
融合特征的深度学习遥感图像目标检测模型
2021-09-28 10:11张永福宋海林汪西莉
计算机技术与发展 2021年9期
张永福,宋海林,班 越,汪西莉
(陕西师范大学 计算机科学学院,陕西 西安 710119)
0 引 言
目标检测是计算机视觉的研究热点之一,随着遥感卫星以及无人机的增多,遥感图像数据的大数据特点日益凸显。遥感图像目标检测,即在遥感图像中获取特定目标的位置和类别,在公共安全、车辆监控、智慧城市等诸多方面具有重要的应用价值。遥感图像目标检测和普通光学图像目标检测相比有很多不同,如遥感图像尺寸较大,而目标相对所占比例小,目标可能非常密集,且目标的大小、姿态等可能会有很大的不同,遥感图像中的复杂背景以及遮挡、阴影等也会使目标检测难度增加。针对这些挑战及标记样本较少的实际情况,提出了一种融合特征的深度学习遥感图像目标检测模型,贡献主要有:小规模的网络结构应对标记样本少的问题,多级特征融合策略应对不同尺度目标检测难题,新的后处理算法进一步提升检测精度。所提模型和Faster R-CNN相比在提高检测精度的同时降低了漏检率和误检率。
1 相关工作
随着深度学习的兴起,卷积神经网络(convolutional neural networks,CNN)被用于图像目标检测,CNN通过大量的训练数据自主学习到图像的多层次特征,相对于传统的手工设计特征,展现了其自动和有效性[1]。但是卷积网络由于卷积和池化操作在信息传递时会导致信息丢失,进而对多尺度目标检测效果不理想。通常采用两种方式解决此问题,一种是改进卷积网络结构,如He等[2]提出了残差网络模型(residual neural network,ResNet),该模型建立前后层之间的“短路连接”,直接将输入信息与输出特征结合使特征更加完整,并有助于训练过程中梯度的反向传播,从而训练出更深的CNN网络,提高目标检测精度。Kuang等[3]提出了DenseNet网络,其每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入,通过这些操作达到保留特征的目的。
另一种解决思路是融合多级特征图。Sean等[4]提出了inside-outside net (ION),ION在最后一层卷积输出的特征图上分别在上、下、左、右四个方向独立地使用RNN,并将它们的输出连接成一个特征输出,将两次相同操作得到的特征作为上下文信息,再与前面不同的卷积层得到的特征连接起来作为一个特征输出。这样得到的特征既包括上下文信息,又包含多尺度信息,有利于对不同尺度的目标进行检测,使检测结果更加精确。Lin等[5]提出了特征金字塔网络feature pyramid network (FPN),利用特征图金字塔,通过bottom-up和top-down的方法创建了一个具有横向连接的自顶向下架构用在多尺度上构建高级语义特征图。Kong等[6]提出一种端到端的全卷积检测方法(RON),通过反向连接块将相邻的特征图融合起来,这样浅层的特征图融合了高层的特征图信息,然后分别对融合后的多个特征图做预测,预测得到的检测框整合在一起输出就得到整个网络的输出结果。Cai等[7]通过级联几个不同阈值训练得到的网络,前一个检测模型的输出作为后一个检测模型的输入,达到不断优化预测结果的目的。Singh等[8]提出了图像金字塔尺度归一化(SNIP),用图像金字塔来处理数据集中不同大小的数据。Zhang等[9]通过scale-depend pooling (SDP)来处理目标尺度多样的问题,根据目标大小选择合适的卷积层的特征作为分类器和边框回归器的输入特征。
