
基于GIS与BP神经网络的矿区塌陷易发性预测
2021-10-17 14:00王绅皓谢婉丽奚家米
煤矿安全 2021年9期
王绅皓,谢婉丽,奚家米,井 旭
(1.西北大学 地质学系,陕西 西安 710069;2.大陆动力学国家重点实验室,陕西 西安 710069)
地面塌陷是矿山常见的地质灾害之一,矿区的地面塌陷为采矿工作及当地居民带来了严重的安全隐患及经济损失[1]。因此,矿区塌陷的预测是保障生产工作正常运行,保护居民生命财产安全的重要工作[2]。针对塌陷易发性的预测,已经有众多学者进行了大量的研究,并提出了各种判别方法。刘宝琛等[3]提出将概率积分法运用到地下开采等实际工程引发地面塌陷的预测工作中;谢和平等[4]使用相似材料作了巷道和采场的岩层塌陷实验,并基于非线性的连续介质模型对地下工程的塌陷进行了非线性力学有限元分析。孔宪立等[5]论述了采空区地表为斜坡条件下,上覆岩层发生多种变形、破坏的力学特征;陈学军[6]、包惠明[7]等分别将GIS技术、模糊数学理论应用在岩溶塌陷评价模型中,对其易发性进行定量评价。以上方法在塌陷易发性预测中均有较好的效果,但由于岩土体的空间特性特殊,建立力学模型的方法复杂且难以简化;数值模拟难以全面考虑矿山塌陷中的复杂因素,选取合理参数,模糊评判存在超模糊现象。为补充以往研究不足,为此选用BP神经网络进行矿区塌陷的预测研究。BP神经网络具有主动学习、多层次,可以通过学习大量的样本来获得适合的连接权值,反映出各种复杂的非线性关系[8]。综合GIS系统空间分析功能在矿区塌陷预测突出的优越性,采用栅格为评价单元,提高预测精度,最大限度地体现出矿区内部塌陷易发性的空间差异[9],为模型预测提供足够的样本数。
1 矿区塌陷预测评价模型
BP神经网络算法是一种信息处理体系,利用神经网络能够进行复杂的逻辑运算,实现多因子相互作用的非线性关系。BP神经网络由输入层、隐含层和输出层3部分组成[10]。网络训练过程主要信号的正向传播和误差反向传播[11],通过BP算法的迭代依次对隐含层到输出层、输入层到隐含层的权重和偏置进行调节,使权重系数和阈值参数逐渐收敛于合适的值,当相邻2次误差值达到目标精度时,模型趋于合理,训练完成。
1.1 信号的正向传播
设xi为人工神经网络隐含层的输入值,则隐含层输出值Hk为:
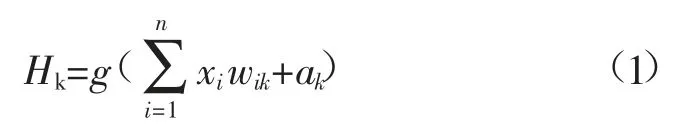
式中:n为输入节点数;wik为隐含层间连接权值;ak为隐含层阈值;g为隐含层激励函数。
激活函数的选取一般认为理想的激活函数是阶跃函数,但阶跃函数具有不连续、不可导的缺点。塌陷预测采用Sigmoid函数:

Sigmoid函数的优势在于其不同于阶跃函数的二值化输出结果,其输出值为(0,1)区间内的可控数值,该数值可以用于表示塌陷易发性的大小。
1.2 误差反向传播
