
复杂网络观点传播模型下的推荐系统评分预测
2021-10-28 07:50:52卞紫莺
软件导刊 2021年10期
艾 均,卞紫莺,苏 湛
0 引言
各种现实世界的系统都可以用复杂网络建模[1-3],然后通过复杂网络理论进行分析,包括生物系统[4]、社交网络[5-10]、语义分析[11]、互联网[12]、链路预测[13-15]、软件[16-18]等,甚至流行的推荐系统也可以用社交网络[19]或复杂的网络模型进行补充,以进行分析和改进[20-24]。
复杂网络理论为人们提供了多种有效工具以分析甚至控制复杂系统[25-29]。例如,中心性可用于衡量复杂系统中节点的相对重要性,并对网络中的个体进行定量排序[30-31]。社团检测可以发现在复杂系统中紧密耦合的小组,并有效地分组[4,32]。诸如中心性和社团发现之类的复杂网络分析方法可以帮助本研究更深入地了解复杂系统的特征。
具体而言,推荐系统也可以使用复杂的网络进行建模和分析,包括使用二部图模型进行评分预测[33],使用社交网络信任关系以提高推荐系统的准确性[34],以及对用户关系或物品之间的关系进行建模以构建用户—用户网络或物品网络,研究推荐系统中个体之间的关系[22]。
在推荐系统中,如果将用户和物品视为两种类型的节点,则将物品的用户评分视为链接,而评分分值是链接的权重。推荐算法或评分预测算法有效预测用户和商品之间的加权链接,假定指向链接权重较高的物品可能被用户偏爱,并向他们推荐这些物品。这样的算法不仅可以预测用户评分,还可以分析缺少数据的网络,并预测可能在网络演化中未来出现的链接[33]。
目前已有基于计算个体之间历史评分相似性矩阵进行预测或分析的方法[35]。例如,基于Pearson 系数的协同过滤(Collaborative Filtering,CF)通过衡量用户间共同评分以评估相似性[36-37];基于余弦系数的协同过滤使用余弦相似性代替皮尔逊相似性[37-38]。用户观点传播(User Opinion Spreading,UOS)方法结合CF 算法和用户观点传播过程使评分预测更精确[39]。
基于网络拓扑结构局部信息的共同邻居(Common Neighbor,CN)指标在较小时间复杂度下有较高的预测精度[40]。为了提高连边之间的分辨率,Adamic 和Adar 在此基础上提出了(Adamic-Adar,AA)指标[41],通过共同邻居的度突出节点对于共同邻居不同的重要性。Javari 等[42]使用了资源分配(Resource Allocation,RA)指标[43],该指标显示了对用户和物品双向网络中缺失链路的较好预估。物品全局配置文件扩展(Item Global Profile Expansion,IGPE)是一种推荐方法,它通过使用与用户已评分项相似的项来扩展用户评分文件[44]。Lemire 等[45]提出Slope One 算法,预先计算用户对两种商品评分的平均偏差。