上述文献研究基于深度学习的图像目标检测仍然存在一些不足。首先,GoogLeNet、ResNet等大型网络在训练时需要大量的标记样本[10],但遥感图像有标记样本往往有限,对于大规模的深度网络,少量训练样本会造成训练不充分。其次,级联不同网络会造成参数的增加,使时间成本增加。最后,现有特征融合方式未高效和有效地将浅层网络与深层网络信息融合用于预测,对遥感图像中小目标的检测帮助不大[11]。
本研究以Faster R-CNN目标检测框架为基础,提出了一种融合特征的深度学习遥感图像目标检测模型(fusion features based deep learning remote sensing image target detection model,FF-DLM),主要工作和创新包括:一,模型用小型卷积深度网络作为特征提取的主干网络,适用于训练样本较少的情况;二,在特征提取主干网络中通过融合特征图提高对不同尺度目标的检测率,在融合后的特征图上进行预测,降低漏检率,并采用RPN网络提取候选框,加快处理速度;三,提出一种新的检测框后处理算法——分组融合剔除检测框算法(packet fusion reject detection bounding boxes,PFR-DBB),在减少冗余检测框的同时微调检测框位置,使检测框对目标定位更精确。模型在有限的训练样本和相对较短的时间内,对遥感图像中较小且密集的目标取得了较高的检测正确率,较低的漏检率、误检率,且对目标定位更为准确。
2 方法原理
两阶段目标检测深度学习模型包括定位和识别两个阶段,其中region with convolutional neural network (R-CNN)[12]目标检测方法重复提取所有的候选区域特征而造成时间花费巨大,效率低下。为此,Fast R-CNN[13]使用ROI-Pooling将提取的候选区映射到最后一个卷积层的特征图上,只需要提取一次特征,大幅度提高了检测速度,但它使用Selective Search进行候选区域的提取耗时过多[14],为此Faster R-CNN[15]提出了区域建议网络(region proposal network,RPN),自动提取候选区域,这样可以使目标检测在一个网络中进行,真正形成端到端的训练。因此Faster R-CNN在时间、效率上比之前的模型有巨大的优势。遥感图像目标检测比普通光学图像目标的检测难度更高,文中以Faster R-CNN框架为基础,提出FF-DLM模型应对遥感图像训练样本较少、目标较小且密集等对目标检测带来的困难。
2.1 融合特征的目标检测模型
FF-DLM和Faster R-CNN目标检测模型具有相同的框架,模型包括3个部分:特征提取、区域提议和检测部分。首先利用一个小型的卷积网络提取特征;其次,融合多层特征图,将融合的特征图送到区域提取网络产生候选区域,再将候选区域送到目标检测网络中得到目标检测框和目标的类别;最后,使用分组融合剔除检测框(PFR-DBB)算法去除冗余的检测框,并调整检测框位置使其对目标定位更精确。
