
基于改进Apriori算法的配电网设备退役信息挖掘
2021-09-13 04:11:44廖孟柯李忠政
科学技术与工程 2021年24期
廖孟柯,樊 冰,李忠政,付 林,舒 楠*
(1.国网新疆电力有限公司经济技术研究院,乌鲁木齐 830002; 2.华北电力大学电气与电子工程学院,北京 102206)
配电网设备作为电网的重要组成设备,是影响电网运行安全性和稳定性的重要因素[1]。随着配电网设备资产规模不断扩大,合理提高设备利用率降低设备成本显得愈发重要[2]。通过对配电网设备退役信息研究,挖掘出影响因素不仅对设备的设计制造具有实际意义[3],并且能够完善配电网退役策略,有效地指导配电网设备的运维管理,提高配电网资产使用效率,优化配电网设备配置及更新方案[4-5]。一些学者在不同的方面考虑到了可能会造成配电网设备提前退役的因素。文献[6]研究了配电网设备运行环境的温度会加快设备老化的速度。文献[7]表明气压会影响设备散热以及绝缘的性能。文献[8]研究发现极端环境因素会增加设备故障的概率。但由于配电网设备种类繁多,工作场景各异,可能涉及的影响因素错综复杂。但目前尚无利用数据挖掘手段针对不同种设备退役因素的系统研究,无法有效地指导退役决策,使得配电网设备投资效率普遍较低。
利用数据挖掘手段可以在庞大的配电网设备退役信息中得到对设备退役影响关系紧密的各个因素。其中,Apriori算法是最经典的数据挖掘算法。但是传统的Apriori算法在计算过程中存在大量冗余过程。随着数据量的增加,算法的时间复杂度会大大增加[9-10]。针对这一问题,对Apriori算法进行改进,应用在配电网设备提前退役信息的挖掘中,更高效地探究外部因素对设备退役的影响情况。
1 配电网设备退役相关信息处理
1.1 配电网设备退役相关指标
较为成熟的配电网设备全寿命周期管理与研究的发展已积累了众多寿命数据。如表1所示,根据配电网设备全寿命数据可以分为基础数据、检试数据、实时数据、环境数据、经济数据和其他数据等6类[11-12]。

表1 配电网设备全寿命周期数据分类
主要研究环境因素对配电网设备的影响,较为关切其中的环境数据。因此在进行统计配电网设备的退役信息时,对目标设备搜集的信息应包括设备类型、设备寿命、设备地域等基础数据之外,还需要收集设备相关的环境数据。
1.2 配电网设备退役相关数据的预处理
