
基于多示例学习的长文档检索
2021-09-07 07:45郝文宁靳大尉
无线电工程 2021年9期
田 媛,郝文宁,靳大尉,陈 刚,邹 傲
(陆军工程大学 指挥控制工程学院,江苏 南京 210000)
0 引言
近年来,随着网络的快速发展,积累了海量的信息资源,为了有效利用这些信息资源,帮助人们从中快速获取所需信息,信息检索(Information Retrieval,IR)技术得到了越来越多的关注和发展。信息检索的目标是根据用户的查询返回相关度高的文档,计算词、句子、段落以及文档之间的相似性是信息检索任务中的一个重要组成部分[1],针对长文本的检索,常见的冗余文档处理、不端文献检测等,现有的基于词频的方法(TF-IDF、词袋模型),往往忽略了文本的语义信息。此外,当文本较长时,一些与查询相关的词分散在文档中,直接比较整篇文档会影响检索性能,并且一些文本相关性计算方法或相似度匹配算法往往会受到长度的影响[2-3]。
很多研究者致力于将文本表示与相似度计算相结合以提升文档检索性能[4-5],已有的一些方法通过简单地将文本中每个句子的句向量进行拼接或者叠加来获取整个文档的向量表示,然后计算文档与查询的相似度,但是这样会造成语义缺失;还有一些基于句相似度的检索模型,通过检索出相关度高的句子来反向定位其所在的文档,但这样可能会使得同一篇文档被重复检索,因为相似度得分高的多个句子可能出自同一篇文档。
多示例学习(Multiple Instance Learning,MIL)最早由Dietterichet等人[6]提出用于药物分子活性检测,随后被广泛应用在场景分类等问题中,相对于单示例,多示例能更好地描述样本。将多示例学习理论作为文本表示的理论基础,从包的角度重新认识文本表示,可以有效解决向量空间模型无法表示词之间序关系的问题[7]。文献[8-9]提出将多示例学习框架应用到图像检索中,并且取得了很好的实验结果,但很少有人研究将其应用到文档检索中。
在多示例学习框架下,提出了一种新的文档检索方法,以语义相对完整的句子为单位分别对查询文本和待检索文本进行切割,从而将文本表示成句子包,而每个句子则作为包中的示例,分别使用BM25和Sentence-Bert作为特征函数计算查询中示例与待检索文档中示例之间的相似度得分,然后设置合适的阈值筛选出待检索文档中与查询高度相关的示例,通过这些示例的相似性得分来度量查询与待检索文档包之间的相似性,同时结合传统的文档级检索模型,最终返回Top-K个文档作为检索结果。在Med数据集上的实验表明,提出的新文档检索模型相较于传统的文档级检索模型在准确率、召回率和F1得分上均有一定程度的提升。
1 相关研究
文档检索的研究主要涉及文本表示、相似度计算等方面,语义文本匹配是信息检索、问答系统、推荐系统等诸多领域的重要研究问题之一[10],传统的模型通常是使用词项频率,往往忽略了文本的语义信息,随着深度学习的发展,越来越多学者开始将语言模型用于文档检索中。本文使用Sentence-Bert模型进行文本表示并通过余弦距离计算相似度完成检索,与传统的BM25模型进行比较,对BM25模型、Sentence-Bert模型以及多示例学习框架的简要介绍如下。
1.1 BM25模型
BM25模型也被称为Okapi模型,由Robertson等人[11]提出,用于计算查询和文档集中每篇文档之间的相关性,通过词项频率和文档长度归一化来改善检索结果,对于给定查询Q和文档D:
(1)
式中,qi表示查询Q的一个语素(一般是单词);wi表示qi的权重,计算方法有很多,一般使用IDF来表示:
(2)
式中,N为文档集中文本总数;n(qi)为包含词qi的文本数。R(qi,D)的计算公式为:
(3)
式中,fi为词qi在文本D中出现的频率;qfi为qi在查询Q中出现的频率;len(D)表示D的长度;avgl表示文档集中所有文档的平均长度;b,k1,k2都是需设置的超参数。
文献[12]研究发现,由于文本长度平均值的设置,BM25模型在实践中往往会过度惩罚有用的长文档。Na等人[13-14]将BM25改进为vnBM25,改进后的公式能有效缓解文本长度的冗余影响。
1.2 Sentence-Bert模型
随着自然语言处理的不断发展,各大预训练模型(如Bert[15]、Robert、GPT-2等)层出不穷,但大部分不适用于语义相似度计算,解决语义搜索的一种常见方法是将句子映射到向量空间,使语义相似的句子在向量空间中相近。文献[16]指出,直接将句子输入预训练模型得到的句向量并不具有语义信息,即相似句子的句向量可能会有很大差别。Sentence-Bert采用孪生或者三重网络结构对预训练的BERT/RoBERTa进行微调,更新模型参数,使调整后的模型所产生的句向量可直接通过余弦距离计算相似度。模型结构如图1所示,使用余弦函数计算2个句子向量之间的相似度,均方误差作为损失函数。

图1 Sentence-Bert结构Fig.1 Structure of Sentence-Bert
Sentence-Bert模型可以很好地从语义上表征一个句子,从而使得语义相似的句子在向量空间中的嵌入向量距离相近,因此,可以很好地完成诸如大规模语义比较、聚类、通过语义搜索的信息检索等任务。
1.3 多示例学习
多示例学习与传统有监督学习的区别就在于二者训练样本的不同,在传统的有监督学习问题中,每一个训练样本的形式为(Xi,Yi),Xi是样本对象,用一个固定长度的特征向量来表示,而Yi则是该样本对应的类别标签,其描述如图2所示。
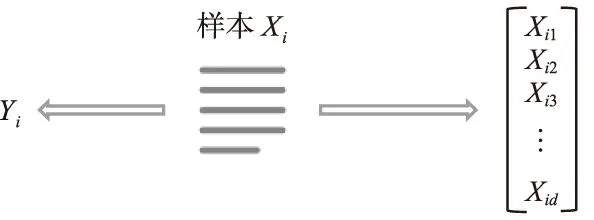
图2 传统有监督学习框架Fig.2 Framework of traditional supervised learning
在多示例学习问题中,每个训练样本不再是一个固定长度的特征向量,而是包含多个特征向量,这些向量称为示例,训练样本称为包。此时,包Xi是由示例空间Rn中有限个点组成的一个集合,训练样本形式变为({Xi1,Xi2,…,Xin},Yi),Xij表示包中的第j个示例,其中j=1,2,…,n,每个包中的示例个数可以不同,Yi是包对应的类别标签,而包中示例的标签是未知的,如图3所示。
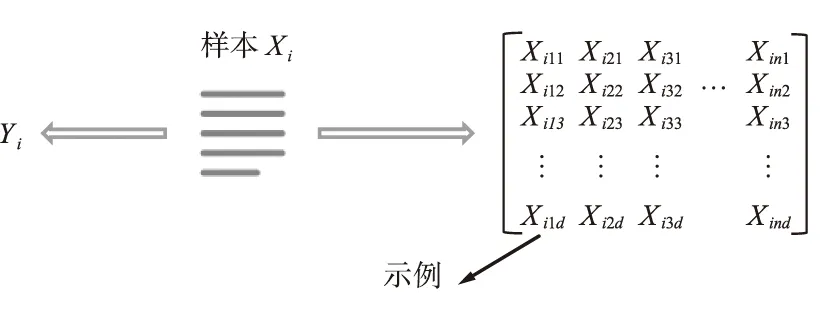
图3 多示例学习框架Fig.3 Framework of multi-instance learning
过去的研究中,已经有很多领域的问题使用了多示例学习框架,例如药物分子活性预测、文本分类[17]、基于内容的图像检索[18]和人脸识别[19]等。
2 多示例文档检索模型
根据已有的基于多示例学习的文本表示思想,本文通过标点符号完成对文本的切分,将其切分成语义相对完整的句子,从而将文本表示成句子包,包中的每个句子作为示例,使用不同的相似度计算方法计算示例之间的相似度,根据示例之间的相似性得分筛选出相关示例并计算相关比率,从而计算出包之间的相似性,同时结合传统的文档级检索来进一步提升检索性能。
