句和上下文语句相同情感倾向统计 单位:%Tab.4 Statistics on the same tendency of sentimental words,implicit sentiment sentences and contextual sentences unit:%
由表3~4 可以得出以下结论:情感词汇占比低、情感词汇和隐式情感句情感倾向不一致这两个特点会使句子情感判别更加困难;上下文语句中蕴含丰富的情感词汇资源,并且情感倾向和情感句情感倾向相同占比平均达63%以上。基础模型输入仅包括隐式情感句,未利用到上下文语句中丰富的情感资源,且有实验证明词语的时序关系以及词语间依赖关系对分类结果有提升作用。针对以上问题,本文采用GRU 提取隐式情感句中的时序关系及词语间的依赖关系,用BiGRU+Attention 的组合结构提取句子外的上下文特征,在融合层使用特征向量点乘的方式,融合时序特征与上下文特征,从而提升中文隐式情感分类效果。
3 隐式情感分类模型
本章主要介绍本文提出的融合时序与上下文特征的隐式情感分类模型。
3.1 任务定义
隐式情感分类任务与传统的情感分类任务相同。为了更加直观地表示本文采用的上下文特征对隐式情感分类的影响,对包含上下文的隐式情感分类任务进行了定义:
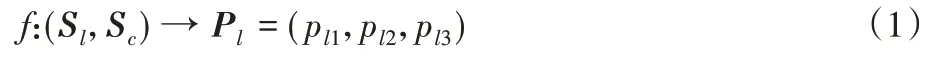
其中:采用Sl代表任意隐式情感句,Sl可表示为Sl=(wl1,wl2,…,wlm),其中wlm表示Sl第m个词语特征,m代表句子中词语的数量;Sc代表隐式情感句对应的上下文语句,Sc可表示为Sc=(wc1,wc2,…,wcm),其中wcm表示Sc第m个词语特征。pli代表情感类别的概率,隐式情感类别可表示为Pl=(pl1,pl2,pl3),其中pl1、pl2和pl3代表中性、褒义和贬义隐式情感类别的概率。包含上下文信息的隐式情感分类任务可定义为:对于给定的任意隐式情感句Sl及其对应的上下文语句Sc,判定Sl和Sc对应的Pl,即计算Sl和Sc在Pl中各元素上的极大似然概率分布。
3.2 模型描述
本文提出的模型总共包含4 个部分,分别为输入层、编码层、融合层和输出层。整体模型结构分为4 层(见图3),输入层主要负责将隐式情感句和上下文语句转换为定长的特征向量并输入进模型;编码层主要负责对输入层表示的特征向量进行编码,并输出编码后的特征值;融合层为包含计算节点的网络结构,用于融合隐式情感句中的时序信息和上下文特征中重要的情感信息;输出层根据融合后的特征计算各个情感类别的概率。
3.2.1 输入层
1)对隐式情感句的处理。
步骤1 文本预处理。由于数据来源于网络,文本数据包含较多的标点符号和“脏数据”。“脏数据”指和官方测评任务描述不同的语句,主要指标签后带有“"”符号的句子。为使隐式情感句数量与官方测评任务保持一致,本文去除了“脏数据”。
