
基于XGBoost的列控车载设备故障预测方法
2021-09-26 08:46许康智蔡伯根郭忠斌
北京交通大学学报 2021年4期
刘 江,许康智,蔡伯根,郭忠斌,王 剑
(北京交通大学 a.电子信息工程学院,b.智慧高铁系统前沿科学中心,c. 北京市轨道交通电磁兼容与卫星导航工程技术研究中心,d.计算机与信息技术学院,北京 100044)
进入新世纪以来,在智能交通全面深化、智能创新应用层出不穷的时代背景下,铁路系统的智能化发展正面临着前所未有的挑战[1].近年来,欧洲、美国、日本均已制定了铁路数字化发展战略,旨在通过推进新兴技术和铁路业务的高效融合,优化运输服务质量、增强运输安全水平、提高运输组织效率、降低运输成本、提高经营效益,我国高速铁路从自动化、数字化、网络化阶段走向智能化发展,已成为明确的发展需求[2].作为高速铁路系统运行的“大脑和中枢神经”,列车运行控制系统具有显著的安全苛求特征,由于其与高速列车、基础设施之间构成的协同运行结构及关系复杂,对自身内部因素及外部环境的敏感性强,任何微小的故障、失误或隐患都有可能引发连锁反应造成安全风险.如何实现以安全保障为前提、经济性与可行性为导向的智能化维修维护,是有效防护列车运行控制系统运用风险、优化系统全生命周期成本水平的重要条件.
近年来,高铁关键装备的智能维护已受到广泛关注,面向高速动车组牵引制动系统[3-4]、悬挂系统[5]、齿轮箱[6]、接触网与供电设备[7-8]、轨道线路与桥梁[9-10]以及维护计划的编制优化[11]等多个方面均已形成了相应成果.对于列车运行控制系统车载设备的智能维护,目前已在电务大数据汇集、一体化运维平台架构以及可靠性分析等方面进行了初步设计与尝试,方法研究层面的成果集中于列车运行控制系统故障风险分析与诊断方法和可靠性评估方法两个方面.故障风险分析与诊断方法包括Dempster-Shafer与神经网络[12]、多智能体组合协同诊断[13]、深度学习模型[14]、粗糙集-智能搜索优化神经网络[15]等;可靠性评估方法包括故障树[16]、贝叶斯网络[17]、随机Petri网[18]、UML状态图工具STOCHARTS[19]等.在此基础上,国内外研究人员已开始针对列车运行控制系统维修维护模式优化及视情维修决策开展了探索性研究,代表性的包括列车运行控制系统视情维护模式框架设计[20-21]、车载设备健康管理模式[22]、基于机器学习的故障预测[23]、基于风险指数的设备寿命预测[24]等.总体来看,当前高速铁路列车运行控制系统中视情维修(Condition-Based Maintenance,CBM)思想尚未得到有效实施.为此,引入全生命周期思想,建立列控车载设备特征追踪、可靠性评估与动态健康诊断机制,是进一步提升智能化水平、优化系统能力、发挥成本效益、支撑新型装备标准体系构建的必然方向.
现阶段,现场设备的维修维护工作主要基于列车运行记录数据结合人工分析来实施,对于引入智能化手段实现自动诊断、决策处理仍面临着两方面技术难题:1)列控车载设备需满足既有规范约束和安全原则,无法根据监测诊断等需求直接增设既有系统之外的相关设施;2)列控车载设备既有模式下随运营过程累积了大量的运行日志信息,对现场维护人员进行准确的深度分析并充分运用其中的间接相关信息带来了巨大挑战.近年来,故障预测与健康管理(Prognostics and Health Management,PHM)技术在航空、机械、电力、军事等领域的智能运维中得到了广泛关注[25-26],以机器学习为代表的智能技术与大数据条件的深度融合,为实施数据驱动的设备故障特征建模、趋势分析以及维修维护决策等提供了重大机遇[27].基于这一背景,本文作者以CTCS2-200H型列控车载设备为对象,分析了设备结构体系与典型故障特征,结合列控车载设备数据平台提供的支撑条件,引入极端梯度提升(eXtreme Gradient Boosting,XGBoost)算法设计了一种基于数据驱动的列控车载设备故障模型构建与预测方法,并结合在实际现场收集的设备运行数据对所提出方法的建模性能及预测效果进行了验证,为进一步构建基于大数据驱动的列控车载设备故障模型与智能维护体系提供技术基础.
