
基于熵的机器翻译伪并行语料库选择方法
2021-09-09 08:20:06刘婉月艾山吾买尔敖乃翔郭锐
现代计算机 2021年19期
刘婉月,艾山·吾买尔,敖乃翔,郭锐
(1.新疆大学信息科学与工程学院,乌鲁木齐 830046;2. 新疆大学新疆多语种信息技术实验室,乌鲁木齐 830046;3. 中国电子科技集团公司电子科学研究院,北京 1000414. 新疆联海创智信息科技有限公司,乌鲁木齐 830010)
0 引言
由于缺乏大规模并行语料使NMT模型无法达到所需的性能[1],导致低资源语言的机器翻译任务困难重重。为了解决这个问题,出现了许多创新技术。迄今为止,最成功的方法是Sennrich等人的方法[2],通过反向翻译将单语目标文本转换为伪造并行数据。此后,该技术已在许多后续研究中被证明是有效的,但大多数研究仅使用BT的所有数据来提高NMT模型的质量。在资源匮乏的环境中,低资源下很难训练高性能的反向翻译模型,因此使用全部的BT数据效果并不好[3],合理适当地选择BT数据子集更能有效提高模型的翻译质量。因此,确定最佳质量的BT数据子集是一个值得探索的问题。
1 相关工作
为了解决低资源问题,先前的研究学者们提出了很多不同的方法扩充平行语料。在不修改NMT翻译模型的条件下,通过前向翻译将大量的源端单语数据翻译成目标语言,构造大规模伪造语料库[4-5]。使用目标端单语数据进行平行语料的扩充,置源端为空,单语数据放置在目标端联合真实平行语料训练翻译模型[6]。和前向翻译完全相反,使用目标单语数据反向翻译成源端数据,构造伪造平行语料库[7]。将单语数据同时放置在源端和目标端联合真实平行语料训练模型[7-8]。源端和目标端单语数据同时使用,联合反向翻译和正向翻译扩充平行语料库[9-11],使用单个翻译模型联合源端和目标端单语数据构造伪造语料库[12]。
单纯的使用大量的外部单语数据可以扩充低资源语料库,但是低资源平行语料训练的NMT翻译模型翻译效果不佳,导致伪造的平行语料质量不高,为了解决这个问题,研究学者们又从两个不同的方向提高伪造平行语料的质量:修改翻译模型内部结构,提高翻译模型的翻译能力,使用不同的句子筛选方法,从大量的伪造语料中筛选高质量语料。修改翻译模型内部结构,提出限制采样,非限制采样,重排序等方法使翻译得到的句子质量更高[11];置信度不断评估反向翻译模型的质量,从而提高模型的翻译质量[13];翻译模型禁用目标到源模型的标签平滑以及限制性采样[14]等方法,都能够提高反向翻译的句子的质量。大量的伪造语料中筛选高质量语料,将目标单语翻译成伪造源语言,然后将伪造源语言翻译成伪造目标语言,计算真实目标单语和伪造目标单语的相似度,按照真实句子和伪造句子的相似度进行伪造语料的筛选[15-16],但是这样需要将大量单语数据翻译两次,时间成本比较高。最简单且最通用的做法是用全部的源端单语训练语言模型,然后计算伪造句子的困惑度,将困惑度从小到大排序,将困惑度小的伪造语料筛选出来作为高质量的伪造语料。
