
基于集聚系数的工作流切片与多云优化调度
2021-09-08 10:44:26王鹏伟雷颖慧赵玉莹章昭辉
同济大学学报(自然科学版) 2021年8期
王鹏伟,雷颖慧,赵玉莹,章昭辉
(东华大学计算机科学与技术学院,上海 201620)
工作流是一组具有依赖性的任务组成的用于完成特定功能的集合。部署在计算机上的工作流,其依赖性通常由数据的传输表示,并且决定了任务的执行顺序。不同的工作流具有不同的拓扑结构,如管道、数据分布和数据聚合,也有不同的资源需求,包括中央处理器(central processing unit,CPU)、内存、输入/出(Input/Output,I/O)等。不同需求所要求的资源类型也不同,在CPU密集的工作流中,任务需要更多的时间来实行计算。在内存密集型的工作流中,任务需要较高的物理内存使用量。而对于I/O密集型工作流,它需要更多的时间执行I/O操作。由于复杂的工作流(如科学工作流)规模大、任务量多、结构复杂,而云计算这种灵活按需的使用模式则很好地为其提供了一种更加高效的运行环境。
云工作流结合了云计算和工作流的诸多特点,是普通工作流往云计算环境下进行迁移所得。云工作流调度是指用户所提交的工作流任务分配到合适的计算资源上执行,并根据资源的使用量即时地支付相应费用。在云计算环境中执行工作流调度时,有两个问题需要考虑,一个是资源的调配,包括确定工作流需要的云资源类型和数量,这意味着需要确定租用多少台实例、它们的类型,以及何时启动,何时关闭等问题。还有一个问题是实际的调度或任务分配阶段,将每个任务都映射到最合适的资源上。在现有的研究中,通常结合了这两个问题一起考虑。
上午快八点的时候,宋市长的秘书以及相关部门的负责人看到宋市长的专车还停在原地,也就不很着急,按惯例或开小车或骑摩托车或骑自行车鱼贯而行,不慌不忙前去镇里开会。哪里料到,一进入会场,宋市长已端坐主席台上,用严厉的目光扫视着每一个人。大家匆忙就坐后,主持人就宣布会议开始了。
随着工作流规模和计算量的不断增长,它们对分布式基础设施的需求也逐渐加大,如何在分布式环境中有效地调度和部署工作流,是一个值得研究的问题。由于能够提供近乎“无限”资源的特性,云计算可以令个人或组织在不需要构建基础设施的前提下,按照需要获取、配置和使用云资源,并按使用进行付费。根据云资源的特性,为了使成本、性能等指标达到最优,需要进行良好的调度和优化,特别是当多个指标需要同时优化时,这个问题变得更具挑战性。
工作流调度,不管在哪种环境下执行,其目的都在于得到一个好的调度方案,将任务和资源做一个映射,保证工作流的成功执行,并优化某些指标。已有的工作流调度相关研究,根据求解方式主要可以分为基于给定约束[1-3]、基于帕累托解[4-6]和基于权重[7-8]的三类方法。这些相关研究大多将单独的任务和云实例匹配起来,一个任务分配到一个实例上,一个实例可能也只被分配到一个任务。而工作流是一个有数据依赖性的结构,这么做忽略了频繁的数据通信可能带来的成本和时间上升,以及故障增加的风险。为此,本文中提出了一种基于集聚系数的工作流切片与多云优化调度框架(clustering coefficient-based workflow fragmentation and scheduling,CWFS)。该框架首先采用聚类的方式将工作流初步切分成若干个子工作流,然后利用集聚系数来优化调整切片结果。在优化调度的过程中,根据云实例的实际情况,利用集聚系数动态地调整工作流切片并完成调度。
1 示例场景与问题提出
工作流由于其任务之间存在数据传输而具有依赖性。在工作流调度过程中,将工作流中的任务和云计算资源匹配,不仅要注意任务本身的执行需求,也要注意任务之间的数据通信带来的消耗。对于一些工作流,尤其是数据通信密集型的工作流来说,频繁或者大量的数据通信都会影响总完工时间和执行成本。此外,如果有频繁数据传输关系的任务或者大数据量的任务部署在不同的云资源上,在数据传输过程中,更容易出现错误,导致发生故障重传的概率更大,容易影响后面的任务执行。