1 列控车载设备故障特性
1.1 列控车载设备结构
列控车载设备用于实现具体的控车操作,是保障高速动车组安全运行的关键设备之一,主要根据地面设备发送的行车信息由安全计算机生成列车运行速度控制曲线,对列车沿轨道方向的纵向运行速度进行监督与控制.在故障预测方法方面的研究以CTCS2-200H型列控车载设备为对象,该设备主要由车载安全计算机VC、轨道电路信息接收模块STM、应答器信息传输模块BTM、继电器单元RLU、记录单元DRU、人机界面DMI、测速测距模块SDU、轨道电路信息接收天线、应答器信息接收天线等组成,并与列车运行监控装置LKJ、车辆接口等相连[28].CTCS2-200H型列控车载设备的组成结构如图1所示.

图1 CTCS2-200H型列控车载设备组成结构Fig.1 Architecture of CTCS2-200H on-board train control equipment
1.2 列控车载设备故障类型分析
CTCS2-200H型列控车载设备获取并处理轨道电路信息和应答器信息,管理CTCS-2级控制模式,控制列车运行速度,向司机显示驾驶信息,并存储内部维修数据.设备在实际运用和维护管理中,主要关注的故障类型包括:硬件故障、软件故障、DMI故障、通信故障、BTM故障、STM故障、测速测距模块故障、环境干扰等.其中,硬件故障包含EOP板、信号接口板、BUF板、CBCH板等故障,以及插孔接触不良、RBR、EB2R、BFB等故障;通信故障包含VC与DMI、BTM的通信故障,或者ATP与BTM的通信故障等.为了确保设备故障信息能够有效得到记录并用于响应处理,200H型列控车载设备在DRU单元的PCR模块上安装了PC卡,用于实时记录ATP控制设备的动作状态和故障信息,为此,在长期获取并积累PC卡导出数据的基础上,能够实现特定设备故障类型与ATP控制设备动作以及相关状态信息的关联,为建立数据驱动的故障模型提供了有利条件.
在CTCS2-200H型列控车载设备PC卡日志文件中,包含了特定字段表征的设备故障状态.以控制类故障信息字段faultInfo_1为例,该字段记录了系统或设备的故障信息,用8位16进制数表示,其所包含的常见故障类型如表1所示.
以表1中的故障类型为例,每一条日志数据中包含了可能出现的故障信息,与之相应的同帧数据中包含了大量的相关状态量字段,展示了相应时刻列车运行状态以及ATP系统的动作状态信息.大量日志数据样本的存在,使我们以数据驱动为手段建立故障与状态特征量之间的关联模型成为可能,从而能够利用所建立的数据驱动模型辅助预判相应故障的发生概率,进而在演化早期即通过主动式的维护响应避免故障发生,优化维修维护的针对性和成效性.
