
基于Storm的数字信号流式处理平台的研究与实现
2021-09-07 07:45:48刘世颖张华冲于浩洋
无线电工程 2021年9期
张 保,刘世颖,张华冲,顾 旭,于浩洋
(中国电子科技集团公司第五十四研究所,河北 石家庄 050081)
0 引言
近年来,现代无线通信和频谱侦察监视领域中电磁环境日益复杂,新体制信号不断涌现,对电子信息装备平台的高效集成、灵活扩展等方面提出了更高的要求;另一方面,为提升电子信息装备的全空域、全时域和全频域的多维快速感知能力,要求在线实时或离线处理的数据量越来越大。因此,把硬件作为无线通信的基本平台,而把数据处理尽可能多地用软件实现的基于软件无线电技术的分布式并发处理的新型数字信号处理平台[1-2]成为了研究热点。
传统的数字信号处理平台中,通过配置大容量存储,将数据采集存储于磁盘之中,在处理时,采用将数据批量导出的方式进行离线处理。此种数字信号处理平台的缺陷在于:① 随着设备采集能力的提升,数据产生的速度远高于数据处理的速度,对磁盘存储能力的要求越来越高,系统设计的硬成本也随之提升;② 数据离线处理的方式拥有较大的信息情报获取延迟,而数据本身的价值也随信息获取时间的增长而逐步降低。为解决该问题,需建立一套流水线式的数字信号处理平台[3-5],能够以较低的时延处理流式数据,在快速获取信息情报的同时,减少非必要数据的存储需求。
Storm[6-7]中间件是一个并行分布式数据流处理框架,适用于处理无边界的数据流,被广泛应用于各类数据流处理场景中,具备可扩展、高容错、与编程语言无关等特性,可以与Kafka[8]、Zookeeper[9]等技术协同工作,构建一套完善的并行分布式数据流处理系统。本文在简要介绍Storm原理的基础上,提出了一种基于Storm的数字信号流式处理平台:基于数字信号处理模块的功能特性设计独立的虚拟设备,基于不同体制信号的业务特性设计数字信号处理有向无环图(DSP-DAG),将DSP-DAG映射至Storm集群,实现采集数据的流式并行处理。实验表明,该平台具有集成效率高、运算速度快、可靠性高和扩展能力强等优点,优于传统的数字信号处理平台。
1 Storm分布式流处理框架
大数据具有4个公认的特性:体量(Volume)、速度(Velocity)、多样性(Variety)和真实性(Veracity)。针对该特性,多种大数据处理工具应运而生,主要包括数据处理、数据传输和数据存储3类。其中,数据处理存在批(Batch)处理和流(Stream)处理2种形式[10],其模型对比如图1所示。
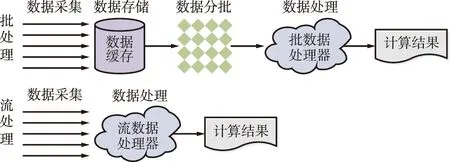
图1 批处理和流处理模型对比Fig.1 Comparison of batch processing and stream processing model
