
深度编码网络下的英语点餐机器人交互系统设计
2021-10-12 00:37母滨彬
食品与机械 2021年9期
母滨彬 王 平
(1. 广安职业技术学院,四川 广安 638000;2. 兰州理工大学电气工程与信息工程学院,甘肃 兰州 730050;3. 兰州理工大学机器人系统实验室,甘肃 兰州 730050)
点餐机器人情感交互(Human machine emotional interaction)的设计理念自被提出之后,一直是人工智能、多维建模、仿生系统等领域的研发重点[1-2],并涉及到上下文语境感知与情感意识等算法。
随着机器学习与神经网络等科技[3]在对话生成领域的发展,国内外科研工作者提出了一些新方法。Radulescu等[4]采用规则提取法获取相关语义数据,该方法算法简单且实时性好,但需要人工翻译大量规则,领域间的移植性差;Chakraborty等[5]将知识先验后验模型引入Seq2Seq编解码的架构中,该模型也叫做Du-Model,可根据动态意图自动生成回复,但该方法不能充分理解与应用情感交互的前后信息;Paladines等[6]采用Multi-RNN网络拼接上下文与用户输入生成自动回复,但该方法不能区分情感交互背景、线索与主旨等重要信息,情感交互常常言不达意;张凉等[7]将多视角GAN引入深度学习架构中,该方法抑制梯度弥散的效果较好,但提取特征能力不强;王孟宇等[8]设计了RCNN网络和HRED模型情感交互生成方法,该方法可及时获取短句语义,对语义情感分析较为到位,但当网络层次较深时,常出现梯度弥散的状况;易炜等[9]在循环网络中引入注意力权值,可挖掘情感交互中的关键信息,但仍难发掘语义中的隐含信息和风格。
试验拟研究点餐机器人情感交互的设计思路与理念,以期设计出以人为本的智能情感交互方法的机器人,为智能服务业提供技术支持。
1 研究基础
1.1 Seq2Seq网络解析
文中提出的SeqGAN模型基于Seq2Seq模型(Sequence-to-Sequence generative model,Seq2Seq)改进而来。Seq2Seq模型是基于深度学习方法[10]的交互生成元模型,该模型可将基列信号采用编解码生成新基列数据,并能够处理自然语言的自适应基列映射的问题。Seq2Seq可输入文本、图像或语音等基列,并输出文本。
图1中设定英语点餐源语M={m1,m2,…,mn},其尺度为n,输出目标语句W={w1,w2,…,wK},其尺度为K;{h1,h2,…,hn}与{v1,v2,…,vn}分别为编码器与解码器的隐层参量,如式(1)。

图1 Seq2Seq网络解析Figure 1 Seq2Seq network
vi=t(wi-1,vi-1,c),
(1)
式中:
vi——解码器第i个输出词的隐状态;
wi-1——第i-1个输出词;
vi-1——第i-1个词的隐状态;
c——语义状态参量;
t()——多层卷积构成的非线性变换。
Seq2Seq网络的目标解析式如公式(2)所示。
P(wi|w1,w2,…,wi-1)=d(wi-1,vi),
