
面向GPU Cache的访存请求处理技术
2021-09-27 16:15李炳超
电脑知识与技术 2021年19期
关键词:线程
李炳超

摘要:GPU内部大量线程的同时运行会生成大量的访存请求,当访问同一L1 Cache組的访存请求所涉及的空间超过L1 Cache一组的容量时,由于没有Cache行可以分配而导致当前访存请求及后续所有访存请求发生停顿,影响了GPU的性能。该文设计了一种访存请求缓冲队列结构,访存请求被发送到不同的队列中,并通过调度策略来选择不会发生停顿的访存请求访问L1 Cache。实验表明,该方法能够有效地减少停顿次数,使得GPU的性能平均提高了26%。
关键词:图形处理器;高速缓冲存储器;线程;访存请求;单指令多线程
中图分类号:TP33 文献标识码:A
文章编号:1009-3044(2021)19-0128-03
1引言
近十多年来,GPU受到越来越多的应用程序的青睐。它不仅可以处理高分辨率的3D图形应用,还能为一些具有数据并行特征的应用程序加速,如图算法、天气预报、加密算法、生物信息处理等等。特别是对于深度神经网络的迅速发展,GPU的硬件支撑起到了积极的推动作用。
GPU由多个可执行相同程序的流多处理器构成,每个流多处理器内部具有数十个用于并行计算的计算核心。另外,为了减少访存操作的开销,GPU还为每个流多处理器配备了高带宽、低延迟的L1 Cache。用户将应用程序的任务以线程为单位进行细分,进而将多个线程组成一个线程块。应用程序以线程块为单位被派遣到各个流多处理器上。每个流多处理器能够同时运行上千个线程,32个线程会被硬件组织成一个线程束。GPU采用单指令多线程的执行模式,一个线程束内的线程以并行的方式执行同一条指令。另外,为了服务计算核心的并行计算需求,GPU在每个流多处理器内部配备了高带宽、低延迟的L1 Cache。GPU在执行访存指令时,线程束内的每个线程都能够生成一个访存请求。GPU的读写单元对访问同一数据块(例如128字节)的访存请求进行合并来减少访存请求个数,从而能够减少访存指令的处理延迟和存储系统的拥堵。对于一些具有不规则数据结构的应用程序,线程束生成的访存请求并不能被读写单元全部合并,从而导致一条访存指令产生多个访存请求,线程束需要串行处理各个访存请求并且等待所有访存请求的数据准备就绪才能继续执行。如果访存请求在L1 Cache中发生命中,则直接从L1 Cache中获取数据;如果发生缺失,根据替换策略,L1 Cache需要为当前缺失的访存请求分配一个Cache行,并向下一级存储器发送访存请求来为该Cache行获取数据。在缺失的数据未取回之前,该Cache行处于“预留”状态,表示该Cache行已经被占用并且不能被替换。
然而,GPU的L1 Cache需要为流多处理器内部的所有线程服务,过多的访存请求将会在L1 Cache发生资源竞争[7]。当访存请求所需的资源全部被占用时,所有的访存请求都不得不发生停顿,从而影响了GPU的性能。文章对由L1 Cache资源竞争引起停顿进行了具体的分析,设计了一种处理访存请求的方法REOD。REOD包含一个多缓存队列结构,并结合相应的调度策略,能够有效地缓解访存请求的停顿现象,最终提高GPU的性能。
2访存请求停顿
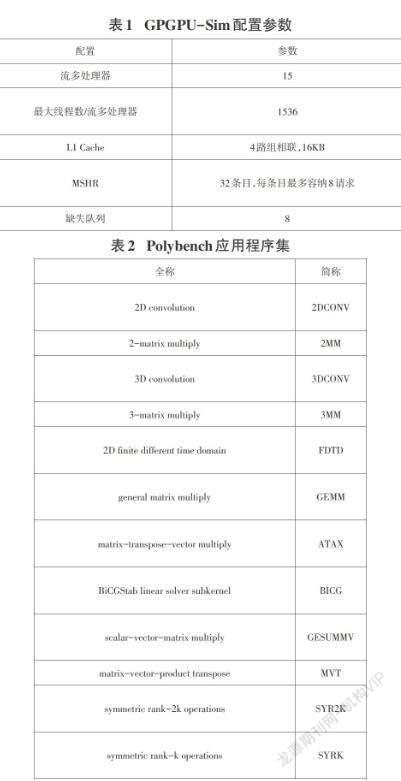
