
面向对话的融入交互信息的实体关系抽取
2021-10-12 04:39陆亮,孔芳
中文信息学报 2021年8期
陆 亮,孔 芳
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
实体关系抽取旨在从非结构化文本中获取实体间所具有的语义关系,抽取出来的信息以三元组
目前,受限于语料资源,实体关系抽取相关研究多集中于新闻报道、维基百科等规范文本。而这类文本通常由专业人士编辑,行文规范,文本内容的信息密度大。随着DialogRE[4]数据集的发布,针对对话文本的实体关系抽取研究得以展开。相较于规范文本,对话文本的特点明显,主要体现在: ①对话中存在大量指代和省略现象,特别是人称代词出现频率较高; ②相比规范文本,对话文本中信息密度较低,存在关系的实体对通常出现在不同对话语句中; ③对话内容通常围绕某些特定主题在交互过程中向前推进,因此对话的交互过程蕴含了大量重要信息。因此,在规模有限的对话文本中如何尽可能多地提取有效特征,特别是隐藏在交互过程中的信息,构建面向对话文本的实体关系抽取模型则更具挑战性。
本文采用轻量级的Star-Transformer[5]模型作为主模型,基于这一模型进行了两个核心工作: ①关注对话交互信息: 目前已有的研究在处理对话语料时大多选择直接将对话拼接成一段长文,这样做的后果是模型难以获取到对话交互过程的信息。本文以对话者的一问一答作为一轮对话,依次选出两轮对话,使用交叉注意力机制[6]挖掘它们之间的关联信息,最后整合所有的关联信息来表征整个对话对应的交互信息。②降低数据不均衡的影响: 通过分析语料我们发现,语料中共包含37种关系,其中,无明确(unanswerable)关系的数量占到了样本总数的21.5%,远大于其他类型的关系。同时,语料中37.6%的样本中包含触发词(trigger),即实体关系是通过某个具体的触发词来传递的。为了解决语料中关系分布不均衡的问题,我们在主模型之上加入了多任务层,通过增加两个辅助任务来辅助主任务的完成。实验结果表明,本文提出的Star-Transformer+交互信息+Multi-task模型在DialogRE公开数据集上的F1值为54.1%,F1c值为50.7%,证明了本文方法的有效性。后续章节中统一使用STCM代表本文所提出的方法。
