
基于混合CNN的自然语言因果关系抽取方法
2021-10-15 12:48兰飞张宇
计算机应用与软件 2021年10期
兰 飞 张 宇
1(重庆电子工程职业学院 重庆 401331) 2(中国科学院重庆绿色智能技术研究院 重庆 400714)
0 引 言
因果关系抽取是指文本实体间因果关系的自动检测,从自然语言中有效地提取因果关系对于信息检索、问题问答、事件推理和预测等应用变得越来越重要[1-2]。建立因果网络可以归纳以前未知的知识,并将其应用于生物学、生物医学、金融和环境科学等各个领域[3-4]。关系提取主要分为基于规则和基于机器学习这两类方法[5-6]。基于规则的方法需要大量的手工工作来构建手工模式,且由于自然语言中因果关系表达的复杂性,其准确性和召回率较低。基于特征的方法从大量的标记数据中自动推断因果关系,其依赖于所设计特征的质量和外部自然语言处理工具包的准确率,因此设计耗时且容易造成错误积累,影响最终的分类性能[7]。
随着深度学习的盛行,研究人员开始构建没有复杂特征工程的模型,并最小化对NLP工具包的依赖。具有预训练词嵌入的卷积神经网络(Convolutional Neural Network,CNN)是用于关系提取的最先进的深度学习模型之一[8-9]。预训练的词嵌入将词的语义和句法信息编码为固定长度的向量,CNN能够从句子中提取有意义的n-gram特征。与基于规则的方法和基于丰富特征的方法相比,具有单词嵌入的CNN模型能够更有效地提取复杂的因果关系,但这些模型依赖于大量应该涵盖自然语言中的所有因果关系表达式的训练数据[10],这是不切实际的,因为自然语言中词和句子具有多样性和歧义性的特征,并且深度学习模型存在大量的自由参数[11],这些模型容易过拟合且有偏差的训练数据,从而影响深度学习模型的性能。
文献[12]综合卷积神经网络抽取局部特征的优势和循环网络在时序依赖中建模能力,提出了卷积循环神经网络。该模型融合了局部和整体信息,比单独建模局部特征和序列关系的模型在关系抽取上更有效。文献[13]提出了基于无监督上下文建模的分布式文档嵌入,该模型能够从文本中捕获词语义、n-gram特征和需要较少的训练数据,得到包含语义相似的n-gram特征的文档在向量空间中具有更紧密的嵌入。文献[14]提出了基于n-gram特征的文档向量的嵌入方法,该方法允许以固定长度、连续和密集特征向量表示文档。但以这种方式学习的嵌套不适合直接用于因果关系提取,因为具有语义相似n-gram特征句子可能涉及因果关系,也可能不涉及因果关系。
本文基于上面的研究,提出用于自然语言因果关系抽取的高效的混合卷积神经网络MCNN,该模型以互补的方式结合人类的先验知识和在数据中学习到的信息从自然语言中抽取因果关系。面向知识的通道将因果关系的语言知识整合到词汇知识库以捕获因果关系的重要语言线索;面向数据的通道基于传统的CNN从训练数据中学习因果关系的其他重要特征,基于词过滤选择和聚类技术来去除冗余特征,通过减少模型的自由参数来解决由于缺乏训练数据而导致的过拟合问题,最后在三个因果关系抽取数据集上对模型进行验证。
1 基于MCNN的因果关系抽取
本文设计的MCNN包含二个传统的CNN通道:面向知识通道和面向数据通信,这两个通道相辅相成,从不同的角度提取因果关系的有用特征,总体结构如图1所示。它基于词汇知识库自动构建CNN的卷积过滤器,使模型能够有效且准确地从自然语言文本中提取重要的因果关系线索,从而缓解深度学习模型的过拟合问题。
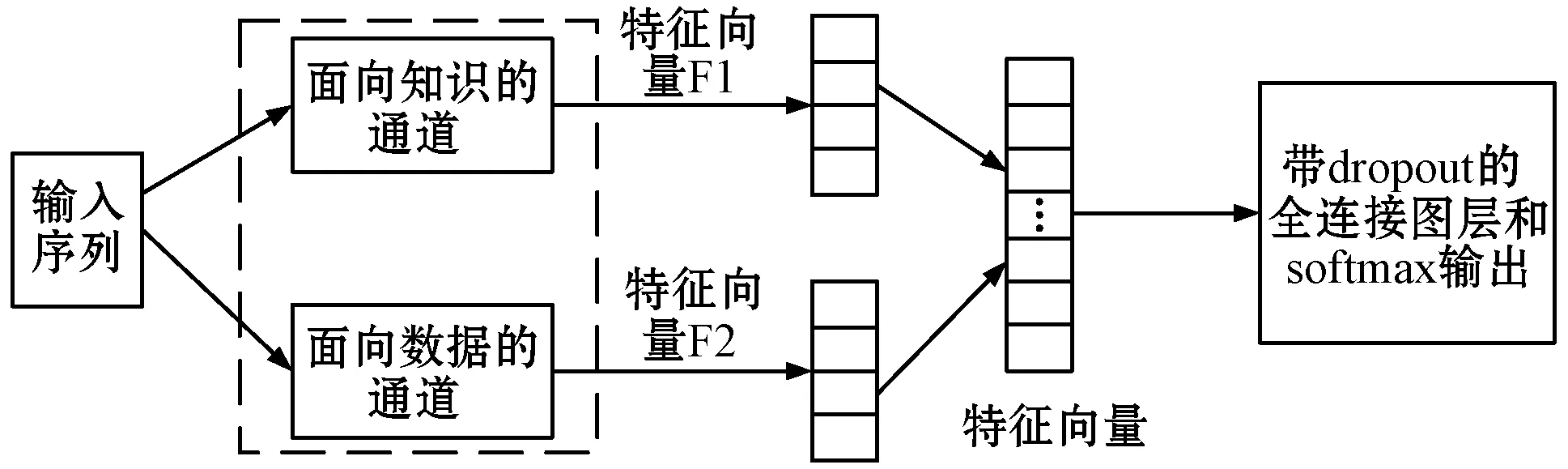
图1 MCNN的总体设计结构
1.1 面向知识的通道
面向知识的通道用来有效地从句中提取因果关系的关键字和提示短语,该通道基于词汇知识库中因果关系的语言知识自动生成的卷积过滤器。与传统CNN中的卷积过滤器相比,词过滤器能够更精确地反映因果关系的语言线索,它的权重是词的嵌入,这些单词通过预先训练可以直接使用而无需任何额外的训练,因此,可以显著减少模型的自由参数,缓解训练数据量较小时的过拟合问题。