通过连接权值和偏置的更新使误差函数取值逐渐减小,当误差取最小值时,认为这时的权重参数趋于最优解[12]。BP神经网络算法基于梯度下降法来求解修正权值。进行参数的传递分析可以发现存在这样的影响传递链条关系,即wkj影响输出层输出值,最终影响误差的大小。反向传播中权值更新公式:
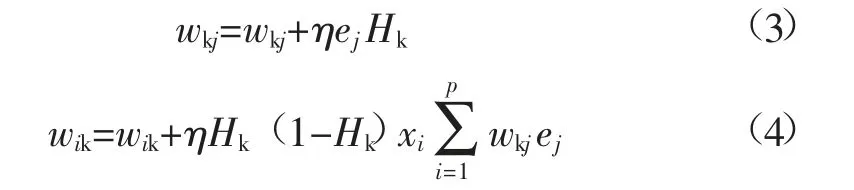
式中:wkj为连接权值;ej为网络预测误差;p为输入节点数;η为学习速率。
当相邻2次之间的误差值小于目标值时认为算法收敛,算法迭代结束[14]。
2 矿区概况及塌陷影响因子分析
2.1 矿区地质概况
研究矿区地处陕西省庙哈孤矿区东南部,该矿区为典型的黄土梁峁地貌,沟壑纵横,梁面宽缓平坦,场地内地势较为平坦。区内地层主要为三迭系细粒石英砂岩,厚度约80~200 m;侏罗系粉砂岩,泥岩夹煤层,厚度约89.78 m,新近系红色黏土,平均厚度3.1 m;第四系黄土覆盖大部分山梁、缓坡,平均厚度24.15 m。
矿区降水较少,年内降水量变化大,水系较发育,流经矿区的水系主要为2条:孤山川河自井田西侧边界穿过,府谷县内流长57 km,流域面积1 018 km2,年平均流量3.48 m3/s,沟谷宽缓;流小南川沟流域面积约6 km2,河流受区域独特的地质地貌条件及气象因素的控制,雨季洪峰多。
井田内设计开采煤层为22、31、42、51、52上、52煤,煤层平均可采总厚度12.22 m。以52煤为例,煤层厚度1.47~3.32 m,平均2.23 m,煤厚变化较小,埋深浅,煤层埋藏深度在0~225.66 m,煤层顶板岩性为1套厚层粉砂岩、局部夹薄层粉砂质泥岩,厚16 m。
2.2 塌陷发育情况
地质灾害类型主要为滑坡、崩塌、塌陷和泥石流,其中因煤矿开采,该地区塌陷显著增多。截至2019年10月,研究区塌陷已增至10余处,目前塌陷有形成贯通的趋势。其中塌陷面积最大达到3 km2,严重影响到矿区煤矿的继续开采以及当地居民日常生活,矿区塌陷分布如图1。
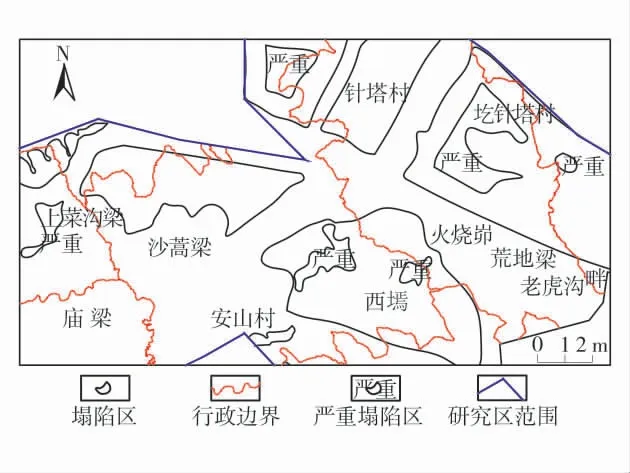
图1 矿区塌陷分布图Fig.1 Distribution map of mining area collapse
以二采区形成的地面塌陷为例,其形成时间为2013—2018年,位于井田中部,走向长度1.91 km,倾斜长度1.06 km,该采区52号煤层平均厚度2.38 m,煤层结构较简单。该地面塌陷区面积较大,塌陷区东侧较宽,向西逐渐变窄,地面裂缝发育,裂缝长约7~50 m。裂缝成组平行发育,间距5~20 m不等,部分裂缝可见深度达1.5 m,两侧错落10~50 cm,在斜坡地带局部发生了滑塌,地面塌陷裂缝方向与采取工作面方向相一致。
2.3 塌陷影响因子选取
2.3.1 数据源