其中,批处理模式下,采集的数据需缓存入固定的数据池中,然后对数据进行分批,数据按既定批次进行处理;批处理的特性在于,所有数据处理流程全部完成之前,无法获得最终结果。而流处理模式下[2],数据在流入系统的同时执行处理,分别处理每个事件,该特性适合于持续地处理数据,同时要求这些数据能够快速产生有效结论的应用场景。
现代无线电磁波通信侦察领域要求对采集数据的处理和感知提出了越来越高的要求,从数据采集、信号处理、变化感知到最终的结果存储与展示,整个过程要求以尽可能低地延迟完成,为电子信息装备的情报整编及时提供分析素材。这就要求以实时的流处理技术构建新型的数字信号处理平台。
Storm集群架构如图2所示,一个Storm集群包含2种类型的节点:主控结点(Master Node)和工作(Worker Node)结点。其中,主控结点只有一个,而工作结点可以有多个;一个主控结点运行一个守护进程Nimbus,而每个工作结点都分别运行一个守护进程Supervisor;每个工作结点可以运行一到多个工作进程,每个工作进程(Worker)可以拥有一个或多个执行器(Executor)。Nimbus围绕集群发布代码,将任务指派给工作节点,并同时监控异常状态;每个Supervisor通过监听Nimbus分配到工作结点上的任务去启动或结束工作进程;每个执行器上运行一个或者多个所分配的计算任务(Task)。
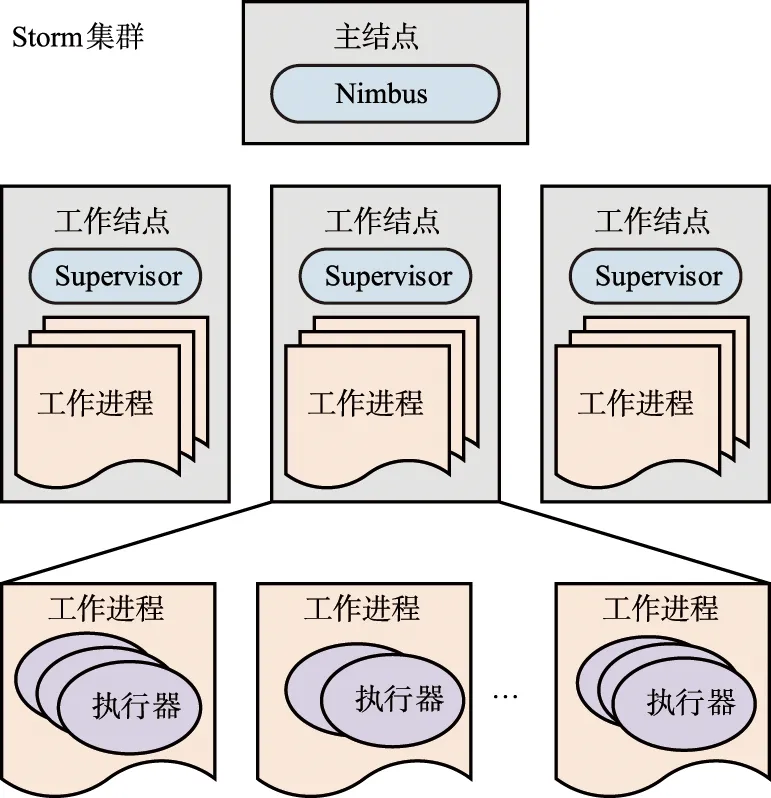
图2 Storm集群架构Fig.2 Storm cluster architecture
Storm拓扑结构如图3所示,在Storm集群中运行的每个作业被表示为一个有向无环的拓扑图(Topology)。其中,每个结点是一个组件,组件有2种类型:Spout组件是数据源,负责生产数据;Bolt组件封装了数据处理逻辑,可以完成过滤、业务处理、连接运算、连接与访问数据库等任何操作。每个组件都含有一个或多个任务(Task),任务是最小的处理单元。任务之间传递的消息由元组(Tuple)构成,是消息传递的基本单元;一个无界的元组序列构成流(Stream)。流分组(Stream Grouping)定义消息分发策略,决定了流/元组如何在Spout到Bolt或Bolt之间的任务间进行分发。

图3 Storm拓扑结构Fig.3 Storm topology structure
Storm具备高度的容错机制,提交拓扑到集群后,Storm会一直运行拓扑直至其被人为杀死。如果运行过程中某个工作进程发生故障,Supervisor检测到故障后会尝试在本机对其进行重启;如果Nimbus或Supervisor守护进程故障,因其状态可以保存,在将其重启后不会对系统任务的运行产生任何影响;如果整个工作结点发生故障,Nimbus监测到错误后会以进程调度的方式将该结点上所有的任务转移至其他可用的工作结点上重新运行。同时,Storm具备高可靠性机制,通过设计一组特殊的Acker任务,对于每个Spout消息元组,跟踪其在拓扑内的有向无环图,确保每个来自Spout的消息元组将被完全处理。