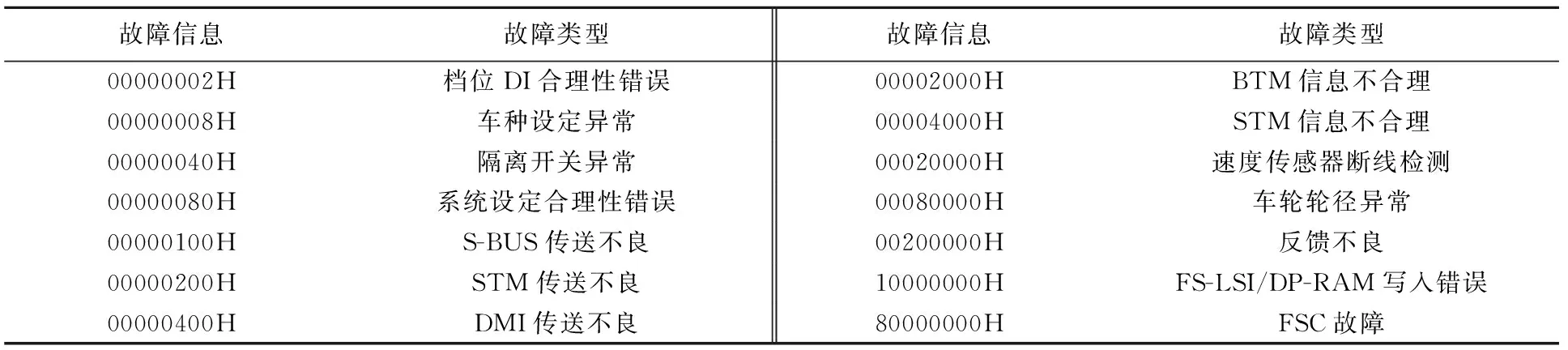
表1 CTCS2-200H型列控车载设备故障类故障中常见故障类型Tab.1 Common fault types under the control fault category for CTCS2-200H on-board train control equipment
2 XGBoost算法原理
XGBoost算法是一种基于Tree Boosting算法,实现高效、可拓展的机器学习系统.XGBoost算法引入一种新的Tree Learning算法来处理稀疏数据,使用一个理论上合理的加权分位数草图算法来处理实例权值,并构建了一个端到端的系统.相应算法与系统的优化,使XGBoost算法能以最少的集群资源拓展到更大的数据,并更快的构建模型[29].近来,XGBoost算法已广泛应用于销售预测、网站文本分类、产品分类、消费者行为预测等领域,并取得了良好的效果[30].
XGBoost算法是梯度提升决策树(Gradient Boosting Decision Tree,GBDT)算法的高效实现,其基本思想是通过不断迭代,将多个树模型进行组合,最终得到准确率更高的模型.通过若干分类与回归树(Classification And Regression Tree,CART)的集成,对每棵决策树预测真实值与之前所有决策树预测值之和的残差进行拟合,将所有决策树的预测值累加起来得到最终预测结果.相比一般梯度提升树模型,XGBoost在多个方面进行了优化,使模型训练速度和精度有很大的提升,主要优化途径为:XGBoost算法采用集成学习思想和向前分布算法,将多个基学习器进行组合,优化学习过程,提升最终训练效果;在损失函数中引入正则项,并对损失函数进行了二阶泰勒展开,同时使用一阶、二阶导数,大大降低过拟合风险[31].
XGBoost算法目标是建立一个具有最大泛化能力的多目标优化函数,一般模型的目标函数可以表示为[32]
(1)
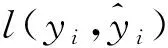
参考逻辑回归迭代的思想,将第t棵树加入模型时,可表示为
(2)

采用泰勒展开法逼近原目标函数,快速优化目标,具体推导过程见文献[29],即
(3)
式中:gi和hi分别为损失函数的一阶、二阶偏导数.
将每个叶子节点拆分为样本集,将Ω展开
(4)
式中:Ij={i|q(xi)=j},表示决策树的叶子节点j;wj表示叶子节点j的权重;λ和γ为加权因子.