图1展示了一个包含15个任务的工作流,任务之间有数据传输的关系。由于工作流的依赖性,任务要想开始必须等到它的父任务将数据传输完成。以任务7为例,任务7的父任务是任务3和任务4,分别要传输2 000个单位和10个单位的数据。而任务3和任务4有共同的父任务:任务1,其要分别传输1 000单位和30单位的数据给任务3和任务4。那么对于任务7来说,要想开始执行,必须等到任务1执行完毕后传输数据给任务3、4,再等到任务3、4执行完毕后传输数据给任务7。在这个过程中,任务1和任务3、任务3和任务7之间传输的数据量远远大于任务1和任务4、任务4和任务7之间的数据量。这也就意味着,假设任务所在云实例传输带宽相等,任务1执行完毕后,任务3等待数据传输的时间是任务4的33倍。而任务7要想开始,等待任务3传输数据的时间是等待任务4传输时间的200倍。可以看出,有大量的时间被浪费在了等待其中一个父任务传输数据的时间。如果将任务1、任务3、任务7放在同一个云实例上,那么任务7需要的数据传输时间只是任务1到任务4,与任务4到任务7的数据传输时间之和。而此时,一共只有40个单位的数据传输,显然会大大减少数据传输带来的成本和时间消耗。

图1 一个有15个任务的工作流Fig.1 A workflow with 15 tasks
因此,在进行工作流的优化调度时,减少工作流任务在不同资源之间的数据传输来保证完工时间满足截止期约束,以及其他的一些优化目标,是一个值得关注的研究方向。从上述场景中可以看出,需要将工作流切分成若干个子工作流,使得子工作流内数据传输尽量频繁,子工作流之间的数据传输尽量少,即子工作流内聚性强,外联性弱。在已有的研究中,研究者们通常会为每一个任务分配一个独立的云资源,任务在不同云之间频繁的数据通信不利于充分地利用云资源,以及更好地节约成本和时间。
工作流切片要求带来的效果类似于聚类:类内元素相似程度高,类外元素相似程度低。因此可以将工作流切片建模成一个聚类问题,利用任务间的数据量来衡量任务间的关系。另外,如果只考虑工作流切片,那么切片结果有可能超过实际的云实例可用负载。以图1为例,当任务1、3、7被划分为一个子工作流时,可以使其内部数据传输量大,外部少。但是考虑到执行任务的计算需求和云实例的承载能力,如果没有一个合适的云实例能够容纳这个子工作流,那么必须要对它再次进行调整。因此在进行优化调度过程中,依然需要对切片的结果进行动态调整,使得云资源的利用率达到一个合理的范围。
2 用于工作流切片的集聚系数
集聚系数概念诞生于图论,表示一个图中顶点的聚集程度。不同于判断类性能的标准,集聚系数更关注节点间的密度。当节点间关系紧密时,那么它们的集聚系数就会变高。如果一个节点相连的节点之间有关系,表示这个群体相互之间比较紧密,那么也会有一个比较高的集聚系数。集聚系数有局部集聚系数和平均集聚系数,前者给出了单个节点的度量,可以判断图中每个节点附近的集聚程度,后者旨在度量整个图的平均集聚性。在近期研究中,集聚系数被广泛应用于社交网络分析、可视化网络安全分析、小世界网络分析等领域。Murray等[9]引入集聚系数来描述小世界模型。集聚系数可以用于判断聚类的效果,Zhong等[10]使用其来解决词关系的聚类问题。
工作流因为任务间有数据传输的关系,将数据传输量大的任务划分成一个子工作流,这样子工作流之间的数据传输就会减少。因此可以采用聚类的方法进行工作流的切片研究。很多聚类算法都基于一些给定的值来进行聚类,这要求使用者必须拥有该领域的一定先验知识。动态的聚类算法可以根据实际情况来分析模型结构来给出k值,但是缺少一个良好的标准来判断类内元素的整体相似度。为此,引入图论中的集聚系数,来帮助判断子工作流内部和外部的聚集程度。