步骤2 对隐式情感句进行分词。采用带有自定义表情符号词典的jieba分词工具将隐式情感句划分为单独的词语。
步骤3 定长处理。为方便进行特征编码,设定使用句子最大长度对隐式情感句进行补齐或者截断处理。设定最大长度阈值为n,采用Sl代表任意隐式情感句,采用wlm表示Sl第m个词语特征,则任意隐式情感句可表示为Sl=(wl1,wl2,…,wlm),采用式(2)对句子进行定长处理:

其中:当词语数量大于n时,对词语顺序大于n的词语进行截断,横向拼接前n个词语作为句子的特征表示;当词语数量小于n时,对词语进行补齐,用n-m个特定标志[padding]进行左补全。
步骤4 词向量表示。查询隐式情感句Sl每个词语在词嵌入模型中的向量表示,将词语特征转化为定长维度的实数向量。假设预训练词向量表为N∈RV×d,其中N为向量表的词典大小,d为词向量的维度大小。对任意隐式情感句Sl=(wl1,wl2,…,wln),采用维度为1×N的向量N(wln)∈R1×N表示wln在N中的位置,其中,wln对应的位置数值为1,其余位置为0,采用式(3)将每一个隐式情感句Sl转换成N×d维度的实数向量。

对于不在词典中的词汇和[padding]标志,采用相同维度大小的全0 向量进行初始化。任意隐式情感句Sl对应的向量表示为wl=,其中wl维度大小为n×d。
2)对上下文语句的处理。
上下文语句不需要进行“脏数据”处理,其余操作同隐式情感句处理操作。
3.2.2 编码层
1)对隐式情感句进行编码。
隐式情感句的编码层包括3个部分:单层GRU单元块、门控循环单元及Dropout机制。
与普通CNN 结构不同的是,GCNN 结合了门控机制和卷积神经网络结构特点,在建模时能简化学习方式,减少非线性计算量。GCNN 能分层次地对输入的语言特征进行分析,根据输入特征建立不同粒度的句法树结构。本文提出了GCNNGRU 隐式情感分类模型,该模型为GGBA 未融合上下文特征的中间模型。本文对GCNN结构进行如下处理:
①由于本文数据集中的隐式情感句属于短文本,本文采用单个门控卷积神经网络块对隐式情感文本特征进行提取,这样既保留了GCNN 独特的特征筛选和提取能力,同时又简化了模型。
②由于本文采用了单层GCNN 结构,分类模型不会出现词表巨大的现象,为了使输出层和其他分类模型保持一致,在输出层部分采用普通的Softmax 代替Adaptive Softmax。本文采用的单层GCNN结构如图4所示。
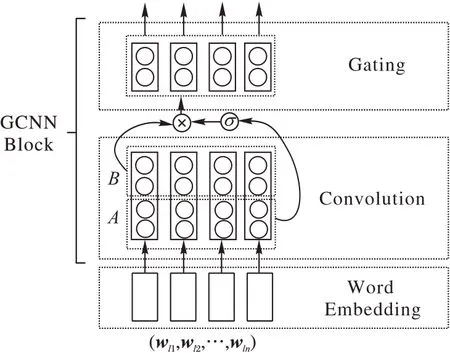
图4 GCNN结构示意图Fig.4 Schematic diagram of GCNN structure
GCNN卷积部分主要分为两部分,卷积激活部分A和用于门控操作的B。GCNN 门控单元会对来自A和B的信息进行如式(4)的计算:
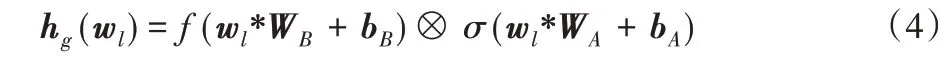
wl为输入层预处理后的特征矩阵;WA和WB为A和B中取值不同的卷积核权重矩阵,WA、WB∈Rk×n×o;bA和bB为A和B中取值不同的卷积核偏置项,n和o为输入特征图信息,k为卷积核信息;σ为Sigmoid 函数,用于控制A部分中信息的传递;⊗为多元乘法运算,用于求A和B两部分各个元素乘积,结果为GCNN 提取到的特征。为便于描述,词向量特征wl经过单个门控卷积神经网络编码后的特征为hg=(hg1,hg2,…,hgn)。
门控循环单元GRU 是RNN 的一种变体结构。GRU 具备同LSTM 相同的长短期记忆能力和更简洁的结构,主要包括两个处理信息的门控结构。在GCNN 编码结构输出部分,本文采用门控循环单元获取更高层语义特征。GRU 结构如图5所示。
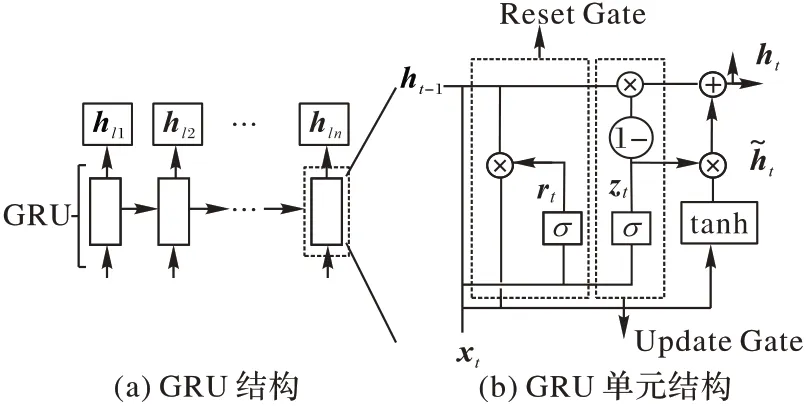
图5 GRU结构示意图Fig.5 Schematic diagram of GRU structure
如图5(a)所示,GRU 中线性序列的特点让特征在前后计算中得以传递,建立了特征长短期距离依赖关系。图5(b)为GRU 单元结构,其中更新门(Update Gate)负责数据的丢弃和更新;重置门(Reset Gate)用于储存遗忘信息的步长。不同时间步内,GRU对输入信息进行式(5)~(8)的计算。
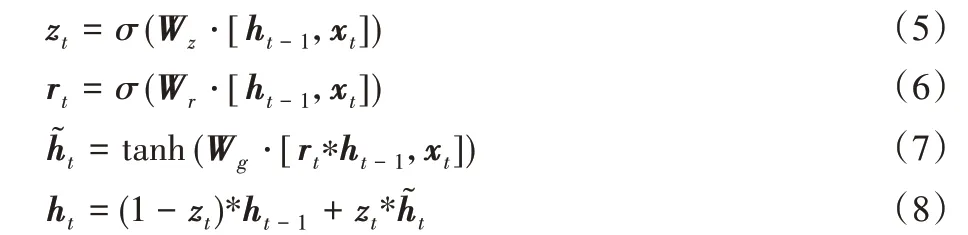
其中:Wz、Wr、Wg分别为更新门、重置门和整个单元的权重矩阵;xt为t时刻的输入;ht-1和ht为t-1 时刻和t时刻GRU 单元输出;zt和rt为t时刻两个门结构的输出,由式(5)和(6)计算得到为新的记忆信息,由式(7)计算得到。为了直观展示特征处理过程,GRU编码过程简化为式(9)~(10):

其中:Wg为GRU 结构的权重矩阵,经过式(3)~(9)的计算,得到GRU结构的输入为前向传播时词语的隐状态为简化的前向序列计算;实际计算过程如式(5)~(8)所示。编码后的特征表示为Hl=[hl1,hl2,…,hln],集合内各元素与wl内元素一一对应。在特征输出部分,本文采用了Dropout机制[24]减弱分类模型中的过拟合现象。
2)对上下文语句进行编码。
为突出上下文语句中的重要情感特征和解决较长上下文语句中关键词信息丢失问题,采用BiGRU 与注意力机制的组合对上下文重要情感特征进行加权输出,结构如图6所示。

图6 BiGRU+Attention网络结构Fig.6 Schematic of BiGRU+Attention network
BiGRU 编码部分会对上下文特征进行双向语义计算,前向计算与GRU编码部分相同,反向计算过程如式(11):