如果选择固定的树结构,此时目标函数只与叶子权重wj相关,将目标函数对wj求导,并带入目标函数,可得到最优解为
(5)
XGBoost核心算法流程为
输入:特征子集ci(i=1,2,…,m),叶子节点最小权重,最大树深度等
输出:测试样本预测值
1. 初始化回归树f(x)
2. 选择由排序特征子集ci的第一个初始分割节点j组成的候选集Sk
3. while (树深度<最大树深度) do
4. for (k=1,2,…,T) do
5. 计算侯选集Sk中每个特征的gci和hci,得到最小增益,并选择该特征增益作为分裂点
6. 将除Sk外的特征按照排序依次添加到特征子集ci中,重复步骤5
7.j=j+1
8. 计算节点的样本权重:Hj=∑i∈Ihci
9. if (Hj< 叶子节点最小权重)
10. 停止节点分裂,防止过拟合
11. end if
12. end for
13. 继续生成树,最终得到k棵回归树
14. end while
15. 得到最终树结构,输出样本预测值
3 列控车载设备故障预测方法
3.1 故障预测总体框架
基于长期的现场数据积累,设计并构建了高速列车列控车载设备运行数据管理平台,平台采用三台服务器,通过时间校准、防火墙设置、SSH配置等操作实现了分布式架构,其中,一台服务器作为主节点,即NameNode,在平台内部提供元数据服务,控制所有的文件操作;另外两台服务器为子节点,即DataNode,供数据存储使用.在此基础上,建立了完整的高速列车列控车载设备故障预测体系框架,如图2所示.
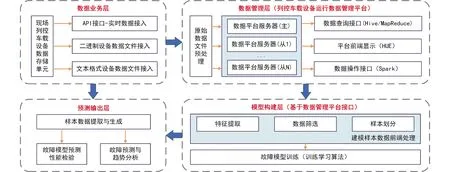
图2 列控车载设备故障预测总体框架Fig.2 Overall architecture of fault prediction for on-board train control equipment
高速列车列控车载设备故障预测体系框架总体可分为四个层次:
1)数据业务层.基于列控车载设备数据增量化采集机制,定期按不同设备型号收集现场日志数据文件,并结合数据格式规范对原始数据文件进行初步筛选.
2)数据管理层.构建基于Hadoop的高速列车列控车载设备运行数据管理平台,完成不同型号列控车载设备运行数据文件的分布式存储管理,平台可通过MapReduce/Spark框架实现新增日志数据的自动处理与管理查询,同时具备与建模、预测逻辑程序的接口.
3)模型构建层.调用平台中格式化存储的运行数据,采用特定学习训练逻辑实施基于特定规模样本数据集的故障模型迭代训练,在给定迭代截止条件下确定模型参数以及不同特征量的贡献度,并完成模型参数的输出与记录.
4)预测输出层.以测试数据集或者新增数据作为输入,调用特定故障预测模型对模型性能进行检验,并对相应故障模式的发生概率进行预测,结合故障趋势分析结果用于辅助开展现场响应与维护.
3.2 基于XGBoost的故障建模与预测
平台采集的原始数据经过批量处理,分布式储存于HDFS平台.选择平台中一段时间内的数据进行数据筛选、特征选取、特征标签化、数据集划分等操作,可构建XGBoost训练样本集与测试样本集,并建立相应的故障预测模型.由于CTCS2-200H型列控车载设备车载安全计算机由完全相同的两个系统构成,因此部分字段信息存在重复,只需选取其中一个系统输出的字段信息作为特征量.基于XGBoost算法的建模过程可划分为数据采集、建模样本数据处理、预测模型学习训练和预测模型评估4个环节,具体内容为:
1)现场数据采集.确定数据来源与原始数据格式.
2)建模样本数据处理.对原始数据进行数据清洗,去除多系之间的重复特征量,并将所选用的特征量统一按XGBoost算法训练所需格式进行数值化转换,进而用于生成模型训练数据集和测试数据集.
3)预测模型学习训练.设置模型训练参数,初始化训练模型,进行训练.
4)预测模型评估.选取模型评估参数,结合模型测试结果进行模型评估,优化模型训练参数或特征量选取.