给定一个工作流的有向无环图模型(direct acyclic graph,DAG)G=(T,E),其中T是n个任务的集合t={t1,t2,…,tn},E是任务之间依赖关系的集合,E={ei,j|i,j=0,1,2,…,m}。依赖关系ei,j表示了任务ti和任务tj的依赖约束,它意味着任务tj必须等到任务ti执行完毕才能开始执行。如果两个任务之间有数据传输的行为,那么认为DAG图中这两个任务之间有一条边。每个任务与其他任务连接的边的集合用N来表示。Ni表示与任务ti连接的边的集合。|Ni|表示集合的度,即边的数量。任务ti的局部集聚系数LCi是它的相邻任务之间的边的数量与它们所有可能存在边的数量的比值。
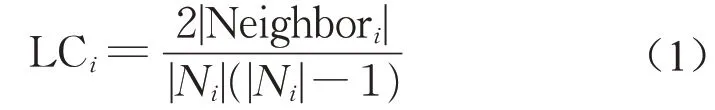
工作流转换成的DAG图是一个有向图,任务间数据的传输可以视为边的权重。权重对于集聚系数的计算影响颇大。不同的权重定义所表示的集聚系数紧密程度也不同。如果权重代表的是距离,那么权重越小顶点间的关系更为紧密;如果权重表示的是关系值,那么权重越大顶点间的关系越紧密。本文中研究的问题,需要将数据量大的任务聚集在一起,因此任务间数据量越大,表示它们越应该聚集在一起,它们的关系应该更紧密。因此,工作流任务的局部集聚系数可以定义为式(2)。
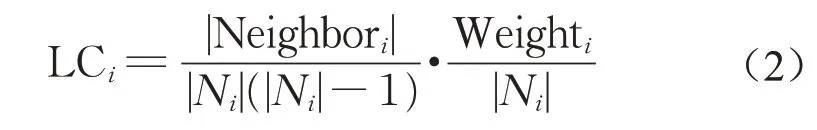
工作流是一个有向图,因此其完全图的边的数量是n×(n-1)。Neighbori和Ni的定义同式(1)中相同,但是这里两个定义都是针对有向图,eA,B≠eB,A。Weighti表 示 集 合Ni中 的 权 重 和,。以图2a中的任务tA为例,与它有边的关系的任务是tB、tD、tE,因此,其度为3。而在三个相连的任务中,只有任务tD、tE之间有边的关系,因此,那么根据式(2),任务tA的局部集聚系数为表 示权重。
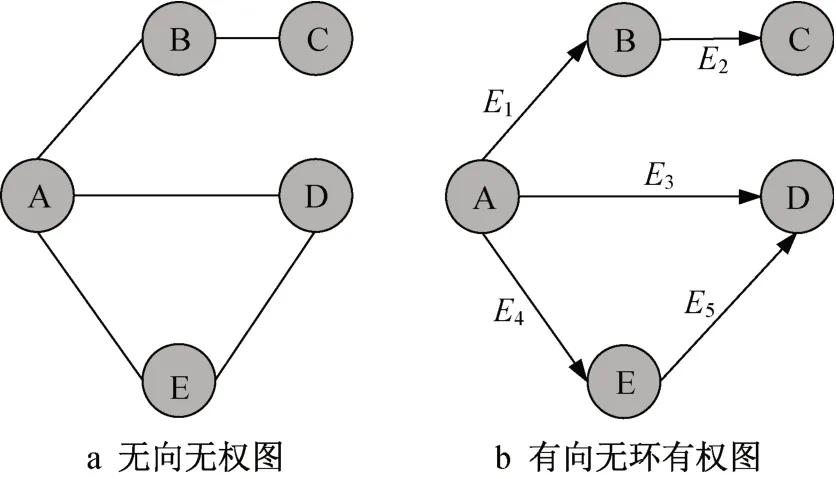
图2 无向无权图和有向无环有权图Fig.2 An undirected unweighted graph and a directed acyclic weighted graph
从式(1)和(2)中可看出,无向无权图的任务局部集聚系数总是在0~1之间。0表示附近任务之间没有抱团的关系,而1表示附近任务之间联系紧密,接近完全图。有向有权图中,当任务与其相邻任务接近完全图,并且任务间的权重趋近于+∞时,任务的局部集聚系数值趋近于+∞。得到任务的局部集聚系数还不足以判断整个图的聚集情况。Watts和Strogatz定义了平均集聚系数[11],通过计算平均值来得到整个图的集聚程度,即
将工作流切成若干个子工作流后,根据子工作流内部任务之间的数据聚集程度和子工作流之间的数据聚集程度判断切片的质量。假设工作流切分后,有 子 工 作 流A,GA={T A,EA}和B,GB={T B,EB}。子工作流A的集聚程度如式(3)所示。其中,ti表示第i个任务,T A表示子工作流A内包含的任务集合,ei,j表示任务ti和tj之间的边,EA表示子工作流A内部包括的边的集合,LCi表示任务ti的局部集聚系数。

3.2.2 切片优化

图3是一个被切分成4个子工作流的工作流。虚线圈起的部分表示被切分的子工作流。虚箭头表示子工作流之间的数据传输,实箭头表示子工作流内部的数据传输。对于子工作流A来说,如果inter(A,B)大于introA,说明子工作流A和子工作流B的类间集聚程度要大于子工作流A的类内集聚程度,将那些与子工作流A有边的关系但是属于子工作流B的任务划分给子工作流A可以提高A的集聚程度。同理,如果inter(B,A)大于introB,则说明把子工作流A中那些与子工作流B有边的关系的任务划分给子工作流B更好。当inter(A,B)≥introA和inter(B,A)≥introB同时成立时,说明子工作流A和子工作流B各自的类内集聚程度都没有它们受另一个子工作流关联的类间集聚程度强,因此将它们合并成一个新子工作流,可以获得更高的集聚程度。同理,如果子工作流A可以被分成A1和A2两个子工作流,且有inter(A1,A2)<introA1和inter(A2,A1)<introA2同时成立。那么说明与子工作流A相比,切分成的两个新子工作流有更高的集聚程度。

