
基于深度语义分割的FY-2E遥感影像云检测方法
2021-11-02 03:08:02高昂肖萌唐世浩姜灵峰咸迪郑伟
气象科技 2021年5期
高昂 肖萌 唐世浩 姜灵峰 咸迪 郑伟
(国家卫星气象中心, 北京 100081)
引言
风云二号(FY-2)气象卫星是我国第一代地球同步轨道气象卫星,自1997年发射FY-2A以来到2018年FY-2H发射成功,当前该系列卫星所有批次已全部发射共计8颗[1],现余3颗业务运行并计划由新一代静止气象卫星风云四号逐步取代。而依托FY-2卫星地面应用系统工程建设,我国于2004年建成了功能完善的天地一体化卫星遥感数据共享系统[2],已积累了十余年静止气象卫星数据并向国内外用户提供数据服务。FY-2卫星数据观测频次高、覆盖范围广,为我国的气候变化、生态环境变化等科学研究提供了宝贵的历史资料[3]。
FY-2资料可有效弥补地面云覆盖观测时空分辨率的不足,定性及定量云基础参量的观测(检测)结果对提供未来天气变化趋势的依据有着十分重要的意义[4]。FY-2云检测结果是形成各类定量遥感产品的基础,无论是以云图为基础的天气、气候分析还是以去云为前提的各类大气和地表参数反演,都需要对遥感影像中的云进行准确识别。一些研究表明FY-2的云检测误差较大,裔传祥等[5]发现相同空间内高分卫星云覆盖率为100%时,FY-2E和FY-2G的云检测结果判识为有云的比例分别为44.98%和40.46%,且无法将碎云表现出来;李娅等[6]发现FY-2G卫星观测云产品较地面观测偏低,基于云检测结果的云覆盖率产品与地面人工观测一致率平均为37.93%,认为卫星观测不能完全替代地面云量观测。刘炼烨等[7]发现,受云检测精度限制,云覆盖率产品在实况多云时一致性较低。云在时间和空间尺度上的不确定性,导致了卫星云图特征千变万化[8],因此云检测始终是气象卫星遥感研究和定量应用的重点和难点,对提高云的自动化观测水平和精度,实现海量卫星历史资料的再处理具有重要意义。
云检测的方法多样,国内外的研究众多,现有的遥感影像云检测方法主要分为利用云与地物多光谱特性差异的物理方法、空间纹理检测方法、基于特征提取的模式识别检测方法以及运用多种方法对云检测效果进行优化的综合优化方法[9]。而云像元的自动提取技术绝大多数都采用多特征(单通道或通道组合)阈值的思路[10-11],即将目标像元不同通道(组合)的亮度温度(简称亮温)、亮度温度差(简称亮温差)以及反射率与设定的阈值比较,来判识该像元是否被云污染。