为了进一步提高算法预测精度,本文在做各类算法实验时对用户观点传播算法进行着重研究。该算法假定用户观点在推荐系统的二部图模型中传播并且相互影响,相互影响的总和作为计算两个用户之间相似度的基础。但该算法有两个问题:首先,相似度计算结果分布太小(最大相似度可能小于0.03);其次,该算法需要太多的邻居才能获得最佳预测精度。第二个问题可能源于前者,由于不可能准确区分哪个用户更相似,因此需要通过更多相似邻居以获得最优预测结果。
1 相关工作
1.1 用户观点传播
如文献[39]所示,由于用户的偏好或习惯,他们对物品评分会有所不同,因此,式(1)用于标准化评分以抵消偏差。
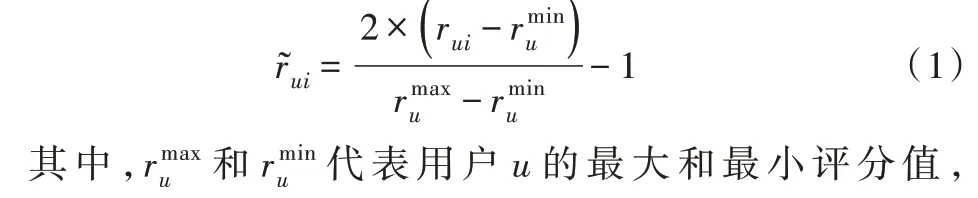
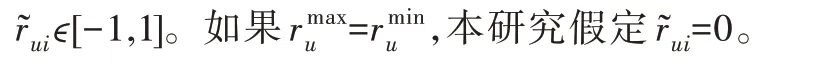
从理论上讲,如果两个用户的所有共同评分都相似,则这两个用户应该相似。在式(2)中,使用以下方法评估用户关系。
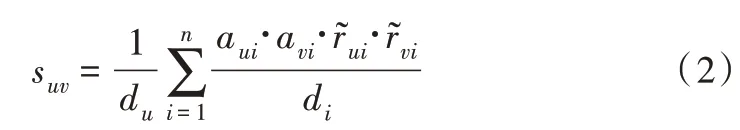
其中,di是物品i的度,du是用户u的度。ɑui是可以推断用户u是否对物品i进行了评分的值。如果用户u对物品i评分,则ɑui=1,否则,则ɑui=0。r~ui表示用户u对物品i执行的标准化评分结果。
评分预测可以通过文献[39]中给出的公式进行计算,本文引用了式(3)。

1.2 度中心性对推荐系统相似性网络的影响
在文献[24]的工作中,基于文献[22]的复杂网络建模方法,研究了物品度值在物品—物品复杂网络中推荐算法评分预测误差的影响,并发现物品度值所代表的受欢迎程度被高估了,这对评分预测的准确性产生了负面影响。因此,他们设计了抵消影响的方法。在此基础上,本文通过设计相似度计算方法,研究度中心性对预测准确性的影响在推荐系统的用户—用户复杂网络中是否同样有效。如果可能,本文将使用该方法进一步提高推荐系统评分预测准确性。
1.3 推荐系统相似性网络中的社团
对推荐系统的复杂网络建模研究可以进一步分析物品社团差异对评分预测的影响[20]。研究表明,在相似复杂网络中,同一社团的物品在预测过程中应具有更高的权重;相反,分布在不同社团中的物品应具有较低的权重。本文使用权重系数调整预测公式中不同邻居的权重。与预测目标在同一社团中邻居的权重增至1.3,不同社团中邻居的权重减小到0.7。各种算法实验表明,基于相似复杂网络中社团分布差异的加权可以有效地提高预测准确性。但他们没有使用这种方法检测用户观点传播(UOS)模型的特性。因此,本文结合这种方法对UOS 作进一步研究。
1.4 用户相似度与置信度
Su 等[21]进行了一项研究,他们发现用于计算相似性的评分数目对评分预测具有重要影响。该工作设计了如下置信系数(Confidence Coefficient)。
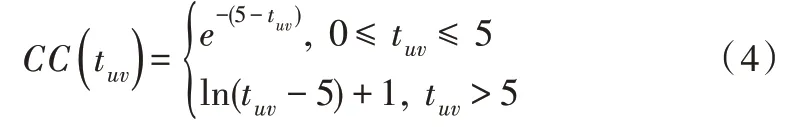
其中,tuv是用户u和v共同的评分数目。
该研究主要集中在设计一种新的相似性方法,同时考虑用户之间的评分差异和置信度系数。
2 复杂网络建模中观点传播的推荐系统评分预测
