
基于关联规则挖掘的铁路超限超重货物运输路径决策方法
2021-10-18 06:08:10张英贵过靖怡雷定猷吴辉
铁道科学与工程学报 2021年7期
张英贵,过靖怡,雷定猷,吴辉
(1.中南大学 交通运输工程学院,湖南 长沙410075;2.中南大学 计算机学院,湖南 长沙410083;3.轨道交通大数据湖南省重点实验室,湖南 长沙410075)
铁路超限超重货物运输是一种组织高度复杂的系统工程,包括限(限速运行)、绕(绕道运输)、禁(禁止会车)、疏(拆除沿途控制设备)、固(桥梁加固)等过程,涉及调度、车辆、机务、工务、电务等几乎所有的铁路运输部门[1]。为发展绿色交通体系,大辐提升铁路货运比例,发展铁路超限超重货物运输是必须的。要想发展铁路超限超重货物运输,优化路径决策至关重要,然而目前主要依靠历史经验人为选择径路,效率较低的同时可能往往不能择出最优路径。因此研究如何提高铁路超限超重货物安全运输路径决策的科学性及可靠性具有重大意义。汤波[2]通过不断修正超限超重运输路径优化模型中各因素权重,设计路径搜索算法实现路径寻优;陈皓等[3]提出了装载加固与路径选择综合优化模型和决策方法;雷定猷[4]从信息化的角度论述超限超重运输优化问题,开发了铁路超限超重货物运输决策支持系统;ZHANG等[5]开发了B/S模式三层的调度系统,并提出一系列网络安全技术和管理措施。随着智慧交通系统的出现,交通大数据已成为基础性资源,关联规则挖掘在交通管理和交通预测方面发挥极大的作用。JIANG等[6−7]利用关联规则挖掘方法和模型对交通事故进行分析;GUO等[8]挖掘城市轨道交通乘客通勤和转移行为数据中的关联规则,为优化运营战略提供依据;FANG等[9]应用关联规则分析寻找不同城市景区之间的关联关系作为旅游线路推荐;易振威等[10−11]采用关联规则改进算法解决危险品的运输优化问题,提高公路危险品运输的安全性;黎丹雨等[12−13]改进了传统的关联规则挖掘算法并通过案例表明了其实际应用价值。关联规则挖掘在交通运输运营管理中应用广泛,但具体在铁路超限超重货物运输组织领域的应用几乎没有。目前,积累了海量的我国铁路超限超重货物运输路径的历史数据,面向数据挖掘的超限超重货物运输路径决策研究条件已经成熟。本文通过关联规则挖掘,揭示铁路超限超重货物运输历史数据间隐含的相关关系,得到某一运输条件下分界口间推荐路径,然后设计实例相似度匹配算法,科学高效地实现铁路超限超重货物运输路径决策。
1 铁路超限超重货物运输路径决策模型构建
综合考虑各类运输费用及耗费的时间成本,以总成本最小为优化目标,铁路限界、车流平衡、桥梁承载能力为约束,构建铁路超限超重货物安全运输路径决策模型M如下:
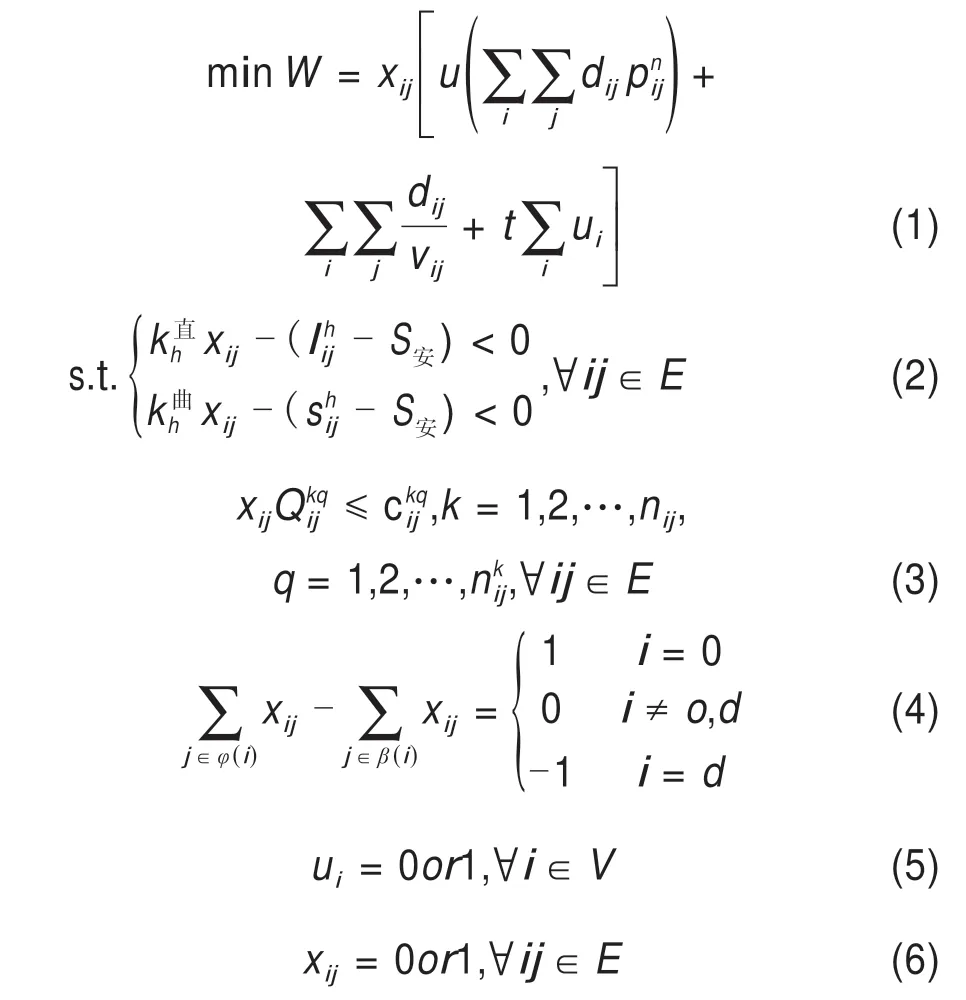
记铁路超限超重运输网络为G=(V,E),V={i|i=1,2,…,nk}为节点集,nk为节点数量,E={ij|i,j=i=1,2,…,nk}为节点路段的集合。模型M中:分别表示该路段直线和曲线综合最小建筑限界h处的半宽,其中因外轨超高造成的限界加宽已扣除。k直h和k曲h分别表示超限货物运行在直线线路和曲线线路时在高度h处占用空间的半宽。S安为超限货物的任何超限部位必须与建筑限界之间保持的安全裕量。记超限超重车通过节点路段ij的第k个区间的第座桥梁的运行活载为检定活载系数为表示该路段的单位运输成本费用(n=1,2,3…表示各种运输费用),vij表示该路段平均运行速度,dij表示该弧的长度,ui为0-1变量,若节点i需要进行技术作业,ui=1,否则ui=0,t为车站作业平均停留时间,xij为决策变量,若超限超重货物运输路径选择了路段ij,xij=1,否 则为 运 输 货 币 成 本,为运输时间成本。运输时间和费用综合表示为运输总成本,两者单位和数量级不同,引入参数进行无量纲化处理,u表示运输时间与货币成本之间的换算系数,按货物价值定义取值。
2 模糊多层次超限超重货物运输路径关联规则挖掘方法
关联规则是数据挖掘中一个重要的研究方向,是描述数据库中数据项之间存在潜在关系的规则。铁路超限超重货物历史运输数据是稀疏的混合类型属性数据集,故将模糊分割和多层次关联规则挖掘的思想应用于铁路超限超重货物历史运输数据挖掘。首先对历史运输数据进行预处理,从数据库中筛选分界口间事务并将数据结构化;其次结合模糊规则对数据进行归纳泛化,基于最小支持度生成频繁序列,实现多因素决策数据分层树的剪枝筛选;最后,通过各因素与路径间置信度度量其关联程度,进而得到某一类运输条件下可能的路径集合。图1是铁路超限超重货物运输路径决策概念层次关系,上层表示项目或概括的项目(即分类)。
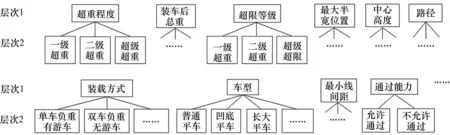
图1 铁路超限超重运输路径决策原始概念层次Fig.1 Original conceptual level of railway out-of-gauge and overweight freights transportation route decision
2.1 超限超重货物运输路径历史数据预处理方法
1)事务筛选