Alan提出的自动动态阈值法[12]是一种易于实现,相对成熟的方法,众多研究都在此基础上针对不同卫星进行适应性改进或优化阈值提取方法[13-15],FY-2云检测采用了滑动窗和嵌套窗方法改进云检测动态阈值提取方法[16-18]。这类云检测算法需要大量的先验知识,依赖大量的人工判读和阈值参数调整,算法的精度往往受制于仪器的通道和空间分辨率,即便有更为精准的验证数据,对算法精度的提升也十分有限。
随着深度学习技术在计算机视觉领域的开疆拓土,图像分类、物体识别和语义分割任务等都获得了重大突破。与传统机器学习需要依赖人工提取特征不同,深度学习可自动提取影像特征,并具有可迁移性的特点,为FY-2历史资料再处理提供了新的思路。近年来深度学习技术已开始用于分辨率较高、光谱通道较多的卫星遥感数据的云检测。瞿建华等[19]提出了基于全卷积神经网络的深度学习方法,徐启恒等[20]结合超像素和卷积神经网络对高分辨率遥感影像进行云检测,陈洋等[21]利用卷积神经网络提取影响特征,然后将影像特征输入支持向量机分类器进行分类,获得云检测结果。研究中发现了冰雪误识别、太阳耀斑处云边界轮廓不连续、雾霾以及沙尘误识别等问题。
本文根据FY-2E云检测的特点,针对性地设计了深度语义分割模型:为了能够聚合不同区域的云的上下文信息,增加了高层特征向低层的跳跃连接,并增加了编码过程中下采样次数,保证提取到足够多的特征信息;针对网络训练中正负样本严重失衡的问题,改进了损失函数,可以有效提取云的边界。最后,通过试验验证了本文方法的性能,并与其他算法进行了比较分析。
1 数据来源和预处理
1.1 数据来源
用深度学习训练模型及其优劣评估需要精度较高的云检测结果进行对比分析,根据参照来源分为3种方法:①通过专家目视分析;②与地面实况资料对比分析;③用公认比较准确的卫星云检测资料进行对比分析。第1种方法需要人工干预,效率较低,较难实现大规模数据评估,限制了自动化检测水平。第2种方法是将云分割结果与地面实况结果进行比较,由于地面观测结果多为单点离散分布,无论是目视观测、还是雷达或全天空成像仪的观测视角均与卫星遥感观测视角有较大差异,存在空间尺度转换不确定性[22-23],难以保障数据匹配精度。本文采用第3种方法,利用Aqua/MODIS的MYD35云检测产品进行对比分析。MYD35产品的空间分辨率高于FY-2E,且精度较高[24-26],适合作为深度学习的期望输出结果。