根据配电网设备的相关指标,收集目标设备相关信息,并且对收集的数据进行预处理。配电网设备的寿命数据分布连续且区间较长,在应用前需先对设备寿命的分布曲线进行分析,取分布曲线中段分布较为集中且数据量足够的部分,平均分为3段进行离散化。根据设备的设计寿命将其划分为正常退役、稍早退役和较早退役。
对环境数据需要进行二值化处理。依据气象预警标准以及配电网设备的物理特性划定因素是否会影响设备状态的标准[13-15]。如果气温大于 35 ℃ 视为高温情况,气温低于0 ℃视为低温情况。如果相对湿度大于90%视为过湿情况。如果海拔高于2 500 m视为高海拔。如果有沙尘暴天气算受沙尘影响情况。如果所受风力大于八级算强风情况。符合条件的属性按所在列顺序进行标号,不符合的则不记。部分数据记录如表2所示。
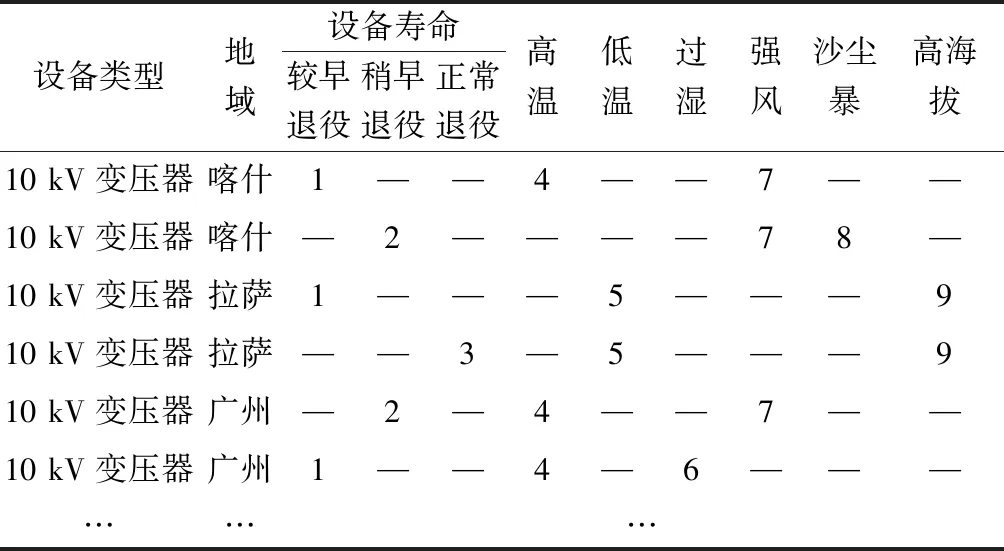
表2 部分配电网设备退役信息
2 基于三维矩阵的数据挖掘算法
2.1 算法描述
2.1.1 相关定义
挖掘关联规则所用到的每一条事务t存储在数据仓库D中,记为
D={t1,t2,…,tM}
(1)
式(1)中:每一条事务t由各项属性i构成,可表示为
t={i1,i2,…,iN}
(2)
定义属性X和Y之间的关联规则为X⟹Y。该关联规则的支持度Support等于事务同时拥有属性X和属性Y的数量与总事务数的比值,可表示
(3)
式(3)中:M为事务的总数;Count(X∪Y)为属性X和属性Y同时出现的事务的次数。
该关联规则的置信度Confidence等于规则的支持度与属性X本身的支持度之比,可表示
(4)
式(4)中:Support(X)为属性X出现的次数。
数据挖掘通过设置最小支持度和最小置信度来控制所得关联规则需要满足的最低要求。
2.1.2 算法过程
传统的Apriori算法在数据量较大且分析类别较多的情况下会产生大量的候选项集,尤其是生成二项集和三项集时。并且在进行每次生成更高一级的频繁项集时,都需要重新扫描数据库,会产生大量计算冗余,效率较低。在Apriori算法的基础上,针对传统算法的这些缺点,进行了改进。改进后的算法思路如下。
(1)首先扫描数据库,将数据库根据所有其事务所含有的属性,抽象成二维矩阵,用于存储该数据库中所有的信息。