2 数字信号流式处理平台设计
为实现电子信息装备所采集的流式数据的快速处理,提出了一种基于Storm的数字信号流式处理平台,与天线、射频前端和数据采集设备共同构成高速数字信号处理系统,其整体架构如图4所示。
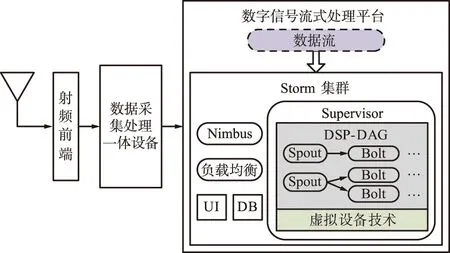
图4 高速数字信号处理系统架构Fig.4 Architecture of high speed digital signal processing system
其中,天线、射频前端和数据采集设备作为采集数据流的生产者,产生的数据以流的形式流入数字信号流式处理平台;而数字信号流式处理平台作为采集数据流的消费者,基于虚拟设备技术和数字信号处理有向无环图(DSP-DAG)构建Storm拓扑作业,由Nimbus和Supervisor守护进程进行调度,在Storm集群上运行;同时,Storm集群可为负载均衡、拓扑作业监控(UI)和数据持久化(DB)等技术提供支撑。
2.1 虚拟设备责任矩阵
广义的虚拟设备(Virtual Device)是指利用数字计算机技术模拟实现示波器、温控仪表、数据采集系统和数据信号处理系统等各种传统设备的计算机系统都可称为虚拟设备[11],而本文所讨论的虚拟设备是指利用通用计算机/服务器实现数据信号处理[12-15]。
本文提出的基于Storm的数字信号流式处理平台中所处理的基本单元是由采集数据流构成的计算任务(Task),而处理计算任务最小的执行单元是最基本的Spout/Bolt组件,即为进行封装后的可完成独立功能的软式虚拟设备实例。
一个完整的数字信号处理流程囊括多种体制信号的处理方式以及各种体制信号的多个处理阶段,本文提出的虚拟设备技术旨在依据数字信号处理流程中各功能模块的独立特性进行切分,划分为具有不同功能的虚拟设备,再对各虚拟设备的输入、输出接口进行标准化设计与封装,以构建Spout/Bolt组件。
依据不同体制(常规、突发和扩频等)信号处理的业务特性可将数字信号处理流程在横向上切分为常规信号处理、突发信号处理和扩频信号处理等;依据信号处理阶段的功能特性可将数字信号处理流程在纵向上切分为预处理、检测、信道化、分析、解调、解码和协议分析等[16]。
Storm平台中任务之间以元组(Tuple)的形式传递消息,元组是一个命名的值列表,其字段所支持的类型包括基本类型、字符串或字符数组,均为较为简单的对象类数据形式。而数字信号处理虚拟设备间所交互的内容除对象类数据外,还包括文件类数据和库表类数据。为适应Storm平台中消息的传输要求,需对虚拟设备的输入、输出接口进行标准化与封装设计,如图5所示,针对不同的数据采用如下3种不同的传输方法:
(1) 对象类数据:直接基于通信网络的方式进行传输;
(2) 文件类数据:将文件在磁盘上的存储路径组织为对象类数据再基于通信网络的方式进行传输;
(3) 库表类数据:将库表名称及相应字段组织为对象类数据再基于通信网络的方式进行传输。
2.2 DSP-DAG模型
一个流式计算作业及其所处理的一系列任务可以用有向无环图(DAG)[17]表示,在Storm集群中称之为拓扑(Topology)。为适应该处理模式,在构建数字信号处理责任矩阵的基础上,提出了DSP-DAG模型,即可用于数字信号处理的有向无环图。该模型采用如下构建方法:
(1) 基于不同体制信号处理的业务特性将其信号处理流程中所需的虚拟设备进行串接,构成虚拟设备作业链;
(2) 基于负责不同功能模块的虚拟设备的性能特性为作业链中每个作业节点配置虚拟设备实例数量。
基于上述方法完成DSP-DAG模型的构建,某种体制信号DSP-DAG模型的示意如图6所示。
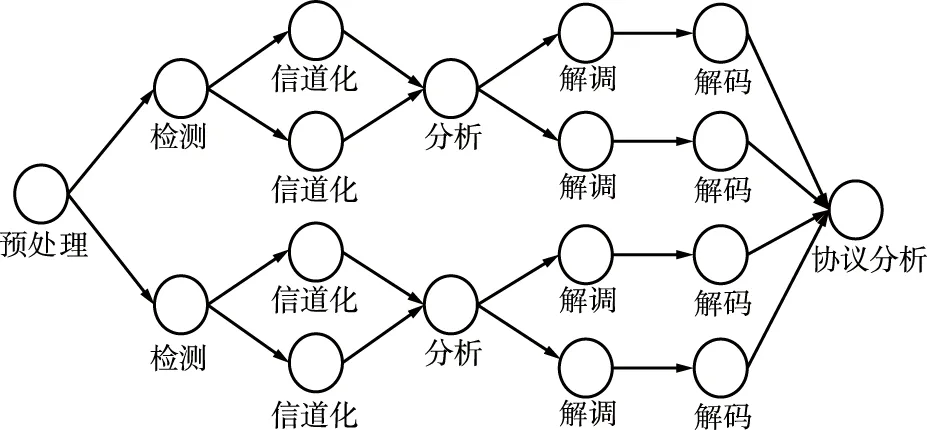
图6 某体制信号DSP-DAG模型示意Fig.6 Schematic diagram of DSP-DAG system signal model
流式数据在时间维度上可分解为连续的多个处理子任务,而DSP-DAG模型将各虚拟设备实例组织为流水线,各类虚拟设备并行地执行其对应阶段的子任务,同类虚拟设备的不同实例并行地执行其相应阶段的子任务,从而达到超标量流水线并行。流水线并行是指将不同的阶段任务分配到不同的处理单元(如集群节点以及节点内多核等)上,各处理单元并行的执行阶段任务,实现时间上的并行;而超标量流水线并行以空间换时间的方法实现多条流水线的并行[18-21]。
DSP-DAG模型可有效地对流式数据的处理进行并行加速,以图6中某体制信号的处理为例,定义各阶段处理时间如下:
tp:单个信号的预处理时间;td:单个信号的检测时间;tc:单个信号的信道化时间;ta:单个信号的分析时间;tm:单个信号的解调时间;te:单个信号的解码时间;to:单个信号的协议分析时间。
为方便进行性能对比,假设图6为理想化配比模型,在信号处理各阶段所产生的数据没有堆积,即某处理阶段在产生一批次数据时,其上一批次的数据已被下个处理阶段消耗完毕。设Δt为耗时最长的虚拟设备处理每个子任务所需执行时间,则:
此时,DSP-DAG模型可等同视为度为4的超标量流水线,与度为1的常规单标量流水线对比如图7所示。
采用串行模型执行时,n(设n=i×4,其中,i为正整数)个计算子任务的总执行时间为:
tSLE=tp+td+tc+ta+tm+te×n+to=11.5Δt,n=8。
采用DSP-DAG模型执行时间,n个计算子任务的总执行时间为:
而2种模型加速比为:
因此,DSP-DAG模型(度为4的超标量流水线)相对于传统流水线的模式极限加速比为4倍。
基于以上分析,采用DSP-DAG模型可有效对流式数据的处理进行并行加速,且该模型与Storm拓扑能够实现完美契合,发挥Storm平台的优势。

(a) 常规单标量流水线(度为1)
2.3 Storm平台映射
依据Storm拓扑结构,在Storm集群中运行的每个作业被表示为一个有向无环的拓扑图(Topology)。而拓扑由消息源Spout组件、处理逻辑Bolt组件,以及组件之间传递的消息由Stream/Tuple组成。
为实现DSP-DAG模型到Storm平台的映射,本文将预处理虚拟设备定义为PreprocessSpout组件,将检测、信道化、分析、解调、解码和协议分析等虚拟设备分别定义为DetectBolt、ChannelBolt、AnalyzeBolt、DemodBolt、DecodeBolt、ProtocalBolt组件,将各虚拟设备的输入、输出封装为标准的Stream/Tuple消息,并在构建拓扑时定义各组件并发的数量。DSP-DAG模型到Storm平台的映射示意如图8所示。
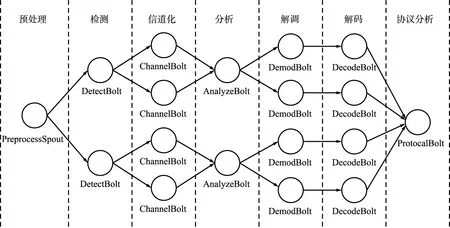
图8 DSP-DAG与Storm平台映射示意Fig.8 Diagram of DSP-DAG and Storm platform mapping
3 验证与测试
3.1 实验环境
本文实验环境基于1台曙光I620-G20服务器和2台曙光W620-G20服务器,分别配置了2颗Intel Xeon 12核CPU(E5-2680 V3,2.5 GHz),128 GB DDR3内存;其中,2台曙光W620-G20服务器各配置了1颗NVIDIA Tesla K20 m GPU(2 496个CUDA Core,4 800 MB显存),用于实现部分应用性能的加速;服务器之间采用万兆交换,数据存储于1台DS600磁盘阵列。
服务器安装了中标麒麟v6.5操作系统,内置Storm应用环境及本实验所需的其他依赖软件库,具体如下:
JDK版本:jdk.1.8.0_91
Maven版本:apache-maven-3.6.0
Storm版本:storm-1.2.3
Kafka版本:kafka-2.3.1-incubating-src
Zookeeper版本:zookeeper-3.5.6
Python版本:Python-2.7.3
CUDA版本:CUDA Toolkit V7.5
3.2 测试应用
