
基于智能手环运动状态的音乐生成系统
2021-10-27 09:06陈诗佳王楚豫
郑州大学学报(理学版) 2021年4期
陈诗佳,王楚豫,谢 磊
(南京大学 计算机软件新技术国家重点实验室 江苏 南京 210023)
0 引言
随着软硬件的快速发展,智能设备逐渐进入人们的生活中,特别是Android系统在智能手环上的广泛应用,为智能生活带来了极大的便利。然而,可穿戴智能设备的软件开发略显落后,以智能手环为例,它们大多仅用于接收手机通知和监控运动状态。目前,已有一些利用智能手环感知运动状态的研究[1],但其应用远不如智能手机丰富。智能手机上有很多流行的短视频应用程序如抖音、快手等,它们为用户提供了免费的创作平台,但很少有应用程序与智能手环结合使用。如果在音乐生成环节中加入智能手环的使用,可以拓宽智能手环的应用场景,提升用户使用智能手环的体验[2]。
基于智能手环的运动状态生成音乐,其目的是将技术与娱乐相结合。音乐生成系统可以简化和抽象出动作模型和乐谱模型,其中动作模型侧重于动作的时间戳和动作内容等信息,乐谱模型侧重于音符的音高、音量等信息。基于此,在音乐生成系统实现的前期有两条主线:一是以可穿戴设备的运动状态数据为研究对象,探索学习可穿戴设备在不同运动状态下的信号特征,通过智能手环感知用户的运动状态;二是探索计算机作曲算法,创造性地从图片中提取信息,创建基本乐谱。在音乐生成系统实现的中期,可以基于运动状态,包括运动停顿时间点、动作重复等信息修改完善乐谱,同步音乐和动作,达到“动作踩点”等效果。在音乐生成系统实现的后期,可以通过加入和弦、四拍编曲、稳定八度等乐理技巧来增强乐谱生成音乐的悦耳性。
音乐生成系统的研究需要解决的一个挑战是从传感器数据中提取动作信息,通过给每个时刻的动作打分,可以设立阈值以剔除由轻微抖动产生的噪声,从而得到表示单独动作的数据段。将动作数据段和模板数据段进行匹配,可以得知动作内容,从而实现动作的切割和匹配。此外,由于音乐的悦耳性是一个感性且不可量化的主观感受,所以该项研究面临的另一个挑战是如何生成符合大众审美的音乐。