
基于动态遍历的分层特征网络视觉定位
2021-09-15 07:36:22蒋雪源陈青梅黄初华
计算机工程 2021年9期
蒋雪源,陈青梅,黄初华
(贵州大学计算机科学与技术学院,贵阳 550025)
0 概述
实现移动设备实时精确的定位是移动增强现实技术的基本要求[1]。由于GPS、北斗等方式难以穿透建筑物,移动设备在建筑密集区域的定位比较困难,而利用超宽带、红外、超声波等设备接收信号实现定位,需要在场景中部署设备[2]。以上两类方法在实际应用时均有不足,而视觉定位方法不存在上述问题,因此受到众多学者的关注[3]。
针对从场景图像中估计查询图像位姿的问题,SARLIN 等[4]提出了层次定位方法。该方法利用卷积神经网络在场景图像中找到候选帧,候选帧聚类后与查询图像进行特征点匹配,建立特征点的2D-3D对应关系,使用PnP 算法估计相机位姿。之后,SARLIN 等[5]在层次定位方法的基础上提出了分层特征网络(Hierarchical Feature Network,HFNet),进一步改善了层次定位的性能。该方法联合估计图像的全局描述符与局部特征点,使层次定位方法具有出色的鲁棒性。HFNet 将基于SIFT[6]的局部特征描述符替换为基于学习的局部特征描述符,引入了多任务知识蒸馏方法,使层次定位方法对计算资源的需求进一步减小。但是HFNet 估计全局描述符的效果仍需提升,这导致层次定位方法查找候选帧的失败率较高同时,同时层次定位方法的聚类步骤计算量也比较大。
本文在HFNet 的基础上,提出结合动态遍历与预聚类的视觉定位方法。利用动态遍历方式搜索候选帧,对粗略检索步骤的候选帧数量做动态调整。在此基础上,根据场景地图进行图像预聚类,引入压缩-激励模块和h-swish 激活函数改进分层特征网络。
1 相关工作
目前视觉定位技术主要分为基于图像检索、基于场景地图、基于学习3 类方法[5]。基于图像检索的方法通过在场景图像中检索查询图像,从场景图像返回与查询图像最相似的图像,近似得到查询图像的位姿[7-8]。该类方法可以应用到大型数据集中,但只能估计查询图像的近似位姿。基于场景地图的方法[9-10]通过直接匹配查询图像与场景地图建立查询图像特征点的2D-3D 对应关系,从而得到查询图像的相机位姿。在大型场景中,由于场景地图规模庞大,该方法可靠性不高。基于学习的方法通过神经网络学习方法获得相机位姿,如KENDALL 等[11]提出的PoseNet,通过训练室内与室外场景图像和图像对应的相机位姿,预测出查询图像的相机位姿。该方法在大规模变化场景下具有出色的鲁棒性,但定位精度不能达到增强现实应用的要求。