本文采用2010年1—12月的FY-2E/VISSR L1数据作为训练样本,标签样本采用同时次的Aqua/MODIS MYD35数据。辅助数据包括3类:①上述两类数据进行时空匹配所需的地理信息数据,即FY-2的标称投影经纬度查照表,以及Aqua/MODIS MYD03数据;②为便于结果比对和误差分析,收集并匹配了FY-2业务应用的多通道阈值云检测算法的对应产品;③部分典型样本选取相应的Aqua MODIS的L1B数据,用于生成真彩色合成遥感影像作为人工判识的辅助参考。
1.2 数据预处理
首先,将FY-2E L1中国区数据(空间分辨率为5 km)与MYD35云检测产品进行等经纬度投影转换,将得到的投影数据采用最邻近法进行匹配,得到空间误差小于5 km(1个像元),时间误差小于15 min 的配准数据。然后,参考MYD35数据的质量控制码剔除质量较差的样本。再次将配准数据切割为256×256大小的瓦片数据以提高训练效率。最后,采用留出法从瓦片数据中随机抽取60%样本作为训练数据集,20%样本作为验证数据集,剩余20%样本作为测试数据集,且数据集之间在地理位置上无任何重叠。
考虑FY-2E L1各通道有效值范围不同,采用离差标准化将不在通道有效值范围内的像素值映射到[0,1]范围内,并将其转换成图像像素值(值域为0~255)以符合模型输入图像数据的要求。数据预处理的结果见表1。

表1 数据预处理结果
2 深度语义分割网络搭建
2.1 网络结构
经典深度学习以卷积神经网络(Convolutional Neural Networks, CNN)[27,28]为代表的模型在图像分类中取得了巨大的成就。但是基于CNN的分类算法在进行卷积和池化过程中丢失了图像信息(比如分辨率和位置),所以无法提取出物体的具体轮廓,也无法指出每个像素具体属于哪个类别。而大气环境遥感监测要求精确识别出气象要素的轮廓,并给出像元级的分类,这就使得CNN分类算法无法直接应用于遥感影像的信息提取。语义分割网络是CNN的一个分支,主要由6种结构组成。
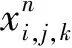
式中,H,W,C分别表示卷积核的长,宽,数量。
(2)激活函数。卷积层和滤波层一般通过激活函数连接[29], 而修正线性单元(rectified linear unit,ReLU)激活在深度卷积神经网络中被广泛采用。文献[30]提出了扩展型指数线性单元激活函数(Scaled Exponential Linear Unit,SELU),可以网络进行自归一化,有效克服梯度消失等问题。其公式为:
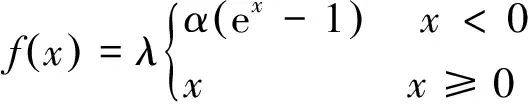
