
基于数据挖掘的药学教育资源库录入信息量的控制
2021-11-01 06:29陈国有程怀志苏红朱江刘金成吕鹏举
微型电脑应用 2021年10期
陈国有, 程怀志, 苏红, 朱江, 刘金成, 吕鹏举
(1.哈尔滨医科大学大庆分校 药学院, 黑龙江 大庆 163319; 2.哈尔滨医科大学大庆分校 人事处,黑龙江 大庆 163319; 3.大庆医学高等专科学校 药学系, 黑龙江 大庆 163319;4.哈尔滨医科大学大庆分校 信息与技术学系, 黑龙江 大庆 163319;5.哈尔滨医科大学大庆分校 教务处, 黑龙江 大庆 163319)
0 引言
随着物联网技术的发展,越来越多的领域逐渐走向网络化与线上资源开发的发展道路,应用互联网技术实现了资源共享与同步利用。随着慕课类型的线上学习模式大规模增长,线上的学习资源储备已经成为未来互联网技术发展的重要内容,对外的数据挖掘资源输出质量总是良莠不齐,需要得到精确的控制才能对数据进行应用,尤其针对药学教育资源的录用,需要进行相对精确地分析[1-2]。
本文将研究基于数据挖掘的药学教育资源库录入信息量自动控制技术,数据挖掘技术下的药学资源开发能够为教育资源的获取带来巨大的后备能源。但是数据挖掘量的过于突出会对整个资源库造成一定的信息输出负担,所以需要对资源库录入信息量进行自动控制,更加优质地获取药学教育资源。
1 基于数据挖掘的药学教育资源库录入信息量自动控制模型设计
随着数据库类型的不断更新,数据信息已经呈井喷式增长,如何能够获取与利用数据信息成为了当前研究的重要内容,数据挖掘技术能够从众多的数据信息中智能总结数据规律并进行提取,应用在大容量的数据库中完成数据库的填充任务,但是数据挖掘技术的核心为大数据量的保障功能与信息关联功能,只有对已知知识深度分解和关联才能更有效获取隐性知识,为数据库的管理者增加知识获取链接,促进更多信息的传递与发掘[3-4]。基于数据挖掘的药学教育资源库录入信息量自动控制过程如图1所示。
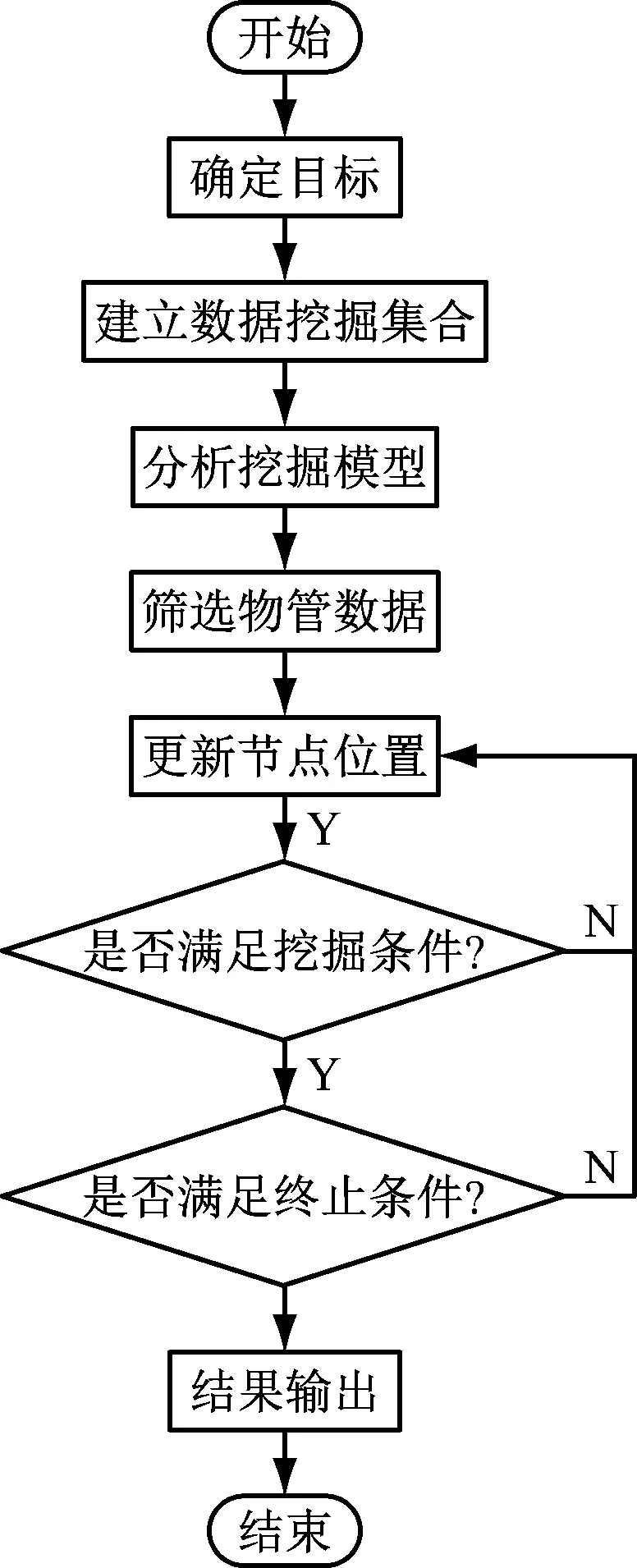
图1 药学教育资源库录入信息量自动控制过程
