
基于语义分析等技术的数据敏感度自动识别
2021-11-03 06:43:42王媛媛陈昱翰
电子技术与软件工程 2021年18期
王媛媛 陈昱翰
(中国电信股份有限公司上海企业信息化运营中心 上海市 200120)
1 引言
数据保护是当今企业、政府和个人关心的基本问题。数据库安全中的敏感数据梳理技术是一种数据资产自动发现及对数据进行分级分类的敏感数据梳理技术。《中华人民共和国数据安全法(草案)》(以下简称《数据安全法(草案)》)中首次对数据的分级分类保护作出明确要求,这对于指导和落实数据安全保护工作具有重要意义,数据的分级分类管理是实施数据全生命周期安全保护的重要基础,只有在科学、规范的分级分类管理基础上,才能够有效地平衡数据的安全要求与使用需求,才能够较好地实现数据的风险管理成本与利用效益的平衡,从而为数据产业的快速健康、可持续发展奠定坚实基础.数据分级分类不仅需要遵循相关规范和标准,还要结合业务特征和需求,采取科学的分级分类方法.对于大型和复杂系统而言,专业团队和技术工具有助于此项工作的顺利开展,数据分级分类管理应当是一项持续性工作,可纳入数据及数据资产运营管理的范畴[1]。
目前中国电信常用的数据库包括中国电信自研数据库TeleDB、Oracle 数据库、Mysql 数据库、Hive 数据库、PgSql 数据库等。电信行业使用的敏感数据梳理检查方式一般是关键字和正则表达式匹配方式。关键字方式是通过读取数据库的字段内容和列名称内容,匹配固定关键字以梳理数据库内容的敏感数据。正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式匹配方式是通过读取数据库的字段内容和列名称内容匹配指定正则表达式以梳理数据库内容的敏感数据。以上关键字和正则表达式匹配的两种常规方式都无法匹配无固定格式的信息。例如姓名、地址、公司名称等。在传统的敏感数据检查技术上,本文新增了语义识别判定方法。通过语义识别判定方法解决了无固定格式的数据识别问题。
2 敏感数据自动识别技术
传统的敏感数据读取方法主要为关键字匹配和正则表达式匹配。对于不具备特征值的姓名、地址无法有效匹配。针对该技术难点,本文引入了语义识别技术。将语义识别应用在姓名、地址、公司名称的中文信息识别上。同时文中使用了多种正则表达式匹配方式识别电话、邮件、IP 地址、身份证号等信息。在实际系统中,灵活组合语义分析、正则表达式、传统的关键字等多种方式进行敏感数据自动识别,达到最佳识别效果。
2.1 语义识别技术的应用
中文语义识别使用PYHANLP 实现。HANLP 是一个第三方开发包,用途是语言分析。PYHANLP 是基于它的python 包。pyhanlp 是HanLP 的Python 接口[2]。使用它的分词方法可以将:广东省深圳市城市假日花园分词为:广东省(名词)深圳市(名词)城市(名词)假日(名词)花园(名词)。系统根据分词结果和特定姓名、地址字典确认地址和人名等信息。HANLP 自然语言处理包支持中文分词(N-最短路分词、CRF 分词、索引分词、用户自定义词典、词性标注),命名实体识别(中国人名、音译人名、日本人名、地名、实体机构名识别),关键词提取,自动摘要,短语提取,拼音转换,简繁转换,文本推荐,依存句法分析(MaxEnt 依存句法分析、CRF 依存句法分析)[2]。
本文将pyhanlp 的语义分析方法应用于数据库敏感数据的语义分析判定中。首先,判定字段值内容是否含有中文字符,对于含有中文字符的字段值获取CRF 分词器。然后,CRF 分词器将字段值分解为子单词和单词属性(名词、动词)。针对分解后的名词在地址特征词字典、姓名特征词字典中进行匹配。最后判定出字段值是否为中文地址、中文姓名、中文公司名称等。
CRF 分词器使用条件随机场模型。条件随机场模型是一条件序列无向图模型,CRF 实在给定观察序列的条件下,计算整个观察系列对应的标记序列的联合概率分布[3]。
如中文地址分析代码为:
# 匹配出中文地址
#(A1-5)用户私密资料:揭示个人种族、家属信息、居住地址、宗教信仰、基因、个人健康、私人生活等有关的用户私密信息等;《征信业管理条例》等法律、行政法规规定禁止公开的用户其他信息。