分界口是各铁路局集团公司之间划分管辖区域的分界站。以路网上2个分界口间的子网络作为研究对象(若起点站或终点站不属于路网分界口,则视为伪分界口)。如图2所示,设共有N条历史运输记录经过A和B 2个(伪)分界口,A-B间有m条不同的路径,每条历史运输路径数据称为1个事务,挖掘这N个事务的关联规则。

图2 分界口间子网络Fig.2 Sub-networks between dividing stations
2)数据结构化
在铁路超限超重货物运输数据中,每条运输记录包含的数据繁杂多样,从中筛选出值得挖掘的信息,并将数据结构化。
某一条事务tN=(超重程度N,货物装车后总重N,超限等级N,最大半宽N,最大半宽高度N,中心高度N,车型N,装载方式N,路径长度N,最小线间距N,通过能力N,桥梁承重力N,…,路径N),其中,每条路径包含的信息为起点−节点1−节点2−…−终点,是否进行限界改造。
2.2 超限超重货物运输路径数据归纳泛化规则
从原始数据表中初步选取合适的因素列表,并作为后续因素关联规则挖掘的基础。结合模糊分割,用因素删除和因素泛化对数据进行模糊泛化。如果因素值是大量相同或相近的,则将其删除,例如最小线间距、通过能力等。如果因素有大量不同的有效取值,则可以对该因素进行泛化。
1)模糊规则
根据《铁路超限超重货物运输规则》,货物超重和超限的程度都分为3个级别。将每个级别内的数值模糊划分,各级别之间精确划分,规则如下:
每个超重等级内按活载系数Q划分为3个模糊子集,每个等级的模糊集表示为F={F(x1),F(x2),…,F(xn)},每个等级内3个模糊子集的隶属度函数F1(x),F2(x),F3(x)按顺序分别为降半正态分布、正态分布、升半正态分布,见式(7)~(9)[14]。
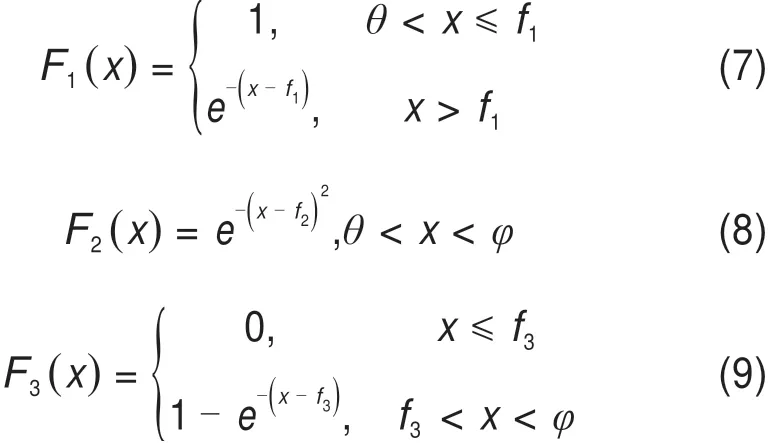
其中,一级和二级超重的f1,f3为该等级内的3等分点,f2为中点;取超级超重等级下限值和历史最大值构成区间,f1,f3为该区间的3等分点,f2为该区间的中点;θ为上一等级上限值(一级超重时θ为该等级下限值),φ为下一等级下限值(超级超重时φ=+∞)。
每个超限等级内按限界尺寸划分为3个模糊子集,每个等级的模糊集表示为G={G(x1),G(x2),…,G(xn)},每个等级内3个模糊子集的隶属度函数G1(x),G2(x),G3(x)参考超重等级隶属度函数F1(x),F2(x),F3(x)设置。
2)数据泛化
①超重程度用A表示,A0,A1,A2,A3分别描述不超重,一级超重,二级超重,超级超重。
②装车后总重用W表示,若货物不超重,用W0描述,否则,将重量值按照模糊规则划分到不同模糊集,用{“W1”,“W2”,…,“W9”}分别描述。
