
大数据视域下不良信息安全过滤系统的仿真研究
2021-09-29 07:10:18胡红
微型电脑应用 2021年9期
胡红
(西安培华学院 思政部, 陕西 西安 710125)
0 引言
随着互联网同日常生产生活的深入融合,使用计算机网络的用户数量不断增加,促使大数据时代的到来,网络中的信息数据量呈爆炸式增长,这些信息的传递需基于相互连接沟通的网络实现,导致网络中的数据信息量不断增加,而这些数据通常蕴含一定的使用价值,但也存在部分具有一定破坏性的不良信息,网络安全稳定运行过程会受到不良信息不同程度的破坏。不断发展的网络业务促使针对不良信息的信息过滤系统成为行业内的一项研究重点[1]。
1 网络不良信息过滤模型的构建
1.1 过滤模型结构
现有的过滤系统大多针对网络不良网页,并且以采用基于网页内容的过滤技术与方法为主,通过实时分析理解网页内容实现对文档语义的动态识别过程,其过滤效果优于基于内容分级、关键字、数据库等的过滤方式,但随着大数据时代的到来,已经难以满足对不良信息的过滤需求。对基于内容理解的有害信息过滤系统来说,对网页内容的准确分类(通过运用机器学习方法完成)是关键所在,在模式分类领域中,K最近邻分类器因具有简捷高效的分类功能而得到普遍应用,K最近邻方法(KNN)作为一种常用的分类算法发展较为成熟,作为一种懒惰学习方法,K最近邻分类方法无需估计参数和预先训练,仅在需分类测试时才对训练数据进行建模,其分类原理在于从样本特征空间中选出相邻的样本K个,在这些样本大多同属一类时,可将该测试样本划分到此类,特别适用于样本比较大的类域分类过程,分类准确率在边界较整齐时较高。为此本研究使用K最近邻算法设计了一个网络不良信息过滤模型,结合运用改进后的KNN分类算法,使分类准确率及处理速度得到显著提升,过滤模型的拓扑结构示意图[1],如图1所示。