音乐生成系统可以利用人的视觉和听觉间的通感[3],通过选用图片中相似的像素生成初始主旋律以保证稳定的音高,采用四拍编曲保证稳定的节奏,使用加入和弦等乐理技巧增强乐谱生成音乐的悦耳性。本文开发了基于智能手环运动状态的音乐生成系统,探索智能手环的应用场景以及利用编曲技巧提高计算机作曲的悦耳性。该系统通过智能手环感知用户的运动状态,并连接到便携式智能终端(手机),将运动节奏转化为音乐节奏,从而实现了智能作曲;根据动作的物理特性对传感器数据进行分析,构建并简化了乐谱模型和动作模型,提出了系统各功能模块的技术方案。
1 研究背景及相关工作
1.1 HSV和MIDI
本文的音乐生成系统选择在颜色空间HSV[4]上处理图片的像素点信息,生成基础主旋律。与其他格式的音乐文件相比,MIDI音乐文件占用的存储空间较小,但可以包含几十个音乐轨道,不同的轨道可以由不同的乐器演奏。同时,MIDI拥有可编程操作的特质使其对应的乐谱能够被计算机理解[5]。基于此,选择MIDI作为生成音乐的格式。
1.2 相关工作
1.2.1基于传感器的感知研究 智能设备上的传感器广泛应用于行为感知、人机交互等领域[6-7]。以智能手机为例,周围的环境可以通过传感器“翻译”成各种物理数据[8-9]。文献[10]使用加速度传感器判断用户是否有久坐的习惯,从而及时给出运动建议;文献[11]通过使用手机中的传感器和事件监听器来采集不同场景中的数据,从年龄、性别和人格特征三方面构建用户画像。QQ音乐可以按用户奔跑的步频推荐相应歌曲,这是由于在跑步状态稳定后,不同的人其步频不同,而歌曲有不同的每分钟节拍数,这是与节奏有关的乐谱元素。因此,步频可以理解为运动节奏,每分钟节拍数可以看作音乐节奏,QQ音乐按照这两者相近的算法为用户推荐歌单。
1.2.2计算机作曲研究 音乐的创作灵感大致分为演奏家的生活体验和不断汲取的音乐欣赏经验两种。得益于音乐的创作方式有迹可循且可以被客观理性地归纳[12],这极大方便了机器学习作曲。例如,SongSmith是一款来自微软的编曲软件,可以自动生成音乐伴奏以匹配歌手的声音[13];DeepBach是由Gaetan Hadjeres和Francois Pachet开发的深度学习机器,可以学习如何创作巴赫风格的音乐。