(2)遍历二维矩阵中每个事务的每个属性。通过每次读取同一事务中的两个不同属性且不重复读取,建立三维上三角属性矩阵Matrix(i,j,k),并根据对应的属性来建立坐标。三个维度上的坐标区间均为[1,N](N为最大属性种类)。扫描过程中,坐标每重复一次,对应的权重加一,矩阵可表示为
Matrix(i,j,k)=Matrix(i,j,k)+1
(5)
(3)其次通过读取三维属性矩阵,直接获取频繁一项集、频繁二项集和频繁三项集。三维矩阵第一卦限的空间对角线上即频繁一项集的支持度,对应平面上的坐标(i,j,j)为频繁二项集的支持度,坐标(i,j,k)为对应三项集的支持度。
(4)因为在属性数量小于k的事务中,必然不存在含有k项集的可能。因此在得到频繁三项集后,扫描数据库。删去包含的属性不大于四项的事务,简约数据库。
(5)通过已经得到的频繁三项集,再利用标准的Apriori算法进行后续计算。
具体的算法流程如图1所示。
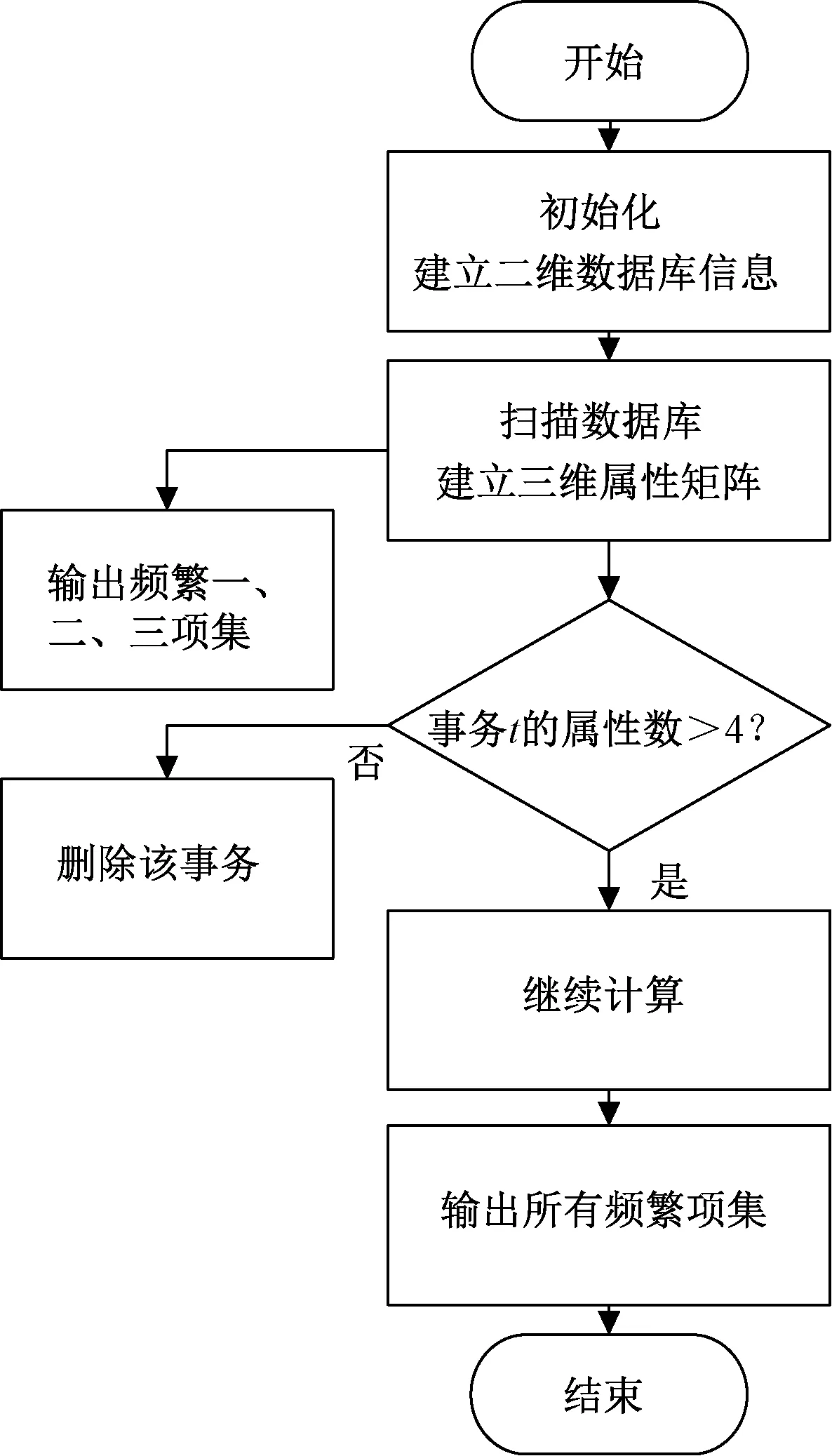
图1 三维矩阵算法流程
2.2 算法时间复杂度分析
假设数据库中事务数量为M,事务平均属性数量为n,属性数量小于4的事务比例为b。表示频繁k项集的项集数量,表示候选k项集的项集数量。
参考文献[16]对传统Apriori算法的时间复杂度的分析,对比两种算法的时间复杂度,时间复杂度用O表示。Apriori算法在形成频繁一项集L1后,通过连枝得到候选二项集的时间复杂度表示为
(6)
随后通过扫描数据库,计算支持度得到频繁二项集L2的时间复杂度表示为
(7)
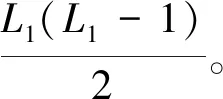
(8)
可见式(8)表示的复杂度与式(6)相同,则计算频繁二项集L2的过程中,基于三维矩阵的数据挖掘算法可以节省的时间为式(6)+式(7)-式(8)=式(7)。可以看出计算频繁二项集的过程节省的时间与M、n和L1有关,在较大的数据样本中能够有效地节省计算时间。
根据频繁二项集L2,通过连枝、剪枝得到候选三项集的时间复杂度,可表示为
O[L2(L2-1)]
(9)
随后通过扫描数据库,计算支持度得到频繁三项集C3的时间复杂度,可表示为
O(C3Mn)
(10)
而利用三维矩阵的形式得到频繁三项集,只需要按照候选三项集中的各候选项集(i,j,k)逐一读取矩阵中对应坐标的支持度,即可得到频繁三项集。其时间复杂度可表示为
O(C3)
(11)
则计算频繁三项集的过程,基于三维矩阵的数据挖掘算法可以节省的时间为式(9)+式(10)-式(11),可表示为
