
从生成到还原
——结构语言学发现程序的重新评价
2021-09-18 13:51陈保亚鲁方昕
思想战线 2021年5期
陈保亚,鲁方昕
一、研究背景
母语习得是语言学研究的中心问题之一。通常而言,儿童在三四岁时已经可以比较熟练地掌握自己的母语,一方面,这种习得不需要父母或者家人特别的指导;另一方面,这种习得也不受儿童智力水平或者母语复杂程度的影响。那么,儿童如何习得自己的母语?对于这一问题,先前的研究主要有三种观点:行为主义者认为,语言是一种行为,语言的习得是语言使用者对外界刺激做出反应的结果,刺激越多则语言能力越强;先天论者认为,儿童在习得母语时所能接收的输入很少,在刺激贫乏的条件下,语言能力并不是通过大量有效输入,而是人脑的一种机能;认知论者认为,儿童的语言能力是认知能力的一部分,语言的习得使用了一般的认知策略,语言的发展是认知能力与语言环境相互作用的结果。
行为主义的习得理论存在一个明显的问题,语言习得并不是简单的模仿。一个观察事实是,儿童可以生成先前从未听过的句子。这种可以生成无限句子的能力,是语言的一个基本特征。因此,语言能力并不通过频繁的刺激与强化获得,不过,强化的过程确实会在语言习得的过程中起到重要的作用。生成学派的先天论也受到了很多批评,因为其理论的两大基石——普遍语法与刺激贫乏并不牢靠。(1)前人关于这方面的讨论比较多,可以参考Geoffrey Pullum and Barbara Scholz,“Empirical assessment of stimulus poverty arguments”,The linguistic review,vol.18,no.1~2,2002,pp.9~50;Alexander Clark and Shalom Lappin,Linguistic Nativism and the Poverty of the Stimulus,Hoboken:Wiley-Blackwell,2011;Paul Ibbotson and Michael Tomasello,“Evidence rebuts Chomsky’s theory of language learning”,Scientific American,no.315,2016,pp.70~75.然而,先天论重视语言规则在语言习得的作用,这是非常有意义的。因为语言的习得既不是纯粹的记忆工作,也不是语料的习得,而是一种规则的习得。认知主义的习得理论不认可规则是内置的,暗含了语言的规则是在话语中获得的,但是并没有给出规则提取的具体程序。那么,儿童如何习得规则?这或许需要四个步骤:第一步,接受一定数量的语料,比如“弹钢琴”“弹吉他”“学古筝”“学古琴”;第二步,了解组合的意义;第三步,通过对比的方法,提取出单位与规则;第四步,生成从未听过的结构,比如“学钢琴”或者“弹古筝”。因此,单位与规则的还原是语言习得中最重要的程序,也是语法描写的目标。
乔姆斯基认为,语法描写的最终目标在于使用有限的规则来生成所有可能的句子。(2)Noam Chomsky,Syntactic Structures,The Hague:Mouton,1957,p.13,p.85.但如何得到这些规则,生成语法并没有给出合理的方案。这里以处理传统语法中两种最为主要的形态现象(派生与屈折)为个案,来说明生成语法中规则与单位提取的不确定。乔姆斯基起初的方案是将派生产生的词(如destruction)与屈折产生的词(如destroying)都视作转换的结果,即只需将destroy一个形式收入词库。(3)Noam Chomsky,Aspects of the Theory of Syntax,Cambridge,MA:MIT Press,1965,pp.184~192.不过,屈折的规则与派生的规则是不平行的,前者的规则适用性非常之广,而后者的规则适用性相对较窄。到了20世纪70年代,乔姆斯基转向了词汇论假说(Lexicalist Hypothesis),(4)词汇论假说的主要观点是,形态与句法属于两套不同的规则,从构词到组成短语这个关系是单向的。Noam Chomsky,“Remarks on nominalization”,in R.Jacobs and P.Rosenbaum(eds.),Readings in English Transformational Grammar,Waltham,MA:Ginn,1970,pp.184~221.认为屈折变化产生的词(如refusing)是转换的结果,而派生变化产生的词(如refusal)并非转换的结果。因此,词库中既要收录refuse,也要收录refusal。这里可以看出,生成语法在确定语言单位上的摇摆,经典时期更倾向于使用语素/语形一层单位,而20世纪70年代以后更倾向于使用语素与词两层单位。