本文组织结构安排如下: 第1节介绍实体关系抽取相关的研究,第2节介绍对话文本中实体关系抽取任务的定义和评价方法,第3节详细介绍融入交互信息的实体关系抽取模型,第4节介绍实验过程及对实验结果的详细分析,第5节是结论。
1 相关研究
近年来深度学习逐渐崛起,学者们将深度学习应用到实体关系抽取任务中。Zeng[7]等人在2014年首次使用CNN进行关系抽取,Katiyar[8]等人在2017年首次将注意力机制Attention与递归神经网络Bi-LSTM结合使用来提取实体和分类关系,Wang[9]等人提出的CNN架构使用了一种新颖的多层次注意力机制提取指定实体的注意力和指定关系的池化注意力。Zhang[10]等人在2018年将一种新的修剪策略和定制的图卷积网络相结合。Guo[11]等人在2019年提出了注意引导图卷积网络,直接以全依赖作为输入,该模型可以更好地利用全依赖树的结构信息。李青青[12]等人在2019年提出了一种基于Attention机制的主辅多任务模型,通过多个关联任务共享信息提升性能。刘苏文[13]等人在2020年提出一种二元关系抽取和一元功能识别共同决策的联合学习模式,能够融合各个子任务的信息。更多改进的深度学习模型在实体关系抽取任务中取得了巨大进步,学者们不再满足于句子级的实体关系抽取,难度更大的篇章级实体关系抽取任务渐渐成为研究重点。Quirk[14]等人于2017年借助远程监督生成了生物领域的跨句子实体关系抽取数据集。Yao[15]等人在2019年发布了DocRED数据集,该数据集覆盖丰富的领域,并且提供了人工标注和远程监督两个版本。
然而目前主流的用于实体关系抽取的数据都是针对新闻报道和维基百科这类规范文本的,DialogRE数据集的出现将学者们的目光吸引到针对人类对话的实体关系抽取。Yu等人在发布数据集的同时将一些主流的神经网络模型如CNN、LSTM、Bi-LSTM和BERT[16]等应用到了该任务上,没有针对对话文本的特点进行处理,同时也没有针对数据分布不均衡的问题进行模型的改进。本文给出了一个基于Star-Transformer的实体关系抽取框架,并针对对话文本的特性进行了交互信息的融入,同时结合多任务学习策略来提高模型在对话文本上实体关系抽取的性能。