根据图1可知,数据挖掘技术的实现首先需要将已知数据作为挖掘目标,建立数据挖掘集合并从不同的数据源中集中数据关联内容;再对关联的已知数据进行杂质去除,自动筛选与挖掘主体无关的数据;在没有发现规律与内容可应用性的信息条件中将可挖掘信息转换为与挖掘主题相关的数据链,具体的转换技术需要参考该类型数据信息的逻辑原理;最终对数据进行挖掘,选择合适且具有针对性的数据设计挖掘模型,在模型中完成数据规律的寻找与录用,还可以对数据信息的基础知识进行组建,经过内容的核心处理,选取挖掘符合用户条件的数据,保障用户的基本数据挖掘任务完成[5-6]。
建立的数据挖掘模型如图2所示。
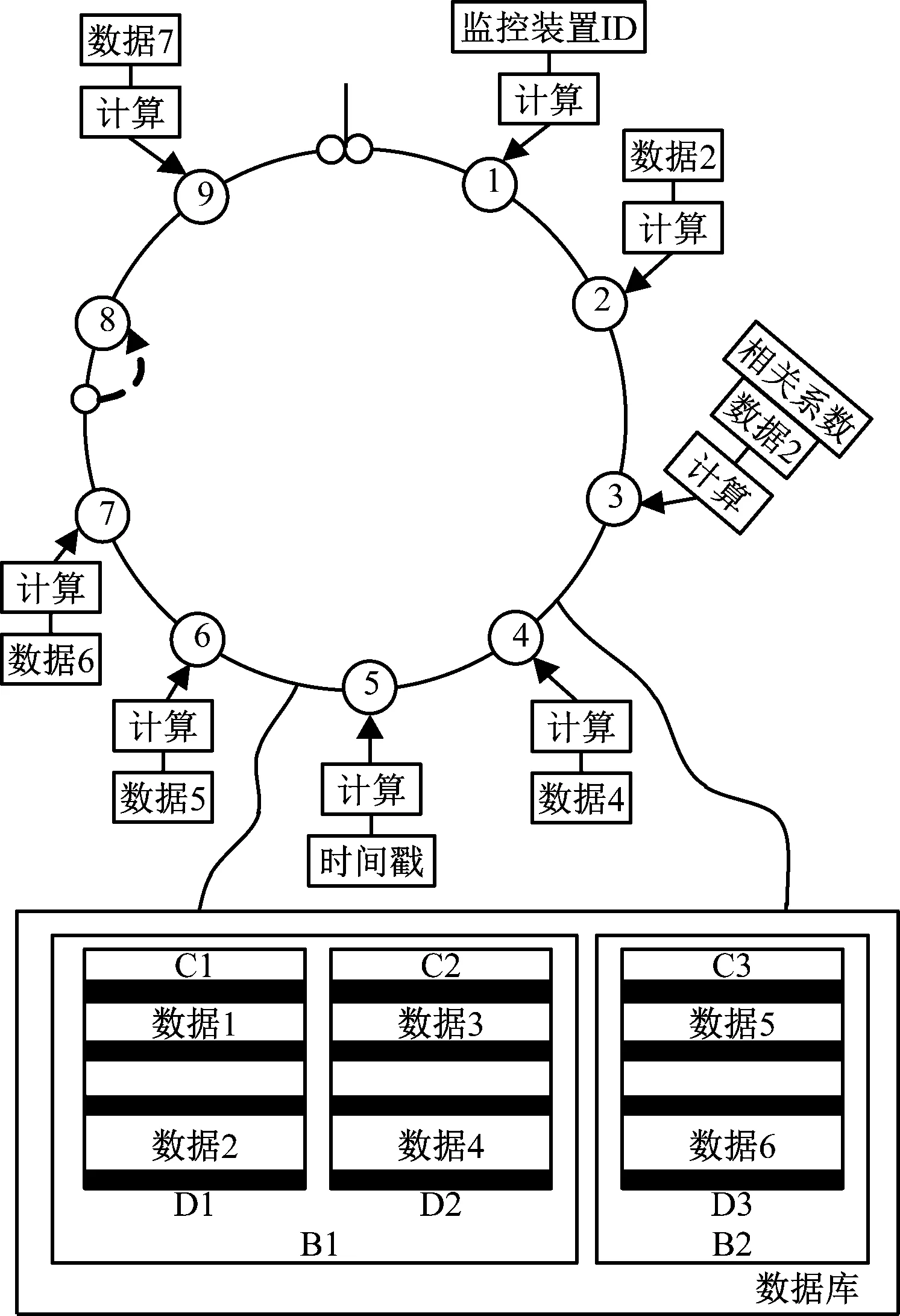
图2 数据挖掘模型
数据挖掘技术具有速度快、挖掘数据量庞大、数据挖掘精准度高等优势。应用此技术向相关数据库中传输内容的同时需要随时控制数据库的占用空间,以及数据挖掘质量,及时控制信息录入量保证数据库的可用率。
1.1 基于数据挖掘的药学教育资源库录入信息量阈值检测
在模型设计中需要对药学教育资源录入信息情况进行阈值设定,检测录入信息是否存在网络方面的隔阂或流量异常状态的存在,还要及时采集网络周围环境对药学教育资源录入信息内容的影响程度,避免外部流量对药学教育资源的更改。资源库对外的信息量引入基本参数需要依靠管理人员进行初步设定,在基本流量传输的基础上保障数据挖掘信息的安全性,设定的参数范围也可以根据药学资源的结构特征进行缩小与扩大[7]。阈值检测过程如图3所示。

图3 阈值检测过程
根据图3可知,当数据挖掘下的外部流量与模型内部网络接口的数据流量相统一时,此时的流量值为资源库录入的阈值,模型管理员能够在不进行数据过滤的情况下完成精准可靠的信息数据挖掘,药学教育资源还可以通过控制原始的资源数据与当前数据挖掘下的阈值信息进行对比控制,设定阈值以内的数据为可入库数据,阈值以外数据为不可入库数据[8]。
1.2 基于数据挖掘的药学教育资源库录入信息量识别
数据挖掘技术大多采用多种算法的联合数据开发方式,发展多个药学教育资源可开发点进行信息变量的关联,通过原始数据代表数据库中的隐性信息,优化录入信息的识别能力能够有效控制算法的关联计算条件与挖掘效率。