FF-DLM模型结构如图1所示。其中特征提取卷积神经网络有7层,前5层是卷积层,后2层是反卷积层。网络中的卷积核均采用较小的尺寸。为了减少参数个数,降低计算量,设置第一个卷积层卷积核的尺寸为7×7,第二层卷积核的尺寸为5×5,剩下的卷积层的卷积核尺寸为3×3。5个卷积层的卷积核个数分别为96、256、384、384、256。卷积核作用于前一层卷积操作后输出的所有特征图上,同一卷积核对于前一层不同特征图的权重不同以提取不同的特征。前四个卷积层包括卷积运算、Relu非线性激活处理、数据归一化和池化操作。采用最大池化方式,池化时对特征图进行Padding=1的扩充。最后一个卷积层不进行池化操作。反卷积阶段使用3×3的卷积核进行反卷积操作恢复conv4、conv5的特征图。这里通过卷积操作提取输入的遥感图像特征,池化操作保留卷积后的主要特征,减少干扰信息。
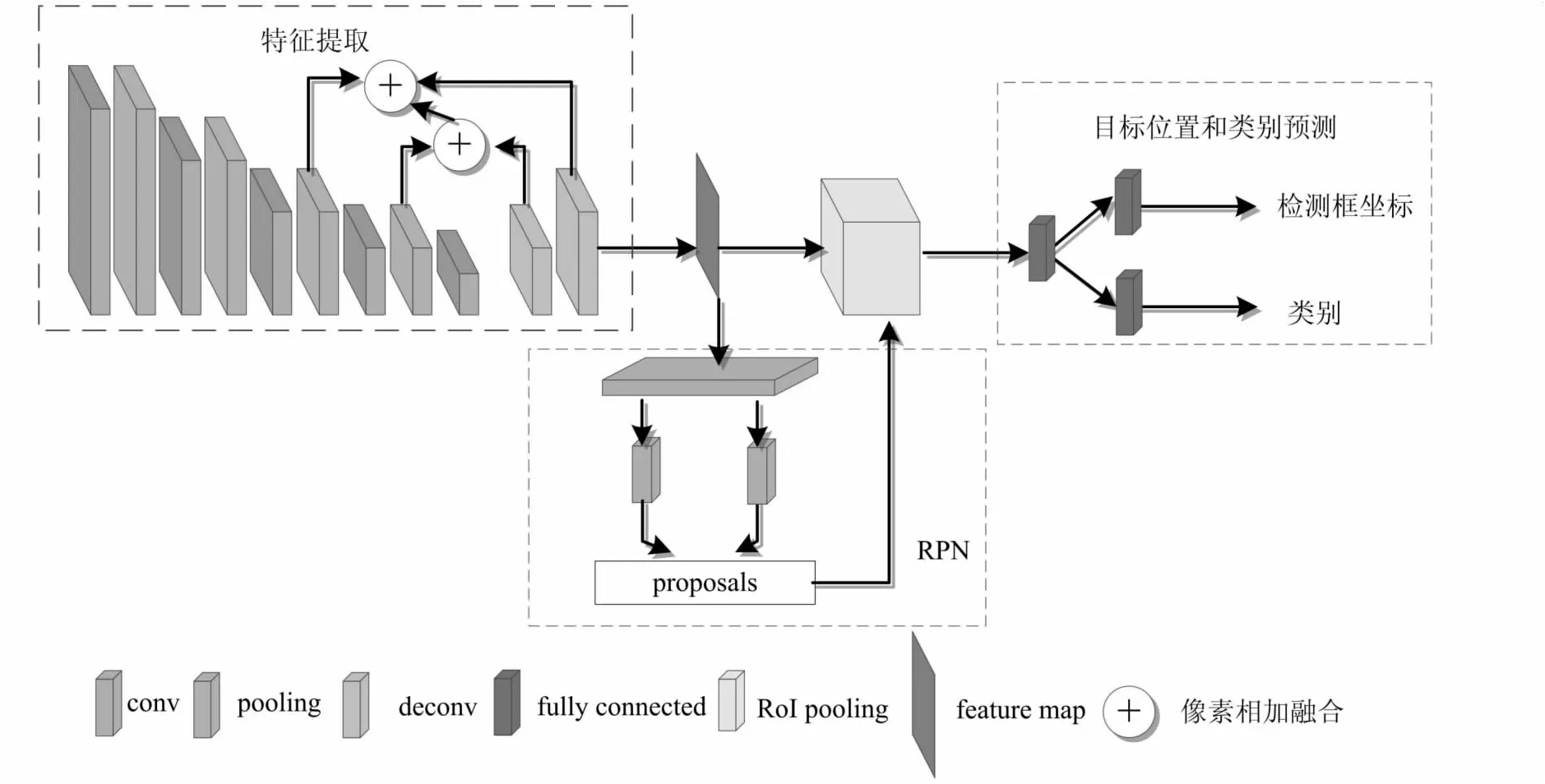
图1 FF-DLM模型结构
鉴于越深层次的特征语义信息越丰富,特征越来越抽象,分辨率越来越低;层次较浅的特征具有较高的分辨率,适于小目标的检测,故提出将多级特征融合以保留不同尺度目标的特征来适应不同尺度目标的检测任务[16]。为了进行融合操作,对conv4、conv5通过反卷积操作得到增大的特征图,在高分辨率特征图上保留语义信息。然后将conv3、conv4、conv5的特征图进行逐像素相加的融合,融合结果既包含浅层次的细节特征,又包含深层次的语义特征。接着,用3×3的卷积核在卷积神经网络融合后的特征图上滑动,每个滑动窗口产生9个不同比例{1∶1,1∶2,2∶1}、不同尺寸{322,642,1 282}的锚框(anchor box),之后用两个1×1的卷积核判断其是否为目标并进行位置回归,将所有锚框按目标置信度排序,取前300个作为候选框。最后将候选框送到检测网络再次对候选区域进行分类,并回归得到目标边界框的坐标。由于多级尺度特征的融合使提取的目标特征更为有效,模型不仅能检测出特征明显的目标,对于尺寸较小的目标、干扰较多的大的目标也提升了检测率,降低了背景对目标的干扰造成的误检。
2.2 分组融合剔除检测框算法(PFR-DBB)
目标检测网络最终输出的检测结果中一个目标可能会被多个检测框检出,且对目标定位可能不够准确。经典的非极大值抑制算法(non-maximum suppression,NMS)[17]将所有的检测框按照置信度从小到大排序,保留得分最高的检测框,计算该检测框与其他检测框的IOU,当IOU大于设定的阈值,则删除该检测框。NMS算法仅去除多余的检测框,没有对检测框位置进行调整,最终剩下的检测框对目标的定位不够准确,且仍然存在多个目标被框在一个检测框中或一个目标被多个检测框包围的情况。
