
基于一卡通学生行为的知识库构建与应用
2021-09-07 02:12刘建华常发财
西安邮电大学学报 2021年3期
刘建华,常发财
(1.西安邮电大学 信息中心,陕西 西安 710121;2.西安邮电大学 计算机学院,陕西 西安 710121)
近年来,随着第五代移动网络(5th Generation Mobile Networks,5G)、大数据和物联网技术在校园领域的普及应用,学校成了产生海量数据的重要场所。为了充分研究学生行为背后隐藏的信息,将来源多样和结构复杂的学生行为数据在大数据平台上构建成具有自动推理功能的知识库,通过异常检测和预警分析对存在异常行为的数据进行可视化展示[1]。这种利用构建知识库分析数据的方式也可以很好地应用到其他各个领域,具有很强的推广价值。
目前,已有多位研究者对学生行为分析模型进行了分析研究。基于神经网络、朴素贝叶斯算法组合模型[2],构建了分析预测平台对学生行为进行预测。文献[3]通过研究学生社会情感发展的规范趋势解释学生的自我报告随时间的变化,并根据报告预防学生情感异常现象发生。文献[4]把基于大数据的决策支持系统基本原理和图书馆专业特点相结合,设计了基于大数据的知识库存储系统。知识库的构建在世界各国的研究均比较广泛,如基于维基百科知识构建的KnowItAll、Probase和DBpedia知识库[5]等。但是,以上研究仅限于对学生行为的分析处理和单一的知识库构建,没有运用大数据的相关技术将学生行为和知识库建立相结合并分析数据。
为了实现对学生异常行为的预测,拟提出了一种在Hadoop大数据平台上构建知识库的模型,对学生的结构化、半结构化和非结构化的一卡通数据进行分析,在知识库中通过对TextRank算法的改进和随机游走技术实现知识库的自动推理功能,根据异常指标判定,对海量学生行为数据进行异常检测,并做相应的预警提示。
1 学生行为处理模型
学生行为数据分析主要包括4个主题库子模块,分别为学习行为主题库、门禁行为主题库、消费行为主题库和上网行为主题库。将不同主题库的数据上传到Hadoop集群,通过MapReduce框架对数据进行分割、排序、归约及合并的操作,结构不规整的冗余数据或缺失数据,形成结构化的数据远程存储在分布式文件系统中。知识库构建在Hive数据仓库中进行,将预处理后的数据集映射到数据仓库中,按照知识抽取和关联规则算法进行知识库的构建[6]。学生行为处理模型如图1所示。
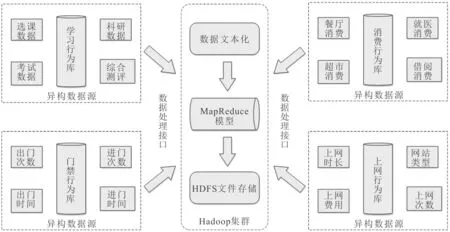
图1 学生行为处理模型
学生一卡通数据包括结构化数据、半结构化数据和非结构化数据等3个方面。结构化数据主要来自学校关系系统数据库数据。半结构化数据主要来自一卡通门禁数据、消费数据和就医数据等数据库,这些数据可以通过信息部门加密后获得。非结构化数据主要来自校园上网数据,上网数据比较随机,不确定性因素高,需要采用Flume组件采集,将上网日志信息包括文字、图像、音频和视频等学生行为数据通过Source采集源、Channel缓冲池和Slink下沉地获取。