研究区塌陷预测评价建模的数据源主要有:①塌陷编录信息和野外调查获取的相关资料,包括研究区1∶2 000井田勘查报告、矿井建设工程地质灾害易发性评估报告、矿井设计书等;②DEM高程数据,用于提取地形地貌等基础环境因子;③研究区地质调查资料。
2.3.2 影响因子
矿区地面塌陷大多数是由于顶板的破坏而引起的,即矿体被开挖、采掘后,失去下部岩层支持的顶板在自重和次生应力作用下发生剪切或拉裂破坏[13],该矿区采用走向长壁后退式综合机械化采煤方法,全部垮落法管理顶板。研究区垂直剖面由上至下可简化为松散覆盖物、坚硬岩层、含水层等,区内分布构造裂隙,采空区垂直剖面如图2。

图2 采空区垂直剖面图Fig.2 Vertical section view of goaf
在煤层回采后,上覆岩体完全垮落,垮落带可达松散覆盖物底部,在松散覆盖层形成裂隙,使松散层本身发生垮落,导致地表塌陷[14]。
影响矿区塌陷的因素多种多样,各个采区情况具有独特性[15],众多研究表明塌陷的发生是基础环境和工程影响共同作用的结果。采煤方法和顶板管理方法在该矿区不同工作面中相同,在预测模型中不予考虑。塌陷预测模型易发性因素包括:①覆岩强度是反映岩体工程地质特征的最根本因素,直接影响着岩体的物理力学性质及其受力变形的全过程;②水文地质特征,地表水、地下水对岩土体的作用是一种地质应力作用,水与岩土体相互作用改变着岩土体的物理、化学及力学性质;③地质构造主要包括不连续结构面、构造应力,地质构造活动使得岩体中聚集大量的弹性变形能,产生构造应力,受到开挖扰动的影响,构造应力释放使岩体中出现局部应力集中现象,诱发地面塌陷[16];④岩层的变形和破坏是从直接顶开始,自下而上扩散直至地面的渐变过程,终采时间越长,塌陷的易发性越高;⑤采矿工程将岩体中原始应力平衡状态破坏,并使其周围一定范围的岩层应力发生重新分布,而开采深度和跨度是影响着扰动后原岩应力的大小、方向与分布状态的重要因素;⑥采煤高度影响着塌陷的易发程度,当采煤高度较高或多煤层迭置开采时,覆岩经多次塌陷分级传至地面造成地表沉陷,产生大量裂缝。
结合研究区的实际情况,本研究选取研究区3个基础环境因子和5个工程影响因子,其中基础环境因子包括水文特征、地层构造和覆岩强度[17],工程影响因子包括终采时间、顶板跨度、开采深度、采煤高度以及空间迭置层数。矿区塌陷影响因子量化方法及易发性分级见表1。
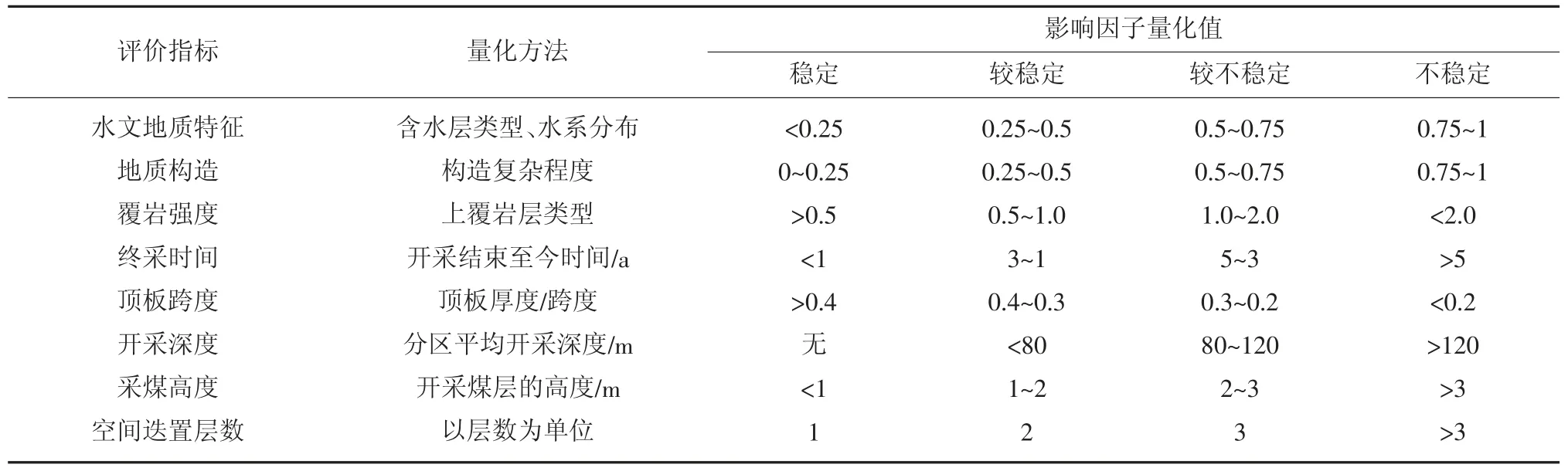
表1 矿区塌陷影响因子量化方法及易发性分级Table 1 Quantification method and stability classification of mining area collapse influence factor
2.4 塌陷易发性单元划分