2 任务定义和评价方法
本节介绍对话文本中实体关系抽取任务的定义以及针对该任务提出的评价方法。
2.1 对话文本中的实体关系抽取
给定一段对话D=s1:t1,s2:t2,…,sm:tm和一个实体对(a1,a2),其中,si和ti分别代表第i轮对话的对话者和他说的话,m代表总的对话轮数。模型需要提取出现在D中的a1和a2之间的关系,图1给出了一个具体的例子,在给定的对话文本中,根据下划线部分可以判断出“Speaker 2”和“Frank”之间的关系是“per: siblings”,而触发词就是“brother”。

图1 对话语料及其提取的关系三元组
本文采用Yu等人提出的两种方法来评估模型性能,下面分别介绍两种评价方法。
2.2 标准评价方法
在标准评价方法中,将对话D视为文档d,模型的输入是对话全文d和实体对(a1,a2),输出是基于d的a1和a2之间的关系。实验采用准确率P、召回率R和F1值对识别结果进行评价[17]。
2.3 对话评价方法
在对话评价标准中,将第i(i≤m)轮对话视为d,采用一种新的衡量标准: 对话准确率(Pc)和对话召回率(Rc)的调和平均值F1c,作为F1的补充。下面介绍如何定义F1c。当输入为a1、a2和第i轮对话时,Oi表示输出的预测关系集合。对于实体对(a1,a2),L表示它对应的人工标注的关系类型集合。R表示37种关系类型的集合,且Oi,L⊆R。定义一个辅助函数f(x),若x没有出现在对话D中返回m,否则返回x第一次出现时的对话轮次。定义辅助函数Φ(r): (1)对于每个关系类型r∈L,如果存在一个r的人工标注的触发词,则Φ(r)=f(λr),λr表示触发词,否则Φ(r)=m。(2)对于每个r∈RL,Φ(r)=1。
第i轮对话的关系类型集合可以用Ei来评价,Ei的定义如式(1)所示。
Ei={r|i≥max{f(a1),f(a2),Φ(r)}}
(1)
式(1)表明,给出第i轮对话中包含的d,如果a1,a2和r的触发词都在d中,那么a1和a2之间的关系r是可评估。该定义是基于以下假设: 根据实体对和触发词的位置,可以大致估计需要多少轮对话来预测两个参数之间的关系。
对话准确率的定义如式(2)所示,对话召回率的定义如式(3)所示。