作为一种结合图像检索与场景地图的视觉定位方法,层次定位方法可在大型数据集中估计查询图像的精确位姿,但其需要提取场景图像的特征点构建场景地图。首先在场景图像中根据全局描述符对查询图像进行粗略检索,得到由场景图像组成的候选帧集合;然后将有共同特征点的候选帧聚类为一组,查询图像与各组候选帧进行局部特征点匹配,匹配的特征点可以从场景地图得到三维坐标,构建特征点的2D-3D 对应关系;最后使用PnP 算法估计查询图像的相机位姿。针对层次定位中全局描述符与局部特征点的提取,HFNet 进行联合估计。该方法以MobileNetV2[12]为编码器,以NetVLAD[8]和SuperPoin[13]为解码器。其中,NetVLAD 解码器输出图像的全局描述符,SuperPoint 解码器输出图像的局部特征点。然而,HFNet 存在全局描述符检索率低的问题,且聚类步骤的速度仍需提升。本文通过分析相机位姿恢复失败的查询图像,发现大部分恢复失败的图像并没有搜索出正确的候选帧。如图1 所示,Query.jpg为查询图像,其余图像为粗略检索得到的候选帧。可以看出,查询图像与候选帧并不在同一地点,在候选帧数量有限的情况下会出现粗略检索候选帧失败的现象,导致恢复相机位姿失败。增加候选帧的数量可以缓解这个问题,但会增加聚类与局部特征点匹配的图像数量,导致运算量成倍增加。

图1 相机位姿估计失败的查询图像与候选帧Fig.1 The query images and candidate frames where camera pose estimation fails
2 本文方法
2.1 改进的层次定位算法
本文提出了基于动态遍历与预聚类的层次定位方法,算法框架如图2 所示,其中上半部分为场景图像预处理,构建场景地图与聚类信息;下半部分为相机位姿估计。
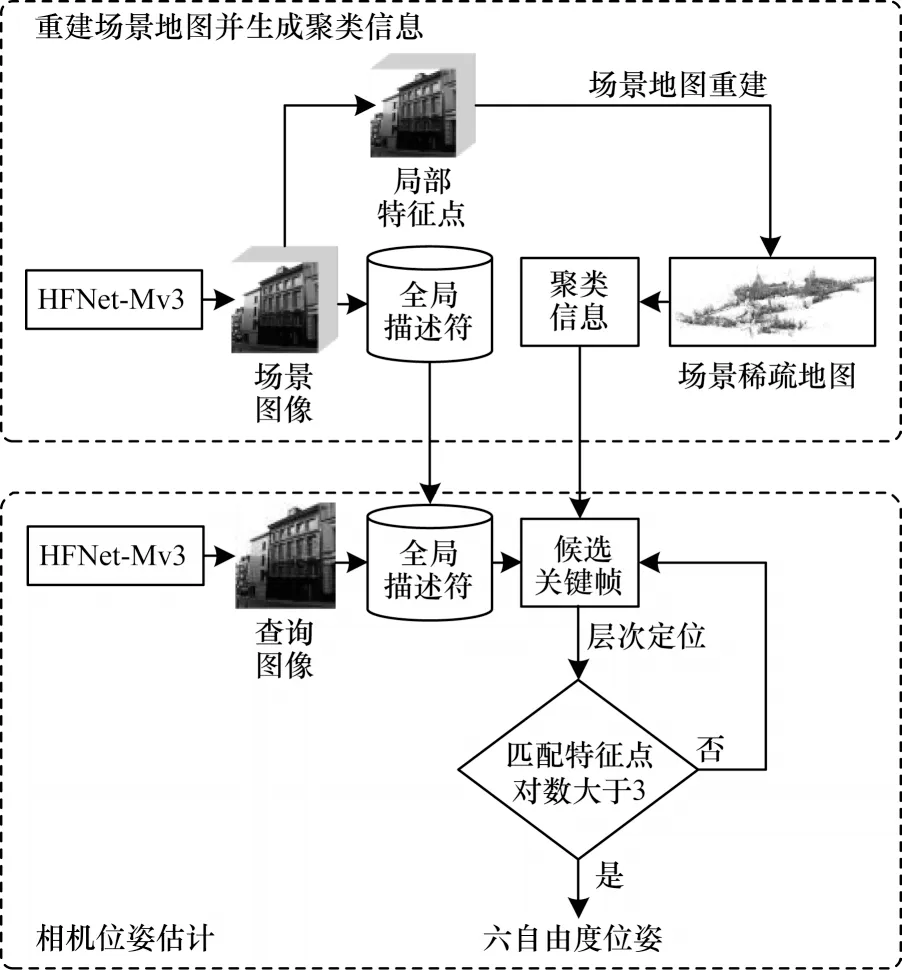
图2 本文方法框架Fig.2 Framework of the proposed method
本文方法主要步骤如下:
1)利用基于MobileNetV3[14]的分层特征网络(简称HFNet-Mv3)提取全局描述符与局部特征点,全局描述符用于查询图像与场景图像的粗略检索,局部特征点用于构建场景稀疏地图Q。
2)通过场景地图Q 对场景图像进行预聚类。层次定位方法先在场景图像中找到候选帧,再将这些候选帧按照是否为同一地点进行聚类,将有共同特征点的候选帧分为一组。笔者发现参与聚类步骤的图像均为场景图像,利用场景地图对场景图像进行预聚类处理,使得上述步骤可以直接对候选帧分组,降低了聚类步骤的运算量,且聚类结果不变。以场景图像L为例,预聚类步骤如下:记图像L的特征点为集合F,F={α1,α2,…,αn},α为集合F中的特征点,记I=P(αk)为拥有特征点αk的场景图像,αk∊F。遍历特征点集合F,将拥有这些特征点的场景图像记为图像L的聚类队列M,即M=(I|I=P(αk),αk∊F)。查找所有场景图像的聚类队列并保存,就能得到场景图像的聚类信息。
3)动态遍历搜索候选帧。如图3 所示,查询图像与场景图像进行全局描述符匹配,得到m张场景图像组成的候选帧,这些候选帧选取前n张进行层次定位。聚类信息包含每个场景图像拥有共同特征点的图像序列,与候选帧匹配可直接完成聚类步骤。算法对参与层次定位的候选帧数量进行动态调整,若前n张候选帧层次定位失败,视为选中的候选帧没有查询图像所在的地点,则动态增加候选帧数量,候选帧向后选取n张图片继续进行层次定位。以n张图片为动态查询窗口,直到计算出查询图像的相机位姿。候选帧数量对粗略检索的速度影响不大,对聚类和局部特征点匹配的速度影响很大。动态遍历搜索候选帧的方法使聚类与局部特征点匹配的候选帧数量保持不变,对粗略检索步骤的候选帧数量进行动态调整,从而以较小的计算量代价缓解了查询图像定位失败的问题。