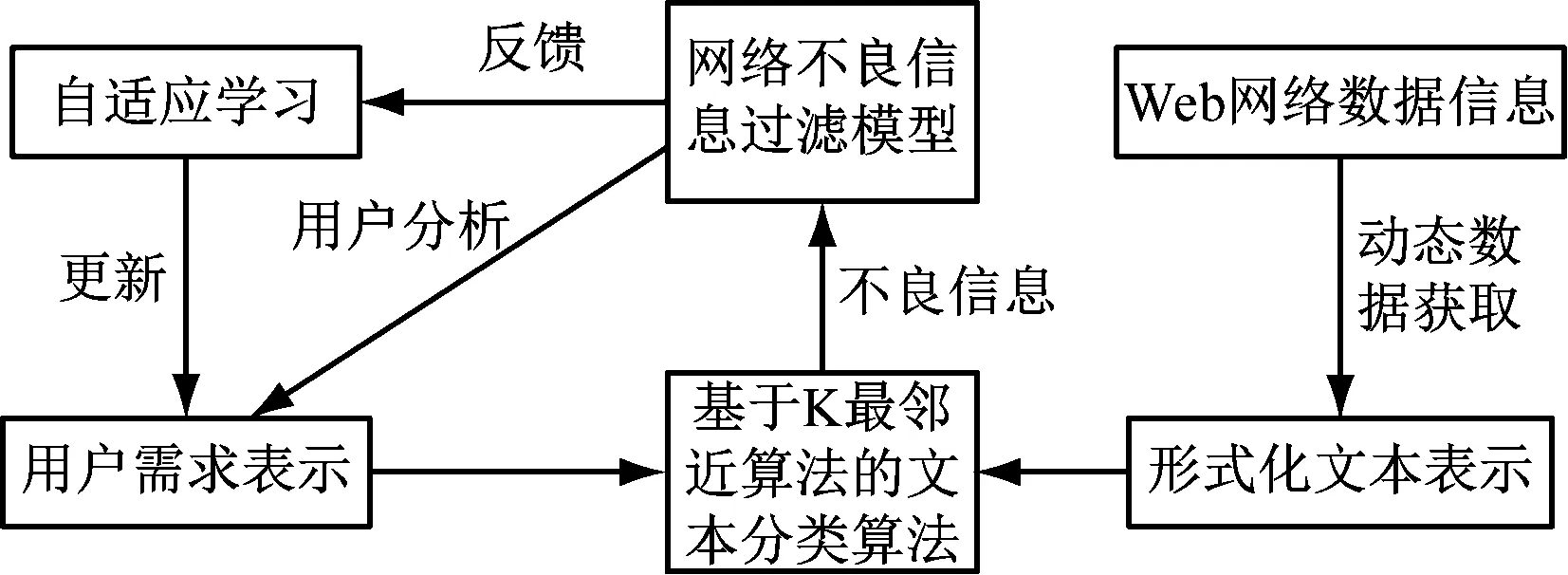
图1 网络不良信息过滤模型架构示意图
1.2 文本表示
文本表示模块的主要步骤为:(1)先完成网页文本的“去噪”处理并保留有用信息,清除掉包括标签、脚本、非文本对象等(用于描述网页信息)在内的信息源中存在的噪声,然后分离出剩余信息的主要特征。(2)完成文本的形式化表示,具体通过向量空间模型(VSM)完成,由(T1,T2,…,Tn)表示经去噪处理后的文本用词条,分别对应特征空间坐标系中的一维,再通过使用TF-IDF公式(用于信息检索与数据挖掘的常用加权技术)完成对各词条Ti权值的计算,权值对应特征空间坐标系的坐标值,由Wi表示权值,在此基础上完成文本到n维空间某一向量的映射。采用两个向量的夹角余弦完成任意两个文本间相似度的计算[2],具体表达式如式(1)。
(1)
Xi=(Xi1,Xi2,…,Xin)
Xj=(Xj1,Xj2,…,Xjn)
1.3 基于KNN算法的分类器
过滤的实质属于一个二值分类问题,需对正常信息和不良信息进行区分。本研究使用KNN算法完成分类器的设计,先针对待测试文本和训练集,使用VSM中的向量方法对其中的全部文本进行表示,再完成全部文本的距离即相似度的计算,具体采用距离加权方法计算,以保证算法的稳定性,接下来在训练集中找到K(K≥1)个离测试文本最近的文本。已知有N个训练样本,样本数量足够大,由X表示测试样本,在奇数K个最邻近文本中,正常信息和不良信息分别对应类标值为 1的样本K1个、类标值为 0的训练样本K2个,判定测试样本的类别表达式[3]如式(2)。
(2)
K=K1+K2
1.4 用户需求表示与自适应学习