对所有实例的对话准确率和对话召回率进行平均,以获得最终的值,计算过程如式(4)~式(6)所示。
在标准评价方法中,模型的输入可以利用整个对话全文,而在对话评价方法中,模型的输入只可以利用根据上述方法得到部分对话。通俗来讲,F1c值就是来评价模型在尽可能少的对话轮数中快速识别出实体间关系的性能。
3 融入交互信息的实体关系抽取模型
本节介绍融入交互信息的实体关系抽取模型及其所用到的相关技术。
3.1 STCM模型
与大多数实体关系识别方法一样,本文也将对话关系抽取任务转化为一个分类任务。在把对话D和实体对a1和a2拼接成一段长文的基础上,拼接上通过交叉注意力机制获取到的交互信息作为模型的输入。图2给出了STCM模型的结构,该模型主要包含三个部分: ①获取对话交互信息层。②基于Star-Transformer的序列编码层。③多任务学习层。
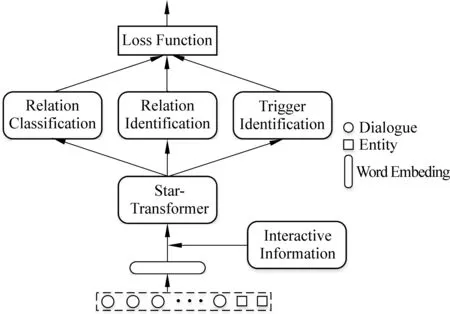
图2 STCM模型结构
3.2 获取对话交互信息层
本文将对话者的一问一答看作一轮对话ui,每个训练样本中平均包含7.5轮对话,依次从中提取出两轮对话来模拟交互过程,使用交叉注意力机制来捕获这两轮对话的关联信息,最后把所有得到的关联信息进行整合得到我们需要的交互信息C。具体过程如图3所示。
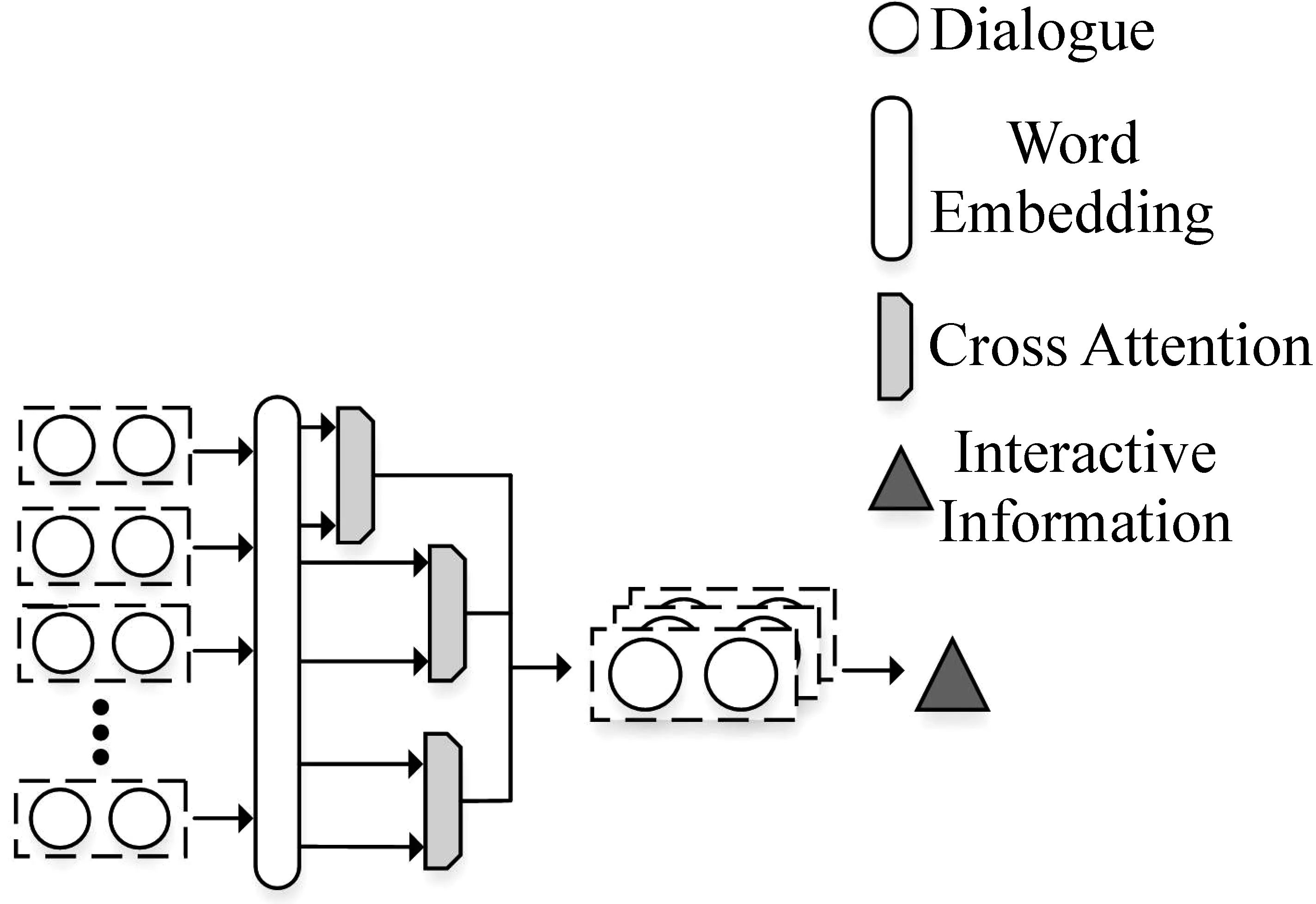
图3 获取对话交互信息
其具体计算过程如式(7)、式(8)所示。
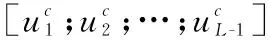
交叉注意力机制的工作原理如图4所示。
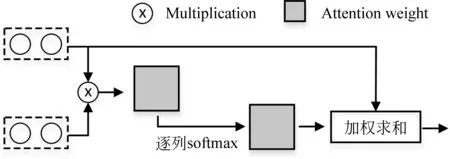
图4 交叉注意力机制
注意力权重的计算如式(9)所示。
ejk=(uij)Tu(i+1)k
(9)
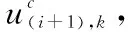
3.3 基于Star-Transformer的编码层
虽然Transformer在很多NLP任务上都取得了很大的成功,但是其结构较复杂,注意力连接是完全连接的,这导致了它对大量训练数据的依赖。为了降低模型的复杂性,Guo[5]等人提出用星状拓扑结构代替全连通结构来简化架构。本节将详细介绍Star-Transformer的相关内容。