利用预测模型开展塌陷区易发性预测的1个关键问题是如何进行预测单元的划分[18]。常用的预测单元多为栅格[19]、同期开采区域、行政区划单元等。其中,栅格具有表达目标明确,模型计算效率高,数据后处理易操作等优点[20]。GIS系统具有范围广阔且功能强大的空间分析能力,使用其核心工具集可以将数据快速处理为栅格化,为数据空间分析提供了丰富、便利的环境和算子[21]。
研究利用GIS的数据管理将离散型、连续型数据整合为面数据,利用GIS的空间分析功能对各影响因子进行栅格化,根据矿区现有资料及GIS系统有效精度选择适宜的网格大小为20 m×20 m,将48.9 km2研究区按大小划分为119 762个单元,通过最邻近分配法分别对各影响因子单元进行指标采样,采样后的栅格数据中每1个像元点为包含8个塌陷影响因子的样本组。矿区的8个影响因子分区如图3。
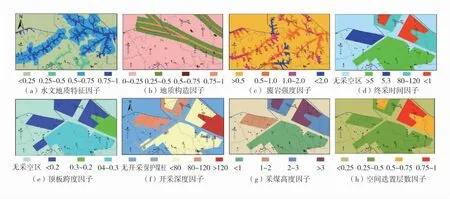
图3 影响因子分区图Fig.3 Impact factor classification
3 矿区塌陷预测
采用GIS系统对矿区影响因子提取466×257个单元,对某些数据偏离平均值过大的畸点取相邻栅格单元平均值,同时为防止由于数据数量级的不统一,对各类评价指标数据进行归一化处理[20]。通过Matlab软件利用矿区中部及南部466×173个单元作为样本进行训练构建BP神经网络模型,并保留矿区北部466×84个单元检验预测结果。
3.1 神经网络模型塌陷预测
神经网络隐含层的确定是建模的1个关键问题,隐含层节点过少,网络难以识别样本,从而无法建立复杂的映射关系,导致模型训练能力降低,预测效果差;隐含层节点过多则会导致网络的过拟合以及训练效率的降低。目前常用的方法是通过多次实验以确定隐含层的最优节点数[22]。参考式(5)~式(7)进行隐含层节点选取:
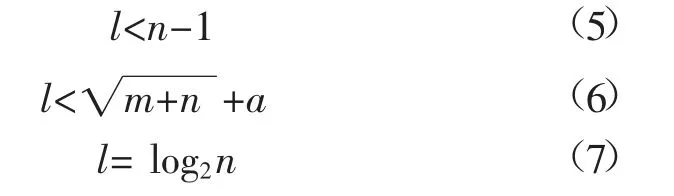
式中:l为隐含层节点数;n为输入层节点数;m为输出层节点数;a为0~10之间的常数。
最终确定隐含层节点数为5。
利用上文生成的输入、输出训练样本在Matlab环境下进行神经网络模型的训练和检验工作。训练使用newff神经网络函数。为保证预测误差较小,隐含层节点传递函数选用S型函数tansig函数,输出层节点传递选用purelin函数,控制学习速率为0.1,选择Levenberg_Marquardt的BP算法训练函数trainlm,性能分析选择均方差性能分析函数mse,误差允许限度设置为1×10-2。训练过程发现迭代次数为2 253时误差达到预期目标,可以认为此时模型训练完成。
将研究区栅格化数据组代入训练完成的神经网络模型,将模型输出结果使用image函数进行图像化,矿区塌陷预测分区图如图4。
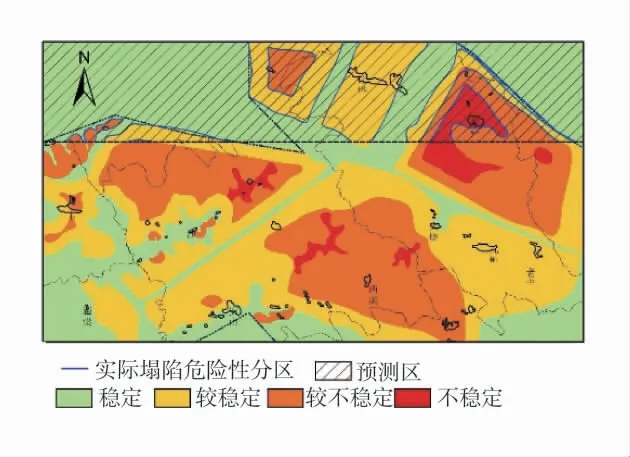
图4 矿区塌陷预测分区图Fig.4 Mine collapse prediction classification