计算机作曲算法主要有类似于专家系统的基于规则与乐理的作曲算法和机器学习算法,其中机器学习算法可分为传统机器学习算法和人工神经网络。传统机器学习算法主要基于概率论和统计学,而人们熟知的“人工智能作曲”则运用了神经网络。文献[14]利用循环神经网络(recurrent neural network,RNN),在使用长短时记忆单元的基础上,用于字节码脚本(actionscript byte code,ABC)格式电子乐谱的建模与生成。
2 前期实验
2.1 传感器数据分析
2.1.1切割 使用互补过滤器给不同的判断条件加上不同的权重,从传感器中获得线性加速度a,归一化后为a′,并获得角速度ω,归一化后为ω′,假设有score=0.2×a′+0.8×ω′,当score低于经验阈值4.5时视为停顿(即数据切割点)。
图1显示了一段动作的得分随时间的变化情况,图中用score=4.5为分界线,可分割得到5段动作,动作①~⑤依次为:向上举起、向下压、向右移动、向左移动、顺时针抡圈。但以上设定经验阈值“一刀切”的做法无法去掉类似轻微抖动的动作数据,轻微抖动动作数据如图2所示。观察发现,数据抖动段具有协方差小、时间跨度小等特点,可以据此筛选出真正的动作数据。实验中对8个动作的60种随机组合进行分割,成功分割了84%的动作,这8个动作包括向上、向下、向右、向左、向前、向后、顺时针抡圈和逆时针抡圈。
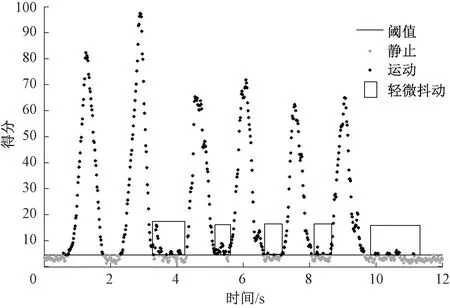
图2 轻微抖动动作数据Figure 2 Action data with slight jitter
2.1.2匹配 动态时间归整(dynamic time warping,DTW)算法是一种衡量两个时间序列之间相似度的方法。两段动作的时间序列对应关系如图3所示。在时间序列中,需要比较相似性的两段时间序列的长度可能并不相等,图中虚线表示序列元素对应关系。考虑到做相同动作时,人体不好把控相同速度,所以采用DTW算法匹配分割好的动作数据。图3展示了做相同动作时不同数据段的匹配情况,为方便观察序列的对应关系,把时间序列向上平移了60个单位,将时间戳变为时间索引。