O{L2(L2-1)+C3[(MN)-1]}
(12)
显然式(12)远大于0,且节省的时间与M、n、L2和C3有关。在进行较大数据集的关联规则挖掘时能够节省大量的计算时间。在进行后续计算前,会删去属性数量小于4的事务。因此在每次扫描数据库的时候,能够减少的最大时间复杂度为
O(bM3)
(13)
能够减少的最小时间复杂度为
O(bM)
(14)
对比分析可知,改进后的算法较传统的Apriori算法降低了时间复杂度,提高了计算的效率。
3 配电网设备退役因素挖掘
3.1 配电网设备退役信息采集
期望挖掘配电网设备与外部自然环境因素之间的关联性,需要在温度、湿度、气压、风力、沙暴等环境因素具有鲜明特色的地域进行分析。因此选取具有地域特色的3个典型城市的配电网设备数据(表3),按照1.2节提出的预处理方法进行处理。

表3 配电网设备地域信息
3.2 配电网设备退役主要因素
为了准确挖掘出外部因素对配电网设备的影响,分析时使用相同的设备类型,以三地提供的变压器设备退役数据为例进行关联规则挖掘。各地域均选取400条变压器退役信息进行数据挖掘。设最小支持度Smin=0.1和最小置信度Cmin=0.5。从计算出的关联规则中筛选出具有分析价值的部分关联规则进行分析。
喀什地区部分关联规则如表4所示,可以看出:喀什地区较常发生强风和沙尘暴天气,两者共同对当地的变压器退役产生影响。其中强风天气发生的概率更高,对设备的影响也较大,是当地变压器提前退役的主要因素。沙尘暴发生概率较低,属于次要因素。

表4 喀什地区部分关联规则
拉萨地区部分关联规则如表5所示,可以得到结论:拉萨地区对变压器提前退役产生影响的主要是低温和高海拔因素,强风是次要因素。低温和高海拔的关系较为紧密,同时高海拔也带来了低气压的因素,共同影响变压器设备提前退役。
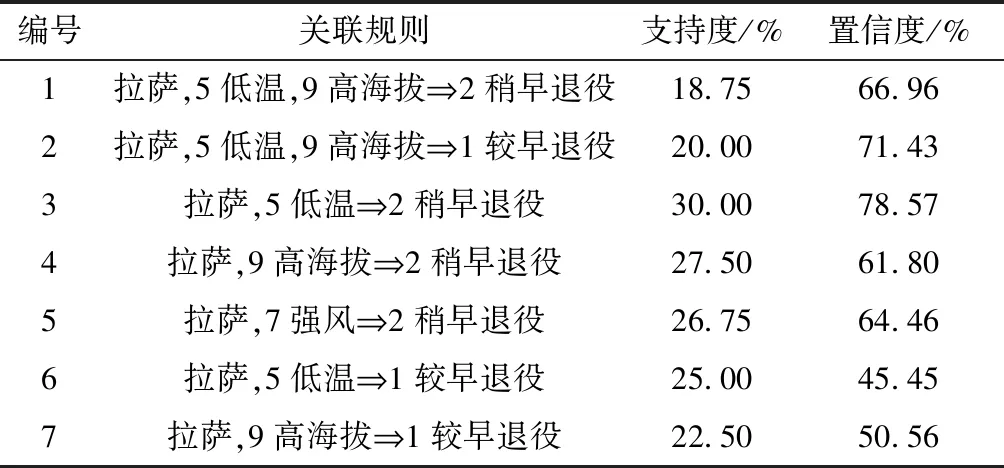
表5 拉萨地区部分关联规则
广州地区部分关联规则如表6所示,可以得到结论:广州地区对变压器提前退役的主要因素有高温、过湿和强风。其中高温与过湿因素联系较为紧密,可以猜测雨热同期可能会加速设备腐蚀。高温与强风因素联系紧密,且强风更易导致设备较早退役,可以猜测强风天气对设备影响更大。
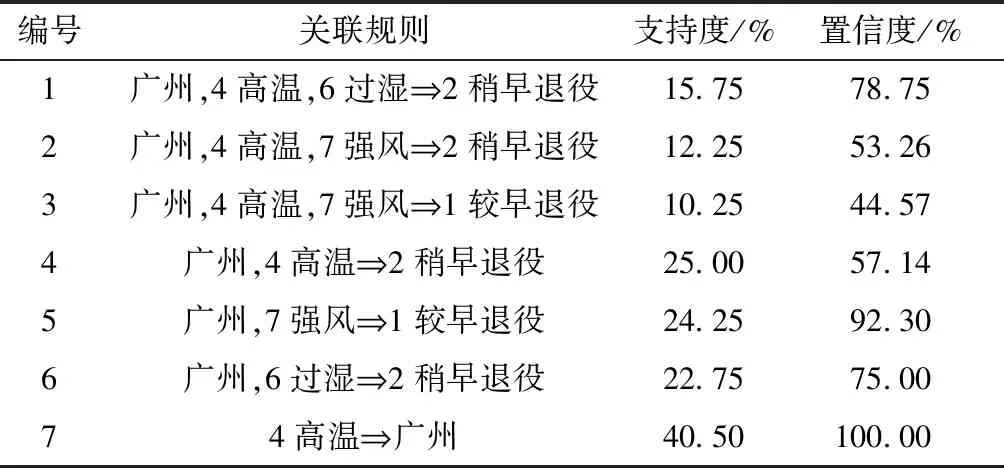
表6 广州地区部分关联规则
