
基于Anchor上下文辅助的教室场景人群计数研究
2021-09-10 06:57李小兵和圆圆尹衍伟
重庆科技学院学报(自然科学版) 2021年4期
雷 亮 李小兵 和圆圆 尹衍伟 龚 宇
(重庆科技学院 智能技术与工程学院, 重庆 400000)
人群计数是人群分析算法研究的重点内容之一。在智慧校园管理中,可应用人群计数算法实时获取教室中的人数及人群流动状态,从而实现动态分析及优化管理[1]。
在人群计数问题上,曾出现过很多算法。2008年,卢湖川等人曾提出利用帧间差直方图检测人体的方法及稀疏人群计数算法[2]。2012年,针对高密度人群计数问题,梁荣华等人提出了基于SURF(speeded up robust features)的计数方法,检测运动人群的SURF,将其作为主要维度构建人群特征向量,学习人群特征向量以获得人群评价函数,最后通过评价函数实现人群计数[3]。2013,覃勋辉等人提出一种基于支持向量回归机的人群计数算法,以图像中人的高度为基准将图像分成多个图像块,向SVR模型输入图像特征以估算图像块中的人数[4]。2016年,周成博等人提出结合像素特征和纹理特征的人群计数方法,获取像素特征后对传统的灰度并发矩阵进行改进,最后通过回归模型估计人数[5]。2017年,袁烨等人针对人群计数和密度检测问题提出了一种分块多列卷积神经网络构架[6]。他们将待检测的图像分为3部分进行训练,在获取了3个模型之后分别进行预测,由预测结果之和得到人数预测结果。然而,这些算法并不能完全有效地解决教室场景内的人群计数问题,应用场景单一、检测精度低,且面对高密度人群检测时误检率较高。
针对教室场景的人群计数问题,我们避开传统算法对人脸先验知识过度依赖的局限性,研究基于Anchor的上下文辅助[8]人脸检测算法的应用。
1 基于Anchor的上下文辅助检测算法
PyramidBox是基于SSD[9]的One-Stage检测器,它从Wider Face验证集和测试集的困难子集中分别获得了高达88.9%和88.7%的mAP(平均精确度)。PyramidBox模型中,是基于Anchor的上下文辅助方法来监督学习小的、模糊的、部分隐藏的人脸特征信息[8]。对于常用人脸检测基准 —— FDDB[10]和Wider Face[11],Pyramidbox模型的表现优异,能够可靠地检测出不受约束的面部信息。将基于Anchor的上下文辅助检测算法应用于教室场景人群计数问题中,能够解决教室场景下学生人数众多、行为不受控制、场景受限等情况下的人脸检测问题,特别是小尺寸和相互遮挡的人脸检测问题。
2 教室人群计数的检测模型搭建
PyramidBox以基于VGG-16[12]的S3FD[13]模型为基础网络,基于Anchor的环境信息支持方法“Pyramid Anchor”,以引入监督的信息来学习小尺寸、模糊、部分隐藏的面部环境特征。其人群统计检测的实现原理如图1所示。
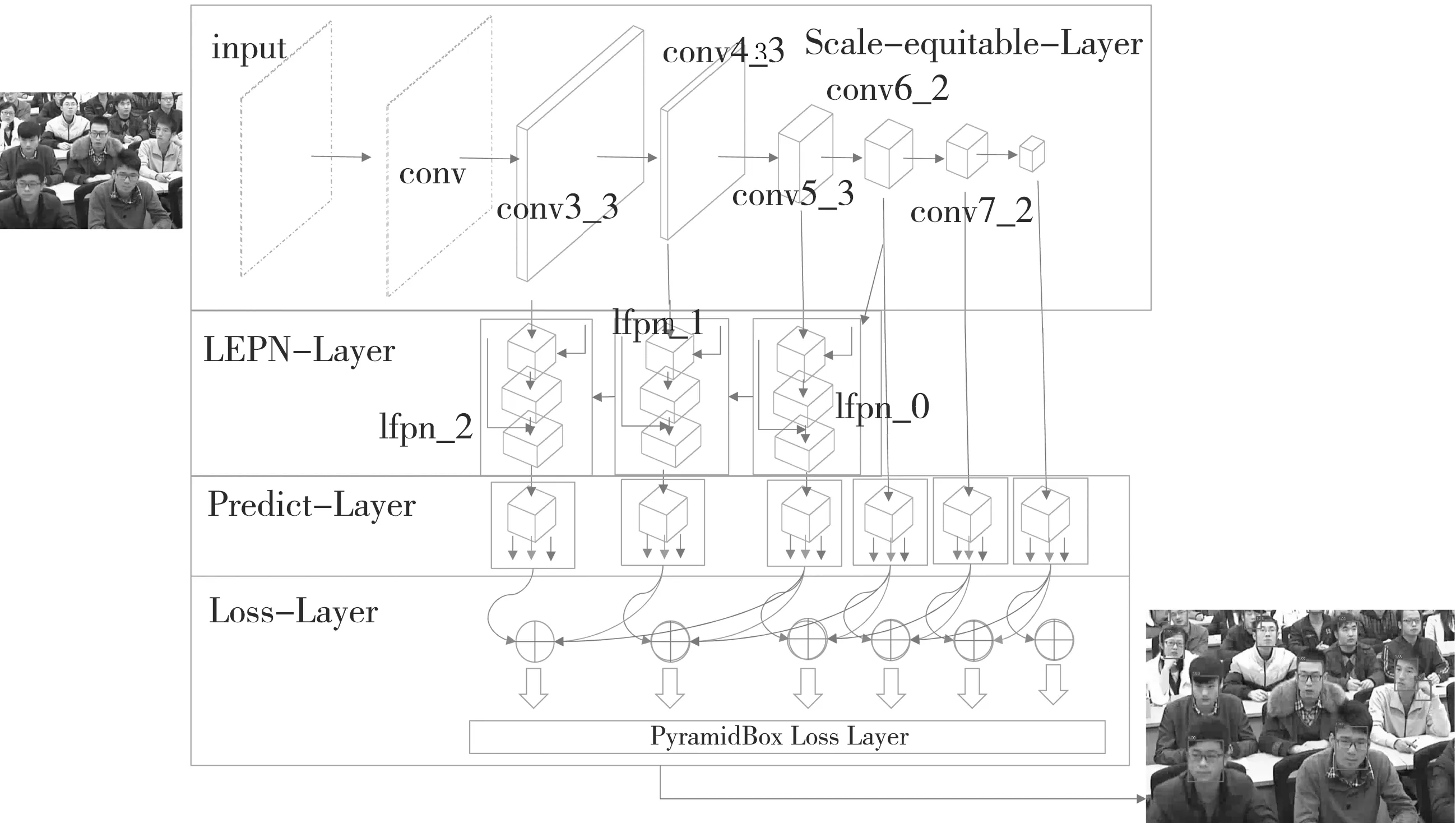
图1 PyramidBox人群统计检测实现原理
利用Netron模型结构可视化工具,使实验中模型的搭建过程可视化。首先,搭建尺度合理的Scale-Equitable 主干网络层,以基础卷积层和额外卷积层作为主干层。其次,基础卷积层将VGG16主干特征提取层保留下来,额外卷积层转换了VGG16的全连接层,最后添加卷积层加深网络。主干网络搭建可视化结果如图2所示。