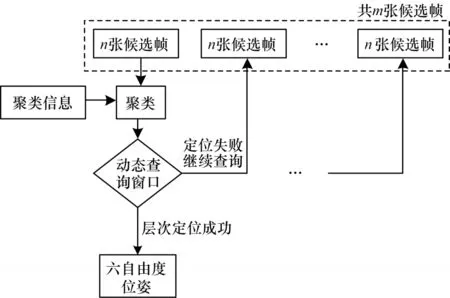
图3 动态查询流程Fig.3 Procedure of dynamic query
2.2 基于MobileNetV3 的分层特征网络
本文算法使用基于MobileNetV3 的HFNet-Mv3提取查询图像的全局描述符与局部特征参与层次定位过程。MobileNetV3 使用神经网络搜索算法构建全局的网络结构,利用NetAdapt[15]算法对每层卷积核数量进行优化。在网络结构上引入了压缩-激励模块[16](Squeeze-and-Excite,SE),网络根据损失函数学习特征权重,增大有效的特征图权重,减小无效或效果小的特征图权重,从而达到更好的训练效果。
HFNet 使用ReLU 激活函数,swish 激活函数在深层模型上的效果优于ReLU,但计算量大。MobileNetV3 引入了h-swish 激活函数,在降低计算量的同时对swish 激活函数进行了拟合,其定义如式(1)所示:
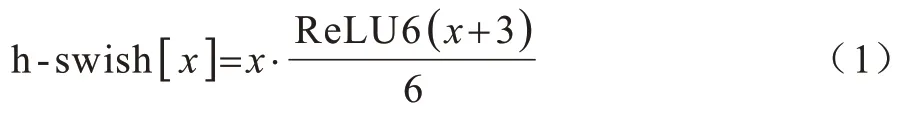
为提升分层特征网络的性能,本文以MobileNetV3-Large[14]作为分 层特征网 络的编 码器,以NetVLAD 和SuperPoin 作为解码器,提出了改进的分层特征网络HFNet-Mv3,其网络结构如图4所示。
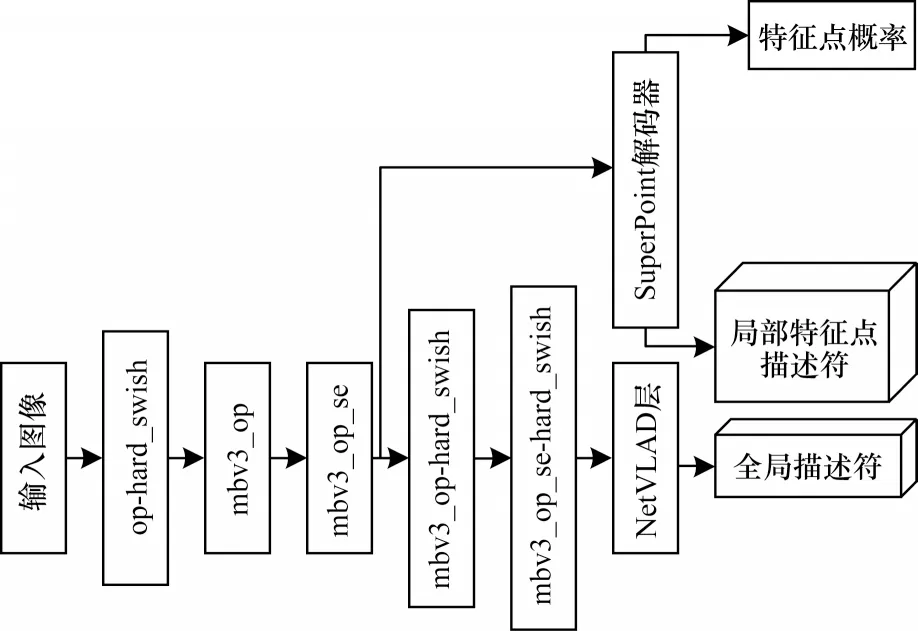
图4 HFNet-Mv3 的网络结构Fig.4 Network structure of HFNet-Mv3
HFNet-Mv3 的编码器由op-hard_swish、mbv3_op、mbv3_op_se 等6 个模块组成,其 中:mbv3_op_se 与mbv3_op_se-hard_swish 引入了压缩-激励模块;op-hard_swish、mbv3_op-hard_swish 和mbv3_op_se-hard_swish 使 用了h-swish 激活函数。除op-hard_swish 外编码器以深度可分离卷积[17]作为卷积核的基本单位。
SuperPoint解码器需要更高的分辨率来保留特征,因此,在mbv3_op_se层之后,即在HFNet-Mv3的第7层引入了SuperPoint解码器,用来输出图像像素的特征点概率和局部特征描述符。由于NetVLAD 解码器需要更多的语义信息用于输出图像的全局描述符,因此在HFNet-Mv3 的最末端引入了NetVLAD 解码器。
损失函数如式(2)所示:

其中:ωi为优化变量,用于避免手动调节各个损失函数的权重[18];为HFNet-Mv3 的全局描述符输出;为教师网络的全局描述符输出;为HFNet-Mv3的局部特征描述符输出为教师网络的局部特征描述符输出;ps为HFNet-Mv3 的局部特征点输出;pt3为教师网络的局部特征点输出,局部特征点采用交叉熵计算损失。
3 实验结果与分析
3.1 实验环境及数据集
基于TensorFlow1.14.0 和pytorch0.4.1 框架进行实验,训练实验的硬件配置如下:IntelXeon®CPUE5-2620v42.10 GHz,NVIDIATITANXp12 GB;定位实验的硬件配置如下:IntelCorei58300H2.30 GHz,NVIDIAGTX10606 GB。
采 用GoogleLandmarks 和Berkeley DeepDrive 数 据集训练HFNet-Mv3。Google Landmarks 数据集包括世界各地的城市场景,选取其中的185 000 张图片进行训练;BerkeleyDeepDrive 数据集由黄昏与夜间的道路场景组成,选取其中的37 681 张图片参与训练。所有图片都预处理为480 像素×640 像素的灰度图。采用SuperPoint与NetVLAD 作为HFNet-Mv3 的教师网络,分别估计GoogleLandmarks 数据集和Berkeley DeepDrive 数据集的局部特征点、局部特征描述符和全局描述符作为图像标签。对HFNet-Mv3 进行多任务知识蒸馏训练[19],batch_size 为16,通道乘数[12]为0.75,总迭代次数为85 000 次,初始学习率设置为10-3,随迭代进行,微调学习率。
在AachenDay-Night 和CMUSeasons 数据集上评估HFNet-Mv3 对HFNet 的提升效果,每个数据集由稀疏的场景地图和图像组成。AachenDay-Night数据集包含了4 328 张来自Aachen 旧城区白天的场景图像、824 张白天查询图像和98 张夜间的查询图像。CMUSeasons 数据集记录了不同季节的图像,由17 个子集组成,包含了市区与郊区的7 159 张场景图像和75 335 张查询图像,由于季节、光照和天气的变化导致环境条件的变化,该数据集具有挑战性。由数据集作者提供的场景地图并不适用于分层特征网络定位,因此,本文利用HFNet-Mv3 在场景图像中提取特征点,利用COLMAP[20]软件对特征点进行匹配与三角测量,得到该数据集的场景地图。
3.2 定位结果及分析
选用通用的基准数据集AachenDay-Night 和CMUSeasons 进行测试,并将测试结果与ActiveSearch(AS)[21]、CityScaleLocalization(CSL)[9]、DenseVLAD[22]、NetVLAD、DIFL+FCL[23]和HFNet 作为定位精度基准进行对比。AS 和CSL 是基于场景地图的视觉定位方法,DenseVLAD、NetVLAD 和DIFL+FCL 是基于图像检索的视觉定位方法,本文方法使用HFNet-Mv3 提取图像的全局描述符与局部特征点,使用基于预聚类与动态遍历的视觉定位方法估计相机位姿。