针对CTCS2-200H型列控车载设备,基于XGBoost算法设计故障建模流程,共选取76个特征量,采用相应建模样本集建立特定故障类型的故障模型,并使用新收集数据实施设备的故障概率预测分析.基于XGBoost算法的CTCS2-200H型列控车载设备故障建模与预测流程如图3所示.

图3 基于XGBoost算法的故障建模与预测流程Fig.3 XGBoost-based fault modeling and prediction flow
4 测试结果与分析
4.1 数据样本构建
实验选取2018-01-2018-06的CTCS2-200H型列控车载设备数据构建数据集,原始数据规模约100G.原始数据已按照3.2节所述原则进行了相应的数据清洗操作,解决了原始数据文件中存在的行缺失、列缺失、字段缺失、特征量重复等问题,并统一进行了数值化转换,完成了在数据平台中的格式化存储.由于故障样本在全集中所占比例较低,为了提高模型训练性能及训练效率,对数据进行了筛选操作,选用702条故障数据用于样本集生成,其中包含了隔离开关异常、系统设定合理性错误、STM传送不良、DMI传送不良、BTM信息不合理、STM信息不合理、FS-LS/DP-RAM写入错误、FSC故障,共8种典型故障类型.选取500组故障记录构建训练样本集,剩余202组数据构建测试样本集,样本集中故障记录与无故障记录数据的比例设为1∶100.
在此基础上,考虑样本集覆盖时间范围和包含的故障类型数,进一步设计了两组样本集进行对比.
1)扩大数据样本集覆盖的时间范围,使用2018-01-2018-09现场数据,以相同方法建立另一组训练样本集,使用多条测试样本对两个样本集训练得到的模型进行测试,用于分析不同时间范围及规模的样本集对模型性能的影响.
2)由于预测目标包含多种故障类型,因此模型训练是一个多分类问题,选取发生频率最多的“STM信息不合理”故障进一步构建一个单故障类训练样本集,用于对比多分类模型与二分类模型的预测效果.
整体来看,所建立的各个样本集参数如表2所示.

表2 样本数据集参数Tab.2 Parameters of sample data sets
4.2 基于XGBoost算法的故障建模与分析
目前,XGBoost算法支持多种操作系统及语言,其中,由Python语言实现的Scikit-learn是一个包含大量经典机器学习模型的开源工具库,具有高效、无访问限制、BDS开源协议等优点,可调用封装好的XGBoost算法模块.实验选用此工具库搭建了XGBoost模型的训练与测试环境.
XGBoost算法建模涉及几十个参数,参数的设置将影响模型最终性能,参数调整是提升模型性能的重要手段.XGBoost算法参数可分为通用参数、Booster参数和学习目标参数三类.通用参数对宏观函数进行控制;Booster参数用于调整模型训练效果和计算代价;学习目标参数控制训练目标的表现.其中,Booster参数对算法性能与模型训练效果的影响最大,XGBoost算法涉及的主要参数如表3所示.经过调整,在固定其他参数不变的情况下,改变树的最大深度“max_depth”和迭代次数“n_estimators”两个参数,对比在不同树深度情况下,模型分类错误率随迭代次数的变化情况.分类错误率定义为分类错误样本数w占总样本数r的比例,表示为
(6)

表3 XGBoost算法主要参数Tab.3 Main parameters of XGBoost algorithm
分别设置树的最大深度为5、4、3、2、1,最大迭代次数为500,输出各模型分类错误率的变化情况,如图4所示.由训练结果可以看出,三组样本集所得趋势基本一致:样本集1训练过程中,树的最大深度为5时,经过216次迭代即可达到完全正确的分类能力,相较于最大深度为4、3、2的设置条件,所需迭代次数分别减少了2.26%、15.29%、39.33%,而当设置树的最大深度为1时,经过500次迭代仍未实现理想的训练效果;样本集2所得结果的情况与样本集1基本一致,树的最大深度为5条件下经过196次迭代即可实现完全正确分类,相对于树的最大深度为4、3、2的条件,迭代次数分别减少了1.01%、7.55%、36.98%,树的最大深度为1时,全部迭代结束后也无法达到最佳训练目标;样本集3条件下,可以看出对于二分类模型,不同的树深度设置均可达到完全正确分类的训练效果,树的最大深度为5时仅需136次迭代,相较于其他深度条件分别减少了5.56%、9.93%、20.47%、53.10%.总体来看,随着树深度的提高,分类错误率下降得越快,模型更快地达到最佳训练效果,减少了达到收敛需要的迭代次数.但是,树深度的提高也会增大模型的复杂度,导致可能的过拟合风险.