提出的方法不同于计算相似度筛选伪造语料,也不同于仅仅使用源端单语数据训练单一语言模型计算困惑度,按困惑度排序的方法。使用基于熵的方法,仅仅将句子翻译一次,使用真实或伪造的双语或单语数据训练单个或多个语言模型,按照不同的困惑度筛选方法,筛选高质量的伪造语料,该方法不但降低了时间成本,而且方法简单易于实现。
2 过滤伪造平行语料
伪造语料作为附加数据,弥补低资源语言对不足的情况。在文中,提出了8种利用语言模型过滤伪造平行语料库的方法,按照不同的语言模型划分为4大类M1,M2,M3,M4。不同的训练数据得到不同的语言模型,使用符号来表示这些训练数据和语言模型。双语用b表示,单语用m表示,源端用s表示,目标端用t表示,伪造数据用p表示,真实数据用r表示,语言模型用LM表示。
M1是用源端真实语料训练语言模型,得到语言模型LM_rbs,对反向翻译伪造的源端数据进行过滤采取四种不同的方式:
M1_a)使用LM_rbs对反向翻译的每一个源端伪造句子计算困惑度,按照困惑度从小到大排序后,按百分比从全部伪造语料中选取困惑度小的伪造数据。
M1_b)使用LM_rbs对真实平行语料中的源端语料计算困惑度,困惑度从小到大排序,最小的20个困惑度求和取平均作为最小困惑度Minppl,最大的20个困惑度求和取平均作为最大困惑度Maxppl,使用LM_rbs计算源端伪造语料的困惑度,将困惑度在在Minppl和Maxppl之间的伪造语料筛选出来。
M1_c)使用LM_rbs对真实平行语料中的源端数据计算困惑度,所有困惑度求和取平均为平均困惑度Avgppl,使用LM_rbs计算源端伪造语料的困惑度,将困惑度小于等于Avgppl的伪造语料筛选出来。
M1_d)考虑到用语言模型计算困惑度时,长句子的困惑度会比短句子的困惑度高,但是短句子的质量不一定比长句子质量好,因此提出按照句子长度进行困惑度选取的方法,使用LM_rbs对反向翻译的每一个源端伪造句子计算困惑度,相同的长度内按照困惑度排序,从每个长度区间内的选取困惑度小的伪造数据。
M2是用源端伪造数据训练语言模型。这种方法和前面提出的M1_a筛选语料的过程完全相同,不同之处是语言模型的训练数据,源端伪造数据训练语言模型是使用反向翻译得到的全部源端伪造数据训练语言模型LM_ps。使用LM_ps对反向翻译的每一个源端伪造句子计算困惑度照困惑度从小到大排序,按百分比从全部伪造语料中选取困惑度小的伪造数据。
