
安防监控中的安全帽检测方法
2021-11-03 06:43:40吴卫红
电子技术与软件工程 2021年18期
吴卫红
(衢州市宇创数码科技有限公司 浙江省衢州市 324002)
在监控领域,安全帽作为一种有效的防护工具,已应用于各类生产现场,但由于监督和审核不到位的原因,不戴安全帽造成的事故时有发生。因此,实现头盔佩戴检测对于保护生产现场员工的生命安全具有重要意义。
近年来,目标检测算法已成为计算机视觉研究领域的一个重要研究热点。基于深度学习的目标检测方法有两种类型:一种是基于候选区域的二阶段目标检测算法如Faster RCNN 等[1],首先生成候选区域,然后对候选区域进行分类和回归操作;另一个是基于一阶段的方法,如YOLO v3[2]和SSD[3],它只使用一个CNN 网络直接预测不同目标的位置,与Faster RCNN 算法相比,YOLO 可以实现实时检测速度,但精度相对较低。
张等[4]使用 Faster RCNN 对安全帽进行识别,获得了较高精度,但在实时目标检测上,由于速度较慢,并不十分适合,为了能良好地应用在实时检测上,王等[5]改进了GIOU 计算方法,通过结合YOLOv3 对安全帽进行检测,在原来基础上提高了2.07%的精度。施等[6]在YOLOv3 中添加特征金字塔进行多尺度的特征提取,获得不同尺度的特征图,以此实现安全帽的检测,取得了很好的结果, Huang 等[7]针对安全头盔的检测,在YOLO v3 上进行改进,与原始算法相比,FPS 增加了3f/s。
深度残差网络(ResNet)[8]是何凯明团队提出的一种卷积神经网络,该网络赢得了当年图像分类的第1 名。ResNet 使用了残差单元,不但减少了参数数量,还增加了CNN 学习特征的能力,参数少,层数深和分类效果优秀等特点使得ResNet 成为常被使用的网络之一。
注意力机制可以将模型的不同部分赋予不同的权重,从而提取出更多关键的和更具区分性的信息,使模型具有更高的精度,它将空间或通道重要性引入由卷积神经网络 (CNN) 提取的特征图,这有助于关注感兴趣目标的特征属性。因此,应用注意力机制有助于通过抑制不必要的细节和增强有用的特征来提高 CNN 的表示能力。
Srinivas 等[9]提出了一种将自注意力机制融入ResNet50 的方法,并将其命名为BotNet50,在一些公开数据集的图像分类上取得很好的效果,但此法还并未在安全帽检测上有过应用。因此本文基于目前表现较好的YOLO v3 算法,采用BotNet50 进行特征提取,同时在构建的安全帽数据集上进行训练,所获得的模型能有效地进行检测和识别。
1 算法结构
YOLO 将区域建议网络(RPN)分支和分类阶段划分为一个网络,具有更简洁的体系结构、高计算速度和更好的计算能力,使其成为实时检测的真正意义。YOLO 模型直接使用单个前馈网络预测边界框及其相应的类,并与之前基于在两阶段中执行检测的检测器进行比较。YOLOv2 是YOLO 的第二个版本,其目的是显著提高精度,同时使其更快。引入YOLOv2 的检测锚的想法受到了faster rcnn 的启发。锚提高检测精度,简化问题,简化网络的学习过程。同时,将批归一化添加到卷积层中,提高了精度。与YOLO 相比,YOLOv2 显著改善了定位精度和召回率。YOLOv3 成为了在YOLO和YOLOv2 上更为先进的目标检测版本。YOLOv3 使用多标签分类,对每个标签使用二进制交叉熵损失,而不是在计算分类损失时使用均方误差,YOLOv3 预测了三个不同尺度上的物体,使用逻辑回归每个边界框的分数。