(2)
式中:
P(wi|w1,w2,…,wi-1)——目标输出语句的条件概率;
d()——Seq2Seq网络的目标解析式;
wi——第i个输出词;
vi——相应的隐状态。
1.2 LSTM神经网络模型解析
随着待处理的英语点餐交互语言序列增长,RNN模型会产生梯度弥散的问题,长短存储神经网络(Long short-term memory,LSTM)[11]是在RNN模型基础上的改进,该模型增加记忆单元,可利用门控模块让记忆单元保存全部英语点餐交互语言序列数据。如图2所示,LSTM神经网络模型包括遗忘、输入与输出3组门控元。
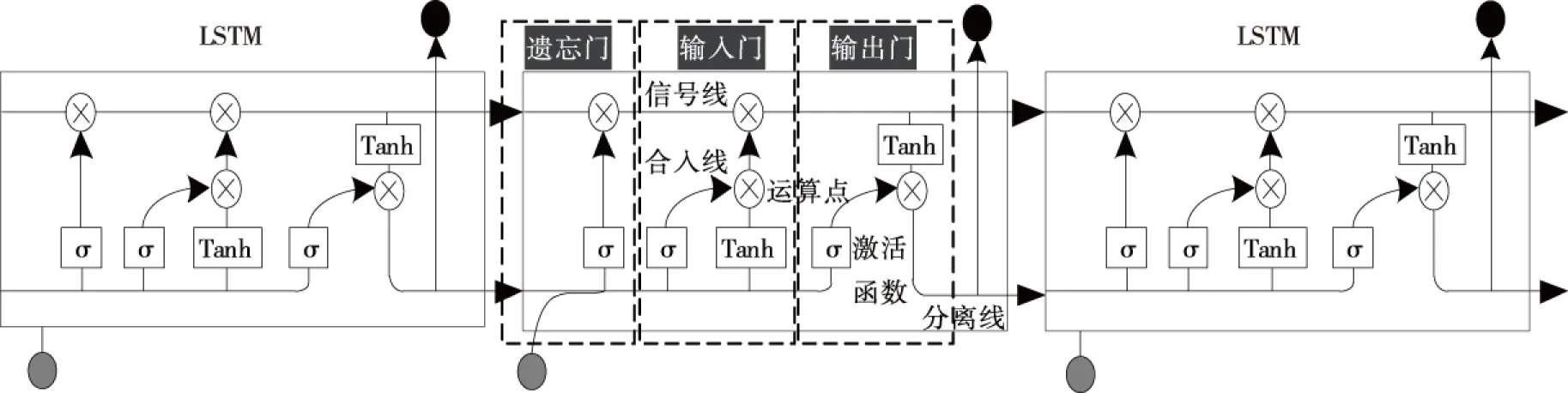
图2 LSTM神经网络模型解析Figure 2 LSTM neural network model
2 基于BLSTM-SeqGAN网络的英语点餐交互系统
2.1 整体架构
Seq2Seq网络在机器学习[12]、智能情感交互等领域运用广泛,但该模型将单个输入基列统一为确定尺度,存在语义信息不能涵盖全部输入数据,数据丢失等问题。此外,实际应用中,单独使用该模型生成的英语点餐语言往往乏味、单一和机器化,面对长难句,往往词不达意。因此,引入约束型GAN架构和主旨型注意力模式,从输入语言中准确捕获语义,并生成确定情感的信息。图3为基于BLSTM-SeqGAN网络的英语点餐交互整体架构,包括输入部分(Input Embeding)、编码部分(Encoder)、主旨注意力机制(Attention)以及约束型SeqGAN网络所构成的解码模型(Decoder)。

图3 基于BLSTM-SeqGAN网络的英语点餐交互整体架构
2.2 基于BLSTM的编码网络
2.2.1 BLSTM神经网络 针对输入的英语点餐交互语言序列,若利用单向LSTM网络处理,则隐层所包括的数据为当前时刻之前获取的,为保证情感交互中英语点餐交互语义的充分理解,则需保障编码过程能获得前后序列数据。选用BLSTM即双向长短存储神经网络构建英语点餐交互的编码模型,与LSTM神经网络相比,BLSTM神经网络可获得正向与反向的隐层输出,其基本架构如图4所示,这是由于BLSTM神经网络包括正向与反向的LSTM编码层,并通过正反向的连接组成。
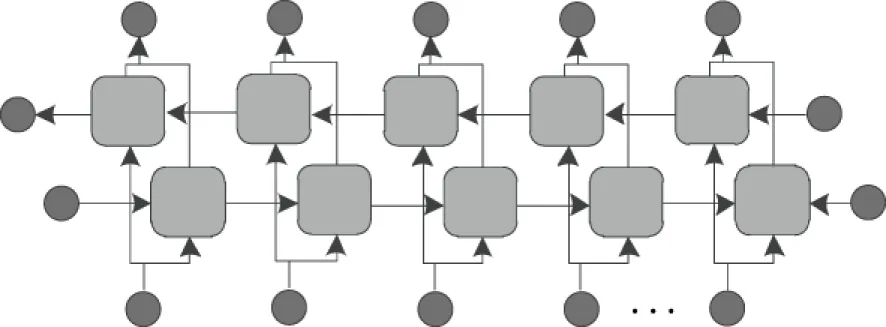
图4 BLSTM神经网络的基本架构Figure 4 Basic architecture of BLSTM neural network
2.2.2 基于BLSTM的编码网络 BLSTM神经网络采用正向LSTM和反向LSTM分别完成历史数据与将来数据的过滤与保存,通过连接正反向LSTM神经网络可获得英语点餐交互语言数据的中间参量表示,基于BLSTM的编码网络如图5所示。在英语点餐交互语句编码前,分解为英语点餐交互源语序列M={m1,m2,…,mn},g=1,2,…n,正反向LSTM神经网络编码的隐层向量分别为yz={yz1,yz2,…,yzn}和yf={yf1,yf2,…,yfn},如式(3)所示。