用户需求表示,主要用于筛选文本,在分析处理各种不同用户需求的基础上,从中筛选出主要的用户需求特征形成一个准确的用户兴趣集合。自适应学习,以KNN的分类结果为依据,向过滤系统提供包括用户体验的相关信息,系统据此完成自适应的反馈学习(需基于相应评价机制)并得到反馈学习结果,据此可动态调整距离的权值与K值,从而使分类的准确率得到显著提升。
1.5 K最近邻算法的改进
需使训练样本数充分大,以保证分类结果的准确率,作为懒惰学习算法的一种,KNN算法存在前期训练不足的问题,进而增加了后续分类时的计算量;此外,KNN算法获取K值时,需计算全部样本的距离,面对较大的训练数量会显著增加计算量。因此对容量较大的样本集进行分类时,可先预处理对分类作用影响较小的样本,为消除可能影响分类的训练样本,通过优化KNN算法得到一种缩减的RKNN(KNN优化改进后)算法,先对特定训练样本周围的邻近样本进行判断,找出其中和自身类别不同的大多数,视为导致错误分类的边界样本,并在最终训练集中去除这部分样本,以提高分类准确率。RKNN算法的流程为:在集合A、B(A=B)中分别置入由(x1,x2,…,xn)表示的训练集,对于xi∈B,若其在A中的K个最近邻中的多数样本不同于xi,则在B中删除xi;取i+1,进入新一轮学习,直至i=n时结束,以B中的剩余样本作为最终的训练集[4]。
2 不良信息安全过滤系统总体设计
传统的识别数据过滤系统是实际应用较多的网络信息过滤系统,是在全部接收完信息的基础上进行逐一的排查和比对,完成过滤过程,存在明显的过滤速度慢且最终过滤效果不佳等问题。为此本研究针对Web大数据动态环境,基于改进后的K最近邻算法设计了一种过滤模型,并构建了一种网络不良信息安全过滤系统,通过网闸式的过滤系统先完成对控制端的优化选择,为保证不良数据信息的过滤质量,又进一步优化了权值的随机自适应算法,实现对不良信息的全面过滤。系统的数据过滤流程,如图2所示。