2.1 模型概述
本文提出的文档检索模型的框架如图4所示,模型共有4个模块,分别是文本预处理模块、句子级检索模块、文档级检索模块和整合模块。其中,预处理模块主要是对查询文本和文档集中的文本做去停用词、词干化等预处理;句子级检索模块即使用的基于多示例学习的检索模块,包括文本切割、示例间相似度计算以及包相似度计算3个部分;文档级检索模块使用传统的计算查询与整个文档的相似度的检索方法;整合模块则是将句子级检索与文档级检索相结合,进一步提升检索性能。在相似度计算部分,分别使用BM25和Sentence-Bert作为特征函数,对使用2种不同特征函数时文档检索的性能进行比较。
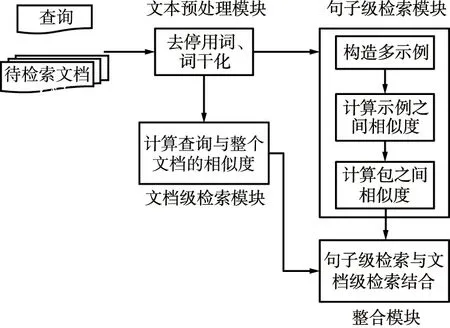
图4 基于多示例学习的文档检索模型框架Fig.4 The document retrieval model framework based on multi-instance learning
不同于已有的一些句子级检索模型,通过句子的相似度得分直接反向定位到其所在的文档,或者直接通过简单对句子的相似度得分进行加和或求平均,计算整个文档的相似度得分。本文的句子级检索模块提出一种新的根据句子之间相似度计算文档相似度得分的方法,首先通过计算待检索文档中每个句子与查询的相关性得分,然后筛选出这篇文档中与查询高度相关的句子,计算相关比率,最后根据相关比率来计算整个文档与查询的相似度得分。
2.2句子级检索
句子级检索主要分为3个阶段,具体处理流程如图5所示。
第一阶段是构造多示例,以语义相对完整的句子为单位,通过标点符号来将查询文本和待检索文本分别切割成句,从而将查询和待检索文本表示成句子包,每个句子则作为包中的示例。
第二阶段是计算示例之间相似度,首先获取查询包中与待检索包中示例的特征表示,然后使用不同的相似性度量方法来计算查询包中示例与待检索文档包中示例之间的相似度得分,如果使用BM25,则相似度计算如式(1)所示,如果使用Sentence-Bert,则使用余弦距离来表示示例间的相似度,对于待检索文档中的每个句子,计算其与整个查询的相似度得分:
(4)
式中,q为查询中的一个查询句子;S表示待检索文档中的一个句子;len(Q)表示查询中句子个数。
文献[20]指出,相关片段比率在评估文档相关性中是一个非常重要的因素,可以大大减少部分短文本高度相似偏向的影响。本文在计算整个文档与查询的相似度得分时参照该文档针对该查询的相关比率,首先通过设定合适的阈值筛选出待检索文本中与查询高度相关的句子,例如在图5中,假设待检索文本中的句子2、句子ni与查询的相似度得分大于给定阈值,则这2个句子即为与该条查询高度相关的句子。每个文本的相关比率计算如下:
(5)
式中,Srelevant表示文档D中经过筛选与查询Q高度相关的句子集合;Swhole则表示文档D中全部句子集合。
第三阶段根据示例的相似度得分计算包的相似度得分:
Score(Q,D)=max(Score(Q,S))×ratio(Q,D),
S∈Srelevant,
(6)
每个文档与查询的相似度得分,由文档中与查询相关的句子的最高相似度得分和该文档与该查询对应的相关比率的乘积表示。
最终可获得待检索文档集中针对每条查询的文档相似度得分,排序后选取得分最高的Top-K个文档作为检索结果返回给用户。