通过相机位姿的估计值与真实值之间的偏差来评估算法的精度。将定位结果上传到数据集作者的网站(https://www.visuallocalization.net/submission/),由数据集作者对算法的位姿精度进行评估。数据集作者设定3 个位姿精度区间,即高精度(0.25 m,2°)、中精度(0.5 m,5°)和低精度(5 m,10°),通过比较在不同精度条件下的召回率来比较算法的精度。
3.3 运行时间
通过记录算法在不同步骤的运行时间,比较本文算法与HFNet 的运行速度。由于实验硬件配置差异的原因,实验结果与原文献数据会略有不同。
表1 为视觉定位方法在不同距离与角度阈值下的召回率,从左到右依次为高精度、中精度和低精度的召回率,算法性能已在数据集网站公开(本文方法名称为Dynamic retrieval and pre-clustering for HFNet-Mv3),其中DIFL+FCL 的作者只在CMUSeasons 数据集上做了测试。由表1 可以看出,本文方法在不同距离与角度阈值下的召回率均大于其他算法,在Aachen 夜间与CMU 公园场景的精度上,相对HFNet 提升5%以上。夜间图像粗略检索正确的候选帧比较困难,公园场景图像的季节、光照和植物的变化更明显,导致层次定位失败。对比HFNet,本文方法缓解了这个问题,因此,Aachen 的夜间图像与CMU 的公园场景图像估计相机位姿精度的提升效果更明显。
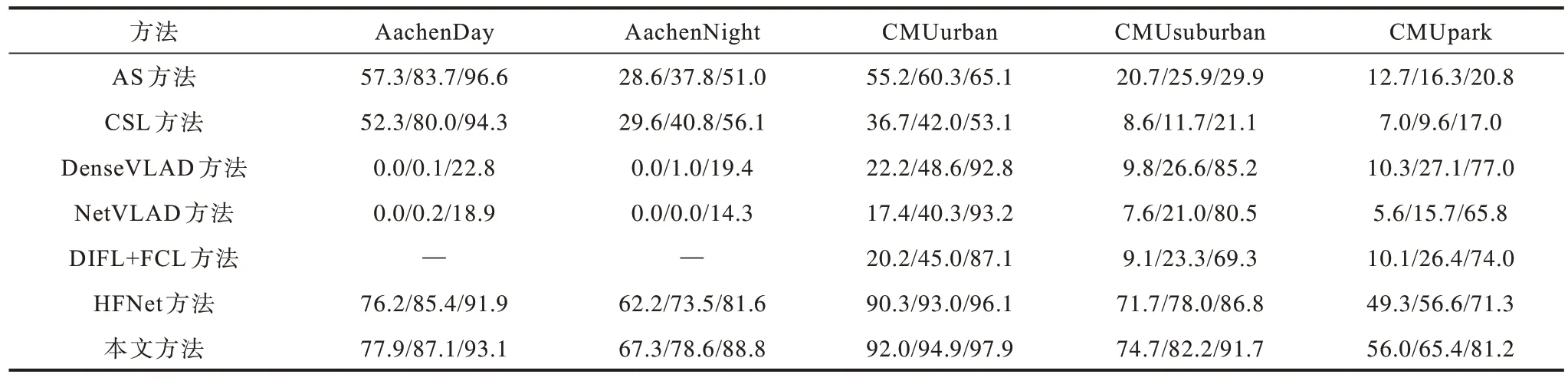
表1 在AachenDay-Night 和CMUSeasons 数据集上的定位精度对比Table 1 Localization accuracy comparison on AachenDay-Night and CMUSeasons datasets %
表2 为视觉定位方法在不同步骤的运行时间,从左到右依次为特征提取、全局检索候选帧、聚类、局部特征点匹配、PnP 求解相机位姿和总耗时,CMUslice2、CMUslice9、CMUslice25 分别为CMUSeasons在市区、郊区与公园场景的子集。由表2 可以看出,本文方法在特征提取与全局检索候选帧步骤的耗时与HFNet 几乎一致。由于本文方法采用了预聚类策略,聚类步骤的耗时缩短为HFNet 的10%。针对HFNet 检索正确候选帧失败的查询图像,本文方法动态增加候选帧的数量,导致局部特征点匹配与PnP 求解相机位姿的平均耗时增加。由于聚类步骤耗时的大幅缩短,本文方法总耗时与HFNet 几乎一致。

表2 在AachenDay-Night 和CMUSeasons 数据集上的定位速度对比Table 2 Localization speed comparison on AachenDay-Night and CMUSeasons datasets ms
3.4 动态遍历参数
