
改进YOLOv3的道路场景目标检测方法
2021-09-24 03:49豆世豪
电脑知识与技术 2021年23期
关键词:目标检测
豆世豪
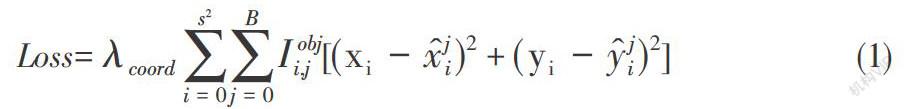
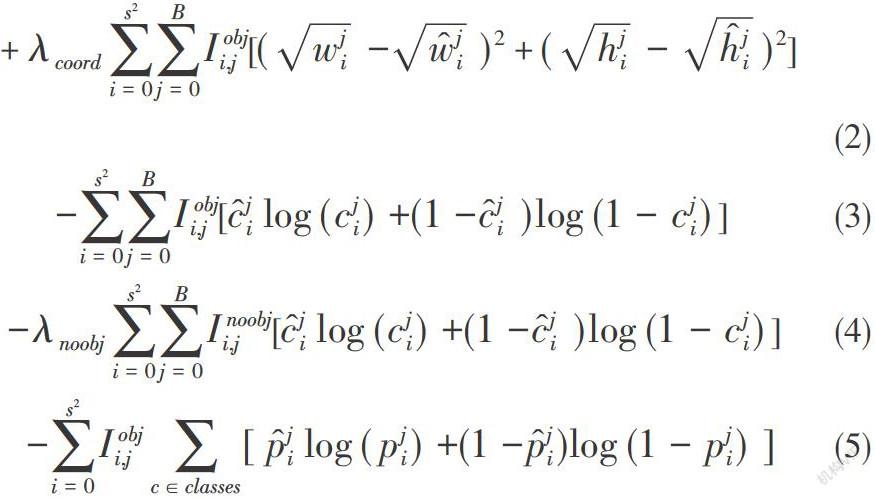
摘要:目标检测作为计算机视觉领域研究的重点之一,被广泛应用于自动驾驶、视频监控、医疗等领域。为了解决传统目标检测在实际应用过程中检测速度过慢以及检测精度不高等问题,本文提出一种改进的YOLO v3算法。首先,对于先验框位置使用K-means++算法进行提取,加快收敛速度;在YOLO v3特征提取部分引入SPP模块,实现局部特征和全局特征的融合,丰富特征图的最终表达能力;实验结果表明,改进后的YOLO v3方法在平均速度和平均精度方面分别提升了1.07%和2.02%,能够提升目标检测的实际效果。
关键词:目标检测;YOLO v3;K-means++;空间金字塔池化
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2021)23-0094-03
1 引言
随着深度学习的不断发展,目标检测建立在卷积神经网络的基础上,取得了显著成效。在2012年的ImageNet大赛上AlexNet网络被提出之后,越来越多更深的神经网络不断出现,开启了计算机视觉技术的革命。至今,基于CNN的目标检测方法主要分为两类:分别是基于区域提取的方法和基于回归的方法[1]。第一种是两步检测网络,该类算法将目标检测分为两步,精确度较高但是检测速度较慢,不能满足实时性要求,代表方法有R-CNN、Fast R-CNN、Faster R-CNN等。第二种是单步检测网络,对目标的位置以及类别预测只需一步,主要包括SSD、YOLO等[2]方法。该类算法的检测速度有很大提升,但检测精度有所下降。之后的YOLO系列算法不断改进,在保证检测速度的同时兼顾准确率,保证整体的使用效果[3]。本文以YOLO v3为基础,利用K-means++算法计算出适用于目标的锚框,然后借鉴SPP-net网络的思想,将SPP模块应用到YOLO v3网络中,能够结合卷积特征融合机制对多层级卷积特征进行融合丰富了卷积特征的表达能力,最终提高目标的检测效果。
2 YOLO v3网络
2.1 特征提取网络Darknet-53
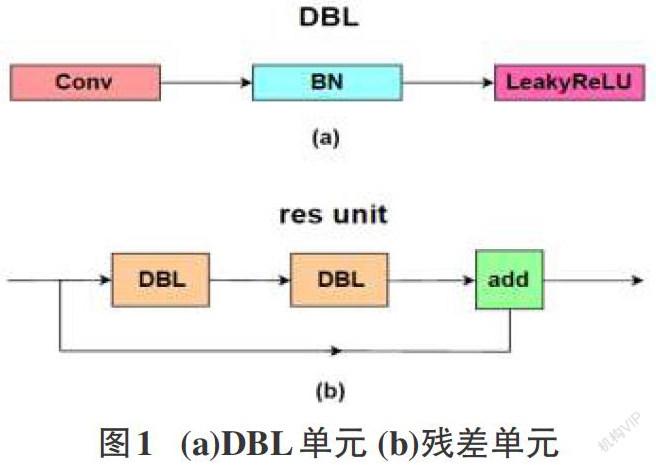
从YOLO v1到YOLO v3,每一代性能的提升都与骨干网络backbone有关。YOLO v3是在YOLO v2的基础上进行改进,骨干网络由原来的DarkNet-19变为DarkNet-53,然后利用特征金字塔网络结构实现了多尺度检测,提高对不同大小目标的检测精度。分类方法使用logistic代替了softmax,解决了不能对多标签目标预测的问题。DarkNet-53[4]由若干网络1×1和3×3的卷积核组成,每个卷积层之后加入一个批量归一化层和一个Leaky Relu激活函数,共同构成一个的基本卷积单元DBL,如图1(a)所示。此外,Dark Net-53融合了残差网络(Res Net),YOLO v3网络中共有5个残差块,每个残差块由若干残差单元构成,其中每个残差单元由两个DBL和残差操作组成,如图1(b)所示。