正是由于规则与单位的不确定,也导致了生成语法中常遇到生成能力过强或者生成能力过弱的问题。所谓生成能力过强,指没有很好地限制规则,产生了大量自然语言中不会出现的结构。以英语为例,-tion是英语中动词变名词的词缀,attract、imitate、act、promote、instruct、inform等许多动词都可以通过加-tion后缀的方式生成名词形式,但也有很多动词不能通过这种规则构成名词,如do、prefer、cry、ignore等。同样,与生成能力过强相对应的是生成能力过弱的问题,指部分可以通过规则生成的单位或结构被处理成了单位,使得单位的数量大幅增加。以汉语为例,汉语中表示序数的“第”不能单独使用,但“第一”“第二”“第一百”等序数词是规则生成的,如果将这些序数词都处理成单位,那么语言中的单位将会是无穷的。
生成语法对于单位问题的态度,一定程度上来源于其对结构主义研究的反思,结构主义在使用语素、词等单位描写语言时都遇到了切实的困难。乔姆斯基将结构主义提取单位的一套工作方法称为发现程序(discovery procedure),这套程序的核心思路在于,利用分布与替换得到语言中的单位与规则,但他认为,发现程序的最终目标难以实现,进而提出评价程序,(5)乔姆斯基提出了语法理论的三种程序,分别是发现程序、决定程序(decision procedure)、评价程序(evaluation procedure)。具体定义可参考Noam Chomsky,Syntactic Structures,The Hague:Mouton,1957,pp.50~52。利用假说模型来完成句子的生成。不过,无论从语言习得抑或田野调查的视角,这套确定单位的程序并非没有价值。本文试图从单位的提取以及使用该单位描写语言两个角度来评价结构主义的得失,并基于发现程序提出描写语言的优化方案。
二、发现程序:从词到话语
从博爱士开始,结构主义对语言的单位问题做了大量的探索。其中尤以布隆菲尔德以及海里斯的工作最为重要,下面我们也将沿着两人的研究轨迹,分别讨论词、语素作为句法单位的优缺点。
(一)词的提取
在布隆菲尔德看来,构成话语的单位是词。对于什么是词,布隆菲尔德给出了定义,即“最小的自由形式”。而什么是自由,布隆菲尔德认为是“能够充当话语”。(6)Leonard Bloomfield,“A set of postulates for the science of language”,Language,vol.2,no.3,1933,pp.155~156.换言之,如果一个成分是能够独立充当话语的最小成分,那这种成分便是词。按照这种思路,我们可以从话语中提取出语言系统中的大多数实词,比如“来”“去”“走”“天”“人”“牛”。单说的方法在判定一个语素是否为词的问题上具有较强的可操作性。但如果遇到两个语素的组合,这一方案在很多时候都不能确定组合中的一个语素是否是词。比如,“再来”“又来”这样的组合,母语者一般视作词组;而面对“将来”“本来”这样的组合,母语者一般视作词。“再来”“又来”类的组合关系比较规则,可以认为其中的“来”能单说,因此这里的“来”是词。但对于“将来”“本来”类,我们既无法断定其中的“来”是否与“又来”中的“来”平行,也无法说明它能否单说。因此,无法确定“将来”的地位。