1.1.1句子表示
MCNN的输入是标有两个目标实体e1和e2的句子,用于因果关系识别。关键字和提示语出现在距离两个目标实体较远的地方,可能无法提供信息和影响分类结果。为了消除噪声并有效地从句中提取语言线索,MCNN仅使用两个目标实体间的单词作为面向知识通道的输入。为了捕获词的语法和语义信息,查找使用大型语料库预先训练的单词嵌入表Wwrd∈Re×|V|,每个词由向量w∈Re表示,其中e是单词嵌入向量的维数,|V|是词汇量。由于CNN仅适用于固定长度的输入,所以句子中单词标记的数量固定为n1,这是e1和e2间的最大词数。使用具有零嵌入向量的特殊填充字符填充具有少于n1个标记的句子。因此,输入序列xk={x1,x2,…,xn1}表示为实值向量序列embk=[w1,w2,…,wn1]。
1.1.2自动生成字过滤器库
这个过程基于人类对因果关系的先验知识自动生成CNN的卷积滤波器以进行因果关系抽取,而无须使用大量数据来训练模型。这种方式构造的词过滤器具有表示因果关系的关键字和提示短语的物理均值,比从训练数据中学习的传统卷积过滤器更精确。此外,这些过滤器的权重是静态值,而不是模型中的自由参数,模型中的自由参数数量显著减少,从而缓解训练数据量较小时的过拟合问题。
1.1.3卷积和池化运算
为了捕获句中因果关系的重要语言线索,将生成的词过滤器与句中的n-gram特征进行卷积以生成相似性分数序列。与基于规则的方法相比,MCNN能够捕获除词过滤器库中的单词以外的语义相似的因果词。具体而言,词过滤器f=[f1,f2,…,fk]T与输入矩阵embk=[w1,w2,…,wn1]进行卷积,其中k∈[1,2,3]为卷积窗口大小,也表示句子中的k-gram特征。本文改进了CNN的传统卷积运算以使每个词过滤器生成一个特征映射m=[m1,m2,…,mn1-k+1],其中mi表示词过滤器f和wkgram=[wi,wi+1,…,wi+k-1]T间的相似度,改进的卷积运算如下所示:
(1)
式中:b为偏差项。与将非线性函数应用于卷积结果的传统CNN不同,本文将卷积结果除以窗口大小k。通过将fj和wi+j-1(词嵌入)限制为单位向量,mi表示f和wkgram间的余弦相似度。在特征图中产生余弦相似度是为了使所有卷积窗口大小的比例相等,从而实现不同长度的词过滤器具有相同的重要性。
采用最大池化来进一步聚合每个滤波器的卷积结果,并从特征映射中提取最重要或最相关的特征。每个特征映射的最大池化操作如下:
p=max{m}=max{m1,m2,…,mn1-k+1}
(2)
从特征映射中获取最大值的原因是最大余弦相似度表明句子中存在因果关键字或提示短语的强线索。
1.1.4词过滤器选择和聚类
为了提高模型性能,本文使用词过滤器和聚类技术进行降维。词过滤器选择先删除由没有提供足够的类可分离性的词过滤器产生的非辨别性特征,基于训练数据及其标签,使用方差分析(Analysis of Variance,ANOVA)F值评估每个特征的可分离性,以衡量类均值间的差异程度。若F值很小,类别均值几乎相近,则该特征对分类没有帮助;若F值较大,至少有一个类别的均值与其他类别不同,则该特征能够为分类器提供有用的信息以区分该类别与其他类别。通过取类间均方比(Mean Square Between Classes,MSB)与类内均方比(Mean Square Within Classes,MSW)来计算在最大池化层后生成的每个特征的F值比率:
(3)
式中:SS为平方和;df为自由度;c为类别数量;N为所有样本数量;ni为类别i的样本数量;GM(总体均值)为所有样本的均值;Mi为类别i的均值;xij为类别i中的第j个样本。
在计算每个特征的F值后,基于自由度为(c-1)和(N-c)的F值的F分布进行假设检验。零假设H0设所有类均值相等,显著性水平为α=50%,并且能够从F分布中找到临界F值Fα。若F>Fα,则可以拒绝H0并保留相应的滤波器,因为它能够提供类均值的可分离性;若F≤Fα,则删除相应的滤波器。