(3)池化。池化操作可以汇合低层特征信息,缩减计算数据量,扩大高层滤波器的感受野。给定大小为H×W×C的特征矩阵x, 采用大小为F×F的池化核(不填充池化,unpadded pooling),且池化步长S,则最大池化操作的输出为:
Fi,j=max(Gi,j)

(4)特征融合。将低层特征向量与相应高层特征向量拼接为新的张量,就能够融合高层的语义信息和低层的局部特征信息,从而实现准确而又精细的云特征提取。在本文提出的网络中,将每次上采样输出的特征图,与下采样部分输出的相同尺度的特征图进行通道串联。
(5)转置卷积。转置卷积相当于正常卷积的反向传播,具体步骤如下:①给定步长s,沿着步长的方向,在输入特征图中每个元素后面补s-1个0,得到扩充后的特征图x。②按照卷积padding规则[31],计算填充0的位置L及个数,将L上下和左右各自颠倒一下,再对x整体补0,得到x′。③将卷积核反转,即上下左右方向进行递序操作。④以x′作为输入,进行步长为s的卷积操作。
(6)Softmax。Softmax将多个神经元的输出值映射到0与1之间,可作为多分类预测的概率描述。给定输出层第i个神经元的输出值Zi,则Zi的概率值Si为:
式中,N为输出层的神经元个数,亦即分类数。
与经典CNN对整幅图像进行分类标记不同,语义分割网络是将输入图像中的每个像素分配一个语义类别,以得到像素化的密集分类。随着深度学习技术在计算机视觉领域的开疆拓土,图像分类、物体识别和语义分割任务等都获得了重大突破[32-34]。但是云目标是流体,呈纤维状分布的不规则结构,其细节信息丰富,且语义信息较为简单。这样的特点对分割网络的细节特征提取能力提出了较高要求。本文针对云像元提取问题的特殊性,设计了网络结构相对较深的语义分割(Deep Semantic Segmentation,DSS)网络,其结构如图 1所示。
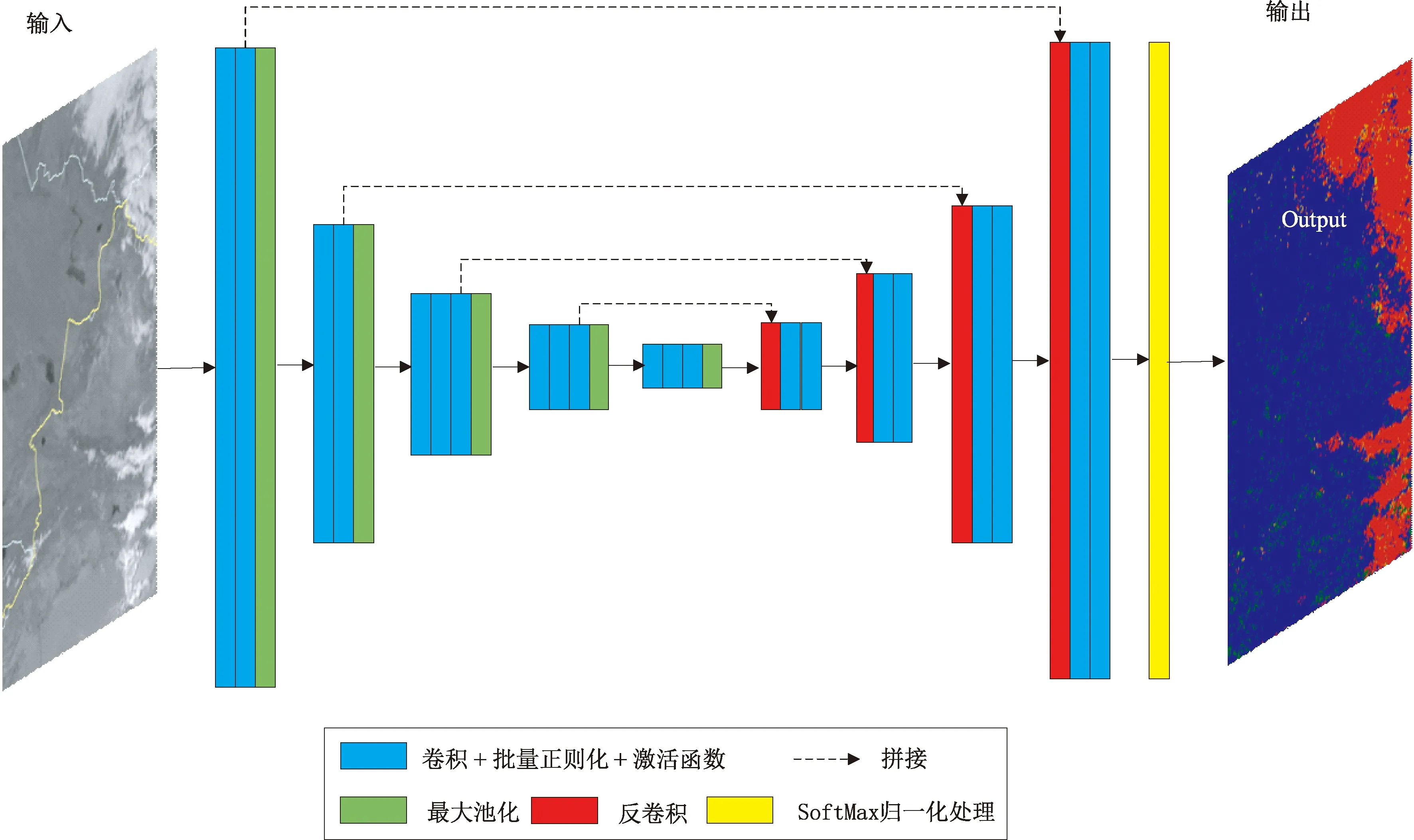
图1 网络结构
DSS网络由编码结构和解码结构组成。其中,编码结构遵循典型的卷积网络结构,其由两个重复的3×3卷积核(填充卷积,padded convolution)组成,且均使用修正线性单元(rectified linear unit,ReLU)激活函数和一个用于下采样(downsample)的步长为2的2×2最大池化操作,以及在每一个下采样的步骤中,特征通道数量都加倍。