3.3 配电网设备退役信息挖掘效率分析
使用基于三维矩阵的数据挖掘算法对配电网设备退役数据进行计算,并在相同的最小支持度和最小置信度条件下与传统的Apriori算法以及文献[17]中提出的压缩矩阵算法进行比对。3种算法的运行时间对比如图2所示。
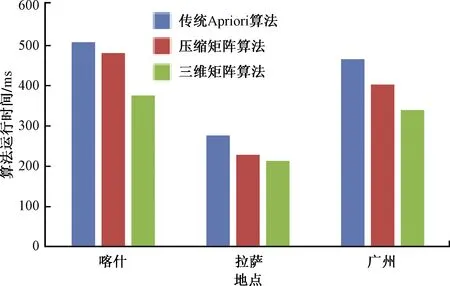
图2 算法运行时间对比
通过比较发现,利用三维矩阵算法在运行时间上有明显的优势。另外地,通过比较传统Apriori算法与三维矩阵算法运行时间来得出优化效率。优化效率η的计算公式为
(15)
式(15)中:t1为传统的Apriori算法运行时间;t2为改进算法运行时间。
比较结果如表7所示,可以看出,相较于传统算法,基于三维矩阵的数据挖掘算法在关联规则挖掘的效率上有明显的优化,各地区数据的优化效率平均能达到24.95%。
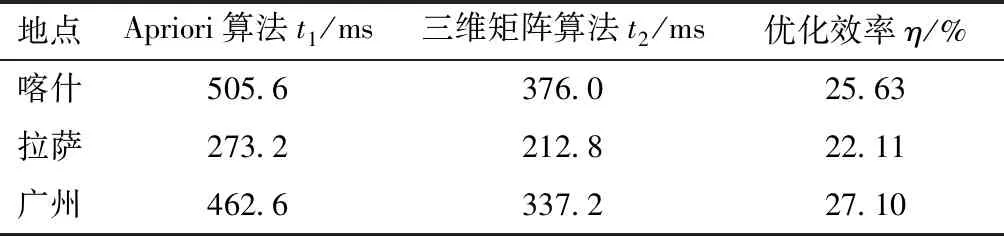
表7 配电网设备退役信息效率分析
4 结论
对传统的Apriori算法进行改进,并针对3个地区的变压器设备进行数据挖掘,对挖掘结果以及计算效率进行分析,得出如下结论。
(1)提出的一种利用三维矩阵的数据挖掘算法,改善了传统Apriori算法计算时间复杂度过大的不足,并验证了计算效率的提高。
(2)通过算例进行关联规则的挖掘,使用本文算法得到了外部自然因素与配电网设备寿命之间的关联性。证明该算法能够应用于配电网设备退役信息的挖掘。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
经济技术协作信息(2018年32期)2018-11-30 01:43:16
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
电力与能源(2017年6期)2017-05-14 06:19:37
电测与仪表(2016年5期)2016-04-22 01:14:14
火控雷达技术(2016年3期)2016-02-06 02:30:28
河南电力(2016年5期)2016-02-06 02:11:24
信息通信技术(2015年6期)2015-12-26 01:16:46
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01 02:54:43