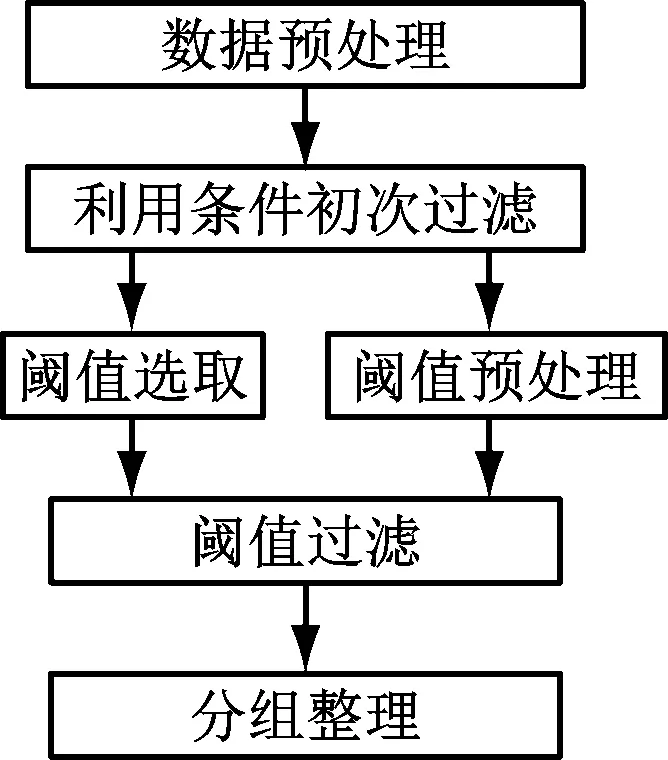
图2 数据过滤流程
为便于系统的使用、维护和后续升级,采用C/S模式构建该不良信息安全过滤系统硬件架构,该过滤系统适用于大量信息数据的处理,硬件系统主要分为3部分:前端控制层,作为过滤系统的命令控制中心;运行系统,主要由数据库、计算器、数据分选器和调控器等构成,主要负责分析和过滤网络数据;用户端,主要负责识别用户、下达和传递命令等,具体由感知运行器、文件驱动器等构成。在过滤海量数据的同时,需保证常规数据的正常运行,完成对信息的把控,要求系统具有较强的逻辑计算能力,为此系统通过优化选择前端主机的控制端,有效提高了系统的过滤能力以及逻辑计算能力,从而使数据信息过滤过程更加精确,确保系统面对Web大数据动态环境的筛选能力[5]。
3 不良信息安全过滤系统软件设计
3.1 网闸式信息过滤功能的实现
为有效解决配差计算失衡的问题,本研究所构建的不良信息安全过滤系统,在过滤不良数据使采用网闸过滤系统实现,实现了良好的过滤效果,同时提高了系统的计算能力。对不同的数据信息类型,通过网闸过滤系统后其符号型属性会发生改变,不同符号型属性选择,数据信息包含文字、图片、逻辑等,如表1所示。

表1 数据信息同符号型属性的对应关系
对于不同的符号型属性,先由网闸过滤系统完成有效的分类过程,以实现对不同数据的精确过滤。假设,系统的过滤阀值由F(u,v)表示,uπ表示信息提取系数的参照比,WEB网络数据涵盖的甄别属性由f(x,y)表示,基于符号型属性建立等式[5]如式(3)。
(3)
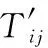