2.3 整合句子级检索与文档级检索
考虑到传统的文档级别检索模型已经取得了较好的性能[21],本文提出将基于多示例框架的检索模型与传统的文档级检索模型相结合,以进一步提升检索性能。将基于多示例检索计算的相似度得分记为Scores(Q,D),基于文档级检索计算出的相似度得分记为Scored(Q,D),则最终的相似度为:
Score(Q,D)=αScores(Q,D)+βScored(Q,D),
α+β=1,
(7)
式中,α,β分别表示不同检索模型所占权重,计算不同α,β取值对检索性能的影响,并选择最佳结果。
3 实验
3.1 数据集及评价指标
使用Glasgow大学收录的用于信息检索的标准数据集Med,Med数据集中共包含1 033篇文档,30个查询,文档的平均长度为1 034。对Med数据集进行了预处理,去除编号等无用信息,根据标准停用词表删去停用词并提取词干。为使Sentence-Bert模型能使用Multiple Negatives Ranking Loss函数在该数据集上fine-tuning,根据每条查询对应的相关文档构造了三元组形式的数据,实验使用准确率、召回率、F1[22]几个信息检索常用评价指标作为模型的评估标准,准确率P、召回率R、F1的计算如图6所示。
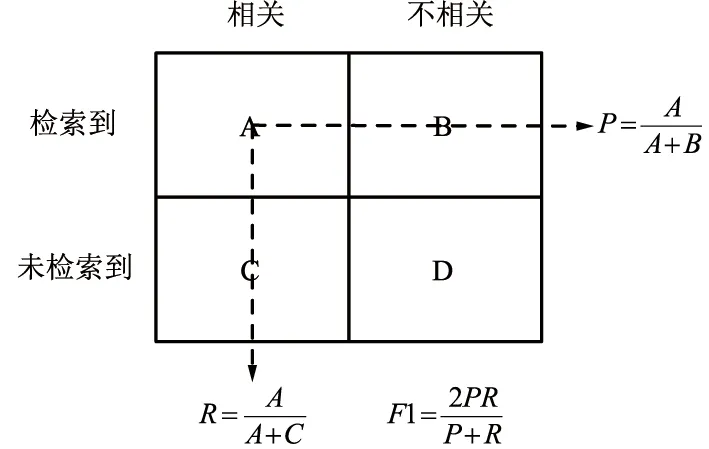
图6 准确率P、召回率R、F1得分Fig.6 Precision P,recall R and F1
3.2 实验结果及分析
实验分别使用BM25和Sentence-Bert作为特征函数来对检索模型进行评估,基准模型即为传统的文档级检索模型,将整个文档看作一个单示例,本文提出的基于多示例学习的检索模型记为“MI-IR”,整合模型则记为“MI-IR+基准”。对于示例级检索模型,在使用BM25作为特征函数时,将文档集中所有单词的平均IDF值作为相关示例筛选的阈值;在使用Sentence-Bert作为特征函数时,将查询包与相关的文档包中的全部示例相似性得分的平均值作为相关示例筛选的阈值。实验对比结果如表1所示。
保险管理的三个阶段是一个前后联系紧密,环环相扣的系统。投保策划决定了出险后事件的定责情况、理赔范围、免赔金额等。保险合同的履行是进行保险理赔的前提。保险理赔阶段将损失定量化,以获得赔付达到转移损失的目的。但是目前很多业主和承包商并没有将三个阶段很好的结合起来,投保时风险分析不全面,合同履行时不够重视,理赔时因承保范围不足,部分或全部损失不能进行理赔等,最终导致理赔效果不佳,经济损失弥补未能达到最大化。

表1 各模型实验结果对比Tab.1 Comparison of experimental results of each model
Top5和Top10分别表示选取得分最高的5,10个文档作为检索结果,从表1的结果来看,使用BM25作为特征函数时,若取Top-5个文档作为检索结果,MI-IR检索模型相较于基准文档级检索模型的准确率有近5%的提升,F1得分有近4%的提升;使用Sentence-Bert作为特征函数,取Top-5个文档作为检索结果时,MI-IR检索模型相较于基准文档级检索模型的准确率也有近5%的提升,F1得分有近2%的提升。