注意力机制层可表示为带有特殊功能的前馈神经网络,主要功能是为拼接后的特征赋予不同的权重。注意力机制层内部主要包括3 个参数,分别为权重矩阵、偏置项及单独的实数序列。注意力机制层会对输入特征进行式(12)~(14)的计算:

其中:Ww为注意力机制层的权重矩阵;bW为注意力机制层的偏置项;μW为随机初始化的实数序列;αt为每个输入分配的独立权重;s为分配权重后的输出。输出后的特征包含了上下文重要情感特征,记作hc=[hc1,hc2,…,hcn]。
3.2.3 融合层
融合层将含有时序特征的向量hl=[hl1,hl2,…,hln]与含有上下文情感特征的向量hc=[hc1,hc2,…,hcn]采用式(15)对隐式情感句特征和上下文特征进行逐元素相乘。

3.2.4 输出层
假设融合后的特征H∈Rn×d,输出层则对输入特征H进行式(16)的计算:

其中:softmax为归一化函数;pli为归一化后的分类模型情感类别结果,Ws和bs分别为输出层的权重矩阵和偏置项向量,取pli中的最大值作为分类模型最终预测结果,即进行式(17)计算:

4 实验与分析
4.1 数据集
本文所用数据集为第8 届全国社会媒体处理大会(SMP2019)举办的“拓尔思杯”中文隐式情感分析评测数据集,由于无法获得该数据集中测试集的标注信息,本文只使用数据集中的训练集和验证集,对训练集重新进行4∶1 的划分,分别作为训练集与验证集,原验证集作为本文测试集。该数据集情感标签为褒义、中性、贬义3 种。表5 展示了标注数据的详细信息。

表5 实验数据信息Tab.5 Experimental data information
4.2 实验设置
4.2.1 数据预处理
对本实验中的数据集进行初步的规则识别,分别提取出隐式情感句和上下文语句。隐式情感句中去除了“脏数据”(3.2.1 节对隐式情感句的处理)。与隐式情感句相邻的语句作为上下文的输入,对于不包含上下文的隐式情感句,采用句子本身作为上下文输入。句子提取完成后,采用带有自定义情感词典的jieba分词工具对句子进行分词处理。
4.2.2 评价指标
本文使用SMP2019 官方提供的评价指标测试各个模型分类性能,即宏平均准确率(Macro⁃P)、召回率(Macro⁃R)及F1值(Macro⁃F1)。宏平均指标的计算需要求得各个类别的准确率(P)、召回率(R)及F1 值。3 个数值的计算如式(18)~(20)所示:
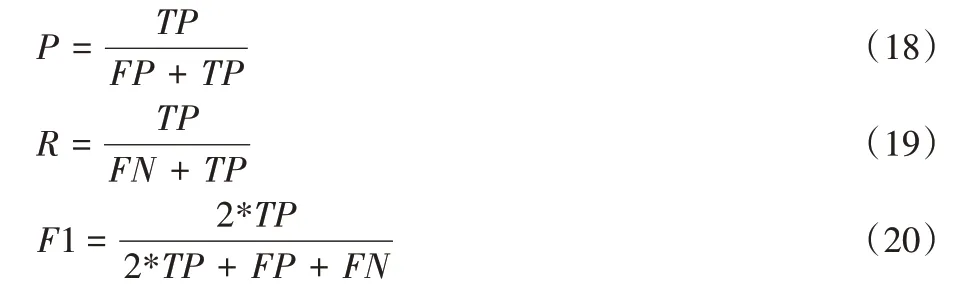
其中:TP(True Positive)表示句子情感类别为正例,分类模型预测结果为正例;FP(False Positive)表示句子情感类别为负例,分类模型预测结果为正例;FN(False Negative)表示句子情感类别为正例,分类模型预测结果为负例。在隐式情感分类研究中,正例为原始情感类别,负例为其他情感类别。宏平均指标为对3 个类别指标求均值,仅展示宏平均准确率计算方式,如式(21)所示,其中Pi与标签信息一一对应,分别代表隐性情感类别:中性、褒义、贬义,其余指标计算相似。