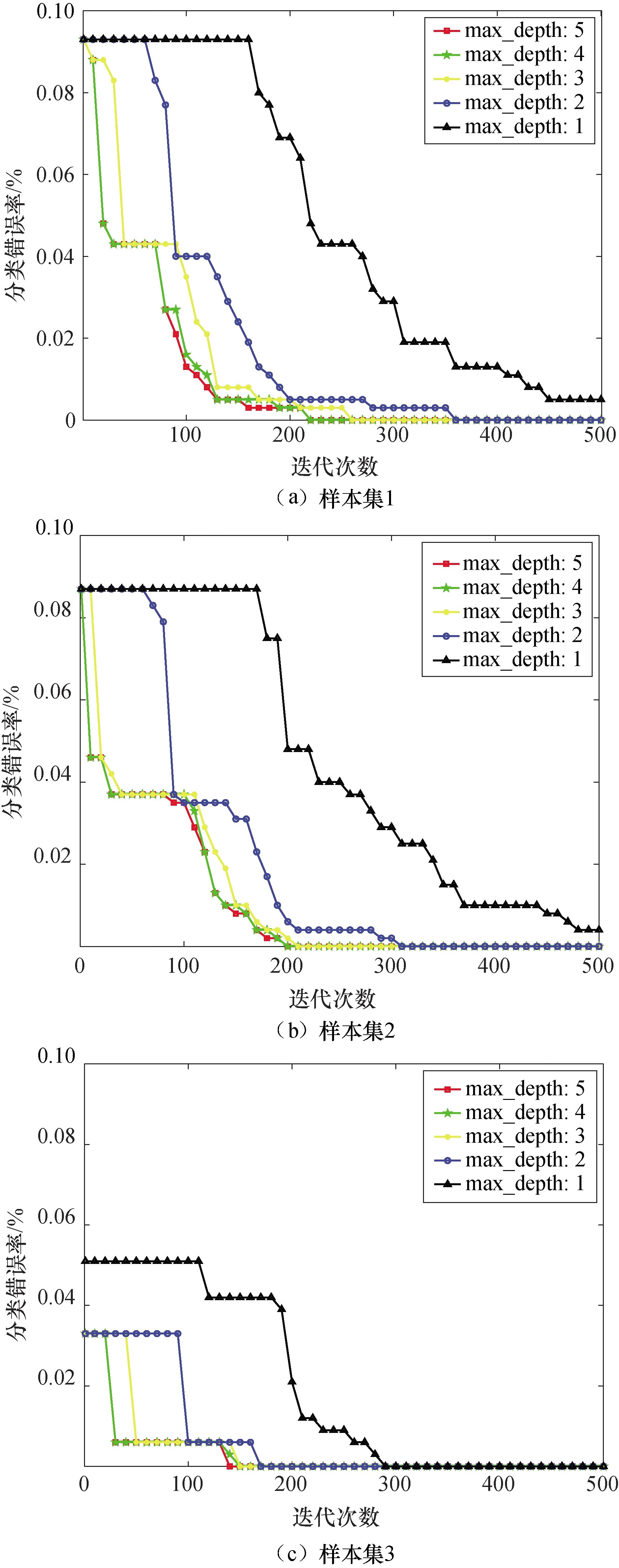
图4 不同树高度下分类错误率 随迭代次数的变化情况Fig.4 Variations of classification error rate with iteration number at different tree heights
XGBoost模型由多颗决策树组成,每次迭代都会产生一棵新树加入到模型中.随着子模型不断加入,集成模型的复杂度逐渐提高,当接近数据样本复杂度时,达到最佳训练效果.训练过程的部分子模型如图5所示.