图3 一个被切分的工作流Fig.3 A segmented workflow
通过不断地优化调整工作流切片结果,可以保证子工作流内的数据依赖较强,子工作流间的数据依赖程度较弱。
3 工作流切片与优化调度框架
3.1 总体框架
CWFS的目的是通过将工作流切分成若干个子工作流,再使用优化算法为它们找到合适的云实例,在减少数据传输依赖的情况下,找到满足优化目标的调度方案。CWFS包括两个部分:基于集聚系数的工作流切片和基于切片的优化调度。整体框架如图4所示。
基于集聚系数的工作流切片分为两步,首先使用聚类算法,根据任务间的数据通信量对工作流进行一个初步的切片,将通信量较大的任务聚成一个类。得到初步的切片结果后,根据第4节中关于集聚系数的相关定义,以及对切片内部和切片之间紧密度的判断公式,对工作流初步切片结果进行优化调整,使得调整后的子工作流内聚性强,外联性弱,从而得到一个基于集聚系数的工作流切片结果。
在工作流切片过程中,只考虑了任务间的通信情况,而没有考虑实际的云实例承载能力。因此,在基于切片的优化调度过程中,使用启发式算法进行寻优时,根据云实例的实际情况,可能会出现子工作流超过云实例的承载能力或者只占云实例承载能力的一小部分,造成无法找到合适的实例或者造成浪费的现象。因此在工作流优化调度时,需要根据实际情况动态地调整切片结果,使其可以找到合适的调度方案。CWFS框架的输出是一个工作流-云计算资源的调度方案。
3.2 基于集聚系数的工作流切片
3.2.1 初步切片
取消上述两类门诊之后,宁波一院开设全科门诊,增开老年医学科门诊,增加内科专科门诊。同时,医院严格控制门诊慢性药物使用,每人次门诊慢病用药不超7天量,希望引导慢病患者到基层配药。
工作流是一组有依赖关系的任务集合。根据任务之间的数据依赖将工作流切分成若干个子工作流,其过程类似于聚类。本节采用K均值聚类算法(K-means)来进行工作流的初步切片工作,主要包括以下步骤:
其次,对照语料选用的是北语语料。尽管统计分析结果显示文学类与非文学类语料之间在字频和词频方面的异与同,但是,若能选用同时代或不同时代典型作家的语料进行对比,则更能突显鲁迅小说遣词用字的特点。
本桥梁直接横跨某既有高速公路,和高速公路一定角度相交,墩身和高速公路的边坡直相紧挨,场地限制较大,现场施工条件相对较差。除此之外,公路的车流量很大,横跨高速公路进行施工,安全保障难度较大。通过现场考察以后,决定采用龙门吊进行吊装施工。在临时支架进行腹杆拼装后,采用空门吊将其安放在横梁要求的位置。在横梁上,一般设置有调整机构,主要用于线性调整。
(1)导入工作流,并且将它转换成拥有一个虚拟入口任务(tentry)和虚拟结束任务(texit)的DAG图。
为了验证所提方法的有效性,使用真实的工作流Cybershake[13]、Epigenomics和Montage[14]来进行性能评估,实验选用任务数量为100的工作流进行实验。
为了求解式(4)关节速度q′,对非方阵J(q)进行转置.利用权值右侧广义逆矩阵,得到了一个特殊的逆矩阵[7]:
如 果 inter(A,B)≤introA+B成 立,同 时inter(B,A)≤introA+B也成立。那么子工作流A和子工作流B可以合成为一个新的子工作流(A+B)。
(3)遍历工作流的每一个任务,计算它们和聚类中心之间的数据传输量。如果一个任务到每一个聚类中心都没有直接的数据传输,那么通过计算它的父任务们的数据传输情况来判断它们应该属于哪一类,并且将它们分别加入数据量最大的聚类中心所在的类中。