M3是用伪造双语语料和真实双语语料分别训练语言模型,联合使用4个不同的语言模型计算源端句子的困惑度。利用真实双语句分别训练语言模型LM_rbs和LM_rbt,从单语数据m中选择长度分布与真实的双语语料库中的目标端句子长度比较接近的单语句子,训练LM_mt模型,将选择的单语数据进行翻译,用翻译得到的源端数据训练语言模型LM_ps。对每个伪造的源端句子按公式(1)(2)计算,λ∈{0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1},λ是插值化超参数,在实验过程中进行调整,确定最好的插值化超参数,最后将ppl按照从小多大排序,按百分比从全部伪造语料中选取困惑度小的伪造数据。
pp1=δ(λ*|LMps-LMrbs|+(1-λ)*|LMmt-LMrbt)
(1)
(2)
M4是用源端伪造数据和源端真实数据分别训练语言模型,联合使用两个不同的语言模型计算源端伪造句子的困惑度,利用真实双语句对中的源端数据训练语言模型LM_rbs,从伪造的全部源端数据中选择和真实源端句子长度接近的句子训练语言模型LM_ps,采取两种不同的方法使用两个语言模型来筛选数据。
M4_a)使用两个语言模型对伪造语料计算ppl并加权求和,按公式(3)计算,LM_pbs权值为α,LM_rbs的权值为β,α ∶β=3 ∶7;4 ∶6;5 ∶5;7 ∶3;6 ∶4,按百分比从全部伪造语料中选取困惑度小的伪造数据。
pp1=α*LMrbs+β*LMpbs
(3)
M4_b)使用两个语言模型对伪造语料按公式(4)(2)计算ppl,λ∈{0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9},λ是插值化超参数,在实验过程中进行调整,确定最好的插值化超参数,按百分比从全部伪造语料中选取困惑度小的伪造数据。
pp1=δ(λ*LMrbs+(1-λ)*LMpbs)
(4)
3 实验和结果
3.1 实验设置
使用OpenNMT Toolkit[17]训练所有的翻译模型,所有实验使用的参数如下:编码器和解码器的层数为6层,词向量维度为768,隐藏层维度768,多头注意力的头数为8,全连接隐藏层状态4096,句子的最大长度为150,优化器方法是Adam,Label smoothing=0.1,学习率衰减方法为noam,最大训练批次为4096。
使用moses中的multi-bleu.perl计算bleu值。维汉翻译模型中,维吾尔语使用bpe进行切分,合并24k次,汉语按字切分,反向翻译模型中维语和汉语均使用bpe切分,合并24k次。古吉拉特语和英语分别合并10k次,实验中的基线系统是用低资源平行语料和反向翻译得到的伪造平行语料共同训练的翻译模型。