3.3.1 Multi-Head Attention
文献[18]中提出了Transformer结构,首先介绍其中的缩放点乘积注意力(Scaled Dot-Product Attention),其本质上是使用点积进行相似度计算。Scaled Dot-Product Attention的计算如式(12)所示。
(12)
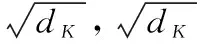
在此基础上,考虑到一个attention机制无法从多角度、多层面地捕获到重要的特征,所以使用多头注意力(Multi-Head Attention)机制,把多个自注意力连起来。Multi-Head Attention的计算如式(13)、式(14)所示。
3.3.2 Star-Transformer
Star-Transformer是基于Transformer结构优化的产物,模型复杂性从二次降低到线性,同时保留捕获局部特征和长期依赖关系的能力。如图5所示,由一个中继节点s和n个卫星节点组成,第i个卫星节点的状态表示文本序列中第i个Token的特征。中继节点s充当虚拟中心,在所有卫星节点之间收集和散布信息。
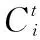
在更新信息后,使用层归一化操作,如式(17)所示。
(17)
在更新中继节点时,中继节点s汇总所有卫星节点的信息以及之前的状态,如式(18)、式(19)所示。
通过交替更新卫星节点和中继节点,Star-Transformer可以捕获局部特征和长期依赖关系。
3.4 多任务学习层
全共享多任务模型的具体结构如图6所示。除了输出层外,模型的所有参数在多个任务之间都是共享的。每个子任务都有一个特定的输出层,它根据全共享Star-Transformer网络产生的表征进行分类。
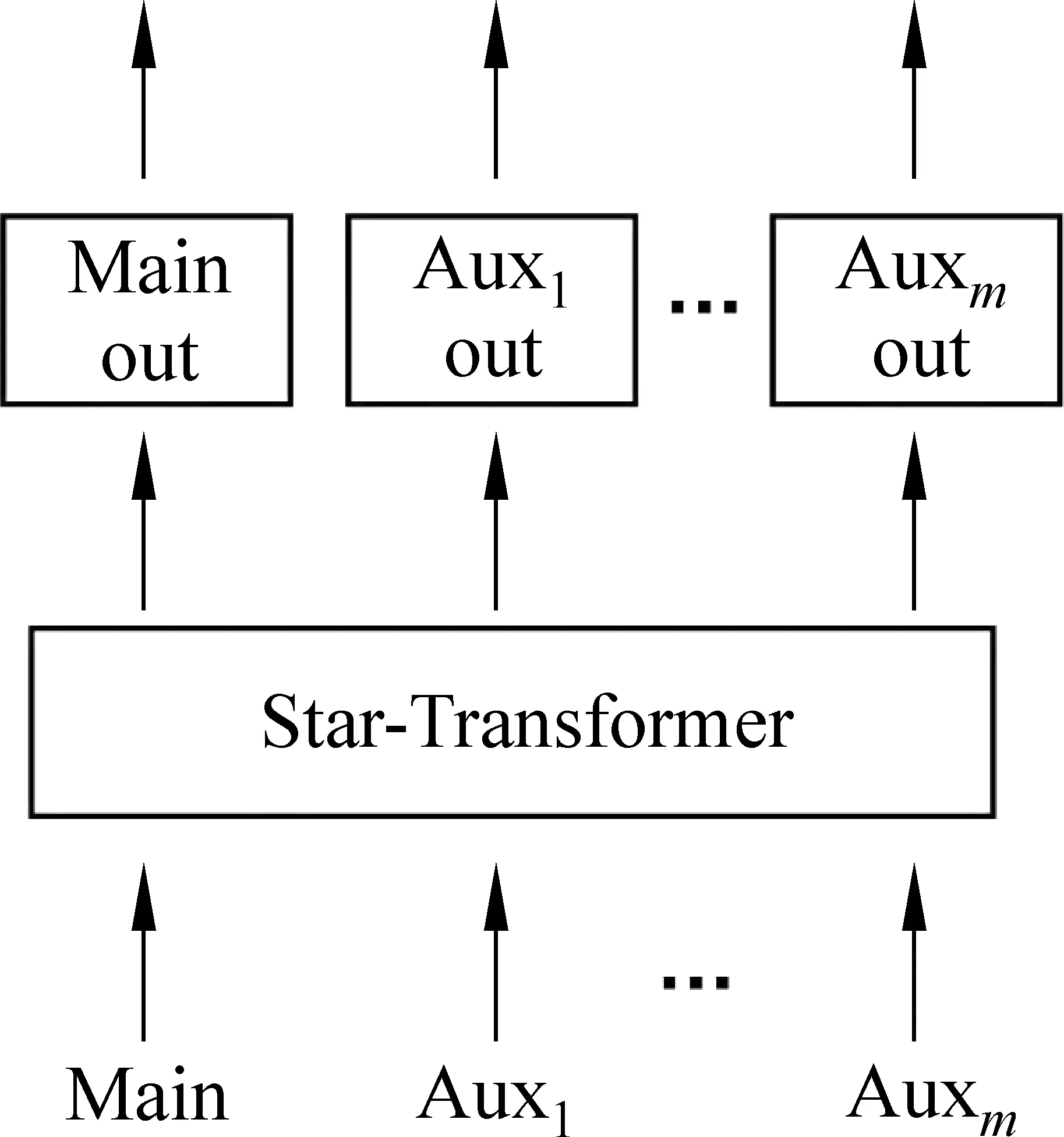
图6 全共享多任务模型