提取词的另一方案是扩展法。布隆菲尔德讨论过以“能否隔开”来断定一个成分是否是词。他以blackbird为例,如果话语可以将两个语素black与bird分隔开,即在两者中间插入其他话语,那这两者各自为一个词,而如果两者中间不能插入任何话语,则二者为一个词。(7)Leonard Bloomfield,Language,New York:Holt,1933,p.221.相较于布隆菲尔德,陆志韦等人的扩展方案更为详尽。他们的核心思路是,如果一个组合AB,中间可以插入C,且ACB的功能与AB的功能基本相同,则AB是一个词组。比如“铁门”,可以在中间插入“的”,构成“铁的门”,且“铁的门”与“铁门”功能上非常接近,因此“铁门”是词组。相反,在“黑板”中间插入“的”构成的“黑的板”,其与“黑板”功能并不相同,因此“黑板”是词。(8)陆志韦等:《汉语的构词法》,北京:科学出版社,1957年,第21页。相比于单说法,扩展法有一些明显的优势,这主要体现在以下几个方面。首先,它可以提取语言中的很多虚词。比如“去吗”,可以扩展成“去学校吗”,二者功能上是近似的,这样可以将疑问词“吗”定义成词。同理,扩展法也可以解决上面“再来”“将来”等类似的问题。因为“再来”可以扩展(比如“再一次来”),而“将来”无法扩展,因此,可以将前一类视作词组,而后一类视作词。此外,扩展法也提供了解决离合词问题的方案。比如,“将军”可以扩展成“将他的军”,而“理发”可以扩展成“理一次发”,那这些离合词可以视作词组。但这也带来一个问题,离合的成分“将军”“理发”虽然可以扩展,但这类词在语言中没有任何的平行实例,两个语素之间的组合也找不到规则。此外,扩展法也有局限,比如很多语言中动词与直接宾语之间不能插入任何成分。按照扩展法的思路,动宾结构也不再是短语,这当然不太准确。本质上而言,扩展法遵循的也是自由的原则,即自由的成分相组合,其组合关系更为离散,可以扩展,而黏着的成分相组合,其组合关系更为紧密,不可扩展。
更早之前,博爱士就提出过以“位置的自由性”来判定词。(9)Franz Boas,“Introduction”,in F.Boas(ed.),Handbook of American Indian languages,Part I.Washington,D.C.:Government Printing Office,1911,p.30.比如,the在英语中不可单说,但在结构the+NP中,the的位置可以相对变动(比如可以插入形容词)。同时,the+NP短语在句中也可以变换位置(比如做主语或者宾语)。因此,the对于句中所有其他词的位置都是不固定的,可以算作词。本质上,这也是一种类型的扩展法。
(二)词作为基本单位
从上面的分析可以看出,词的提取要比想象中更为困难。无论是单说法还是扩展法,都有无法提取的单位或者无法解决的问题。如果以词作为描写语言的基本单位,意味着缺少了语素构成词的规则的描写,这势必会导致词的数量激增(甚至是无限的),不符合语法描写需要遵循的有限单位的基本要求。这种分析也不符合母语习得时的语感,母语者并不会通过记忆(习得普遍意义上“词”的方法)来习得以及使用规则的黏着语素组合。在汉语中,这种类型的语素主要可以分为三类:第一类是规则活动的实语素,比如“金”“银”“男”“女”“木”“石”,这些黏着语素除了不能独立担任句法成分,在构成更大单位时与一般的实语素分布相当;第二类是传统语法中的虚词,比如“又”“再”“非常”;第三类是语法化程度较高的规则活动语素,比如“某(校)”“(西)化”“(美)式”,这类语素虽实义性较弱却具有很强的能产性。
如果将视野转向黏着语或者多式综合语,词作为基本单位存在的问题就更为明显。在黏着语中,作为核心成分的名词或动词常常携带多个语素,而且每个语素往往只负载单一的语法意义。以芬兰语为例,talo-i-sta-ni(10)talo:词干(房子),i:复数,sta:出格,ni:第一人称单数属格。是一个词,无法切分出更小的可以自由使用的单位,意为“出我的房子(复数)”。这类语言中,小句的组成往往只需两至三个词。从语素到词的过程,多数情况下都要比从词到短语过程更重要。如果不引入语素这层单位,理解语言都会产生困难。多式综合语的词更为复杂,单一的词便可成句。以尤皮克语为例,negh-yaghtugh-yug-uma-yagh-pete-aa=llu(11)negh:吃,yaghtugh:去,yug:想要,uma:过去时,yagh:沮丧范畴;pete:传信(果然);aa:人称,第三人称单数作用于第三人称单数;llu:也。尤皮克语例子来自W.Reuse,“Polysynthetic language:Central Siberian Yupik”,in K.Brown(ed.),Encyclopedia of Language and Linguistics,Amsterdam:Elsevier Science,2006,p.745.是一个词,意为“他/她果然也想去吃,可惜……”。这种情况下,词既是语法分析的起点,又是语法分析的终点,但这显然不太合理。