对药学资源库录入信息量的识别需要首先确定药学资源库内外数据条件的差异性,尽量减少不同属性的数据关联,进一步提升数据挖掘的方向精准度,本文尝试从算法的关联技术方面入手,建立算法识别体系,根据资源库内外的数据挖掘特征识别数据类型特征。在分析录入信息数据属性特征时可以参考网络数据中的基本参数,如数据挖掘行为时间、数据挖掘行为名称、数据挖掘行为主体等,对特征分析完成后的数据应用布尔型算法关联规则完成资源库录入识别程序,关联规则主要围绕行为主体能够按照行为路径进行资源库录入、行为时间能否决定行为主体的基本程序、行为名称能否更改行为时间内容等[9-10]。
1.3 基于数据挖掘的药学教育资源库录入信息量控制接口
本文采用TCP/IP网络数据传输协议作为资源库录入信息主要接口,此接口主要面对数据挖掘下的网络层,当数据挖掘后的数据从计算机中完成程序对接后便需要经过更高层的运输协议实现从主机到资源库的直接对接,负责处理接口端的网络层会根据IP地址对制定的数据传输目标进行数据选择录用,依靠路由器的高兼容性融合不同存在格式的数据包,逐级通过数据接口向资源库完成录入[11]。控制接口如图4所示。
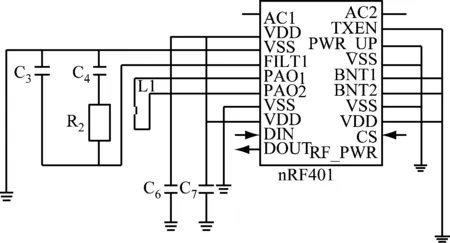
图4 控制接口
数据接口的端口能够为信息量的控制提供自动分配服务,对于不同结构的数据和接口需要采用不同的数据端完成信息量的分化,在协议中开通不同级别的信息传输通道,不断为数据挖掘下的药学资源进行待审核程序,直到数据进入接口中完成物理层的传送,经过数据格式更改与资源类别分化进入教育资源库的引用层。
2 基于数据挖掘的药学教育资源库录入信息量自动控制的实现
2.1 药学教育资源库录入信息量提取
基于数据挖掘的药学资源库录入信息量的提取需要在数据实现控制前完成,为药学教育资源库提供优质的录入资源,首选确定药学教育资源的网络检测范围,根据网络范围内的数据内容设定异常流量的识别与测定,要求录入的数据能够达到网络安全条件,在网络安全地址中计算不同数据挖掘下的数据录用前缀,规范由某个路由器纳入其管理范围,在路由器中安装有网络协议与通信协议,使药学教育资源库管理人员能够随时进行信息识别,在教育资源库彻底激活数据内容前完成信息量的精准提取。流量采集范围图如图5所示。