我们通过添加两个辅助任务来缓解数据分布不平衡带来的问题。具体来说,实体关系识别为主任务,二元关系识别为辅助任务,第一个辅助任务判断两个实体之间关系类型是否为unanswerable,第二个辅助任务判断两个实体在对话中是否含有触发词。三个任务分类器共享相同的上下文表征嵌入,因此它们可以通过互相传播监督信号来彼此帮助,最终的Loss由三个任务各自的loss按照一定权重相加得到,其计算如式(20)所示。
Loss=lossmain+α1·lossaux1+α2·lossaux2
(20)
其中α1和α2是两个辅助任务各自的权重。
4 实验设置与结果分析
前文介绍了融入交互信息的实体关系抽取模型,模型通过融入对话中隐藏的交互信息和多任务学习而提升模型性能。本节将使用Yu等人发布的DialogRE数据集进行实验,并对实验结果进行分析。
4.1 实验数据集
本文采用Yu等人发布的已经划分好的DialogRE语料,该数据集收集了美剧《老友记》中的人物对话,通过人工注释的方式在1 788段对话中标注了10 168个实体关系对,涵盖了37种关系。表1详细地给出了该语料的结构,可以看出该语料整体规模不大。
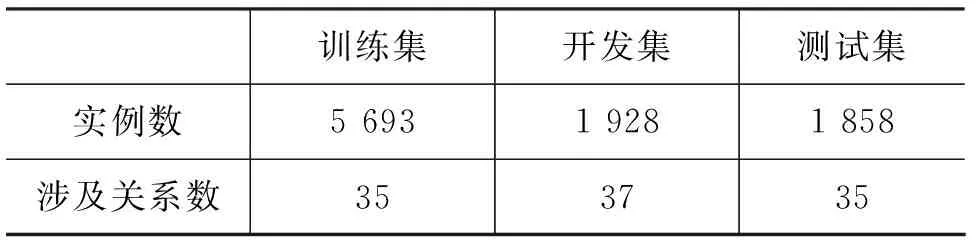
表1 DialogRE数据集结构
DialogRE语料的对话分析如表2所示,每段对话平均包含4.5个关系三元组和7.5轮对话。此外,65.9%的关系三元组不出现在同一轮的对话中,所以有大量信息隐藏在对话的交互过程中,这些交互信息在面向对话的实体关系识别任务中起着重要作用。
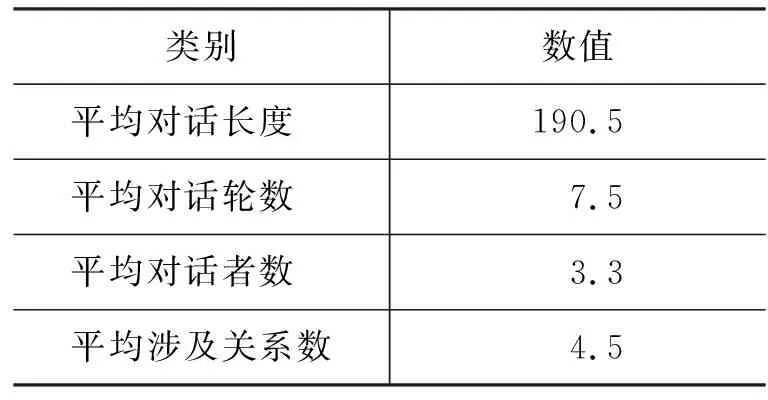
表2 DialogRE语料对话统计
4.2 实验设置
实验中采用PyTorch 1.1.0框架,并用NVIDIA的1080GPU进行了加速。和Yu等人的基准模型一样,本文使用GloVe[20]预训练词向量进行初始化,Embedding_dim为100,Batch_size为24,最大句子长度设置为512,学习率为3e-5,主函数以及两个辅助函数的损失函数使用的都是BCEWithLogitsLoss,用Adam[21](Adaptive Moment Estimation)算法优化模型参数。Star-Transformer的d_model是100,d_head是4,layers是2,Dropout设置为0.1。第一个辅助任务的loss值权重为0.000 3,第二个辅助任务的loss值权重为0.000 3。