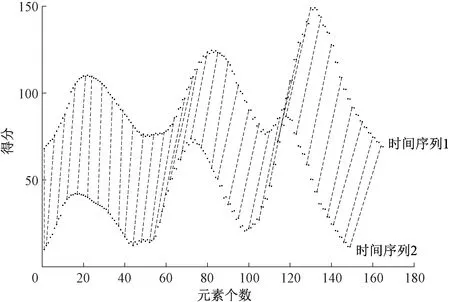
图3 两段动作的时间序列对应关系Figure 3 Time series correspondence relation of two actions
2.2 问题与分析
前期实验主要存在以下两个问题:1)在动作倾向不明确时,识别匹配准确度不高。首先,当动作不够有力时,切割和匹配的结果不尽如人意,因为动作的得分在静止阈值附近。其次,由于没有对原始数据进行滤波处理,DTW算法无法处理离群点、异常点,且未抑制和处理噪声,也不能够适应时间上的偏移。DTW算法本质上是动态规划,可以用其他算法替代,例如支持向量机、随机森林算法等。2)动作和音乐节奏的对应问题。在本文的音乐生成算法中,动作开始时间与音符响起时间最多错开63 ms,人们无法感知到这种细微的不同步,还是会感觉到“踩点”,即动作和音乐节奏相对应。
3 音乐生成系统模型
3.1 模型需求分析
系统需要使用智能手环内置的传感器感知佩戴者的运动状态,将数据上传到服务器,服务器按照动作特性修改原始乐谱,最终生成音乐文件,其中涉及两个主要的数据模型,即动作模型和乐谱模型。服务器处理动作数据时,需要提取的动作数据特性包括每个动作的开始时间、结束时间以及动作类型。服务器处理由图片生成的基础乐谱时,预设的乐谱模型需要包含音符的音高、音量、响的时长、每分钟节拍数等。
3.2 坐标系转换
因为在设备坐标系下传感器数值和设备朝向有关,所以此时的数值在很多情况下是没有意义的。而世界坐标系提供了一个标准化数值的方法,便于得到数据特征与动作特性的映射。坐标系转换如图4所示,在提供重力传感器和磁力计的数据后可以确定世界坐标系,进而得到设备坐标系到世界坐标系的旋转矩阵,实现坐标系转换。实验发现,不进行坐标系转换也能实现动作识别和匹配,并且未配备磁力计的设备也能使用本文实现的应用程序。因此,在系统实现中并未进行坐标系转换。

图4 坐标系转换Figure 4 Coordinate system conversion
3.3 基于DTW算法的动作匹配
