
基于隐语义模型的学生选课推荐算法
2021-10-01 16:30陈钢常笑胡枫
计算技术与自动化 2021年3期
陈钢 常笑 胡枫

摘 要:为了使学生可以准确、合理的进行选修课程,并调动其学习主动性,考虑到学生-课程之间潜在关系,提出了一种基于Funk-SVD技术的隐语义模型学生选课推荐算法。本算法使用随机梯度下降法优化损失函数;对选课推荐算法执行过程中的冷启动问题提出了一种处理方案;通过评价指标召回率、准确率以及平衡F分数验证本算法推荐的可行性和有效性,在所收集到的学生选课数据集上进行测试,实验结果表明,该算法具有一定的优势。
关键词:推荐算法;潜在关系;隐语义模型
Abstract:In order to enable students to take courses correctly and reasonably, and to arouse their enthusiasm of learning, in view of the actual relationship between students and courses, this thesis proposes a latent factor model of recommended algorithm for students on the basis of Funk-SVD technology. This algorithm applies a method of stochastic gradient descent to optimize the loss function; a solution to solve the problem of cold boot during the process of recommended algorithm for students course-choosing is provide accordingly; the feasibility and validity of this kind of recommended algorithm are verified by evaluating the index recall rate, accuracy rate, and balanced F score, testing on the data collected from students' course-choosing. The experimental results show that the algorithm is advantageous.
Key words:recommended algorithm; actual relationship; latent factor model
近年来,随着信息化的高度发展,信息的自动处理以及线上交互已被广泛应用于各领域。借助信息技术批量管理学生信息是目前各高校都极为重视的教学管理工作之一,也是各高校的关鍵一环。为了更好的管理选课信息而设计的学生选课系统作为一种现代化的课程选修方式,与传统的选修方式相比不但更加快捷有效,而且使选课管理工作更加标准化、准确化。学生选课系统的使用一方面使高校选课工作更加有效率,为广大师生及相关工作人员节省了大量的时间,另一方面又增加了学生灵活选课的自主权,提高学生学习选修课的积极性。但大多数的选课系统,学生在选择时往往对所选修的课程一知半解,仅凭选修课的名称或者本身的学科专业去选择课程。这样的选择不但过于盲目,导致学生难以选到真正感兴趣的课程,而且还会使一些有价值的精品课程陷入无人选择的尴尬情况。为了使学生可以准确、合理的进行选修,并调动其学习的自主性,许多研究者把各种模型用到学生选课系统中,也相继提出了分级筛选的处理方法分配学生的课[1]、按名额比例分配算法[2]和分志愿筛选算法[3]、按照先来后到的方式去选择选修课[4]和基于项目-用户和属性值的矩阵的协同过滤算法[5]等。
