
基于分布式数据库的矿山生态评价系统基于分布式数据库的矿山生态评价系统
2021-11-04 02:41:54陈振武黄泽坤卢文涛张哲涵林思思兰添才
龙岩学院学报 2021年5期
陈振武,黄泽坤,卢文涛,林 柯,张哲涵,林思思,兰添才
(1.龙岩学院;2.大数据挖掘与应用福建省重点实验室 福建龙岩 364000)
对矿山生态环境的评价数据广泛分布于矿山各个角落,对数据的收集、存储与加工处理具有实时的特性,对于这些数据的收集、加工、处理、存储,具备了去中心化的分布式数据存储与应用特性。近年来,国内外诸多专家学者进行了相应的研究并应用于物流管理、仓储管理以及矿山信息管理领域。
文献[1]研究云计算、服务器虚拟化、分布式数据库等技术,建设了具有中心数据库并实现各地分布式数据库交互的兖矿应急救援示范平台。在企业资产管理应用方面,可以利用非关系数据库MongoDB设计实现[2]。
由于关系型数据库的横向数据存储的扩展在Web应用设计中是比较困难的,而非关系型数据库对数据的存储一般以文档的形式进行,对数据的查询操作没有横向的概念,也可以无须建立固定的键值[3]。文献[4]证明了将使用MongoDB数据库提供Web存储服务融合前端交互设计,比传统的关系数据库具有更好性能(数据处理速度及资源占用率)优势。史晔翎等[5]也证明了这种结合,可以弥补关系型数据库在数据存储方面的缺点。
本文利用端开源框架Angular以及MongoDB在分布式存储系统的高可用特性,将Angular与传感器自动获取相关环境指标数据技术融合,将矿山企业各分支机构的生态数据存储系统整合,实现对异地分布的矿山生态实时数据的高效存储与评价管理。
1 系统高可用性架构
本系统高可用性设计的基础思想包括[6-7]:
(1)业务服务器的建立。逻辑上将一些位于同一地点或不同地点的服务器集中建立业务服务器系统;
(2)数据库分层架构。物理上采用分布式架构,系统架构示意参见图1所示;
(3)数据分区的设计。整个系统需依据数据库的规模设定一个或多个数据分区;
(4)为每个分区选择设定相应的“key”。该“key”是对数据存储所在的分区位置的标识,也可做为共享数据元素的相应“key”的拷贝;
(5)系统重构功能的设定。通过共享数据元素“key”对分区位置的标识设定,构成可复制的若干系统重构Replica_Set节点及树形结构(包括主节点与从节点的定义),其中,同级节点间须有相同数据备份;
(6)分区服务器设置。包括端口、IP及名称的设置;
(7)节点服务器配置。为分区内的每个节点配置至少一个或多个路由器,提供客户端连接路由服务申请,并向数据分区分发客户端的路由申请。
2 数据库分层架构
利用数据库的分层架构,也叫N层架构[7],本文采用4层数据仓库结构模型,架构示意参见图2所示。
3 数据库分区与操作均衡
3.1 数据库系统用例
数据库系统的超级用户、普通用户用例参见图3所示。
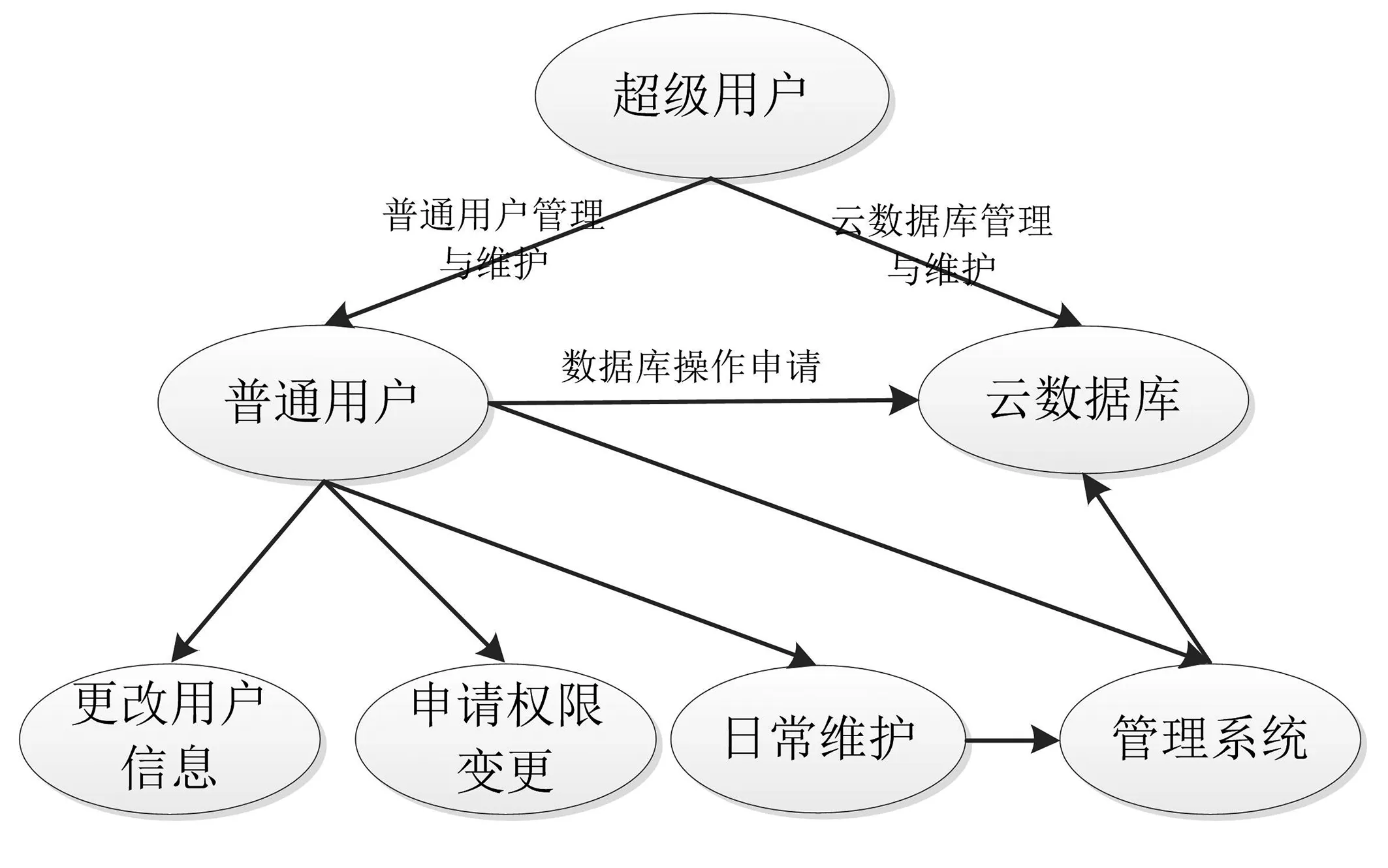