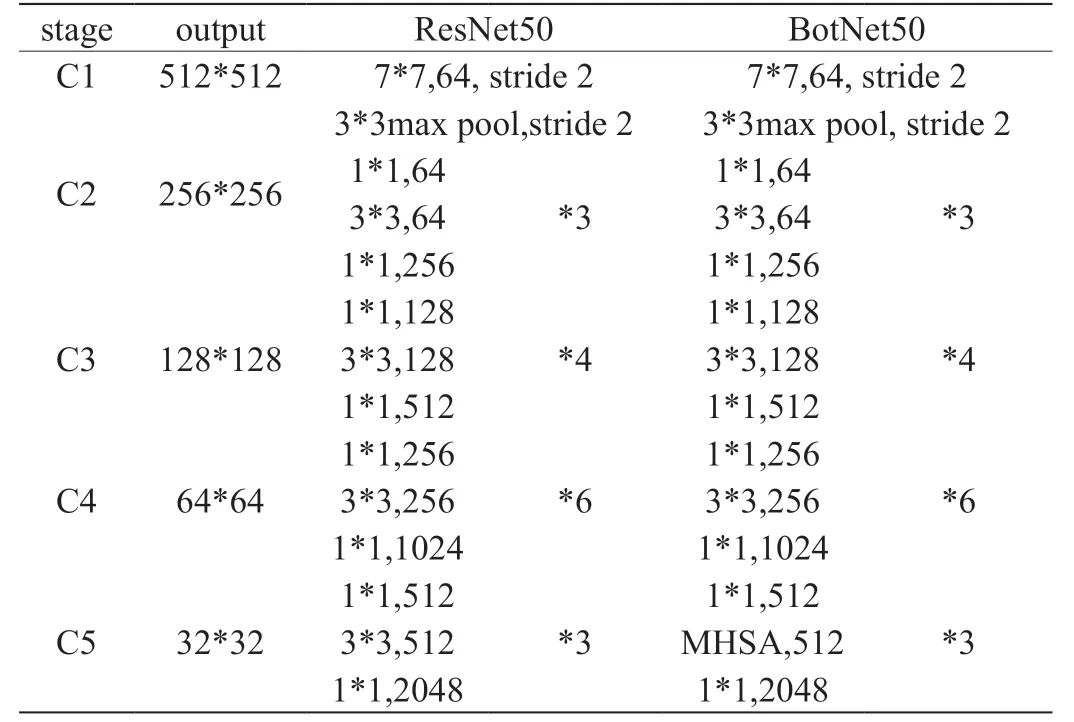
表1:BotNet50 网络结构

表2:设备信息
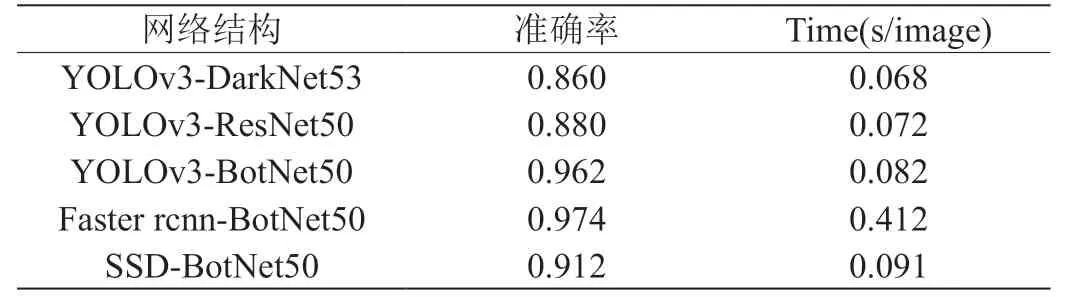
表3:不同网络下的准确率
本文使用了一种基于YOLOv3-BotNet50 的检测模型, 用ResNet50 替换了Darknet53 模型,并将ResNet50 中最后三个瓶颈模块用全局自注意力替换空间卷积,形成了新的ResNet50-attention模型,具体的如表1 所示。
从表1 中,可以得知,修改后的ResNet50 仅仅使用MHSA 替换卷积层,一个ResNet50 通常包括[c2,c3,c4,c5]阶段,它们对应了的步长为[4,8,16,32],并由多个瓶颈块与残余的连接器组成。MHAS[10]由Vaswani 等提出,由图1 表示。
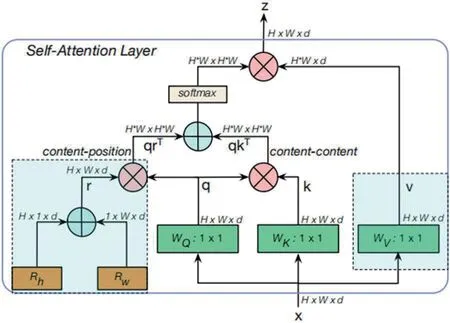
图1:MHSA 结构
如图1 所示,自注意力机制在二维特征图上执行, 相对的位置编码高度和宽度分别由Rh 和Rw 表示;注意力对数(attention logits)表示为qkT+qrT,其中,q,r,t分别表示查询(query),键值(key),位置编码(position encodings),⊕和⊗表示矩阵中元素的加法和乘法,1×1 表示进行逐点卷积(pointwise convolution);H,W,d 分别表示高度,宽度和深度。
2 实验结果
本文使用自制的实际场景下的数据集,利用监控设备处采集图像,共计432 张锈蚀图像,按3:1 的比例划分为训练集和测试集,并利用LabelImg 标注软件对数据集进行标定,然后按照 COCO 格式建立标准的数据集,在实验时,随机划分多次取平均值。使用的评价指标采用COCO 数据集的评价指标,即平均准确率(Average Precision,AP)。
本文实验使用的开发平台为Ubuntu 16.0,平台配置见表2 所列。
实验中的Batchsize 设置为1。梯度的优化算法为Adagrad,初始的学习率为0.005,之后在训练到40000 次时学习率衰减为0.001。实验中的测试结果如表3 所示。
从表3 中可以发现,本文使用的YOLOv3-BotNet50 具有良好的性能,相比与faster rcnn,在准确率并未降低太多时就降低了约80%的检测时间,最终也达到了96.2%的准确率,能很好地用于实际场景中的安全帽检测。
图2 展示了实际场景中的效果,从中可以发现,尽管出现了重叠区域,但仍然能够较好地被检测出来。

图2:检测效果图
3 结论
本文针对变电站安全帽检测场景,提出一种改进后的YOLOv3检测算法,该方法通过结合yolov3 本身的特性,能够满足多尺度场景下的目标检测,引入注意力机制,从而使得在重要位置的特征提取更加有效,使用从正常环境条件下获得的安全帽数据集能够最大程度的满足度学习的测试与训练场景的相对关系,经过实验发现,改进后的模型在识别效果上超过了原始的模型。在以后将使用更加优秀的网络结构,解决其他复杂场景中的安全帽检测。
猜你喜欢
星星·诗歌原创(2023年12期)2024-01-06 08:24:53
机电安全(2022年4期)2022-08-27 01:59:42
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电视技术(2014年19期)2014-03-11 15:38:20
华东理工大学学报(自然科学版)(2014年3期)2014-02-27 13:49:03
