
高校数字化校园大数据平台设计研究
2021-09-23 15:27梁烜彰
企业科技与发展 2021年8期
梁烜彰
【关键词】数字化校园;大数据平台;Hadoop
【中图分类号】TP311 【文献标识码】A 【文章编号】1674-0688(2021)08-048-03
0 引言
随着互联网科学技术的高速发展,如今世界已进入全面信息化的时代。数据信息遍及我们生活中的每个角落,已然成为现代生活中一项重要的资源,各大顶尖公司都在竞相争夺数据资源,建立大数据平台对收集到的数据进行处理分析,从而获取有价值的信息,以便在竞争中处于有利的地位。
目前,大部分高校都已经建设多种信息化系统进行管理,例如教务管理系统、财务管理系统、一卡通管理系统、图书管理系统、就业管理系统、食堂管理系统等,这些系统虽然能完成各自部分的功能管理,但是这些系统都是在独立运作,它们之间存在信息孤立,没有实现数据互通。高校系统管理着成千上万的师生,每年汇集了海量的数据,这些数据结构多样复杂,如果不能有效地利用就会造成资源的浪费。在大数据时代背景下,如何高效地利用这些海量数据进行处理分析是未来高校信息化管理的一个挑战。因此,依托高校信息管理系统建设一个大数据平台具有重要的意义。本文提出一种基于Hadoop大数据技术的数据处理方案,对高校系统中产生的海量数据进行有效整合及处理,实现高校各管理系统功能一體化,提供高校师生的数据分析,从而提升信息化管理质量。
1 Hadoop大数据技术
作为一个开源分布式的系统架构,Hadoop是专门研发用于大数据处理的工具,能有效地解决并行计算和分布式存储。Hadoop的自由可扩展性、开源性和廉价低成本,使之成为目前应用最广泛的大数据处理平台,备受研发人员的青睐。整个ApacheHadoop平台包括Mapreduce、HFDS、Hadoop内核及一些相关工具,其中又包括Hive和HBase等 [1]。
Hadoop能够让开发者轻松地搭建分布式计算平台并应用于开发数据处理相关的工具。作为分布式集群的框架,Hadoop可以方便地扩展到无数的节点中,分配相关数据计算等任务到空闲的计算机节点。与其他大数据框架相比,Hadoop的BitMap技术和优良的数据处理能力,能够实现数据节点间的动态交互通信,这使得Hadoop在数据处理方面拥有极高的效率。Hadoop的副本策略在集群中会默认存储多个数据副本,当出现任务失败时能将任务自动重新分配,具有很高的容错性。同时,构建Hadoop平台只需要廉价的服务器便能实现,无须额外购买搭配昂贵的设备。由于Hadoop的开源特性,因此在基于Hadoop的开发项目上能降低许多软件的开发成本,使开发者们可以放心地依赖它应用研发项目。
1.1 Hadoop的整体框架
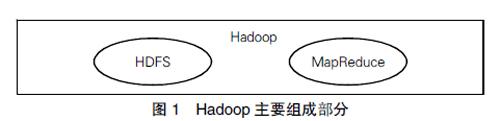
Hadoop的整体框架主要由两个部分组成构成(如图1所示),一是分布式文件系统HDFS,它在Hadoop中作为最基础的底层存储系统,是Hadoop的核心组件之一,其主要功能是为收集的数据提供分布式存储。二是分布式计算框架MapReduce,它构建于分布式文件系统之上,拥有大规模并行计算的能力,是Hadoop核心主键之一,其功能是对分布式文件系统上的数据进行并行计算处理。在Hadoop中,开发者可通过重写接口实现自定义分布式文件系统,并在分布式文件系统上通过MapReduce对存储的数据进行处理,因此开发者拥有极大的可扩展性开发。
1.2 HDFS分布式文件系统
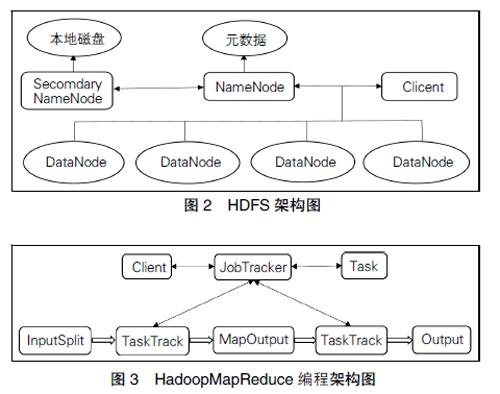