图3 数据库系统用例
超级用户:能够对普通用户进行管理与设定,也可以对生态环境指标监测的传感器终端设备进行设置(包括设备的启/停、初始化、IP地址,客户端数据库访问权限,评价系统的指标比例因子,数据库服务的启/停等);
普通用户:可以按照需求申请数据库,获得对相应云数据库访问的地址、端口及数据库名称等信息。功能主要包括启/停数据库、修改用户信息、日常维护以及对相关节点的生态环境信息进行采集、录入、管理、回存等基本操作。
3.2 建立分区数据库
由于MongoDB可以支持依据数据分类将数据拆分并自动存储到相应分区的功能,这就为建立分布式系统架构进而对大量分散数据进行分区存储提供依据。
分区数据库的建立关键点,首先需对相应数据进行分组,分组的依据是属性的定义。各分区具有代表性的属性一般都是被定义成关键属性或称为共享键(如Share_key01、Share_key02……),并作为建立数据分区的依据。如使用“声环境”sound_key可以用来定义各噪音污染传感节点数据库、传感节点设置位置等数据库表的共享属性键。客户端对“声环境”sound_key查询时,如果发现该key属于某矿山“声环境”数据库,则将该key发送到该矿山“声环境”数据分区所在的分区服务器或客户端上;获取该“声环境”数据的对应传感器节点或通过人工录入数据的节点所属的指标库信息发送到相应的分区数据库中。然后将分组数据分别存储于较大的一级分区中,再对一级分区进一步细分为基于稍小些的二级分区并负责存储上一级分区总数据的一部分,依此类推。这里需要对分区数据库的连接状态进行分别定义,包括主控程序创建相应的管理进程、客户端对分区数据库的连接申请进程,很明显此两进程须为不同名,否则,系统会产生冲突。
3.3 数据分区的均衡性
分析MongoDB的特性可以发现,其对数据的存储与处理机制是通过将用户或系统访问的数据缓存至本地进行的。这种机制中,对数据库的数据添加造成对节点的工作负载远比对数据的读取、写入负载大,会造成数据块所在的节点的负载不均衡[8],系统需对这种负载不均衡进行适时调节,否则系统很容易产生因对某个节点数据、文档高密度访问而造成系统拥堵甚至崩溃,但调节过程又会造成系统资源的浪费[9]。
对节点数据库的均衡操作关键是如何将对数据的插入、查找、修改等操作比重进行均衡性调节,文献[3]采用在计算对数据库的插入数据频率时乘上一个大于1的调节系数(λ)的方法来实现对插入、查找、修改等操作的均衡性。同时,利用文献[9]所提出的基于数据操作的频率(FODO)改进的均衡算法设计,以实现对分区节点数据库的均衡操作。算法的Python描述如下:
(1)初始化
#导入python的random库及numpy模块中的随机函数
import random
import numpy
#数据操作频率计算,p为节点数,M[i][j]文档操作参数矩阵
p = input(“集群节点数”)
p = int(p)