本实验选用常规体制卫星信号的自动普查应用进行测试,实验进行3轮,数字信号处理的对象分别为1 000,2 000和3 000组采样数据文件,数据中含频分多址和时分多址信号,数字信号处理的目的是获得信号的详细特征参数和调制方式。其中,为方便实验对比,每组数据文件采样率fs为500 Ms/s,采样深度为16 bit,采样时长为8 ms,采集带宽200 MHz;数据为仿真生成,每组数据中包含5个调制方式为BPSK的频分多址信号(符号速率Rs均为10 Ms/s)和5个调制方式为QPSK的时分多址信号(符号速率Rs均为2 Ms/s)。
基于频分和时分多址信号的处理的业务特性,将其处理过程设计为数据预处理、宽带信号检测、多信号分割、非均匀信道化、通信体制识别、FDMA信号特征参数估计和TDMA信号特征参数估计等7个虚拟设备,基于本文描述的DSP-DAG模型的构建方法,搭建本测试应用的数据信号处理拓扑图,依据以下步骤,推算过程如表1所示,搭建本测试应用的数据信号处理拓扑图如图9所示,等同于度为68的超标量流水线。
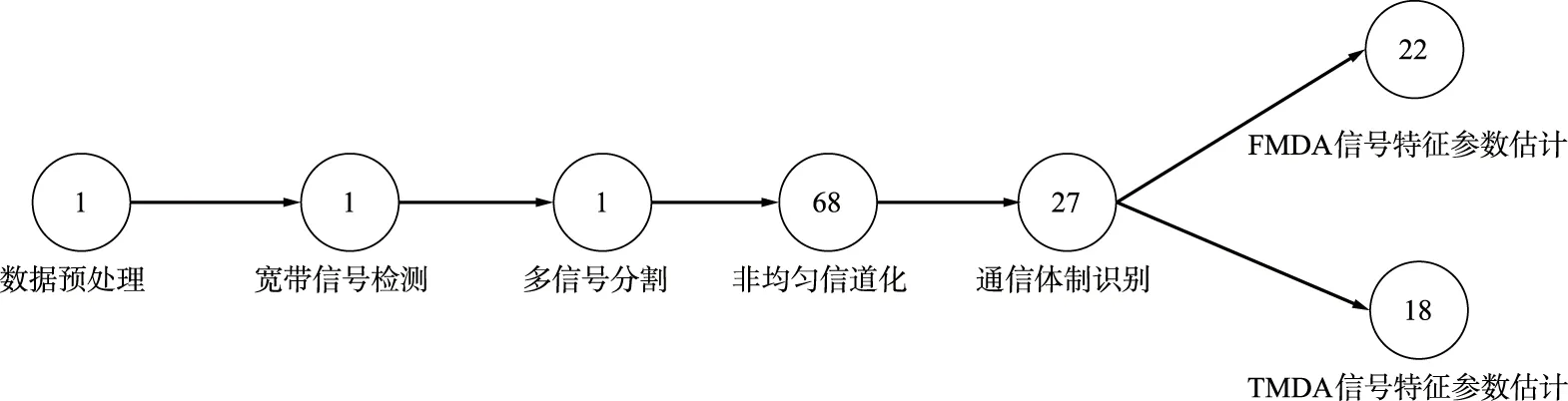
图9 常规体制卫星信号的自动普查拓扑图Fig.9 Automatic general investigation topological graph of conventional system satellite signals
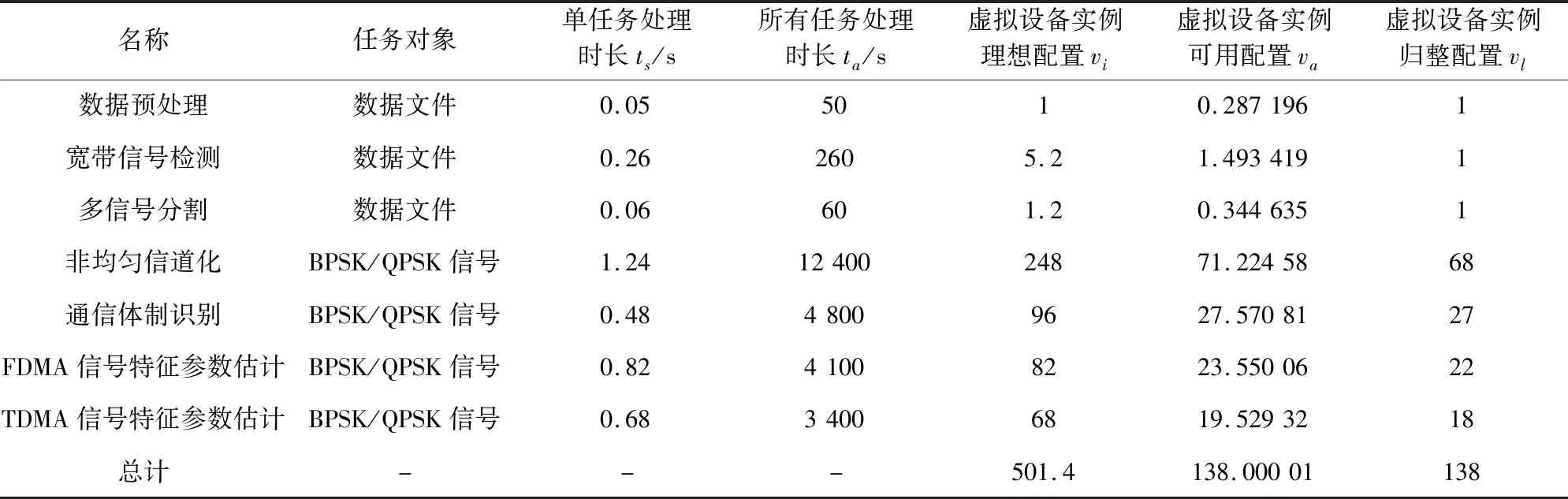
表1 常规体制卫星信号的自动普查拓扑图构建过程表Tab.1 Automatic general investigation topological graph construction process table of conventional system satellite signals
注:3台曙光服务器共计72核,可同时运行144线程,为保证服务器系统运行,分配每服务器2个线程用于系统的监控运行,即虚拟设备可用138线程,因此调整因子factor为:factor=∑vi/138;则每虚拟设备实例可用配置va为:va=vi/factor。
(1) 统计各虚拟设备单任务处理所需时长;均采用曙光W620-G20服务器进行多次测量取平均值;
(2) 统计各虚拟设备所有任务处理所需总时长;
(3) 计算理想配比条件下,各虚拟设备所需配置实例个数;
(4) 依据当前实际测试环境,基于可同时运行总线程数计算调整因子,计算虚拟设备可配置实例个数;
(5) 各虚拟设备可配置实例进行归整计算。
3.3 测试结果与分析
测试结果如图10所示。
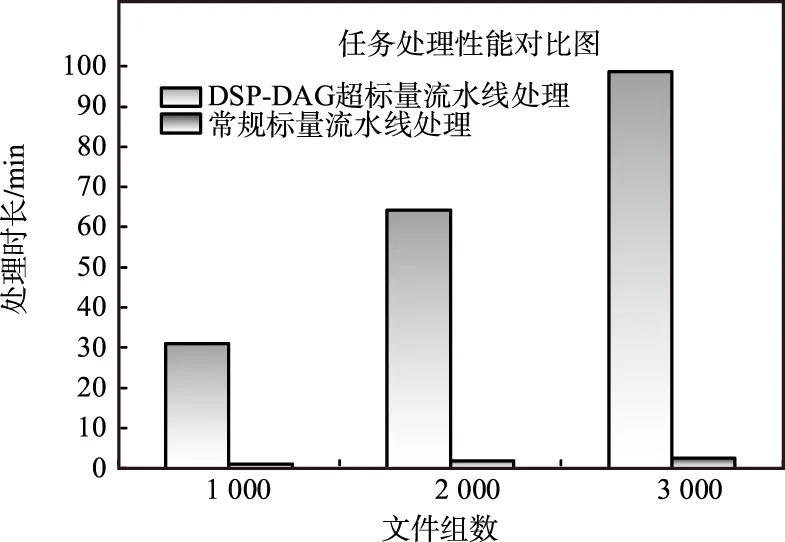
图10 常规体制卫星信号的自动普查任务处理性能对比图Fig.10 Comparison chart of automatic general investigation task processing performance of conventional system satellite signals