图5 流量采集范围图
药学教育资源库录入信息量的提取还需要经过网络设备的流量采集,计算待提取数据的字节数、数据端口、IP地址等信息,利用网络日志与信息行为进行数据提取前的预处理,必须访问教育资源库内的驱动程序并确定能否满足待提取数据量内容,若能满足挖掘数据的传输则建立驱动程序完成信息的提取,若不能满足挖掘数据的传输则终止信息提取的结构组建[12]。
2.2 检测药学教育资源库录入信息样式
挖掘数据下的药学教育资源库录入信息量样式决定能否完成资源的正常运用,由于数据挖掘技术自身没有信息结构样式识别功能,所以需要完成数据挖掘后对信息样式进行安全性能的评估。一般的信息样式分为具有漏洞风险与无漏洞风险,具有漏洞风险的信息样式又划分为漏洞编号、漏洞名称、严重程度等具体内容的分析识别,对漏洞样式的识别主要采用网络遗传免疫算法,在算法中引用已经发生过的漏洞信息作为基本神经元,在神经元确定的情况下引用数据挖掘下的信息样式,若神经元与新录用信息产生连接则证明此信息具有一定程度的漏洞,不能够应用在未来的药学教育中,若神经元不与信息产生连接则证明信息样式不存在漏洞问题,可以以安全身份用于未来的药学教育[13]。
2.3 基于数据挖掘的药学教育资源库录入信息量储存
数据挖掘下的药学教育资源库录用信息量较为庞大,在进行信息量储存时需要对原本的文件扩展,能够适用于大数据的结合,每个文件均需要对资源内的数据完成一次改写任务,应用目录生成的方式防止数据的重复性储存,对上传成功的数据及时进行影像处理,再分别应用高频数据储存方式、中频数据储存方式、低频数据储存方式保留挖掘数据中的副本,编辑储存代码节省数据读取步骤,建立数据的智能通道使挖掘数据能够通过中频储存通道中实现自主录用[14]。存储后的数据波形图如图6所示。
图6 存储后的数据波形图
3 实验研究
为了检测本文提出的基于数据挖掘的药学教育资源库录入信息量自动控制仿真方法的有效性,与传统方法进行对比,设定仿真实验。
本文选用的仿真平台为TOSSIM仿真平台,生成的能量模型为TRACE文件,生成的信息为DEBUG信息。实验参数如表1所示。