获取动作信息时,将切分后的动作与模板进行匹配以识别动作。匹配算法选用DTW算法,它定义所有相似点间的欧氏距离之和为归整路径距离,用来衡量两个时间序列之间的相似程度。最短归整路径如图5所示,动作越相似,路径就越接近对角线。图中的得分坐标轴仅为方便观察两个时间序列的相似程度,实际进行动作匹配时,DTW算法则使用线性加速度和角速度数据的欧氏距离进行计算比较。
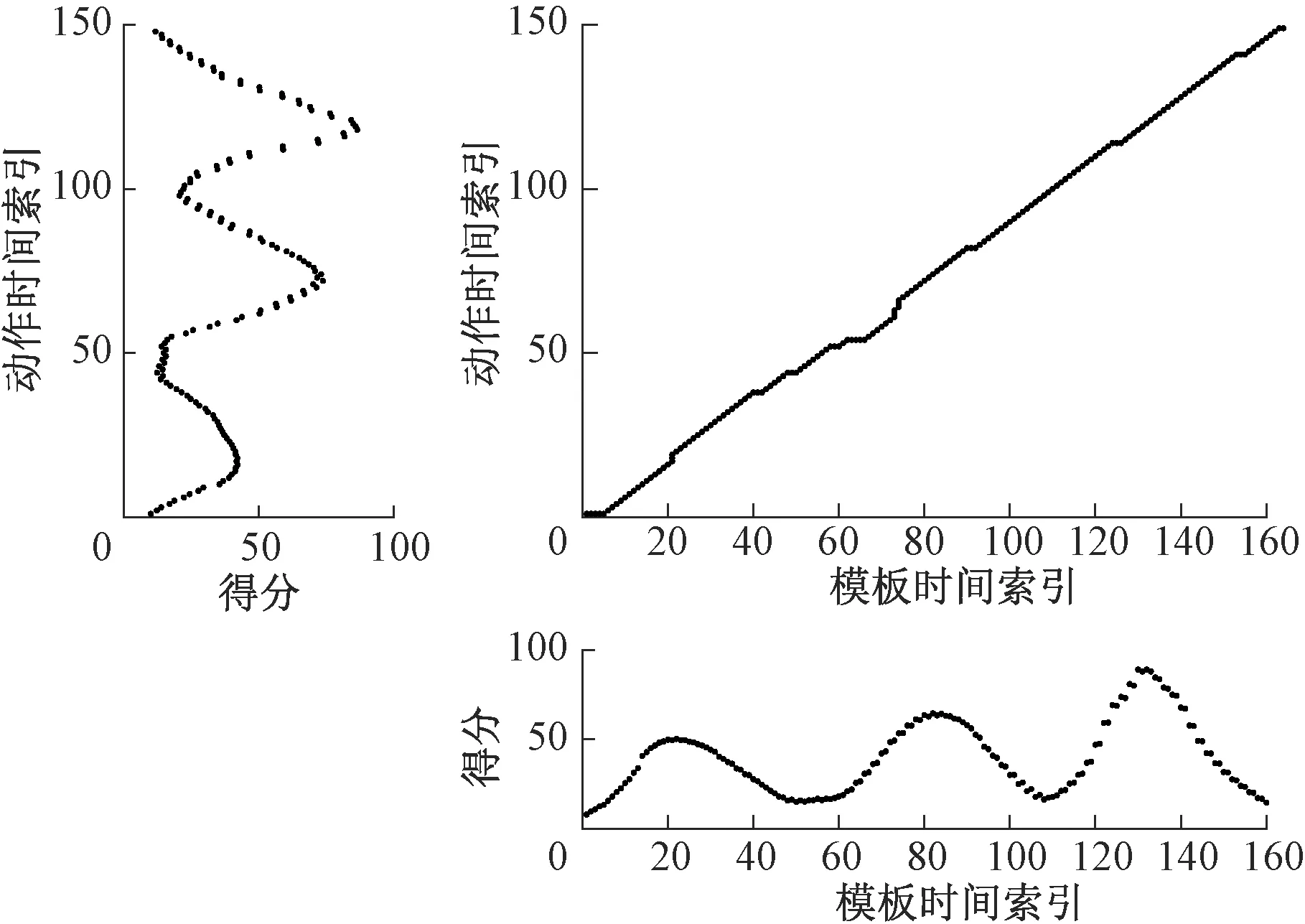
图5 最短归整路径Figure 5 Minimum-distance warp path
实验发现,位移幅度较大的动作按线性加速度匹配,结果较为准确;姿势变化较大的动作按角速度匹配,结果较为准确。使用“向上举起”模板与图1中的5个动作进行匹配,匹配结果如表1所示,与事实相符。
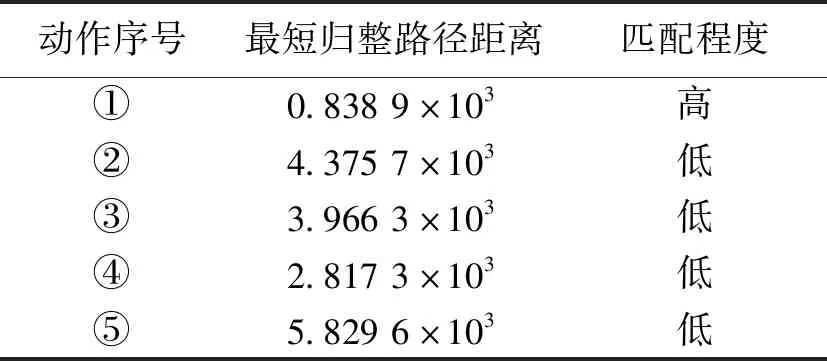
表1 动作模板数据与动作数据的DTW匹配结果Table 1 DTW matching results of action template data and action data
3.4 乐谱模型和动作模型
对模块之间的数据流格式做出以下约定:传感器数据流中有时间戳、xyz三轴线性加速度、xyz三轴角速度;动作数据流中有动作开始时间戳、动作匹配序号、动作结束时间戳;乐谱数据流中有音高、音量、音符开始响时间戳、音符响的时长。原始乐谱的修改如图6所示,用动作数据的起止时间戳去修改原始乐谱。动作①和动作②各自新增了一个音符,而动作③起止时间处已有音符,所以不再新增。动作数据的时间点和音符起止时间最多相差63 ms,而63 ms仅为半个十六分音符时长。因此,通过这种修改,人们可以感觉到音乐节奏符合动作节奏。
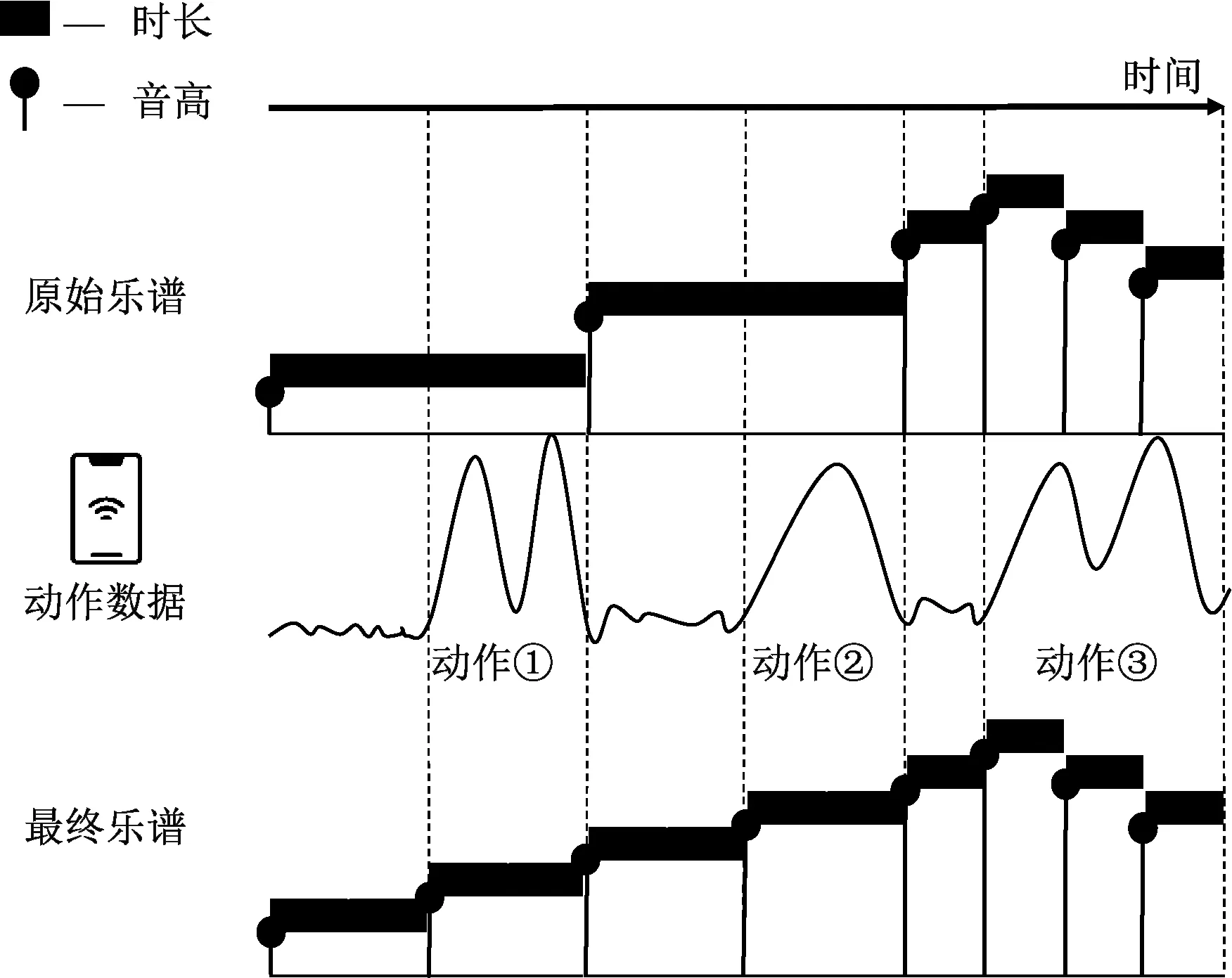
图6 原始乐谱的修改Figure 6 Modification of the original music score
4 系统设计和实现
4.1 系统概览