(4)
(5)
图3 实际信息的矩阵图
图4 条件矩阵图
完成对比后去除不同于条件矩阵的数据,进而完成一次初级过滤过程。
考虑到初级数据过滤无法满足系统的实际过滤需求,因此对阈值进行过滤,假设,预处理的参数及属性参数集合分别由rk-1和RK表示;IZ表示甄别系数;信息的重权系数由FYLK表示;符号型属性经初级条件矩阵处理后由FY2K表示;其中符合进入阈值过滤的由La表示;LB表示属性中的只读,过滤阈值前需先完成相应的预处理[6],如式(6)。
(6)
然后再对数据进行阈值选定即可完成阈值的计算,假设,yi表示专属阈值;yj表示专属辨别系数;调用的参数和阈值分别由αi、αj表示,对应粒子集群由K(xi,xj)表示;阈值选定的表达式如式(7)。
(7)
数据信息接下来进入阈值的过滤,过滤过程表达式如式8(得到的d值属于一个范围值,以确保有用的数据信息不被过滤掉)。
(8)
据此实现数据信息过滤逻辑性的有效提高,自动分组过滤后的数据信息,在进行分类管理时,假设,B表示序列号;D表示可进行分组的数据集;T表示数据识别属性;实际数据转换值由Δt表示[7],具体表达式如式(9)。
(9)
(10)
按照上述操作和处理完成信息的分类过滤。
3.2 基于随机自适应算法的过滤能力

(11)
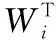
(12)
4 仿真实验测试与结果分析
采用VC实现本研究网络不良信息过滤模型的构建和运行,使用向量空间模型表示搜集到的全部样本,采取不同的K值,对比分析基于KNN和RKNN两种算法的过滤模型的性能,查准率、查全率和耗时的实验对比结果,如图5所示。
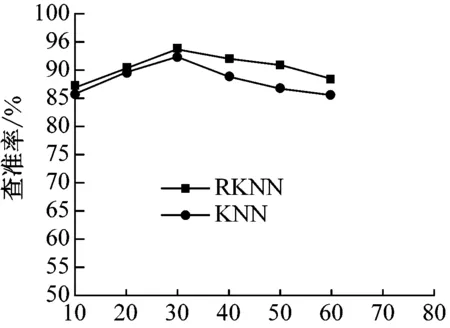