③超限等级用B表示,B0,B1,B2分别描述一级超限,二级超限,超级超限。
④最大半宽位置用L=(x,y)表示,将其值按照模糊规则划分到不同子集,用{“L0”,“L1”,“L8”}分别描述各组数值。
根据《超规》,这里按超限部位和超限等级将最大半宽位置泛化为9个描述值:一级超限,上中下部分别用L0,L1,L2表示;二级超限,上中下部分别用L3,L4,L5表示;超级超限,上中下部分别用L6,L7,L8表示。
⑤中心高度用H表示,将其值按照模糊规则划分到不同模糊集,用{“H0”,“H1”,…,“H8”}分别描述各组数值。
⑥路径用P表示,{“P0”,“P1”,…,“Pm”}分别描述,Pm=[a,b,c,…,f,0]。
2.3 超限超重货物路径频繁序列创建
基于归纳泛化得到的因素序列对原始概念层次进行初步剪枝和转化,得到可挖掘的铁路超限超重运输路径决策数据分层树,如图3所示。由A到P的6层单枝是基本单元,每个聚集的层用“*”表示。令6维向量z=(z1,…,zl,…,z6)为一个单元,根据层次关系,如果zl不满足最小支持度,则其后代也不可能满足,故剪除(z1,…,zl,*,…)对应分枝。
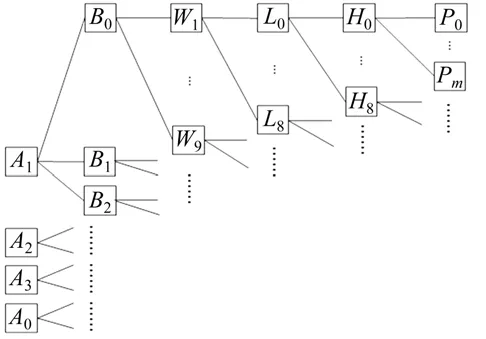
图3 铁路超限超重运输路径决策数据分层树LTFig.3 Decision data level tree for railway out-of-gauge and overweight freights transportation route decision
遍历分层树LT,对A层到P层的不同属性值用最小支持度α逐个筛选,选取每个“*”的取值,得到频繁向量集,从而创建频繁序列,方法步骤如下:
1)扫描输入,遍历LT,得到各单枝计数,对应向量(*,*,*,*,*,*,*)。
2)根据A层的取值将输入划分为4个分枝,并记录A的每个不同值元组的计数。
3)对第1个“*”的取值,分别聚集A1,A2,A3和A0分区,并为其分组创建元组。A1分区对应向量(A1,*,*,*,*,*,*),若此单元满足最小支持度α,则在A1分区上递归进行划分。
4)在B层上划分A1分区,对第2个“*”取值,获取B层B0节点对应向量(A1,B0,*,*,*,*,*)的计数,用最小支持度α检查。如果满足最小支持度,则在(A1,B0,*,*,*,*,*)上从W1开始划分。否则,剪除(A1,B0,W1,*,*,*,*)上的分枝。
5)依次迭代下去,在(A1,B0,W1,*,*,*,*)上完成L层、H层和P层的取值划分后,回溯到A2的划分,并迭代进行,直到所有层的所有取值都进行完毕。