本研究基于置信度系数改进UOS 相似度,以解决UOS相似度总体较小的问题。因此,基于现有研究,可以设计如式(5)的相似性计算公式,该公式综合考虑评分偏好观点的传播,以及计算时使用的评分数量。
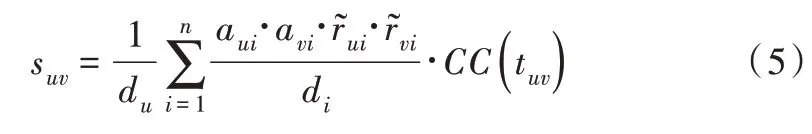
图1 显示了训练集中相似度值的分布情况(彩图扫OSID 码可见,下同)。两种类型的相似性等式包括用户观点传播(UOS)相似性和具有置信度系数的UOS 相似性(User Opinion Spreading-Confidence Coefficient,UOS-CC)。y轴是相似度值,x轴指示两种不同的方法,它们的形状宽度可以推断相似度的分布概率。图1 证实了UOS-CC 将UOS相似度的分布从0.03 增加到0.06,需要在实验中探索这种相似性分布变化的影响。
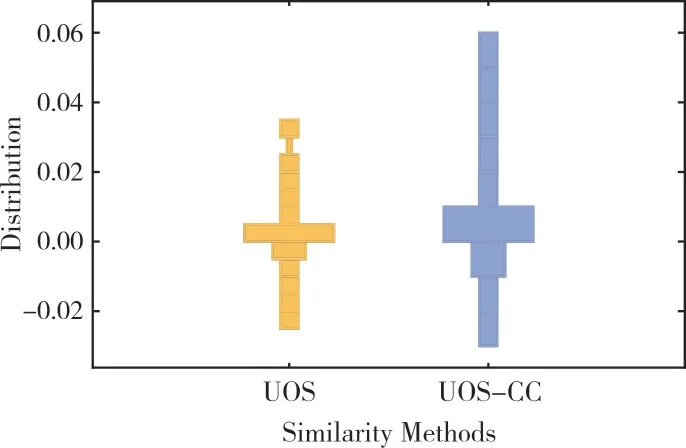
Fig.1 Distribution of similarity degree value in training set图1 训练集中相似度值分布
研究基于改进的UOS 相似性,对用户之间的关系进行复杂网络建模。通过删除低相似度的链接,将剩余的相似度作为用户之间链接的权重,并且将用户作为构建复杂网络模型的节点;然后基于该模型,计算用户节点的中心性及其社团差异;最后根据目标用户相似度选择目标用户的邻居集,并通过邻居评分、邻居度值、社团之间的差异以及邻居与用户之间改进的UOS 相似度预测目标用户评分。此过程可以总结如下:①基于置信系数改进相似性,并计算用户之间的相似性;②通过表示用户的n个节点和表示用户相似性的kn条链接的复杂网络建立推荐系统模型;③计算建模网络中节点的度值和社团;④根据改进的相似性结果,为每个目标用户选择一组邻居;⑤基于共同评分、邻居置信度的UOS 相似性、邻居的度值和邻居的社团差异预测目标用户评分。
当通过复杂网络对推荐系统进行建模时,关键问题是控制边的数目。由于节点数由用户数(n)决定,因此本文使用k操纵边的数目。为了防止相似度低的节点被孤立,先为每个节点保留具有最高正相似度的边。如果总共保留了nr条边,则在其余边中具有最高相似性的前kn=nr条边将进一步保留,使k=m/n在网络中保持不变。具有低相似性或负相似性的所有其它边将从网络中删除。
表1 列出了具有不同k值建模网络的详细特征,表中3C 是UOS-3C 的缩写。
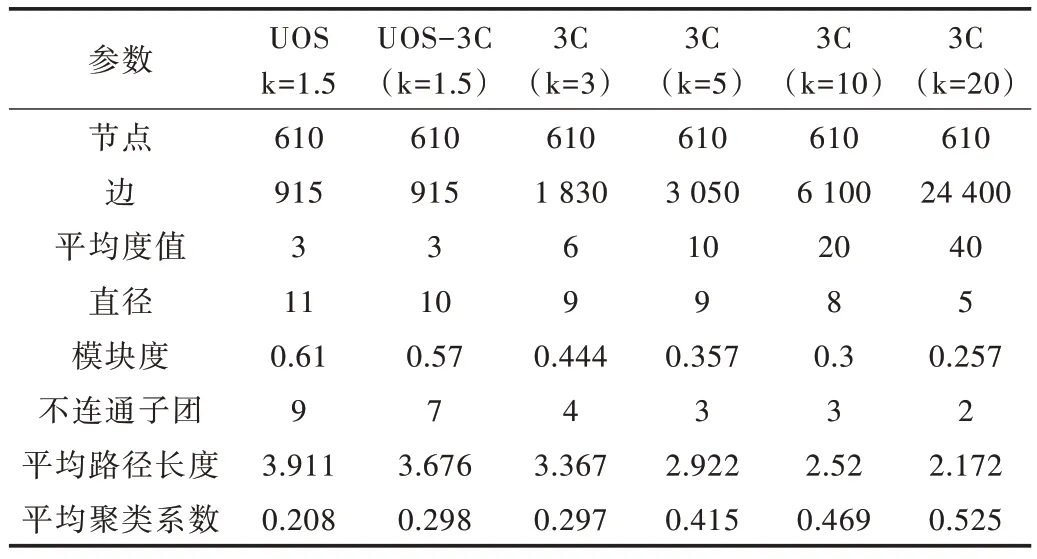
Table 1 Detailed characteristics of the modeling network with k as input表1 以k 为输入的建模网络详细特征
表1 中的结果显示了一种模式,随着k值和链路数量的增加,以及网络直径的持续减小,模块度持续下降,平均聚类系数增加,平均路径长度减小。即使在k增加到k=20后,平均聚类系数仍然不够高,这意味着该网络不是小世界网络,结果与采用其他相似方法(如Pearson 或Cosine)开展的实验不同。通常,基于Pearson 相似性和相同数据集的建模网络具有较高的平均聚类系数,并且当k≥10 时,平均路径长度较短(平均聚类系数可以大于0.74)。这种现象表明,由于系统中用户核心观点的传播,UOS 的相似性与其他相似性方法不同。