(4)当所有任务都加入到某个类中后,每个类重新计算聚类中心。计算类中每个任务到其他任务的数据量,将最大的那个任务定义为新的聚类中心,一轮迭代结束。
(5)判断新的k个聚类中心和上一轮迭代相比是否有变化,有则跳转步骤(3);若否,则迭代结束,进行步骤(6)。
(6)得到工作流初步切片结果,输出k个子工作流集合。
仅靠子工作流内部的集聚程度无法判断工作流切片的合理性,需要对子工作流之间的集聚程度进行判断。下面定义类间集聚系数[10],公式(4)是对子工作流A而言,其与子工作流B之间的类间集聚系数。inter(A,B)强调的是A受B关联的类间集聚系数。如果是B受A关联的类间集聚系数,那么计算公式变为inter(B,A)。
铁路通信系统中UPS不间断电源原理及使用维护分析……………………………………………………… 崔圣青(4-88)
采用K-means算法进行初步切分时,k值的选择是基于使用者自己的经验和判断,无法证明划分成k个子工作流是合适的。可能某些工作流中有些任务需要被划分出去,而有些子工作流需要合并成一个新的工作流,凭自身经验很难直接判断这一点。为此,优化的工作流切片要求在初步切片后采用合理的方法对初步切片结果进行合理的调整,因此要使用第2节提到的用于工作流切片的集聚系数。如第2节所述,有两个衡量的标准——类间集聚系数和类内集聚系数,可以帮助衡量工作流切片后的结果,判断它们是否需要进一步切分或合并。下面首先给出两个定义。
定义1子工作流分割 :现有子工作流A,如果满足下列条件,那么子工作流A将切分成子工作流A1和子工作流A2。
如果introA<inter(A1,A2)成立,同时introA<inter(A2,A1)也成立。那么子工作流A可以被分割成新的子工作流A1和子工作流A2。
3)基本顶组成及运动特点。由于工作面存在明显的顶板周期来压显现,因此基本顶的周期性断裂是其主要运动特征。工作面基本顶主体岩层为粗砂岩,厚度8 m,周期断裂步距约20 m。
定义2子工作流合并 :现有子工作流A和B,如果两者满足下列条件,那么子工作流A和B将合并成一个新的子工作流(A+B)。
(2)根据实验工作流的大小,指定合适的k值,从工作流的任务集合中,随机选择k个任务作为初始的聚类中心(不包括两个虚拟任务)。
切片优化就是对工作流进行初步切分后,利用定义1和定义2对初步切分后的子工作流集合不断地进行优化调整的过程。迭代的终止条件可以根据设置的标准或者迭代次数来确定。每次迭代分为子工作流分割和子工作流合并两部分操作。首先是对导入的工作流进行一个初始切片的工作,得到初步切分好的子工作流集合后,给每个子工作流添加“0”的标记。
分割操作过程为:依次从未处理的子工作流集合中取出一个子工作流,对其进行预分割操作,预分割即为依次将子工作流分为两份,利用类内集聚系数和类间集聚系数来判断预分割结果是否可行;如果满足定义1,则此次分割操作可以进行,并且将两个新得到的子工作流标记改为“1”;如果不可行则放弃此次分割操作,并且给该子工作流的状态改为“1”;接着继续从标记“0”的工作流中拿出下一个子工作流进行处理。当未处理的子工作流集合为空时,表示这轮迭代的分割操作已经全部结束,进入合并操作。
合并操作过程如下:取出一个标记为“1”的子工作流,计算它的类内集聚系数,以及该工作流和其关联子工作流之间的类间集聚系数,判断它们是否满足定义2;如果满足则对两个子工作流进行合并,并且将合并后的新子工作流的状态变为“2”;依次取集合中的子工作流,直到集合为空;此时迭代中的合并操作也已经完成。如果此轮迭代满足了迭代停止条件,那么将输出一个经过切片优化调整的子工作流集合;如果不满足,则跳转到分割操作继续进行切片工作。
求知欲是儿童思维的原动力。根据儿童的心理特征。教学中,我们更应该创设诱发学习动机的教学情境,把学生的不随意注意吸引到参与学习的兴趣上来,引导他们对数学问题积极思考与探索,从而达到掌握知识、发展智能的目的。
4 基于切片的工作流多云优化调度