在解码结构中,每一步都包含对特征图进行上采样(upsample);然后用2×2的卷积核进行转置卷积运算(transpose convolution),用于恢复一半的特征空间分辨率,并减少一半的特征通道数量;接着级联编码结构中相应层输出的特征图;再用两个3×3的卷积核进行卷积运算,且均使用ReLU激活函数,将特征图映射到256×256×4大小的特征图,即每个云像元对应4个分类的特征值。由于在每次卷积操作中,边界像素存在缺失问题,因此有必要对特征图进行裁剪。在最后一层,利用1×1的卷积核进行卷积运算,将特征向量映射成为每个像素的概率向量,其大小为256×256×4,通过选取每个像素所对应的概率向量中最大值所在的位置,得到像素级的分类结果。
2.2 损失函数的改进
云检测是一个四分类问题:有云,晴空,疑似有云,疑似晴空,样本中会存在大量的简单样本,且都是负样本(有云和晴空样本)。如果用交叉熵损失函数计算损失值,简单负样本会对损失值起主要贡献作用,会主导梯度的更新方向。 在云图中,疑似有云和疑似晴空的特征一般位于有云和晴空的过渡地带。由于网络学习不到复杂正样本(疑似有云和疑似晴空样本)的信息,导致云的边缘很难区分。在标准交叉熵损失函数的基础上,文献[35]提出的focal loss算法可以解决正负样本不均衡,以及区分简单与复杂样本的问题。本文针对云检测的复杂性,给定预测值y′∈[10-5, 1-10-5]及其真实标签y,提出的改进算法为:
式中,wa=α(1-y′)γy,wb=(1-α)(y′)γ(1-y),其中,γ用来减少易分样本的损失,使得模型更关注于困难样本,α用来平衡正负样本的数量比例不均。
3 模型训练
3.1 超参数设置
超参数是在模型训练之前设置的参数,而不是通过训练得到的参数。通常情况下,需要人工对超参数进行优化,选择一组最优超参数可以提高模型训练的性能和效果。本文提出的DSS网络模型同样需要设置训练样本大小、批次大小、迭代次数、学习率、优化器以及损失函数等超参数,具体设置见表2。

表2 超参数设置
3.2 模型调优
神经网络中的参数(权重和偏置)是实现分类问题的重要部分,设置参数的过程就是训练模型的过程,只有经过有效训练的模型才可以真正检测云像元。在CNN优化算法中,最常用的方法是反向传播算法(BP,backpropagation)[36],BP算法基于梯度下降(gradient descent)策略,以目标的负梯度方向对参数进行调整。