在整个过程中,默认满足最小支持度阈值,故形成的单元(Ax,Bx,Wx,Lx,Hx,Px)为频繁序列。
2.4 超限超重货物运输路径模糊多层关联规则
满足最小置信度的频繁序列,输出为关联规则。使用Prefix Span挖掘提取最频繁的序列,初步得到多个关联规则后,利用提升度进行筛选:X是某个运输条件,Y是运输路径,若Lift(X⇒Y)<=1,则删除该规则。
3 超限超重货物运输路径实例匹配决策方法
在基于相似度的实例匹配路径决策方法中,运输路径方案由(伪)分界口间的路径连接起来得到。
3.1 实例相似度计算方法
由于铁路超限超重货物运输路径决策的特殊场景,目标实例与历史案例相似度分为OD相似度和货物属性相似度,取值[0,1]。
3.1.1 OD相似度计算
设目标实例与历史案例起点站/终点站之间的相同节点数v,可能相似的两分界口间路径上的节点数为Vs,起点站/终点站相似度计算公式为:
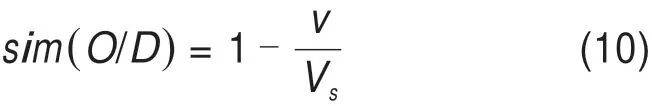
目标实例与历史案例的OD相似度为:
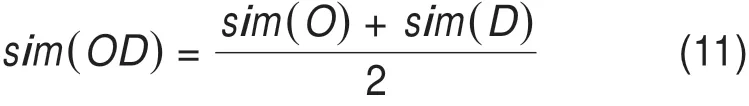
3.1.2 货物特征属性相似度计算
铁路超限超重货物特征属性间可能存在相关性或者包含性,对不同的属性值需采用不同的相似度计算方法。
1)重量属性相似度
超重程度为有序枚举型属性。相似度计算公式为:

式中:X1,Y1分别表示例X和例Y第1个属性值,取值为A0=0,A1=1,A2=2,A3=3。
货物装车后总重是数值型属性,决定了货物的超重程度。当货物不超重,X2=Y2=W0,即sim(X2,Y2)=1;否则,计算点X2=a2与区间Y2(b21,b22)的相似度公式如下:
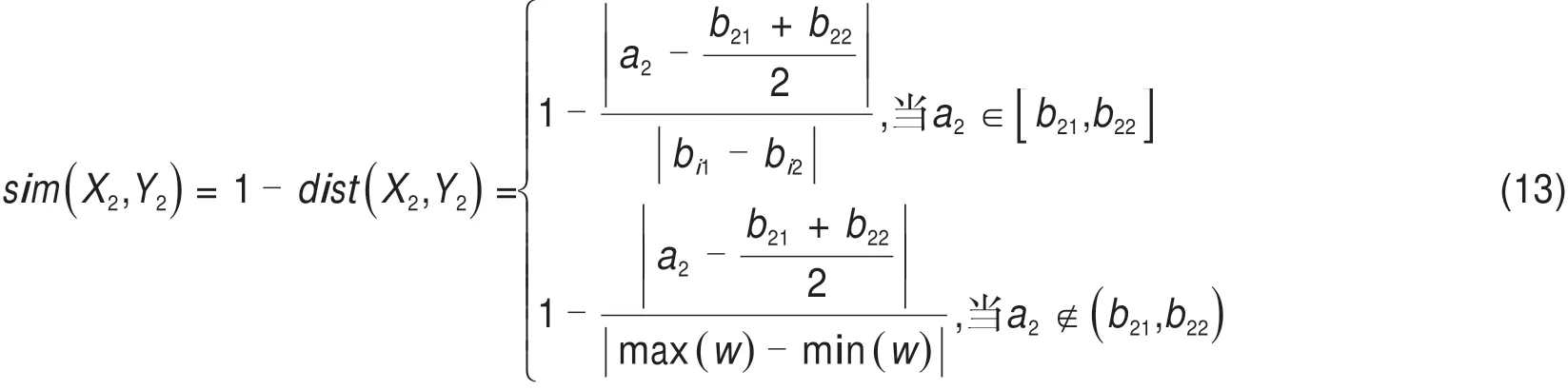
式中:max(w),min(w)分别表示例X和例Y货物超重程度的高等级值上限和低等级值下限。
2)轮廓属性相似度
超限等级也是有序枚举型属性。采用的相似度计算公式与超重程度一致,其中B0=1,B1=2,B2=3。
中心高度是数值型属性,是决定货物超限等级的重要因素之一,相似度计算方法与货物总重相似度计算公式一致。
最大半宽位置也是决定货物超限等级的重要因素之一,是一个点值属性(x,y),包括最大半宽x和最大半宽高y。先确定目标实例最大半宽位置点所在分区,再根据分区中心点(a5x,a5y)与目标实例最大半宽位置点(b5x,b5y)之间的距离定义相似度,计算公式为:
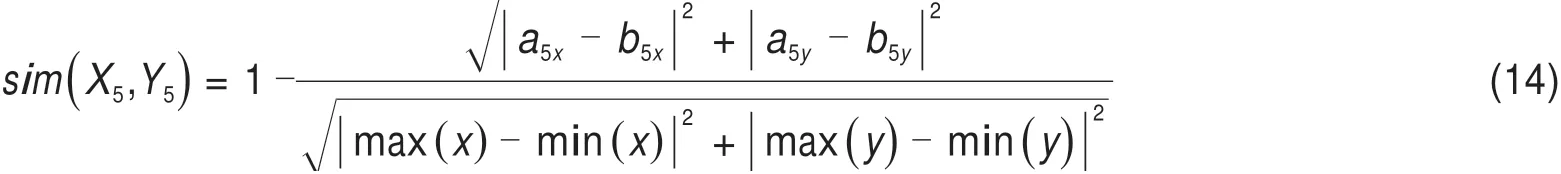