三、发现程序:从语素到话语
前文的分析已经表明词作为基本单位存在诸多局限。在布隆菲尔德之后,海里斯放弃了词这一层级的单位,并尝试直接从语素描写话语。(12)Zellig S.Harris,“From Morpheme to Utterance”,Language,vol.22,no.3,1946,pp.161~183;Zellig S.Harris,Methods in Structural Linguistics,Chicago:University of Chicago Press,1951.他认为,可以从语素的分布开始,生成全部的话语,所有的功能关系,包括语法结构关系、语义结构关系、表达关系,都不再被考虑。此时海里斯已经完全和功能主义分道扬镳,走向形式化的道路。海里斯的研究和布洛赫的音系理论(13)Bernard Bloch,“Phonemic Overlapping”,American Speech,no.16,1941,pp.278~284.有共同的地方,希望借助最少的概念和原则,提取单位并分类,通过单位的分布来说明组合关系。这种以发现程序为目标的研究取向,可以被称为“后结构语言学”。
(一)语素的提取
语素是语言中最小的有意义的单位,海里斯指出:
句法分析的主要目的之一,就是要给某一种语言里的话语结构做出严密的描写。许多语法著作缺乏甚至根本没有句法方面的描写,这也是笔者要提出这种工作程序的原因之一。
想寻找一个更明确的方法来概括某一种语言里的话语结构,那最好先抓住那些可以观察到的最简单的东西,这就是语素。语素比较容易理解,也比较容易确定。在本文所介绍的方法里,除了语素和语素序列之外,不需要其他的单位,除了替换之外,不需要其他的手续。(14)Zellig S.Harris,“From Morpheme to Utterance”,Language,vol.22,no.3,1946,p.161.此内容为笔者翻译。
这两段文字分别说明了海里斯的研究目标与研究方案。不过,这一方案过于理想化,下面将会分析语素作为句法基本单位的问题。
语素作为句法单位需要面临的第一个问题,也是如何提取的问题。索绪尔最早提出了可操作性的方案,即采取音义同一性对比来提取语素。(15)Ferdinand de Saussure,Cours de linguistique générale,Paris:Payot,1916,p.179.以défaire(拆除)为例,可以通过与左侧的词对比,提出语素dé;再通过与右侧的词对比,提出语素faire,因此,défaire是由dé和faire两个语素组成的。
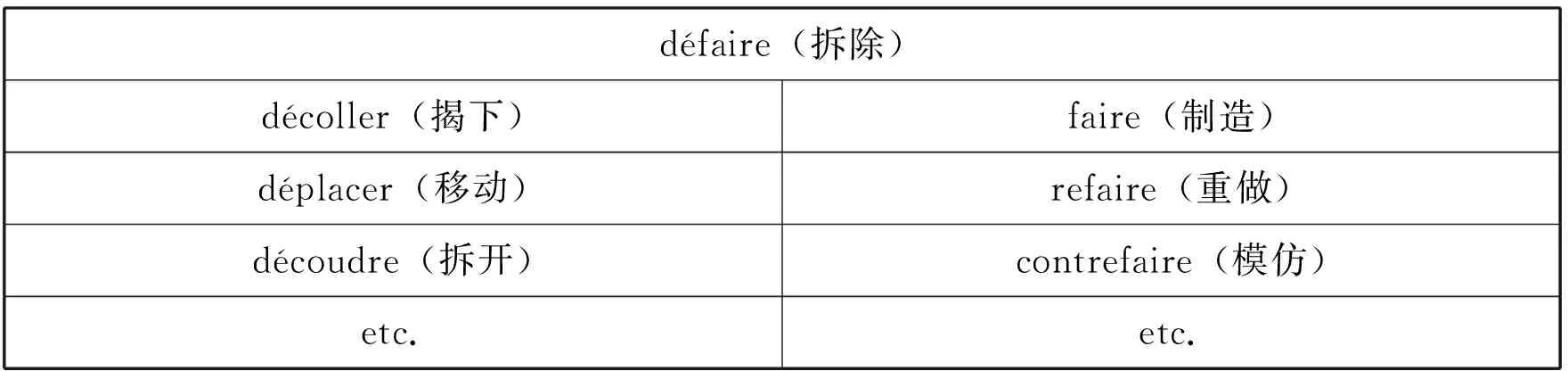
表1:défaire的语素提取
然而,语素在很多语言中不是最自然的单位,提取语素的操作也不如索绪尔所设想的那么简单。以英语单词international为例,母语者一般认为其有两个语素internation和al(库尔德内视角(16)据目前的材料来看,语素这一概念最早应该是库尔德内在1881年提出的。他认为,语素(morfema)是“词的一部分,具有心理自主性且不能进一步切分”。此处可参考Jan Baudouin de Courtenay,“An attempt at a theory of phonetic alternations”,in E.Stankiewicz(ed.),A Baudouin de Courtenay Anthology,Bloomington and London:Indiana University Press,1972,p.153.)