图5 决策树子模型(树的最大深度:5)Fig.5 Decision tree submodel ( max_depth: 5)
使用XGBoost算法对故障进行建模,经过多次决策树子模型的迭代得到最终训练模型.利用XGBoost算法中的特征筛选工具,可以输出模型训练过程中各个特征的重要度分值,并进行排序.由此,可以筛选对目标标签分类和预测更有效的特征,并分析各个特征与目标之间可能存在的关联关系.三组数据集训练输出的特征重要度排序如图6所示.图6中数值表示特征在所有决策树模型中出现的次数.每个特征的对应含义及重要度得分可以在关系图谱中体现,如图7所示.

图6 三组样本集建模所得特征重要度排序Fig.6 Feature importance ranking results by modeling with three data sets
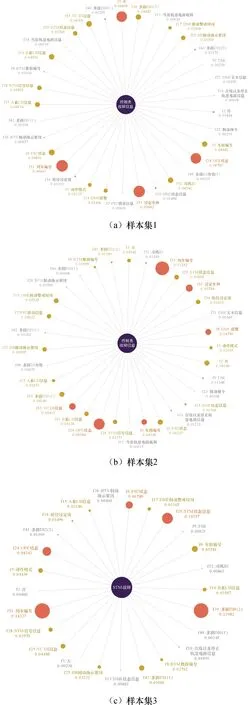
图7 三组样本集模型关系图谱Fig.7 Relationship graph of modeling results by modeling with three data sets
4.3 模型性能评估
对于训练得到的模型,使用搭建的测试集对其进行测试与评估,评估的具体参数包括:准确率、精确率和召回率,所涉及的混淆矩阵如图8所示,包含四个部分:TN表示实际为负样本,预测为负样本的样本数;FP表示实际为负样本,预测为正样本的样本数;FN表示实际为正样本,预测为负样本的样本数;TP表示实际为正样本,预测为正样本的样本数.

真实值预测值010TNTP1FNTP
根据混淆矩阵,各评估参数的意义为:
1)准确率A(Accuracy).预测正确的样本数占总样本数的比例,定义为
(7)
2)精确率P(Precision).预测正确的正样本数占全部预测为正样本总量的比例,定义为
(8)
3)召回率R(Recall).预测为正的样本数占实际正样本总数的比例,定义为
(9)
上述评价指标一般针对二分类模型,对于故障标签涉及多种故障类型的多分类模型,无法简单用上述参数进行评估,需要将多分类问题转换为多个二分类问题,再进行相关计算.在多分类问题中,准确率的计算过程与二分类问题中一致,而精确率和召回率需要先计算每个标签预测结果的精确率和召回率,再取不加权平均值.采用构建的样本集对各个模型测试结果如表4所示.

表4 模型性能评估结果Tab.4 Model performance evaluation results
基于模型性能评估结果可知,对于CTCS-200H型列控车载设备的常见故障类型,基于XGBoost的多分类故障预测模型具有很好的预测性能,准确率达到了98.61%.并且,随着建模样本数据覆盖的时间跨度的增大,模型的预测性能得到了提升.而二分类模型相比于多分类模型,在相同时间跨度下,故障预测准确率提高了1.31%,并且精确率和召回率有了显著提高.因此,针对特定故障类型分别建立故障模型实施预测与决策支持,同时兼顾运算效率与现场增量数据条件下的应用需求,将是运用本文所述方法开展实践应用需进一步考虑的问题.总体来看,以数据驱动思路为核心,建立有效的列控车载设备数据平台,实现运行数据的连续存储与管理,对故障数据进行更细致的预处理和分类,对提高模型性能、提升列控车载设备故障预测能力并支撑实际应用具有积极意义.