为了同时减少漏检、误检,并使检测框位置更为准确,文中提出了一种新的后处理方法,分组融合剔除检测框算法(PFR-DBB)。这种方法和NMS类方法的思想完全不同,通过分组处理的方式,在去除冗余框的同时对检测框进行位置的微调,使其对目标定位更精准。PFR-DBB先将检测框分成不同的组,认为每组检测框框住的是同一个目标,这样做是为了防止两个位置较近的物体被框到一个检测框中的情况;然后对每组中的检测框再进行处理,剔除多余检测框,同时调整检测框的大小和位置,使检测框对目标的定位更为精确。
算法包括两个部分,首先是分组过程,对应于算法步骤中的(1)~(4),其次是在每个分组中去除冗余的检测框,同时微调检测框位置的过程,对应于步骤(5)、(6)。后处理算法过程如下:
(1)将所有的检测框按照置信度递增排序,得到m个检测框{R1,R2,…,Rm},放入队列Q中,令i=1;
(2)将Ri放入组Gi中,并将其从Q中移除,将i+1→j;
(3)如果IOU(Ri,Rj)>0.6,则将Rj放入组Gi中并从Q中移除,j+1→j。若j>m转到(4),否则转到(3);
(4)i+1≥i,如果Q不为空,转到(2);若Q为空,分组过程结束,这时把检测框分成了多个组,每个待检测目标对应一组检测框;
(5)将组内的所有检测框按照面积递增顺序加入到一个队列中;
(6)对于每个组对应的队列,从第一个检测框开始依次计算它与队列中其他检测框间的IOU值,如果IOU值大于0.7,则计算重叠区域的中心,以此为新检测框的中心,以两个框的长之和的一半为长,宽之和的一半为宽,重新构造一个检测框并将该框加入队尾,删除这两个检测框;否则和队列中的下一个检测框对比;重复本步骤直到队列中检测框间的IOU均小于0.7,得到最终的检测框。
3 实验设置与评价指标
实验使用的是Ubuntu14.04系统,硬件配置为Intel(R) Xeon(R) CPU E5-2690 2.60 GHz处理器、256 GB内存和4 TB硬盘,采用Caffe深度学习框架。训练过程中参数设置如下:初始学习率为0.01,迭代次数每增加10 000次,学习率降低0.1倍,gamma为0.1,权重衰减为0.000 5,动量为0.9。
评价指标包括IOU(intersection over union)、AP(average precision)、误检率FAR(false alarm rate)和漏检率MR(missing ratio)。IOU指检测得到的结果和标注结果重合的程度;AP是查准率的平均值,用来衡量检测效果;FAR计算的是误检为目标的结果的数量占目标总数的比例;MR计算的是没有被检测出的目标占目标总数的比例。将召回率分成n级,则IOU、AP、FAR、MR分别用下式计算:
(1)
(2)
(3)
(4)
(5)
其中,B是检测得到的检测框,BT是Ground Truth,r是查全率,TP是真正例,TN是真反例,FP是假正例,FN假反例。
4 实验结果和分析
4.1 飞机目标检测实验
遥感数据集中的样本相对较少,为了提高检测精度,利用迁移学习的思想,先对模型使用Pascal VOC 2007数据集进行预训练。预训练结束后,分别使用UCAS-AOD[18]、RSOD-Dataset[19]遥感数据集中的飞机目标样本对模型进行微调训练,使网络中的权值学习更充分。UCAS-AOD和RSOD-Dataset中的飞机数据集在实验中被划分成训练集和验证集(70%)以及测试集(30%),具体信息如表1所示。

表1 UCAS-AOD、RSOD-Dataset飞机数据集