式中:max(x),min(x),max(y),min(y)分别表示该轮廓分区x和y的上限和下限。
3.2 超限超重货物运输路径实例匹配决策算法
基于我国铁路超限超重货物运输网络,结合多层关联规则挖掘和模糊数学理论,综合评估关联规则挖掘结果与目标实例的相似度,得到推荐路径集合,根据相关属性参数的约束规则和目标函数值进一步择优,最后得到推荐运输路径方案,算法步骤如下:
Input铁路超限超重运输网络参数,关联规则数据集R,目标实例起点站o和终点站d及其所属路局j和k,目标实例货物属性及取值,相似度阈值β,γ,δ,ε。
Output运输路径集
Step 1确定分界口。若j=k,则转至Step 7;否则,找出路局j和k间的2条最短路,按路径方向的顺序提取分界口f=(fj,…,fk)。
Step 2按分界口检索。在数据集R中检索(伪)分界口之间的关联规则,按顺序存入表1−表z。若表1-表z均为空,转至Step 7。
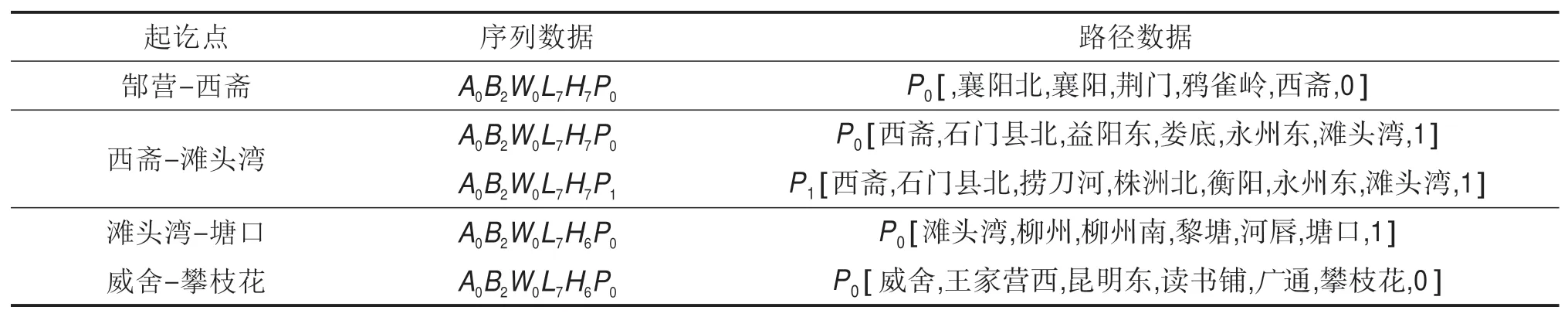
表1 部分模糊多层关联规则挖掘结果Table 1 Part of fuzzy multi-level association rules mining results
Step 3根据OD相似度初步筛选。不满足相似度阈值β的关联规则从表1和表z删除。
Step 4根据货物特征属性相似度进一步筛选。
Step 4.1删除表1−表z中超重程度和超限程度相似度为0的数据;
Step 4.2计算表中剩余数据的各货物属性相似度,任何一项未达到阈值的数据从表1−表z中删除。
Step 5约束检查。根据约束验算当前实例验算表1−表z中各条数据的路径和相关参数,不满足的从表1−表z内删除。若表1−表z均为空,转至Step 7。
Step 6排序筛选。按表1−表z中各条数据货物装车后总重、最大半宽位置和中心高三者的相似度平均值降序更新表1−表z,删除路径相同的数据。
Step 7完整性检查。若表1−表z存在空表,根据限界、桥梁承载能力初筛当前铁路运输网络,并在该网络上采用K-最短路算法得到空缺路段路径,使起点站o至终点站d路径完整;否则转至Step 8。
Step 8按表1−表z的(伪)分界口顺序组合列出各条完整的路径,计算各路径目标函数值,将完整路径及数据按目标函数值升序填入表Isdata。
Step 9将Isdata中数据作为推荐运输路径方案集合并输出,供超限调度人员决策。
4 实例