3.2 实验数据
用维语-汉语语言对进行深入的实验,用古吉拉特语-英语对最好的筛选方法进行验证。其中维-汉双语平行语料来自2019 CWMT和新疆大学多语种实验室小组自建的98万句对维吾尔语-汉语数据集,2019 CCMT中的验证集作为实验的验证数据集,汉语单语数据也来自2019CWMT。古吉拉特语-英语数据集来自WMT19,验证集为newdev2019,测试集为newtest2019,单语英语来自WMT19的news crawl数据集,从中筛选100万作为单语语料。如表1所示为实验数据集的数据量。
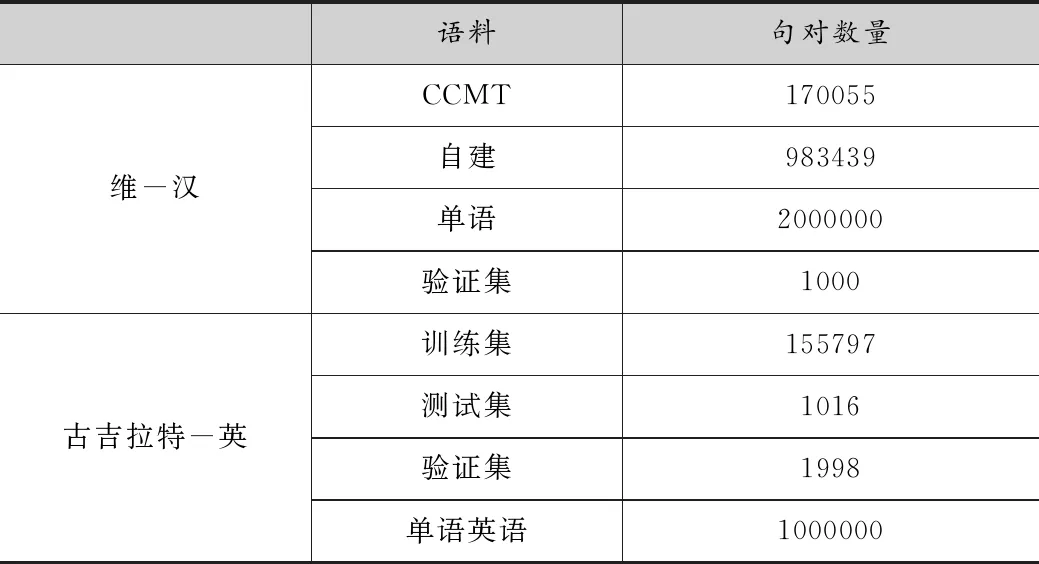
表1 数据统计
17万维汉句对的预处理包括编码转换、全角半角转换、乱码过滤、分词、BPE切分。具体操作为利用新疆大学多语种实验室研发的编码转换工具对维汉语料进行编码转换;利用开源的哈尔滨工业大学中文NLP工具LTP对中文语料进行分词处理;用自主研发的维语分词工具对维语语料分词处理;用subword-nmt开源工具对维汉语料bpe切分处理。CWMT2019的700万汉语进行初步筛选,首先将700万汉语反向翻译成维吾尔语,同时将维汉双语中句子长度小于5大于140的句对删除。计算17万数据和700万数据的单词频率,每行句子中单词频率之和除以句子长度作为相似度标准,将700万数据中与17万数据相似程度高的数据筛选出来,最后得到478万数据。从478万数据中随机选择200万汉语作为单语数据。
古吉拉特语-英语数据集中古吉拉特语和[18]使用相同的预处理方式,使用Indic NLP Library工具切分,moses中的tokenizer.perl和truecase.perl对英语预处理。单语英语使用nltk切分句子最后得到的句子个数44001362,平行语料中英语的句长在2-81,英语单语数据从大量单语中随机选择在句长范围内的句子,选取100万作为单语数据。
3.3 统计语言模型筛选句子
维汉翻译实验使用两种不同的单语数据,分别为新疆大学多语种实验室小组自建的98万句对中的汉语作为单语数据和从CWMT2019单语汉语中筛选出来的200万汉语。使用kenlm训练3-Gram统计语言模型,分别对92万和200万翻译的维语进行筛选。
3.3.1 筛选92万数据
实验中采用了8种不同的方法训练语言模型,计算反向翻译的伪造语料的困惑度,如表2所示。