为了降低工作流调度过程的数据通信量,减少完工时间,在对工作流进行切片的基础上,本节中给出一种基于切片和基于免疫粒子群优化算法(immune-based particle swarm optimization,IMPSO)[12]的工作流多云优化调度方法。
工作流模型用DAG图表示,其中G=(T,E),T={t1,t2,…,tn}表示工作流任务集合,每个任务的参 数 为 ti=(id,namespace,name,size);其 中namespace为任务所属的工作流名称,name为任务名称,size是任务需要的计算量。边的集合E={ei,j|i,j=0,1,2,…,N}, 其 中ei,j=(orig,dest,data),分别表示父任务、子任务和它们之间传输的数据量。选择的依然是云实例类型,不对更底层的结构进行考虑。云实例instancei=(id,speed,cost,bandwidth,bdprice,type),其 中 ,speed表示云实例计算能力;cost是一个时间单位内的成本;bandwidth为带宽;bdprice为单位传输量的传输价格;type为实例类型。用户将工作流提交到调度器进行处理时,对于切片后的子工作流,调度器将它们调度在同一资源节点上,此时子工作流内部的传输成本和时间均为0。因此子工作流subi的总成本和总完工时间分别为:
两次获得法国摄影联合会组织的“国家自然竞赛”奖,在2002年和2003年的美国摄影协会名人录中位居世界第10位自然类摄影师,1998年被英国皇家摄影学会提名为自然摄影奖,在肖像摄影大师杯2009年业余节中获奖,2011年想像虚拟布宜诺斯艾利斯-阿根廷国际展览中获最佳作者,2011年在法国国际展览中获第二名。
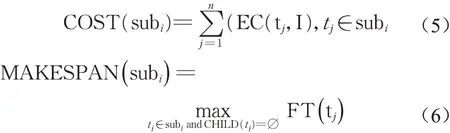
由于不需要计算传输成本,因此子工作流subi的总成本即为各个任务的执行成本的总和。EC(tj,I)是任务在实例上执行的成本;子工作流的完工时间由其内部最后执行的任务的结束时间决定,值得注意的是,子工作流和工作流不同,为了方便计算,通常会在工作流开始和结束的位置分别加一个虚拟的任务,因此工作流的开始和结束任务只有一个。而切片的子工作流可能会有多个可以同时开始的任务和多个结束任务。因此,子工作流的完工时间应是结束时间最晚的那个任务。而公式(6)中的CHILD(tj)=∅指的是在该子工作流内部没有子任务,并不一定在整个工作流中没有子任务。任务的结束时间由公式(7)和(8)决定,同样式(7)中,PRED(ti)=∅指的是任务在子工作流内没有父任务。

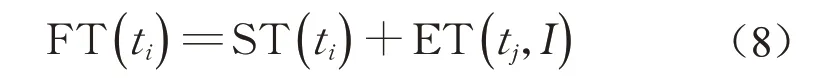
因此,工作流调度的优化目标如下所示:


由此,对于整个工作流W来说,总的成本和时间可以计算得到:

IMPSO方法引入了免疫机制,在粒子寻找全局最优解的过程中,不断地进行免疫操作来加强粒子的寻解能力。关于IMPSO方法的详细介绍可参考文献[12]。将工作流切片结果作为IMPSO的输入时,由于切片过程没有考虑到真实的云实例的承载能力。可能存在切片超过云实例的容量的情况。因此,在使用IMPSO进行优化调度的过程中,依然需要动态地对切片结果进行调整。在寻优过程中,粒子寻找到的解是一个切片-实例关系对,如果切片过大找不到合适的云实例类型,那么根据提出过的抗体和抗原之间的亲和力公式,粒子的某一维和当前最优粒子之间的距离是无穷大的,那么根据公式计算得到的亲和度就会为0;这意味着,该粒子中存在需要分割的工作流切片,即需要调用工作流切片模块来调整。
图5展示了基于切片和IMPSO算法的工作流多云优化调度方法的流程图。对于待执行的工作流进行基于集聚系数的工作流切片后,调用IMPSO算法进行调度。进行粒子的初始化后,计算抗体和抗原间的亲和度。如果切片的大小超过了实际的云实例负载,现有的云实例类型无法为切片找到合适的选择,那么将调用基于集聚系数的切片方法,重新动态地调整切片结果。直到所有切片都能找到合适的实例,重新计算各抗体的亲和度,并且加入免疫操作,包括抗体克隆、抗体变异等。经过若干轮的迭代,直到找到合适的抗体,算法结束。输出为一个优化调度的解决方案。
