
大数据技术在智慧工程中的研究和应用
2021-09-24 12:02马花月张诗媛周星妤
水利规划与设计 2021年10期
关键词:算法
马花月,卫 慧,张诗媛,周星妤
(上海勘测设计研究院有限公司,上海 200434)
1 研究背景
随着工业4.0浪潮的兴起,新一轮科技革命和产业变革正重塑全球经济结构,大数据的发展应用引起了国家和社会的重视。2015年国务院发布的《促进大数据发展行动纲要》指出,“推动产业创新发展,培育新兴业态,助力经济转型”是大数据发展的主要任务之一。当前,物联网、云计算、大数据、人工智能、区块链等信息技术不断向工程领域融合渗透,为工程大数据应用的实施奠定了坚实的技术基础。
近年来,三峡上海院在三峡集团清洁能源和长江生态环保“两翼齐飞”战略指引下,践行生态优先、绿色发展、数字赋能等发展理念,参与了大量的水电、海上风电、生态环保建设项目,工程规划设计、施工建设和运营过程中产生了大量多类型数据。由于各类工程特点不同,面临海量数据难存储、数据通讯难畅快、信息难共享、信息安全隐患等问题,出现了数据条块化及孤岛现象,数据资产管理能力薄弱等问题日益突出。
针对上述突出问题,上海院开展了智慧工程大数据平台建设,通过建立纵向联动、横向协同、互联互通的大数据平台,满足日益迫切的各类工程数据全生命周期管理的需求。大数据平台作为工程数据资料库的信息载体,需具备海量数据统一采集、清洗汇聚、分析计算、存储和共享服务能力。平台建设的同时,还需建立有序共享、适度开放、安全可靠的数据共享新机制,探索出一套由“资源”到“资产”再到“资本”的数据管理渐进增值新模式。
2 智慧工程大数据平台搭建
2.1 技术架构
智慧工程大数据平台技术架构如图1所示。根据数据从来源到应用,实现数据传输的流程,可将大数据技术架构分为采集清洗层、数据存储层、数据分析层、数据服务层、平台管理层。
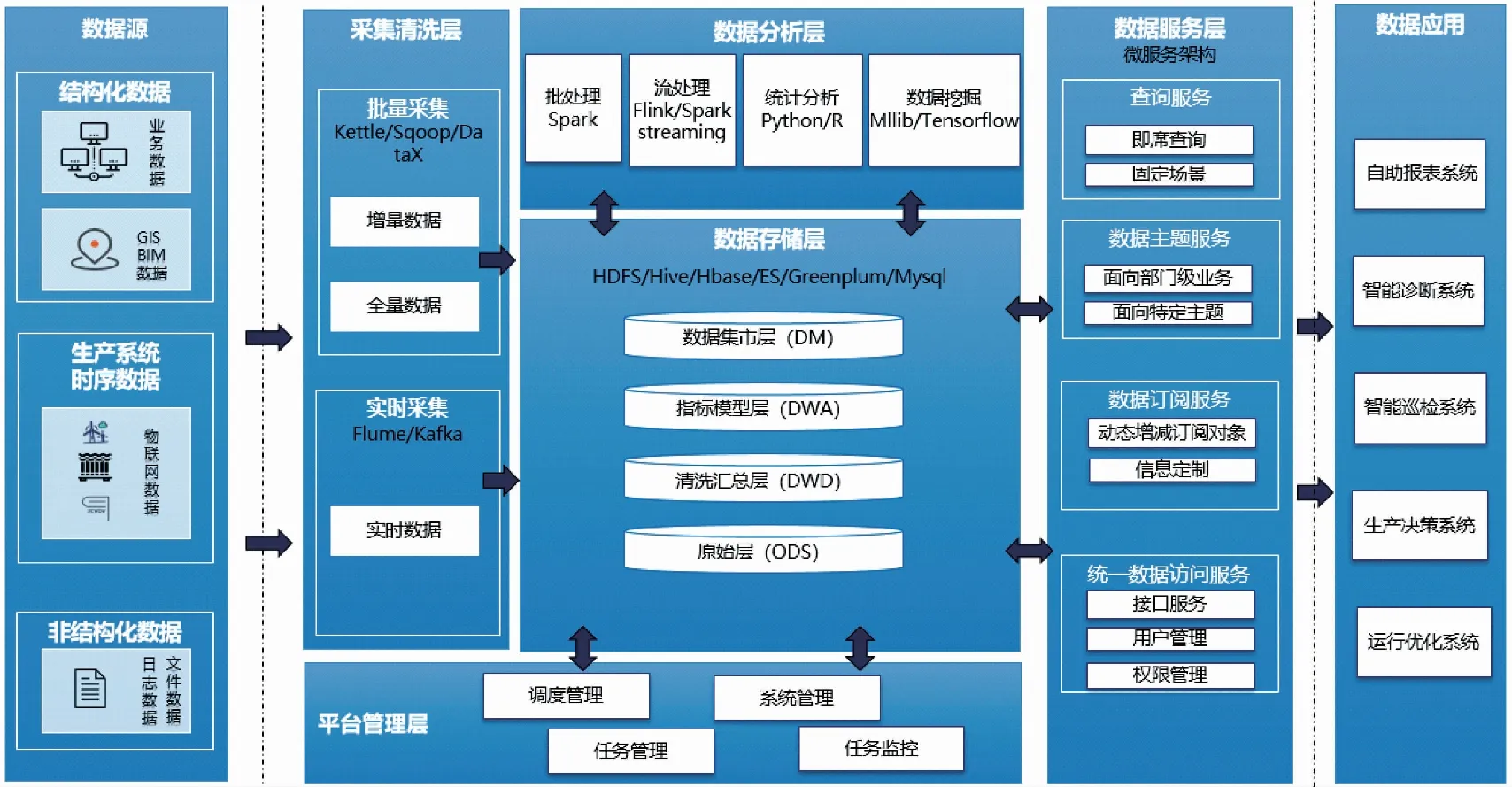
图1 大数据技术架构图
2.1.1采集清洗层
采用批量和实时采集技术,实现物联网平台的时序数据、业务系统结构化数据、日志文件等非结构化数据的标准化统一采集和清洗。
2.1.2数据存储层
运用HDFS、HBase、Hive、Greenplum等技术,构建统一的数据湖平台,实现数据的统一存储和管理,为跨库的数据关联分析提供基础。
2.1.3数据分析层
基于大数据计算引擎MapReduce、Spark、Flink,采用开源的统计算法、机器学习算法、深度学习算法,构建开放灵活可扩展的数据分析环境。
2.1.4数据服务层
采用微服务架构,搭建适用于各类用户的数据共享服务,如查询服务、数据主题服务、数据订阅服务、统一数据访问服务。
2.1.5平台管理层
采用Yarn作为资源管理调度器,为集群的各类计算框架提供统一的管理和调度,采用Zookeeper解决分布环境下的数据管理问题,采用OOzie工作流调度系统用来管理任务和工作流调度,采用Cloudera Manager监控集群的运行状态。如图1所示。