图5 基于BLSTM的编码网络Figure 5 BLSTM based coding network
ysg=[LSTM(yzsg,mg),LSTM(yfsg,mg)],
(3)
式中:
ysg——s时刻第g个英语点餐交互源语得到的隐层状态;
mg——第g个英语点餐交互源语;
yzsg——s时刻第g个英语点餐交互源语的正向LSTM隐层向量;
yfsg——s时刻第g个英语点餐交互源语的反向LSTM隐层向量;
LSTM(yzsg,mg)——s时刻正向LSTM编码网络得到的隐层状态;
LSTM(yfsg,mg)——s时刻反向LSTM编码网络得到的隐层状态。
2.3 主旨型注意力模式
注意力模式[13]是基于人的观察特点与逻辑,可有效获取数据的典型特征。在英语点餐交互语言序列的情感交互处理中,并不是全部单词的重要程度都相应,而是根据英语点餐交互语言特征和情感交互场景区分单词的优先级和重要性。文中提出的主旨型注意力模式可通过赋权值的方式提取不同情感主旨的文本数据,如积极或消极的情感/情绪。如图6所示,将编码装置中的输出{ys1,ys2,…,ysn}和语境中的主旨单词{c1,c2,…,cn}传输至注意力模式中。

图6 主旨型注意力模式Figure 6 Attentional pattern
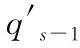
(4)
式中:
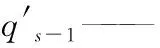
kd——获取门权值;
qs-1——获取门kd读得上一刻的语境信息。
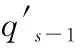
(5)
式中:
ysg——s时刻的隐层状态;
y(s-1)g——s-1时刻编码的隐层状态向量;
fs-1——前一刻获得的英语点餐交互词参量;
wg——与语境相关的向量;
bg——与情感主旨相关的向量;
LSTM[y(s-1)g,fs-1,wg,bg]——基于[y(s-1)g,fs-1,wg,bg]输入的LSTM编码。
2.4 约束型SeqGAN解码网络架构
2.4.1 约束型GAN架构 英语点餐情感交互的生成回复,需充分考量当前输入的英语点餐语言信息与上下文约束,因此在传统GAN网络中引入约束o,利用约束o完善生成与判别进程的同时,增强调控度与适应性。约束型GAN网络架构如图7所示。
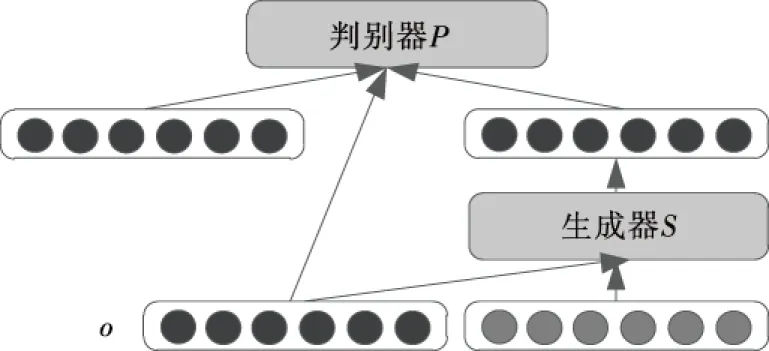
图7 约束型GAN网络Figure 7 Constrained GAN network