图2给出了Faster R-CNN和FF-DLM的一些测试样本的检测结果。由结果可见,在不同的场景以及光照条件下,FF-DLM的检测结果与Faster R-CNN的检测结果相比目标检出率均有提高。FF-DLM对分布密集的小目标(即使背景和目标的光谱特征相似)、不同尺度的目标检出情况较好。图2中(1)~(4),由于场景中目标和背景特征相似或目标较小等情况,Faster R-CNN都有漏检的目标,而FF-DLM较好地检出了这些目标。另外图像中的被漏检绿色的小飞机被检测出,说明FF-DLM的特征融合策略有利于复杂场景不同尺度目标的检出。小飞机和一些背景在形状、颜色等方面和飞机较为相似,容易将背景误检为目标。图2中的(5)、(6)显示了Faster R-CNN误将背景检测为目标,而FF-DLM减少误检的情况。实验结果表明FF-DLM模型可以在小样本数据集上充分学习,和Faster R-CNN比较,在提高检测率的同时减少了误检、漏检的情况。

图2 不同深度目标检测模型飞机检测结果
图3显示了FF-DLM采用PFR-DBB算法和NMS算法对检测框进行后处理的结果。图3的(1)图中(a)子图是用NMS算法后处理的结果,其中有两个小飞机被检测到一个框里面,(2)、(3)图中有的小飞机被多个检测框框住。而采用PFR-DBB算法有效去除了多余检测框,且没有将两个目标框到一个检测框中的情况,同时对一些检测框的位置和大小进行了调整,使目标定位更加精确,从而提升了检测精度。

图3 检测框后处理结果
采用平均准确率AP对检测结果进行定量评价,Fast R-CNN、Faster R-CNN模型和FF-DLM的检测结果和所用时间如表2所示。其中Fast R-CNN和Faster R-CNN采用ZF网络作为特征提取主干网络,它和FF-DLM模型都采用训练Pascal VOC数据集得到的参数为初始参数进行训练,测试时IOU设置为0.7。Fast R-CNN和Faster R-CNN未进行特征融合,后处理方法和FF-DLM模型不同。从表2可见,FF-DLM在检测精度、检测时间上都具有明显的优势。FF-DLM使用RPN提取候选区域比Fast R-CNN使用Select search穷举搜索提取候选区域减少了大量的时间,并且实现了端到端的训练使精度提高。和Faster R-CNN相比,FF-DLM进行多级特征的融合,使模型可以更好地提取有效的特征,提高了检测精度,降低了误检率。还因为FF-DLM使用了PFR-DBB后处理算法,比Faster R-CNN使用NMS算法对目标的定位更加精确,也为检测精度的提高做出了贡献。FF-DLM使用小型网络作为主干网络,在样本不是很多的情况下可以使学习更加充分,得到更好的检测结果。

表2 不同数据集上不同模型的结果比较
表3展示了飞机数据测试集在不同的模型上的漏检率和误检率。可见,采用PFR-DBB后处理算法的FF-DLM模型比Faster R-CNN和采用NMS后处理算法的FF-DLM模型的效果要好。由于融合不同层特征使模型对于遥感图像中小目标的特征能够更好的学习与定位,提高对小目标的检测性能。同时因为对特征学习的更加充分,可以降低误检率。此外,采用所提PFR-DBB后处理算法对于提升检测精度也带来了贡献。