在同为文档级检索即基准模型的前提下,使用BM25作为特征函数与使用Sentence-Bert作为特征函数在检索性能上差别不大,因为Sentence-Bert模型主要用于获取句向量。当文本过长,对整个长文本进行嵌入时,效果不是很好,对于检索性能的提升相对较小,但在使用了MI-IR模型后,由于更好地利用了文档句子的语义信息,使用Sentence-Bert作为特征函数比使用BM25作为特征函数在准确率上有一定提升,但是在召回率上有小幅下降,因此,如果对召回率的要求不高,追求更高的检索准确率,Sentence-Bert模型相对较优。实验结果也表明,在随着检索结果中文档数量增加的情况下,Sentence-Bert在各方面均略优于BM25,可能是由于BM25没有考虑语义信息,导致一些语义相近但是词本身不相同的文本检索不到。
表1中的数据同时也表明,将基准模型与MI-IR模型相结合,显然能进一步提升检索性能,在使用BM25作为特征函数时,MI-IR与基准相结合的模型相较于MI-IR模型在准确率上有近2%的提升;在使用Sentence-Bert作为特征函数,选取Top-5个文档作为检索结果时,MI-IR与基准相结合的模型相较于MI-IR模型在准确率上有近4%的提升。α和β取不同值时,句子级与文档级相结合的模型有不同的表现,以选取Top-5个文档作为检索结果为例,如式(7)所示,α和β的取值分别表示基准模型所占权重以及MI-IR模型所占权重,实验通过计算F1的值的变化来探索α,β不同取值对文档检索性能的影响。实验结果如图7所示,取α的取值作为横坐标。
图7(a)为使用Sentence-Bert作为特征函数,选取Top-5个文档作为最终返回的检索结果,随着参数α取值的改变,F1得分的变化曲线。从图中可以看出,当α取值范围在0.84~0.88,即β取值范围在0.12~0.16时,F1得分最高,随后当α值继续增大,β值相应的减小时,F1得分开始下降;图7(b)为使用BM25作为特征函数,同样选取Top-5个文档作为最终返回的检索结果,随着参数α取值的改变,F1得分的变化曲线,依然是当α取值范围在0.84~0.88时,整体模型表现最好。此外,实验结果表明,α取值较大,β取值较小,即当基于多示例框架的检索模型所占权重较大,传统的文档级检索模型所占权重较小时,整体检索模型的性能较好。
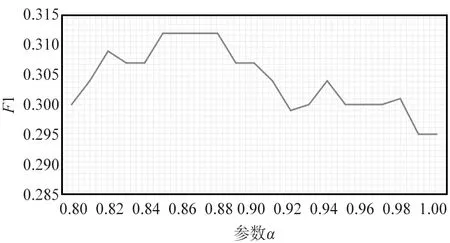
(a) Sentence-Bert作为特征函数
4 结束语
已有的文档检索模型已然取得了不错的性能,但对其研究探索仍在不断继续。本文提出将多示例学习框架用于长文档检索中,同时提出使用Sentence-Bert作为特征函数来对句子进行表示,目的是获取包含语义信息的句向量,从而更好地利用长文本中的每个句子的语义信息,提升文档整体相似度得分在文档检索中的参考价值,实验结果验证了所提出的模型具有较好的性能。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
数学年刊A辑(中文版)(2020年1期)2020-05-19
黑龙江科学(2020年5期)2020-04-13
通化师范学院学报(2019年12期)2019-12-18
新世纪智能(语文备考)(2019年10期)2019-12-18
山东冶金(2019年5期)2019-11-16
山东冶金(2019年1期)2019-03-30
邢台学院学报(2018年4期)2018-12-14
中学生数理化·七年级数学人教版(2018年9期)2018-11-09