2.4.2 约束型SeqGAN网络架构 在约束型SeqGAN网络的基础上生成英语点餐情感交互回复,以“start”作为起始信号,激励生成装置得到回复。该网络中包含了全连接层(Fully connected-net,FC-net)、多尺度卷积和语义向量模拟层(Semantic vector simulation layer,SVSL)。该网络可分为3个功能模块,其中,回复生成模块S是基于LSTM的编解码部分,可将输入的英语点餐语言数据完成实值参量的映射,并基于该数据生成回复;语义向量模拟层则依据生成装置产生的英语点餐语言数据分布获得语言向量并传送至判别装置,并将获得的反馈信息传送至生成装置;判别装置则利用深度学习方法获得语句的语义,并通过卷积操作判别是真实或生成回复,从而调整生成装置参量,缩小生成语言与真人英语点餐情感交互回复间的差距。约束型SeqGAN网络架构如图8所示。
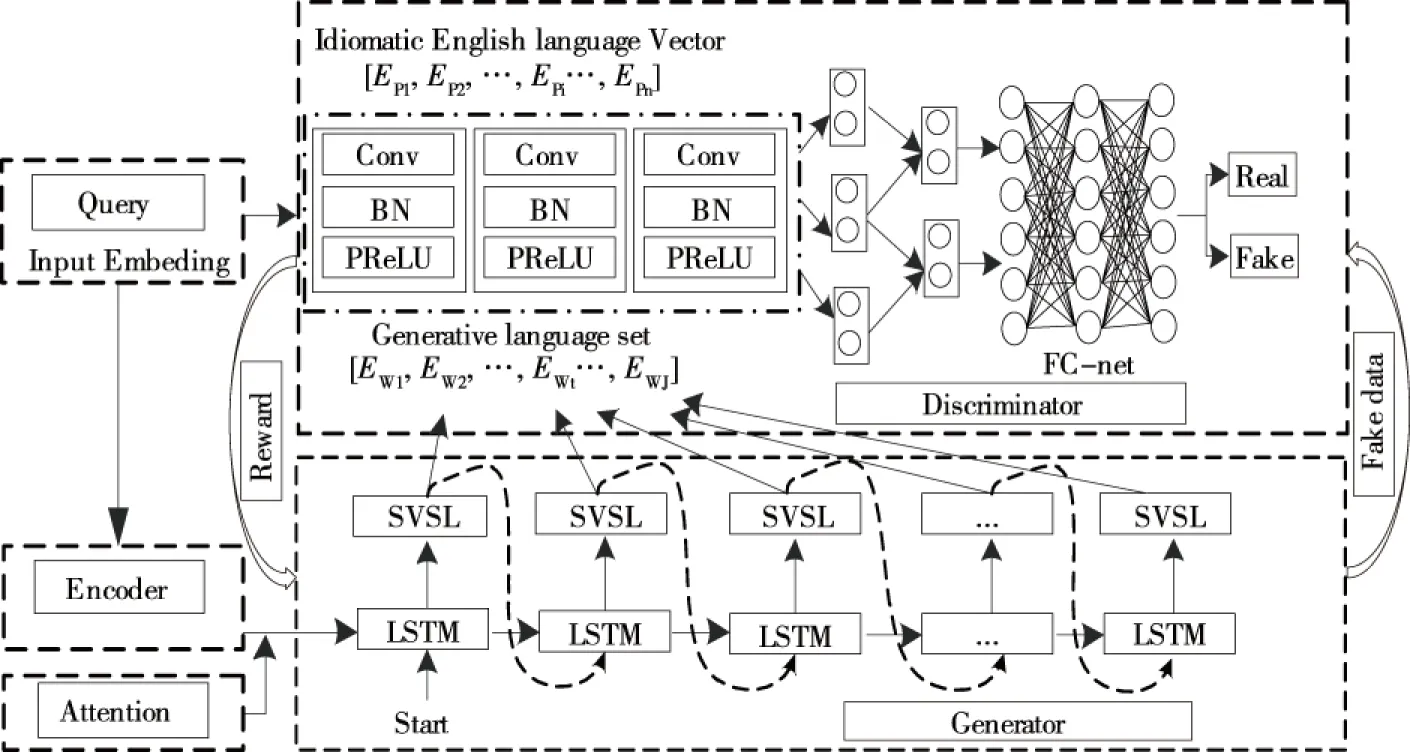
图8 约束型SeqGAN网络架构Figure 8 Constrained SeqGaN network architecture
在生成装置部分可依据输入中间层英语点餐语言数据Em={Em,1,Em,2,…,Em,n}得到相应的情感交互数据Ew={Ew,1,Ew,2,…,Ew,J},该模块的训练目标是基于确定的输入英语点餐语言—情感交互消息对的过程中获得最佳条件概率P(m|w)。其步骤为:编码装置可将输入英语点餐交互语言数据转换为语言向量E(w),生成装置则依据该向量估测情感交互消息中各词产生的概率,如式(6)所示。
(6)
式中:
P(m|w)——英语点餐语言—情感交互消息对最佳条件概率;
E(w)——语言向量;
Ew,1,Ew,2,…,Ew,J——情感交互数据。
生成模块中的消息情感交互回复部分如图9所示。

图9 生成模块中的消息情感交互回复部分Figure 9 Generates the message dialogue responsesection of the module
2.5 模型训练
模型训练的过程就是不断优化英语情感交互生成模型的过程。基于BLSTM-SeqGAN的模型在训练的过程中选用了dropout策略[14],该方法能够避免参量过拟合。模型的目标函数选用交叉熵解析模型。在模型训练中,选用困惑指标Per分析生成英语点餐交互语言的状态,该指标越低则模型状态越好,如式(7)所示。模型优化则选用Adam策略[15],学习率可动态调整,若校验集中的损失超过前五次校验值,则将学习率减小。
(7)
式中:
Per——困惑指标;
n——输出英语点餐交互语言序列的长度;
wg——输出英语点餐交互语言序列W中第g个单词。
3 基于深度编码网络的英语点餐情感型交互试验
BLSTM-SeqGAN下的英语点餐情感型交互生成实验的硬件配置为ROG STRIX-RTX 2080Ti的计算机,8核CPU,16 G内存,硬盘容量为8 T,显存容量为12g*4;软件选用matlab与python混合编程。基本参量设定:dropout的比值设0.3,Adam的学习速率设定为0.000 1,英语点餐单词嵌入层设置为256维,样本集中训练次数epochs设为10,完成一个epochs的迭代次数iterations为550。数据集选用的WordReference Forum和daily dialog语料库中共包含11 356组英语点餐交互,daily dialog语料库具有上万组多轮情感交互,包含各类点餐交互者,并主要覆盖七类情绪,能够表现各类点餐生活场景,主题涉及文化点餐、旅游点餐、健康型点餐、工作点餐、儿童食品点餐等,能够适应各层次学习者用英语交互的需求。并依据0.85∶0.10∶0.05分割成训练、校验与测试三类语料集,语料集的分割统计如表1所示。对比试验的基线模型选用Du-Model与HRED-Model。