不过现有的选课推荐算法中并没有考虑到学生-课程之间的潜在关系,如学生选择某门选修课是因为其对代课老师感兴趣,或者是因为其对该门课程本身感兴趣。基于此,提出了基于隐语义模型的选课推荐算法来为学生推荐选修课,隐语义模型推荐算法根据学生的行为对选修课进行统计,并自动的把选修课划分到不同的属性(即学生的兴趣)中,可以较为充分的发现学生-课程的潜在关系。实验表明,基于隐语义模型的推荐算法在Top-N推荐中更有优势,预测准确度更高。
1 相关工作
随着基于物品的协同过滤(Item-CF)推荐算法在商业界得到了广泛的应用,如电子商务[6](阿里巴巴、亚马逊、淘宝商城等)、信息检索[7](中国知网、谷歌、百度等)以及社交网络(豆瓣、Facebook、微信等)等应用领域并带来的巨大经济效益,如Netflix上66%以上的影片观看率出自给观众个性化的推荐、Amazon的销售量有35%来自于购物界面上的推荐以及Choice-stream上28%的用户会选择付费获得更多的音乐也是基于该对用户的推荐。目前,从海量冗余的数据中帮助用户发现其可能感兴趣物品信息,为他们每个人提供个性化的推荐服务的推荐系统(RS)成为了一个的重要研究领域。而推荐算法又是RS的核心部分,直接和系统的性能相挂钩,一般可分为:基于内容的推荐算法、协同过滤推荐算法[8]和混合推荐算法[11],如图1所示:
(1)基于内容的推荐(content-based recommendation,CB),其主要是根据推荐物品的实质内容,得出不同物品间的相关性,然后结合用户对物品的历史行为操作,给用户推荐和其之前喜好的相似的物品。
(2)协同过滤推荐(collaborative filtering recommendation,CF), 其主要是遵循“物以类聚,人以群分”的假设,通过分析用户之间或者物品之间的相似度[12-13]得出适合给用户推荐的物品。基于CF的算法一般应用在有用户-物品的评分矩阵的系统之中[13],根据评分去分析用户对于物品的喜欢程度。目前,协同过滤推荐算法主要分为两种类型:基于用户的协同过滤算法[13]和基于物品的协同过滤算法[15]。
(3)混合推荐(hybrid-recommendation),在现实生活中,很少会使用单一的推荐算法去实现推荐任务。因此,通常将不同推荐算法在实际的应用场景进行分析后组合应用。混合策略有加权、交叉、切换、串联、分层、特征组合和特征补充等[16]。
基于内容的推荐虽然简单通俗、实现快捷,不需要用户数据集,因此不存在稀疏性和冷启动问题;而且由于是基于物品本身属性的推荐,所以也不存在不断推荐热点信息的问题。但对于一些难以提取物品本身特征的推荐内容而言,CB算法很难令人满意以及CB算法依赖于物品底层实质信息的提取,容易导致过度拟合;协同过滤推荐算法不需要对物品或者用户构建十分标准的模型,并且计算出来的推荐是可以共享他人经验的,但是这些基于近邻计算的算法往往存在可扩展、冷启动以及数据稀疏等问题。