该代码的模块说明图见图1 语义分析模块说明图。
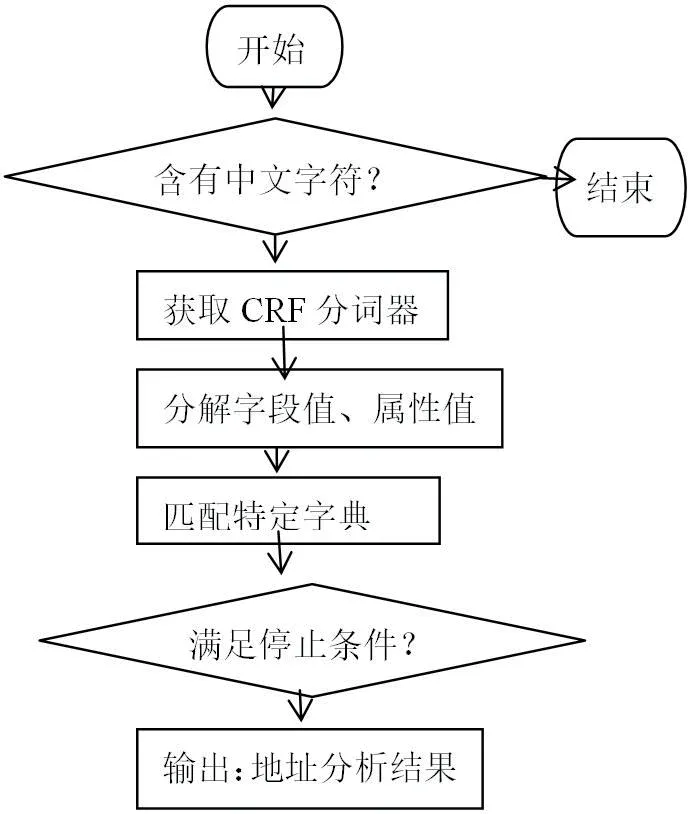
图1:语义分析模块说明图程
2.2 正则表达式识别方式的应用
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。8 位电话号码、11 位电话号码、身份证号、银行账号、邮箱地址、即时通信账号都符合一定的正则表达式。
本文识别了多种正则表达式,并应用在实际系统中[4]。其中:
设备IP 正则表达式为

非中文的字符正则表达式为
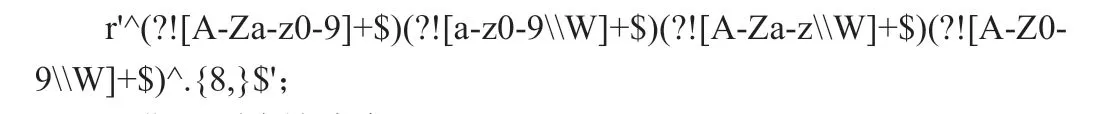
日期正则表达式为

电话号码正则表达式为r'^((0d{2,3})-)(d{7,8})|(d{7,8})$';
个人手机号码正则表达式为

身份证号正则表达式为

驾照正则表达式为r'^[1-8]d{11}$';
qq 号码正则表达式为

邮箱正则表达式为email_pattern = r'[w-]+@[w-]+(.[w-]+)+';
2.3 关键字识别方式的应用
关键字识别是查看列名称和字段内容中是否含有特定的关键字。该方法是一种传统的识别方式。这种方法和正则表达式识别方法、语义识别方法结合使用可达到更好的识别效果。
2.4 多种识别方式的组合应用
敏感数据检查和分级分类模块对每个采样的字段值、列名称进行分析。首先对字段值进行检查,通过正则表达式匹配电话、Email、手机号、驾照、身份证。然后通过关键字匹配是否为套餐、合同、业务订购关系、公开业务运营服务数据等。接下来通过列名称的关键字补充确认该列是否为电话、Email、联系人信息、银行账号、费用、订购关系等。最后通过语义分析判断是否为用户名称、用户地址。
在实际生产中,为了便于随时增加配置新的正则表达式和新的关键词。建立本地的sqlite 数据库,将匹配规则对应的各类正则表达式和关键词存储在数据库中。
存储表如表1 所示。

表1:匹配规则存储表
根据字段内容content、列名column_name 对照规则rule 判定是否为对应类别。代码和存储表结合,通过5 种情况可解决多类数据的识别问题。对于新增的数据识别项目,只要在表格中根据实际情况添加对应的识别方法、识别关键字或正则表达式,即可在不更改代码的情况下进行识别。该方法避免了每类数据都要新增代码的问题。
3 多线程和加密技术
因为敏感数据识别应用需要访问海量数据库,同时需要记录访问数据库的用户和密码信息。所以在实际应用中需要解决的一个重要问题即性能问题。另一个重要问题是安全问题。本文通过多线程和信号量控制手段解决海量数据库读取的性能问题。通过自定义的加密算法加密数据库用户访问密码解决存储密码的安全问题。
3.1 加密技术的应用
本文实现的软件程序首先读取已经预先加密的数据库配置文件,对数据库配置文件进行解密,解密后获得数据库连接信息。
采用MD5 加盐值(Salt)的加密方式,将数据库配置文件加密。在加密时混入一段“随机”字符串(盐值),可放在原始数据前或原始数据后,再进行哈希加密。即使原文相同,如果盐值不同,那么哈希值也是不一样的。
MD5 加盐(Salt)的加密算法的代码为:


该代码的模块说明图见图2 MD5 加盐值说明图。
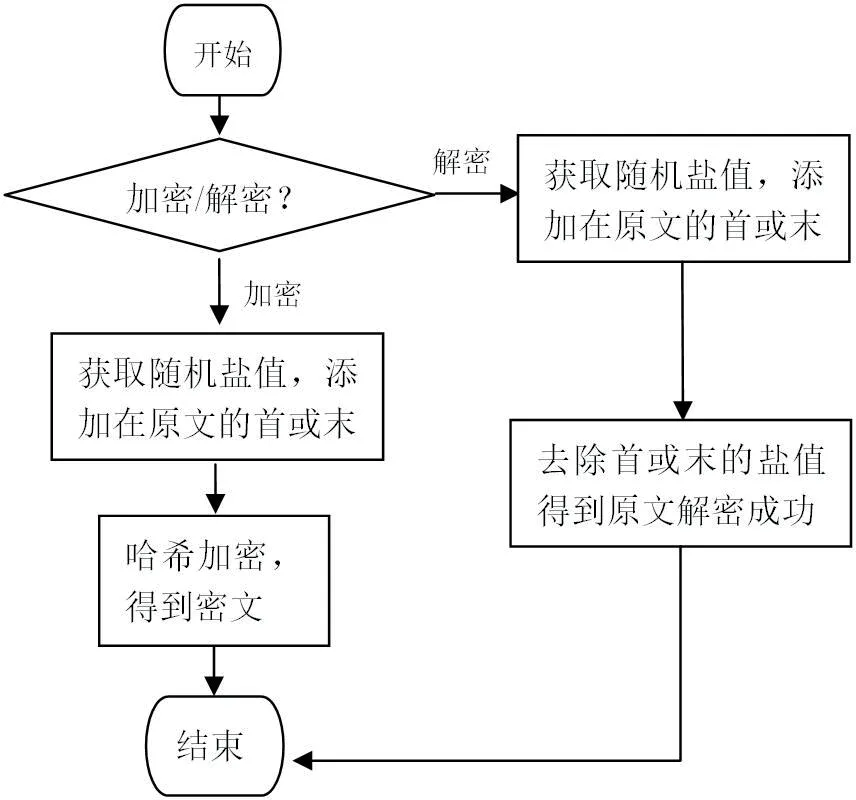
图2:MD5 加盐值说明图
3.2 多线程技术的应用
软件程序的每一个独立线程根据数据库连接信息,针对不同数据库类型:teleDb、mysql、oracle、pgsql、hive 数据库分别调用不同的驱动接口进行检查。对于每个数据库类型,程序编写针对性的驱动接口。每个独立线程使用驱动接口连接一个具体的数据库,读取该库中所有表信息。对于每个表获取所有列信息。对于每个列信息,记录列名称并采样一个或几个字段值进行数据分级分类和敏感数据识别。
4 结语
本文在实现了正则表达式、关键词识别的基础上推出了语义分析识别。可以通过pyhanlp 的语义识别技术进行姓名、地址、公司名称的无特征值中文信息识别。本文通过配置表的方法实现了正则表达式、关键字匹配的识别方式动态增加。同时本文采用多线程技术,解决了大量数据库检查的并行问题。在32G 内存、2coreCPU的一台Windows 主机。可以在一周内完成上千数据库实例的检查。在数据库配置信息存储方面,本文使用了自研加密技术。
猜你喜欢
上海电机学院学报(2022年4期)2022-08-29 10:59:02
黑龙江省人民政府公报(2022年3期)2022-06-01 06:16:16
华人时刊(2022年1期)2022-04-26 13:39:28
网络安全和信息化(2020年6期)2020-06-20 13:02:06
动漫界·幼教365(大班)(2019年10期)2019-10-28 01:54:09
周口师范学院学报(2019年5期)2019-10-16 08:48:52
网络安全和信息化(2018年12期)2018-12-24 03:25:14
计算机时代(2018年2期)2018-02-27 21:57:09
知识经济·中国直销(2017年12期)2018-01-03 08:21:06
智能计算机与应用(2011年4期)2012-05-15 02:24:18