表1 语料集的分割统计状态
3.1 生成情感交互质量对比
选用的基线模型为Du-Model[5]与HRED-Model[8]。Du-Model是基于Seq2Seq模型下利用前验与后验知识的认知型多轮情感交互模型,HRED-Model在深度RNN网络编码架构下传送隐层英语点餐交互语言向量,这两种基线模型在多轮情感交互任务中取得的效果远优于Seq2Seq模型。表2给出试验设计方法(BLSTM-SeqGAN)和两种基线方法的情感交互生成实例。从生成的情感交互可以看出,针对英语长难语句,Du-Model易出现丢失源语句的状况,使得该模型偏向于产生常规回复;针对语境或主题复杂的英语语句,HRED-Model对前后文的提取能力不强,对英语语义的理解和情感倾向易带来偏差。如例2所示,当顾客提出他的鸡蛋是溏心的(没有太熟),这个句子带有消极情感。Du-Model和HRED-Model都未充分理解语句的情感状态,误以为情感是积极状态,带来回复偏离语境的问题。Du-Model向顾客推荐皮蛋(皮蛋属溏心类蛋),HRED-Model则建议顾客再点一份饮料,搭配口感更佳;而BLSTM-SeqGAN法判断顾客语义消极,因而回复歉意并让顾客稍等后再上一份煎蛋,贴切语义。BLSTM-SeqGAN法采用主旨型注意力模式,并利用正向和反向LSTM分别完成历史与将来数据的过滤与保存,生成的情感交互回复更加自然。

表2 试验设计方法和两种基线方法的情感交互生成实例
3.2 情感交互生成指标对比
3.2.1 困惑指标对比 采用式(7)给出的困惑指标完成BLSTM-SeqGAN与Du-Model法和HRED-Model法在单个epoch下的对比,如图10所示。与两种基线方法相比,试验设计的方法困惑指标更小,并伴随迭代数目增加而稳定程度更高。
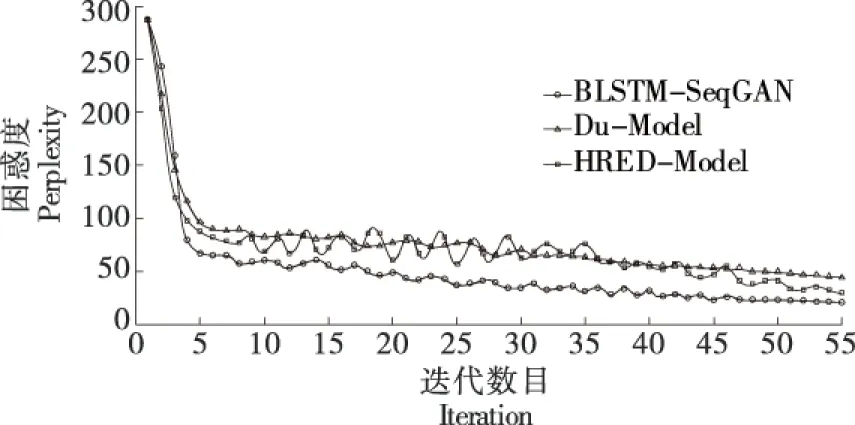
图10 试验设计方法与两种基线方法的困惑指标对比
3.2.2 精准度指标对比 精准度指标模型Precision如式(8)所示。BLSTM-SeqGAN、Du-Model和HRED-Model 3种方法在首个epoch中的精准度曲线如图11所示,该epoch中的精准度变化程度大,三者稳定达到的精准度分别为74.9,70.1,65.4,其中BLSTM-SeqGAN法可以较快地进入最优状态,且精准度更高。

图11 试验设计方法和两种基线方法的精准度指标对比Figure 11 Comparison of precision indexes
Precision=(RP+RN)/(RP+EP+RN+EN),
(8)
式中:
RP——“Right Positive”,即样本被准确预测为积极情感/情绪的主题;
RN——“Right Negative”,即样本被准确预测为消极情感/情绪的主题;
EP——“Error Positive”,即样本被错误预测为积极情感/情绪的主题;
EN——“Error Negative”,即样本被错误预测为消极情感/情绪的主题。
3.3 算法的效能对比
图12给出试验设计方法与两种基线方法在10个epoch中的精准度变化状态。在前8个epoch的网络训练中,随着epoch个数增加,3种方法的精准度不断增加,BLSTM-SeqGAN法的精准度明显高于两种基线方法。此外,在8个epoch之后,Du-Model法与HRED-Model法由于产生了过拟合状况,精准度逐渐降低。试验设计了BLSTM-SeqGAN架构,并在训练过程中选用dropout策略方法,能够有效规避过拟合问题。表3给出3种方法在单个epoch中的平均训练时间和最优精准度。由表3可知,BLSTM-SeqGAN法的效率与准确率均优于两种基线方法。

表3 试验设计方法和两种基线方法的平均训练时间和 最优精准度Table 3 Average training time and optimal accuracy of the three methods
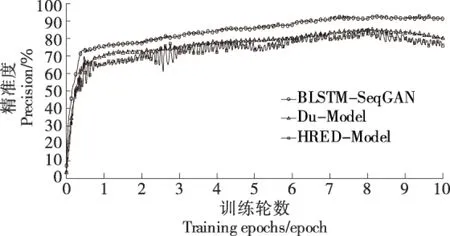
图12 试验设计方法和两种基线方法在10个epoch中的精准度变化状态Figure 12 Precision changes of the three methodsin 10 epochs
4 结论
在Seq2Seq网络和LSTM神经网络模型的基础上,引入约束型GAN架构和主旨型注意力模式,实现基于BLSTM-SeqGAN网络的英语点餐情感交互生成,可从输入语言中准确捕获语义,并生成确定情感的信息。在训练过程中选用了dropout策略,该方法能够避免参量过拟合,模型优化则选用Adam策略,学习率可动态调整。而且BLSTM-SeqGAN法生成的情感交互回复更加自然,困惑指标更小,并伴随迭代数目增加而稳定程度更高,并能够较快进入最优状态,精准度更高。此外,在单个epoch中的平均训练时间最短。
目前,研究尚存在参数训练需要的数据量大,网络结构仍较为复杂的问题。在未来的研究工作中,将分析如何利用少量的训练数据获取更通用的情感特征。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
小学生学习指导(中年级)(2021年12期)2021-12-30
汽车工程(2021年12期)2021-03-08
汉字汉语研究(2020年2期)2020-08-13
当代陕西(2020年24期)2020-02-01
电子制作(2019年22期)2020-01-14
时代人物(2019年27期)2019-10-23
疯狂英语·新读写(2018年3期)2018-11-29
安阳工学院学报(2018年6期)2018-11-28
互联网天地(2016年1期)2016-05-04