M = [[0]*5]*p #第一列文档块 第二列操作频率 第三列插入操作频率 第四列查询操作频率 第五列更改操作频率
for i in range(0,p):
for j in range(0,5):
M[i][j]= random.randint(1,10)
print(M)
(2)计算各节点各文档块总体操作频率及各种操作频率
#变量SUM_O、SUM_I、SUM_F、SUM_C、SUM_SUM_DO分别用于存放对各节点文档块的操作次数之和及插入、查询、修改、整个分区的操作频率之和
赋各变量初值(为零)
for i in range(0,p):
for j in range(0,5):
SUM_O = SUM_O + M[i][1]
SUM_I = SUM_I + M[i][2]
SUM_F = SUM_F + M[i][3]
SUM_C = SUM_C + M[i][4]
#DO、DI、DF、DC、SUM_DO分别用于存放对各节点文档块操作频率及对文档块的插入、查询、修改操作频率、所有操作频率之和[10].
for a in range(0,p):
print(“这是第” + str(a) +“个节点”)
DO = M[a][1] / SUM_O
DI = M[a][2] / SUM_I
DF = M[a][3] / SUM_F
DC = M[a][4] / SUM_C
print(DO)
SUM_DO = DI + DF +DC
print(SUM_DO)
(3)计算引入调节参数λ后各节点文档块数据操作频率SUM_DOX
#λ是为了调整插入操作与查找、修改操作的均衡关系参数,λ>1
λ = input(“调节参数”)
SUM_DOX = λ*DI + DF +DC
print(SUM_DOX)
(4)计算整个分区的操作频率
#用每个节点中所有文档数据的操作频率之和即是整个分区的操作频率
SUM_SUM_DO = SUM_SUM_DO + M[a][0]*SUM_DO
print(SUM_SUM_DO)
4 系统设计与实现
4.1 系统功能模块
模块包括指标统计、数据库设计、指标数据获取与输入(传感器采集与人工获取两部分数据)、管理与维护、节点访问均衡性设置共五个模块,采用B/S模式。各服务器均可存储数据并运行数据管理程序。
(1)指标统计。为了克服定性评价对结论的影响,采用融合层次分析与模糊数学分析方法对综合评价指标进行统计计算,层次分析法中的评价结构分为三层;
(2)数据库设计。系统数据库共需四张表用于存储指标权重、判断矩阵、实测指标(人工)、传感器指标(自动采集),分别为Q_zhong表、PD_max表、RG_sc表、CG_cj表;
(3)数据获取与输入。通过传感器获取的数据主要包括声音、水质、空气等数据(如噪音指标、空气的PM值、水质的PH值,等等)送入数据库;无法布设传感器则通过人工实测获取(如废弃物的排放量、地灾频度与规模、土地压占面积或圧占率、土地复垦面积或复垦率,等等),并可以在任一节点上进行手工输入,以体现分布式存储的优点;