4.3 实验结果及分析
实验采用F1值和F1c值对识别结果进行评价,表3给出了各个模型的实验结果,其中,前三个模型是Yu等人给出的基准模型。从表中可以看出,本文提出的STCM模型在综合性能F1值上达到了54.1%,F1c值上达到了50.7%。实验证明,使用Star-Transformer模型作为基准框架,融入对话交互信息和多任务学习可以有效提升模型在对话文本中进行实体关系识别的性能。
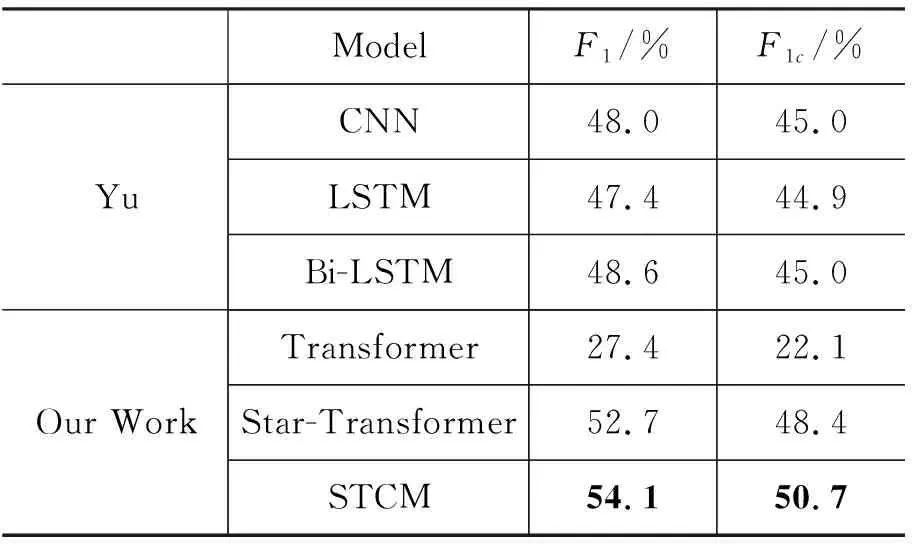
表3 对话关系抽取实验结果
4.4 交互信息的效用分析
关于交互信息的效用,本文将通过分析表4中的实验结果来证明。
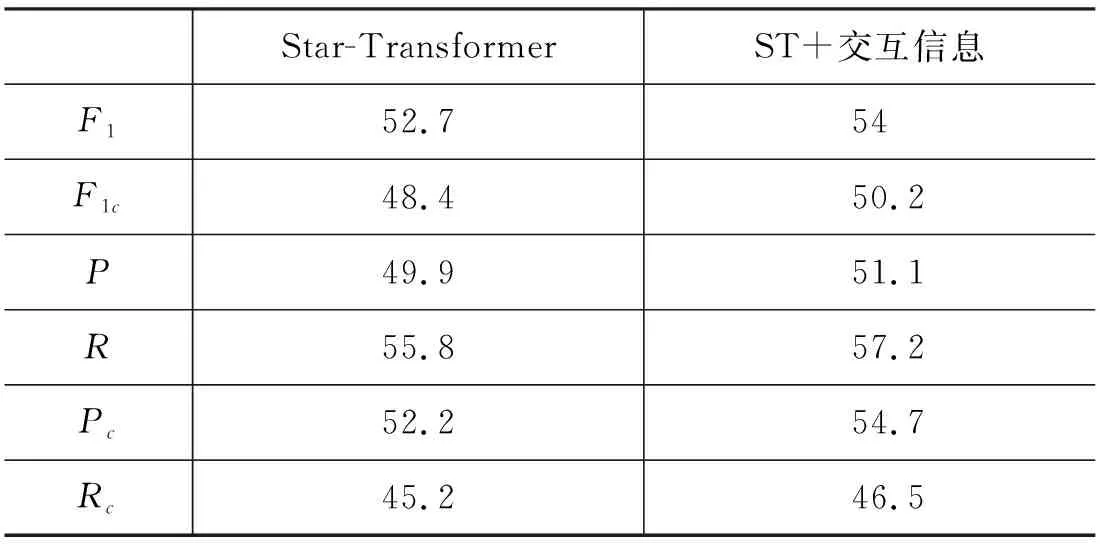
表4 交互信息的效用分析(%)
实验结果显示,在融入对话交互信息后,模型的所有指标都得到了提升,其中提升最明显的是Pc,上升了2.5%,说明模型在得到较少轮数的对话特征时,交互信息显得尤为重要,它可以帮助模型快速辨别实体对之间的关系。例如,在图1的例子中,对话“Speaker1: Any sign of your brother?”中的“your brother”和对话“Speaker2: No, but he’s always late.”中的“he”有关联语义,而其中的“he’s always late”又与对话“Speaker2: …Frank’s always late.”中的“Frank’s always late”有关联语义,交叉注意力机制可以挖掘上下文中的这种有关联性的词,帮助模型把“he”和“Frank”联系在一起,然后通过触发词“brother”识别出“Speaker2”和“Frank”之间的关系是“per: siblings”。
4.5 Multi-task的效用分析
关于多任务的效用,本文将通过分析表5中的实验结果来证明。
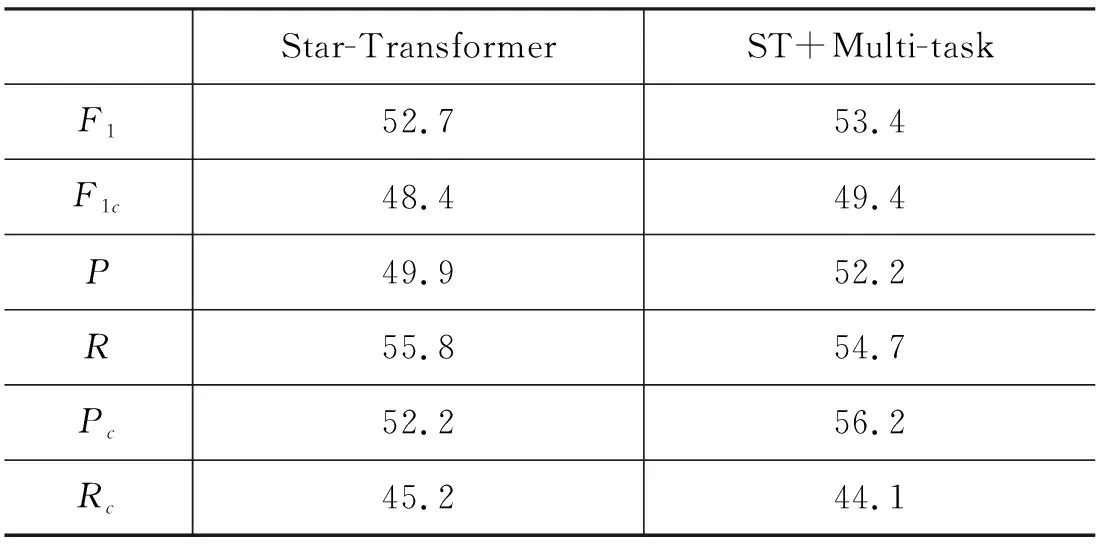
表5 Multi-task的效用分析(%)