表1 实验参数
根据上述参数,选用本文提出的基于数据挖掘的药学教育资源库录入信息量自动控制仿真方法与传统的基于动态数据的药学教育资源库录入信息量自动控制仿真方法,基于小波计算的药学教育资源库录入信息量自动控制仿真方法进行对比实验,得到的录入时间实验结果如图7所示。
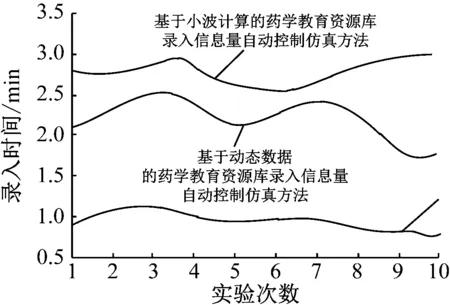
图7 录入时间实验结果
根据图7可知,本文提出的基于数据挖掘的药学教育资源库录入信息量自动控制仿真方法在10次实验中,花费的录入时间始终小于传统方法。本文提出的方法引入数据挖掘技术,能够在短时间内确定数据特点,筛选无用信息,提取有效信息。而传统方法由于不具备深入挖掘能力,所以需要进行多次分析,因此花费的录入时间过长。
录入准确率实验结果如表2所示。

表2 录入准确率实验结果
由表2可知,在10次实验中,本文提出的仿真方法录入准确率高于传统方法。本文提出的方法设定了数据库,通过对比数据库进行药学信息提取,因此准确率更高,而传统方法缺少比对工作,所以录入结果的准确率难以得到保障。
综上所述,本文提出的基于数据挖掘的药学教育资源库录入信息量自动控制仿真方法录入能力要优于传统方法,更适合于实际应用工作。
4 总结
本文主要研究数据挖掘技术后的药学教育资源库录入储存控制部分,对数据传输过程中的相关技术进行分析与设计,建立阈值体系规范教育资源库的录入标准,以模型的方式设计挖掘数据进入教育资源库的流程与方法,再设计挖掘数据的控制实现步骤体现本文应用方法的有效性。
猜你喜欢
房地产导刊(2022年1期)2022-02-28
武术研究(2021年2期)2021-03-29
西南交通大学学报(2018年5期)2018-11-08
通信电源技术(2018年3期)2018-06-26
知识文库(2018年13期)2018-05-14
电子制作(2017年13期)2017-12-15
电子制作(2017年10期)2017-04-18
中国教育技术装备(2016年11期)2016-12-01
新闻传播(2016年11期)2016-07-10
铁道通信信号(2016年12期)2016-06-01