2.2 关键技术
2.2.1多源异构数据采集
数据采集主要实现内外部系统的结构化、半结构化、非结构化等不同类型、不同时效的数据的复制与整合。例如将视频监控、日志文本等对象数据,接入到对象存储数据库中;将物联网平台采集的时序数据,如光伏组件监测数据、风力发电机组监测数据、升压站监测数据等,接入到时序数据库中;将业务系统传输过来的业务数据,如计划、调度、运营等结构化数据,接入到关系存储数据库中。
大数据平台集成MapReduce、Spark、Flink并行计算框架以提供高效灵活的接入,数据采集技术总体设计特点包括:①支持高吞吐量数据的高并发接入;②数据不丢失不重复接入,保证数据高可靠性;③接入数据的事务性,同一批数据要么都接入,要么都未接入;④支持复杂网络环境下的可靠数据采集;⑤支持跨网段、跨单位的数据采集;⑥支持基于通道、文件的加密传输;⑦支持多种数据接口和传输协议;⑧支持断点续传。
2.2.2数据集成处理
数据集成实现数据的转换、逻辑判断、数据质量的检查、异常处理、数据路由、数据的规范化等处理。数据集成包括数据清洗、数据校验、数据转换、数据标准化。
数据清洗目的在于删除重复信息、纠正存在的错误,保证数据的有效性。数据校验基于数据接入标准,比如数据类型、数值特征等,对数据进行校验,保证数据的准确性。数据转换一般包括两类,第一类:数据名称及格式的统一;第二类:数据仓库中存在源数据库中可能不存在的数据,因此需要进行字段的组合、分割或计算,数据转换解决数据不一致问题。数据标准化就是对数据的命名、数据类型、长度、业务含义、计算口径、归属部门等,定义一套统一的规范,保证数据定义、理解、使用的统一。
2.2.3数据仓库设计
数据仓库是发展数据化管理的重要基础,具备高效的分层数据组织形式,更加完整的数据体系,清晰的数据分类和分层机制。数据仓库在逻辑上可以分为ODS层(源系统层)、DWD层(数据明细层)、DWS层(数据汇总层)、DM层(数据集市层),如图2所示。
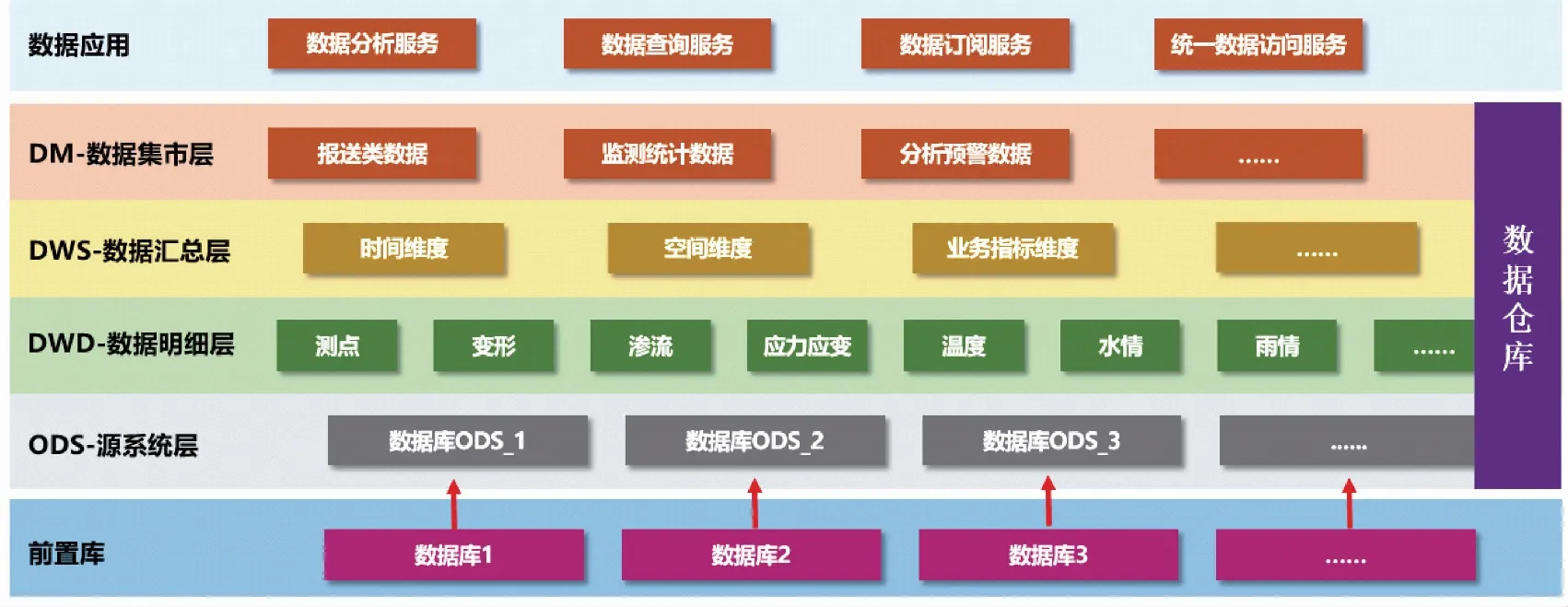
图2 数据仓库分层示意图
ODS层是业务数据流动过程的第一个存储区,为后续的数据抽取、清洗、转换过程打下坚实的基础。DWD层有选择地集成ODS层缓冲区的数据,以数据主题域为数据集成的基础,对数据进行分类和组织。DWS层通过概念模型、逻辑模型和物理模型3个阶段设计阶段,整理得到大量的指标数据,以便业务人员实现数据挖掘和业务分析等功能。DM层将数据汇总成分析某一主题域的服务数据,一般是宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
2.2.4数据分析