HDFS的架构如图2所示。HDFS主要负责维护Hadoop框架中的分布式文件系统,它由一个主节点(NameNode)和多从节点(DataNode)共同组成,也被称为Master/Slave主从结构 [2]。NameNode节点又被称作管理节点,作为整个集群的文件管理者维护HDFS的正常运行,并负责文件系统的命名空间和客户端对数据的访问 [3]。一个集群中存在一个NameNode作为主节点,还有一个SecondaryNameNode作为辅助节点在主节点旁边,它负责同步检查点与主节点之间的数据并备份主节点上的文件系统操作日志和元数据。一个集群中可以拥有多个DataNode节点,也被称为数据节点,是HDFS重要的组成部分,其功能是用于存放数据,DataNode节点与NameNode节点之间的交互通信是通过心跳机制进行的。HDSF的核心功能是管理每个数据节点,对某一组数据进行有效的加工以达到维护系统的目的,对于每一个文件的块的来源、状态数据信息和切割情况等都能够进行详细的记录 [4]。
1.3 MapReduce编程架构
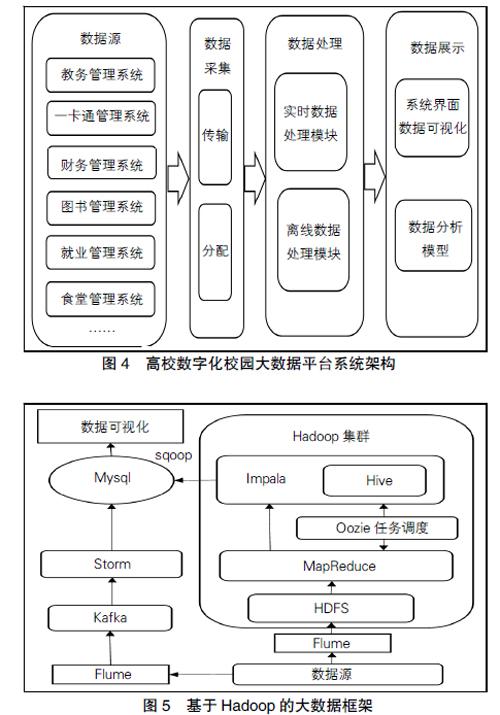
MapReduce是一种高性能面向大规模数据处理的并行计算框架,它的编程架构如图3所示。MapReduce在处理数据时的核心思想是Map(映射)和Reduce(归约),它在做并行数据处理计算任务时,首先分配任务到集群的各个不同节点上,在Map端会先将接收到的任务做分块处理,接着对切分成大批量的小任务单独处理,然后在Reduce端整合每个小任务的处理结果,最后经过不断计算处理之后输出最终的结果。MapReduce框架完善的机制可以自动解决任务调度、容错处理、负载均衡等问题,所以开发者不用担心在多节点计算中涉及的这些问题。
2 大数据平台架构设计
高校数字化校园大数据平台系统架构可以分成4个部分(如图4所示),第一部分是数字化校园内教务管理系统、财务管理系统、一卡通管理系统、图书管理系统、就业管理系统、食堂管理系统等产生的数据源。第二部分是数据采集,通过数据采集工具对数据化校园的数据源进行传输和分配。第三部分是数据处理,这个架构中对数据的处理可以分为两个离线数据处理和实时数据处理两个部分。第四部分是数据展示,实时数据处理模块输出结果通过网页客户端或者App端展示数据实时动态,离线数据处理模块输出数据分析模型,提供师生个体或者群体行为的数据分析和行为预测。
基于Hadoop的大数据框架如图5所示,在这个架构中,离线数据处理部分是由Hadoop集群完成的,实时数据处理部分是由Storm实时数据处理框架完成的。数字化校园数据源的采集通过Flume工具完成,Flume是由Cloudera提供的一种高可靠、高可用的分布式日志收集系统,它支持定制数据收集和传输的方式。同时,Flume可以对采集到的数据进行预处理,并将数据传输至指定地点,在采集数据时可以依据不同的数据处理方式对不同的数据源进行采集处理。
Hive是基于Hadoop的数据仓库分析工具,它可以根据SQL语句在MapReduce实现统计任务。Impala是应用于处理在Hadoop集群中存储的海量数据的MPP(大规模并行处理)SQL查询引擎,它实现了一个基于守护进程的分布式架构,降低了MapReduce方面的延迟,Impala处理任务的速度比Hive更快,可以通过Impala对海量数据处理实现一些复杂查询的需求,同时Impala的查询需要在Hive端导入完成。
Storm是一个类似Hadoop的分布式实时数据处理框架,能够很好地完成实时数据的处理并实现数据可视化。Kafka是一种高吞吐量的分布式消息处理平台,能够支持每秒数百万消息的吞吐量,完全满足系统对数据传输的要求。
Sqoop是用于Hadoop或者Hive与关系型数据库间数据传输的工具,可以将处理好的数据转移至数据库中。Mysql数据库作为最后数据处理结果的存储仓库,网页客户端或者App端可以从数据库中提取数据展示出来。
3 大数据平台功能实现
在服务器上搭建好Hadoop和Storm的环境,安装Kafka、Flume、Mysql等相关软件,并配置好软件相关的配置文件。每台机器上都有一个Flume agent运行,通过Avro的方式进行数据的传输,其中一个Flume agent由多个Sinks和Sources组成,而这两者连接是以Channel作为通道的。