基于Funk-SVD技术的隐语义模型(latent factor model,LFM)[12],[17]是现在在物品推荐系统中应用相当成熟的一种模型。相比于传统的协同过滤技术,LFM对所有物品自动的先进行聚类,划分成若干个兴趣属性,再根据用户的兴趣属性的权重给用户推荐物品,其推荐结果相对更个性化、准确化,更契合人们的选择。
2 构建隐语义模型和相关算法
以用户对物品的评分构成一个评分矩阵,但是显然,用户不会对所有的物品进行评分,所以这个矩阵一般都较为稀疏。如果某个用户对某个物品没有评过分,那么推荐算法就要预测这个用户会对这个物品评多少分,再让所预测的评分去填充评分矩阵。基于隐语义模型的选课推荐算法的本质也是如此:用预测的评分来将评分矩阵补全后,得出学生对选修课的偏好程度,从而给其推荐合适的选修课。
为了便于表示,相关的符号标记见表 1。
2.1 隐语义模型及其推荐算法
在大多数情况下,用户对物品的第一感官会受到该物品属性上的影响。比如用户A打算换个新手机,在众多的手机中A选择了手机B,而用户A本身喜欢具有外观精致、性价比高等特点的手机,这些特点就是A对手机属性的一种偏好。每种手机在外观、性价比等属性上都具有不同的评价,对于用户A而言,其选择的手机B一定是一个在其偏好的属性中具有较高评分的一款。
从评分矩阵R中虽然仅能得到用户对物品的评分,但是却可以认为该评分是用户在物品属性上的偏好程度和物品在这些属性上所占分值的综合体现,这里的属性即为用户和物品之间的潜在关系。
在选修课的推荐过程中也是如此,隐语义模型基于学生行为统计后自动把选修课划分为有若干个属性,并且属性的数量是可控的。但若具体想要得到F个属性,则必须找到两个矩阵P和Q,并使这两个矩阵的乘积近似的等于R,如下式(1)所示:
在多次迭代后,依据所得到的Pu,k、Qi,k由式(2)进行预测学生对未选修课程的评分,进而得到一个备选课程的排序,再通过Top-N推荐列表实现个性化推荐。
算法的流程如下图2所示。首先,读入学生对课程的选课记录,进行构造学生-选课评分矩阵R。其次,将学生-选课评分矩阵拆分成P和Q矩阵,并开始构造学生-选课预测评分矩阵。然后,用损失函数Loss计算R和之间误差,同时采用随机梯度下降法不断的迭代优化损失函数。最后,将计算得到的预测评分进行排序,再依据要求推荐课程的门数输出Top-N推荐结果。
2.2 冷启动问题的处理
基于隐语义模型的选课推荐算法是从学生已有的选课记录中提取学生-课程的潜在关系来推荐选修课,但对于没有选课记录或选课记录很少的学生时该算法并不十分理想。因此,为处理冷启动问题,避免新生(含现有选课门数小于或者等于2门的学生)在没有选课行为时推荐结果的不准确,以及一些有价值的精品课程陷入无人选择时无法推荐,造成教学资源的浪费,在学生选课系统中采用基于物品的协同过滤推荐算法(Item-CF)处理冷启动问题。当有新生进入选课时,学生选课系统从全部学生数据库中调取与该新生相同学科专业、录取分数接近的学长或学姐选课的历史记录数据,然后把该新生的数据和历史记录数据合并成一份,再导入到Item-CF算法中后经学生选课系统中向该新生推荐选修课程作为选课参考。通过此方法,提高了课程推荐的准确性。
3 实验与分析
3.1 实验数据集
以某高校(其通识选修课程要求10学分)的不分学科专业、年级方向的3 251位学生的431门选修课(含网络课)的24 384条选课记录作为推荐算法的数据集进行实验。该数据集包括学生、课程、学生的选修记录。数据集详细信息及具体见表2、表3。