以从西安西站将换流变压器运输至丽江东站为例,进行基于关联规则挖掘的铁路超限超重货物运输路径决策方法应用。换流变压器外形尺寸为12 000 mm×3 500 mm×4 850mm,重300 t,采用DK36型360 t落下孔车装载运输。起始站西安西站属于中国铁路西安局集团有限公司(简称西安局,后文各铁路局集团有限公司均采用简称),终点站丽江东站属于昆明局。提取路径决策所需关键参数,如表2所示。

表2 换流变压器运输路径决策关键参数Table 2 Key parameters ofconverter transformertransportation routedecision
成都局至周围各路局路段不具备办理超限货物运输业务资质,西安局与武汉局分界口胡家营、武汉局与南昌局分界口西河村所在区段综合限界不符合限界要求,排除相关线路,故经过的路局为:西安—郑州—武汉—广州—南宁—昆明,线路如图4所示。
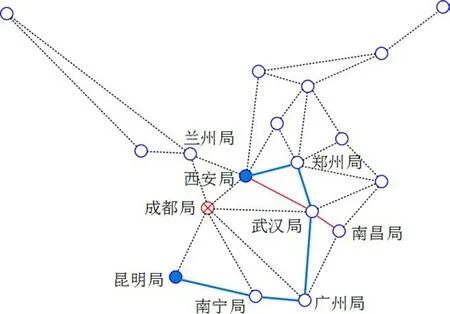
图4 路局路线示意图Fig.4 Railway bureaus route map
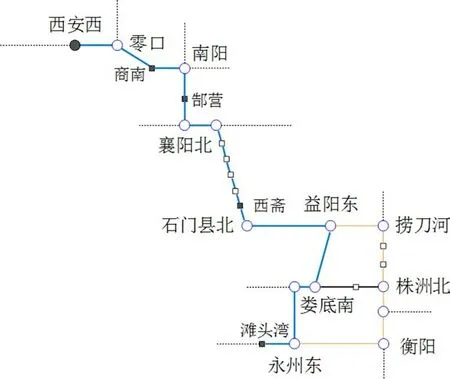
(伪)分界口连接成的运输路线为:西安西、商南、郜营、西斋、滩头湾、威舍、丽江东。根据路网分析,西安西—郜营有唯一路径:西安西—零口—商南—南阳—郜营。由关联规则挖掘结果,西斋—滩头湾有2条可能运输路径。根据数学模型分别核算2条路径,参数u取值1.2×10-5。
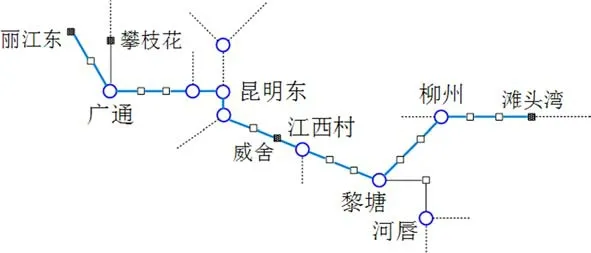
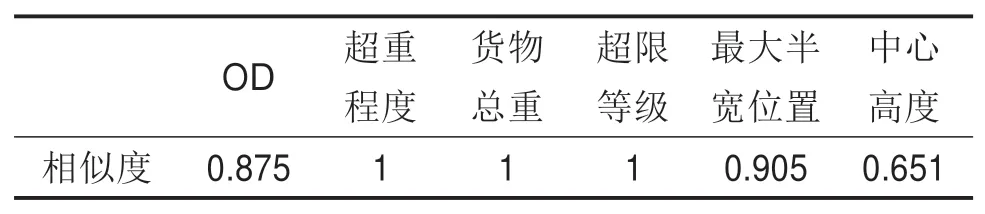
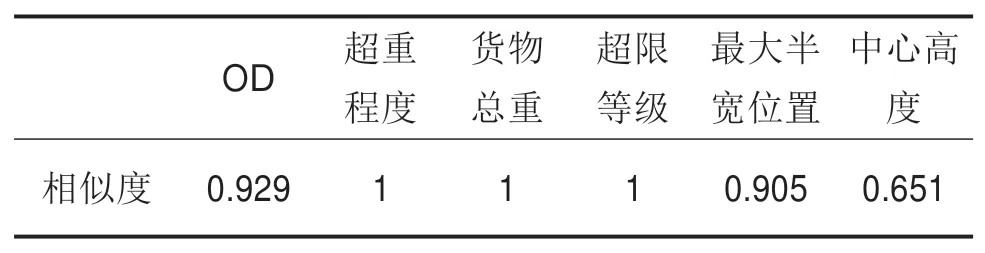
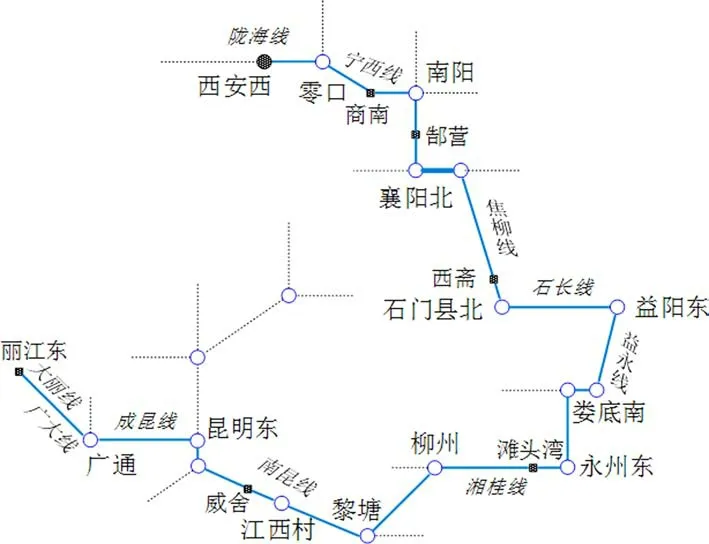
由表3可得WP0 表3 西斋—滩头湾模型核算结果Table 3 Results of model accounting for Xizhai-Tantouwan Fig.5 Railway transportation rout for Xi’anxi-Tantouwan 滩头湾—威舍、威舍—丽江东没有相应的关联规则挖掘结果,检索相似路径,对应铁路路网如图6所示。 图6 滩头湾—丽江东段铁路路网示意图Fig.6 Railway networks of Tantouwan-Lijiangdong 各相似度阈值为:OD相似度阈值β=0.75,货物总重相似度阈值γ=0.75,最大半宽位置相似度阈值δ=0.67,中心高度相似度阈值ε=0.60,检索挖掘结果可得:滩头湾—威舍与滩头湾—塘口路径高度相似,威舍—丽江东与威舍—攀枝花路径高度相似,其各项属性均大于对应相似度阈值,可作为推荐运输路径。