3.2 塌陷预测结果检验
从BP神经网络模型的预测分区图来看,预测区塌陷情况整体符合矿区采空塌陷的实际情况:矿区塌陷主要分布于下部有采空的地区,同时塌陷受到地下巷道支护控制,具备煤柱支护的地区塌陷易发性最低,且支护具备一定区域范围内的塌陷控制能力,将塌陷分割为多个区域且塌陷易发性明显降低。地层岩性变化较小时,上覆岩层硬质岩层占比越大,采空区塌陷的易发性越低。采空区顶板越厚、跨度越小,越不容易发生离层破坏或顶板折断,对应区域塌陷易发性越低。塌陷的易发性在一定程度上受到水文特征的影响,其中,中南部矿区内有水系发育的地区塌陷易发性较高。
为检验BP神经网络的预测结果,根据矿区实际发生的地面塌陷作为检验标准,采用ROC曲线完成神经网络预测模型的结果验证[23]。大量研究表明,ROC曲线可以作为验证预测模型的良好指标[24]。选取矿区北部466×84个单元采用绘制ROC曲线,计算得到曲线下面积AUC=0.902,预测精度可达90.2%,BP模型ROC曲线测试图如图5。

图5 BP模型ROC曲线测试图Fig.5 ROC curve test diagram of BP model
验证结果表明:采用BP神经网络预测模型对矿区地下开采引起的地面塌陷可以很好地达到预期的预测结果。
4 结语
1)采矿区是塌陷地质灾害高发区之一,通过选取3个基础环境因子和5个工程影响因子构建的BP神经网络预测模型,BP神经网络具有很强的主动学习、适应能力,反映出矿区地面塌陷发育过程中各种复杂的非线性关系。
2)结合GIS技术将矿区数据栅格化和人工神经网络模型应用于塌陷易发性分区,可以很好地满足预测精度,同时在训练计算过程中的迭代次数和耗时较少,可以达到快速、优良的收敛效果。
3)将预测模型与实际调查资料进行对比,BP神经网络模型用于矿区易发性预测的效果较好,适用于矿区开采结束后地面塌陷的预测,为环境保护、土地复垦方案以及矿区工程建设提供可行性、科学性及准确性的防治建议。
4)目前建立塌陷预测模型所采集的塌陷实际发生样本均发生在终采6年之内,时间尺度较短,采空区顶板的残余变形、破裂并未完全停止,后期深入研究可根据时间尺度更长的塌陷样本完成矿区地面塌陷预测模型。
猜你喜欢
国外核新闻(2022年7期)2022-11-25
农业工程学报(2022年8期)2022-08-08
舰船科学技术(2022年11期)2022-07-15
中国药学药品知识仓库(2022年9期)2022-05-23
大众科学(2022年5期)2022-05-18
煤气与热力(2022年2期)2022-03-09
矿山安全信息(2021年16期)2021-11-29
今日农业(2021年10期)2021-11-27
北京航空航天大学学报(2021年4期)2021-11-24
今日农业(2021年1期)2021-03-19