M1_a,M1_b,M1_c,M1_d使用相同的语言模型用不同的方法对伪造维语进行筛选,其中M1_a的结果最高,比baseline高了0.53个bleu值。M1_b和M1_d方法模型效果比baseline要低,说明这两种方法并不能筛选出质量高的伪造语料。M3方法提高了0.43个bleu值,剩余的几种方法均有0.5个bleu以上的提高,在8种不同的方法中,M4_a方法训练的模型质量最好为41.94,比baseline提高了0.93个bleu值,说明这种方法筛选的伪造语料质量最好。除此以外,由于自建的98万语料中汉语存在与之平行的维语数据,98万真实语料同17万语料联合训练模型的bleu值为42.03,和M4_a相比仅仅高了0.09个bleu值,由此可见,使用M4_a筛选的伪造语料质量相对较高。
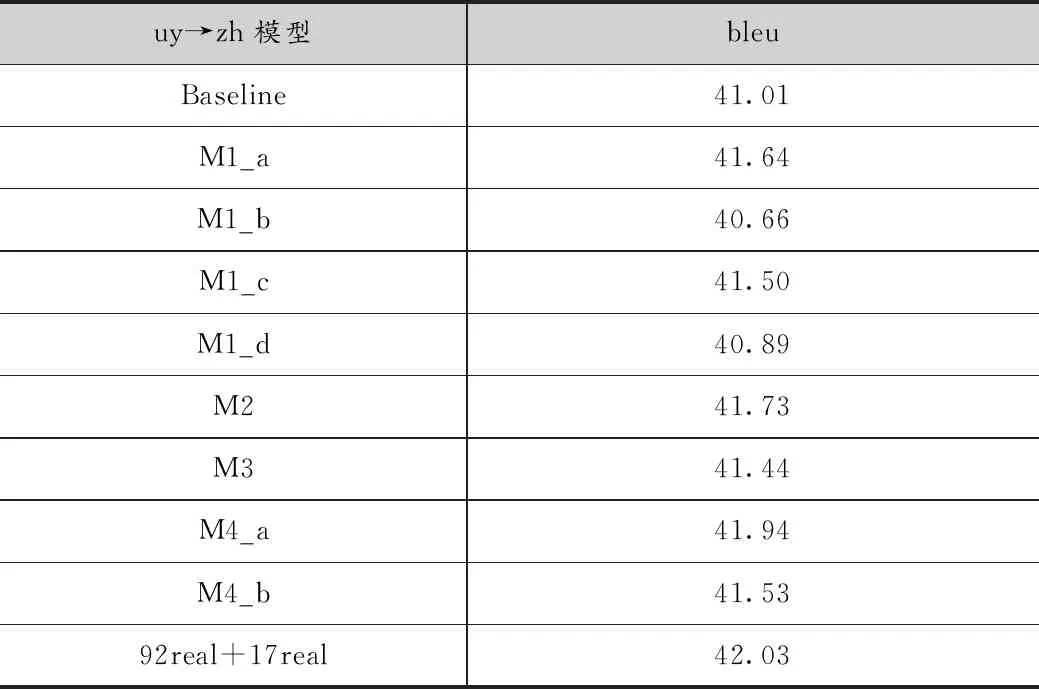
表2 维-汉模型实验结果
使用语言模型计算伪造语料的困惑度,将伪造句子按困惑度从小到大排序,按照百分比从伪造语料中筛选出高质量的伪造语料,如表3所示,M1_a的实验结果显示,当伪造语料取值大于top30时,模型的质量开始高于baseline,当取92万数据的top70时,模型的质量最好,bleu值为41.64。除此之外,在表3中可以看到,top10-top70随着伪造数据的增加,模型的质量也随之升高,但是top80之后模型质量下降,因为过多的伪造数据会引入过多的噪声,从而降低模型的翻译质量。

表3 M1_a实验结果
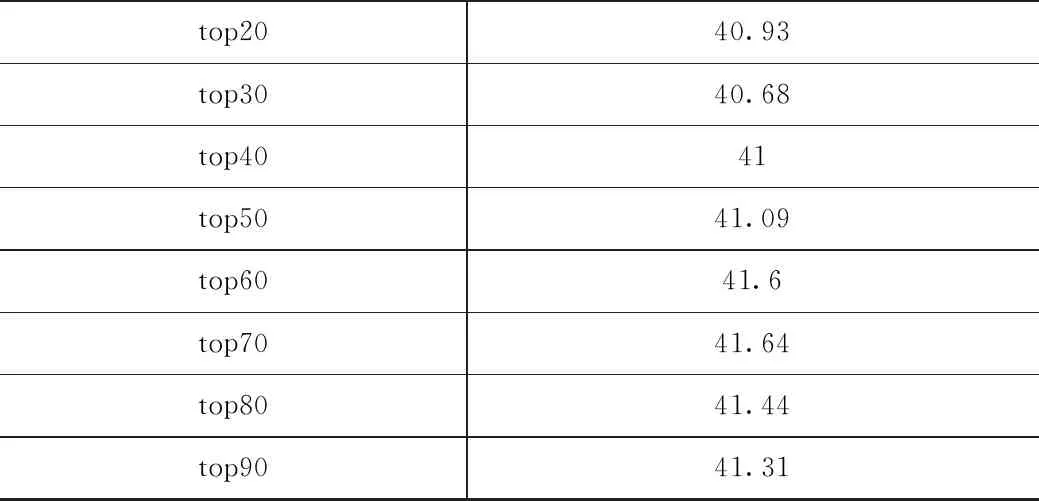
续上表
3.3.2 筛选200万数据
由于98万数据是平行语料,实验中有真实的语料作对比,最终确定使用两种语言模型联合计算句子的困惑度,能够筛选出质量较好的伪造语料。接下来,扩大单语数据的规模,使用200万汉语作为反向翻译的目标单语数据,构造伪造语料库,使用M4_a的方法对伪造语料进行筛选,实验结果如表4所示。权重比为3 ∶7时,取top50的伪造数据翻译模型达到了最好的效果bleu为43.23,baseline高出了1.25个bleu值。
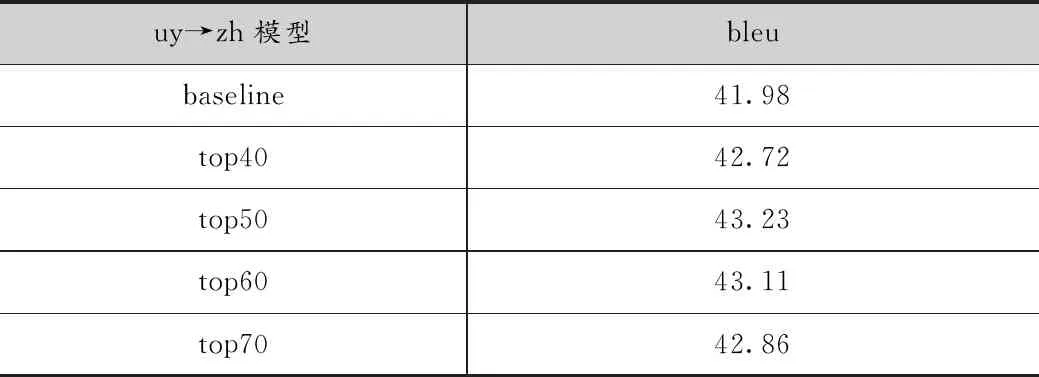
表4 200万M4_a结果
3.3.3 古吉拉特语-英语验证实验
取100万数据的top90会得到最好的模型,因此下面所有的实验都是取的top90的数据。表5所示,M4_a方法进行的实验,伪造古吉拉特语和真实古吉拉特语分别训练语言模型,联合使用两个不同的语言模型计算伪造古吉拉特语句子的困惑度,按公式(3)计算,LM_ps权值为α,LM_rbs的权值为β,α ∶β=1 ∶9;2 ∶8;3 ∶7;4 ∶6;5 ∶5;6 ∶4;7 ∶3;8 ∶2;9 ∶1,按top90从全部伪造语料中选取困惑度小的伪造数据,实验结果表明α ∶β=2 ∶8时比baseline结果高了1.06个bleu值,除此之外,随着LM_ps权值的增大,模型的效果先提高后降低,选取的伪造数据质量先越来越好随后质量越来越坏。
