
Audio2Face基于音频文件智能生成虚拟角色面部动画
2021-09-27 07:43:40蔡国鑫
现代电影技术 2021年9期
近日英伟达 (Nvidia)公司发布了一款基于人工智能 (AI)的Audio2Face应用程序,根据音频源生成3D 虚拟角色面部动画并实现唇音同步,可用于实时交互应用或作为内容创作通道。传统虚拟角色面部动画制作需进行建模、绑定、动画等一系列处理,而Audio2Face以.wav或.mp3音频文件为输入,直接生成角色面部动画或几何缓存,制作人员只需根据应用需求进行调整定制即可使用。
1 Audio2Face技术难点与解决方案
仅由音频源生成虚拟角色面部动画和实现唇音同步的难点在于基于同一音频源可能生成多种不同的面部动画。尽管深度卷积神经网络 (DCNN)在各种推理和分类任务中非常有效,但如果训练数据中存在歧义,其往往会向均值回归,因此基于深度卷积神经网络为虚拟角色生成逼真且一致的面部动画尚存在一定困难。
针对技术难点,Audio2Face提出了以下解决方案:
(1)设计一种深度卷积网络,用于有效处理人类语音并在不同的虚拟角色上实施模型泛化。
(2)采用一种新颖方法,使网络能够发现训练数据中不能由音频单独解释的变化,即明显的情绪状态。
(3)构建具有三个损失项的损失函数 (Loss Function),确保在数据高度模糊的情况下,网络依然能够具有时间稳定性和快速响应能力。
2 Audio2Face网络结构
按照功能划分,Audio2Face网络由频率分析网络(Formant Analysis Network)、发音网络 (Articulation Network)和输出网络 (Output Network)组成,网络结构如图1所示。
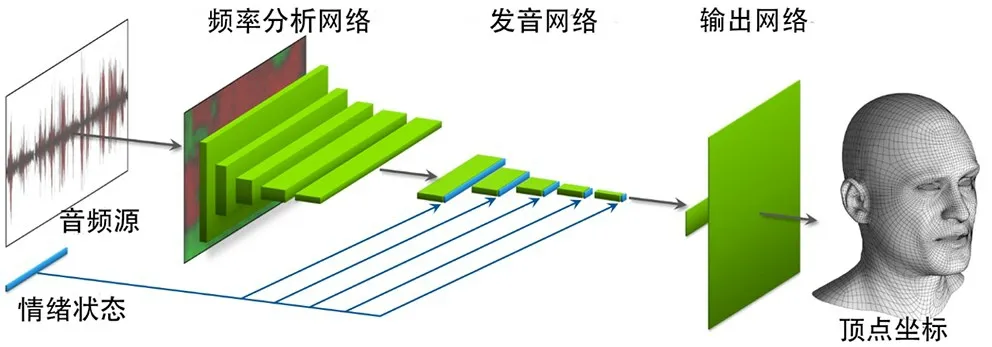
图1 Audio2Face网络结构
频率分析网络 (Formant Analysis Network)包括一个固定功能的自相关分析层 (Fixed-Function Autocorrelation Analysis Layer)和5 个卷积层。自相关分析层使用线性预测编码 (Linear Predictive Coding,LPC),以提取音频的自相关系数。自相关系数描述了原始音频信号共振峰的能量谱分布,可用于表示音频特征。自相关层以多帧音频信号为输入,处理后输出2D 音频特征图,2D 音频特征图再经5个卷积层对自相关系数进行压缩,学习并提取与面部动画相关的短时特征,如语调、强调和特定音素等,最终输出特征向量。发音网络(Articulation Network)使用5 个卷积层在时序上提取相邻序列帧的关联特征,输出语音特征图。由于语音不仅与声音频率密切相关,还与说话者的情绪和类型等特征密切相关,因此发音网络还需输入通过训练提取的情绪状态。情绪状态采用数据驱动方法由神经网络自动学习生成,并被添加到发音网络所有层的激活列表中,成为损失函数计算图的一部分,在误差反向传播期间随着网络权重变化而更新。输出网络 (Output Network)通过两层全连接层实现从特征到人脸表情顶点坐标的映射,其中第一个全连接层将语音特征映射到人脸表情系数,第二个全连接层将表情系数映射到顶点坐标值。
3 Audio2Face训练数据集
训练数据采用专业动作捕捉设备采集,直接捕捉演员头骨、肌肉和皮肤的细微动作,通过多角度重建技术获得每帧的3D 人脸数据,并逐帧对齐到标准人脸模版,以得到拓扑一致的逐帧表情数据。整个数据集包括两个演员的表演数据,训练数据集和测试数据集分别包括15000帧和2600帧的图像数据。录制人员通过不同情绪分别说出所有字母和指定剧本,尽可能包含不同字母的发音,以获得更多的情绪样本。
4 Audio2Face损失函数