最终实现的音乐生成系统应由佩戴智能手环的用户做出一段动作后上传动作数据,经由音乐生成算法处理后,用户可下载音乐试听。音乐生成系统模型如图7所示。系统分为客户端和服务器,客户端由手环应用程序和手机应用程序组成,手环收集传感器数据传输至手机,手机通过HTTP协议和服务器通讯上传传感器数据,从服务器下载音乐文件并播放,服务器根据功能模块处理得到的动作数据和乐谱数据完成最终乐谱,生成音乐文件供客户端下载。
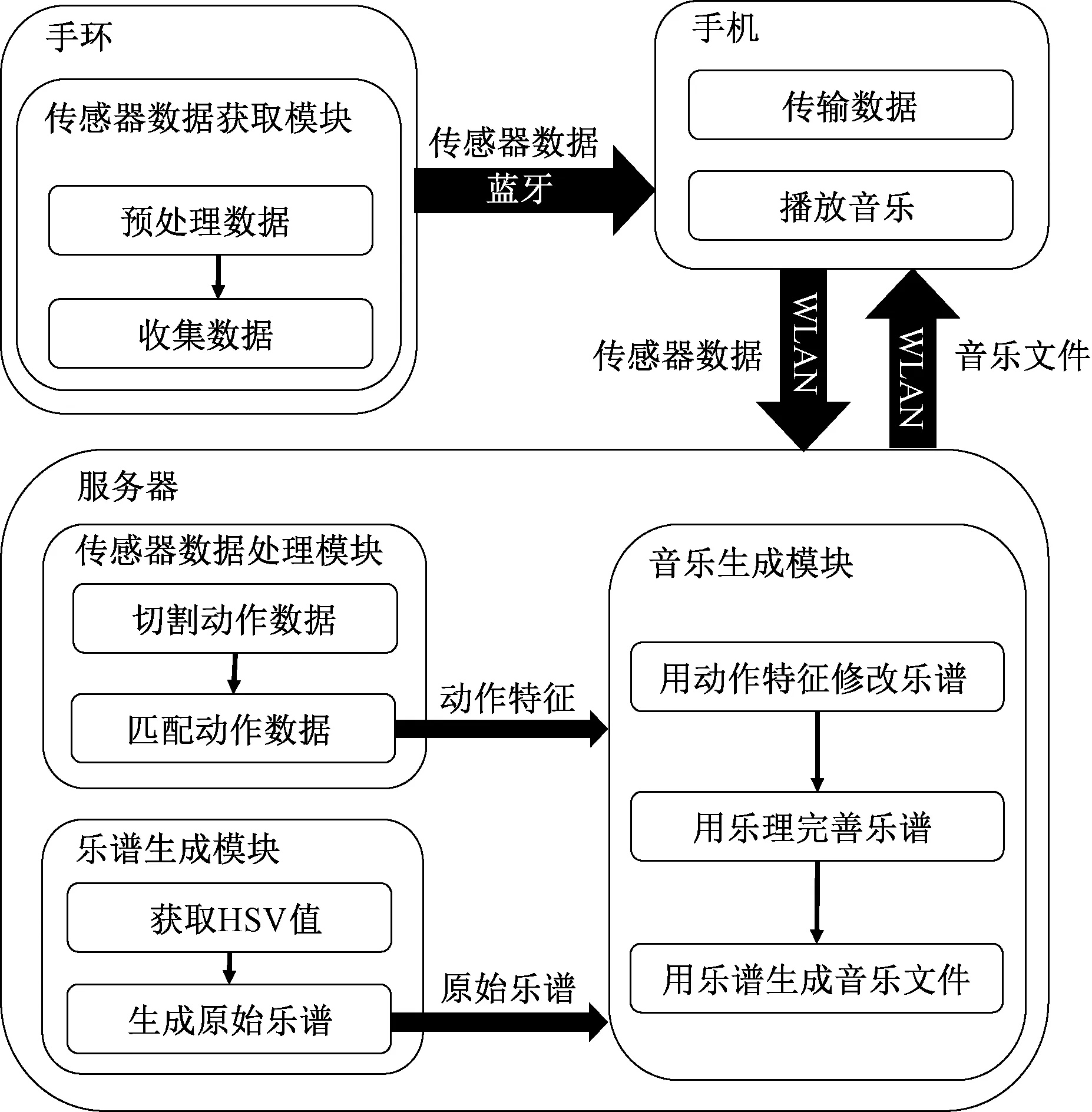
图7 音乐生成系统模型Figure 7 Music generation system model
4.2 模块设计和实现
4.2.1传感器数据获取模块和处理模块 获取模块位于智能手环,监测线性加速度传感器和陀螺仪的数据变化,之后标准化得到的实时数据并存储,在得到指令后上传数据以供后续处理分析。处理模块位于服务器,在服务器接收传感器数据后进行处理分析,根据经验阈值将传感器数据分为动作数据段和静止数据段。由于经验阈值无法分辨出轻微抖动的数据,所以还要利用数据抖动段时间间隔短和协方差小的特点进一步筛选出动作数据段,此时得到了每个动作的开始时间戳和结束时间戳,并且可以将其和预设的动作模板数据段匹配。
4.2.2乐谱生成模块 这一模块位于服务器端,由图片像素信息生成包含主旋律的基础乐谱数据。读取图片,将像素点按HSV值分类存储,取含有最多像素点的类别,根据预设的对应关系,按HSV值设定乐谱主旋律音符的高低、强弱、长短。例如,若图片主色调为红色,则对应音符偏高、强、短,给人欢快、热情的感觉;若图片主色调为蓝色,则对应音符偏低、弱、长,给人幽静、低沉的感觉。
4.2.3音乐生成模块 首先,根据传感器数据处理模块得到的动作数据结果(切割后动作起止时间、匹配的动作编号)来修改图片生成的乐谱数据,以实现修改后的乐谱生成的音乐节奏能和动作节奏相符合。其次,在得到的乐谱数据结果基础上使用编曲技巧,加入和弦、鼓点等增强生成音乐的悦耳性。音符响起时间、结束时间和动作的起止时间对应,从而可以让用户感受到音乐节奏与动作节奏相符,该模块实现了乐谱修整并且生成音乐文件供用户下载。音乐生成算法的具体步骤如下。
输入:动作数据文件日期date,文件索引index。