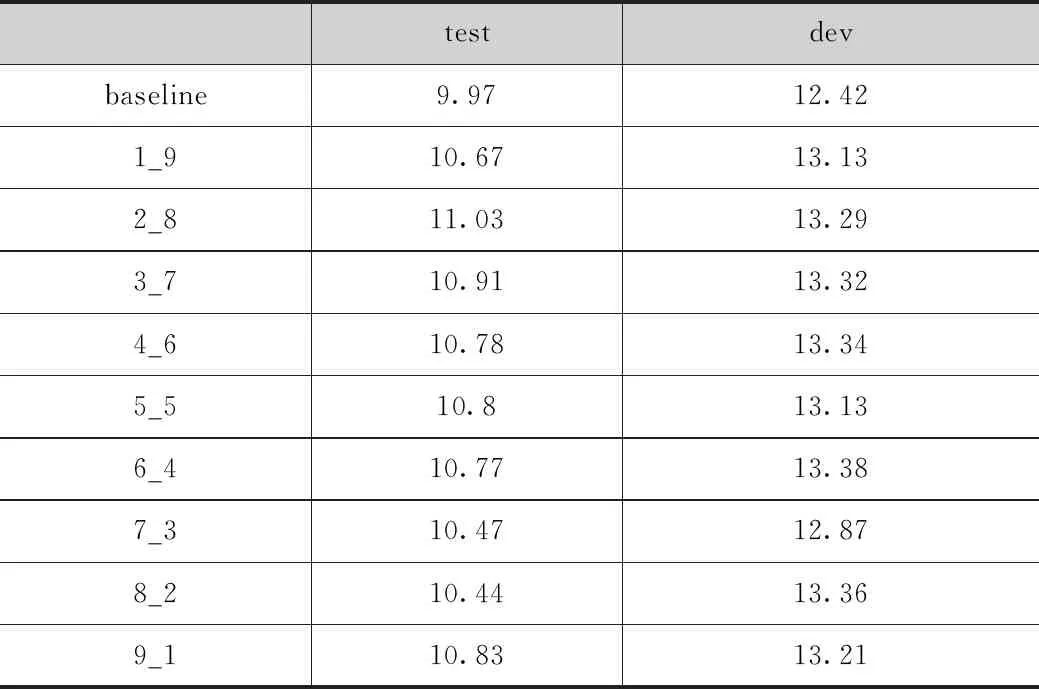
表5 古吉拉特语-英语验证实验结果
3.3.4 对比语言模型
本小节对比了4种不同的语言模型,包括统计语言模型kenlm、预训练语言模型bert、highway语言模型、rnnlm。在维汉语料上做实验,四个实验使用相同的数据训练语言模型,相同的方法筛选合成的维语句子,其中使用M4_a方法获取训练数据、训练语言模型并进行语料筛选。实验中使用200万汉语作为单语数据。由于不存在已经训练好的维语bert语言模型,所以维语的bert语言模型是重新训练的。
统计语言模型使用M4_a的方法筛选伪造语料的实验,前期实验中,当取top50的数据时,模型的质量最好,因此在对比实验中,每种不同的比例均取top50的数据进行实验,实验结果如表6所示。统计语言模型中最好的结果为43.21,bert语言模型最好的结果42.82,highway语言模型最好的结果是42.81,rnnlm最好的结果是43.11。使用统计语言模型筛选的伪造语料训练的翻译模型的bleu值相对更高,翻译模型的质量更好。Bert语言模型产生这种结果的原因可能是因为维语bert语言模型是从头开始重新训练的,但是bert语言模型需要大规模的训练语料,维语bert训练数据较少,训练完成的语言模型计算句子困惑度准确度不高,造成筛选的伪造语料质量较低,训练的翻译模型质量不好。Highway语言模型的网络结构相对简单,训练的语言模型相对于其他三个语言模型质量最不好。rnnlm选择的数据质量相对高一些,但是仍没有统计语言模型筛选的数据质量好。
这四种不同的语言模型中,从3个不同的方面进行对比。第一方面,语言模型的训练时间,bert语言模型和rnnlm语言模型训练的时间相对较长;highway语言模型的训练时间短,统计语言模型训练的时间最短,很快完成。第二方面:计算单语数据的困惑度时间,bert、rnnlm、highway都需要较长的时间,其中bert花费的时间最长,200万句子需要花费几天完成,而统计语言模型只需要几分钟就可以完成。第三方面:训练的语言模型的质量方面,通过筛选伪造数据进行机器翻译的bleu值来判断语言模型的好坏。由于在低资源情况下,维语数据并不多,因此bert语言模型的质量并不高;highway语言模型和bert语言模型质量差不多;rnnlm的质量比前两个要好很多,但是就翻译模型的质量而言,统计语言模型筛选的数据质量要更好一些,也就是统计语言模型的质量要比rnnlm更高一些。