词过滤器的聚类除去非分离特征后,仍然存在许多会产生相同或接近的值的冗余特征,这将增加模型的维数和损害分类性能。这些冗余特征由具有相近单词嵌入的语义相似的单词过滤器产生,本文根据词过滤器的语义相似度对其进行聚类,以解决特征冗余问题。
对bi-gram词过滤器,将两个词嵌入连接起来以形成单个向量表示,然后执行K-均值聚类算法,分别找到uni-gram和bi-gram词过滤器的聚类。基于这些聚类,对CNN的最大池化层后的特征执行进一步的池化操作。对于与第i个聚类中的词过滤器相对应的特征{pi1,pi2,…,pin},用式(4)执行最大池化或平均池化。
(4)
最大池操作保留了句子中最重要的语言线索,而平均池操作考虑所有词过滤器。由于池化操作将一个簇内的特征聚合成单个特征,所以降低了特征向量的维数。面向知识的通道的特征向量维度由用户设置的uni-gram和bi-gram词过滤器的聚类数量确定。
1.2 面向数据的通道
面向数据的通道用来从训练数据中学习因果关系的重要特征,它通过使用更长的卷积窗口来捕获整个句子中更长的相关性。卷积滤波器根据训练数据来调整其权重,给予模型足够的能力来学习较长的相关性和面向知识通道所忽略的重要信息。因此,面向数据通道和面向知识通道相辅相成,使得MCNN能够有效地从句中提取因果关系。
1.2.1句子表示
为了保留除e1和e2之间的单词以外的词信息,面向数据通道的输入包含该句子中的所有单词,句子中的最大字数(n2)可以非常大,但CNN不能捕获词在句中的位置信息,并且词出现在距离e1和e2较远的地方,可能没有信息性。
1.2.2卷积和池化运算
卷积滤波器f=[f1,f2,…,fk]T被随机初始化并通过反向传播进行训练,其中fi∈Re+2d,k为卷积窗口大小。为了捕获句中更长的相关性,使用更宽的窗口大小(k=3,4),将输入语句的表示简化为embD={x1,x2,…,xn},该通道中的卷积运算如下:
(5)
式中:tanh是双曲正切函数,b为偏差项。得到的特征映射m=[m1,m2,…,mn-k+1]被传递到与面向知识通道中相同的最大池化层,以提取最重要的特征。滤波器的数量r是用户选择的超参数,它确定面向数据通道的输出维数。
1.3 规则化和分类
最终的特征向量p∈Rh+r由面向知识的通道输出和面向数据的通道输出组成,代表MCNN提取的输入语句的高级特征。在将特征向量传递给分类器以做出因果关系的最终判断之前,应用dropout正则化则,防止出现过拟合问题。
pd=p∘b
(6)
式中:∘表示逐元素乘法,并且b∈Rh+r是以概率为ρ的伯努利分布随机生成的向量。然后特征向量pd作为分类器的输入以预测类别标签。分类器由标准神经网络的全连通层和预测类概率的softmax层组成。
本文通过最小化分类交叉熵损失函数来训练模型。用于训练的自由参数包括位置嵌入矩阵、面向数据通道的滤波器权重、完全连接的层权重和softmax层权重的分类器权重。用带有自适应学习率调整更新规则的小批量随机梯度下降进行训练。
2 实验与结果分析
为了评估本文MCNN模型在因果关系抽取中的有效性,采用关系抽取数据集SemEval-2010 task 8与Causal-TimeBank和Event StoryLine进行实验。将测试结果与使用位置嵌入和训练单词嵌入的具有单个窗口大小(k=3)的滤波器方法(简称SingleCNN)和具有多个窗口大小(k=2,3,4,5)的滤波器和微调预先训练的单词嵌入方法(简称MultiCNN)[12]进行分析比较。
实验的所有模型采用的是预训练的基于依赖关系的词嵌入,词嵌入是维度为e=300维的在训练期间保持静态的单位向量;位置嵌入的维度为d=20,dropout正则化概率ρ=0.4,训练的最小批量为20个,softmax层之前的隐藏层的维数是特征向量维数的一半。对于未在词嵌入中的词,初始化为具有与词嵌入量相同维数的随机单位向量。