本文提出的动态遍历方法有2 个关键参数,即候选帧数量m和动态查询图像数量n。候选帧数量决定了分层特征网络获取正确候选帧的能力,随着候选帧数量的提升,定位精度的提升变得不明显,而速度明显降低。动态查询图像数量决定了聚类图像数量,太小会减少匹配的特征点数量,影响定位精度,太大会导致下一窗口得不到充足的聚类图像,并降低运行速度。
表3 和表4 为不同动态遍历参数下本文方法在AachenDay-Night 数据集中的定位精度与速度。由于动态遍历参数不影响特征提取,因此特征提取步骤耗时相同。候选帧数量m设为80,定位精度最高,但速度降低幅度过大。由实验结果可得,候选帧数量m设为40,动态查询图像数量n设为10 的情况下,定位精度与速度最优。

表3 不同参数情况下本文方法在AachenDay-Night数据集上的定位精度Table 3 Localization accuracy of the proposed method on AachenDay-Night dataset under different parameters %
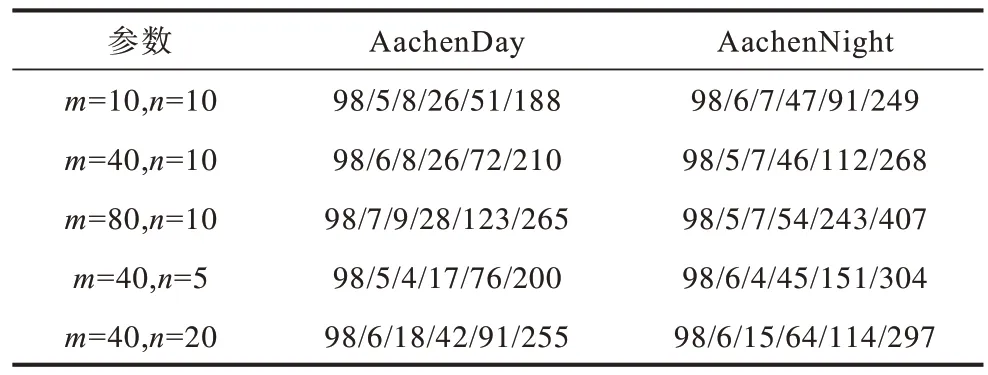
表4 不同参数情况下本文方法在AachenDay-Night数据集上的定位速度Table 4 Localization speed of the proposed merthod on AachenDay-Night dataset under different parameters ms
4 结束语
本文针对层次定位方法粗略检索失败率高和聚类耗时长的问题,在分层特征网络中引入压缩-激励模块与h-swish 激活函数,提出基于动态遍历与预聚类的视觉定位方法。在2 个通用基准数据集上的实验结果表明,本文方法通过对粗略检索步骤的候选帧数量进行动态调整,有效降低了检索候选帧的失败率,与HFNet 方法相比,高精度、中精度和低精度的召回率均有所提升,其中夜间与公园场景的精度提升达到5%以上。同时该方法采用了预聚类策略,使得运行速度与HFNet 基本一致。本文方法适用于城市和郊区等室外场景,下一步将针对室内环境训练优化HFNet-Mv3,并对室内环境下的层次定位方法进行改进。
猜你喜欢
测绘学报(2022年12期)2022-02-13 09:13:01
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
数字通信世界(2018年1期)2018-04-18 11:05:22
测绘科学与工程(2017年5期)2017-05-07 06:30:44
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
专利代理(2016年1期)2016-05-17 06:14:36
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
组合机床与自动化加工技术(2014年12期)2014-03-01 02:22:51
中国科技信息(2010年9期)2010-11-07 08:40:44