本文基于BP算法训练DSS网络模型。如图 2所示,在每次迭代训练的开始,首先选取一个批次的训练样本。然后,将训练样本输入到语义分割模型(前向传播算法)中得到一个批次的预测结果。再次,基于改进的focal_loss方法计算预测值和真实值之间的损失值loss。最后,使用BP算法的扩展——Adam算法[37]对loss进行优化,并根据loss梯度的反方向更新模型参数。该训练过程迭代进行,直到达到某些停止条件为止,例如loss已经达到很小的值,或训练轮数已达到上限。

图2 训练流程
4 试验结果与分析
4.1 模型性能分析
经过多轮训练,DSS模型在评估数据集上得到的结果趋向稳定,利用该评估精度的模型,对预测训练集的样本进行预测,得到预测结果。从表 3可以看出,该模型在评估集和检测集上没有显著差异,说明模型的稳定性较好,未出现明显过拟合现象。其中,模型对晴空和有云的分类能力较好,但疑似晴空和疑似有云的分类能力较差。分析其原因是4类样本所占比例不均衡,疑似晴空和疑似有云的样本数量显著少于晴空和有云的样本数量(4类分布占总体比例分别为29%,7%,6%,58%);另外FY2E的VISSR仪器通道与Aqua MODIS云检测所用的通道有显著不同,VISSR仅有的5个通道无法完全反映MODIS云检测的分类机理。

表3 定量评估结果
4.2 与其他方法对比
为进一步分析和评估DSS云检测模型的效果,将测试数据集的预测结果和FY-2E业务云检测结果分别与Aqua MODIS的云检测结果进行比对,使用机器学习领域通用的评估方法计算准确率,即检测正确的样本数除以所有的样本数。由于FY-2E缺乏独立的云检测数据集,因此通过FY-2E CLC云分类产品进行转换,将晴空海面和晴空陆地作为“晴空”分类,其余作为有云分类(表 4)。FY-2E缺乏疑似晴空和疑似有云的分类,为便于比较,利用两种方法计算准确率:
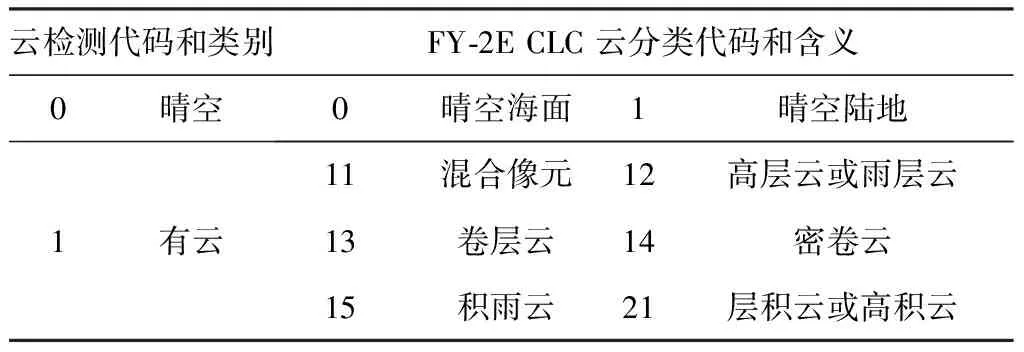
表4 FY-2E CLC云分类产品与云检测类别关系
式中,Ai表示混合矩阵中(表 5)的行序号,Xi表示混合矩阵中的列序号(X分为M和C类),例如A0M0表示Aqua MODIS为晴空且DSS模型也为晴空的像素数量,A0C3表示Aqua MODIS为晴空且FY2E CLC为有云的情况。Yacc1为忽略MODIS疑似晴空和疑似有云的像素计算的准确率,对DSS模型更有利;Yacc2将疑似晴空和疑似有云合并仅晴空和有云类,转化为二分类计算的准确率,对现有阈值方法分类更有利;Yacc0为表 3中四分类的像素准确率。
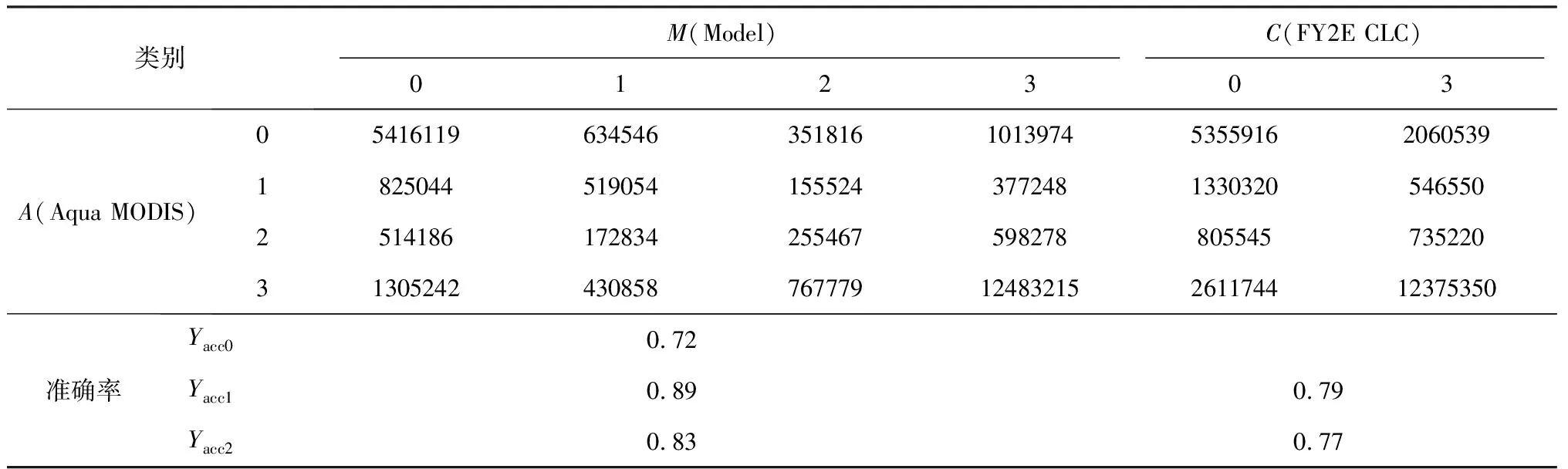
表5 像素匹配混淆矩阵与准确率计算