实验结果显示,在使用多任务学习后,召回率R值和对话召回率Rc值都出现了一定程度的下降,说明原先存在无关系的实体对被错分到了别的关系,模型在结合两个辅助任务的学习后将原本的错误分类纠正。所以准确率P值上升了2.3%,对话准确率Pc值上升了4%,二者的巨大提升使得模型的整体性能提升。同时我们分析结果发现,仅使用Star-Transformer时模型对unanswerable关系的识别准确率是68%,而在使用了多任务学习后模型对该关系的识别准确率达到了87.3%,说明多任务学习确实帮助模型缓解了语料库数据分布不均衡的负面影响,只是目前语料库的规模较小,所以多任务学习只发挥了部分作用。我们认为在扩大语料库规模后,多任务学习可以更好地帮助模型提升性能。
4.6 在BERT上的进一步实验
面向对话的实体关系抽取,用于在对话过程中进行用户画像,因此对模型的响应速度有很高的要求,Star-Transformer这一轻量级框架在响应速度上优于BERT模型,因此我们并未直接比较两者的性能,而是把交互信息和多任务模块添加到BERT模型中,即BERT_CM,实验结果如表6所示。
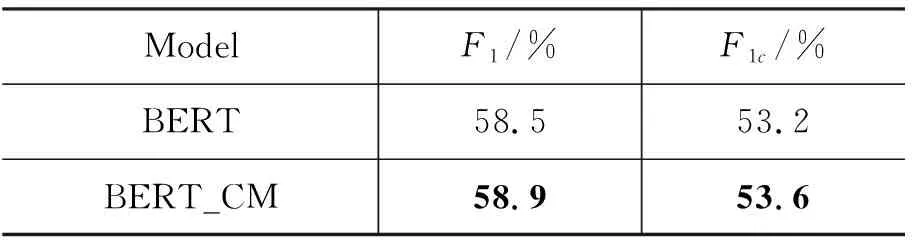
表6 BERT_CM实验结果
本文提出的交互信息和多任务模块进一步提升了BERT的性能,证明了方法的有效性。
5 结论
本文提出了面向对话的融入交互信息的实体关系抽取模型STCM。模型基于Star-Transformer这一轻量级框架来编码特征,通过交叉注意力机制从模拟交互过程的对话文本中获取交互信息,同时使用多任务学习来解决语料库数据分布不均衡的问题,提升了模型对对话文本进行实体关系抽取的性能。
在未来的工作中,我们希望针对对话文本的特点,进一步提取对话特征,同时对模型本身做出优化,从而进一步提高模型的性能。
猜你喜欢
中国外汇(2019年18期)2019-11-25
中国生物医学工程学报(2019年6期)2019-07-16
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
海外华文教育(2016年1期)2017-01-20
自动化学报(2016年3期)2016-08-23
电测与仪表(2016年5期)2016-04-22
长春师范大学学报(2015年8期)2015-12-29
当代教育理论与实践(2015年9期)2015-12-16