因此,四种不同的语言模型,从三个不同的角度进行比较,无论是模型的训练时间还是计算ppl的时间,或者是模型的质量,统计语言模型都是最好的。
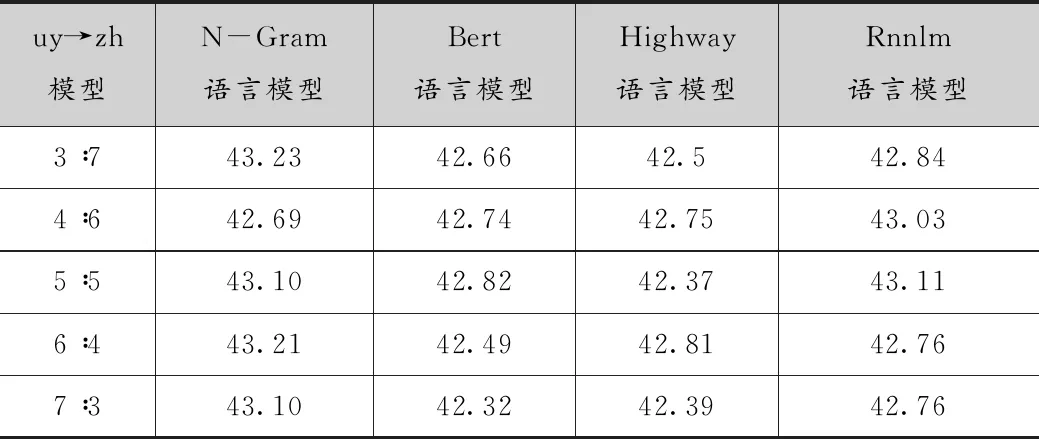
表6 对比实验
4 结果与分析
实验中一共使用了8种不同的方法进行数据筛选,实验结果表明使用单一语言模型,无论是源端真实语料训练的语言模型还是源端合成语料训练的语言模型,他们筛选出的语料都能够提高模型质量,但是筛选的伪造数据质量不是最好的;联合使用这两个语言模型,两种语言模型计算的困惑度加权求和能够筛选出最多的高质量的伪造语料,在98万维汉实验数据上,模型取得了41.94的结果相比baseline提升了0.93个点,和98万真实数据训练的模型相比仅仅低了0.09个点。在200万维汉实验数据上,模型取得了43.23的结果,相比于baseline高出了1.25个点。在古吉拉特语和英语数据集上提高了1.06个bleu。除此之外四种不同的语言模型进行对比,从模型训练时间,困惑度计算时间以及筛选句子的质量三个方面综合考虑,统计语言模型是最好的选择。
5 结语
本文提出了8种不同基于熵的机器翻译伪并行语料库选择方法,不同的方法在相同的数据集上进行实验,对比结果表明,使用源端真实和伪造语料分别训练语言模型,加权求和能够筛选出质量非常好的伪造语料。文中提出的这8种不同的方法都是对反向翻译语料进行处理,并没有对模型进行修改,下一步的工作就是修改反向翻译模型,从模型结构入手,提高反向翻译模型的质量,从根本上提高反向翻译伪造数据的质量。
猜你喜欢
文苑(2020年4期)2020-05-30 12:35:30
中文信息学报(2019年8期)2019-09-05 12:33:36
数码世界(2019年4期)2019-05-10 09:52:54
小学生作文(中高年级适用)(2018年3期)2018-04-18 01:24:47
海外华文教育(2016年1期)2017-01-20 08:21:58
华北电力大学学报(社会科学版)(2016年4期)2016-12-01 03:59:30
科技视界(2016年22期)2016-10-18 15:53:02
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
少儿科学周刊·少年版(2015年4期)2015-07-07 21:11:17
民族古籍研究(2014年0期)2014-10-27 08:24:34