(4)系统管理与维护。由超级管理员承担对系统进行相关的管理与维护,包括对普通管理员帐户的管理与修改,也可以对指标进行管理操作,如属性定义、添加删除修改、指标权重调整等操作;
(5)节点访问均衡性。通过设置与调整节点访问均衡性参数λ(λ>1)对存储于分布式系统中的数据进行均衡性调整,实现对分区节点数据库的均衡操作。
4.2 顶层数据流图
顶层数据流图主要用于描述超级管理员与普通管理员之间操作不同的功能模块所产生的数据流向关系,功能模块包括判断矩阵、传感器数据、人工数据的输入、数据的请求与返回、超级管理员、普通管理员等模块。系统顶层数据流参见图4所示。
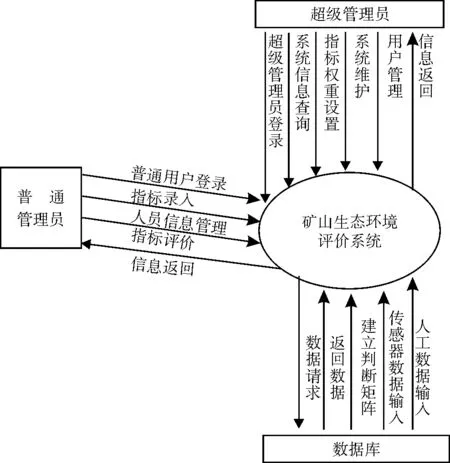
图4 系统顶层数据流
4.3 第二层数据流图
第二层数据流所描述的是各角色(主要是指不同管理员)操作相应功能模块所产生的数据流向关系。不同角色具有不同的操作权限。系统第二层数据流参见图5所示。
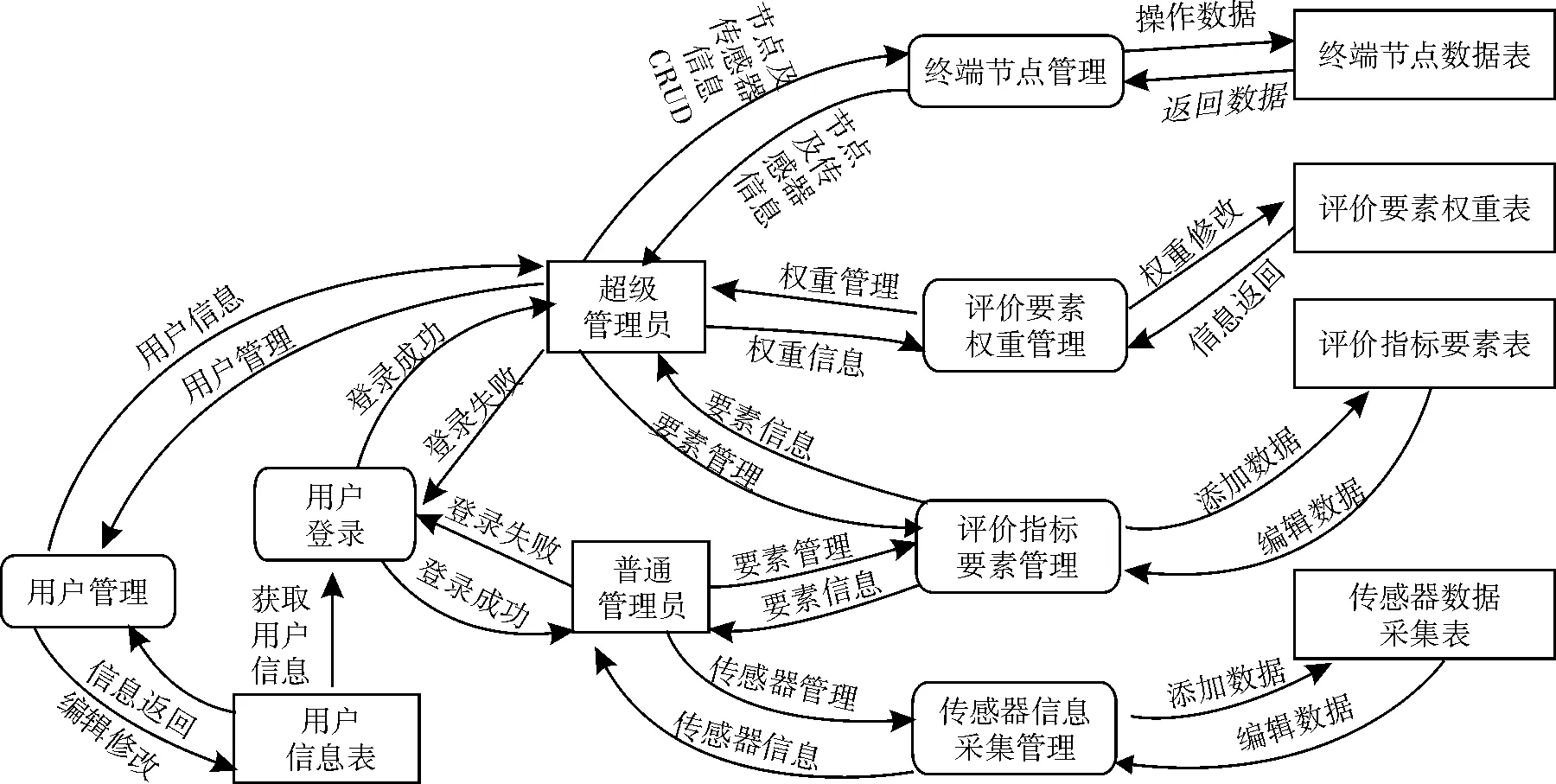
图5 系统第二层数据流
4.4 系统设计与实现
4.4.1 数据库设计
从业务数据节点、数据安全、节点数据一致性及节点数据访问频率等方面的需求进行分布式数据库设计,还需对系统重构、数据备份进行相应架构与设计,系统共设计了5张表用于存放用户信息、各分区节点服务器数据、评价要素权重、评价指标要素、传感器信息采集[11]。
(1)用户信息表结构应包括名称、密码、编号、角色、邮箱等字段;
(2)各分区节点服务器数据表结构包括节点名称、编号、节点地址、节点IP等字段;
(3)评价要素权重表结构包括指标名称(一级指标、二级指标、三级指标)、指标权重(对应于指标名称分别建立指标三层权重A、ai、aij)等字段;
(4)评价指标要素表主要指因素指标的判断矩阵格式表,判断矩阵的建立是依据各级评价指标要素之间的关系利用层次分析及模糊数学分析融合的方法进行整理建立起来的[11];
(5)传感器数据采集表:所属矿山名称、矿山位置ID、管理员、传感器布设位置信息、传感器ID、指标数据采集日期时间、采集的指标数据。
4.4.2 系统前端对数据库的访问
系统前端对数据库的访问可以通过封装在Angular中的“http客户端”模块、封装在ng-alain中的“http客户端”方法进行,通过这种基于“http客户端”的模块与方法可以很方便地自动添加请求并对返回的数据格式进行加工与处理。本文利用Postman软件提供能够根据用户不同接口定义去选择http的请求并进行数据接口的配置与服务器的部署。
4.4.3 功能模块实现
系统功能模块包括一级的登录模块,成功登录后即可进行二级模块的操作(包括判断矩阵构建、判断矩阵一致性校验、传感器管理、手工实测数据管理、评价及评价结果管理等),依此类推。
系统登录主界面参见图6所示。
实现系统登录主界面的代码可简单表述如下(其他模块及实现代码略)。
if (res.role === '') {