数据分析指数据分析或运维技术人员利用自身经验知识,使用大数据平台的案例数据和运行数据,针对要分析的业务对象进行业务理解,理解业务目标、业务目标产生的机理逻辑、筛选与业务目标有关的数据,利用平台提供的数据挖掘算法进行建模分析,推动业务的智慧化运营。
常用的数据挖掘具如:Mahout、MLlib、TensorFlow。Mahout 是Apache Software Foundation(ASF)开发的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。MLlib(machine learning library)是Spark提供的可扩展的机器学习库,MLlib中已经包含了一些通用的学习算法和工具,如:分类、回归、聚类、协同过滤、降维以及底层的优化原语等算法和工具。TensorFlow是人工智能AI领域的一个重要软件工具,是谷歌开发的开源软件,包含了DNN、CNN、RNN等深度学习模型,可以在创建深度学习网络时对数据进行数值和图形计算,快速建立数学模型。
2.2.5数据服务
数据服务主要解决以下4个关键问题:①不知道数据被哪些应用访问;②数据接入方式多种多样,数据接入效率低;③数据和接口没有办法复用;④底层数据变更引起表重构,增加额外的开发工作量,造成数据变更进度缓慢。
为解决以上问题,数据服务设计应具备6大功能:①规范化定义接口;②作为网关服务,数据服务必须具备认证、权限、限流、监控5大功能;③维护数据模型到数据应用的全链路关系;④利用中间存储加速数据查询;⑤构建逻辑模型,实现数据的复用;⑥建立API集市,实现接口复用。
3 大数据技术在智慧工程中的应用
大数据技术在智慧工程中的应用如图3所示。随着物联网、数据挖掘、人工智能等先进的科学技术日益成熟与广泛应用,工程建设逐渐由机械化、数字化模式向智能化模式发展。以工程应用为导向,通过数据统计、数据挖掘等大数据分析手段,构建典型的应用场景,充分发挥数据资产在工程建设应用中的价值。
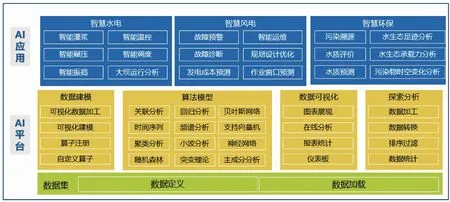
图3 大数据技术在智慧工程中的应用
3.1 智慧水电
大坝建设攸关经济发展与国计民生,是水利水电工程建设中最为重要的部分[1]。大量工程实践表明,大坝建设和运行数据中蕴藏了丰富的反映坝体结构形态及水库运行规律的信息。对大坝建设和运行数据进行处理分析,利用分析结果进行生产管理和辅助决策,有助于快捷科学地管理大坝安全系统中的各个环节,提高大坝工程质量并规避安全风险,为大坝的建设和运行管理提供有价值的科学依据[2]。
目前针对大坝运行数据分析的算法包括回归模型、频谱分析、ANN、小波分析、神经网络、突变理论、灰色系统、Kalman滤波法等,可根据数据量、数据类型、算法优缺点、分析目的选择合适的算法,例如大坝渗流及变形分析可采用回归分析法及神经网络法。由于大坝观测值与影响因素之间往往存在非线性、非确定性的复杂关系,可能会导致回归模型的计算结果与实际情况相差较大。而人工神经网络法将生物特征应用到工程计算分析中,可以解决大数据量情况下的学习、识别、控制和预报问题[3]。