根据统计结果,DSS模型的云检测的准确率比现有FY-2E的云检测结果总体提升6%以上。对每个样本计算准确率,并比较DSS模型与FY-2E CLC云检测像素准确率的偏差(图3),可以看出DSS模型的云检测准确率在大部分样本中高于FY2E CLC的云检测准确率(ΔYacc1和ΔYacc2大于0占比分别为91%和81%)。准确率一般用来评估模型的全局准确程度,特别当正负样本不均衡的情况下,无法全面评价一个模型性能。所以本文还计算了Kappa系数[38]用以衡量模型分类的精度(表3)。
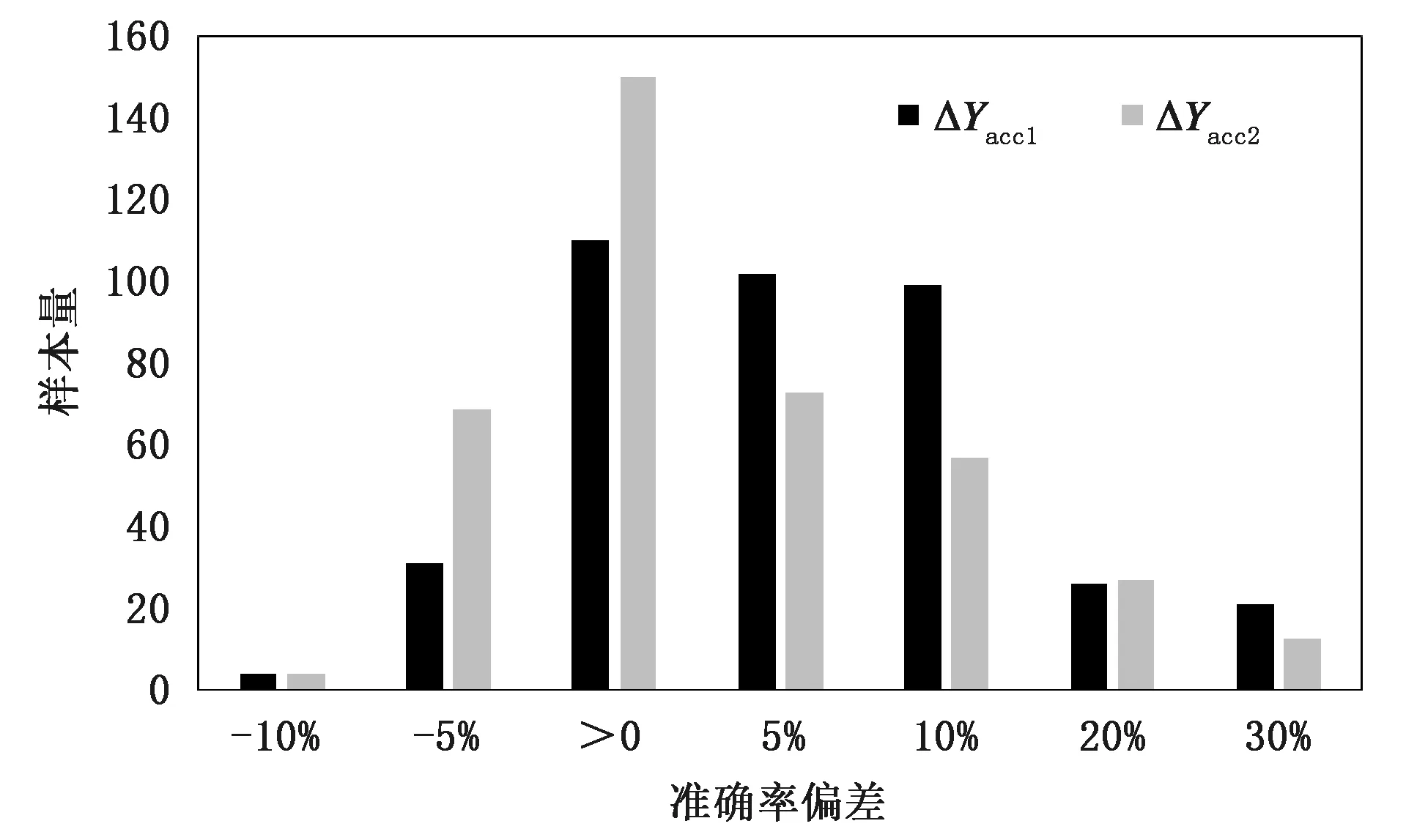
图3 DSS模型与FY2E CLC云检测准确率偏差
4.3 样例误差分析
选取部分典型样本(图4)进行误差分析,将DSS模型的准确率与FY-2E CLC算法的准确率进行比较(表6)。样本1和2的结果表明DSS模型对于目视可见的云判断较为准确,对于碎积云等细节识别能力提升较为显著,由于这些区域占比较少对像素准确率贡献小;FY-2E CLC算法多判或漏判区域较多,部分边缘明显的云区也无法准确识别。此外,在对比中发现FY-2E CLC算法的混合像元分类(见FY-2E CLC黄色区域)在实际的云与晴空交界处较多,可为后续改进多通道阈值算法提供借鉴。

图4 云检测样本分析(云检测标签中0~3颜色分别代表晴空、疑似晴空、疑似有云、有云)
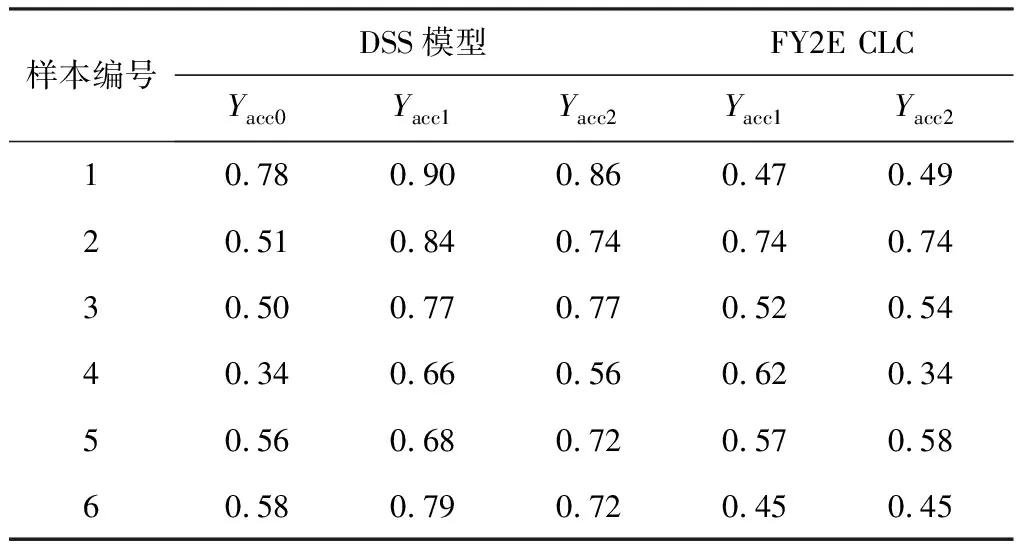
表6 样本云检测准确率比较
从样本3~6可以看出,一些样本的准确率相对偏低,特别是MODIS将薄云、雾霾、沙尘等对晴空地物遥感有影响的像元均判识为有云,对积雪区域有云判识偏多,而DSS模型则倾向于将该类像元判定为其他类别,FY-2E CLC在这些复杂情况下判识表现较差。可能存在两方面原因:一是VISSR仪器缺少对高层卷云敏感的1.375 μ,对积雪、气溶胶敏感的1.64 μ等光谱通道,光谱通道数量和响应敏感性都远远低于MODIS,对需要更多光谱信息才能做出准确判识的情况识别能力较差;二是由于此类样本量远远少于常规的云类别,导致模型训练不充分,因此对这些少数情况还未找到更有效的特征进行识别。
此外,由于MODIS在云检测中存对薄云判别标准不同(如样本4与样本6海上云区对比),以及对积雪(样本5 圆圈所示)甚至入海口泥沙(样本6中箭头所示)误判为有云的可能性,说明标签数据集自身存在一定比例的不良数据,这对于模型的训练和评估会产生一定影响。在训练模型时也应考虑其影响,不能一味追求准确率等指标的提升,以防止模型训练过拟合。从另一方面也体现出大数据的优势所在,DSS模型对错误标记的样本存在一定的容错机制,在大部分样本标签正确的前提下,少量错误标签对模型训练的影响较小,有利于降低数据预处理的成本。