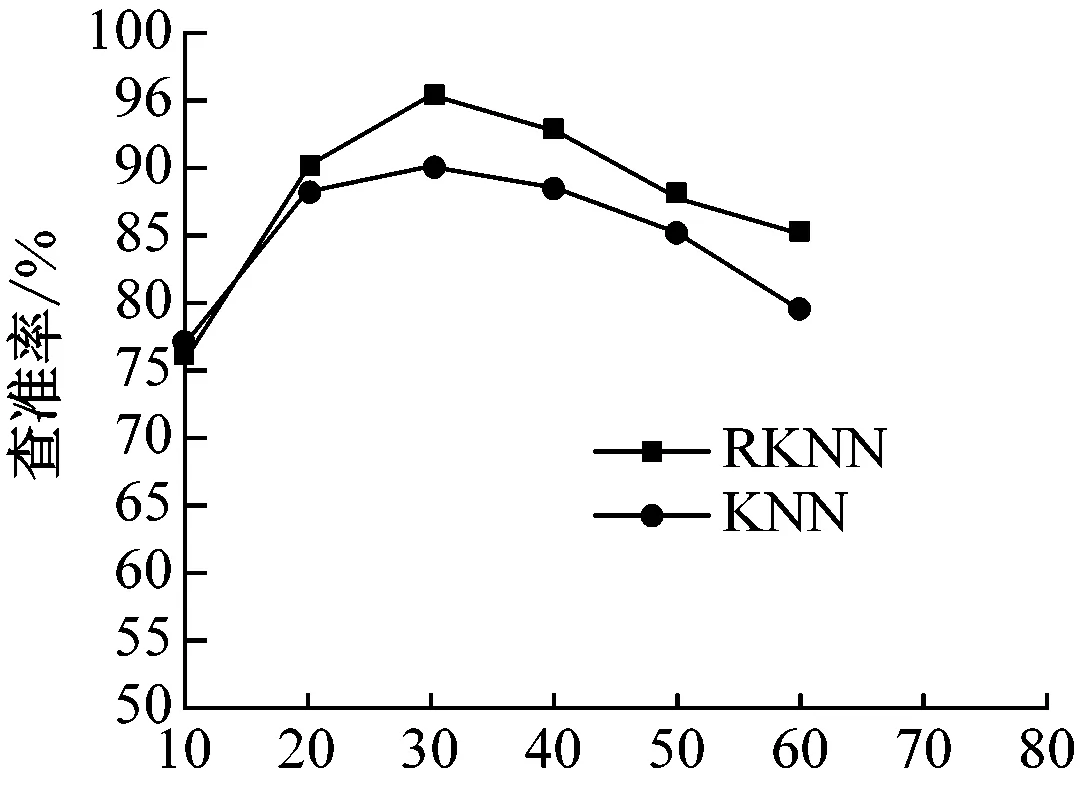
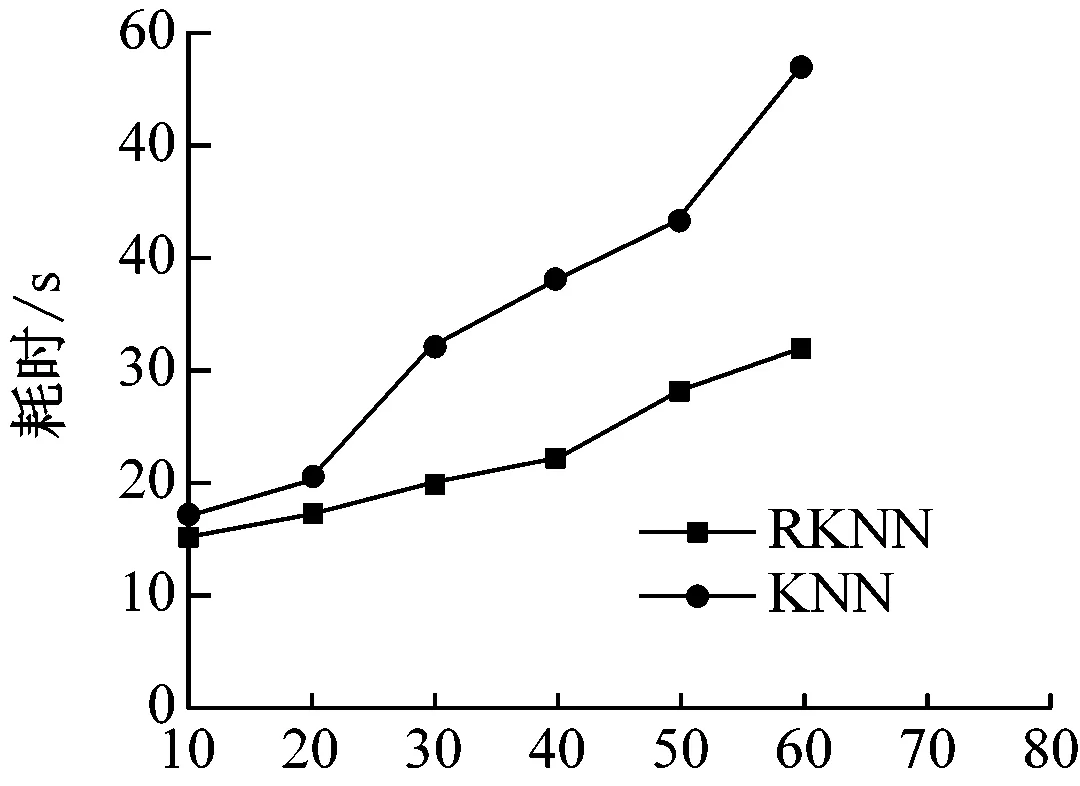
图5 RKNN与KNN的查准率、查全率和耗时对比结果
实验所采用的数据如表2所示。
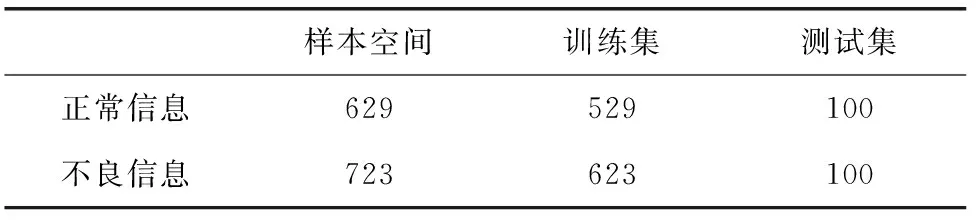
表2 实验样本数据
结果表明基于RKNN算法的过滤模型的性能更好,准确率较高,并且K值的选择较为关键,过小的K值易使分类器受到过分拟合(由噪声导致)的影响,过大的K值易融入进远离其近邻的数据点,实验表明K取30时得到了最高的查准率和查全率,这是因为RKNN算法有效优化了训练过程,通过删除部分会产生分类错误的样本实现了距离计算量的有效降低。
接下来设计仿真实验检测本研究安全过滤系统信息过滤的有效性,实验参数如表3所示。
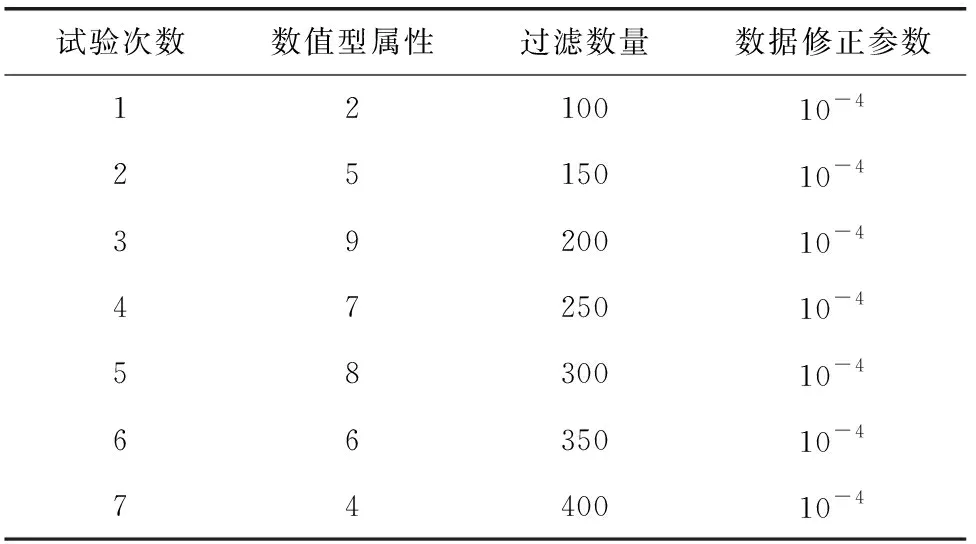
表3 实验参数表
SelectNsrsbh=NSRSBH,
Nsyc_lx=CONVERT(char(6),KPRQ),
Value_actual=sum(KPJE),
Value_threshold=0,
Nsyc_count=1intotemp_fp
andCONVERT(char(6),
KPRQ)<=Date_endgroup
byNSRSBH,CONVERT(char(6),KPRQ)
该安全过滤系统与传统方法的鲁棒性及过滤误差的实验对比结果,如图6所示。
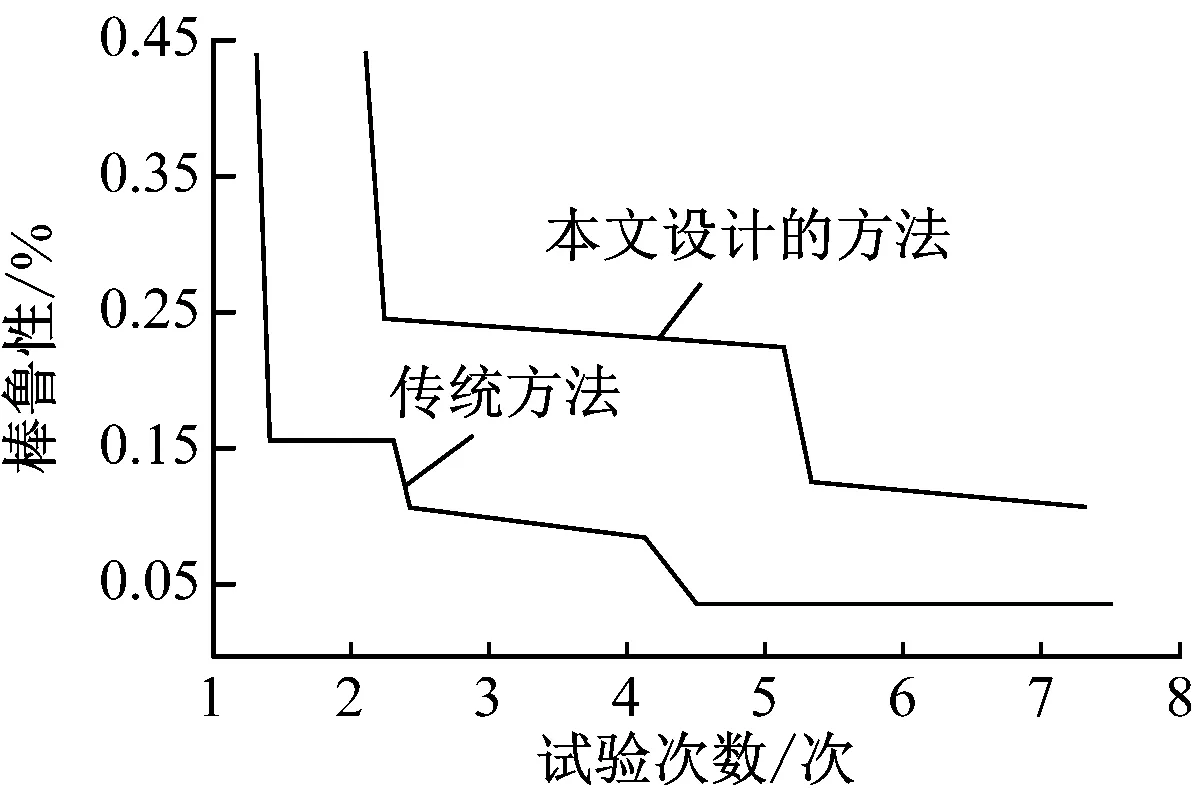

图6 仿真试验结果