实验过程中采用train_test_split函数把24 384条评分数据集分为19 507条训练集(80%) 和4877条测试集(20%),且经多次实验后,最终取分类数F=6,迭代次数N=9,学习速率α=0.05,正则化参数λ=0.01。最终实验结果取30次实验的平均值。
3.2 性能评价
根据学生选课记录数据集的性质,推荐算法的评测采用离线实验中的Top-N推荐方式。网站在给用户推荐具有个人色彩的服务时,一般是以推荐列表的形式为主,这种推荐即为Top-N推荐(推荐数N的大小可以指定)。大多数情况下,其预测准确度以准确率和召回率两个指标来进行衡量[20]-[22]。
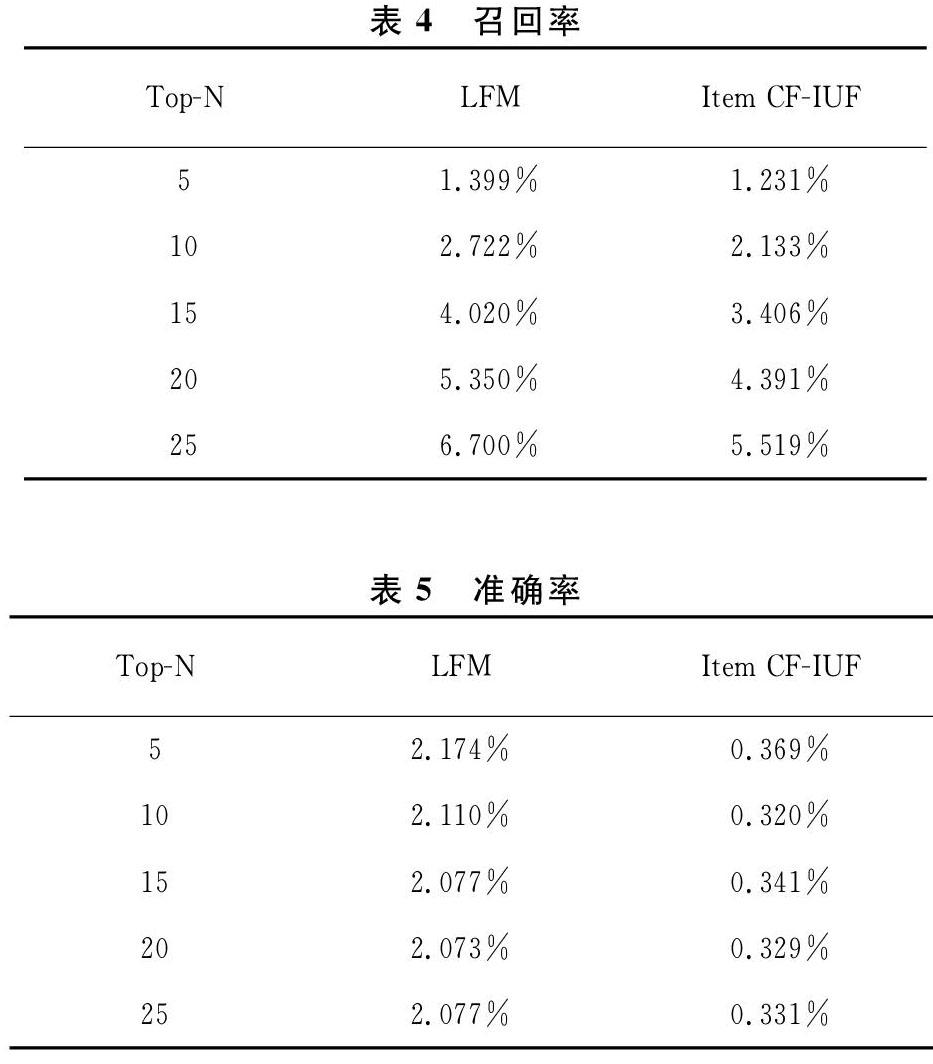
可以从表4中发现,随着推荐数N的增加,LFM算法与Item CF-IUF算法的召回率都在持续上升且LFM算法的增长速度一直大于Item CF-IUF算法;可从表5中发现,两种算法的准确率都趋于下降,但LFM算法明显比Item CF-IUF算法更加准确且在准确性方面至少要高出1.7%。
為了更好的说明推荐系统的性能,尤其在多个推荐系统之间做比较时度量出各系统之间的优劣。同时应用统计学中兼顾准确率和召回率的调和平均数-平衡F分数[23]-[25],也称为F1分数(F1 Score)来作为系统的性能指标:
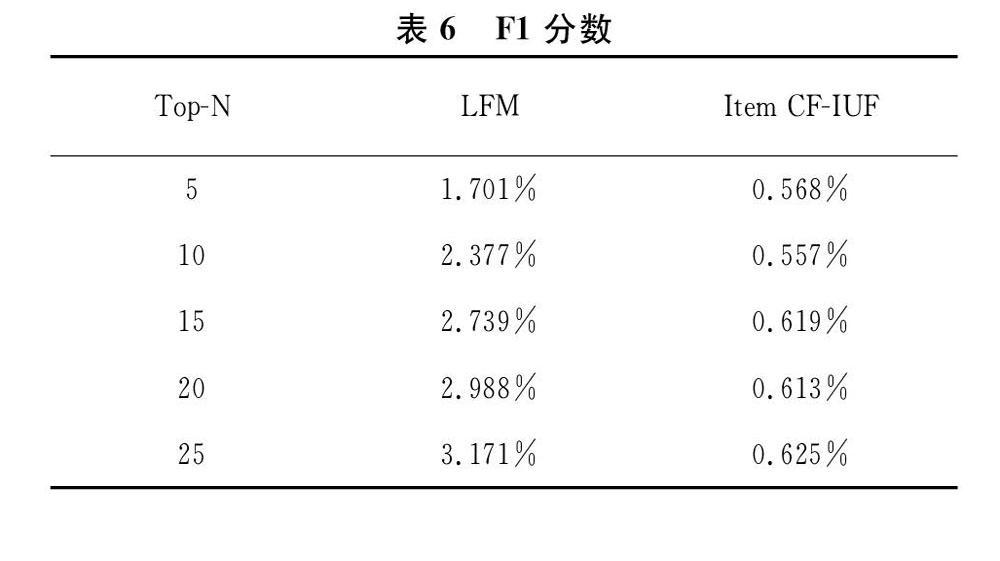
从表6中可以发现,Item CF-IUF推荐算法的F1分数基本上趋于稳定,而LFM推荐算法的F1值则不断上升,同时其F1分数在Top-N(N=5,10,15,20,25)推荐中均比Item CF-IUF推荐算法的F1分数高,且最高高出2.5%。基于此,并结合对两种算法的召回率以及准确率的分析,可以认为在学生选课系统中,应用隐语义模型的推荐算法比基于物品的协同过滤技术的改进推荐算法要更加准确、有效,更能给学生推荐个性化的选修课程,可以更好的调动学生学习选修课的主动性,以培养多层次的人才。
4 结 论
在已有的推荐算法基础之上,针对目前高校普遍使用的学生选课系统有针对性的提出了基于隐语义模型的选课推荐算法。LFM推荐算法相比于传统的选课推荐算法,存在以下优点:
(1)隐语义模型推荐算法较充分的考虑到了学生-课程的潛在关系。根据Top-N推荐列表中预测值的大小向学生推荐个性化的选修课作为参考进行选课,使学生在选课时目标清晰,更能选择契合个人感兴趣的课程,大大提高学生学习选修课的积极性;而且均衡了学校的教学资源,缩小了一些有价值的精品课程陷入无人选择情况的几率。
(2)隐语义模型推荐算法在一般高校的学生选课系统中更为实用。如今高校招生人数在扩增[26],[27],其选课数据也因此逐渐上升,而传统的推荐算法在大规模的数据下其准确率及平衡F分数值相较于隐语义模型推荐算法的准确率及平衡F分数值都要低上许多,因此隐语义模型推荐算法相较于传统的推荐算法在高校中更为适用。
但由于学生选课系统的制约,推荐算法并没有直接给出课程推荐的原因,对学生而言缺乏一定的说服力;另外未能充分考虑到每位学生的特点,只能基于选课系统中已存在数据进行推荐,结果可能存在时间上的滞后性。由此,后续可以在时效方面进一步改进,使该算法不但可以在学生选课系统中准确、有效的为学生推荐选修课程,也可以在一些音乐或者电影平台等上为用户提供优质的服务,使得用户在同类产品中更加倾向于选择该平台。
参考文献
[1] 陈月英,宗平,庄卫华,等.高校选课系统中的公平算法及其研究[J].计算机工程与应用,1998(11):40-41.