。而从同一性对比的角度,我们可以从中提取三个语素inter、nation与al(索绪尔视角)。但如果从“最小的有意义的单位/音义结合体”的定义角度,我们可以将international切分成五个语素,in、ter(表“土地”之义),nat(表“出生”之义)、tion、al(通行定义视角)。可以看出,提取语素具有一定的主观性,从不同角度出发,得到的结论可能不一致。当然,汉语中语素的提取要相对确定,多数情况下,一个“字”为一个语素,这种描写方法可以参考徐通锵的研究。(17)徐通锵:《语言论》,长春:东北师范大学出版社,1997年。
需要说明的是,海里斯对于语素的界定并不完全等同于索绪尔,后者在语素切分上几乎完全遵循在线性层面操作的原则。在这种方案下,sang是一个语素,且与sing不同,而sang与drank之间没有共同语素,但sang与sing、sang与drank之间确实有很多共同的分布。海里斯、霍凯特更新了这种方案,(18)Zellig S.Harris,“Morphemic alternants in linguistic analysis”,Language,vol.18,no.13,1942,p.171;Charles Hockett,“Problems of morphemic analysis”,Language,vol.23,no.4,1947,pp.321~343.除了海里斯与霍凯特,布洛赫1947年也提出了一种语素分析方法。他的方法更为激进,即将sing与sang当成同一语素的变体,而将sang与sing的差别认定为sang后面有一个零形式的过去时后缀。布洛赫的方案可以参考Bernard Bloch,“English Verb Inflection”,Language,vol.23,no.4,1947,pp.399~418.提出可以将范畴抽象出新的语素,比如复数语素、过去时语素,这样sang被分析为“sing”与“/i/~/æ/(过去时)”两个语素,这种方案很大程度上减少了单位的数量,为海里斯从语素到话语的描写提供了便利。(19)后来乔姆斯基对于语素的处理类似于海里斯,但做了进一步的抽象,比如,英语中wh词的改写规则可以简化成wh+he→/huw/,wh+him→/huwm/,wh+it→/wat/。Noam Chomsky,Syntactic Structures,The Hague:Mouton,1957,p.69.
(二)语素作为基本单位
相对于词作为语法研究的单位,语素作为基本单位有一定的优势,这是因为语言中很多语素的组合是有规则的。比如英语中复数的-(e)s,如果将books、boxes这样的成分视作语言中的基本单位,那么语言中的单位将会是无穷的,同时也会忽视英语中最为基础的复数规则。要从语素逐层描写话语,必须符合一个基本条件,即语素组合的类可以从语素的类中推导得出,而语素与词的差别主要在于分布,这也是海里斯的基本思路。
不过,语素组合的类并不总是能通过语素自身的类来推导。一般情况下,汉语中一个形容词性的语素与一个动词性的语素结合,产生出的语素组合也是动词性的,比如“远看”“慢跑”“早起”。但如果把后面的语素换成另一个动词性的语素“视”,前面的规则就很难成立。“视”与一个形容词的语素组合,可能产生一个动词性的语素组(如“重视”),也可能产生一个名词性的语素组(如“远视”),或是一个形容词性的语素组(如“近视”)。此外,如果语素的组合只考虑规则,而不考虑规则使用的限制,便会产生过度类推。比如,英语最能产的表示“两”概念的前缀是bi-,可以生成一系列与时间相关语义的词,如biennial,biyearly,biannual,biweekly,bimonthly,bihourly等。如果只考虑语素组合规则,便会生成bidayly或是biminutely这样语言中没有的组合。总的来看,语素作为基本单位面临的最大问题,是单位的类不能确定地推导出组合的类。如果只使用一层单位,便不能生成所有可能的话语,不符合语言描写的目标。