相比传统方法,本研究所设计系统的鲁棒性较高,验证了系统的稳定性,并且随着数据量的持续增加,本研究所设计系统保持在较低的过滤错误率,该系统有效实现了网络不良信息的准确过滤过程,更加适用于实时在线网络系统,具有一定的实际应用价值。
5 总结
大数据时代的到来使Web环境越来越复杂,传统的信息安全过滤方法普遍存在数据动荡的缺陷,而信息的准确分类是过滤网络不良信息的基础,本研究构建了一种网络不良信息过滤模型,设计了一种基于C/S架构的网络不良信息安全过滤系统,进一步优化了权值的随机自适应算法,以确保过滤掉全部的动态大数据环境中的不良数据信息,最后采用对比仿真试验验证本研究不良信息过滤方法及安全过滤系统的有效性,实验结果表明该过滤模型明显提高了系统的处理效率、查准率和查全率,通过该安全过滤系统实现了对不良数据信息的有效过滤过程。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
制造技术与机床(2019年9期)2019-09-10 07:36:54
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
西南交通大学学报(2018年6期)2018-12-18 02:22:28
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
现代企业文化(2018年13期)2018-06-09 08:22:16
消费导刊(2017年20期)2018-01-03 06:26:38
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
河北遥感(2017年2期)2017-08-07 14:49:00
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