图2 主干网络搭建可视化结果
低层特征金字塔层从中间层做自上而下融合,并且感受野达到输入大小的一半。此外,每个LFPN模块的结构与FPN[14]相同。金字塔检测层,选择LFPN中的子层和卷积层作为检测层。其中,子LFPN层分别是基于卷积层的 LFPN输出层。此外,与其他 SSD 类型一样,L2正则化也用于重新调整LFPN 层。
对于预测层,其每个检测层后均有一个上下文敏感预测模块,用来输出及监督PyramidAnchors。实验中,人群的面部、头部、身体部位被粗略覆盖。多通道输出功能用于面部、头部和身体的分类和回归。其中,面部的分类需要4个通道,作为前景和背景的max-in-out输出。另外,头和身体的分类需要2个通道,脸、头和身体分别排列在4个通道中,用式(1)表示。
(1)
式中:cl为通道数;l为所在特征层数。
损失层为每个人脸检测目标提供了一系列的 Pyramid Anchors,可同时监督分类和回归任务。所设计的PyramidBox Loss通过SoftMax损失进行分类,通过平滑损失函数进行回归[8]。
通过对PyramidBox人脸检测算法的复现,加载vgg16_reducedfc预训练权重,并采用Pytorch在Wider Face数据集中训练PyramidBox模型。其主要超参数设置如表1所示,实验所得Wider Face中的mAP参数如表2所示。

表1 主要超参数设置

表2 文献[8]与算法复现的mAP参数对比
通过实验算法复现得到的PyramidBox算法结果与原论文的算法结果相近。因此,复现的PyramidBox网络模型可用于验证教室场景人群计数的可行性。考虑到Wider Face 数据集中并没有国内高校教室场景的样本,所以为了提高实验效果,对其作了一些改进[15]。
3 Wider Face 数据集的改进
作为人脸目标检测的基准数据集,Wider Face数据集包含了32 203幅图像、393 703张人脸的信息样本,这些样本在很大范围内涵盖了人脸的各种变化。选择了公开数据集Wider中的61类样本,随机选择每个类别的40%、10%、50%分别作为训练集、验证集和测试集。增加教室场景类别的样本,使检测算法特征提取层对该场景更加敏感,从而得到更为精准的检测模型。
3.1 样本收集
为了提高教室场景人脸检测的准确度,对Wider Face数据集进行扩充,选取了某高校教室视频监控图像及互联网上符合条件的图像。为了提高检测器在不同环境、不同人数条件下的检测能力,选用了多张不同时间、不同光照和不同人数的监控视频截图及图像(见图3)。通过对权威数据集Wider Face的扩充,使实验训练的模型更具有针对性,教室场景中人群数量的检则结果更加准确。