目前针对工程建造数据分析的算法较多,以大坝灌浆为例,灌浆工程涉及到的数据分析应用可分为单位注入量预测及灌后质量综合评估两个方面。岩体单位注入量是对岩体可灌性最直接的反映,有助于定量分析岩层吸浆情况,实时调整灌浆压力、灌浆材料及优化灌浆孔位布置,为岩体的可灌性研究和地质条件分析提供参数指标[4]。此外,灌浆施工过程中会受到地质条件、施工方法、灌浆压力等多种条件的影响,可能导致灌浆效果无法满足设计方案的要求,因此需要采用科学有效的方法评价灌浆施工的效果[5]。目前常用的灌浆注入量预测方法包括随机森林法、神经网络法、回归模型法等,常用的灌浆质量评估方法包括云模型、模糊综合评价法等。
大数据在智能建造中应用范围广泛,除了智能灌浆,还可运用于智能碾压、智能振捣、智能温控等多个领域。
例如采用粗糙集和神经网络数据挖掘算法,建立混凝土施工期最高温度与浇筑施工信息间的关联规则;采用K邻近、支持向量机、长短期记忆网络等算法分析浇筑机械(缆机)的运行规律以及在时空方面的运行冲突情况,并针对不同的冲突情况制定相应的调整机制,优化机械调度方案;基于数据驱动模型评价混凝土振捣及压实质量,如人工神经网络、支持向量回归、随机森林等模型;基于路径智能规划技术的运输车辆智能调度方法,实现路况信息的智能分析与更新、运输路径的智能规划与车辆智能调度[6]。
3.2 智慧风电
风能作为可再生能源,近年来发展迅猛,装机容量迅速上升。但是由于风电场所处位置的气候变化、日照变化、地形因素等原因,发电功率和风速具有不确定性,可能会对发电平衡的保持产生不利影响。对风力发电进行预测,不仅可以指导电力公司应对由于发电不稳定造成的影响,为风电机组的运维和管理提供依据,还有利于降低运营成本,保障风电的稳定输出。
风力发电的预测分为单台风电、风电场和区域风电场群的发电预测。在单台风电机预测中,滑动平均、多元回归等方法适用于发电较短期平稳的发电预测[7],指数平滑、主成分分析、NWP等方法适用于长期平稳预测[8]。在风电场发电预测中,上下界估计网络、成组数据推断网络、贝叶斯推断、神经网络等方法适用于短期平稳发电的场合[9],自适应小波网络、前馈网络适合长期稳定的预测[10],小波支持向量机适用于非稳定的情况[11]。NWP、神经网络、测量关联预测等适用于风电场群的发电预测[12]。大量研究的计算结果表明,利用大数据算法分析的发电预测与其他常用的预测方法(如:常值法)相比,误差可以减少2.5%~50%,说明大数据算法的使用有助于提高风力发电预测的准确性。
除发电预测之外,大数据技术还广泛应用于风力发电运营阶段的各项业务应用,如利用设备历史监测数据和历史故障数据来分析故障发生前的隐患因素,并在故障发生时进行故障的智能诊断,甚至故障预警;在设备运行期间,利用历史的设备生产、维修检修数据,结合实时的物联网监测数据,分析判断设备老化趋势和剩余寿命预估,以此优化设备更新换代的机制,减少运营成本。