4.2.3 对比实验设置
为直观比较各模型特征提取特点,本文采用Word2vec 词向量,且在训练时融入Word+Character+Ngram 特征[25]。本节选取了隐式情感分类和显式情感分类研究中常用的模型,详细信息如下:
1)LSTM。本文采用文献[15]提出的LSTM网络获取词语的时序关系及词语间的依赖关系,在此基础上建立了LSTM隐式情感分类模型。
2)GRU。获取文本特征表示后,本文采用文献[15]提出的GRU 网络获取词语间的时序关系及依赖关系,从而建立了GRU隐式情感分类模型。
3)GCNN。在文献[14]中的GCNN 分类模型基础上,采用单层门控卷积神经网络进行局部特征提取,通过最大池化和输出层实现特征情感判别。
4)TextCNN。本文在编码器部分采用了文献[12]提出的TextCNN模型。
5)DRNN。本文在文献[16]中DRNN 分类模型基础上,采用GRU 作为中断门控循环单元,通过全连接层、最大池化层提取更高层的特征信息。
6)BERT。本文采用中文预训练BERT 模型[17]获取词语深层次语义信息,搭建了一个Softmax 分类器实现隐式情感句的判别。本文还采用了L2正则化减弱模型的过拟合程度。
7)RoBERTa。本文采用RoBERTa 预训练模型[18]获取词语深层次语义信息,搭建了一个Softmax 分类器实现隐式情感句的判别。本文还采用了L2正则化减弱模型的过拟合程度。
8)GCNN-GRU。本文提出的一种融合词语时序信息的隐式情感分类模型。采用单层GCNN 提取局部特征,通过GRU网络增强距离依赖特性,并获取词语间的时序信息及更高层的语义特征信息,结构内部设计见3.2.2节编码层描述部分。
4.2.4 超参数设置
采用参考相关研究文献和重复实验的方式确定超参数的取值,如表6所示。
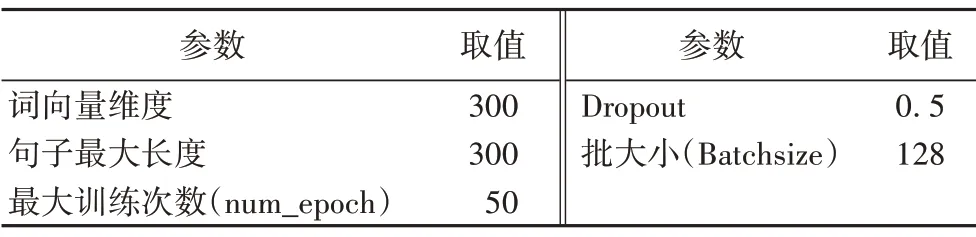
表6 分类模型统一超参数Tab.6 Unified hyperparameters for classification models
分类模型主要包括两大类:一种为循环神经网络相关的分类模型,其中隐层神经元个数对分类结果有较大影响,如LSTM、GRU、DRNN 和GCNN-GRU;另一种为卷积神经网络相关的分类模型,如GCNN-GRU、GCNN 和TextCNN,卷积核数和窗口大小对模型分类结果有较大影响。在确定隐层神经元最佳取值时,设定取值分别为8、16、32、64、128 和256。在确定GCNN-GRU 和DRNN 隐层神经元时,本文参照文本分类任务中卷积神经网络敏感性研究,将卷积核数设定为100,窗口大小设定为1,DRNN 窗口大小设定为10。本节采用宏平均F1 值作为评价指标,在测试集上进行一次实验并记录各分类模型实验结果,实验结果如图7所示。