海里斯之后,也有一些方案尝试直接从语素描写语言,比如词句法、分布式形态学。(20)词句法:Elisabeth Selkirk,The Syntax of Words,Cambridge,MA:MIT Press,1982;分布式形态学:Morris Halle and Alec Marantz,“Distributed morphology and the pieces of inflection”,in K.Hale & S.Keyser(eds.),The view from building 20:essays in linguistics in honor of Sylvain Bromberger,Cambridge,Mass.:MIT Press,1993,pp.111~176.下面我们以分布式形态学为例简要分析一下这些方案的研究思路。分布式形态学将词分解成三个部分:句法终端(syntactic terminal)、词汇表(vocabulary)、百科知识(encyclopedia)。句法终端中储存词根与抽象语素,词汇表负责为推导后的语素提供音系信息,百科知识负责为词表征语义。这种方案下,语素不能等同于结构主义的“语素”,它是完全抽象的,而且没有音义结合的意味,但这里的语素比起结构主义的“语素”,更适合担任推导的起点。相对而言,词变成了句法推导的目标,与短语产生的机制相同。分布式形态学的核心思路,是认为词法与句法等同,因此,只需要“单引擎”就能描写语言。从奥卡姆剃刀准则来看,只用一套概念来描写整个系统无疑是最好的。但就语言事实来说,很难找到一种自然语言,它的所有语素组合都是规则生成的。因此,使用两层单位描写语言很有必要。(21)阿罗诺夫将词法/句法等同与词法/句法双分称为“刺猬与狐狸之争”(狐狸知道很多事,刺猬知道一件大事)。他的观点与本文类似,即句法与词法有很多类似的地方,这点不可否认,但相对而言,词法不像句法那样规则,两者在很多地方依然存在着差异,因此,需要保留词法。Mark Aronoff,“A fox knows many things but a hedgehog one big thing”,in A.Hippisley & G.Stump(eds.),The Cambridge Handbook of Morphology,Cambridge:Cambridge University Press,2016,pp.186~205.
四、基于平行周遍的还原程序
发现程序以寻找自然语言中的单位(与单位对应的是规则)为主要目的,认识到了语言习得的关键问题。从这个层面发现程序的基本方向是正确的。但同时,它也存在着比较明显的局限,这体现在它未能意识到平行类推和平行周遍类推机制在获取单位和规则上的重要性。因此,在实际操作时,无论是使用语素作为基本单位,还是使用词作为基本单位,都在描写实际语言时遇到了问题。比如,在“发现程序”的框架下,英语中的enlarge是一个语素组合,由前缀en-与large组成。这样的分析势必导致一个问题,我们需要标注所有的en-(意为“使变得”)为前缀的动词性语素组合,因为哪些形容词性的语素(如large)可以与前缀en-搭配产生一个动词性的语素组合是不可预测的。这种情况下,我们不如直接将enlarge这样的语素组合直接视作单位。但这样也有两个缺点:一则enlarge确实可以再切分,二则忽视了前缀en-的语义和一定的能产性。更困难的是,前缀en-不仅可以与形容词语素组合,也可以与名词性语素组合(如encage、enshrine、entitle,表“放于……之中”或者“配以……”之意),或者与动词性语素组合(如enclose、enforce、enkindle,表动作的加强)。不过,如果从语言习得的角度去理解,我们可以更好地解释这类现象。enlarge的语素组合是有规则的,当然这个规则并非生成性的,它的习得需要记忆而非理解。在逐渐了解组合规则之后,再看到en-与形容词性语素的搭配,便可以判定组合整体是动词性成分。这种现象类似于汉语的儿化现象,一方面,学习者不能通过简单的规则来知道哪些名词可以儿化;另一方面,如果学习者看到语料中有“名词+儿”的语素组合,却可以理解组合的语义以及组合的词性。