5 结论与讨论
本文针对FY-2历史资料再处理的特点,设计了基于深度学习语义分割(DSS)的云检测模型,并进行了云检测算法的评估和误差分析。
(1)DSS模型充分利用现有精度更好的云检测产品,无需人工设计分类特征,可实现快速自动云检测分类,由于利用了MODIS作为标签,实现了云检测的四分类,更易与风云三号和风云四号及其他国外卫星的云检测分类保持一致。
(2)针对模型训练中正(疑似晴空和疑似有云)负(晴空和有云)样本严重失衡的问题,改进了损失函数,实现少量正样本有效赋权,可以更好地提取云的边界。
(3)DSS模型仅通过FY-2E VISSR的5个5 km通道信息,就能够达到MODIS四分类精度的75%左右,Kappa系数达到0.53左右; 判识准确率总体较多通道阈值法提升6%~10%,部分样本可显著提升20%以上,特别是对于破碎云、云与晴空边界的识别较多通道阈值法有显著优势。
(4)现有模型可通过提升训练样本精度和增加训练样本种类和数量,进一步提升精度和适应性:①对于疑似有云和疑似晴空的过渡类别的准确率还有待提升。由于在过渡类别主要处在云边界区域,从1~5 km的尺度变换会导致混合像元被判为同一类。
使用最临近法在5 km像元的中心区域判定比较准确。使用众数法采样,可能会导致过渡类别的进一步减少,经测试二者在过渡类别的差异约为1%。未来需要细化重采样策略,以提升云边界、破碎云的检测精度。②FY-2E为静止卫星,每小时有一幅全圆盘数据,其时间分辨率远高于Aqua卫星的每日两次,采用现有训练样本无法覆盖所有静止卫星观测时次,未来考虑进扩充精度较高的其他云检测产品,扩展模型的时间适应性。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小学阅读指南·教研版(2023年10期)2023-10-19 14:14:30
车主之友(2023年2期)2023-05-22 02:51:24
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
读友·少年文学(清雅版)(2019年1期)2019-05-09 02:35:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