图2 通过训练集中的数据将建模的推荐系统显示为网络。节点代表用户,链接代表他们的相似性。节点颜色表示其社团的差异,节点大小表示其度值,边的宽度表示它们的相似程度。不同用户节点的度值在很大程度上是可变的,并且不同社团中的用户与社团中节点的联系更加紧密,这是本研究用度值和社团改进UOS 的原因所在。

Fig.2 UOS similarity network based on confidence coefficient(k=1.5)图2 基于置信系数的UOS 相似性网络(k=1.5)
在这样的网络中,用户度值表示用户的受欢迎程度,链接代表用户之间的相似性,因此网络中的高度值用户意味着他的口味或偏好是普遍的。
在某些情况下,用户的度值很重要,例如用户u有两个相似的用户v1和用户v2作为邻居,它们相似度相同,suv1=suv2=0.8,度值高的v1有多数偏好,度值低的v2有少数偏好,后一个用户v1应该根据文献[24]中已有研究进行优先级排序。
因此,本研究基于相似度方法等式(5)和UOS 预测公式(3),利用如式(6)预测方法分析对用户程度的影响。

其中,svu是用户v和u之间的相似性,是用户v给出的平均评分。该式选择了n个用户进行预测,而Degree*(v)是用户—用户复杂网络模型中用户v的归一化程度。
此外,本文还知道在预测中应该相应地考虑在同一社团或不同社团的节点[20]。本文通过式(7)进行预测。
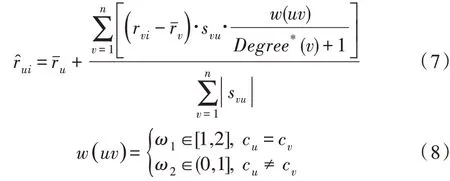
其中,w(uv)用于调整每对用户之间的权重;cu和cv分别表示用户u和用户v的社团,这些社团由社团发现算法标记[46]。
本研究同时考虑用户观点传播相似度和置信系数(Confidence Coefficient),节点在复杂网络模型中的度值(Degree Centrality),以及节点社团特征(Community)进行推荐系统评分预测,故将本文算法命名为UOS-3C。
3 实验设置
3.1 数据集与参数
为了测试所提出算法的性能,选择MovieLens 作为基准数据集。Movielens 有671 个用户和9 125 个电影,并且有105个评分(范围从0.5 到5)。
为了更精确地测试所提出的算法,将折十交叉验证应用于数据集。训练集随机分为10 个组。每组数据都被测试过,其余9 个组用于训练。测试中的任何算法都会根据其他9 组提供的信息预测每个组,其中该算法会选择ω个邻居(ω∈{1,2,3,4,5,…,19,20,25,30,…,150}),将多个实验取平均值以得出最终结果。
3.2 算法比较
由于目标方法主要集中在UOS 问题上,因此在下文中将使用UOS[39]进行比较。本文还基于文献[20]添加了模块化用户观点传播(MUOS),被标记为MUOS,并用于基于物品的评分预测。本文提议的方法缩写为UOS-3C,其中3C 表示置信系数、度中心性和社团差异。