为了进一步对XGBoost算法用于故障模型构建及预测的性能进行检验,采用交叉验证方法,将梯度决策提升树(Gradient Boosting Decision Tree,GBDT)[33]、随机森林(Random Forest,RF)[34]这两种代表性建模方法与XGBoost算法进行了对比.使用数据为二分类样本集,相关参数设置保持一致,图9给出了模型预测正确率和交叉验证耗时随迭代过程的变化情况,相应的统计结果如表5所示.
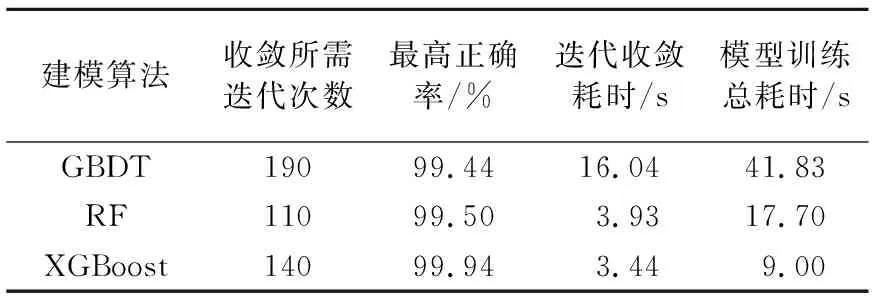
表5 三种算法性能对比结果Tab.5 Performance comparison results of three involved algorithms
通过三种方法的对比可知,随着迭代次数的增加,三种模型均能够达到99%以上的分类正确率,RF达到稳定的正确率水平所需迭代次数最少,相较于GBDT、XGBoost算法分别提升了42.11%、21.43%,但XGBoost算法相较于GBDT、RF算法能够实现更高的正确率.从训练时间的对比中,能够明显看出XGBoost算法耗时有显著降低,相较于GBDT、RF算法,达到各自最高正确率水平所需训练时间分别降低了78.55%、12.47%,对比测试的总训练耗时降低了78.48%、49.15%.综合分析XGBoost算法在模型正确率及训练效率方面的性能,可以明确其在大规模数据环境下进行模型训练更具整体优势,能够充分发挥故障建模与预测框架中数据驱动思想的核心作用,支撑相应维护决策的实施.
5 结论
1)目标标签维度对应的故障类型数量对模型预测性能有直接影响,二分类模型性能优于多分类模型,基于高速列车列控车载设备运行数据管理平台实现故障数据的处理和分类,针对特定故障类型进行模型建立,有助于提升列控车载设备故障预测能力.
2)建模样本覆盖时间范围对所得模型的覆盖度及预测性能有直接影响,运用所构建的列控车载设备运行数据管理平台积累现场数据对模型进行样本增量化更新,将使所得模型具备更优的实际应用能力.
3)XGBoost相较于GBDT、RF算法,在模型正确率和训练效率方面具有明确优势,在大数据环境下能充分发挥列控车载设备故障建模与预测能力,为实施相应维护决策提供支持.
4)后续研究中,将进一步探索增量数据条件下故障预测模型的高效动态更新方法,在此基础上,基于所得模型对特定故障的概率水平演化趋势进行建模与跟踪,将故障预测结果与设备运行可靠性评估进行关联,是下一步将故障模型的作用延伸至维修维护决策域的关键方向.
猜你喜欢
黄河之声(2022年10期)2022-09-27
汽车实用技术(2022年10期)2022-06-09
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
汽车维修技师(2019年7期)2020-01-16
汽车维修与保养(2019年3期)2019-06-19
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
现代兵器(2017年4期)2017-06-02