表3 Faster R-CNN和FF-DLM模型在UCAS-AOD测试集上的漏检率和误检率
4.2 汽车目标检测实验
采用UCAS-AOD遥感数据集汽车目标进行实验。图像大小为1 280×659,共用了310张图像,其中训练集和验证集的图像268张,测试集图像42张。使用不同的模型进行检测的结果如表4所示。FF-DLM模型和Faster R-CNN的结果进行比较,得到了较低的误检率、漏检率和较高的精度。对测试集在检测精度上FF-DLM模型比Faster R-CNN提高了7.9%。同时,后处理算法PFR-DBB比NMS在提高检测精度以及降低漏检率和误检率上表现更好。

表4 Faster R-CNN和FF-DLM模型在汽车数据集上的检测精度、漏检率、误检率
遥感图像中的汽车目标与飞机目标相比,所占像素更少,汽车的方向、大小、颜色差别大,所处场景多变,检测起来更加困难。从图4可见,FF-DLM模型对不同场景中的汽车的检测结果比Faster R-CNN的检测效果都好。图4中的(1)图显示FF-DLM不仅减少了漏检目标个数,而且检测框对目标的定位更加精确;(2)图中FF-DLM模型将较小以及颜色与背景相似的汽车均能检测出来,与Faster R-CNN相比误检汽车数大幅度减少;(3)图中汽车尺寸更小,背景与汽车的颜色更为相似,可以明显看出FF-DLM的检测结果更好。

图4 不同检测模型对遥感图像中汽车的检测
Faster R-CNN仅使用较深层的特征图,对于小目标的检测效果并不好,漏检汽车的数量较多,而且检测框对目标的框取不够精确,且将很多阴影部分错检为汽车;FF-DLM检出的目标更多,没有将阴影错检为汽车。可见所提模型对于汽车目标同样取得了较好的检测效果,表明模型在少量样本下对于多尺度的目标检测具有优势。
5 结束语
提出了一种深度学习遥感图像目标检测模型,针对复杂场景遥感图像中密集的、大小不一、姿态各异的目标,以及训练样本有限的情况,提出融合多级特征的小型卷积神经网络提取有效的目标特征,并提出PFR-DBB后处理算法在有效去除冗余检测框的同时微调检测框位置。所提模型在两个遥感图像数据集上获得了明显优于比较方法的检测结果,在提高检测正确率的同时降低了漏检率和误检率。在更小的汽车目标上同样取得了明显优于对比方法的结果,表明所提模型在样本有限的情况下对不同尺度的遥感目标检测具有优势。
由于所提模型在规模上、采取的特征提取手段上都是简单、适合标记样本不是很多的情况的,如果结合注意力、特征金字塔等更多特征提取阶段的措施,性能将会进一步提升,当然训练和测试时间相应也会增加。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
汽车实用技术(2022年15期)2022-08-19
计算技术与自动化(2022年1期)2022-04-15
汽车工程师(2021年12期)2022-01-18
现代仪器与医疗(2021年4期)2021-11-05
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
化学教学(2015年4期)2015-06-18
读者(2015年9期)2015-05-04