3.3 评估标准
本研究选择两个度量标准衡量预测准确性,即平均绝对误差(MAE)和均方根误差(RMSE)[35]。通过将用户给出的实际评分与算法给出的预测评分进行比较,MAE 和RMSE 越小,算法越精确。RMSE 在求和之前预测误差平方,从而使大误差更加明显。
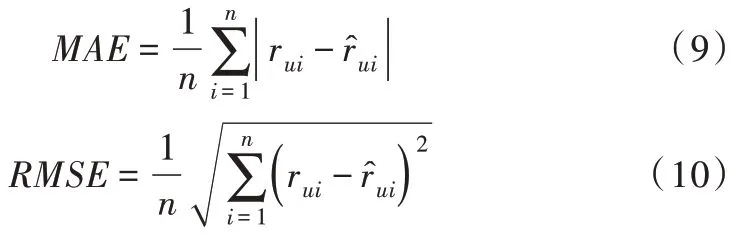
其中,测试集有n个用户对物品的评分,是预测评分,而rui是测试集中的真实评分。
4 实验结果
本文介绍了MAE 和RMSE 两种比较预测结果好坏的方法。比较不同k、ω1和ω2参数下 评分预测的MAE 和RMSE 结果,通过实验可以确定所提出方法的最合适参数。将本文方法与最近工作进行比较,以测试USO-3C 的有效性,如图3 和图4 所示。
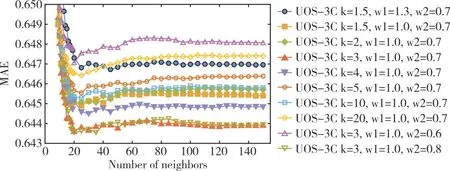
Fig.3 MAE results predicted by UOS-3C algorithm under different k、ω1 and ω2 parameters图3 UOS-3C 算法在不同的k、ω1 和ω2 参数下预测的MAE 结果
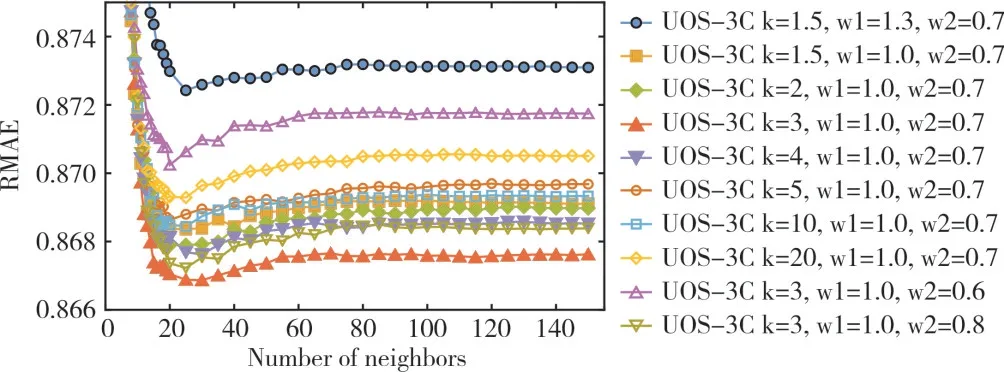
Fig.4 RMSE results predicted by UOS-3C algorithm under different k、ω1 and ω2 parameters图4 UOS-3C 算法在不同的k、ω1 和ω2 参数下预测的RMSE 结果
对数据集进行折十验证的实验证明了本文方法的有效性。实验结果表明,基于改进的UOS 相似度对推荐系统建模,根据用户节点的度中心性和社团差异可以稳步提高系统评分预测准确性,提高幅度为0.7%~5.5%,获得最好评分预测精度所需的邻居数从130 个减少到20 个(减少84%)。
图3 和图4 显示了在不同k、ω1和ω2参数下预测的MAE和RMSE 结果。可以看出,k=3,ω1=1.0,ω2=0.7 提供了最佳精度,增大或减小参数k都会增加预测总体误差。与ω2=0.6和ω2=0.8 相比,ω2=0.7 会使具有不同社团邻居的重要性降低30%,且准确性更高。
图5 和 图6 显示了由UOS、MUOS 与提出的UOS-3C 进行评分预测的MAE 和RMSE 结果。可以看出,对于MAE 和RMSE,k=3,ω1=1.0 和ω2=0.7 提供了最佳精度。与原始UOS模型相比,UOS-3C 将预测准确度平均提高了1.3%,最高5.5%,最低0.7%,MAE 的最佳值为0.8%,平均提高了1.2%。RMSE 分别为最高5.4%至最低0.8%,最佳1.0%。
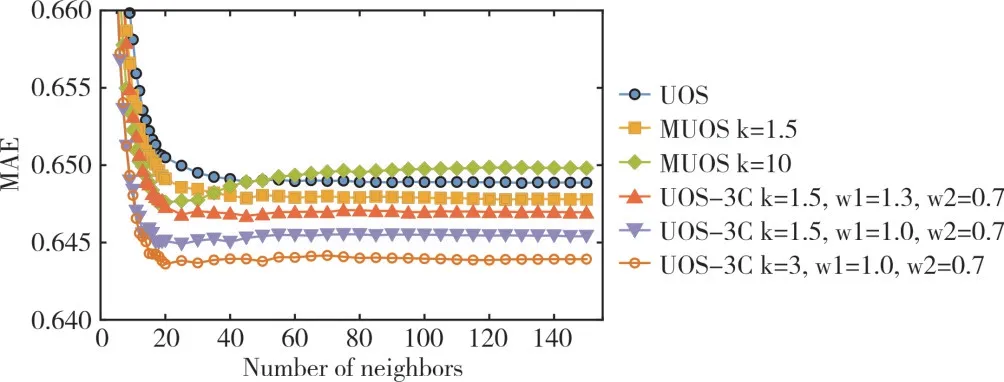
Fig.5 Results of MAE of UOS,MUOS and proposed UOS-3C algorithm in different neighbor numbers图5 UOS、MUOS 与UOS-3C 算法在不同邻居数目的MAE 结果