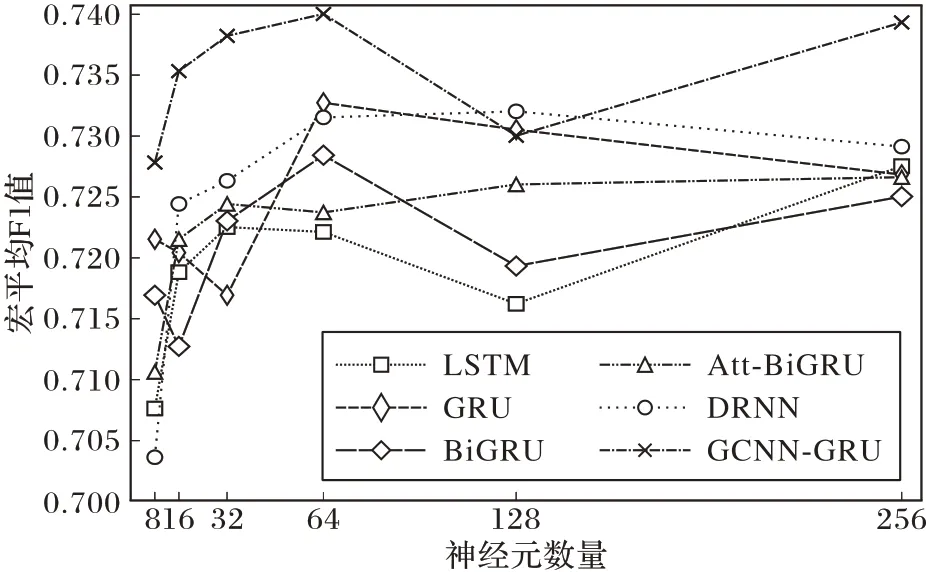
图7 神经元数与F1值关系Fig.7 Relationship between the number of neurons and value of F1
对实验结果进行分析,当隐层神经元数量取值为64 时,循环神经网络相关的分类模型均可以取得不错的分类效果。GCNN-GRU、DRNN、LSTM 和GRU隐层神经元个数设定为64。在研究卷积神经网络相关的分类模型超参数时,窗口大小分别设定为1、3、5、7、10和15。实验结果如图8所示,其中,CNN窗口大小测试参考了文献[17]研究内容,主要目的是测试单层CNN 在不同大小窗口的敏感性。根据单层CNN 敏感性测试结果,本文确定了CNN相关网络的窗口取值。
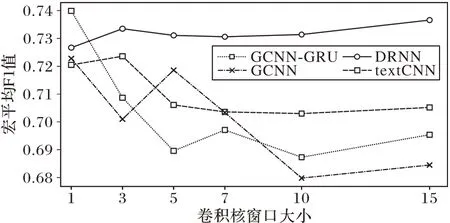
图8 卷积核窗口大小与F1值关系Fig.8 Relationship between size of convolution kernel window and value of F1
对实验结果进行分析,DRNN 分类模型在取值为15 时可以取得不错分类效果,综合其他大型数据集实验结果,将DRNN 窗口大小设定为15。GCNN 和GCNN-GRU 分类模型宏平均F1 值随着窗口增大而下降,在取值为1 时最优。CNN 分类模型宏平均F1 值在3 时效果最优。综合实验结果,分类模型独特的超参数设置如表7所示。
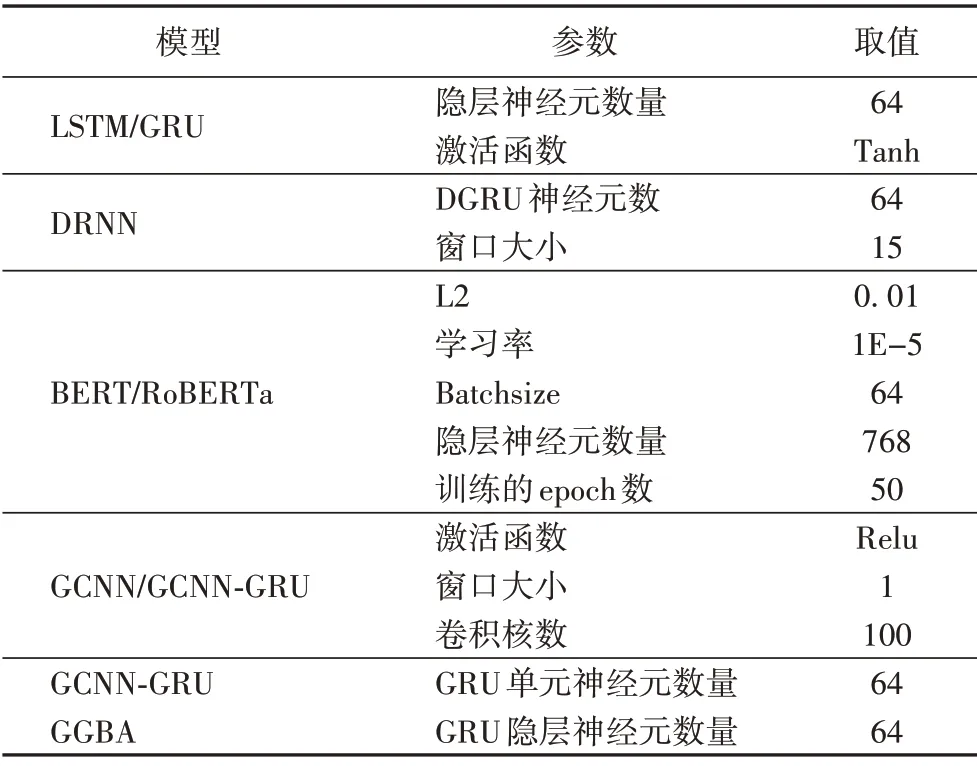
表7 各模型参数取值Tab.7 Different parameter values of models
4.3 实验结果分析
本文对各分类模型进行了5 次重复实验,获取了宏平均准确率、召回率以及F1 值。为了方便对比,本文还列举了各分类模型参与训练的参数量,实验结果详细信息见表8。

表8 各分类模型宏平均准确率、召回率和F1值Tab.8 Macro⁃P,Macro⁃R and F1 values of each classification model
对实验结果进行分析可以得到如下结论:
1)对比GCNN-GRU、LSTM 和GRU 模型,GCNN-GRU 具备更强的局部特征提取和信息筛选能力。与最优的GRU 相比,本文提出的GCNN-GRU 在宏平均准确率上从73.15%提高到了73.74%,提升了0.80%;在宏平均召回率上从72.01%提高到了73.71%,提升了0.97%;在宏平均F1 值上从72.27%提高到了73.65%,提升了1.91%,验证了本文提出的GCNNGRU 在融合局部特征和词语时序信息上的有效性。