从网上获取的源数据结构不规整,存在脏数据和噪音数据,因此,将源数据导入Hadoop集群,使用split将元数据切割成文本化数据,再经过MapReduce框架模型的Map阶段、Shuffle阶段和Reduce阶段对学生行为数据清理、集成、变换和归约等操作[7],将不利于分析和结构不规整的数据剔除或变换成结构规则的结构化数据。所处理数据容量大,实现本地存储难度大,因此,采用远程分布式文件系统[8](Hadoop Distributed File System,HDFS),通过使用HDFS的主从节点机制,实现对海量学生行为数据的可靠存储。
2 学生行为知识库构建
将预处理之后的数据从HDFS文件系统映射到Hive数据仓库的索引库[9],通过对TextRank算法的改进和随机游走技术,实现对学生行为知识的抽取、知识融合和知识的实时更新。
2.1 知识库构建流程
2.1.1 TextRank算法
TextRank算法[10]是一种运用图模型排序的算法,其核心思想是借鉴PageRank寻找关键词之间重要性的算法。首先,将采集的数据按照词性进行分割,形成具有独立含义的词文本。然后,按照算法得分函数公式计算词与词之间的重要权值,将权值按照倒排索引进行排序,从中抽取前t个关键词存储到结构化数据集中,将权值存放到矩阵中进行迭代获取共现关系,按照共现关系将实体关联起来,初步形成学生行为知识图谱。最后,按照共指消解、实体消歧和知识加工将重复冗余数据进行删除,确保每一个节点数据的实时性和准确性,将知识图谱映射到Hive数据仓库中就形成了学生行为知识库。知识库的构建示意图如图2所示。
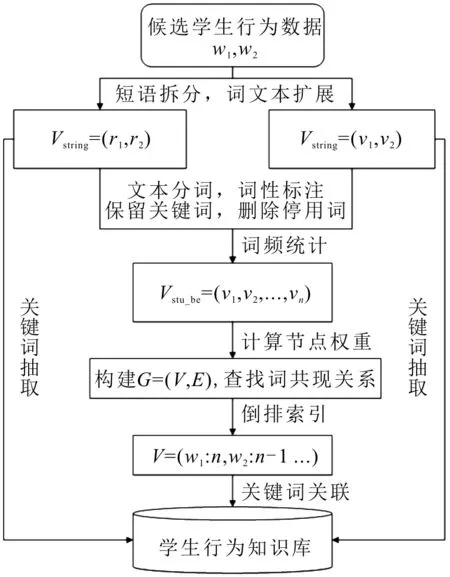
图2 知识库构建示意图
知识库构建有向图的具体表达式为G=(V,E),其中:V表示关键词节点集合;E表示关键词之间的边集合;r表示文本拆分后的词文本。计算文本中有共现关系的关键词权重表征词之间的重要性,通过不断迭代计算权重,按照权重值将关键词连接起来形成知识网络实现知识库构建[11]。知识网络中任意两个节点i,j的权重计算公式为
(1)
式中:Ii为该节点的入度;Oj为该节点的出度;wji表示入度的节点j到节点i的边连接重要程度;wjk表示出度的节点j到节点k的边连接重要程度;d为阻尼系数,一般取0.85。当权重值趋于极限值时,知识网络构建趋于稳定。
2.1.2 随机游走搜索判定
根据随机游走技术[12]判定知识库中学生异常行为数据。实体属性有向图如图3所示,用R表示根节点,□表示下位节点,○表示叶子节点,R和B1有上下位关系,B1与C1有上下位关系,则R和C1在语义上有某种相似度,但是,关联强度相对R和B1、B1和C1要弱一些。
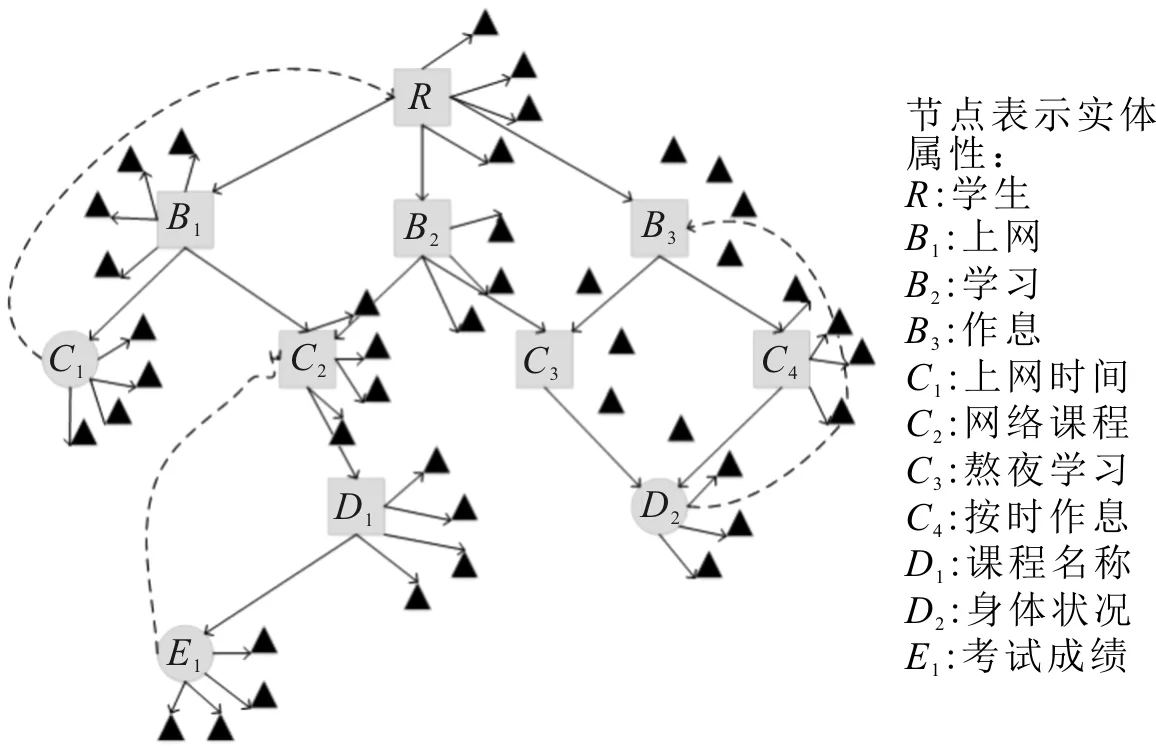
图3 实体属性结构
在利用随机游走算法之前,需要建立概念图的初始分布。假设从节点i开始随机游走,则概念图的初始分布表达式为
(2)
概念图的随机游走具体算法步骤如下。
步骤1给定初始化节点v0,并令v=v0。