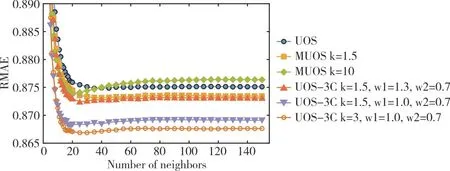
Fig.6 Results of RMSE of UOS,MUOS and proposed UOS-3C algorithm in different neighbor numbers图6 UOS、MUOS 与UOS-3C 算法在不同邻居数目的RMSE 结果
与UOS 模型相比,本文使用置信系数改进相似性计算结果[39],后者将相似度分布增加到更大的数字(从0.03 到0.06)。此外,本研究还在推荐系统的建模复杂网络中利用了用户的度值和社团。实验结果表明,与文献[20]中的现有结果相比,UOS-3C 网络的局限性在于,参数k必须很小(k=3)才能提供最佳精度,而不是文献[20]中具有更多链接的更大的k=10。此外,研究结果表明,同一社团中用户之间权重的增加对预测准确性会产生负面影响。
5 结语
用户观点传播算法在推荐系统中的应用具有重要意义,为了解决用户观点传播模型的两个问题,即UOS 相似性的较小值分布和为达到最佳预测精度而需要大量邻居,本文设计了一种方法,即通过复杂网络模型中的置信系数、度中心性和社团差异,提高用户观点传播的评分预测。
本文研究表明,基于中心性、社团和置信系数的方法可以将预测精确度提高最小0.7%、最大5.5%,同时,达到最佳精度所需的邻居数量减少84%,说明本文方法的合理性与有效性。研究表明,在推荐系统中,用户观点的传播在特定用户中更为明显,这些用户有更多共同评分的物品、小众品味且身处同一个社团中。
本文预测方法与实验中的k值有关,与文献[20]中使用的k不同,因此k与评分的最优预测精度之间的关系尚未完全确定。本文假设相似度计算方法对该现象具有决定性影响,不同相似性设计中所涉及的不同因素会影响由网络拓扑表示的系统特性。
为了进一步研究该问题,本文设想了一系列推荐系统的复杂网络模型,这些模型可以专门适用于各种相似性方法,本文比较并讨论了实验结果。并且,在k与最佳预测精度之间的关系中可以找到其他见解。后续将在其他作品中对该问题作进一步研究。
猜你喜欢
交通科技与管理(2022年19期)2022-10-12 03:57:30
数学物理学报(2022年5期)2022-10-09 08:56:44
阅读(中年级)(2022年9期)2022-10-08 01:56:16
河北画报(2020年8期)2020-10-27 02:54:20
军事文摘(2017年16期)2018-01-19 05:10:15
中学生(2016年13期)2016-12-01 07:03:51
电讯技术(2016年8期)2016-11-02 05:40:50
科技传播(2016年17期)2016-10-10 01:46:58
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
俄罗斯问题研究(2013年1期)2013-03-11 15:44:01