由于本文数据集中包含修辞语句、情感类别增多(增加中性)、情感类别数据不均衡(中性>贬义>褒义)、不同情感类别的句子不存在界限分明的情感词、数据来源广泛、等特点,导致隐性情感分析任务比显式情感分析任务更加困难,也导致了隐性情感分析的准确度不可能大幅度提升。GGBA 在GCNN-GRU 基础上融合了上下文特征,将宏平均准确率、召回率、F1 值分别提升了1.75%、0.87%、1.33%,证明了上下文信息对隐式情感分类任务的影响。
2)对比GGBA、GCNN、TextCNN 和DRNN 模型,GGBA 模型比效果最好的DRNN 模型在宏平均准确率上提高到75.03%,提高了1.9%;召回率提高到74.35%,提升了1.5%;F1 值提高到74.63%,提升了1.6%,验证了本文所提模型在中文隐式情感分类任务上的有效性。
3)对比GGBA、BERT 和RoBERTa 分类模型,RoBERTa 分类模型采用的双向Transformer 结构、多维度的注意力机制和动态Masking 方法有效获取了词语的深层语义特征,但具备最高数量级的参数量。相对于基础的BERT 模型,改进后的RoBERTa 分类模型在隐式情感数据集上可以获得更好的分类效果。BERT 相关模型由于其庞大的参数量导致预训练时花费的时间更久,且对设备和内存的要求较高[26],若需在手机等资源有限的设备上使用BERT 相关模型,必须缩减模型中的参数量,但紧凑的BERT 相关模型往往会丢失潜在的重要信息,表现出较低的性能。虽然知识蒸馏技术[22]在一定程度上增强了BERT 相关模型的可迁移性,但其性能相较于教师模型仍有所降低。本文的GGBA 模型虽然对宏平均准确率、召回率和F1 值的提升不如BERT 模型和RoBERTa 模型,但其参数量骤降,更适用于资源有限设备。
5 结语
本文首先对隐式情感句文本特征和情感词汇资源进行了分析,然后提出了一种融合局部特征提取的隐式情感分类模型GCNN-GRU 和一种融合时序信息和上下文信息的中文隐式情感分类模型GGBA。GCNN-GRU 模型证明了局部信息与时序信息对中文隐式情感分类任务效果的提升,基于隐式情感分类对上下文信息的依赖;在GCNN-GRU 模型基础上,融合了上下文信息,提出GGBA 模型,在宏平均准确率、召回率和F1值上均有不错的表现,效果相较于参数量级较低的模型均获得了不同程度的提升。虽然分类效果不如BERT 和RoBERTa,但是GGBA 模型小、参数量低、迁移性高,能够在手机等资源有限的设备上达到最好的性能。随着互联网行业的发展,人们表达感情已经不仅仅局限于文本,图片、声音、视频均可以传达人们想要表达的感情,所以,接下来的工作也会着重研究多模态的情感分析,更加贴合人们的实际生活。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
软件(2017年6期)2017-09-23