this.error = res.msg;
return;
}
if (res.role === 'ROLE_USER') {
this.aclService.setRole(['ROLE_USER']);
}
if (res.role === 'ROLE_ADMIN') {
this.aclService.setFull(true);
}
//路由信息清理
this.reuseTabService.clear();
// 设置用户标志信息
this.tokenService.set(res);
//当应用信息受当前用户授权范围影响需要重新启动服务
const user = {
name: res.name,
// avatar: res.avatar,
avatar: './assets/tmp/img/avatar.jpg',
userId: res.id,
};
this.settingsService.setUser(user);
this.startupSrv.load().then(() => {
let url = this.tokenService.referrer.url || '/';
if (url.includes('/passport')) url = '/';
this.router.navigateByUrl(url);
});
}
5 结束语
针对在多点多级生态环境评价指标系统所涉及的复杂应用管理,探索将分布式数据库、传感器技术结合应用于指标数据的获得与存储,对于异地性、分布式的矿山生态环境评价的大规模数据管理与分析具有一定的借鉴意义。由于不同类型矿山的开采方式、生态影响范围、评价指标定义及指标权重选择、环境治理恢复方式及程度要求也不尽相同,因此,评价指标数据的可扩展性、自适应性等方面的研究还需要进一步开展;通过传感器自动获取生态指标数据的种类也可不断研究扩展,以减少指标数据人工获取的主观影响;各层次指标权重的设定主要依据评估专家的意见建议并结合层次分析或融合层次分析与FUZZ进行,可以进一步探索通过更为合理、全面的数学方法,以获得更为准确的评价结论。
猜你喜欢
环球时报(2022-03-29)2022-03-29 17:14:11
天天爱科学(2020年6期)2020-09-10 07:22:44
知识经济·中国直销(2018年7期)2018-07-27 02:49:52
能源(2017年10期)2017-12-20 05:54:07
能源(2017年5期)2017-07-06 09:25:54
美术文献(2016年6期)2016-11-10 09:09:40
雷达与对抗(2015年3期)2015-12-09 02:38:50
电测与仪表(2015年8期)2015-04-09 11:50:16
电测与仪表(2015年7期)2015-04-09 11:40:16
全球定位系统(2015年4期)2015-02-28 12:38:08