图3 不同的教室场景样本
3.2 原始数据预处理
采用软件LabelImg对收集到的图片进行标注,产生xml 文件,其中包含目标分类名称及目标所在位置的坐标信息,最后将图像和xml文件中的图像标注信息添加到Wider Face数据集文件中。采用多种方法增强数据的鲁棒性,设置随机参数调整原始图像的亮度、对比度和饱和度,以应对光照及其他不友好因素带来的影响。训练样本及标注后的训练样本如图4所示。最终得到扩充后的实验数据集,其中包含9 226个训练样本、3 954个测试样本和3 400幅验证图片。各数据集中的数据均不重复。

图4 训练样本的标注
4 模型训练
采用基于Pytorch深度学习框架的PyramidBox模型进行训练和测试。Anchor参数值设置为16、32、64、128、256、512,主要超参数设置同复现PyramidBox算法相同。采用vgg16_reducedfc预训练权重,并通过数据增强扩充后得到含9 226幅图像的训练集,然后进行模型训练。训练步骤如下:
(1) 根据损失函数计算预测框的误差。模型如下:
(2)

(3)
式中:L—— 损失函数;
Lk,cls—— 2个类别的对数损失函数;
Lk,reg—— 平滑L1损失函数;
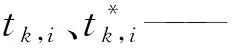
Nk,cls、Nk,reg—— 归一化Lk,cls和Lk,reg,通过λ和λk进行平衡;
k—— 目标人体的部位,可取0、1、2;
Pk,i—— 第i个Anchor第k个目标的概率;
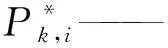
(4)
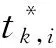

(5)
式中:δx,k、δy,k—— 基于二分类的对数损失,下标x表示输入样本,y表示真实分类;sw,k—— 宽度的缩放因子;sh,k—— 高度的缩放因子。
当k<2时,δx,k=δy,k=0,sw,k=sh,k=1;
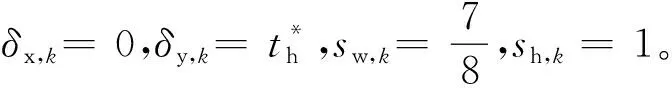
(2) 根据预测值与真实值的误差,计算网络模型中每个参数的梯度。
(3) 通过基于梯度和动量的随机梯度下降法(SGD)更新权重。
在训练过程中保存模型,训练结束后选出最优的教室场景人脸检测器。
5 实验结果
为了获得可以反映整体性能的各项指标,实验中以mAP参数作为模型的评价标准。选择mAP是因为与解决precision、recall、f-measure的单点值局限性有关。
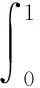
(6)
式中:p—— 准确率;r—— 召回率。
以FP表示负样本,TP表示正样本,GT表示正确标注,确立以下关系式:

(7)
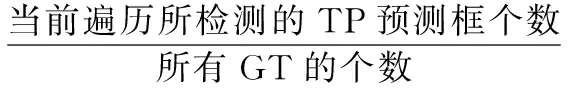
(8)
当完成网络模型训练后,得到教室人数检测模型。将教室监控的帧数据输入模型中,即可完成对教室人数的检测,结果如图5所示。针对PyramidBox扩充后的数据集,将其中3个不同难度子数据集中的mAP参数与文献[8]进行对比(见表3)。

图5 数据集改进后检测效果

表3 文献[8]与本次实验检验的mAP参数对比
可以看到,本次实验所得的mAP参数分别可达到0.912、0.890、0.800,与文献[8]的结果接近。从图5也可以看出,检测模型对一些存在人脸过小、光照影响、遮挡问题的目标也能进行有效检测。在实际应用中,本模型可以准确检测教室人群数量,满足实验需求。
6 结 语
传统的人群计数算法往往检测精度低,不能够有效处理一些不友好因素,使用场景单一。针对教室场景下的样本检测问题,提出一种新的方法 —— 基于Anchor上下文辅助的人脸检测方法。应用此方法,可有效地检测出复杂环境下的人脸,实现基于教室场景的实时检测与人群计数功能。在实验中,通过改进原始数据集,对检测模型进行再训练,最后得到适用于教室场景下的检测模型。实验结果表明,本算法准确、可靠,基本能够满足教室场景的人群计数精度需求。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
恋爱婚姻家庭(2020年27期)2020-10-09
小学生学习指导(低年级)(2020年4期)2020-06-02
数学大王·低年级(2019年8期)2019-08-27
百花洲(2018年1期)2018-02-07
智富时代(2018年12期)2018-01-12
智富时代(2018年12期)2018-01-12
瞭望东方周刊(2017年45期)2017-12-08