基于Hadoop的大数据框架数据处理流程如图6所示,包括数据采集模块、离线数据处理模块、实时数据处理模块、数据存储分析模块、数据展示模块。
数据采集模块,利用分布式日志采集系统Flume從数字化校园系统采集离线数据和实时数据,Source从数字化校园系统采集数据后传输到Channel,Channel收集的数据通过Sink输出。
离线数据处理模块,采集的离线数据经过SinK输出上传到HDFS分布式文件系统上,在Hadoop集群中通过Map-Reduce计算框架对存储在HDFS分布式系统上的离线数据进行预处理,预处理之后的离线数据传输至Hive数据仓库中存储。
实时数据处理模块,采集的实时数据经过SinK输出上传到Kafka上,Storm实时计算框架从Kafa中提取出实时数据并进行预处理,预处理之后的数据传送到Mysql数据库中进行分类存储。
数据的预处理主要包括数据清洗、格式整理、滤除脏数据等过程。在Eclipse软件上,通过Java编程语言编写相关数据预处理程序,完成后打包放到Linux系统中运行。
数据存储分析模块,Hive数据仓库中可以提供实时查询功能,为更好地管理调度海量任务单元,可以在项目中增添一个Ooize任务调度模块,在Hive数据仓库中建立相应的模型表以满足离线数据处理的需求,同时利用Impala工具实现对Hive中的数据实现复杂查询的功能。
数据展示模块,通过Sqoop工具将Hive数据仓库中处理完的数据结构传送至Mysql数据库中,经过处理之后的离线数据和实时数据都会传送至Mysql数据库中进行分类存储。网页客户端或者App端访问Mysql数据库中提取数据通过界面展示出来,展示的实时数据可以提供师生查询个人或群体在数字化校园上最新的数据动态,展示的离线数据则为师生提供行为分析预警、学期考核评定、就业分析预测等信息。
4 结语
在当今全球大数据时代的背景下,数据已经成为不可或缺的宝贵资源,如果能利用好这些资源就能给我们带来巨大的好处。高校推进大数据技术的发展,从海量数据资源中挖掘出有价值信息,不仅能改善师生的学习和生活服务,提升部门间协同工作,实现数据资源有效整合和共享,也为高校未来的发展提供更合理的规划和定位。本文根据高校信息化管理现状,设计了基于Hadoop的大数据处理框架,研究了大数据平台在高校数字化校园的应用,对涉及相关的技术功能和实现流程做了介绍。希望通过大数据技术充分挖掘整合数据资源,为高校师生进一步提升信息化管理服务质量,为高校未来的发展变革提供方向。
参 考 文 献
[1]陈娜姗.基于Hadoop的用户行为分析方法的应用研究[D].南京:南京邮电大学,2016.
[2]Dean Jeffery,Ghemawat Sanjay.Map Redece:si-
mplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[3]Leiqing Shi,Fei Gao,Zhengping Jin.Novel design of the model of distributed namenode in HDFS[C].IEEE International Conference on Cloud Computing and Intelligence Systems,2012:310-330.
[4]李莉.基于云计算平台Hadoop的并行k-means聚类算法设计研究[J].网络安全技术与应用,2017(12):46-47.
猜你喜欢
物联网技术(2016年11期)2017-01-12
电子技术与软件工程(2016年20期)2016-12-21
时代金融(2016年27期)2016-11-25
数字技术与应用(2016年9期)2016-11-09
数字技术与应用(2016年9期)2016-11-09
电脑知识与技术(2016年21期)2016-10-18
中国教育信息化·基础教育(2016年9期)2016-10-18