相似度计算结果如表4和表5所示。 表4 滩头湾—威舍与滩头湾—塘口历史路径相似度Table 4 Route similarity between Tantouwan-Weishe and Tantouwan-Tangkou 表5 威舍—丽江东与威舍—攀枝花历史路径相似度Table 5 Route similarity between Weishe-Lijiangdong and Weishe-Panzhihua 故滩头湾—丽江东路径为:滩头湾—柳州—黎塘—江西村—王家营西—昆明东—广通—丽江东。 综上,最终运输路径为:西安西—零口—南阳—襄阳北—石门县北—益阳东—娄底—永州东—柳州—黎塘—江西村—昆明—广通—大理—丽江东,全程3 862 km,沿途经陇海线、宁西线、焦柳线、石长线、益永线、湘桂线、南昆线、成昆线、广大线和大丽线,如图7所示。 图7 西安西站至丽江东站换流变压器铁路运输线路示意图Fig.7 Railway transportation route of converter transformer from Xi’anxi-Lijiangdong 经核查,本线路中西安西火车站至娄底、黎塘至广通段运输过大型换流变压器,娄底至黎塘段线路限界条件较好,仅线路上有部分站台、雨棚和信号灯等需要改造或拆除,因此线路条件能满足丽江换流站换流变压器运输要求。 1)通过构建数据归纳泛化规则和创建频繁序列,生成模糊多层关联规则,并设计了一种基于相似度的实例匹配决策算法。 2)所提出的超限超重货物运输路径实例匹配决策方法可以充分挖掘历史数据中对当前决策有效的隐含信息,同时排除安全隐患。 3)所提方法尚未考虑改造费用、运输风险等因素的影响,这是下一步要研究的工作。
5 结论
猜你喜欢
幼儿画刊(2023年12期)2024-01-15 07:06:10
VOGUE服饰与美容(2022年7期)2022-06-30 21:25:45
东坡赤壁诗词(2022年3期)2022-05-29 04:58:53
东坡赤壁诗词(2019年4期)2019-09-12 03:53:06
扬子江诗刊(2018年6期)2018-11-13 00:33:55
电子制作(2018年1期)2018-04-04 01:48:46
天天爱科学(2017年12期)2018-01-31 02:11:16
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
减速顶与调速技术(2014年4期)2014-03-16 03:38:01