2010年央行宣布重启人民币汇率形成机制改革后,人民币汇率继续升值,但由于此时我国新增4万亿经济刺激计划的逐步落实,宏观经济增长率并没有出现大幅下滑,但此次经济增长更多依赖于国内投资和内需增加,并引发国内物价的小幅上升;此外,在全球货币贬值背景下人民币币值的坚挺也使我国进出口贸易受到影响。由于后金融危机时期我国经济对世界经济的带动地位,我国外汇储备规模得到了进一步提升。
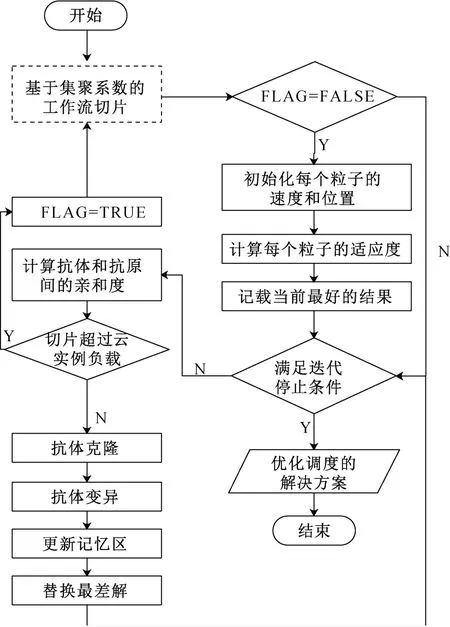
图5 基于切片和IMPSO的工作流多云优化调度Fig.5 Multi-cloud workflow scheduling based on slicing and IMPSO
5 实验与分析
5.1 实验设置
1.2.1 供试材料发芽。按照《农作物种子检验规程》(GB/T 3543.4—1995)要求,从鑫两优212杂交标准种、亲本及纯度待测样品中均随机取200粒种子,均匀置于发芽床上,在温度为30 ℃、光照为750 lx、湿度为75%的条件下发芽3~7 d。
实验中采用真实的亚马逊AWSEC2云计算实例类型参数,如表1所示。设置的时间间隔为1小时。每个云实例的容量设置为100 000单位,负载达到80%即视为负载已满。在实验中,使用属性ECU代表实例的速度。
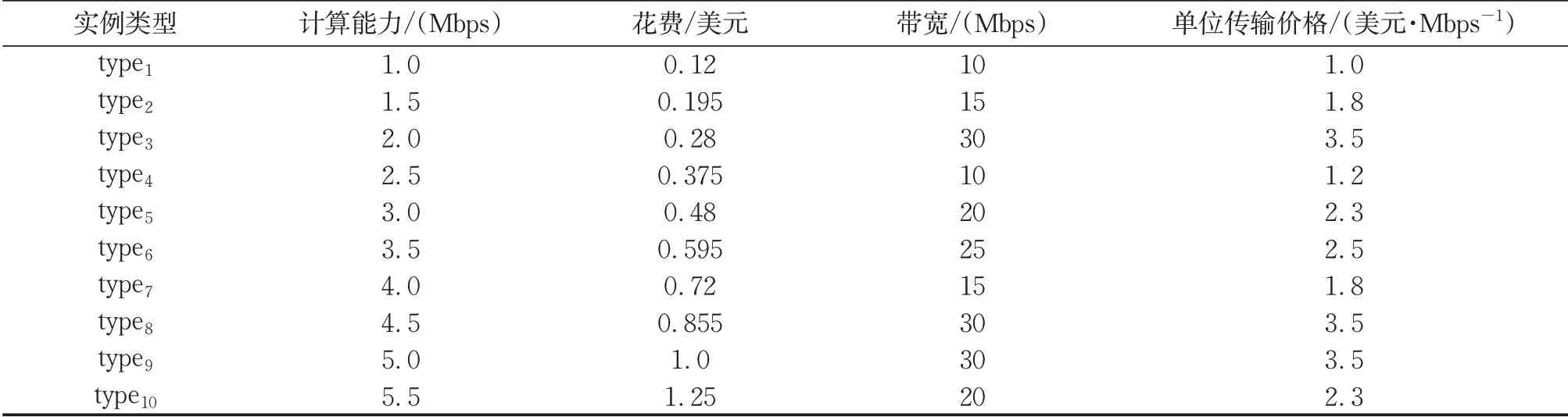
表1 云实例参数Tab.1 Cloud instance parameters
实验环境的配置为:Core(TM)i5 3.40 GHz,16 GB RAM,Windows 10,Java 2 Standard Edition V1.8.0。
5.2 实验结果
本文中提出的CWFS框架与IMPSO结合的方法称为CWFS-IM,将CWFS与遗传算法结合的方法称之为CWFS-GA。下面比较和分析CWFS-IM、CWFS-GA、遗传算法GA、免疫粒子群优化算法IMPSO这4种方法的性能。IMPSO的相关参数设置为:学习因子和PSO中的速度更新的惯性因子设置为:ω=0.5;c1=2;c2=2。种群大小和迭代次数被设置为100。结合免疫机制的研究和实验,与免疫有关的参数机制如下:记忆单元容量为种群的一半,随机生成的新粒子数量设置为种群的1/10。所需的克隆的大小被控制在大约两倍的种群数量。CWFS和遗传算法的种群规模设置为100,迭代次数设置为100,交叉概率Pc和变异概率Pm分别为0.5和0.5。动态切片的k值设置成工作流任务数的1/10。
本文选择了3种真实工作流,分别为Cybershake、Epigenomics和 Montage。 其 中Cybershake是数据密集型工作流,执行时有大量的数据传输工作,该工作流是南加州地震中心用于表征地震灾害的工具;Epigenomics是计算密集型工作流,用于自动执行各种基因组测序操作,相对于计算来说,数据传输不是特别多;Montage用于根据输入的图像来创建天空的工作流,其特点是需要大量的I/O,任务间有频繁的通信需求。三种工作流的任务间数据传输情况各不相同,与自身的计算需求相比,Cybershake有最多的数据传输需求,Montage次之,Epigenomics最少。实验分别使用GA、IMPSO、CWFS-GA、CWFS-IM 4种方法对这三个工作流进行调度,4种方法分别运行200次,每10次进行求平均得到一次运行时间。图6中分别展示了Cybershake、Epigenomics和Montage在4种调度方法下的完工时间。

图6 三个工作流在4种调度方法下的完工时间Fig.6 Make-span of three workflows in four scheduling methods