步骤2根据图中概念的得分函数,计算节点权重,并生成矩阵P。
步骤3vn=αPTv+(1-α)v0。其中:α为初始基向量;n为节点总数。
步骤4v=vn。
步骤5重复步骤3和步骤4,直到vn达到稳定状态或者迭代次数超过某个阈值。
从节点R开始随机游走,到达稳定状态后,图3中的每个节点的概率值反映了该节点与节点R的语义相似重要程度[13],通过实验证明,在迭代20次后各节点概率值达到稳定状态。
如果从图3的R节点进行随机游走,第1次和第20次迭代的结果分别为

(3)

(4)
由式(3)可知,第1次迭代概率权值都小于1,无异常,继续迭代至数据节点权值稳定,有异常数据出现为止。由式(4)可知,经过20次迭代,各个节点的值达到稳定状态,将迭代后的概率值与学生手册标注值对比,判定学生行为数据是否在规定的阈值范围内,如果向量中的值大于1,则判定该对应行数据为异常行为[14]。
2.2 知识库实体融合
为了提高学生行为知识库的覆盖能力和扩展能力,知识融合可以有效地利用校园大数据的价值,并提高知识库的搜索精度。
知识的融合[15]主要是从文本数据中获取新的实体与语义关系并与开放网络做映射,其融合方式有两种可能性:一种是相容度高或已经存在的实体只需在知识库中找到对应的映射实体;另一种相容度低或不存在的实体,通过标注分类类别将其嵌入知识库。知识库内部实体通过计算语义相容度[16]实现水平或垂直融合,学生数据中两个实体e1和e2之间的实体语义相容度计算表达式为
(5)
其中:X和Y分别表示开放网络出现e1和e2的实体集合;Z表示知识网络包含所有实体的集合;|·|表示集合中元素的个数。
2.3 知识库实时更新
知识库更新是保持学生行为数据动态性的重要环节,采用自适应的原理实现了自动更新方法,该方法通过获取最新知识和知识语料库的备份识别知识库的变化,剔除过时数据和冗余数据,将新增数据及时同步到知识库。
3 实验与分析
3.1 实验数据
实验数据来源于西安某高校2016年的一卡通数据,对原始数据进行敏感度计算和隐私化处理后,随机采集2万条数据,在Hadoop集群上做预处理,将脱敏后的数据上传到HDFS文件系统并映射到Hive数据仓库中进行数据分析。一卡通数据主要包括学习数据、消费数据、门禁数据、上网数据、考勤数据、借阅数据和就医数据。对这些行为数据进行异常判定,学生行为部分数据统计如表1所示。

表1 学生行为数据统计
3.2 实验过程
3.2.1 准确度验证
知识库的精准度标志着对学生行为的预测精度和准确性,利用算法构建的知识库能够实现知识的自动推理,提升对异常行为数据监测,并能降低抽取数据的时间复杂度。
知识库对学生行为数据表示的有效性用正确率表示,通过词频统计对实体正确率进行计算。从学生数据中采集x条行为数据,Cx表示每个学生产生的总行为的类集合,用y表示标记有误的数据,Cy(y=1,2,…,x)表示学生每天产生的错误数据类集合,Cx-y表示学生产生的正确数据类集合,|Cy|,|Cx-y|分别表示两个类集合中元素的个数,用P表示学生行为抽取的正确率。其计算公式为
(6)
P是介于0到1之间的概率值。