输出:音乐文件生成是否成功字符串消息success/fail。
读入动作数据actList和乐谱数据musicList;
根据musicList和actList各自生成音符列表noteList和extraNoteList,音符列表中存放myNote音符类,内含属性音高note、音量vel、启停标志onOrOff、音符启停绝对时间戳beatStamp;
用extraNoteList修整noteList:
el是extraNoteList列表首音符;
FOR 音符nlin 音符列表noteList:
IF 超出extraNoteList范围:break;
IFel的beatStamp==nl的beatStamp:el变为extraNoteList下一个音符;
IFel的beatStamp IFnl为小节首字符:将el加入noteList; ELSE:将nl变为el; el变为extraNoteList下一个音符; 将noteList中的音符加入音轨track中; 将为noteList中的音符配的和弦音符加入音轨track中; 生成音乐文件供用户下载。 系统评估使用的手环是Moto 360,使用的手机是华为荣耀Che2-TL00 M。通过对原始乐谱和动作的相关性以及最终乐谱和动作的相关性进行对比分析,可以发现,算法修改后的乐谱和动作的相关性更高。假设乐谱变量为A,动作变量为B,每个变量有N次观测,则皮尔逊相关系数定义为 R的绝对值越大,相关性越好[15]。设P为不相关的概率值,表示关系的显著性。如果P值小于0.05,那么就表明两者之间有相关性。图8显示了乐谱和动作的相关性。可以看出,算法修改后的P值变小,R值变大,意味着乐谱和动作间的显著性增高,相关性增强。 系统的流程包括:用户佩戴手环运动;将数据传输给手机;由手机上传数据到服务器并下载播放生成的音乐。图9显示了动作时长和系统响应时间的相关性。可以看出,系统响应时间与动作时长呈线性关系,这一结果与所设计算法的时间复杂度吻合。系统响应时间从手机上传数据开始计时到音乐文件下载完成,由于系统原型实现简单,未使用专业的数据库,所以主要耗时在数据文件的打开和读取。