可以看出,在这4种方法中,CWFS-IM和CWFS-GA的效果比IMPSO、GA好,这说明基于集聚系数的切片方法可以有效地减少完工时间。另外,对比这三张图可以看出,对于资源需求和特点不同的工作流,CWFS带来的提升也不尽相同。对于Cybershake来说,CWFS的效果最好,这是由于Cybershake执行过程中有大量的数据传输请求,这会带来大量的数据传输时间。进行合理的工作流切片后,可以将这部分传输时间节省掉。而对于Epigenomics来说,这项提升没有Cybershake那么明显,因为Epigenomics工作流更侧重于计算资源需求。
图7 中分别展示了三个工作流在4种调度方法下的执行成本。

图7 三个工作流在4种调度方法下的执行成本Fig.7 Execution cost of three workflows in four scheduling methods
从图中可以看出,CWFS可以有效地降低成本。不同工作流成本降低的效果和完工时间类似。对于通信需求多的Cybershake工作流来说,CWFS可以带来明显的成本下降效果,因为它节省了大量的数据通信所造成的成本。Montage工作流的成本也有明显下降,而对于Epigenomics工作流来说,效果没有前两者那么明显。
6 结论
在面向多云的工作流优化调度研究中,对于一些数据传输量较多或者数据通信较为频繁的工作流来说,由任务间的依赖性而带来的传输成本和时间消耗不容忽视。为解决该问题,本文提出了先对工作流进行切片,然后再进行优化调度的思路。首先根据工作流切片的实际需要,引入集聚系数概念,并定义了类内聚集系数和类间集聚系数,进而给出了对子工作流进行分割与合并的判断标准;在此基础上,提出了一个基于集聚系数的工作流切片与多云优化调度框架。引入集聚系数来优化调整工作流的切片结果,并在寻优求解过程中根据可用云实例的实际承载能力,动态地调整切片结果。最后,使用三种不同类型的科学工作流,利用真实的云实例信息进行实验,结果表明,相较于对比方法,所提方能够有效减少完工时间和成本。
CBTC(基于通信的列车控制)系统能够确保列车灵活、高效运行。但近年来,采用CBTC系统的线路仍时有事故发生。2011年9月11日,上海轨道交通10号线发生列车追尾事故,造成295人受伤;2017年11月15日,新加坡地铁发生列车碰撞事故,造成28人受伤。这些事故都造成了巨大的社会影响和经济损失。事故原因是,CBTC系统地面设备故障,事故列车无法识别其他列车,因而不能实施有效控制。那么,如果列车具有自主运行能力,并且各车之间能够直接通信,就可有效避免列车追尾或碰撞事故的发生。这一技术将成为新一代CBTC系统的一个重要着力点。
作者贡献说明:
王鹏伟:论文的提出、构思、方法、写作、修改、验证、分析、校对与编辑。
我国养老床位总数仅占全国老年人口的1.8%,不仅低于发达国家5%-7%的比例,也低于一些发展中国家2%-3%的水平[8]。
雷颖慧:论文的数据准备、实验、初稿撰写、验证与分析。
赵玉莹:论文的初稿撰写、图表与格式排版。
章昭辉:论文的阅读、校对与编辑。
猜你喜欢
电子测试(2017年15期)2017-12-18 07:19:27
电信科学(2016年11期)2016-11-23 05:07:58
中国组织化学与细胞化学杂志(2016年3期)2016-02-27 11:15:40
智能系统学报(2015年4期)2015-12-27 09:38:39
中国当代医药(2015年17期)2015-03-01 02:03:38
电子设计工程(2015年6期)2015-02-27 12:04:53
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
河北医科大学学报(2010年10期)2010-03-25 10:15:06