实验结果表明,采用DSP-DAG超标量流水线进行加速后,处理速度有了明显提升,数据文件在1 000组以上时,相对常规单标量流水线处理方式性能提高了31倍以上。且随着处理总任务量的提升加速比逐步提高,但加速比趋势逐步降低,具体如图11所示。

图11 常规体制卫星信号的自动普查任务加速比趋势图Fig.11 Trend chart of acceleration ratio of automatic general investigation task for conventional system satellite signals
实验结果表明,针对本应用设计的数据信号处理拓扑图,可有效提升处理性能。但该拓扑图采用度为68的超标量流水技术,理论加速比可达到68倍,鉴于测试结果加速比小于理论加速比的情况,分析原因包括两方面内容:① 总任务量有限,随着任务量的提升加速比会逐步提高,但会趋于一个平衡;② 处理线程的增加,增加了一定的通信开销,在一定程度上阻碍了处理性能的提升,且大量线程对磁盘的并发读写也是影响性能的主要瓶颈。
4 结束语
在介绍流处理技术和Storm原理的基础上,提出了一种基于Storm的数字信号流式处理平台。结合不同体制信号处理的业务特性,及信号处理过程中各阶段的功能特性,构建虚拟设备责任矩阵;基于超标量流水线并行原理,将各类虚拟设备串接处理某种体制信号的作业链,构建DSP-DAG模型;将虚拟设备映射为Storm平台的Spout/Bolt组件,将DSP-DAG映射为Storm平台的Topology,最终实现基于Storm的数字信号流式处理平台。实验结果表明,提出的DSP-DAG数字信号处理模型可有效提高应用的整体性能。
同时,在基于集群进行分布式计算时,集群中各节点间的互联网络以及磁盘等环境,均会对应用性能产生影响,因此,后续研究集群环境布设、处理线程间的通信效率和对磁盘的读写速率等对应用的并发改善仍具有重要的意义。
猜你喜欢
汉语世界(The World of Chinese)(2023年2期)2023-06-22 14:50:17
小学科学(学生版)(2020年2期)2020-03-03 13:40:16
工程与建设(2019年5期)2020-01-19 06:22:38
信号处理(2018年5期)2018-08-20 06:16:02
信号处理(2018年5期)2018-08-20 06:16:00
信号处理(2018年8期)2018-07-25 12:25:42
信号处理(2018年8期)2018-07-25 12:24:56
光学精密工程(2016年1期)2016-11-07 09:01:17
中国资源综合利用(2016年9期)2016-01-22 08:35:22
西南石油大学学报(自然科学版)(2015年4期)2015-08-20 09:05:28