学生行为的异常判定标准是通过相对异常因子来判断的, 相对异常因子[17]的思想是用异常行为的数据与正常行为数据的量做比值。采用T衡量|Cy|和|Cx-y|在类体积上的相对变化率,其表达式为
(7)
如果T<1,则该行为正常,如果T>1,该行为则属于异常行为。
在相同的实验环境下,利用TextRank算法和随机游走技术构建的知识库与文献[18]中sym-KL算法构建的知识库对异常数据检测做对比分析,再将检测结果与相对异常标准做一致性对比,结果如表2所示。

表2 TextRank算法与sym-KL算法检测一致性占比/%
由表2可以看出,利用TextRank算法检测出的不一致的数据占比越来越小,sym-KL算法检测出不一致数据占比越来越高。因此,所采用的方法构建的知识库对实体的抽取、关系的指代及异常的检测准确率更高,具有可行性和操作性。
3.2.2 学生异常行为预测分析
对学生异常行为的预测是该实验的重要组成部分,也是对该方法构建知识库的一种检测应用。随机抽取3位学生的数据,从一卡通数据统计学习、消费、门禁、上网、考勤、借阅和就医数据次数,按照学校管理规范手册设置每一种行为数据的标准值,在数据分析工具中统计学生行为数据次数,如果超过标准值,则判定该行为出现异常[19]。3位同学行为数据与标准值的对比情况如图4所示。

图4 异常行为对比情况
由图4可知,如果学生1的学习数据、消费数据和门禁数据超出标准值,则判定该行为数据出现异常。因此,可以预测上网行为对学习成绩和考勤数据有影响,学校管理者可以提供针对性的教育指导。其他异常行为同理可判定。
3.3 结果分析
以上实验分析主要通过一卡通数据验证学生行为知识库构建的准确度和判定异常数据,利用TextRank算法和随机游走技术构建的知识库能够更加精准地提取关键词和关联度,实现知识库自适应性和自动推理功能,增强了知识库的健壮性和准确度。另一个模块主要是对构建知识库应用,通过一卡通数据统计学生不同的行为的活动次数与标准值的比对,判定异常数据,这种检测功能可以推广到学校智能分析系统。
4 结语
通过学生一卡通数据构建学生行为知识库,从数据的采集、预处理、入库分析和可视化多个阶段构建知识库,利用算法实现关键词的自动抽取、知识融合和更新操作。实验验证结果显示,该方法构建的知识库提升了自动推理和异常检测能力,能够处理动态变化和来源多样的复杂数据,也具有较高的异常预测功能。
猜你喜欢
锦州医科大学报(2022年3期)2022-06-06
学习与科普(2022年17期)2022-04-23
北京大学学报(自然科学版)(2022年1期)2022-02-21
军民两用技术与产品(2021年2期)2021-04-13
云南教育·小学教师(2021年12期)2021-03-23
福建基础教育研究(2020年3期)2020-05-28
新高考·高一物理(2015年5期)2015-08-18
——基于与QuestionPoint的对比
新世纪图书馆(2014年11期)2014-02-23
读写算·高年级(2009年3期)2009-11-16