2.1 面向数据的通道效果
为了研究面向数据通道的影响并找出其最优滤波器数,本文对范围从0到100的滤波器数量进行网格搜索,使用根据10倍交叉验证计算得出的宏平均F1分数进行评估,三个数据集的网络搜索结果如图2所示。
从图2可以看出面向数据通道中每个窗口大小的最佳滤波器数量在25到30之间。进一步增加滤波器数量将导致F1得分下降,且模型性能不稳定。这是因为,当自由参数的数量很大且训练数据有限时,该模型容易过拟合。与通常使用数百个卷积滤波器的传统CNN相比,所设计的MCNN的面向数据通道中所需的滤波器数量显著减少。
2.2 面向知识通道效果与维度缩减
表1给出了在数据集SemEval、CausalTB和EventSL上提取因果关系的人工模型的宏观平均F1得分。可以看出与SingleCNN和MultiCNN相比,本文MCNN能够更有效地提取因果关系,这是因为MCNN基于词汇知识库自动构建词过滤器,比随机初始化的卷积过滤器对因果关系的关键词和提示短语具有更精确的表示和更广泛的覆盖率。面向知识通道和面向数据通道的有效结合使模型能够捕获因果关系的重要特征。表2给出了SemEval-2010 task 8数据集的关系类型,例1中在数据集SemEval-2010 task 8上关系实例,MultiCNN判定为Other类别,而本文的模型则正确标识为Cause-Effect类,可以看出不同算法对于例1处理结果的差异。

表2 SemEval-2010 task 8数据集的关系类型
例1:The tsunami generated by earthquake killed hundreds of thousands of people.
<译>:地震引发的海啸使数十万人丧生。
实体1 earthquake
实体2 tsunami
关系 Cause-Effect
为了研究MCNN在缓解过度拟合中的有效性,在训练集上训练MCNN和MultiCNN,并在训练集和验证集上测试模型,测试模型的学习曲线由图3到图5给出。

图3 SemEval-2010 task 8数据集上的学习曲线
可以看出训练集和验证集上的宏观平均F1得分随训练次数的增加而增加,两个模型的训练集得分最终都可以达到100%,训练得分和验证得分间的差距实际上是由于训练数据上的模型过度拟合造成的。本文MCNN在验证集上比MultiCNN获得了更高的得分,这表明MCNN能够缓解过拟合问题。MCNN的训练速度比MultiCNN更快,这是因为MultiCNN需要从头开始训练所有参数,而MCNN只需要训练面向数据的通道,面向知识的通道由于已经包含许多有用信息可以在训练前提取因果关系。
3 结 语
为了能够有效地抽取自然语言因果关系和解决训练数据量较小时的过拟合问题,本文提出了一种高效的混合卷积神经网络(MCNN),它包含面向知识通道和面向数据通道两个传统CNN通道。面向知识的通道基于词知识库自动生成卷积过滤器,以捕获因果关系的语言线索;面向数据的通道从数据中学习因果关系的其他重要特征,通过减少模型的自有参数来解决由于缺乏训练数据而导致的过拟合问题。实验表明,与SingleCNN和MultiCNN相比,本文MCNN在因果关系提取方面性能更好。未来的工作是研究如何自动选择用于因果关系识别的目标实体以及如何更有效地提取复杂的因果关系。
猜你喜欢
客联(2022年4期)2022-07-06
成都信息工程大学学报(2022年2期)2022-06-14
高中生·天天向上(2018年7期)2018-07-23
科学与技术(2018年16期)2018-05-16
法制博览(2018年12期)2018-03-08
儿童故事画报·发现号趣味百科(2017年4期)2017-06-30
发明与创新·大科技(2017年5期)2017-05-16
计算机应用(2016年10期)2017-05-12
智能计算机与应用(2016年1期)2016-03-02
江淮论坛(2013年6期)2013-11-16