损失函数(Loss Function)用来评价模型预测值和真实值 (Ground Truth)的差异度,损失函数值越小,模型性能就越好,不同模型一般使用不同的损失函数。考虑到训练数据的模糊性,Audio2Face设计了一个包含三个损失项的损失函数:(1)位置项 (Position Term):描述了期望输出与预测输出之间的逐顶点坐标值的均方差值,以确保输出的每个顶点位置大致正确,位置项只约束了单帧预测误差,并未考虑帧间关系,容易导致帧间表情动作波动;(2)运动项 (Motion Term):可确保输出的帧间顶点运动趋势与数据集一致,以有效避免表情动作抖动,使表情动作更趋平滑;(3)正则项(Regularization Term):用于确保网络正确地将短时效应归因于音频信号,将长时效应归因于情绪状态,避免学习到的情绪状态包含与音频信号相似的特征。对于包含多个损失项的损失函数,主要挑战在于如何给各个损失项确定适宜的权重值,以实现整体最优并区分重要性,为此Audio2Face对每一项都进行了归一化处理,以避免额外增加权重。
5 相关研究及解决方案
2019年浙江大学和网易伏羲AI实验室曾发表了一篇由音频源智能生成虚拟角色面部动画的论文,该方法在网络输入、网络结构、损失函数上均与Audio2Face有所不同。关于网络输入,该论文通过对梅尔频谱进行倒谱分析得到梅尔频率倒谱系数(Mel Frequency C epstrum Coefficient,MFCC),将其作为声学特征输入网络。该论文也对MFCC和线性预测编码 (LPC)进行了分析比较,考虑到训练数据特点,最终选择了MFCC。
关于网络结构,该神经网络由输入层、长短时记忆层 (Long Short-Term Memory Layer,LSTM 层)、注意力层(Attention Layer)和输出层组成,如图2所示。该神经网络的特点是LSTM 层包含两个双向长短时记忆网络 (Bidirectional LSTM),LSTM 层将音频特征作为输入提取高级语义信息并输出到注意力层学习注意力权重。这种结构使网络能够记忆以往输入的音频特征,并鉴别可对当前动画帧产生影响的音频特征。
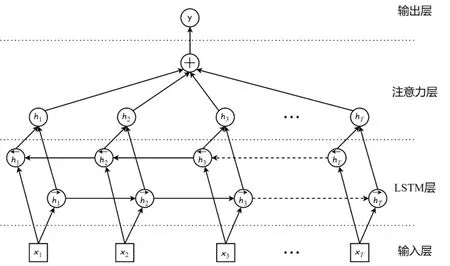
图2 浙大论文所采用的神经网络结构
关于损失函数,该论文也采用了拥有多个损失项的损失函数,该损失函数包括目标损失和平滑损失,前者用于确保每个输出的BlendShape角色表情参数基本正确,后者用于保证在训练网络时的时间稳定性和帧间平滑度。以上两项损失的作用与Audio2Face损失函数的位置项、运动项大致相同。总之,浙大论文与Audio2Face的主要区别在于采用不同方法来解决同一音频源生成虚拟角色面部动画不一致的问题,其使用注意力层来鉴别可对动画产生影响的音频特征,Audio2Face则引入情绪状态并配合损失函数正则项,通过情绪状态特征来确定最终的输出动画。
6 未来展望
上述两种方法由于角色的眨眼与音频之间无任何关联性,无法准确地模拟角色眨眼和眼球运动,此外浙大论文中所述模型尚无法生成高质量的面部图像。Audio2Face目前仍处于公开测试阶段,应用案例很少,其在升级版中将允许用户直接通过训练参数调整输出结果或通过组合不同表情以实现复杂效果,因而制作人员可省去建模、绑定等步骤,根据实际需求智能生成音频对应的面部动画。总之,根据现有功能实现和未来扩展升级,Audio2Face有望能够简化虚拟角色面部动画制作流程,提升虚拟角色面部动画制作效率,有效服务影视虚拟角色动画的智能化制作。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
电子制作(2019年11期)2019-07-04 00:34:38
家庭影院技术(2018年11期)2019-01-21 02:20:52
今日农业(2019年15期)2019-01-03 12:11:33
电子制作(2018年19期)2018-11-14 02:37:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电子制作(2017年9期)2017-04-17 03:00:46
人间(2015年8期)2016-01-09 13:12:42