如图9所示,样本中有两个离群点,这两个观测值产生在服务器启动和重启时,建立HTTP连接有时间开销;拟合的直线与y轴的交点表示系统的固定时间开销,例如网络连接、开启脚本进程等。 图9 动作时长和系统响应时间的相关性Figure 9 Correlation between action duration and system response time 智能手环应用程序的运行界面有3个控制按钮,手机应用程序的运行界面包括传感器数据显示部分、动作文件功能按钮区和音乐文件功能按钮区。功能测试结果表明:1)智能手环在录制传感器数据后,传输数据文件到手机,测试发现,系统能够正确响应。2)手机将文件传输到服务器,服务器返回录入动作数量到手机,刷新手机界面,测试发现,系统在用户误操作的情况下仍能响应并给出提示。3)手机向服务器请求下载音乐文件并播放,测试发现,系统能够对误操作给出错误提示。 基于智能手环运动状态的音乐生成系统实现了基于用户动作的自动作曲。本文分析了智能手环的传感器数据,根据动作的物理特性对数据进行分割和匹配,以便分类动作;由动作特性修改图片生成的基础乐谱数据,并按照乐谱生成音乐文件供用户下载播放;讨论了实现系统功能模块的不同技术方案,对可穿戴智能设备与计算机作曲的融合进行了创造性的探索。5 性能评估
5.1 乐谱和动作的相关性
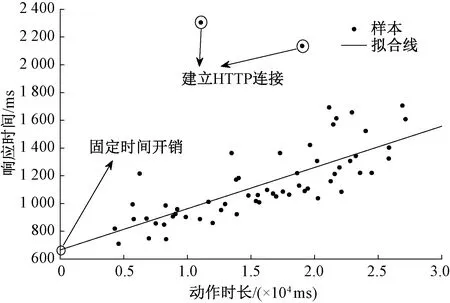
5.2 系统响应时间开销
5.3 功能测试
6 小结
猜你喜欢
歌唱艺术(2022年6期)2022-10-23
阅读(低年级)(2020年10期)2020-01-07
北方音乐(2019年20期)2019-12-04
电脑报(2019年30期)2019-09-10
作文大王·低年级(2019年5期)2019-06-13
海峡姐妹(2018年9期)2018-10-17
作文大王·中高年级(2018年7期)2018-08-18
琴童(2018年11期)2018-01-23
小猕猴学习画刊(2017年1期)2017-02-17
小康(2016年19期)2016-09-10