3.3 智慧环保
大数据技术在生态环境方面的应用主要体现在实时监测、动态分析、预测预警、调度管理等方面。在实时监测方面,大数据技术增强了监测数据的有效性和精确性,提升了监测数据的分析与评价效率;在动态分析方面,大数据技术通过数据挖掘等分析算法研究了生态环境的影响因素,为各类环境管理提供决策支持;在预测预警方面,大数据技术提高了生态环境模拟的精度和处理速度,并实现了不同时空尺度的污染预报预警;在调度管理方面,大数据技术通过整合生态环境监管机构系统,构建互联网舆情动态感知数据库,实现应急事件的快速响应和处置,为调度方案的制定提供数据支撑。
目前常用的水环境数据分析方法包括时间序列分析、决策树法、聚类分析、支持向量机、神经网络法等。常用的水质评价方法包括灰色聚类、人工神经网络、综合污染指数、模糊综合评价、主成分分析等。例如董建华[13]等针对三峡库区监测系统构建了Hadoop Spark混合计算框架,采用基于三元色的可视离散化算法、基于PCA的水质评价方法等,为多指标水质时间序列数据评价提供了算法支持。周晓磊[14]等提出一种基于大数据的水生态承载力模型,利用生态足迹法计算水生态足迹和水生态承载力,实现海量水文数据的存储及有效计算。
除了传统的数据分析算法外,现有的生态环境管理系统常采用大数据技术与专业模型相结合的方法,以提升模型模拟的有效性和精度。例如通过大数据平台提取取水、用水、排水、供水等实时监测数据,对河道监测断面进行数据动态跟踪,并采用线性趋势、累积异常、迁移扩散模拟等物理模型对数据进行分析,研究河道污染物的时空变化,追溯污染源,从而有效促进水资源监督管理和污染源头控制。
4 结语
随着工程建设与管理思路的不断创新,加上新技术与新模式的不断实践,应用大数据驱动工程管理实现智能化、智慧化已逐步成为新的共识。通过对数据的规范管理,打通数据堵点,消灭数据壁垒,加快形成跨部门、跨专业、跨领域一体化数据资源体系,推进数据汇集融合共享。同时开展数字创新,提供数据服务及数字产品,构建智慧工程大数据生态圈,培育新动能,助推新业态,以数字化助力工程管理提升,引领业务创新和价值创造。
猜你喜欢
小学生学习指导(低年级)(2021年12期)2021-12-31
成都信息工程大学学报(2021年3期)2021-11-22
成都信息工程大学学报(2021年1期)2021-07-22
成都信息工程大学学报(2021年1期)2021-07-22
小学生学习指导(高年级)(2020年12期)2021-01-07
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
小学生学习指导(低年级)(2018年11期)2018-12-03
雷达学报(2018年3期)2018-07-18