[2] 刘敦涛.选课算法与选课信息系统的研究和实现[D].武汉:华中师范大学,2006.
[3] 杨春蓉.高校公选课网上选课系统的设计与实现[D].上海:华东师范大学,2007.
[4] 黄海东.网上选课系统的算法分析与改进[J].淮南职业技术学院学报,2009,9(1):27-28.
[5] 徐天伟,宋雅婷,段崇江.基于协同过滤的个性化推荐选课系统研究[J].现代教育技术,2014,24(6):92-98.
[6] XU H, ZHANG R, LIN C,et al. Construction of E-commerce recommendation system based on semantic annotation of ontology and user preference[J]. TELKOMNIKA Indonesian Journal of Electrical Engineering, 2014,12(3):2028-2035.
[7] GUPTA Y, SAINI A, SAXENA A K. A new fuzzy logic based ranking function for efficient information retrieval system[J]. Expert Systems with Applications, 2015,42(3):1223-1234.
[8] PIATCTSKY G. Interview with simon funk[J]. Acm Sigkdd Explorations Newsletter, 2007, 9(1):38-40.
[9] HAN P, XIE B,YANG F. A scalable P 2 P recommender system based on distributed collaborative filtering[J]. Expert Systems with Applications, 2004,27(2):203-210.
[10]BALTRUNAS L, RICCI F. Experimental evaluation of context-dependent collaborative filtering using item splitting[J]. User Modeling and User-Adapted Interaction, 2014,24(1-2):7-34.
[11]KLANJA-MILICEVIC A, VESIN B, IVANOVIC M,et al. E-learning personalization based on hybrid recommendation strategy and learning style identification[J]. Computers & Education, 2011,56(3):885-899.
[12]王升升,赵海燕,陈庆奎,等.个性化推荐中的隐语义模型[J].小型微型计算机系统,2016,37(5):881-889.
[13]邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003(9):1621-1628.
[14]BREESE J, HECHERMAN D, KADIE C. Empirical analysis ofpredictive algorithms for collaborative filtering[C]. In:Proceedings of the 14th Conference on Uncertaintyin Artifi-cialIntelligence (UAI'98), 1998,43-52.
[15]ARWAR B, KARYPLS G, KONSTAN J,et al. Item-based collaborative filtering recommen dation algorithms[C]. In:Proceedings of the 10th International World Wide Web Conference, 2001,285-295.
[16]BURKE R. Hybrid recommender systems:survey and experiments[J]. User Modeling andUser-adapted Interaction, 2002,12(4):331-370.
[17]鲁权,王如龙,张锦,等.融合邻域模型与隐语义模型的推荐算法[J].計算机工程与应用,2013,49(19):100-103+134.
[18]李薛剑,刘梦雅,海健强,等.基于时间效应与隐语义模型的高校图书馆的个性化推荐研究[J].计算机应用与软件, 2018,35(5):130-134.
[19]范慧婷,钟春琳,龚海华.基于隐语义模型的个性化推荐[J].计算机应用与软件,2017, 34(12):206-210.
[20]黄震华,张佳雯,田春岐,等.基于排序学习的推荐算法研究综述[J].软件学报,2016,27(3):691-713.
[21]荣辉桂,火生旭,胡春华,等.基于用户相似度的协同过滤推荐算法[J].通信学报,2014,35(2):16-24.
[22]蔡淑琴,袁乾,周鹏,等.基于信息传播理论的微博协同过滤推荐模型[J].系统工程理论与实践,2015,35(5):1267-1275.
[23]HRIPCSAK G, ROTHSCHILD A S. Agreement, the fmeasure, and reliability in information retrieval[J]. Journal of the American Medical Informatics Association, 2005,12(3):296-298.
[24]蒋胜臣,王红斌,余正涛,等.基于关系指数和表示学习的领域集成实体链接[J/OL].自动化学报:1-10[2019-11-06].https://doi.org/10.16383/j.aas.c180705.
[25]韩忠明,刘雯,李梦琪,等.基于节点向量表达的复杂网络社团划分算法[J].软件学报,2019,30(4):1045-1061.
[26]李春玲.高等教育扩张与教育机会不平等——高校扩招的平等化效应考查[J].社会学研究,2010,25(3):82-113,244.
[27]张建华,万千.高校扩招与教育代际传递[J].世界经济,2018,41(4):168-192.