我们主张,通过类推平行周遍原则来提取语言中的规则组合与不规则组合。(22)关于平行周遍的理念以及操作原则,参见陈保亚《再论平行周遍原则与不规则字组的判定》,《汉语学习》2005年第1期;陈保亚《论平行周遍原则与规则语素组的判定》,《中国语文》2006年第2期;陈保亚《语法描写的必要条件:双层语法单位—就句法单位问题答潘秋平等》,《语言学论丛》2014年第1辑(总第49辑),第280~311页。如前文所述,语言系统存在两套单位,一套是自由单位与黏着单位,另一套是规则活动的单位与不规则活动的单位。从语言习得的角度来看,规则单位与不规则单位的区分应该更为基本。多数情况下,自由与规则是对应的,自由成分的组合一般比较规则。但一些情况下,黏着成分与自由成分(或另一黏着成分)的组合也是规则的。一个典型的例子,是汉语中的不自由语素“鸭”。从语义与构词的角度,“鸭”与“鸡”“鹅”这些单位都是平行的,“鸭肉”“鸭翅”“鸭肠”“鸭脖”等这些组合的生成在方法上与“鸡肉”“鸡翅”“鸡肠”“鸡脖”是一样的,完全可以使用规则控制。但由于“鸭”不自由,先前的研究一般将“鸭”与“鸡”视作不同层级的句法单位,而在平行周遍的方案中,二者都被视作规则语素,“鸡肉”与“鸭肉”都被视作规则语素组(或字符组)。(23)王洪君专门讨论过汉语两字组的成词性问题,她的基本观点是,汉语中词与短语在语法上没有显著的界限,很多黏着语素(实字)都可以规则活动。本文认同这一观点,这里的“鸭”就是典型的例子。参见王洪君《从字和字组看词和短语——也谈汉语中词的划分标准》,《中国语文》1994年第2期。

表2:平行周遍原则为基础的语法系统
表2展示了这套以描写语言中规则单位与不规则单位为基础的语法系统,这套系统涵盖了语素组合的各种可能性。第一列是自由语素与自由语素组合,两个语素都可以被替换,两者构成了传统语法中的词组或者短语;第二列是自由语素与词缀组合,这类词缀主要是屈折词缀,词缀的能产性较强;第三列、第四列是传统语法中的附缀词,其中一个语素是派生词头/词尾;第五列、第六列是合成词,其中第六列已经转义。在平行周遍的框架下,前三列属于规则语素组合,因为这里的所有组合中至少有一个成分可以被平行替换,在习得时不需要记忆,也没有理解的负担。第四列、第五列是理解式规则语素组合,习得时需要记忆哪些语素可以组合,但是语义部分可以推导。第六列是不规则语素组合,习得时需要整体记忆,内部没有规则可以推导。
五、余 论
语言习得的核心是规则的习得,儿童掌握母语,主要依赖于通过特定的手段提取出母语中的单位与规则。这种手段不仅是简单的类推,同时也综合了归纳与演绎。先从少量的语料中通过类推获得规则,并通过规则生成全新的话语。当然,儿童对于规则的概括不总是精确的,容易出现过度类推。在接收到他人的负面反馈后,他会重新归纳规则,这样儿童的规则系统会逐步接近成人。语法描写的目标便是揭示这样的规则,从这个角度来看,结构主义发现程序的方向基本上是正确的,即先还原出单位,再生成句子。但在具体操作时,无论使用语素或者词作为基本单位,都在描写语言时遇到了困难。
语言中存在规则组合与不规则组合,这是人类语言的共性之一,本文主张应以此为语法描写的出发点。平行周遍的方案在结构主义的基础上,将是否规则视作提取语言单位的标准。语言中的组合关系可以分为三类:不可类推、可平行不周遍类推、可平行周遍类推,而这三者分别对应了三种不同的习得策略:记忆性、理解性、生成性。平行方案最重要的程序便是寻找规则与不规则的边界(周遍的条件),这也是规则习得的关键步骤。在习得规则以后,语言记忆与生成的负担都会极大减轻。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
思维与智慧·上半月(2022年4期)2022-04-08
小哥白尼(神奇星球)(2021年4期)2021-07-22
大连民族大学学报(2021年2期)2021-07-16
华中学术(2020年2期)2020-11-30
——针对对外汉语语素教学构想
长江丛刊(2020年30期)2020-11-19
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
汽车观察(2016年3期)2016-02-28
当代修辞学(2014年3期)2014-01-21