与YOLOv2相比,YOLOv3有多处改变。首先,DarkNet-53取消最大池化层,使用步长为2的卷积进行下采样缩小特征图的尺寸,可以减少目标信息的丢失,有利于小目标的检测。其次,通常网络结构越深表达特征越好,但容易出现不收敛的情况,残差结构的使用使得网络结构在很深的情况下依然保持收敛,保证模型持续训练获得更好的检测效果。最后,通过将网络的中间层和后面某一层的上采样进行张亮拼接,实现多尺度特征融合[5]。
2.2 损失函数
YOLOv3网络损失函数由三部分组成,分别为定位损失、置信度损失和分类损失[6]。损失函数公式如下:
3 改进的YOLO v3网络
3.1 Anchor Box聚类算法改进
网络模型通过学习训练不断调整Anchor Box的大小,而合适的初始化边界框尺寸的选择能够提升网络训练的速度。YOLOv3和YOLOv2一樣,使用K-means算法选取先验框尺寸,该方法存在一定的不足。初始点位的选择会影响收敛的快慢,而K-means算法需要事先指定点的个数且位置随机,最终导致局部最优而非全局最优。因此,使用K-means++算法对初始点位的选取进行改进,尽可能使聚类点之间保持最大距离[7]。该算法的实现过程如下:第一步,随机选择一个点作为第一个聚类中心。第二步,计算出剩余的每一个样本与最近的聚类点的最短距离,接着计算出每个样本成为下一个聚类中心的概率并选出下一个聚类中心。第三步,重复步骤二直至选出k个聚类点。使用K-means++算法能够降低收敛需要的迭代次数,加快了收敛的速度。
3.2 加强网络的特征提取功能
大多数网络结构中,最后一层是全连接层,该层要求的特征数是固定的,这就要求输入的图片尺寸大小也是固定的。需要对不同尺寸的图片进行裁剪、缩放、拉伸等操作使图片满足输入的要求,这会使图片失真,进而影响检测精度。最初为了解决图像失真问题,提出SPP模块。在YOLOv3网络结构中引入SPP模块,可以对不同尺寸的输入图片实现相同大小的输出,因此能够避免这一问题。SPP模块共由四个并行的分支组成,分别是卷积核大小为5×5、9×9、13×13,步长为1的最大池化下采样和一个输入到输出的跳跃连接,其模块结构如下图2所示。最后将四个分支特征图连接起来传到下一层网络中,依次通过1×1和3×3的卷积核再次进行融合,从而实现了不同尺度的特征融合[8]。
借鉴空间金字塔的思想,通过SPP模块实现了局部特征和全局特征特征图级别的融合,因此空间金字塔池化结构中最大的池化核大小要尽可能地接近或者等于需要池化的特征图的大小。加入SPP模块之后,丰富了卷积特征的表达能力,有利于检测图片中存在大小差异较大的目标,尤其是对于YOLOv3一般针对的复杂多目标图像,能够提高平均精度值(mAP)。改进后的YOLOv3网络结构如下图3所示。
猜你喜欢
科技创新与应用(2016年36期)2017-02-21
软件(2016年4期)2017-01-20
科教导刊·电子版(2016年28期)2017-01-10
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年4期)2016-02-22
哈尔滨理工大学学报(2015年5期)2016-01-19
湖南大学学报·自然科学版(2015年10期)2015-11-30
现代电子技术(2015年20期)2015-10-26
现代电子技术(2015年14期)2015-07-22