由于流多处理器内部能同时运行上千个线程,并且每个线程束又能够产生多个访存请求,因此流多处理器内部会存在大量的访存请求对L1 Cache进行访问。频繁的访问L1 Cache不仅会造成Cache行局部性的丢失,甚至会造成L1 Cache的暂停。图1描述了造成访存请求停顿的三种现象:(1)对于采用组相联映射的Cache架构,访存请求只能访问其访存地址所映射的Cache组。由于大量线程的同时运行,并且每个线程束又能够产生多个访存请求,从而导致访存请求对某一Cache组的集中访问。若一个Cache组的所有Cache行都已经处于“预留(R)”状态,则意味着当前Cache组中没有可以被替换的Cache行,表示该Cache组已满(例如图1中的Cache组set-0)。若继续有访存请求访问该组并发生缺失,该访存请求只能停顿并等待数据返回该Cache组才能继续被处理。对于这种停顿现象,文章将其命名为“CSF”;(2)若缺失的访存请求没有发生CSF,那么缺失信息会暂存在缺失状态保持寄存器MSHR中。MSHR由多个条目构成,每个条目保存一个Cache行的块地址,每个条目可容纳若干访问该Cache行的访存请求。当访存请求发生缺失时,若MSHR所有的条目都已经被占用或将要访问的Cache行所容纳的访存请求个数已满,该访存请求也会发生停顿,文章将这种停顿现象命名为“MSHRF”;(3)若MSHR能够保存缺失信息,则访存请求会被发送到片内互联网络的缺失队列中。如果缺失队列已满,则访存请求依然会发生停顿直到缺失队列中的一个访存请求被片内互联网络发送出去,文章将这种停顿现象命名为“MQF”。在以上三种情况中,访存请求发生停顿之后,后续访问其他未满Cache组的访存请求也必须停顿等待,从而造成访存指令处理延迟的增加,严重影响GPU的性能。
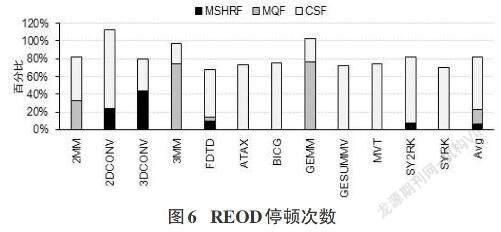
文章对一些应用程序运行过程中发生的停顿次数进行了统计并进行了归一化,如图2所示。三种停顿现象中,CSF的平均比例为92%,MSHRF的平均比例为1%,MQF的平均比例为7%。因此,访存请求发生停顿的主要瓶颈是一个访存请求由于所要访问的Cache组没有可分配的Cache行而造成所有的访存请求都发生停顿。
3 REOD架构
3.1多缓存队列结构
REOD的主要目标是减少CSF次数,使得访存请求出现CSF时不会影响后续访存请求的处理。为此,文章在REOD中设计了一种新的访存请求缓存队列结构,并结合访存请求调度策略,有效地减少访存请求的停顿现象。如图3所示,REOD包含若干个容量较小的队列,每个队列可与一个(或多个)Cache组对应。线程束的访存请求在访问L1 Cache之前,首先要根据访存请求的访问地址计算其将要访问的Cache组索引,然后根据Cache组索引通过队列选择器将访存请求发送到相应的缓存队列中。访存请求选择器在每个周期根据轮询调度器的调度结果从所有的缓存队列中选取一个有效的访存请求发送到L1 Cache进行访问。若新的访存请求所对应的缓存队列已满,则该访存请求暂定等待。
猜你喜欢
山西电子技术(2021年3期)2021-06-28
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
环球市场(2017年36期)2017-03-09
网络安全技术与应用(2016年10期)2016-02-06
计算机与网络(2014年6期)2014-05-25
计算机工程与科学(2013年2期)2013-06-07
网络安全与数据管理(2012年8期)2012-08-15
吉林建筑大学学报(2012年3期)2012-08-15
杭州电子科技大学学报(自然科学版)(2010年5期)2010-01-08
